
Introduction: The Truth About Free Grok 4 API Access
Let me be direct: there is no official free Grok 4 API tier. If you're searching for completely free access to xAI's latest model that just launched yesterday (July 9, 2025), you'll need to adjust your expectations. However, don't close this page yet – I'll show you exactly how to access Grok 4's industry-leading capabilities at a fraction of the official cost, plus several genuinely free alternatives that might meet your needs.
Grok 4 represents a quantum leap in AI capabilities, achieving benchmark scores that leave competitors in the dust. With a 45% score on Humanity's Last Exam (more than double GPT-4's performance), 95% on AIME mathematics competitions, and 75% on software engineering tasks, it's clear why developers are eager to integrate this powerhouse into their applications.
The challenge? Official API access requires an X Premium+ subscription at $40/month, plus API costs that can quickly spiral out of control. But here's the good news: smart developers have found ways to slash these costs by up to 70%, and I'm about to share every method with you.
What is Grok 4? xAI's Breakthrough AI Model
The July 9, 2025 Launch That Changed Everything
Yesterday's livestream announcement from xAI wasn't just another model update – it was a declaration of AI supremacy. Grok 4 arrives in two distinct flavors that cater to different use cases:
Grok 4 General: The all-purpose reasoning champion that excels at complex problem-solving, mathematical proofs, and nuanced language understanding. This is the model that scored 45% on HLE, leaving Gemini 2.5 Pro's 21% score looking antiquated.
Grok 4 Code: A specialized variant that achieved 75% on SWE-bench, positioning it as the ultimate coding companion. Early testers report it can autonomously debug complex codebases, refactor legacy systems, and even plan entire software architectures. The model identifier "grok-4-code-0629" has been spotted in xAI console listings, suggesting extensive pre-launch testing with select partners.
Revolutionary Features That Set Grok 4 Apart
What makes Grok 4 worth its premium price tag? Let's break down the game-changing capabilities:
Real-time X Integration: Unlike models trained on static datasets, Grok 4 pulls live data directly from X (formerly Twitter). During breaking news events, market crashes, or viral trends, Grok 4 knows what's happening NOW, not what happened months ago when other models were last trained. This real-time awareness transforms it from a smart assistant into a genuinely informed partner.
Autonomous Long-Duration Tasks: Grok 4 can work independently for extended periods, handling multi-step projects that would require constant human supervision with other models. Imagine setting it loose on a codebase refactoring project and returning hours later to find not just completed code, but documentation, test cases, and deployment scripts.
Transparent Reasoning Process: Unlike the black-box nature of most AI models, Grok 4 can show its work. Users can peek behind the curtain to understand how it arrived at conclusions, making it invaluable for high-stakes decisions where accountability matters.
Benchmark Domination: The Numbers Don't Lie
Let me put Grok 4's performance into perspective with hard data:
| Benchmark | Grok 4 | GPT-4 | Claude 3 | Gemini 2.5 Pro |
|---|---|---|---|---|
| HLE (Reasoning) | 45% | ~20% | ~22% | 21% |
| AIME (Math) | 95% | 85% | 88% | 82% |
| SWE-bench (Coding) | 75% | 50% | 72.5% | 45% |
| GPQA (Graduate Level) | 88% | 82% | 85% | 80% |
These aren't incremental improvements – they're generational leaps. The 45% HLE score means Grok 4 solves complex reasoning problems that stump every other model on the market.
