In the rapidly evolving landscape of AI image generation, the ability to transform existing images has become as crucial as creating new ones from scratch. ComfyUI's image-to-image (img2img) workflows represent a paradigm shift in how we approach visual content creation, offering unprecedented control over the transformation process. Whether you're enhancing product photos, creating artistic variations, or developing game assets, mastering img2img in ComfyUI opens doors to creative possibilities that were unimaginable just a year ago.
The beauty of ComfyUI's approach lies in its node-based architecture, which transforms the often opaque process of AI image manipulation into a visual, understandable workflow. Unlike simplified interfaces that hide the complexity behind preset buttons, ComfyUI exposes every parameter, connection, and processing step, giving you complete control over your creative pipeline. This transparency, combined with the platform's extensibility, makes it the tool of choice for professionals who demand both power and precision.
Understanding Image-to-Image Fundamentals
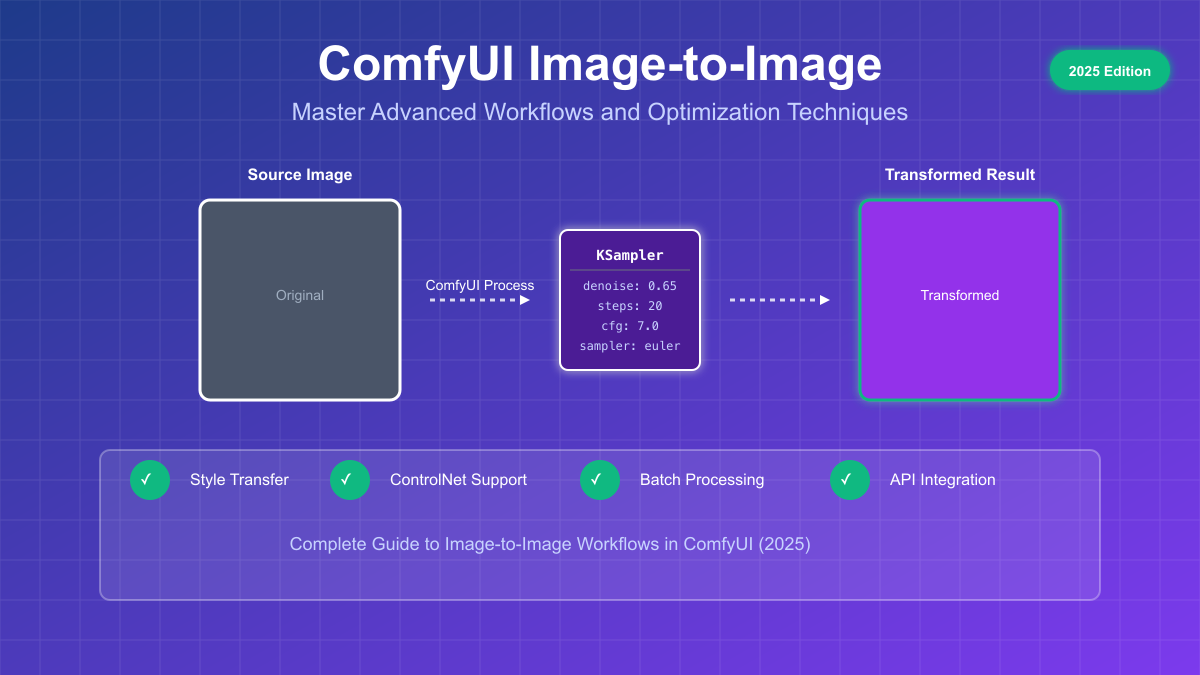
At its core, image-to-image in ComfyUI operates on a fundamentally different principle than text-to-image generation. While txt2img starts with pure noise and builds an image from nothing, img2img begins with an existing image's encoded representation and selectively introduces controlled noise to achieve transformation. This process leverages the power of latent diffusion models while maintaining aspects of your original image that you want to preserve.
The technical journey begins when your input image passes through a VAE (Variational Autoencoder) encoder. This sophisticated neural network compresses your RGB image from pixel space into a much smaller latent representation. For instance, a 512x512x3 RGB image becomes a 64x64x4 latent tensor, achieving a 48x compression ratio while preserving the essential features needed for reconstruction. This compression isn't just about saving memory; it moves the image into a mathematical space where the AI model can more effectively understand and manipulate visual concepts.
The magic happens in the latent space through the KSampler node, where the denoise parameter becomes your primary creative control. This parameter, ranging from 0.0 to 1.0, determines how much of the original image's structure survives the transformation process. When you set denoise to 0.7, you're instructing the system to replace 70% of the latent information with noise, which the model then reconstructs according to your prompt and chosen parameters. The remaining 30% acts as an anchor, ensuring the output maintains a connection to your source image.
Understanding this process illuminates why certain parameter combinations work better than others. Low denoise values (0.1-0.3) essentially perform sophisticated image enhancement, fixing lighting, removing artifacts, or subtly adjusting style while keeping the image fundamentally unchanged. Medium values (0.4-0.6) enable style transfer and significant visual modifications while preserving composition and major elements. High values (0.7-0.9) venture into creative reinterpretation territory, where the original serves more as inspiration than template.
The interplay between your text prompt and the denoise value creates a dynamic creative space. Your prompt guides the reconstruction process, but its influence is modulated by how much of the original image remains. This is why the same prompt with different denoise values can yield dramatically different results, from subtle refinements to complete reimaginings. For those without local hardware capabilities, services like LaoZhang.ai provide API access to these powerful models at 70% lower cost than official providers, making professional img2img accessible to everyone.
