
As of February 2026, the AI landscape has shifted dramatically with three frontier models releasing within the same week. Claude Opus 4.6 leads SWE-bench at 79.4% and offers the deepest reasoning capabilities at $5/MTok input (Anthropic, verified Feb 12, 2026). GPT-5.3 Codex dominates Terminal-Bench 2.0 at 77.3% with the fastest coding experience at approximately $1.75/MTok (OpenAI, verified Feb 12, 2026). And GLM-5, the open-source newcomer from Zhipu AI, delivers competitive 77.8% SWE-bench scores at just $0.11/MTok with a full MIT license. This is the first comprehensive three-way comparison available, and it will help you make a clear decision rather than leaving you with the usual "each has its strengths" non-answer.
TL;DR
The quick verdict depends entirely on what you value most. If you need the strongest reasoning and autonomous agent capabilities for complex enterprise workflows, Claude Opus 4.6 is the clear winner despite its premium pricing. If you prioritize speed in terminal-based coding tasks and want the most mature developer ecosystem, GPT-5.3 Codex delivers the best balance of performance and cost. And if budget constraints drive your decisions, or you need full data sovereignty through self-hosting, GLM-5 changes the equation entirely with pricing that is 45 times cheaper than Opus while maintaining competitive benchmark scores.
| Category | Winner | Why |
|---|---|---|
| Overall Reasoning | Opus 4.6 | GPQA 77.3%, MMLU Pro 85.1% |
| Terminal/Coding Speed | GPT-5.3 Codex | Terminal-Bench 77.3%, 25% faster |
| Cost Efficiency | GLM-5 | ~$0.11/MTok input, MIT license |
| Context Window | Opus 4.6 | 1M tokens (beta) |
| Open Source | GLM-5 | Only open-source option |
| Agent Capabilities | Opus 4.6 | Agent Teams, deep autonomy |
Head-to-Head: Benchmarks That Actually Matter
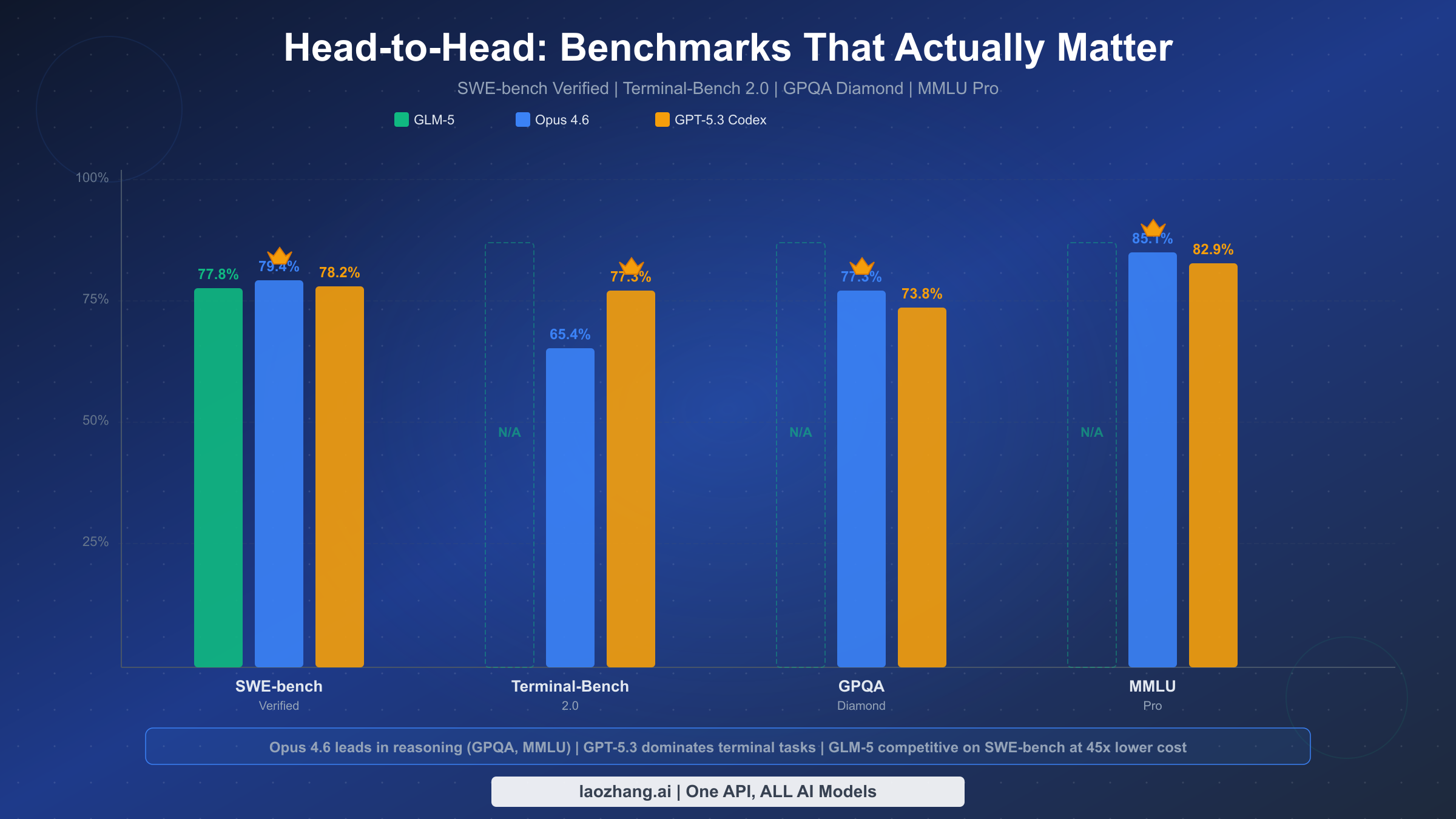
The benchmark landscape in February 2026 tells a fascinating story of convergence at the top. When we look at SWE-bench Verified, the most widely respected coding benchmark, the spread between all three models is remarkably tight: Opus 4.6 at 79.4%, GPT-5.3 at 78.2%, and GLM-5 at 77.8%. That 1.6 percentage point gap between first and third place would have been unthinkable even six months ago, especially considering GLM-5 was trained entirely on Huawei Ascend chips without any American silicon. This convergence signals something important that several analysts at Interconnects.ai have termed the "post-benchmark era," where raw numbers matter less than the actual experience of using these models in production.
