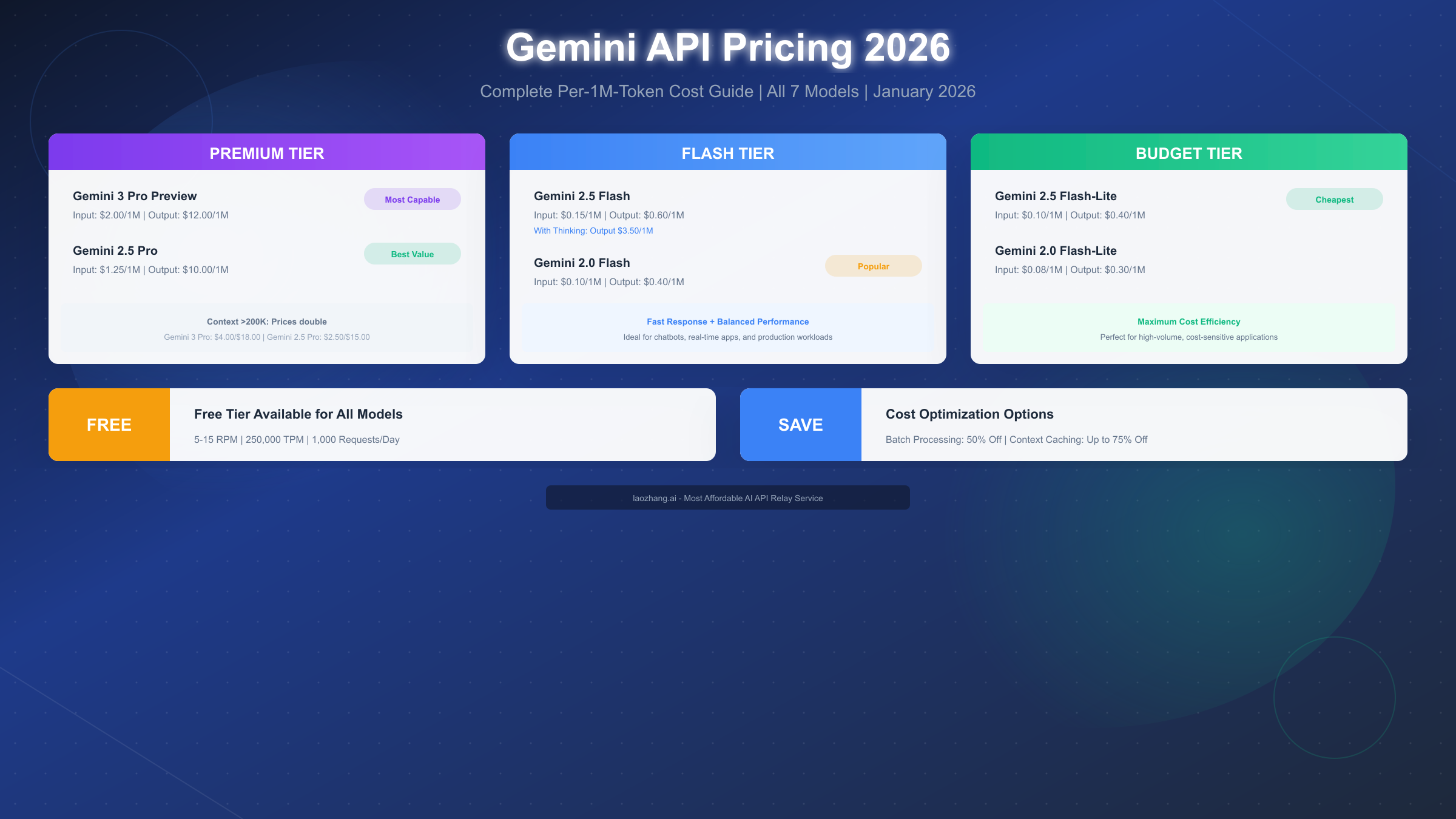
Google's Gemini API pricing in January 2026 ranges from $0.10 to $4.00 per million input tokens and $0.40 to $18.00 per million output tokens, depending on the model and context length. The most affordable option is Gemini 2.5 Flash-Lite at $0.10/$0.40 per 1M tokens, while the flagship Gemini 3 Pro Preview costs $2.00/$12.00 per 1M tokens for standard context (up to 200K). All models include a generous free tier with up to 1,000 daily requests. This comprehensive guide covers complete pricing for all 7 Gemini models, competitor comparisons with OpenAI and Claude, and proven cost optimization strategies that can save you up to 75%.
Understanding Gemini API Pricing in 2026
Google's Gemini API uses a token-based pricing model that charges separately for input tokens (what you send to the model) and output tokens (what the model generates). This fundamental pricing structure determines your actual costs, and understanding it properly can save you significant money on your AI applications.
What Are Tokens and Why Do They Matter?
Tokens are the basic units that language models process. In English, one token roughly equals 4 characters or about 0.75 words. For other languages like Chinese or Japanese, the ratio differs significantly. When you send a prompt to Gemini and receive a response, you're charged for both the tokens in your prompt (input) and the tokens in the response (output).
The critical distinction between input and output pricing exists because generating new content (output) requires more computational resources than processing existing text (input). Across all Gemini models, output tokens cost 3-4x more than input tokens, making it essential to optimize your prompts for concise responses when cost is a concern.
Context Length Pricing Tiers
One aspect that catches many developers off guard is Google's context length pricing tiers. For most Gemini models, prices remain standard for contexts up to 200,000 tokens. However, when your context exceeds 200K tokens, prices typically double. This tier structure applies to both Gemini 2.5 Pro and Gemini 3 Pro Preview.
