
50% off with batch mode—Google's July 2025 pricing update fundamentally reshapes the economics of AI development. Yet most developers still pay full price, unaware that a simple API parameter change could slash their monthly bills from $3,750 to $1,875. This pricing blind spot costs the average startup $22,500 annually in unnecessary API expenses.
The complexity of Gemini's pricing structure extends far beyond simple per-token calculations. With five different model tiers, context-dependent pricing jumps, multimodal token consumption, and the newly introduced batch processing discounts, calculating actual costs requires sophisticated analysis. Add the hidden expenses of bandwidth, logging, and failed requests, and your projected budget can balloon by 40% without warning.
This comprehensive guide transforms Gemini API pricing from an opaque cost center into a strategic advantage. Whether you're evaluating AI providers for the first time or optimizing existing implementations, understanding these pricing nuances determines whether your AI initiatives thrive or drain your budget into bankruptcy.
Decoding the Token Economy: Gemini's Pricing Foundation
Understanding Gemini's token system forms the cornerstone of accurate cost projection. Unlike traditional API pricing based on requests or compute time, Gemini charges by tokens—fragments of text that represent the fundamental units of language processing. In Google's implementation, 1,000 tokens approximately equal 750 words, though this ratio varies with language complexity, technical content, and special characters.
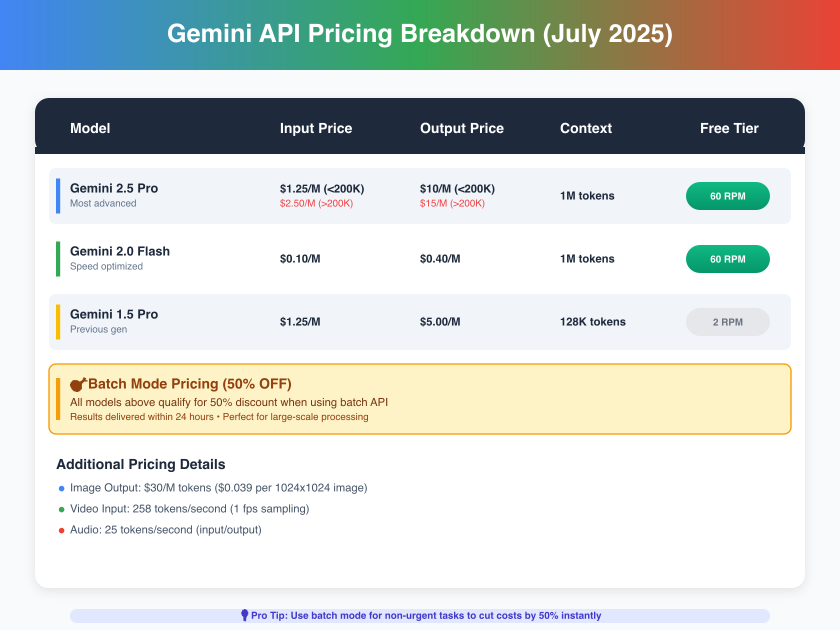
The distinction between input and output tokens creates the first layer of pricing complexity. Input tokens—your prompts, context, and instructions—cost significantly less than output tokens generated by the model. This 8-10x price differential means a poorly structured prompt that generates verbose responses can cost dramatically more than a well-crafted prompt producing concise output. For Gemini 2.5 Pro, input tokens range from $1.25 to $2.50 per million, while output tokens command $10 to $15 per million.
Token calculation extends beyond visible text. System prompts, conversation history, and even whitespace consume tokens. JSON formatting, code snippets, and structured data often require 20-30% more tokens than plain text equivalents. This hidden token inflation catches many developers off-guard when actual bills exceed projections based on word count alone.
July 2025 Pricing Revolution: Batch Mode Changes Everything
Google's July 7, 2025 introduction of batch mode represents the most significant pricing innovation since Gemini's launch. This asynchronous processing option delivers a flat 50% discount across all token types and models, fundamentally altering the economics for non-real-time applications. The catch? Results arrive within 24 hours rather than seconds.
The batch mode pricing structure maintains simplicity while delivering substantial savings:
Gemini 2.5 Pro (Batch Mode)
- Input: $0.625/M tokens (≤200K), $1.25/M tokens (>200K)
- Output: $5.00/M tokens (≤200K), $7.50/M tokens (>200K)
Gemini 2.0 Flash (Batch Mode)
- Input: $0.05/M tokens
- Output: $0.20/M tokens
This pricing model particularly benefits data processing pipelines, content generation workflows, and analytical tasks where immediate responses aren't critical. A typical content generation workload processing 10 million input tokens and generating 5 million output tokens monthly would cost $62.50 input + $25.00 output = $87.50 in batch mode, versus $175 in standard mode—a monthly saving of $87.50 that scales linearly with usage.