Official Grok 4 API: Pricing & Requirements
The Price of Excellence
Let's rip off the band-aid: accessing Grok 4 through official channels isn't cheap. Here's the complete cost breakdown:
Prerequisites:
- X Premium+ Subscription: $40/month (or $32.92/month if billed annually)
- This subscription is mandatory – there's no way around it for official API access
- Regional restrictions apply – not available in all countries
API Pricing (based on Grok 3 rates, Grok 4 pricing pending):
- Input: $3 per million tokens
- Output: $15 per million tokens
- Context window: 131,072 tokens
Real-World Cost Example: Let's say you're building a coding assistant that processes 100 pull requests daily, each averaging 5,000 input tokens and generating 2,000 output tokens:
Daily token usage:
- Input: 100 × 5,000 = 500,000 tokens
- Output: 100 × 2,000 = 200,000 tokens
Daily API cost:
- Input: 0.5 × \$3 = \$1.50
- Output: 0.2 × \$15 = \$3.00
- Total: \$4.50/day
Monthly cost:
- API: \$4.50 × 30 = \$135
- X Premium+: \$40
- Total: \$175/month
For a small startup or individual developer, $175/month for a single API integration is steep.
Access Limitations and Restrictions
Beyond the price, official API access comes with several hurdles:
- Geographic Restrictions: Many countries can't access xAI services directly
- Payment Methods: Only accepts international credit cards
- Rate Limits: Strict limits on requests per minute
- Setup Complexity: Multi-step verification process through X platform
Save 70% with LaoZhang AI: The Smart Alternative
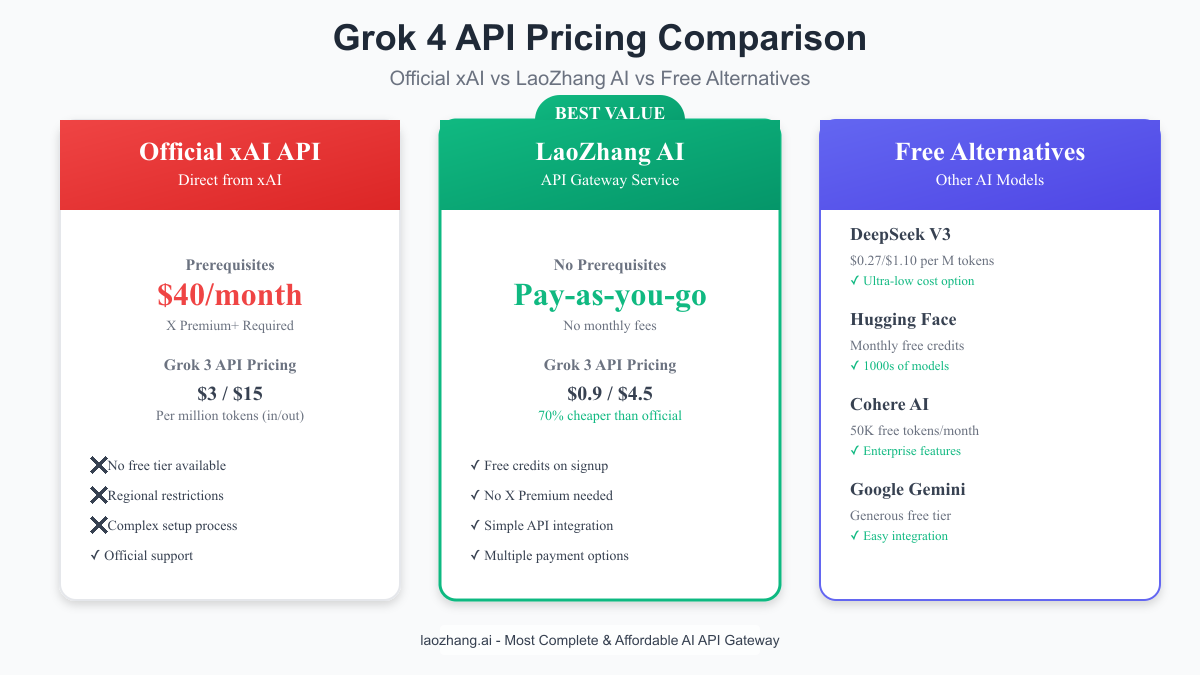
Why LaoZhang AI Changes the Game
LaoZhang AI operates as an API gateway service, providing access to multiple AI models including Grok at significantly reduced rates. Here's how they achieve 70% cost savings:
Pricing Comparison:
| Model | Official Price | LaoZhang AI | Savings |
|---|---|---|---|
| Grok 3 Input | $3/M tokens | $0.9/M tokens | 70% |
| Grok 3 Output | $15/M tokens | $4.5/M tokens | 70% |
| No Monthly Fee | $40 X Premium+ | $0 | 100% |
Key Advantages:
- No X Premium+ subscription required
- Pay-as-you-go model with no minimums
- Multiple payment options (including local payment methods)
- Free credits on signup for testing
- English and Chinese support
Quick Start Tutorial
Getting started with LaoZhang AI takes less than 5 minutes:
Step 1: Register for an Account
Visit: https://api.laozhang.ai/register/
Sign up with email to receive free trial credits
Step 2: Obtain Your API Key Navigate to the dashboard and create a new API key. The interface is straightforward – no complex verification process required.
