The dreaded 429 error—"Too Many Requests"—strikes fear into the hearts of developers working with the Claude API. One moment your application runs smoothly, processing requests with impressive speed. The next, you're staring at error logs filled with rate limit violations, frustrated users, and a system grinding to a halt. This comprehensive guide transforms that frustration into mastery, providing eight proven solutions that range from quick fixes to architectural improvements.
In 2025, as Claude's capabilities expand with Opus 4 and Sonnet 4 models, the demand on API infrastructure has intensified. Rate limits exist not as arbitrary restrictions but as necessary guardrails ensuring fair access and system stability. Understanding these limits—and more importantly, how to work within them—separates amateur implementations from production-ready systems. This guide provides the knowledge and tools to build resilient applications that gracefully handle rate limits while maximizing throughput.
Understanding Claude's Rate Limit System

Claude's rate limiting operates through three distinct mechanisms, each serving a specific purpose in maintaining system stability. Requests Per Minute (RPM) prevents server overload by limiting the number of API calls regardless of their complexity. Tokens Per Minute (TPM) manages computational load by restricting the total input and output tokens processed. Daily token quotas ensure fair usage distribution across all users over extended periods.
These limits vary dramatically based on your account tier. Free tier users might encounter limits as low as 5 RPM and 20,000 TPM, while enterprise customers negotiate custom limits reaching thousands of requests per minute. The tier system rewards consistent usage and account longevity—your limits automatically increase as you demonstrate responsible API usage over time. This progressive approach encourages developers to start small and scale gradually.
When any limit is exceeded, Claude responds with a 429 status code accompanied by specific error messages that identify which limit triggered the response. "Number of requests has exceeded your per-minute rate limit" indicates RPM violations, while "Number of request tokens has exceeded your daily rate limit" points to quota exhaustion. Understanding these messages proves crucial for implementing appropriate recovery strategies.
Decoding 429 Error Messages
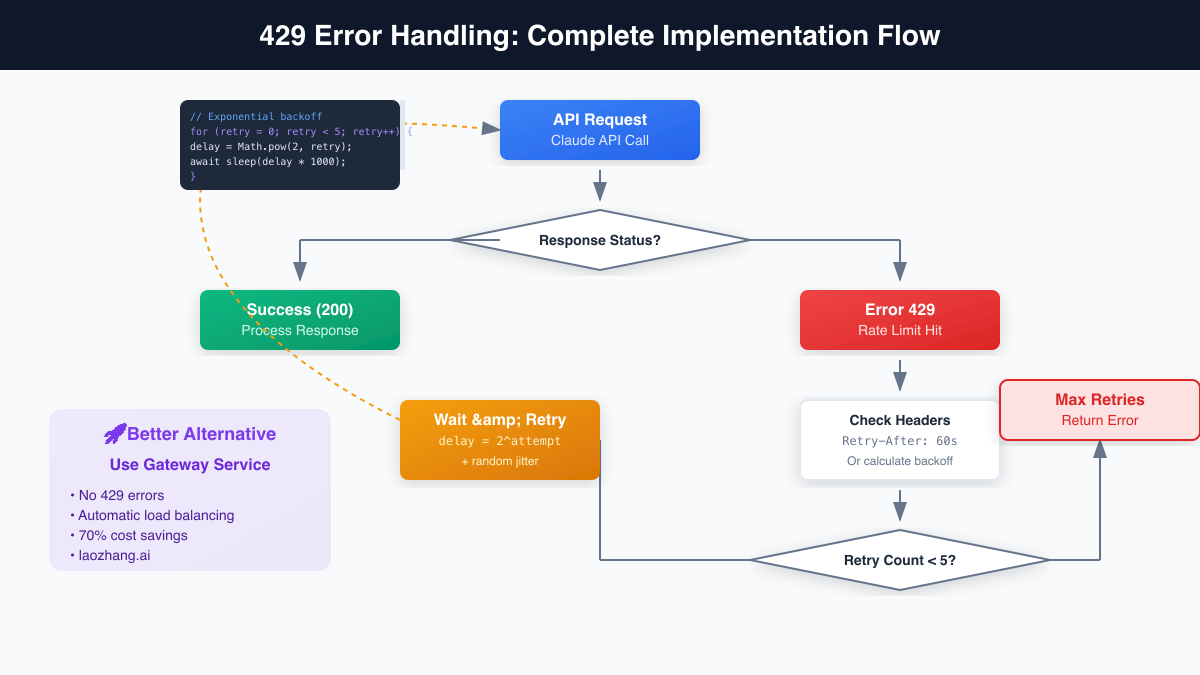
The anatomy of a 429 error response contains valuable information often overlooked in hasty debugging sessions. Beyond the status code, the response headers provide critical guidance for recovery. The Retry-After header, when present, specifies the exact number of seconds to wait before retry attempts. This server-provided timing represents the optimal recovery window, eliminating guesswork from retry logic.