For example, Gemini 2.5 Pro charges $1.25 per million input tokens for contexts under 200K, but this jumps to $2.50 per million for longer contexts. If you're processing lengthy documents or maintaining extended conversation histories, factor this pricing tier into your cost calculations.
January 2026 Pricing Updates
Google has continued to make Gemini pricing more competitive throughout late 2025 and into 2026. The introduction of Gemini 3 Pro Preview brought new capabilities at premium pricing, while existing models like Gemini 2.0 Flash have become even more affordable. The free tier has expanded to cover all production models, making it easier than ever to prototype and test before committing to paid usage.
Multimodal Pricing Considerations
Gemini's native multimodal capabilities introduce additional pricing considerations beyond pure text. When processing images, each image contributes approximately 258 tokens to your input count regardless of the image's pixel dimensions, though higher resolution images may tokenize slightly higher. Video processing follows similar patterns, with each frame contributing to the token count.
Audio content processes at video-equivalent rates, making voice-to-text and audio analysis workloads comparable in cost to video processing. For applications combining multiple modalities, calculate your expected token usage across all input types to accurately project costs.
The multimodal pricing structure actually works in developers' favor compared to using separate APIs for vision, audio, and text. Rather than paying separate services for OCR, image captioning, and text generation, a single Gemini request handles the complete workflow at competitive token-based pricing.
Understanding Gemini's Pricing Philosophy
Google's pricing strategy with Gemini reflects their competitive position in the AI market. By offering aggressive pricing at the budget and mid-tier levels while maintaining premium pricing for flagship models, they've created an attractive on-ramp for developers who might otherwise default to OpenAI or Anthropic.
The tiered context pricing above 200K tokens ensures that extreme use cases pay proportionally for the additional computational resources required, while keeping standard use cases affordable. This approach differs from competitors who often charge flat rates regardless of context length, potentially subsidizing heavy users at the expense of typical applications.
If you're setting up Gemini for the first time, check out our Gemini API key setup guide for step-by-step instructions on getting your credentials configured properly.
Complete Pricing Breakdown by Model
Understanding the full pricing landscape across all Gemini models helps you make informed decisions about which model fits your use case and budget. Here's the complete January 2026 pricing for every production Gemini model.
| Model | Input (per 1M) | Output (per 1M) | Context Window | Best For |
|---|---|---|---|---|
| Gemini 3 Pro Preview | $2.00 | $12.00 | 2M tokens | State-of-the-art tasks |
| Gemini 3 Pro Preview (>200K) | $4.00 | $18.00 | 2M tokens | Long context premium |
| Gemini 2.5 Pro | $1.25 | $10.00 | 2M tokens | Complex reasoning |
| Gemini 2.5 Pro (>200K) | $2.50 | $15.00 | 2M tokens | Long document analysis |
| Gemini 2.5 Flash | $0.15 | $0.60 | 1M tokens | Fast, balanced tasks |
| Gemini 2.5 Flash (Thinking) | $0.15 | $3.50 | 1M tokens | Reasoning-enhanced |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | 1M tokens | Budget-conscious |
| Gemini 2.0 Flash | $0.10 | $0.40 | 1M tokens | Production workloads |
Premium Tier: Gemini 3 Pro Preview
The newest flagship model represents Google's most capable offering. At $2.00 per million input tokens and $12.00 per million output tokens, it's positioned competitively against GPT-4o and Claude 3.5 Sonnet while offering superior multimodal capabilities and the industry-leading 2 million token context window.
The "Preview" designation means pricing may adjust as the model moves to general availability. Early adopters should budget for potential changes, though historically Google has maintained or reduced prices when transitioning from preview to production.
Best Value: Gemini 2.5 Pro
For most professional applications requiring high-quality outputs, Gemini 2.5 Pro delivers exceptional value at $1.25/$10.00 per million tokens. It handles complex reasoning tasks, code generation, and content creation with results approaching the newer Gemini 3 at roughly 60% of the cost.
The 2M token context window matches the flagship model, making it ideal for processing entire codebases, lengthy legal documents, or comprehensive research papers without truncation.
Balanced Performance: Gemini 2.5 Flash
The Flash tier offers an excellent middle ground between capability and cost. Standard pricing at $0.15/$0.60 per million tokens makes it 8x cheaper than Pro for input and 16x cheaper for output. The optional "Thinking" mode at $3.50 per million output tokens adds enhanced reasoning capabilities when needed.
This model excels at real-time applications where response latency matters, including chatbots, live translation, and interactive assistants. The 1M token context window handles most practical use cases comfortably.
Budget Champions: Flash-Lite and 2.0 Flash
At $0.10/$0.40 per million tokens, both Gemini 2.5 Flash-Lite and Gemini 2.0 Flash represent Google's most cost-effective offerings. These models are perfect for high-volume applications where every token counts, including content moderation, simple classification tasks, and batch processing workflows.
The near-identical pricing between these models means your choice should depend on specific capability needs rather than cost. Flash-Lite offers the newest architecture, while 2.0 Flash provides proven production stability.
Special Features Pricing
Beyond text processing, Gemini offers additional capabilities with their own pricing structures:
- Text Embedding: $0.00004 per 1,000 characters (approximately $0.01 per million tokens equivalent)
- Grounding with Google Search: Additional per-request charges apply
- Image Processing: Included in token counts at approximately 258 tokens per image for most sizes
- Audio Processing: Charged at video rates when processing audio content
Understanding the Embedding Model Economics
Text embeddings deserve special attention for applications building semantic search, recommendation systems, or RAG pipelines. At $0.00004 per 1,000 characters, embedding costs typically represent a small fraction of overall API expenses, but they scale with your total content corpus.