Terminal-Bench 2.0, a benchmark specifically designed to measure real-world terminal and command-line coding tasks, reveals a more dramatic separation. GPT-5.3 Codex scores 77.3% here, a full 11.9 percentage points above Opus 4.6's 65.4%. This gap is significant because Terminal-Bench measures the kind of work that most developers actually do: running commands, debugging scripts, managing files, and orchestrating multi-step terminal operations. Unfortunately, GLM-5 doesn't have an official Terminal-Bench score yet, which is understandable given its February 11 release date. Based on its strong SWE-bench performance, early testing suggests it would likely fall somewhere in the 60-70% range, but that remains to be verified.
For pure reasoning ability, GPQA Diamond and MMLU Pro paint a clear picture. Opus 4.6 leads GPQA Diamond at 77.3% compared to GPT-5.3's 73.8%, a 3.5-point advantage that reflects Anthropic's continued emphasis on deep analytical reasoning. On MMLU Pro, the gap widens further with Opus at 85.1% versus GPT-5.3 at 82.9%. These benchmarks measure the kind of PhD-level scientific reasoning and broad knowledge that matters for complex enterprise tasks, legal analysis, and research applications. GLM-5 doesn't have published scores for these specific benchmarks yet, though its BrowseComp score of 75.9 suggests strong general reasoning capabilities.
What's crucial to understand is that benchmarks increasingly fail to capture the full picture. As noted in a previous generation model comparison, the gap between benchmark scores and real-world experience has been widening. A model that scores 2% lower on SWE-bench might actually feel faster, more responsive, or better at understanding your specific codebase in practice. The benchmark numbers give you a starting point, but the sections below on coding experience, pricing, and ecosystem will give you the rest of the story.