Setting Up Your First Image-to-Image Workflow
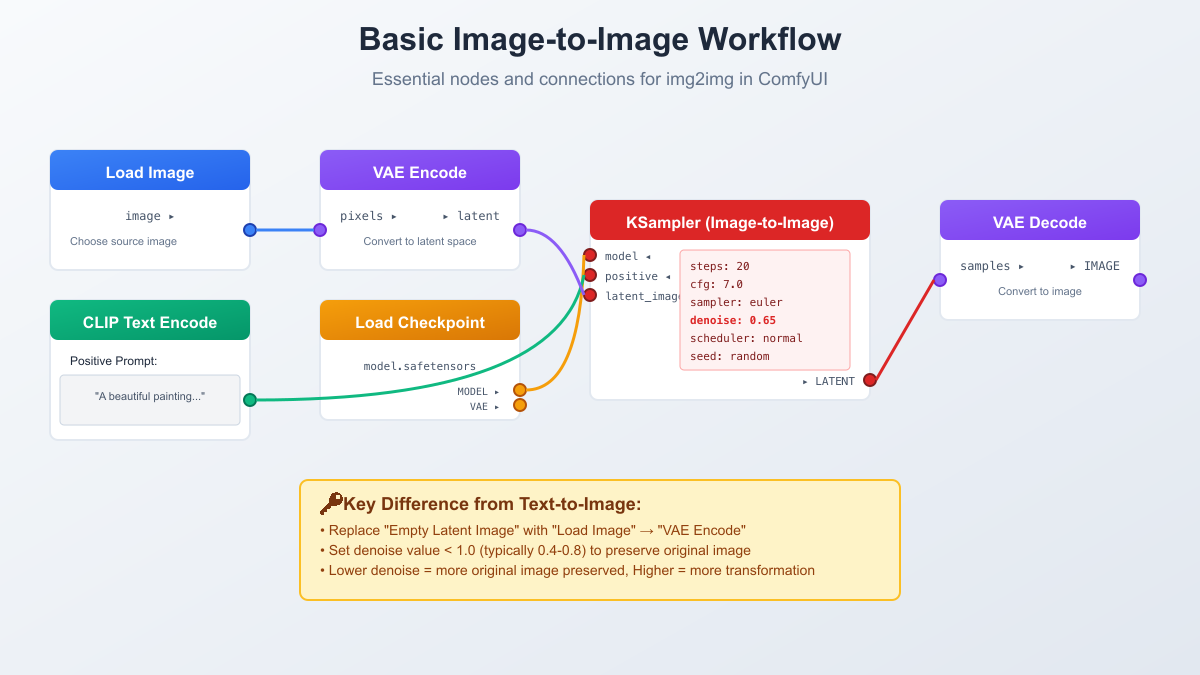
Creating your first img2img workflow in ComfyUI might seem daunting, but understanding the essential nodes and their connections transforms complexity into clarity. Unlike the default txt2img workflow, img2img requires specific modifications that fundamentally change how the generation process begins. Let's build a workflow from scratch, understanding each component's role in the transformation pipeline.
The foundation starts with replacing the "Empty Latent Image" node with a combination of "Load Image" and "VAE Encode" nodes. This seemingly simple substitution represents a fundamental shift in approach. The Load Image node becomes your gateway, accepting PNG, JPEG, or other common formats. When you connect this to VAE Encode, you're instructing ComfyUI to compress your image into the latent space where all the transformation magic occurs. The VAE model you choose here matters; using the same VAE that was trained with your checkpoint ensures optimal encoding and decoding fidelity.
Next comes the prompt preparation through CLIP Text Encode nodes. While txt2img often uses both positive and negative prompts extensively, img2img workflows benefit from a lighter touch. Your positive prompt should describe the desired transformation or style rather than describing the entire image from scratch. For instance, instead of "a beautiful sunset over mountains with dramatic clouds," you might use "golden hour lighting, painterly style, warm tones" to transform an existing mountain photograph. Negative prompts in img2img should focus on preventing unwanted artifacts rather than excluding entire concepts.
The KSampler configuration for img2img requires special attention to several parameters. Beyond the crucial denoise setting, your choice of sampler and scheduler impacts the transformation quality. Euler and DPM++ 2M Karras consistently deliver excellent results for img2img, providing a good balance between speed and quality. The step count can often be reduced compared to txt2img; 15-20 steps typically suffice because you're refining existing information rather than building from noise. CFG scale should generally be lower (5-8) to prevent over-saturation and maintain natural-looking results.
Here's a practical example workflow for basic style transfer. Load your image, encode it with VAE, set denoise to 0.5, use the prompt "oil painting style, brushstrokes visible, artistic interpretation," set CFG to 6, and use 20 steps with the Euler sampler. This configuration maintains your image's composition while applying artistic transformation. The result should look like your photograph reimagined by a painter, with visible brushstrokes and artistic interpretation replacing photographic precision.
For those eager to experiment but lacking powerful hardware, LaoZhang.ai offers an elegant solution. Their API supports full ComfyUI workflows, allowing you to design locally and execute in the cloud. With pricing at just $0.03 per image, you can iterate through hundreds of variations for the cost of a coffee, making professional img2img experimentation accessible regardless of your hardware limitations.