For a knowledge base of 10,000 documents averaging 5,000 characters each, initial embedding costs approximately $2.00. This one-time cost amortizes well since embeddings only need regeneration when source content changes. Compare this to generation costs: querying that same knowledge base 10,000 times with Flash would cost roughly $50-100 depending on response lengths, making embeddings an extremely cost-effective investment.
Thinking Mode Pricing Analysis
Gemini 2.5 Flash's optional "Thinking" mode at $3.50 per million output tokens represents a significant premium over standard output pricing ($0.60). This 5.8x multiplier requires careful consideration of when the enhanced reasoning justifies the additional cost.
Thinking mode excels at multi-step reasoning, mathematical problem-solving, and complex analytical tasks where standard Flash might produce inconsistent results. For straightforward generation, classification, or extraction tasks, standard mode typically provides equivalent quality at dramatically lower cost.
Implement conditional thinking mode activation based on query characteristics. Route queries containing mathematical expressions, logical operators, or multi-part questions to thinking mode while keeping simple requests on standard processing. This selective approach captures thinking mode's benefits while minimizing cost impact.
Real-World Cost Examples
Understanding pricing tables is one thing; knowing what your actual monthly bill might look like is another. These practical scenarios demonstrate real costs across different application types and usage patterns.
Scenario 1: Customer Support Chatbot
A mid-sized e-commerce company runs a customer support chatbot handling 10,000 conversations daily. Each conversation averages 500 input tokens (customer questions) and 800 output tokens (bot responses).
Using Gemini 2.0 Flash at $0.10/$0.40 per million tokens:
- Daily input: 10,000 × 500 = 5M tokens → $0.50
- Daily output: 10,000 × 800 = 8M tokens → $3.20
- Monthly total: ~$111
The same workload on Gemini 2.5 Pro would cost approximately $1,850/month, making Flash the obvious choice for this use case where response quality differences are minimal.
Scenario 2: RAG-Based Document Analysis
A legal tech startup processes 500 documents daily through a Retrieval-Augmented Generation system. Each document averages 8,000 tokens of retrieved context plus 200 tokens of query, generating 1,500 token responses.
Using Gemini 2.5 Flash:
- Daily input: 500 × 8,200 = 4.1M tokens → $0.62
- Daily output: 500 × 1,500 = 750K tokens → $0.45
- Monthly total: ~$32
Scenario 3: Code Assistant for Development Team
A 20-developer team uses Gemini for code generation and review. Each developer makes approximately 50 requests daily with average 2,000 input tokens (code context) and 1,000 output tokens (generated code).
Using Gemini 2.5 Pro for higher code quality:
- Daily input: 20 × 50 × 2,000 = 2M tokens → $2.50
- Daily output: 20 × 50 × 1,000 = 1M tokens → $10.00
- Monthly total: ~$375
Scenario 4: Content Generation Pipeline
A marketing agency generates 200 blog posts daily, each requiring 500 input tokens (prompts, outlines) and producing 3,000 output tokens (article content).
Using Gemini 2.5 Pro:
- Daily input: 200 × 500 = 100K tokens → $0.13
- Daily output: 200 × 3,000 = 600K tokens → $6.00
- Monthly total: ~$184
Scenario 5: Multimodal Image Analysis
An e-commerce platform analyzes 5,000 product images daily for categorization and description generation. Each image processes as approximately 258 tokens, with 100 text tokens of instruction and 500 output tokens of description.
Using Gemini 2.0 Flash:
- Daily input: 5,000 × (258 + 100) = 1.79M tokens → $0.18
- Daily output: 5,000 × 500 = 2.5M tokens → $1.00
- Monthly total: ~$35
Scenario 6: Long Document Summarization
A research institution summarizes 50 academic papers daily, each averaging 50,000 tokens with 2,000 token summaries generated.
Using Gemini 2.5 Pro (under 200K context):
- Daily input: 50 × 50,000 = 2.5M tokens → $3.13
- Daily output: 50 × 2,000 = 100K tokens → $1.00
- Monthly total: ~$124
This scenario illustrates an important consideration: even with large documents, staying under the 200K context threshold keeps costs manageable. If documents exceeded 200K tokens, the same workload would cost approximately $187/month due to the doubled pricing tier.
Understanding Cost Drivers Across Scenarios
Analyzing these six scenarios reveals several key cost patterns that apply broadly across Gemini API applications:
Output tokens dominate costs in most use cases. Across all scenarios, output generation typically accounts for 65-85% of total costs despite output volumes being lower than input volumes. This makes output optimization the highest-leverage cost reduction strategy for most applications.
Model selection dramatically impacts economics. The chatbot scenario demonstrates how choosing Flash over Pro for appropriate use cases can reduce costs by over 90%. However, the code assistant scenario shows situations where the quality difference justifies higher-tier pricing.
Volume scales linearly but optimization compounds. Processing 10x more documents costs roughly 10x more, but implementing caching, batching, or model routing strategies can reduce the base cost by 50-75%, making the scaled cost dramatically lower than naive projections suggest.
For teams needing to control costs across multiple models and providers, services like laozhang.ai offer API relay with unified pricing and the flexibility to switch between models based on task requirements without managing multiple provider accounts. This approach simplifies cost management when your application benefits from using different models for different task types.