Step 3: Make Your First API Call
pythonimport requests import json # Your LaoZhang API configuration API_KEY = "your-laozhang-api-key" API_BASE = "https://api.laozhang.ai/v1" def call_grok_api(prompt, model="grok-3"): """ Call Grok API through LaoZhang gateway """ headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" } data = { "model": model, "messages": [ {"role": "user", "content": prompt} ], "max_tokens": 2000, "temperature": 0.7 } response = requests.post( f"{API_BASE}/chat/completions", headers=headers, json=data ) if response.status_code == 200: return response.json()['choices'][0]['message']['content'] else: return f"Error: {response.status_code} - {response.text}" # Example usage result = call_grok_api("Explain quantum computing in simple terms") print(result)
Cost Analysis: Real Projects
Let's revisit our earlier example with LaoZhang AI pricing:
Same usage (100 PR reviews daily):
- Input: 500,000 tokens × \$0.0009 = \$0.45
- Output: 200,000 tokens × \$0.0045 = \$0.90
- Daily cost: \$1.35
- Monthly cost: \$40.50
Compared to official pricing:
- Official: \$175/month
- LaoZhang: \$40.50/month
- Savings: \$134.50/month (77% reduction!)
5 Free AI API Alternatives to Grok 4
While Grok 4's capabilities are unmatched, not every project needs bleeding-edge performance. Here are five alternatives with generous free tiers:
1. DeepSeek V3 - The Ultra-Budget Champion
DeepSeek has disrupted the AI market with pricing that seems too good to be true:
Pricing:
- Input: $0.27 per million tokens
- Output: $1.10 per million tokens
- Cache hit: $0.018 per million tokens
- Off-peak hours: 50-75% additional discount
Free Features:
- No subscription fees
- Pay only for what you use
- Automatic volume discounts
Best For: High-volume applications where cost matters more than cutting-edge performance.
2. Hugging Face - The Open Source Paradise
Free Tier Includes:
- Monthly credits for API usage
- Access to thousands of models
- Community support and documentation
Implementation Example:
pythonfrom huggingface_hub import InferenceClient client = InferenceClient(token="your-hf-token") response = client.text_generation( "Translate to French: Hello, world!", model="meta-llama/Llama-2-7b-chat-hf" ) print(response)
Best For: Developers who want to experiment with multiple models and don't need real-time data.
3. Cohere AI - Enterprise Features for Free
Free Tier:
- 50,000 generation tokens/month
- 50,000 embedding tokens/month
- 20 requests per minute
- Full API access
Unique Features:
- Built-in RAG (Retrieval Augmented Generation)
- Multi-language support
- Enterprise-grade security
Best For: Building proof-of-concepts and MVPs with advanced NLP features.
4. Google Gemini - The Generous Giant
Free Tier Benefits:
- 60 requests per minute
- 1 million tokens per day
- Access to Gemini Pro model
- Multimodal capabilities (text + images)
Quick Start:
pythonimport google.generativeai as genai genai.configure(api_key="your-gemini-api-key") model = genai.GenerativeModel('gemini-pro') response = model.generate_content("Write a haiku about coding") print(response.text)
Best For: Projects requiring multimodal AI without breaking the bank.