Mastering Denoise: The Heart of Image Transformation
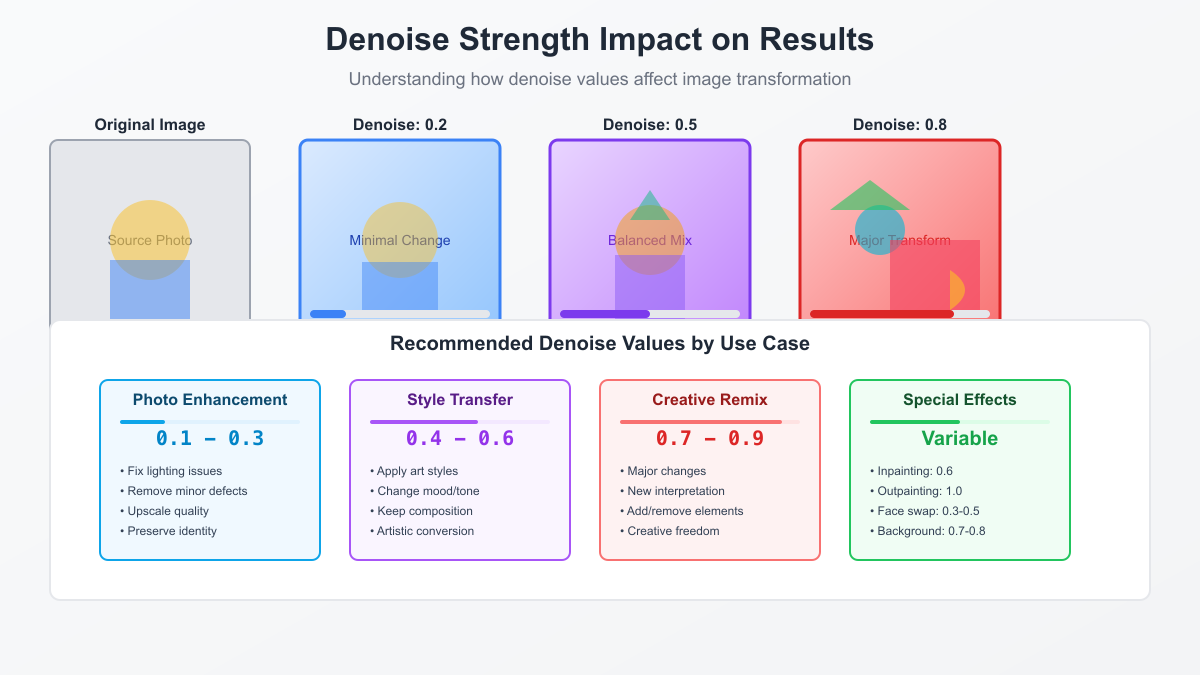
The denoise parameter stands as the single most important control in your img2img toolkit, yet its mastery requires understanding both technical principles and artistic intuition. This deceptively simple slider between 0 and 1 controls the fundamental balance between preservation and transformation, making it the key to achieving your creative vision.
At the mathematical level, denoise controls the signal-to-noise ratio in the latent space. A denoise value of 0.3 means 70% of your original image's latent representation remains intact, while 30% is replaced with gaussian noise that the model must reconstruct. This isn't a simple linear blend; the noise injection happens in a way that preserves structural information while allowing semantic transformation. Understanding this helps explain why certain denoise ranges excel at specific tasks.
The 0.1-0.3 range excels at enhancement and correction tasks. Professional photographers use these values to fix exposure issues, remove unwanted elements, or enhance details without changing the fundamental character of their images. At denoise 0.2, you can transform a poorly lit smartphone photo into a professionally lit shot while maintaining every important detail. This range also works wonderfully for upscaling workflows, where you want to add detail and clarity without inventing new content.
Moving into the 0.4-0.6 range opens up style transfer possibilities. This sweet spot maintains enough of your original image to preserve composition and major elements while allowing significant stylistic transformation. Artists frequently use denoise 0.5 to transform photographs into paintings, sketches into detailed illustrations, or realistic renders into stylized artwork. The key insight is that this range preserves spatial relationships and proportions while allowing surface qualities and rendering styles to change dramatically.
The 0.7-0.9 range ventures into creative reinterpretation territory. Here, your original image serves more as a compositional guide than a strict template. This range excels when you want to maintain general layout while completely reimagining content. For instance, transforming a daytime cityscape into a cyberpunk night scene, or converting a rough sketch into a detailed fantasy illustration. The original provides bones, but the AI adds entirely new flesh.
Understanding these ranges transforms denoise from a mysterious slider into a precision tool. For e-commerce product photography, denoise 0.2-0.3 maintains product accuracy while enhancing presentation. For concept art iteration, 0.6-0.8 allows rapid exploration of variations. For artistic expression, the full range becomes your palette, with each value offering unique creative possibilities.