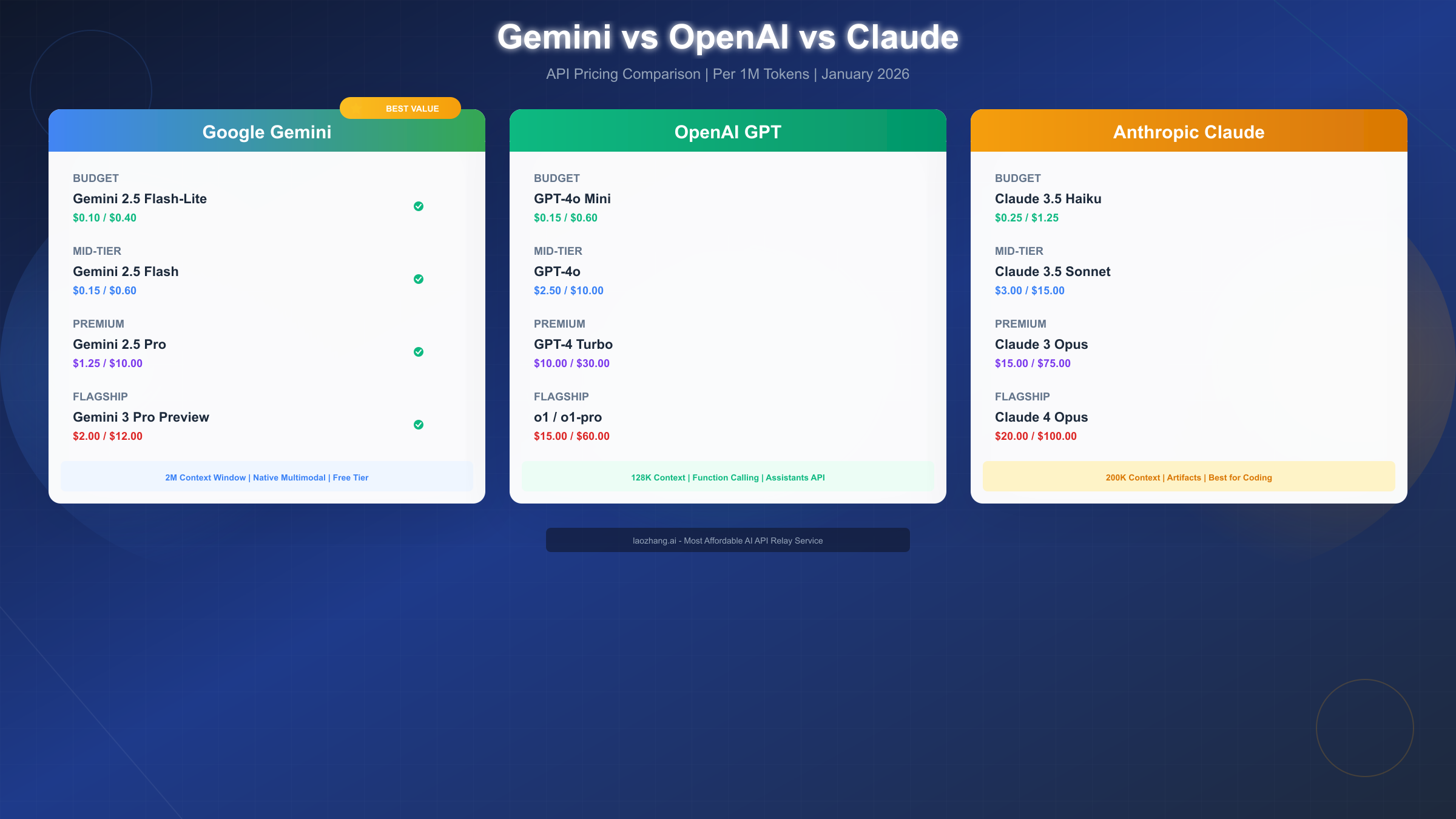
Gemini vs OpenAI vs Claude: Price Comparison
Choosing between major AI providers involves more than just comparing raw token prices. Performance characteristics, context lengths, and specialized capabilities all factor into the total cost of ownership for your applications.
| Tier | Gemini | OpenAI | Claude |
|---|---|---|---|
| Budget | Flash-Lite: $0.10/$0.40 | GPT-4o Mini: $0.15/$0.60 | Haiku 3.5: $0.25/$1.25 |
| Mid-Tier | 2.5 Flash: $0.15/$0.60 | GPT-4o: $2.50/$10.00 | Sonnet 3.5: $3.00/$15.00 |
| Premium | 2.5 Pro: $1.25/$10.00 | GPT-4 Turbo: $10.00/$30.00 | Opus 3: $15.00/$75.00 |
| Flagship | 3 Pro: $2.00/$12.00 | o1: $15.00/$60.00 | Opus 4: $20.00/$100.00 |
Budget Tier Analysis
Gemini dominates the budget tier with Flash-Lite at $0.10/$0.40 per million tokens, undercutting OpenAI's GPT-4o Mini by 33% on input and Claude's Haiku 3.5 by 60%. For cost-sensitive applications processing millions of tokens daily, this difference translates to substantial monthly savings.
For teams evaluating Claude's pricing in detail, our Claude API pricing guide provides comprehensive breakdowns and optimization strategies specific to Anthropic's models.
Mid-Tier Comparison
The mid-tier shows the most dramatic pricing disparity. Gemini 2.5 Flash at $0.15/$0.60 costs just 6% of GPT-4o's $2.50/$10.00 pricing and 5% of Claude Sonnet's $3.00/$15.00. While GPT-4o and Claude Sonnet offer somewhat higher quality for complex tasks, Flash's capabilities satisfy most production requirements at a fraction of the cost.
Premium Tier Value
Gemini 2.5 Pro at $1.25/$10.00 represents arguably the best value in the premium tier. It costs 12.5% of GPT-4 Turbo's input pricing and 8% of Claude Opus 3's pricing while delivering comparable results for most reasoning and generation tasks. The 2M token context window exceeds both competitors' offerings.
Flagship Comparison
At the flagship tier, Gemini 3 Pro Preview at $2.00/$12.00 positions below both OpenAI's o1 series ($15.00/$60.00) and Claude's Opus 4 ($20.00/$100.00). While o1 offers unique chain-of-thought reasoning capabilities, Gemini 3 Pro's pricing makes it accessible for more experimental and production use cases.