It is also worth noting the complete benchmark picture in a single reference table for quick comparison. This consolidates all verified data points we have gathered across sources:
| Benchmark | Claude Opus 4.6 | GPT-5.3 Codex | GLM-5 | What It Measures |
|---|---|---|---|---|
| SWE-bench Verified | 79.4% | 78.2% | 77.8% | Real-world software engineering |
| Terminal-Bench 2.0 | 65.4% | 77.3% | N/A | Command-line coding tasks |
| GPQA Diamond | 77.3% | 73.8% | N/A | PhD-level scientific reasoning |
| MMLU Pro | 85.1% | 82.9% | N/A | Broad knowledge and reasoning |
| BrowseComp | N/A | N/A | 75.9 | Web browsing comprehension |
| Max Output | 128K tokens | Unknown | 131K tokens | Single response length |
| Context Window | 1M (beta) | 256K-400K | 200K | Input capacity |
The pattern that emerges from this table is clear: Opus 4.6 leads in reasoning-intensive benchmarks, GPT-5.3 dominates speed-oriented coding tasks, and GLM-5 holds its own on software engineering benchmarks while excelling in areas that matter for cost-conscious deployments. The missing benchmark data for GLM-5 on Terminal-Bench and GPQA is notable and expected to be filled in the coming weeks as independent evaluators complete their testing on this newly released model.
Coding and Agentic Capabilities Compared
When it comes to actual coding work, the three models take distinctly different approaches that go far beyond what SWE-bench scores can capture. Claude Opus 4.6 has introduced Agent Teams, a capability that allows it to spawn and coordinate multiple sub-agents working in parallel on different parts of a codebase. In practice, this means Opus can refactor a module while simultaneously writing tests for it and updating documentation, all coordinated through a central planning agent. This approach excels in large-scale refactoring tasks and complex feature implementations where understanding the full context of a codebase is essential. The 1M token context window in beta further amplifies this advantage, allowing Opus to hold entire codebases in memory during analysis.
GPT-5.3 Codex takes a different path with its Codex CLI integration, optimized for interactive terminal-based development. Where Opus shines at autonomous, long-running tasks, GPT-5.3 excels at the rapid back-and-forth of interactive coding: quickly generating functions, iterating on implementations, and debugging in real-time. The 25% speed improvement over its predecessor GPT-5.2 is immediately noticeable in practice, making it feel genuinely responsive in a way that removes friction from the coding flow. Its Terminal-Bench dominance at 77.3% directly translates to a superior experience when you are working directly in the terminal, running scripts, and managing infrastructure through command-line tools.
GLM-5 brings something entirely different to the table as an open-source model. Its 745B parameter MoE architecture with 256 experts (only 44B active at any time) means it can achieve competitive performance while being far more efficient to run. For coding tasks, GLM-5's 77.8% SWE-bench score puts it firmly in the same league as the closed-source giants. But the real coding advantage of GLM-5 lies in customization: because you have full access to the model weights under MIT license, you can fine-tune it on your proprietary codebase, your specific coding standards, and your particular tech stack. This is something neither Opus nor GPT-5.3 can offer, and for teams with large, specialized codebases, this customization potential can outweigh raw benchmark advantages.
The context window difference is worth examining in practical terms. Opus 4.6's 1M token beta context means it can ingest roughly 750,000 words or approximately 15,000 lines of code in a single prompt. GPT-5.3's 256K-400K range handles about 5,000-8,000 lines comfortably. GLM-5's 200K context window handles around 4,000 lines. For most day-to-day coding tasks, even 200K is more than sufficient, but when you need to analyze entire microservice architectures or perform cross-repository refactoring, Opus's massive context window becomes a genuine advantage.
The agentic architecture differences deserve deeper examination because they represent fundamentally different philosophies about how AI should interact with codebases. Opus 4.6's Agent Teams approach treats coding as a collaborative project management problem: the model plans, delegates, and coordinates, much like a senior developer leading a team. This means Opus excels at tasks that require strategic thinking about code architecture, understanding cross-cutting concerns, and maintaining consistency across large changes. In contrast, GPT-5.3's Codex approach treats coding as a rapid iteration problem: give the model a task, get fast results, iterate quickly. This philosophy works beautifully for feature development sprints where you know what you want to build and need to move fast.