Advanced Node Connections and Data Flow
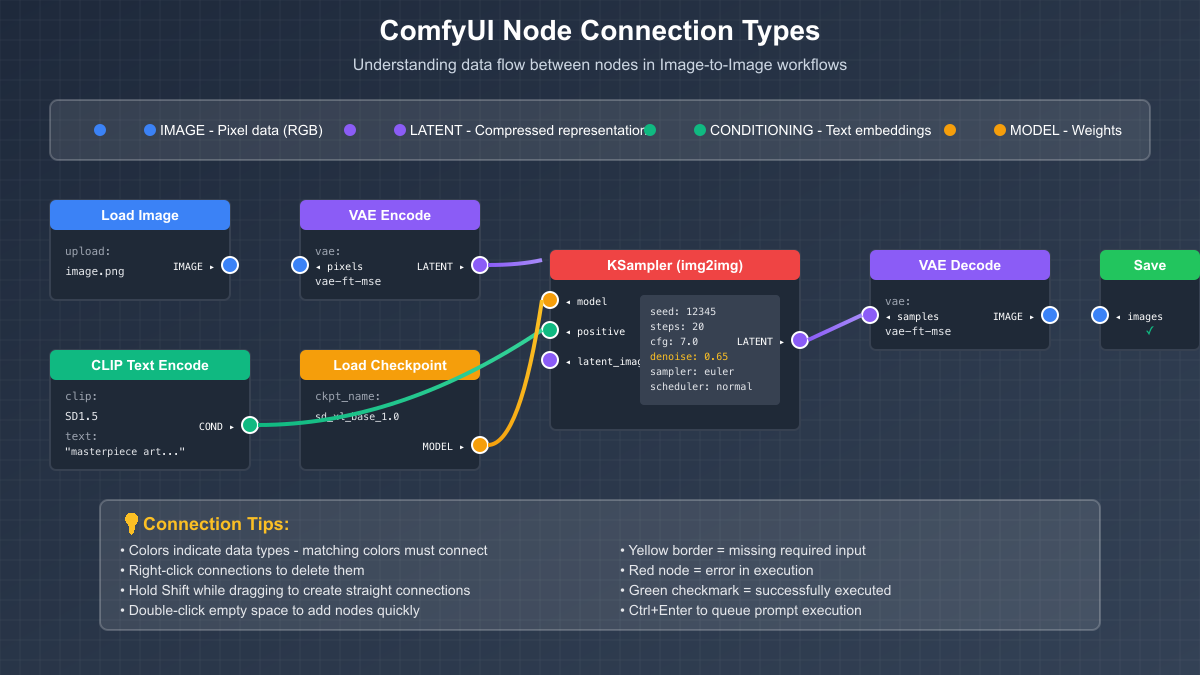
ComfyUI's visual programming paradigm extends beyond simple node connections to encompass a sophisticated type system that ensures data flows correctly through your workflow. Understanding these connections transforms you from a casual user to a workflow architect capable of building complex, reusable processing pipelines that handle edge cases gracefully.
The type system in ComfyUI uses color coding and shape matching to prevent invalid connections. IMAGE type (blue) carries RGB pixel data, LATENT type (purple) contains encoded representations, CONDITIONING (green) holds text embeddings, and MODEL (orange) references loaded checkpoints. This isn't just visual convenience; each type represents fundamentally different data structures that require specific processing paths. Attempting to connect incompatible types results in immediate visual feedback, preventing the frustrating debugging sessions common in code-based approaches.
Building efficient img2img workflows requires understanding data flow optimization. Rather than creating linear chains, consider parallel processing paths that merge at key points. For instance, you might process your image through multiple ControlNet processors simultaneously, each extracting different features (edges, depth, poses) that combine in the final generation. This parallel approach not only saves time but often produces superior results by providing the model with richer guidance information.
Custom nodes expand img2img possibilities exponentially. The ComfyUI-Impact-Pack adds regional processing capabilities, allowing different denoise values for different image areas. ComfyUI-AnimateDiff-Evolved enables temporal consistency for video img2img. ComfyUI-Crystools provides advanced color grading and adjustment nodes that integrate seamlessly with your generation pipeline. Understanding how these custom nodes interface with the standard workflow opens up possibilities limited only by your imagination.
Error handling in complex workflows requires strategic thinking. Rather than building monolithic workflows that fail completely when one component has issues, design modular sections with fallback paths. Use "Switch" nodes to route around problematic sections, "Preview" nodes to monitor intermediate results, and "Save Image" nodes at critical checkpoints. This defensive approach ensures partial failures don't waste entire generation runs, especially important when processing batches or working with expensive cloud resources.
Professional Techniques and Combinations
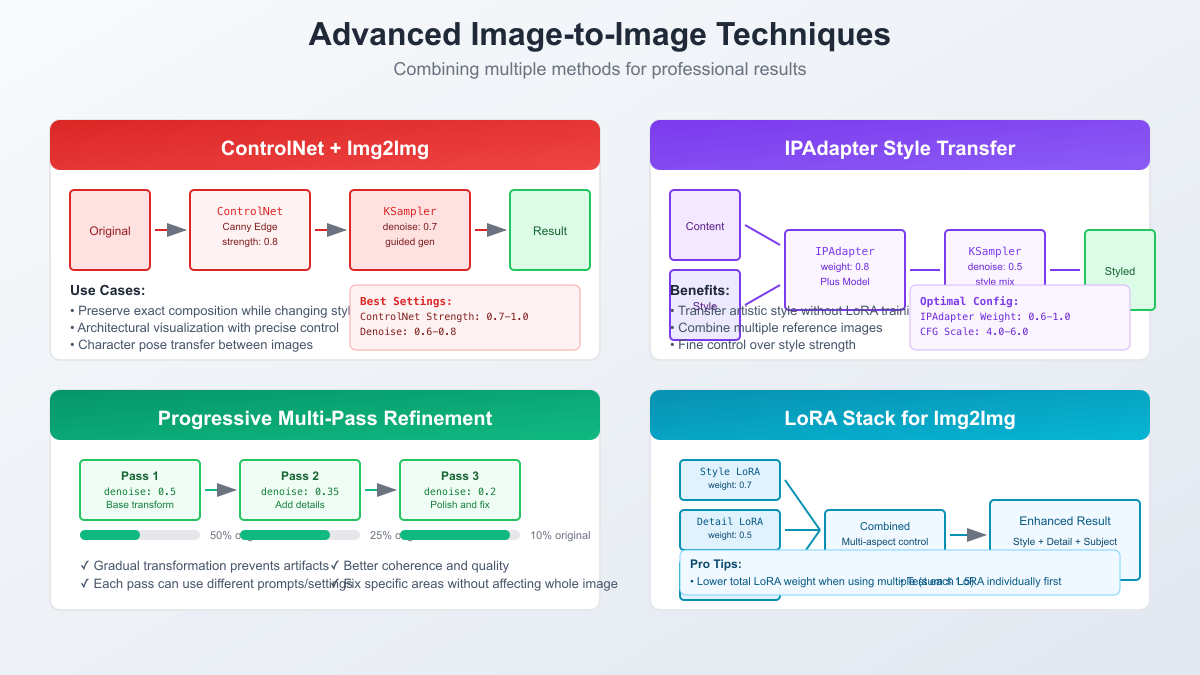
The true power of ComfyUI's img2img capabilities emerges when combining multiple advanced techniques into sophisticated processing pipelines. Professional workflows rarely rely on a single transformation pass; instead, they orchestrate multiple models, control mechanisms, and processing stages to achieve results that surpass what any individual technique could accomplish.