Context Window Advantage
Gemini's 2M token context window stands unmatched in the industry. OpenAI's models max out at 128K tokens, while Claude offers 200K. For applications requiring processing of entire codebases, book-length documents, or extensive conversation histories, Gemini's context window eliminates the need for complex chunking strategies that can compromise output quality.
For detailed OpenAI pricing information and comparison strategies, see our OpenAI API pricing details.
When to Choose Each Provider
- Choose Gemini for: Budget-conscious applications, multimodal tasks, long-context requirements, Google Cloud integration
- Choose OpenAI for: Established tooling ecosystems, function calling complexity, ChatGPT-compatible applications
- Choose Claude for: Code generation excellence, safety-critical applications, detailed instruction following
Total Cost of Ownership Considerations
Raw token pricing tells only part of the story. Consider these factors when evaluating total cost:
Integration effort varies significantly between providers. If your team has extensive OpenAI experience, switching to Gemini involves learning curves that translate to developer time costs. Conversely, organizations already using Google Cloud benefit from seamless Gemini integration with existing infrastructure.
Reliability and uptime affect real costs beyond pricing. An API experiencing 99.9% uptime versus 99.5% uptime represents a 5x difference in downtime-related issues. While all major providers maintain high availability, historical performance data should inform your planning.
Rate limits at different pricing tiers impact cost-effectiveness for scaling applications. Gemini's generous free tier and gradual scaling make it attractive for startups, while enterprise customers may find all providers offer comparable committed-use pricing.
Consider egress and ancillary costs. While token pricing dominates API costs, applications processing images, audio, or video may incur additional charges for data transfer or storage that differ between cloud providers.
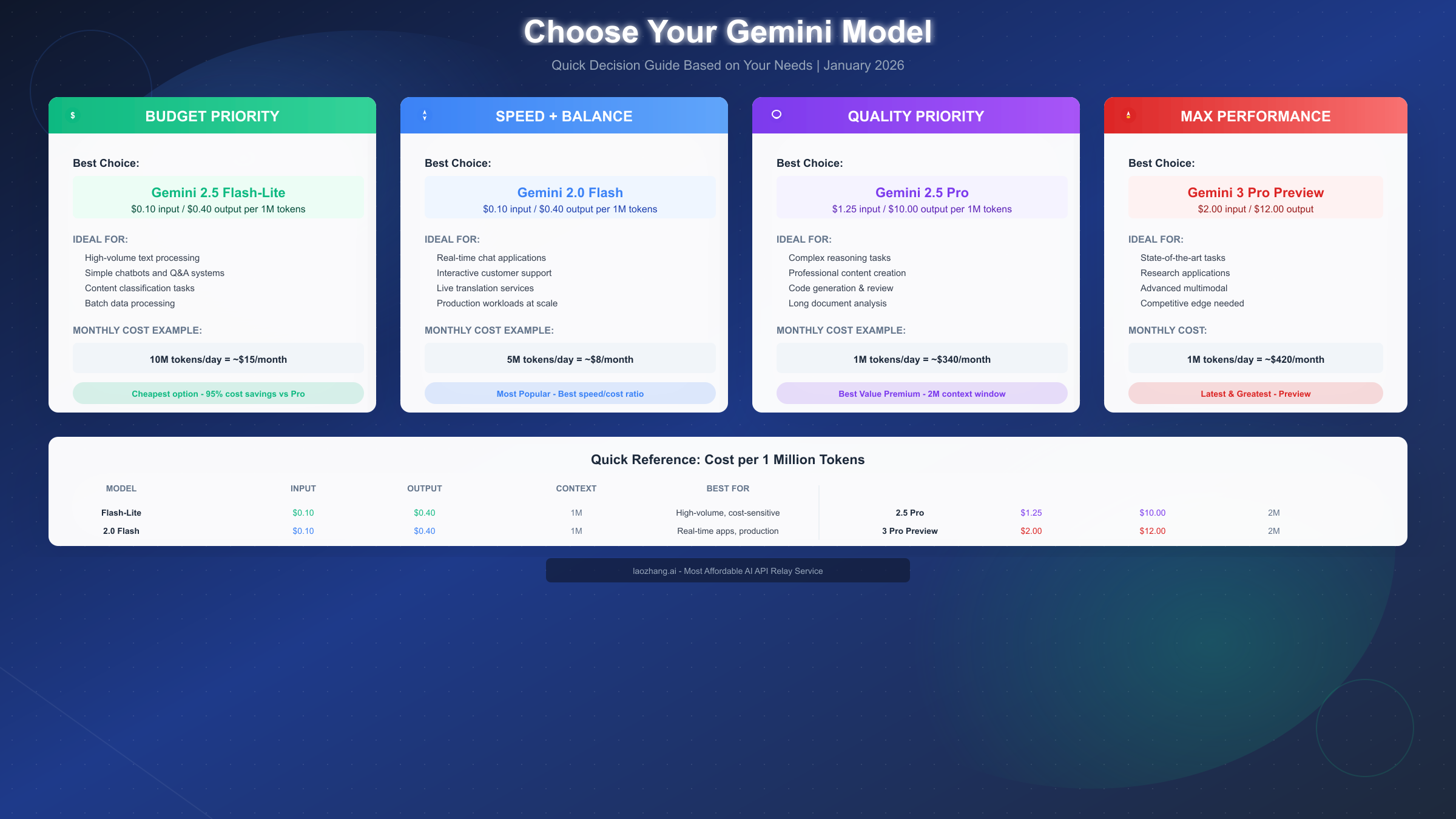
Choosing the Right Gemini Model
Selecting the optimal Gemini model requires balancing cost, capability, and latency requirements for your specific use case. This decision framework helps you navigate the choices systematically.