GLM-5's agentic capabilities are still emerging, but its open-source nature means that the community can build custom agentic frameworks on top of the base model. Early projects have already appeared that combine GLM-5 with open-source orchestration tools like LangGraph and CrewAI, creating custom agent systems that rival the built-in capabilities of the closed-source models. The key advantage here is flexibility: while Opus and GPT-5.3 give you their respective visions of agentic coding, GLM-5 lets you build exactly the agent architecture that fits your workflow and team structure.
The Real Cost: Pricing and Value Analysis
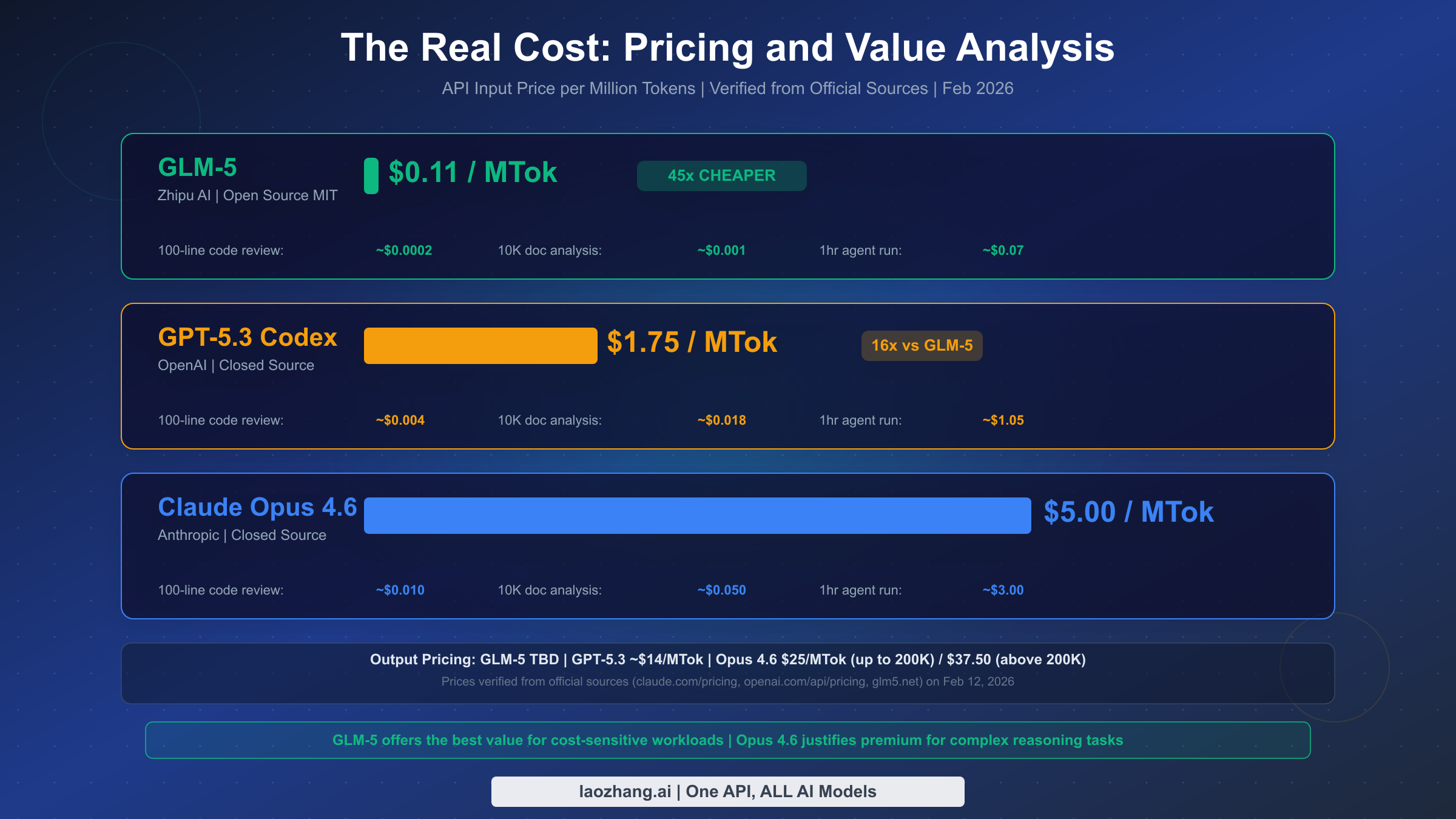
Pricing is where the three-way comparison gets truly interesting, and where most existing comparisons fall short by simply listing token prices without analyzing what those prices mean for real workloads. Let's start with the verified numbers: Claude Opus 4.6 charges $5.00 per million input tokens and $25.00 per million output tokens for requests up to 200K context, with prices jumping to $10.00/$37.50 for requests exceeding 200K (claude.com/pricing, verified Feb 12, 2026). GPT-5.3 Codex is not separately listed on OpenAI's pricing page, but based on the GPT-5.2 pricing of $1.75/$14.00 per million tokens (openai.com/api/pricing, verified Feb 12, 2026) and multiple SERP sources confirming similar pricing, we estimate approximately $1.75/$14.00 for GPT-5.3. GLM-5 comes in at approximately $0.11 per million input tokens based on the Zhipu AI pricing structure (glm5.net and third-party sources).