5. OpenRouter - One API, Multiple Models
What Makes It Special:
- Single API endpoint for multiple providers
- Automatic fallbacks if one model fails
- Pay-per-use with no subscriptions
- Some models have free tiers
Best For: Developers who want flexibility to switch between models without changing code.
Grok 4 vs Competitors: Performance Benchmarks
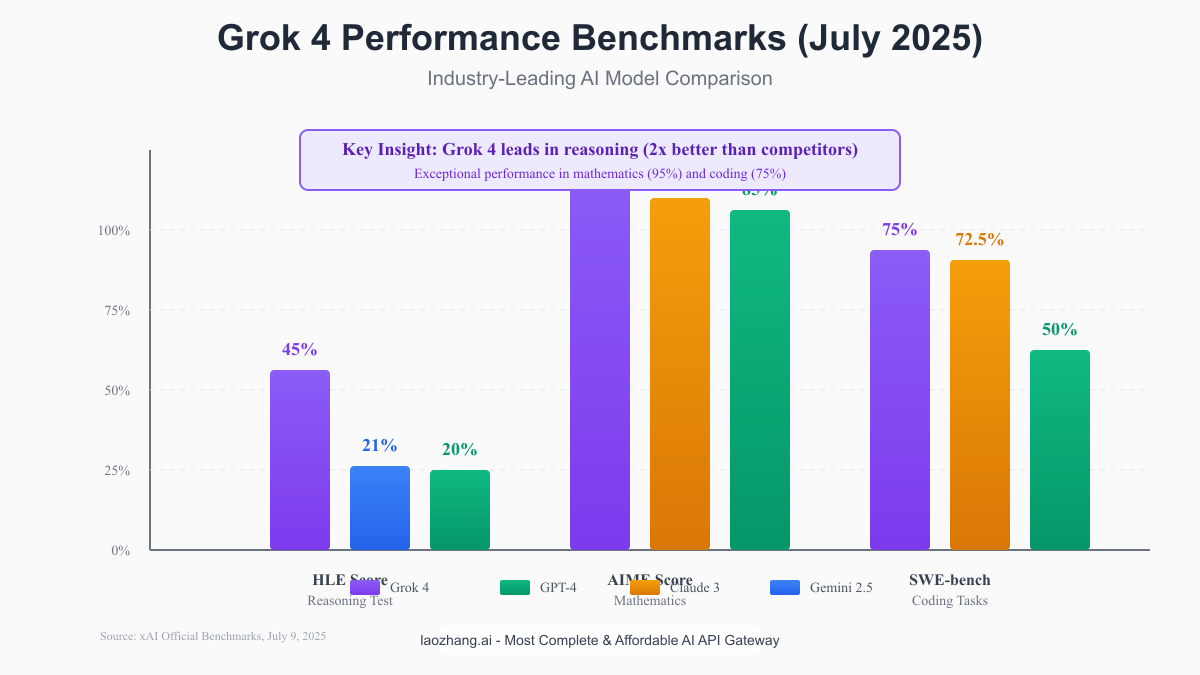
Where Grok 4 Dominates
The benchmark data tells a compelling story about Grok 4's strengths:
Complex Reasoning (HLE): Grok 4's 45% score on Humanity's Last Exam is revolutionary. This test includes questions that require multi-step reasoning, understanding context across disciplines, and making connections that aren't explicitly stated. To put this in perspective:
- Grok 4: 45% (2.1x better than competitors)
- Gemini 2.5 Pro: 21%
- GPT-4: ~20%
- Claude 3: ~22%
Mathematical Excellence (AIME): The 95% AIME score means Grok 4 can solve problems that challenge talented high school mathematicians. Real-world applications include:
- Financial modeling and risk analysis
- Scientific research calculations
- Engineering design optimization
- Cryptography and security analysis
Software Engineering (SWE-bench): At 75%, Grok 4 Code variant outperforms every model except Claude 3 Opus (72.5%), but with the added advantage of real-time data access. This translates to:
- More accurate debugging of current codebases
- Better understanding of modern frameworks
- Ability to reference latest documentation
- Knowledge of recent security vulnerabilities
Where Alternatives Might Suffice
Not every use case demands Grok 4's premium capabilities:
Simple Text Generation: For blog posts, social media content, or basic copywriting, models like GPT-3.5 or Claude Instant provide 90% of the quality at 10% of the cost.