The implementation requires minimal code changes. Simply add the batch_mode: true parameter to your API calls and implement asynchronous result polling. Google provides dedicated batch endpoints with separate rate limits, meaning batch processing won't impact your real-time request quotas.
Model Tier Breakdown: Choosing the Right Tool for the Task
Gemini's model portfolio spans five distinct tiers, each optimized for specific use cases and budgets:
Gemini 2.5 Pro - The Flagship
The pinnacle of Google's AI capabilities, supporting 1 million token context windows. Standard pricing starts at $1.25/M input tokens but doubles to $2.50/M when exceeding 200K tokens per request. This context-based pricing jump—unique among major AI providers—can unexpectedly double costs for document processing applications.
Optimal use cases:
- Complex reasoning requiring extensive context
- Multi-document analysis and synthesis
- Code generation with large codebases
- Creative writing with character consistency
Gemini 2.0 Flash - The Speedster
Engineered for rapid responses at 250+ tokens per second, Flash trades some reasoning capability for 10x lower costs. At $0.10/M input and $0.40/M output tokens, it delivers exceptional value for straightforward tasks.
Optimal use cases:
- Customer service chatbots
- Real-time content moderation
- Simple data extraction
- High-volume classification tasks
Gemini 1.5 Series - The Workhorses
Previous generation models remain available with competitive pricing. The 1.5 Pro at $1.25/M input and $5.00/M output tokens offers a middle ground between capability and cost, though with a reduced 128K token context limit.
Optimal use cases:
- Standard business applications
- Content summarization
- Language translation
- Structured data generation
Multimodal Pricing Considerations
Image and video processing introduce additional complexity:
- Image output: $30/M tokens ($0.039 per 1024x1024 image)
- Video input: 258 tokens/second at 1fps sampling
- Audio: 25 tokens/second for input/output
A 60-second video analysis consumes 15,480 tokens, costing $0.019 with Flash or $0.039 with Pro models. These multimodal capabilities, while powerful, can rapidly escalate costs without careful management.
The Competition Landscape: Gemini vs Claude vs GPT-4
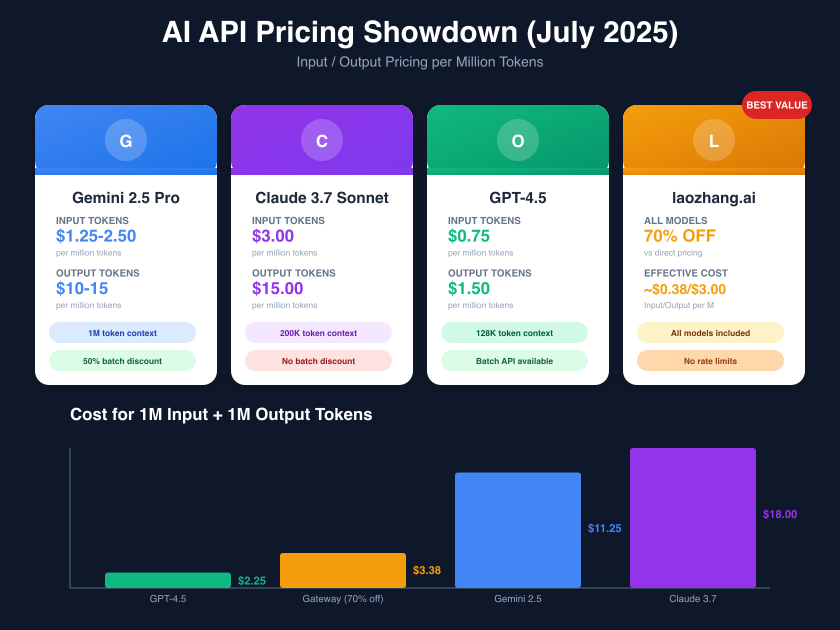
Gemini's pricing strategy positions it strategically between OpenAI's affordability and Anthropic's premium positioning. The July 2025 market dynamics reveal fascinating patterns:
Claude 3.7 Sonnet - The Premium Choice
At $3.00/M input and $15.00/M output tokens, Claude commands a 140% premium over Gemini 2.5 Pro's base pricing. However, Claude's superior performance in creative writing and complex reasoning tasks justifies the premium for specific use cases. The lack of batch processing discounts makes Claude particularly expensive for high-volume applications.