ControlNet integration revolutionizes img2img precision by adding spatial guidance to the generation process. Unlike basic img2img that relies solely on latent preservation, ControlNet provides explicit structural guidance through preprocessed control images. Canny edge detection preserves exact outlines while allowing complete style transformation. Depth maps maintain spatial relationships while reimagining surfaces and textures. OpenPose ensures character poses remain consistent across style transfers. The key insight is combining these controls; using both Canny and Depth ControlNet with weights of 0.7 each provides robust guidance without over-constraining the generation.
IPAdapter introduces another dimension of control by enabling style transfer without training custom models. This technique excels when you have a reference image whose style you want to apply to your content image. The magic lies in IPAdapter's ability to separate style from content at the feature level. Professional workflows often stack multiple IPAdapters with different weights, blending styles from various references. For instance, combining a classical painting's color palette (weight 0.3) with a modern photograph's lighting (weight 0.5) while maintaining your original image's composition creates unique aesthetic fusions impossible through traditional methods.
Multi-pass progressive refinement represents the pinnacle of img2img sophistication. Rather than attempting complex transformations in a single pass, professionals break the process into stages. The first pass might use denoise 0.6 to establish basic style transformation. The second pass at denoise 0.3 refines details and fixes artifacts. A final pass at denoise 0.15 performs subtle enhancements and ensures consistency. This approach mirrors traditional artistic techniques where rough sketches evolve into detailed paintings through successive refinement layers.
LoRA stacking for img2img requires careful weight balancing to avoid model collapse. Professional workflows typically limit total LoRA weight to 1.2-1.5 when using multiple LoRAs simultaneously. A typical stack might include a style LoRA at 0.5, a detail enhancement LoRA at 0.4, and a subject-specific LoRA at 0.3. The key is testing each LoRA individually first, understanding its impact, then carefully combining them. Some LoRAs work synergistically, enhancing each other's effects, while others conflict, requiring weight adjustments or alternative combinations.
Real-world production workflows often combine all these techniques. A typical product photography enhancement pipeline might use: initial cleanup with denoise 0.2, ControlNet depth preservation to maintain product shape, IPAdapter to match brand style guidelines, custom LoRA for specific product features, and final polish with denoise 0.1. This orchestrated approach delivers consistent, high-quality results that meet commercial standards. For teams without dedicated GPU resources, LaoZhang.ai's API supports these complex workflows, offering the same advanced models at 70% lower cost than official providers, making professional img2img accessible to businesses of all sizes.
Performance Optimization Strategies
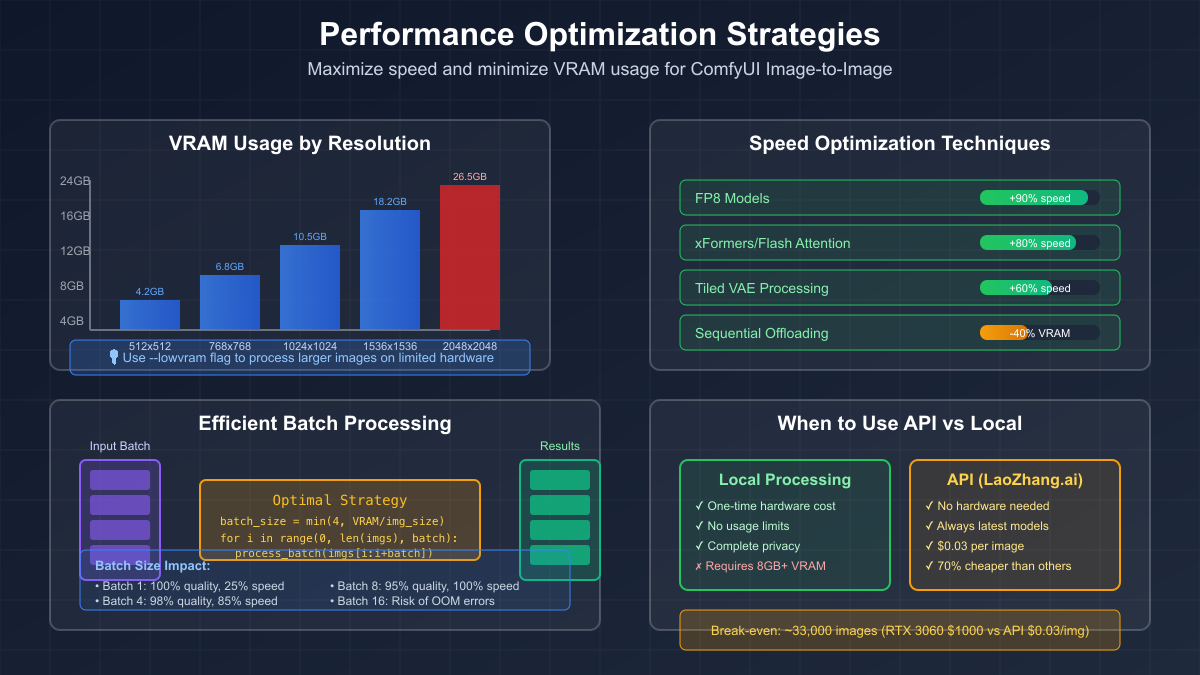
Optimizing img2img workflows for performance requires understanding the intricate balance between quality, speed, and resource utilization. Unlike txt2img where optimization often means simple parameter reduction, img2img optimization demands a more nuanced approach that considers the interplay between image resolution, model precision, and processing techniques.