Error response bodies follow a consistent structure that aids in programmatic handling. The type field always contains "error" for 429 responses, while the error object provides granular details including the specific rate limit violated and sometimes additional context about current usage levels. This structured approach enables sophisticated error handling that adapts to different limit types.
Real-world 429 errors often cluster around specific usage patterns. Morning peaks when automated systems activate simultaneously, end-of-day report generation creating token surges, and viral content driving unexpected user growth all trigger characteristic rate limit patterns. Recognizing these patterns in your application helps predict and prevent 429 errors before they impact users.
Solution 1: Implementing Exponential Backoff
Exponential backoff represents the foundational strategy for handling 429 errors, mandated by best practices and proven through decades of distributed systems experience. The algorithm delays retry attempts exponentially, starting with short waits that increase with each failure. This approach prevents thundering herd problems while giving the rate limit time to reset.
Here's a production-ready Python implementation with jitter:
pythonimport time import random import requests from typing import Optional, Dict, Any class ClaudeAPIClient: def __init__(self, api_key: str, max_retries: int = 5): self.api_key = api_key self.max_retries = max_retries self.base_delay = 1.0 # Start with 1 second self.max_delay = 60.0 # Cap at 60 seconds def make_request(self, endpoint: str, data: Dict[str, Any], attempt: int = 0) -> Optional[Dict]: """Make API request with exponential backoff retry logic""" headers = { 'x-api-key': self.api_key, 'anthropic-version': '2023-06-01', 'content-type': 'application/json' } try: response = requests.post( f'https://api.anthropic.com/v1/{endpoint}', json=data, headers=headers ) if response.status_code == 429: if attempt >= self.max_retries: raise Exception(f"Max retries ({self.max_retries}) exceeded") # Check for Retry-After header retry_after = response.headers.get('Retry-After') if retry_after: delay = float(retry_after) else: # Calculate exponential backoff with jitter delay = min(self.base_delay * (2 ** attempt), self.max_delay) jitter = random.uniform(0, delay * 0.1) # 10% jitter delay += jitter print(f"Rate limited. Waiting {delay:.2f}s before retry {attempt + 1}") time.sleep(delay) return self.make_request(endpoint, data, attempt + 1) response.raise_for_status() return response.json() except requests.exceptions.RequestException as e: if attempt < self.max_retries: delay = self.base_delay * (2 ** attempt) print(f"Request failed: {e}. Retrying in {delay}s") time.sleep(delay) return self.make_request(endpoint, data, attempt + 1) raise # Usage example client = ClaudeAPIClient('your-api-key') response = client.make_request('messages', { 'model': 'claude-3-opus-20240229', 'max_tokens': 1024, 'messages': [{'role': 'user', 'content': 'Hello, Claude!'}] })
The JavaScript implementation leverages async/await for cleaner error handling:
javascriptclass ClaudeAPIClient { constructor(apiKey, maxRetries = 5) { this.apiKey = apiKey; this.maxRetries = maxRetries; this.baseDelay = 1000; // 1 second in milliseconds this.maxDelay = 60000; // 60 seconds } async makeRequest(endpoint, data, attempt = 0) { const url = `https://api.anthropic.com/v1/${endpoint}`; try { const response = await fetch(url, { method: 'POST', headers: { 'x-api-key': this.apiKey, 'anthropic-version': '2023-06-01', 'content-type': 'application/json' }, body: JSON.stringify(data) }); if (response.status === 429) { if (attempt >= this.maxRetries) { throw new Error(`Max retries (${this.maxRetries}) exceeded`); } // Check for Retry-After header const retryAfter = response.headers.get('Retry-After'); let delay; if (retryAfter) { delay = parseInt(retryAfter) * 1000; } else { // Exponential backoff with jitter delay = Math.min( this.baseDelay * Math.pow(2, attempt), this.maxDelay ); const jitter = Math.random() * delay * 0.1; delay += jitter; } console.log(`Rate limited. Waiting ${delay}ms before retry ${attempt + 1}`); await this.sleep(delay); return this.makeRequest(endpoint, data, attempt + 1); } if (!response.ok) { throw new Error(`API error: ${response.status} ${response.statusText}`); } return await response.json(); } catch (error) { if (attempt < this.maxRetries && this.isRetryableError(error)) { const delay = this.baseDelay * Math.pow(2, attempt); console.log(`Request failed: ${error.message}. Retrying in ${delay}ms`); await this.sleep(delay); return this.makeRequest(endpoint, data, attempt + 1); } throw error; } } sleep(ms) { return new Promise(resolve => setTimeout(resolve, ms)); } isRetryableError(error) { return error.name === 'NetworkError' || error.name === 'TimeoutError' || error.message.includes('fetch failed'); } }
Solution 2: Client-Side Rate Limiting

While exponential backoff handles errors reactively, client-side rate limiting prevents them proactively. The token bucket algorithm provides an elegant solution, maintaining a "bucket" of available request tokens that refill at a constant rate. When the bucket empties, requests wait rather than hitting the API and triggering 429 errors.