Decision Matrix by Priority
| Priority | Recommended Model | Monthly Budget Range |
|---|---|---|
| Minimum Cost | Flash-Lite / 2.0 Flash | $10-50 for 10M+ tokens |
| Speed + Balance | 2.0 Flash / 2.5 Flash | $20-100 for 5M+ tokens |
| Quality + Value | 2.5 Pro | $200-500 for 2M+ tokens |
| Maximum Performance | 3 Pro Preview | $400-1000 for 1M+ tokens |
Budget-First Selection
When cost is your primary constraint, start with Gemini 2.5 Flash-Lite or 2.0 Flash. Both deliver surprisingly capable results for:
- Content classification and tagging
- Simple question-answering systems
- Data extraction from structured text
- High-volume moderation tasks
- Basic summarization
Test your specific workload against both models to determine which provides acceptable quality. Many developers find Flash-Lite's newer architecture handles edge cases better, while 2.0 Flash offers more predictable behavior for established prompts.
Speed-First Selection
For applications where response latency directly impacts user experience, the Flash family excels. Gemini 2.0 Flash and 2.5 Flash both deliver sub-second response times for typical requests, making them ideal for:
- Real-time chat interfaces
- Live translation services
- Interactive coding assistants
- Voice-enabled applications
- Gaming NPCs and assistants
The Flash models process tokens 2-3x faster than Pro models while maintaining coherent outputs for straightforward tasks.
Quality-First Selection
When output quality directly impacts business value, Gemini 2.5 Pro offers the best balance of capability and cost. It excels at:
- Professional content creation
- Complex code generation and review
- Detailed analysis and recommendations
- Multi-step reasoning tasks
- Long-form writing projects
The 2M token context window handles entire documents or conversations without truncation, preserving nuance that shorter contexts might lose.
Performance-First Selection
For bleeding-edge capabilities and research applications, Gemini 3 Pro Preview provides access to Google's latest advances. Consider this model for:
- Competitive benchmarking against other flagship models
- Research and experimentation requiring maximum capability
- Applications where quality differences translate directly to revenue
- Early access to new features and capabilities
Hybrid Approach Recommendation
Most production applications benefit from a tiered model strategy:
- Routing Layer: Use Flash-Lite or 2.0 Flash for simple queries and initial classification
- Standard Processing: Route moderate complexity tasks to 2.5 Flash
- Complex Tasks: Escalate sophisticated requests to 2.5 Pro or 3 Pro Preview
This approach can reduce costs by 60-80% compared to using a single premium model for all requests while maintaining quality where it matters most.
Implementing an effective routing strategy requires a classification system that can identify query complexity with high accuracy. The good news: this classifier itself can run on Flash-Lite at minimal cost. Train it on examples of queries that require different capability levels, using features like query length, domain-specific keywords, and request type indicators.
Start with a conservative routing strategy that errs toward higher-capability models, then gradually tighten thresholds as you gather production data. Monitor user satisfaction metrics alongside cost metrics to ensure quality remains acceptable as you optimize for efficiency.
Model Transition Planning
When planning to upgrade or downgrade between models, consider these transition strategies:
Run shadow testing before fully committing to model changes. Send a sample of production traffic to both models simultaneously and compare outputs. This approach reveals quality differences in your specific use cases rather than relying on general benchmarks.
Implement gradual rollouts with feature flags. Start by routing 5% of traffic to a new model, monitor metrics, then increase incrementally. This methodology catches issues before they affect your entire user base.
Maintain fallback capabilities. If Gemini 3 Pro Preview experiences temporary issues or unexpected behavior, having the ability to quickly route traffic to 2.5 Pro provides business continuity without emergency debugging sessions.
For teams exploring cost optimization across multiple providers, API management services provide unified access with consistent pricing, allowing you to route requests to the most cost-effective model dynamically.
Free Tier Complete Guide
Gemini's free tier represents one of the most generous offerings in the AI API market, enabling developers to prototype and test extensively before committing to paid usage. Understanding its limits helps you maximize value during development.
Free Tier Limits by Model
| Model | RPM (Requests/Min) | RPD (Requests/Day) | TPM (Tokens/Min) |
|---|---|---|---|
| Gemini 3 Pro Preview | 5 | 50 | 32,000 |
| Gemini 2.5 Pro | 5 | 50 | 32,000 |
| Gemini 2.5 Flash | 10 | 500 | 100,000 |
| Gemini 2.5 Flash-Lite | 15 | 1,000 | 250,000 |
| Gemini 2.0 Flash | 15 | 1,000 | 250,000 |
What You Can Build for Free
The free tier supports surprisingly robust applications:
A personal coding assistant making 500 requests daily with Flash models provides ample coverage for individual developers. Each request can process up to 250K tokens per minute, handling substantial code reviews and generation tasks.
A prototype chatbot serving 50 users making 10 queries each per day fits comfortably within Pro model limits, letting you validate product-market fit before investing in paid capacity.
Development and testing workflows benefit enormously from free tier access. You can iterate on prompts, test edge cases, and refine system prompts without accumulating costs during the exploratory phase.
Free Tier Best Practices
Maximize your free tier usage with these strategies:
Implement request caching for identical or similar queries. If users frequently ask the same questions, cache responses to reduce API calls without impacting user experience.
Use Flash-Lite for development and testing, reserving Pro model evaluations for final quality checks. This approach lets you iterate rapidly while preserving Pro quota for meaningful comparisons.
Batch similar requests where possible. Instead of making 10 separate classification requests, combine them into a single prompt when your use case permits.
Monitor rate limits proactively. Implement exponential backoff and request queuing to gracefully handle limit exhaustion rather than failing hard.