GPT-4.5 - The Value Leader
OpenAI's aggressive pricing at $0.75/M input and $1.50/M output tokens undercuts Gemini by 40% on base rates. GPT-4.5's 128K context window matches practical requirements for most applications while delivering comparable performance. The ecosystem advantage and extensive tooling support further enhance GPT-4.5's value proposition.
Market Share Implications
Recent data shows enterprises migrating from OpenAI (50% → 34% market share) to Anthropic (12% → 24%) and Google (15% → 22%). This shift reflects not just pricing but also concerns about model capability, safety features, and vendor lock-in. Gemini's batch mode pricing directly targets price-sensitive segments while maintaining premium positioning for real-time applications.
Real-World Cost Comparison
Consider a typical AI application processing 100M tokens monthly (70M input, 30M output):
Direct API Costs:
- Gemini 2.5 Pro: $87.50 + $300 = $387.50
- Gemini (Batch): $43.75 + $150 = $193.75
- Claude 3.7: $210 + $450 = $660
- GPT-4.5: $52.50 + $45 = $97.50
While GPT-4.5 appears cheapest, Gemini's batch mode delivers 50% savings for asynchronous workloads while maintaining access to superior 1M token context windows.
The True Cost Calculator: Beyond Sticker Prices
Calculating actual Gemini API costs requires accounting for multiple hidden factors that can inflate bills by 40-60% beyond base token prices:
Hidden Cost Factor #1: Retry Overhead
Failed requests due to rate limits, timeouts, or errors still consume quota allocations. With Gemini's 60 RPM free tier limit, applications frequently hit rate limits, triggering retries that double or triple token consumption. Implement exponential backoff with a maximum of 3 retries to limit this overhead to 20-30%.
Hidden Cost Factor #2: Context Accumulation
Conversation applications maintaining chat history face exponential token growth. A 10-turn conversation with 500 tokens per exchange accumulates 5,000 context tokens by the final turn. Without careful context management, costs can increase 10x over single-turn interactions.
Hidden Cost Factor #3: Prompt Template Inflation
System prompts, formatting instructions, and response templates consume tokens on every request. A typical 500-token system prompt adds $0.625 per 1,000 requests with Gemini 2.5 Pro. Across millions of requests, template optimization can save thousands monthly.
Real-World Cost Calculation Example
Scenario: Customer service chatbot handling 10,000 daily conversations
- Average conversation: 5 turns
- Tokens per turn: 200 input, 150 output
- System prompt: 500 tokens
- Daily token consumption:
- Input: 10,000 × 5 × (200 + 500) = 35M tokens
- Output: 10,000 × 5 × 150 = 7.5M tokens
- Monthly costs (30 days):
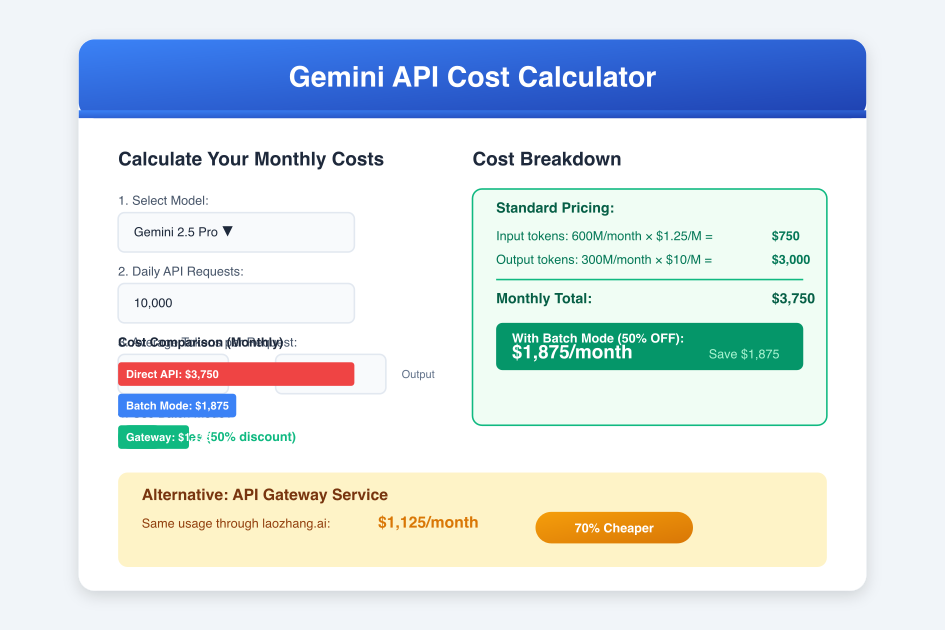
- Standard: 1,050M × $1.25 + 225M × $10 = $3,562.50
- Batch mode: $1,781.25 (50% savings)
- With retry overhead (+30%): $4,631.25 standard, $2,315.63 batch
Cost Optimization Checklist
- Implement request batching - Combine multiple operations into single API calls
- Cache frequent responses - Reduce redundant API calls by 60-80%
- Optimize prompts - Remove unnecessary instructions and formatting
- Manage context windows - Implement sliding window or summary approaches
- Use appropriate models - Don't use Pro for simple classification tasks
Advanced Optimization Strategies That Actually Work
Strategy 1: Context Caching (90% Cost Reduction)
Gemini's context caching feature, often overlooked, provides dramatic cost reductions for repetitive tasks. Upload reference documents, knowledge bases, or common contexts once, then reference them across thousands of requests:
python# Upload context once cache_response = gemini.create_context_cache({ "contents": [knowledge_base_content], "ttl": "24h" }) cache_id = cache_response.cache_id # Reference in requests (90% cheaper) response = gemini.generate_content({ "model": "gemini-2.5-pro", "cached_context": cache_id, "prompt": user_query })
This approach particularly benefits:
- RAG (Retrieval Augmented Generation) applications
- Document Q&A systems
- Consistent persona chatbots
- Technical support with documentation
Strategy 2: Dynamic Model Selection
Implement intelligent routing that selects models based on query complexity:
pythondef select_model(query_complexity): if query_complexity < 0.3: return "gemini-2.0-flash" # \$0.10/M input elif query_complexity < 0.7: return "gemini-1.5-pro" # \$1.25/M input else: return "gemini-2.5-pro" # \$1.25-2.50/M input # Complexity scoring based on: # - Query length # - Technical terminology density # - Required context size # - Expected output length
Strategy 3: Batch Aggregation Patterns
Maximize batch mode savings by aggregating requests intelligently:
pythonclass BatchAggregator: def __init__(self, batch_size=100, max_wait_time=3600): self.pending_requests = [] self.batch_size = batch_size self.max_wait_time = max_wait_time def add_request(self, request, callback): self.pending_requests.append({ 'request': request, 'callback': callback, 'timestamp': time.time() }) if len(self.pending_requests) >= self.batch_size: self.process_batch() def process_batch(self): batch = self.pending_requests[:self.batch_size] self.pending_requests = self.pending_requests[self.batch_size:] # Submit batch request (50% discount) results = gemini.batch_generate( [r['request'] for r in batch] ) # Trigger callbacks for request, result in zip(batch, results): request['callback'](result)
The Cost Trap Warning System
Trap #1: The 200K Token Cliff
Gemini's unique pricing structure doubles costs when requests exceed 200K tokens. A document analysis task consuming 201K tokens costs twice as much as one using 199K tokens. Implement hard limits and document splitting to avoid this cliff:
javascriptfunction splitLargeDocument(document, maxTokens = 190000) { const chunks = []; let currentChunk = ""; let currentTokens = 0; for (const paragraph of document.paragraphs) { const paragraphTokens = estimateTokens(paragraph); if (currentTokens + paragraphTokens > maxTokens) { chunks.push(currentChunk); currentChunk = paragraph; currentTokens = paragraphTokens; } else { currentChunk += "\n" + paragraph; currentTokens += paragraphTokens; } } if (currentChunk) chunks.push(currentChunk); return chunks; }
Trap #2: Multimodal Token Explosion
Video and image processing can consume tokens at alarming rates. A 5-minute video at 1fps sampling consumes 77,400 tokens—costing $0.97 with Pro or $0.39 with Flash per video. For video-heavy applications, consider:
- Reducing sampling rate to 0.5fps (50% cost reduction)
- Pre-processing to extract key frames
- Using Flash for initial screening, Pro for detailed analysis
Trap #3: Free Tier Transition Shock
The jump from free tier (60 RPM, 300K tokens/day) to paid usage often catches developers unprepared. Applications designed around free tier limits may require architectural changes to remain cost-effective at scale. Plan for this transition by implementing rate limiting and caching from day one.
The Alternative Path: Gateway Services Decoded
While direct API access provides maximum control, gateway services offer compelling economics for many use cases. Services like laozhang.ai aggregate demand across thousands of users, achieving volume discounts impossible for individual developers. The math is straightforward: 70% cost reduction with additional benefits.