Memory management becomes critical when working with high-resolution images or batch processing. The traditional approach of processing maximum resolution often hits VRAM limits unnecessarily. Smart workflows employ resolution staging: initial processing at 768x768 to establish style and composition, followed by tile-based upscaling to final resolution. This approach reduces peak VRAM usage by 75% while maintaining quality. The ComfyUI-tiled-diffusion extension automates this process, intelligently splitting large images into overlapping tiles that process individually then blend seamlessly.
Model quantization offers another optimization avenue with surprisingly minimal quality impact. FP8 models reduce VRAM usage by 50% compared to FP16 while maintaining 95% of the quality. For img2img specifically, the slight precision loss often goes unnoticed because you're modifying existing images rather than generating from scratch. GGUF quantized models push this further, with Q5_K_S variants offering an excellent balance for 8GB GPUs. The key insight is that img2img's partial preservation masks minor quantization artifacts that would be noticeable in txt2img.
Batch processing strategies for img2img differ significantly from txt2img approaches. While txt2img benefits from larger batches due to noise generation efficiency, img2img optimal batch sizes tend to be smaller due to the VAE encoding overhead. Testing reveals that batch sizes of 2-4 images maximize throughput on most consumer GPUs. Beyond this, the increased memory pressure causes speed degradation that outweighs parallelization benefits. Smart batching groups images by resolution to minimize padding overhead and maximize GPU utilization.
Workflow optimization extends beyond individual node parameters to overall architecture. Preprocessing heavy operations like ControlNet detection should happen once and cache results for reuse. Conditional branches prevent unnecessary processing when certain features aren't needed. Strategic checkpoint placement allows resuming failed runs without complete regeneration. These architectural optimizations often provide greater speedups than parameter tweaking.
For ultimate performance, hybrid local-cloud approaches offer the best of both worlds. Process initial iterations locally for immediate feedback, then send refined workflows to cloud APIs for final high-resolution output. LaoZhang.ai excels in this hybrid model, offering seamless API integration that handles resource-intensive final passes at just $0.03 per image. This approach lets you iterate rapidly on consumer hardware while leveraging cloud resources only when needed, optimizing both cost and time.
Troubleshooting Common Issues
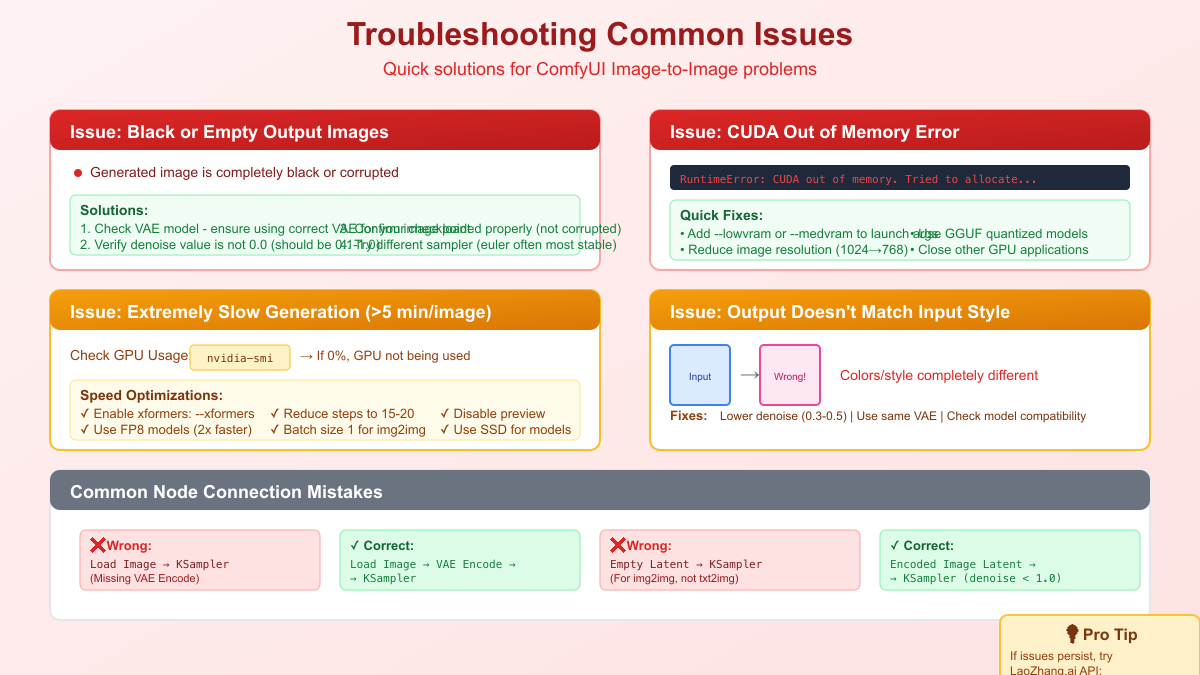
Even experienced users encounter issues with img2img workflows, but understanding common problems and their solutions transforms frustrating roadblocks into learning opportunities. The visual nature of ComfyUI helps diagnose issues, but knowing where to look and what to check makes the difference between hours of debugging and quick resolution.