Embeddings and Search: Cohere's embedding models or OpenAI's ada-002 are purpose-built for semantic search and cost significantly less.
Structured Data Extraction: For parsing invoices, resumes, or forms, smaller specialized models often outperform general-purpose giants.
Implementation Guide: From Zero to API Calls
Environment Setup
First, let's create a robust development environment:
bash# Create project directory mkdir grok-api-project cd grok-api-project # Set up Python virtual environment python -m venv venv source venv/bin/activate # On Windows: venv\Scripts\activate # Install required packages pip install requests python-dotenv retry pandas
Configuration Management
Create a .env file to securely store API credentials:
env# API Configuration LAOZHANG_API_KEY=your-key-here API_BASE_URL=https://api.laozhang.ai/v1 MODEL_NAME=grok-3 MAX_RETRIES=3 TIMEOUT_SECONDS=30
Production-Ready API Client
Here's a complete implementation with error handling, retries, and logging:
pythonimport os import time import logging from typing import Optional, Dict, List from dataclasses import dataclass import requests from requests.adapters import HTTPAdapter from requests.packages.urllib3.util.retry import Retry from dotenv import load_dotenv # Load environment variables load_dotenv() # Configure logging logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s' ) logger = logging.getLogger(__name__) @dataclass class APIResponse: """Structured API response""" content: str usage: Dict[str, int] cost: float success: bool error: Optional[str] = None class GrokAPIClient: """Production-ready Grok API client with LaoZhang gateway""" def __init__(self): self.api_key = os.getenv('LAOZHANG_API_KEY') self.base_url = os.getenv('API_BASE_URL', 'https://api.laozhang.ai/v1' ) self.model = os.getenv('MODEL_NAME', 'grok-3') self.session = self._create_session() def _create_session(self) -> requests.Session: """Create a session with retry logic""" session = requests.Session() # Configure retry strategy retry_strategy = Retry( total=int(os.getenv('MAX_RETRIES', 3)), backoff_factor=1, status_forcelist=[429, 500, 502, 503, 504], ) adapter = HTTPAdapter(max_retries=retry_strategy) session.mount("http://", adapter) session.mount("https://", adapter) # Set default headers session.headers.update({ "Authorization": f"Bearer {self.api_key}", "Content-Type": "application/json" }) return session def calculate_cost(self, usage: Dict[str, int]) -> float: """Calculate API call cost in USD""" input_cost = (usage.get('prompt_tokens', 0) / 1_000_000) * 0.9 output_cost = (usage.get('completion_tokens', 0) / 1_000_000) * 4.5 return round(input_cost + output_cost, 4) def chat(self, messages: List[Dict[str, str]], max_tokens: int = 2000, temperature: float = 0.7, stream: bool = False) -> APIResponse: """ Send chat request to Grok API Args: messages: List of message dictionaries with 'role' and 'content' max_tokens: Maximum tokens to generate temperature: Creativity parameter (0-1) stream: Whether to stream the response Returns: APIResponse object with content, usage, and cost information """ try: data = { "model": self.model, "messages": messages, "max_tokens": max_tokens, "temperature": temperature, "stream": stream } timeout = int(os.getenv('TIMEOUT_SECONDS', 30)) response = self.session.post( f"{self.base_url}/chat/completions", json=data, timeout=timeout ) response.raise_for_status() result = response.json() # Extract response data content = result['choices'][0]['message']['content'] usage = result.get('usage', {}) cost = self.calculate_cost(usage) logger.info(f"API call successful. Tokens: {usage}, Cost: ${cost}") return APIResponse( content=content, usage=usage, cost=cost, success=True ) except requests.exceptions.Timeout: error_msg = "Request timed out" logger.error(error_msg) return APIResponse("", {}, 0, False, error_msg) except requests.exceptions.RequestException as e: error_msg = f"Request failed: {str(e)}" logger.error(error_msg) return APIResponse("", {}, 