When to Upgrade from Free Tier
Consider moving to paid usage when:
- Daily request volume consistently exceeds 500-1000 requests
- Response latency from rate limiting impacts user experience
- You need guaranteed availability for production workloads
- Token limits prevent processing larger documents
- Your application requires consistent throughput
The transition path is straightforward: simply add a billing account to your Google Cloud project. All code remains unchanged; only your limits increase.
Calculating Your Free Tier Runway
Before committing to paid usage, calculate how far the free tier can take your project. A prototype chatbot receiving 500 daily users making an average of 2 interactions each fits comfortably within Flash-Lite's 1,000 daily request limit. At this scale, you can validate your product concept, gather user feedback, and refine your prompts without incurring any API costs.
For development teams, the free tier provides substantial capacity for iterative prompt engineering. Testing 100 prompt variations daily across 5 different scenarios consumes only half of Flash's daily allocation. This allows rigorous A/B testing and optimization before production deployment.
The tokens-per-minute limits rarely constrain typical applications. Flash-Lite's 250,000 TPM handles requests up to 125,000 tokens every 30 seconds, accommodating substantial document processing even within free tier constraints.
Strategic Free Tier Usage
Maximize your free tier impact with these strategies:
Split traffic between models strategically. Use Flash-Lite's higher limits for simple requests while reserving Pro's smaller allocation for complex queries requiring superior reasoning. This tiered approach multiplies your effective free capacity.
Implement client-side caching aggressively. Identical queries returning cached responses consume no API quota. For applications with common questions or repeated analyses, caching can extend free tier viability by 2-5x.
Time non-urgent batch processing to span multiple days. If you need to process 2,000 documents and have time flexibility, spreading the workload across two days keeps you within daily limits while avoiding paid usage entirely.
For comprehensive information on free tier capabilities and limits, review our detailed Gemini 2.5 Pro free tier limits guide.
Cost Optimization Strategies
Reducing Gemini API costs without sacrificing quality requires strategic approaches across prompt engineering, model selection, and Google's built-in discount mechanisms.
Batch Processing: 50% Savings
Google offers a 50% discount on batch processing jobs that don't require real-time responses. This applies to workloads where you can accept results within 24 hours rather than immediately.
Ideal batch processing candidates include:
- Nightly content generation pipelines
- Bulk document classification
- Large-scale data extraction
- Periodic report generation
- Training data preparation
Submit batch jobs during off-peak hours for fastest turnaround while still capturing the full 50% discount.
Context Caching: Up to 75% Savings
For applications that reuse large context windows (like RAG systems with consistent knowledge bases), context caching dramatically reduces costs. Cached context tokens cost approximately 25% of standard input token pricing.
Implement context caching for:
- Customer support bots with product documentation
- Code assistants with repository context
- Research tools with consistent reference materials
- Specialized assistants with domain knowledge
The cache persists for your specified duration, eliminating redundant processing of unchanged context across requests.
Prompt Optimization Techniques
Efficient prompts reduce both input and output token consumption:
Eliminate verbose instructions. Instead of "Please provide a comprehensive, detailed response that thoroughly explains...", use "Explain briefly:". Models respond appropriately to concise guidance.
Request specific output formats. "List 5 key points" produces tighter responses than "Share your thoughts on" which may generate paragraphs of unnecessary elaboration.
Use system prompts for recurring instructions rather than repeating them in every user message. System prompts are processed once per conversation context.
Set appropriate max_tokens limits to prevent runaway responses when shorter outputs suffice.
Model Selection Optimization
Implement intelligent routing based on query complexity:
Simple queries → Flash-Lite (\$0.10/\$0.40)
Standard tasks → 2.5 Flash (\$0.15/\$0.60)
Complex tasks → 2.5 Pro (\$1.25/\$10.00)
A basic complexity classifier (which itself runs on Flash-Lite) can route requests appropriately, reducing overall costs by 40-70% compared to using Pro for everything.
Monitoring and Budget Controls
Google Cloud provides granular usage monitoring and budget alerts:
- Set daily and monthly spending caps to prevent unexpected bills
- Monitor per-model usage to identify optimization opportunities
- Track request patterns to find caching candidates
- Analyze output token distributions to tune max_tokens settings
Effective monitoring goes beyond simple spending alerts. Track your cost-per-task metrics to identify inefficiencies. If your chatbot's average response costs $0.002 but outlier conversations cost $0.05, investigate what drives those expensive sessions. Often, runaway conversations or unnecessarily long contexts create cost spikes that targeted optimization can eliminate.
Build dashboards that correlate API costs with business metrics. Understanding that each customer acquisition costs $0.50 in API usage or each document processed returns $2.00 in value transforms cost optimization from a technical exercise into a strategic business decision.
Advanced Optimization Techniques
Beyond basic strategies, sophisticated teams implement additional optimizations:
Implement semantic caching that matches similar queries to cached responses. Instead of exact string matching, use embedding similarity to serve cached responses for queries that are meaningfully equivalent. This approach can achieve 40-60% cache hit rates even for diverse user queries.
Use streaming responses for interactive applications to improve perceived performance without changing actual costs. Users experience faster time-to-first-token while your total token consumption remains unchanged.
Consider fine-tuning smaller models for specialized tasks. A fine-tuned Flash-Lite model handling your specific domain can outperform general-purpose Pro models at 10% of the cost. Google's Vertex AI provides fine-tuning capabilities for enterprise customers.
Implement progressive disclosure in conversational applications. Start with concise responses and offer to elaborate only when users request more detail. This user-driven approach naturally reduces average output length without sacrificing user satisfaction.
For teams managing costs across multiple AI providers, unified API services like laozhang.ai provide consolidated billing with bonus credits, offering approximately 84% of official rates when purchasing in bulk (for example, $100 gets you $110 in credits). This approach simplifies cost tracking while providing flexibility to route between providers based on specific task requirements.