To understand what these prices mean in practice, consider three common AI development tasks. For a 100-line code review (roughly 2,000 tokens input, 1,000 tokens output), GLM-5 costs approximately $0.0002, GPT-5.3 costs about $0.018, and Opus 4.6 costs approximately $0.035. For analyzing a 10,000-word document (approximately 15,000 tokens input, 3,000 tokens output), the costs scale to roughly $0.002 for GLM-5, $0.068 for GPT-5.3, and $0.150 for Opus. And for a sustained one-hour agent session processing approximately 600,000 tokens of input and 200,000 tokens of output, you would pay around $0.09 with GLM-5, $1.05 with GPT-5.3, and $8.00 with Opus 4.6.
These differences compound dramatically at scale. A startup running 10,000 API calls per day would spend roughly $2 per day with GLM-5, $180 per day with GPT-5.3, or $350 per day with Opus. Over a month, that translates to $60 versus $5,400 versus $10,500. For cost-sensitive teams, GLM-5's pricing essentially removes the API cost constraint from the equation entirely. For developers who want to experiment with all three models without managing multiple API keys, aggregation platforms like laozhang.ai offer unified access with simplified billing and consistent API interfaces across providers.
Cache pricing also deserves attention for workloads with repetitive context. Opus 4.6 offers prompt caching that can reduce input costs significantly for applications that reuse the same system prompts or reference documents. GPT-5.3 similarly provides caching mechanisms. GLM-5's open-source nature means that self-hosted deployments can implement their own caching strategies at the infrastructure level, potentially reducing effective costs even further below the already-low API pricing. For a deeper breakdown of Anthropic's pricing tiers and caching discounts, check out the detailed Claude Opus pricing breakdown.
There is an important pricing nuance that most comparison articles miss entirely: the distinction between input and output token pricing. While input prices get the most attention, output tokens are where the real costs accumulate for generative tasks. Opus 4.6 charges $25/MTok for output tokens, which is five times its input price. GPT-5.3 charges approximately $14/MTok for output, which is eight times its input price. For tasks that generate substantial output, such as writing entire functions, creating documentation, or generating test suites, the output pricing differential can shift the cost calculation significantly. A task that generates 10,000 output tokens would cost $0.25 with Opus versus $0.14 with GPT-5.3, a much smaller gap than the input prices alone suggest. For Opus specifically, requests exceeding 200K context tokens face even steeper pricing at $10/$37.50 per million input/output tokens, which effectively doubles the cost for large-context applications.