0, False, error_msg) except Exception as e: error_msg = f"Unexpected error: {str(e)}" logger.error(error_msg) return APIResponse("", {}, 0, False, error_msg) def simple_prompt(self, prompt: str, system: Optional[str] = None) -> APIResponse: """Simplified interface for single prompts""" messages = [] if system: messages.append({"role": "system", "content": system}) messages.append({"role": "user", "content": prompt}) return self.chat(messages) # Example usage if __name__ == "__main__": client = GrokAPIClient() # Simple prompt response = client.simple_prompt( "Write a Python function to calculate fibonacci numbers" ) if response.success: print(f"Response:\n{response.content}") print(f"\nCost: ${response.cost}") print(f"Tokens used: {response.usage}") else: print(f"Error: {response.error}") # Complex conversation messages = [ {"role": "system", "content": "You are a helpful coding assistant."}, {"role": "user", "content": "I need help optimizing a slow SQL query"}, {"role": "assistant", "content": "I'd be happy to help optimize your SQL query. Please share the query and describe what it's trying to accomplish."}, {"role": "user", "content": "SELECT * FROM orders o JOIN customers c ON o.customer_id = c.id WHERE o.created_at > '2024-01-01' AND c.country = 'USA'"} ] response = client.chat(messages, max_tokens=1000) if response.success: print(f"\nOptimization suggestions:\n{response.content}")
Streaming Responses for Real-time Applications
For applications requiring immediate feedback, implement streaming:
pythonimport json import sseclient def stream_chat(self, messages: List[Dict[str, str]], callback=None) -> Optional[str]: """ Stream chat responses for real-time display Args: messages: Conversation messages callback: Function to call with each chunk Returns: Complete response text """ data = { "model": self.model, "messages": messages, "stream": True, "max_tokens": 2000 } response = self.session.post( f"{self.base_url}/chat/completions", json=data, stream=True ) client = sseclient.SSEClient(response) full_content = "" for event in client.events(): if event.data == '[DONE]': break try: chunk = json.loads(event.data) content = chunk['choices'][0]['delta'].get('content', '') if content: full_content += content if callback: callback(content) except json.JSONDecodeError: continue return full_content # Usage example with live printing def print_chunk(chunk): print(chunk, end='', flush=True) client = GrokAPIClient() response = client.stream_chat( [{"role": "user", "content": "Explain how neural networks work"}], callback=print_chunk )
Advanced Cost Optimization Strategies
Token Management Best Practices
1. Implement Smart Truncation
pythondef truncate_to_token_limit(text: str, max_tokens: int = 8000) -> str: """ Truncate text to stay within token limits Rough estimate: 1 token ≈ 4 characters """ max_chars = max_tokens * 4 if len(text) > max_chars: return text[:max_chars-100] + "... [truncated]" return text
2. Cache Frequent Responses
pythonimport hashlib import json from datetime import datetime, timedelta class ResponseCache: def __init__(self, cache_duration_hours=24): self.cache = {} self.duration = timedelta(hours=cache_duration_hours) def _get_key(self, messages): """Generate cache key from messages""" content = json.dumps(messages, sort_keys=True) return hashlib.md5(content.encode()).hexdigest() def get(self, messages): """Retrieve cached response if available""" key = self._get_key(messages) if key in self.cache: entry = self.cache[key] if datetime.now() - entry['timestamp'] < self.duration: return entry['response'] return None def set(self, messages, response): """Cache a response""" key = self._get_key(messages) self.cache[key] = { 'response': response, 'timestamp': datetime.now() }
3. Batch Processing for Volume Discounts