Here's a sophisticated Python implementation using threading for accurate timing:
pythonimport threading import time from collections import deque from typing import Callable, Any class RateLimiter: def __init__(self, requests_per_minute: int, tokens_per_minute: int): self.rpm_limit = requests_per_minute self.tpm_limit = tokens_per_minute self.request_times = deque() self.token_count = 0 self.token_reset_time = time.time() self.lock = threading.Lock() def wait_if_needed(self, estimated_tokens: int) -> None: """Wait if request would exceed rate limits""" with self.lock: current_time = time.time() # Clean old request times while self.request_times and self.request_times[0] < current_time - 60: self.request_times.popleft() # Check RPM limit if len(self.request_times) >= self.rpm_limit: sleep_time = 60 - (current_time - self.request_times[0]) if sleep_time > 0: print(f"RPM limit reached. Sleeping {sleep_time:.2f}s") time.sleep(sleep_time) return self.wait_if_needed(estimated_tokens) # Check TPM limit if current_time - self.token_reset_time >= 60: self.token_count = 0 self.token_reset_time = current_time if self.token_count + estimated_tokens > self.tpm_limit: sleep_time = 60 - (current_time - self.token_reset_time) if sleep_time > 0: print(f"TPM limit would be exceeded. Sleeping {sleep_time:.2f}s") time.sleep(sleep_time) return self.wait_if_needed(estimated_tokens) # Record request self.request_times.append(current_time) self.token_count += estimated_tokens def execute_with_limit(self, func: Callable, estimated_tokens: int = 1000) -> Any: """Execute function with rate limiting""" self.wait_if_needed(estimated_tokens) return func() # Usage with Claude API rate_limiter = RateLimiter(requests_per_minute=50, tokens_per_minute=20000) def make_claude_request(): # Your actual API call here return client.make_request('messages', {...}) # Automatically rate-limited execution response = rate_limiter.execute_with_limit(make_claude_request, estimated_tokens=1500)
Solution 3: Request Queue & Priority System
Production applications often require more sophisticated request management than simple rate limiting provides. A priority queue system ensures critical requests process first while maintaining overall rate compliance. This approach proves invaluable for applications serving multiple user tiers or handling mixed workload types.
pythonimport heapq import threading import time from enum import Enum from dataclasses import dataclass from typing import Callable, Any, Optional class Priority(Enum): LOW = 3 MEDIUM = 2 HIGH = 1 CRITICAL = 0 @dataclass class QueuedRequest: priority: Priority timestamp: float func: Callable callback: Callable[[Any], None] error_callback: Callable[[Exception], None] def __lt__(self, other): # First by priority, then by timestamp if self.priority.value != other.priority.value: return self.priority.value < other.priority.value return self.timestamp < other.timestamp class PriorityRequestQueue: def __init__(self, rate_limiter: RateLimiter): self.rate_limiter = rate_limiter self.queue = [] self.lock = threading.Lock() self.worker_thread = threading.Thread(target=self._process_queue, daemon=True) self.running = True self.worker_thread.start() def add_request(self, func: Callable, priority: Priority = Priority.MEDIUM, callback: Optional[Callable] = None, error_callback: Optional[Callable] = None) -> None: """Add request to priority queue""" with self.lock: request = QueuedRequest( priority=priority, timestamp=time.time(), func=func, callback=callback or (lambda x: None), error_callback=error_callback or (lambda e: print(f"Error: {e}")) ) heapq.heappush(self.queue, request) def _process_queue(self): """Worker thread processing queued requests""" while self.running: with self.lock: if not self.queue: time.sleep(0.1) continue request = heapq.heappop(self.queue) try: # Execute with rate limiting result = self.rate_limiter.execute_with_limit(request.func) request.callback(result) except Exception as e: request.error_callback(e) def stop(self): """Gracefully stop the queue processor""" self.running = False self.worker_thread.join() # Usage example queue = PriorityRequestQueue(rate_limiter) # High priority request queue.add_request( lambda: client.make_request('messages', {'content': 'Urgent request'}), priority=Priority.HIGH, callback=lambda resp: print(f"High priority response: {resp}") ) # Lower priority batch processing for i in range(10): queue.add_request( lambda: client.make_request('messages', {'content': f'Batch {i}'}), priority=Priority.LOW )
Solution 4: Queueing and Capacity Planning for Sustained Load
While the previous solutions manage rate limits request by request, the next step is architectural: stop letting burst traffic hit the model layer directly. Queueing, traffic shaping, and capacity planning do not eliminate 429s by magic, but they are the most reliable way to keep them from becoming a recurring production incident.