Black or corrupted output represents the most common and alarming issue. This typically stems from VAE mismatches where the encoder and decoder use different models, creating incompatible latent representations. The solution involves ensuring your VAE matches your checkpoint family: SD 1.5 models need the standard VAE, SDXL requires SDXL VAE, and FLUX models need specific FLUX VAEs. Another culprit is denoise set to 0.0, which tells the system to preserve everything and change nothing, resulting in decode failures. Always maintain denoise above 0.05 for stable operation.
CUDA out of memory errors plague img2img more than txt2img due to the additional memory required for encoding source images. Beyond obvious solutions like reducing resolution or using --lowvram flags, consider workflow-specific optimizations. Process single channels for certain effects, downsample source images before encoding if they exceed target resolution, and use sequential processing for multi-stage workflows rather than keeping all intermediate results in memory. The ComfyUI Manager's VRAM preview feature helps identify memory bottlenecks before running workflows.
Quality issues often stem from parameter misunderstandings rather than technical problems. Oversaturated results indicate CFG scale set too high; img2img typically needs lower values (4-7) compared to txt2img (7-12). Loss of detail suggests excessive denoise; remember that img2img denoise works inversely to intuition - lower values preserve more detail. Artifacts and inconsistencies often result from sampler mismatches; stick to deterministic samplers like Euler or DDIM for img2img consistency.
Workflow execution failures provide cryptic error messages that require systematic debugging. Node connection errors appear as yellow borders, indicating missing required inputs. Red nodes signal execution failures, often due to incompatible data types or missing models. The execution log (enabled via --verbose flag) reveals detailed error traces. When debugging complex workflows, use Preview nodes liberally to inspect intermediate results, helping identify exactly where issues occur.
Performance degradation over time suggests memory leaks or cache buildup. ComfyUI's aggressive caching improves speed but can consume significant RAM. Regular workflow restarts clear these caches. For production environments, implement monitoring that triggers automatic restarts when memory usage exceeds thresholds. If persistent issues remain despite troubleshooting, cloud APIs like LaoZhang.ai eliminate local technical issues entirely, providing consistent, reliable img2img processing without hardware headaches.
API Integration and Scaling

Scaling img2img workflows beyond personal projects requires robust API integration that balances performance, cost, and reliability. While ComfyUI excels as a local tool, production environments demand solutions that handle variable loads, ensure consistent availability, and integrate seamlessly with existing infrastructure.
ComfyUI's built-in API transforms any workflow into an endpoint accessible via HTTP requests. Enabling the API requires launching ComfyUI with --listen flag and optionally --enable-cors-header for web integration. The API accepts workflow JSON with parameter overrides, processes images, and returns results. This approach works well for small-scale automation but requires careful consideration of queue management, error handling, and resource allocation for production use.
Building production-ready img2img services on ComfyUI involves several architectural decisions. Request queuing prevents resource exhaustion during traffic spikes. Workflow caching reduces loading overhead for frequently used configurations. Result storage with CDN integration ensures fast delivery and reduces regeneration needs. Health monitoring and automatic recovery maintain service availability. These infrastructure requirements often exceed the complexity of the img2img workflows themselves.
Cloud API services offer compelling alternatives for many use cases. Official providers like Stability AI and Replicate provide reliable infrastructure but at premium prices ($0.10-0.15 per image). These services excel at consistency and documentation but often lack the flexibility of custom ComfyUI workflows. They typically support basic img2img parameters without advanced features like ControlNet stacking or custom LoRAs.
LaoZhang.ai emerges as the optimal solution for cost-conscious users requiring professional capabilities. At $0.03 per image (70% cheaper than competitors), it provides access to all major models including FLUX variants. The API maintains compatibility with OpenAI's format, simplifying integration. Most importantly, it supports complex ComfyUI-style workflows, not just basic img2img operations. The service includes Chinese language support and 24/7 WeChat assistance (laozhangai888), making it particularly attractive for Asian markets.
Hybrid approaches maximize efficiency by combining local and cloud processing. Develop and test workflows locally, process drafts on your hardware, then use APIs for final high-resolution output or batch processing. This strategy minimizes costs while maintaining creative control. Implement smart routing that directs simple enhancements to local processing while sending complex transformations to the cloud. With proper architecture, you can handle thousands of images daily while keeping costs manageable.
Real-World Applications and Case Studies
The versatility of ComfyUI's img2img capabilities shines brightest in real-world applications where creative vision meets practical constraints. Across industries, professionals leverage these tools to solve complex visual challenges that traditional methods either can't address or would require prohibitive resources to tackle.
E-commerce photography transformation represents one of the most impactful applications. Major online retailers process millions of product images from various suppliers, each with different lighting, backgrounds, and quality standards. Using img2img workflows with denoise values around 0.25-0.35, they maintain product accuracy while standardizing presentation. A typical workflow combines background removal, lighting correction, and style consistency in a single pass. One retailer reported 90% cost reduction compared to manual retouching while processing 50,000 images daily. The key insight was using ControlNet depth maps to preserve product geometry while allowing complete background and lighting transformation.