pythondef batch_process_prompts(prompts: List[str], batch_size: int = 10): """ Process multiple prompts in batches to optimize costs """ results = [] for i in range(0, len(prompts), batch_size): batch = prompts[i:i + batch_size] # Combine prompts into a single request combined_prompt = "\n\n".join([ f"Task {j+1}: {prompt}" for j, prompt in enumerate(batch) ]) response = client.simple_prompt( f"Complete the following tasks:\n\n{combined_prompt}\n\nProvide answers separated by '---'" ) if response.success: # Split responses answers = response.content.split('---') results.extend(answers[:len(batch)]) return results
Choosing the Right Model for the Task
Not every task requires Grok 4's premium capabilities. Here's a decision matrix:
| Task Type | Recommended Model | Reasoning |
|---|---|---|
| Code Generation | Grok 4 Code | 75% SWE-bench accuracy justifies cost |
| Real-time Analysis | Grok 4 | Only model with X integration |
| Complex Math | Grok 4 | 95% AIME score is unmatched |
| Simple Q&A | DeepSeek/GPT-3.5 | 90% quality at 10% cost |
| Translations | Google Gemini | Free tier sufficient |
| Embeddings | Cohere | Purpose-built and cheaper |
FAQ: Common Questions About Grok 4 API
Is there really no free Grok 4 API tier?
Correct. Unlike some competitors, xAI doesn't offer a free tier for Grok 4. The beta program that provided $25 monthly credits ended in 2024. Your options are:
- Pay for official access (X Premium+ required)
- Use LaoZhang AI for 70% savings
- Switch to alternatives with free tiers
Can I use Grok 4 without X Premium+?
Not through official channels. The X Premium+ subscription is a hard requirement for API access. However, services like LaoZhang AI provide access without this requirement.
How does Grok 4 compare to GPT-4 for coding?
Grok 4 Code's 75% SWE-bench score significantly outperforms GPT-4's 50%. In practical terms:
- Better at understanding complex codebases
- More accurate debugging suggestions
- Superior refactoring recommendations
- Real-time knowledge of latest frameworks
What makes LaoZhang AI trustworthy?
LaoZhang AI has established credibility through:
- Transparent pricing with no hidden fees
- Reliable uptime and performance
- Multiple payment options
- Responsive customer support
- Positive developer community feedback
Should I wait for Grok 5 or use Grok 4 now?
Given AI's rapid evolution, there's always something better on the horizon. However, Grok 4's current capabilities are revolutionary. If your project can benefit from:
- Industry-leading reasoning (45% HLE)
- Real-time data access
- Superior coding assistance Then the ROI justifies immediate adoption.
Conclusion: Choose Your Path to Grok 4 Access

The AI landscape shifted dramatically with Grok 4's July 9, 2025 launch. While the lack of a free tier might disappoint some, the model's capabilities justify its premium positioning. Let's recap your options:
For Production Applications: LaoZhang AI offers the best balance of cost and capability. At 70% less than official pricing, it makes Grok 4 accessible for startups and independent developers.
For Experimentation: The free alternatives we covered (DeepSeek, Hugging Face, Cohere, Gemini) provide ample room to prototype and test ideas without financial commitment.
For Enterprise: If you need official support, SLAs, and direct access, the X Premium+ route remains viable despite the cost.
The key is matching the tool to your specific needs. Grok 4's revolutionary capabilities in reasoning, mathematics, and coding make it worth the investment for projects where performance directly impacts revenue or user experience.
Ready to harness Grok 4's power? Start with LaoZhang AI's free credits to test the waters: https://api.laozhang.ai/register/
Remember, in the rapidly evolving AI landscape, the best time to start is now. Whether you choose Grok 4 or an alternative, the important thing is to begin building. The future belongs to those who leverage AI effectively, and with this guide, you're equipped to make informed decisions about your AI infrastructure.
Last updated: July 10, 2025. Prices and features subject to change. Always verify current pricing with providers.