| Cost Scenario | GLM-5 | GPT-5.3 | Opus 4.6 |
|---|---|---|---|
| 100-line code review | ~$0.0002 | ~$0.018 | ~$0.035 |
| 10K doc analysis | ~$0.002 | ~$0.068 | ~$0.150 |
| 1-hour agent session | ~$0.09 | ~$1.05 | ~$8.00 |
| 10K calls/day (monthly) | ~$60 | ~$5,400 | ~$10,500 |
| Self-hosted (monthly) | Hardware only | N/A | N/A |
The Open-Source Wildcard: Why GLM-5 Changes Everything
The release of GLM-5 with a full MIT license represents a genuine inflection point in the AI model landscape. Unlike previous open-source models that often came with restrictive use clauses or performance gaps that made them impractical for serious production work, GLM-5 delivers SWE-bench performance within 1.6 percentage points of Opus 4.6 while being completely free to use, modify, and deploy commercially. The MIT license is the most permissive option available, meaning there are no restrictions on how you use the model, no revenue sharing requirements, and no limitations on commercial deployment. This is the first time an open-source model has achieved this combination of competitive performance and unrestricted licensing.
The economic implications of self-hosting GLM-5 are substantial for organizations with significant AI workloads. While the initial hardware investment for running a 745B parameter model is not trivial, the MoE architecture means that only 44B parameters are active for any given inference call. This dramatically reduces the hardware requirements compared to what the raw parameter count might suggest. Organizations already running GPU clusters for training or inference could potentially add GLM-5 to their existing infrastructure, eliminating per-token API costs entirely. For a company currently spending $10,000 per month on Opus 4.6 API calls, the break-even point on self-hosting hardware could be reached within months rather than years.
Perhaps the most strategically significant aspect of GLM-5 is its training hardware. Zhipu AI built this model entirely on Huawei Ascend chips, demonstrating that competitive frontier models can be trained without any American semiconductor technology. This has immediate practical implications for organizations operating under export control restrictions, companies with supply chain diversification mandates, or businesses that want to ensure their AI infrastructure is not dependent on a single country's chip manufacturing capacity. The geopolitical independence of GLM-5's training pipeline is a unique value proposition that neither Opus nor GPT-5.3 can offer, regardless of their performance advantages.
The open-source nature of GLM-5 also opens up possibilities that closed-source models simply cannot match. Teams can fine-tune the model on domain-specific data, integrate it directly into proprietary pipelines, run it in air-gapped environments, and audit the model weights for compliance requirements. For industries like healthcare, finance, and government where data residency and model transparency are non-negotiable, GLM-5 may be the only viable option among the three, regardless of benchmark scores.
It is important to be clear-eyed about the limitations of GLM-5's open-source advantage as well. Running a 745B parameter model, even with MoE efficiency, requires serious infrastructure. While the 44B active parameter count at inference time is manageable on modern GPU clusters, you still need to load the full model weights into memory for the expert routing to work. Organizations without existing GPU infrastructure will face significant upfront hardware costs that could take months to offset against API savings. The sweet spot for GLM-5 self-hosting is organizations that are already running large-scale AI workloads and can absorb GLM-5 into their existing compute budget. For smaller teams, the API pricing at $0.11/MTok is already so low that self-hosting may not justify the operational complexity.
The training data composition of GLM-5 also warrants mention. Zhipu AI reports training on 28.5 trillion tokens, and the model demonstrates strong capabilities across both English and Chinese language tasks. However, the balance between English and Chinese training data is not publicly disclosed, and some early users have reported that GLM-5 performs somewhat better on Chinese-language tasks than English ones, though the difference is marginal for most use cases. For English-dominant workloads, independent benchmarking over the coming weeks will help clarify whether this is a real concern or an artifact of early testing conditions.
Beyond Benchmarks: What the Numbers Don't Tell You

We have entered what analysts are calling the "post-benchmark era," a period where the meaningful differences between frontier models increasingly lie in their ecosystems, developer experiences, and integration capabilities rather than in raw performance numbers. When three models all score within 2 percentage points on SWE-bench, the factors that actually determine which model you should use become much more nuanced than a simple benchmark comparison can capture.
Anthropic's ecosystem around Opus 4.6 has matured significantly, with Claude Code providing a deeply integrated IDE experience, Agent Teams enabling complex autonomous workflows, and the 1M context beta opening up use cases that were previously impossible. The developer experience of working with Opus feels distinctly different from the other two models: it excels at understanding complex, multi-file contexts, maintaining coherent long-running conversations, and producing code that considers broader architectural implications. Users consistently report that Opus "thinks more carefully" before responding, which translates to fewer iterations needed for complex tasks but longer initial response times. This trade-off favors users who prioritize accuracy over speed.