The idea is straightforward:
- interactive traffic gets priority
- low-priority jobs enter a queue
- retries are controlled centrally
- batchable work is separated from latency-sensitive work
pythonimport queue import threading job_queue = queue.Queue() def worker(client): while True: job = job_queue.get() if job is None: break try: client.messages.create(**job) finally: job_queue.task_done()
This approach does not replace official rate limits. It makes your system behave predictably inside them.
Solution 5: Increasing Your Rate Limits
For organizations requiring direct API access with higher limits, Anthropic provides paths to increased quotas. The automatic tier progression rewards consistent, responsible usage—accounts demonstrating sustained activity without abuse see gradual limit increases. This organic growth suffices for many applications, requiring only patience and steady usage.
Enterprise agreements offer immediate access to higher limits for organizations with substantial needs. The process begins with documenting your requirements: expected request patterns, token usage projections, and business justification for increased limits. Anthropic's sales team evaluates these requests considering both technical capacity and business alignment.
The negotiation process typically involves several key points. Usage commitments often unlock preferential rates and higher limits—committing to minimum monthly spending demonstrates serious intent. Technical architecture reviews ensure your implementation efficiently uses allocated resources. Support level agreements may bundle increased limits with premium support access.
Best Practices and Prevention Strategies
Preventing 429 errors requires holistic thinking about API usage patterns. Request batching transforms multiple small requests into fewer large ones, dramatically reducing RPM pressure while maintaining throughput. Caching frequently requested data eliminates redundant API calls—implement intelligent cache invalidation to balance freshness with efficiency.
Token optimization deserves special attention given its direct impact on TPM limits. Prompt engineering that achieves the same results with fewer tokens provides immediate capacity increases. System prompts should be concise and reusable rather than repeated in each request. Response streaming, where supported, allows processing partial results without waiting for complete responses.
Monitoring forms the foundation of proactive rate limit management. Track not just errors but usage patterns approaching limits. Implement alerting when usage exceeds 80% of any limit, providing time for intervention before errors occur. Dashboard visibility into real-time usage helps identify optimization opportunities and usage anomalies.
Architecture Patterns for Scale
Scaling beyond single-account limits requires architectural evolution. The multi-account pattern distributes load across several API keys, each with independent limits. Implement intelligent routing that tracks per-account usage and directs requests to available capacity. This approach multiplies effective limits while maintaining single-point management.
Circuit breaker patterns prevent cascade failures when rate limits are reached. After detecting repeated 429 errors, the circuit breaker "opens," redirecting requests to fallback handling rather than overwhelming the API. This protects both your application and the API infrastructure from sustained overload conditions.
Hybrid architectures combine direct API access for latency-sensitive requests with queue-based or batch-based processing for background work. This approach optimizes for both performance and cost without making a third-party gateway the centerpiece of your 429 strategy.
Taking Action: Your 429 Prevention Toolkit
The journey from 429 frustration to implementation mastery begins with understanding your specific needs. For rapid prototyping and development, start with exponential backoff—it's simple, effective, and requires minimal code changes. As usage scales, add client-side rate limiting to prevent errors proactively rather than handling them reactively.
For production applications, the choice between solutions depends on your constraints. If you control the full stack and need minimal latency, implement comprehensive rate limiting with priority queues. If your load is sustained rather than bursty, move more work into queued or batch-friendly workflows and request higher official capacity when needed.
The solutions presented here aren't mutually exclusive. The most robust implementations combine client-side limiting, exponential backoff, caching, batching, and queueing. This defense-in-depth strategy ensures your application gracefully handles rate limits instead of turning them into outages.
Rate limits exist as features, not bugs—they ensure fair access and system stability for all users. By implementing these solutions thoughtfully, you transform potential frustrations into architectural strengths. Your applications become more resilient, cost-effective, and scalable. The 429 error, once a development nightmare, becomes just another handled edge case in your robust system design.