Frequently Asked Questions
How much does Gemini API cost per request?
Cost per request varies based on your prompt and response lengths. A typical chatbot exchange with 500 input tokens and 800 output tokens costs approximately $0.00037 on Flash models or $0.0087 on Pro models. For accurate estimates, multiply your token counts by the per-million-token rates: Flash at $0.10/$0.40 and Pro at $1.25/$10.00.
Is there a free tier for Gemini API?
Yes, all Gemini models include free tier access. Flash models offer 1,000 requests per day with 250,000 tokens per minute. Pro models provide 50 requests per day with 32,000 tokens per minute. This free access is sufficient for development, testing, and low-volume production applications.
What's the cheapest Gemini model for production?
Gemini 2.5 Flash-Lite and Gemini 2.0 Flash both cost $0.10 per million input tokens and $0.40 per million output tokens, making them the most affordable options. For most text processing tasks, both deliver acceptable quality at minimal cost.
How does Gemini pricing compare to ChatGPT?
Gemini offers significant cost advantages, particularly at lower tiers. Flash-Lite costs 33% less than GPT-4o Mini, while Gemini 2.5 Pro costs 50% less than GPT-4o for comparable capabilities. Gemini's 2M token context window also exceeds ChatGPT's 128K limit.
Why does context length affect pricing?
Processing longer contexts requires more computational resources for attention mechanisms that scale quadratically with sequence length. Google's tiered pricing at 200K tokens reflects this increased processing cost. Keeping contexts under 200K maintains standard pricing.
Can I get volume discounts on Gemini API?
Google offers committed use discounts for high-volume customers through Google Cloud sales. Additionally, batch processing provides an automatic 50% discount for non-time-sensitive workloads. Context caching can reduce costs by up to 75% for applications with reusable contexts.
What's the best model for a chatbot?
For most chatbot applications, Gemini 2.0 Flash offers the optimal balance of speed, quality, and cost. Its sub-second response times ensure good user experience, while pricing at $0.10/$0.40 per million tokens keeps costs manageable even at scale. Upgrade to 2.5 Flash if you need enhanced reasoning capabilities.
How do I estimate tokens before making API calls?
Use Google's tokenizer or approximate with the rule that 1 token equals roughly 4 English characters or 0.75 words. For more accurate estimation, the Gemini API provides a countTokens endpoint that returns exact token counts before you commit to a generation request. This approach is particularly valuable for applications where token counts directly impact user-facing costs or quotas.
Does Gemini charge for failed requests?
Google does not charge for requests that fail due to errors on their end, including rate limit errors, server errors, or content policy rejections. However, you are charged for requests that complete successfully even if the output doesn't meet your expectations. This makes thorough prompt testing in the free tier essential before production deployment.
How often does Gemini pricing change?
Historically, Google has adjusted Gemini pricing 2-3 times per year, typically reducing prices as efficiencies improve. Major model releases like Gemini 3 Pro introduce new pricing tiers. Google generally provides advance notice of pricing changes, and existing committed-use agreements typically honor original pricing for their duration.
Can I use Gemini API for commercial applications?
Yes, Gemini API is fully licensed for commercial use across all pricing tiers including the free tier. There are no restrictions on monetizing applications built with Gemini, though you should review the terms of service for specific requirements around attribution and acceptable use policies.
Quick Reference Summary
| Model | Input/1M | Output/1M | Best Use Case |
|---|---|---|---|
| Flash-Lite | $0.10 | $0.40 | High-volume, simple tasks |
| 2.0 Flash | $0.10 | $0.40 | Production chatbots |
| 2.5 Flash | $0.15 | $0.60 | Balanced performance |
| 2.5 Pro | $1.25 | $10.00 | Complex reasoning |
| 3 Pro Preview | $2.00 | $12.00 | Maximum capability |
Key Takeaways
- Start with Flash models for most applications - they cost 90%+ less than Pro while handling common tasks effectively
- Leverage free tier extensively during development to validate your approach before committing to paid usage
- Use batch processing for any workload that can tolerate 24-hour latency to capture 50% savings automatically
- Implement context caching for RAG systems and applications with consistent reference materials
- Consider context length when designing prompts - staying under 200K tokens maintains standard pricing
- Compare total cost rather than per-token rates when evaluating providers, as context windows and capabilities differ significantly
Next Steps for Implementation
With a solid understanding of Gemini API pricing, the path forward depends on your current stage:
For those just starting out, begin with the free tier to validate your use case. Create a Google Cloud project, enable the Gemini API, and experiment with different models using the AI Studio playground. This hands-on exploration builds intuition for how different models handle your specific requirements before you write any code.
For teams migrating from other providers, start with a side-by-side comparison using identical prompts. Document quality differences, response times, and edge case handling. Many teams discover that Gemini's budget models handle their workloads adequately, enabling significant cost reductions without quality compromises.
For production applications seeking optimization, instrument your API calls to collect detailed usage metrics. Identify your highest-cost operations and evaluate whether model routing, caching, or batching could reduce expenses. Often, the 80/20 rule applies: a small percentage of request types drive the majority of costs.
For enterprise deployments, engage with Google Cloud sales to discuss committed use discounts, dedicated capacity, and SLA guarantees. Large-scale deployments often qualify for pricing structures unavailable through standard self-service channels.
The AI landscape continues evolving rapidly, with new models and pricing updates arriving regularly. Bookmark the official pricing page and monitor announcements for opportunities to optimize your implementation as new options become available.
For API integration documentation and getting started guides, visit the official resources at https://ai.google.dev/gemini-api/docs/pricing or explore unified API options at https://docs.laozhang.ai/ for multi-provider access with consistent pricing structures.