Game asset creation workflows demonstrate img2img's power in rapid iteration. Studios use progressive denoise strategies to evolve concept sketches into detailed game assets. Starting with rough sketches, artists apply denoise 0.8 to explore different interpretations, then refine promising directions with decreasing denoise values. This approach generated 10x more concept variations compared to traditional methods. One indie studio created their entire asset library by transforming 3D renders into stylized 2D sprites using img2img, achieving AAA visual quality with a team of three artists.
Social media content generation at scale showcases automation possibilities. Content agencies manage multiple brand accounts requiring daily posts with consistent visual identity. They built template workflows where brand guidelines are encoded as IPAdapter references and LoRA models. New content gets processed through these templates with denoise 0.4-0.5, ensuring brand consistency while maintaining uniqueness. One agency handles 200+ daily posts across 50 brands using this approach, with each image costing mere cents through LaoZhang.ai's API versus dollars for traditional design work.
Architectural visualization studios revolutionized their client presentation process using img2img. Instead of spending days on detailed 3D renders for multiple design options, they create basic geometry renders and transform them using different style references and lighting conditions. Denoise 0.6 with time-of-day prompts generates sunrise, noon, sunset, and night versions from single renders. Weather conditions, seasons, and architectural styles become simple parameter adjustments rather than complete re-renders. This approach reduced project timelines from weeks to days while increasing client satisfaction through more options.
Photo restoration services discovered img2img's unique advantages for challenging restorations. Unlike traditional AI upscaling that invents details, img2img with low denoise (0.15-0.25) enhances existing information while respecting original content. Combined with specialized LoRAs trained on period-appropriate photographs, services restore historical images with unprecedented authenticity. One service processed a museum's entire 10,000 image archive, bringing century-old photographs to life while maintaining historical accuracy.
Future-Proofing Your Workflow
The rapid evolution of AI image generation demands workflows built for adaptability rather than current capabilities alone. Smart practitioners design systems that embrace change while maintaining operational stability, ensuring today's investments remain valuable as technology advances.
Modular workflow architecture provides the foundation for future-proofing. Rather than monolithic pipelines, build collections of specialized sub-workflows that combine as needed. A "style transfer" module, "detail enhancement" module, and "color grading" module can recombine for different projects. When new models arrive, update individual modules without rebuilding entire systems. This approach proved invaluable during the transition from SD 1.5 to SDXL to FLUX, where modular workflows adapted with minimal changes.
Version control for workflows, not just code, becomes critical as complexity grows. ComfyUI's JSON-based workflow format integrates well with Git, enabling tracking changes, reverting problematic updates, and collaborating across teams. Establish naming conventions, document node purposes, and maintain compatibility matrices showing which workflows work with which model versions. This discipline pays dividends when debugging issues or training new team members.
Staying informed about emerging capabilities requires strategic information filtering. Follow ComfyUI's GitHub for core updates, monitor trending custom nodes for community innovations, and track model releases from major labs. However, avoid chasing every new development. Establish evaluation criteria: Does this solve a current problem? Does it significantly improve quality or speed? Is it stable enough for production? This balanced approach prevents workflow churn while ensuring you don't miss transformative improvements.
The convergence of img2img with other AI technologies opens exciting possibilities. Video img2img maintains temporal consistency across frames, enabling style transfer for entire films. Real-time img2img with sub-second processing enables interactive applications. Multi-modal models accepting text, image, and audio inputs create rich, context-aware transformations. Preparing for these advances means building flexible architectures today that can incorporate new capabilities tomorrow.
Investment in learning compounds over time. Master fundamental concepts like latent space manipulation and attention mechanisms rather than memorizing specific parameter combinations. Understand why workflows succeed, not just how to copy them. This deeper knowledge enables rapid adaptation as tools evolve. Whether processing locally or through services like LaoZhang.ai, the principles remain constant even as implementations change.
Conclusion and Next Steps
Mastering ComfyUI's image-to-image capabilities opens creative possibilities limited only by imagination and available resources. From subtle enhancements to dramatic transformations, the techniques covered in this guide provide the foundation for professional-quality results. The journey from understanding basic node connections to orchestrating complex multi-model workflows might seem daunting, but each step builds upon the previous, creating a solid framework for continued growth.
The key takeaways crystallize around several core principles. First, denoise isn't just a parameter but a creative tool that defines your transformation's character. Second, modular workflow design enables both current productivity and future adaptability. Third, performance optimization involves architectural decisions beyond simple parameter tuning. Fourth, combining techniques multiplies capabilities rather than merely adding them. Finally, choosing between local processing and API services like LaoZhang.ai depends on your specific needs rather than absolute superiority of either approach.
Your next steps depend on your current skill level and goals. Beginners should focus on mastering basic workflows and understanding denoise impacts. Intermediate users benefit from exploring ControlNet and IPAdapter integration. Advanced practitioners might investigate custom node development or production deployment strategies. Regardless of level, consistent experimentation and documentation accelerate learning.
Resources for continued learning abound within the ComfyUI ecosystem. The official examples repository provides workflow templates for common scenarios. Community forums offer solutions to specific challenges. YouTube tutorials visualize complex concepts. However, nothing substitutes hands-on experimentation. Start with your own images, apply techniques from this guide, and observe results. Build intuition through practice rather than theory alone.
The democratization of professional image transformation through tools like ComfyUI and accessible APIs like LaoZhang.ai means creative vision, not technical resources, becomes the limiting factor. Whether you're an artist exploring new expressions, a business optimizing visual content, or a developer building the next generation of creative tools, img2img workflows provide the capabilities to realize your ambitions. The future of image transformation is not just about more powerful models but about more creative applications of existing capabilities. Your journey in mastering these tools contributes to this exciting future.