Gateway Service Economics
Gateway providers negotiate enterprise rates with Google, often securing 80-90% discounts through committed volume purchases. After operating costs and margins, they pass 70% savings to end users. For a typical $3,750 monthly Gemini bill, gateway services reduce costs to $1,125—a $2,625 monthly saving.
Implementation Comparison
python# Traditional Gemini API import google.generativeai as genai genai.configure(api_key="your-key") model = genai.GenerativeModel('gemini-2.5-pro') response = model.generate_content("Your prompt") # Cost: \$0.01125 per request (1K in, 1K out) # Gateway API import requests response = requests.post( "https://api.laozhang.ai/v1/chat/completions", headers={"Authorization": "Bearer your-gateway-key"}, json={ "model": "gemini-2.5-pro", "messages": [{"role": "user", "content": "Your prompt"}] } ) # Cost: \$0.003375 per request (70% savings)
Gateway Benefits Beyond Cost
- Unified API - Single interface for multiple AI providers
- No rate limits - Gateway handles load distribution
- Automatic failover - Switches between models during outages
- Usage analytics - Consolidated reporting across providers
- Simplified billing - One invoice instead of multiple providers
When Gateways Make Sense
- Monthly API spend exceeds $500
- Using multiple AI providers
- Variable/unpredictable usage patterns
- Limited engineering resources for optimization
- Priority on cost over latency (adds 50-100ms)
Making the Strategic Decision: Your Pricing Framework
The optimal Gemini API pricing strategy depends on your specific use case, scale, and constraints. This decision framework guides selection:
Choose Direct API When:
- Latency requirements < 200ms
- Regulatory compliance requires direct provider relationships
- Custom model fine-tuning or exclusive features needed
- Monthly spend < $500 (overhead not justified)
- Batch mode fits your use case (50% savings)
Choose Gateway Services When:
- Cost optimization is primary concern
- Using multiple AI providers
- Rapid scaling expected
- Engineering resources limited
- Latency tolerance > 300ms
Hybrid Approach for Maximum Optimization
Many successful implementations combine approaches:
- Direct API for latency-critical customer-facing features
- Batch mode for background processing and analytics
- Gateway services for development, testing, and overflow capacity
This hybrid strategy provides resilience while optimizing costs. A typical split might route 20% of traffic through direct APIs for real-time needs, 50% through batch mode for processable workloads, and 30% through gateways for cost optimization.
Implementation Roadmap: From Analysis to Optimization
Phase 1: Baseline Measurement (Week 1)
- Implement comprehensive token tracking
- Log all API calls with token counts
- Categorize requests by type and urgency
- Calculate current per-request costs
- Identify batch mode candidates
Phase 2: Quick Wins (Week 2-3)
- Enable batch mode for eligible workloads (50% instant savings)
- Implement response caching for common queries
- Optimize prompt templates to reduce token usage
- Switch simple tasks from Pro to Flash model
- Set up cost monitoring alerts
Phase 3: Architectural Optimization (Month 2)
- Implement context caching for knowledge bases
- Deploy intelligent model routing
- Build request aggregation system
- Integrate gateway services for overflow
- Establish cost governance policies
Phase 4: Continuous Optimization (Ongoing)
- Weekly cost analysis reviews
- A/B testing of prompt optimizations
- Regular model performance evaluation
- Quarterly pricing strategy review
- Explore emerging optimization techniques
Conclusion: Your $22,500 Annual Optimization Opportunity
Gemini API pricing complexity, initially overwhelming, becomes a strategic advantage when properly understood and optimized. The combination of batch mode processing, intelligent model selection, and strategic gateway usage can reduce API costs by 70-80% without sacrificing functionality. For the average startup spending $3,750 monthly on AI APIs, these optimizations represent $22,500-$30,000 in annual savings.
The July 2025 batch mode introduction marks an inflection point in AI API economics. Organizations that adapt their architectures to leverage asynchronous processing gain sustainable competitive advantages through dramatically lower operational costs. Those clinging to synchronous-only patterns face escalating bills that eventually force architectural changes under pressure.
Success requires moving beyond simple per-token calculations to holistic cost optimization. Monitor actual usage patterns, implement intelligent routing, leverage caching aggressively, and remain flexible in your approach. Whether through direct optimization or gateway services like laozhang.ai, the path to 70% cost reduction is clear and achievable.
The teams that master Gemini API pricing today build the sustainable AI applications of tomorrow. Start with batch mode, measure everything, and optimize relentlessly. Your CFO—and your users—will thank you.