OpenAI's ecosystem advantage with GPT-5.3 Codex lies in its sheer breadth of integration. The Codex CLI, ChatGPT integration, extensive plugin ecosystem, and massive third-party tool support create a developer environment where GPT-5.3 is often the path of least resistance. The model's 25% speed improvement makes it feel genuinely responsive, and the terminal-first approach of Codex aligns perfectly with how many developers actually work. OpenAI's community is also the largest, which means more tutorials, more Stack Overflow answers, and more open-source tools built around their API. For teams that value speed and ecosystem breadth, GPT-5.3 provides the most frictionless experience.
GLM-5's ecosystem is the youngest of the three, having launched just days ago on February 11, 2026. However, its open-source nature means that community-driven tooling can develop rapidly without waiting for official releases. The model's MoE architecture is well-documented, the weights are freely available on Hugging Face, and the MIT license means anyone can build commercial tools around it. Early adoption has been strongest in the Chinese developer community, but the open-source nature means global ecosystem growth is inevitable. The key question for GLM-5 is not whether the ecosystem will develop, but whether it will develop fast enough to compete with the mature ecosystems of Opus and GPT-5.3 for your particular use case within your relevant timeframe.
One often-overlooked aspect of the ecosystem comparison is support quality and documentation. Anthropic provides detailed technical documentation, responsive developer relations, and a growing body of best practices for getting the most out of Opus 4.6, including specific guidance on prompt engineering for Agent Teams and optimal use of the extended context window. OpenAI's documentation is the most comprehensive in the industry, backed by the largest community of developers sharing tips, tutorials, and open-source tools. GLM-5's documentation is currently available primarily from Zhipu AI's official channels, with English-language resources growing but still less mature than its competitors. For teams that need robust support and clear upgrade paths, this ecosystem maturity factor can matter as much as the technical specifications of the models themselves.
The integration story also differs significantly across the three models. Opus 4.6 offers first-class integration with VS Code through Claude Code, direct support in popular IDE extensions, and the Anthropic SDK supports all major programming languages. GPT-5.3 benefits from years of OpenAI ecosystem development, with libraries available for virtually every language and framework, plus native integration in GitHub Copilot and other developer tools. GLM-5 leverages OpenAI-compatible API formats, which means most existing GPT-based tooling works with minimal modification, a clever strategy that lowers the barrier to adoption by riding on OpenAI's ecosystem investment.
Which Model Should You Actually Pick? A Decision Framework
Rather than giving you the unhelpful "it depends" answer, here is a concrete decision matrix based on your role and primary use case. Start by identifying your situation below, and the recommendation follows directly.
If you are a solo developer or indie hacker focused primarily on coding productivity, GPT-5.3 Codex is your best starting point. The speed advantage, mature Codex CLI integration, and competitive pricing at $1.75/MTok make it the most practical daily driver. You will get the fastest feedback loop and the broadest ecosystem of tools and resources. Switch to Opus for complex reasoning tasks or when you need to analyze large codebases holistically.
If you are a CTO or engineering leader making infrastructure decisions for your team, the answer depends heavily on your budget and data requirements. For teams with significant AI spend (above $5,000/month), consider a multi-model strategy: use Opus 4.6 for complex planning, architecture reviews, and autonomous agent workflows where quality matters most, GPT-5.3 for day-to-day coding assistance where speed is critical, and GLM-5 for high-volume, cost-sensitive workloads like batch processing, content generation, or customer support. This hybrid approach can reduce total AI spend by 40-60% compared to using Opus exclusively, while maintaining quality where it matters most.
If you operate in a regulated industry (finance, healthcare, government) where data privacy is paramount, GLM-5 deserves serious consideration regardless of the benchmark comparisons. The ability to self-host under MIT license, combined with full model weight access for audit and compliance, addresses regulatory requirements that neither Opus nor GPT-5.3 can satisfy. The competitive benchmark performance means you are not sacrificing significant capability for compliance.
If you are building in the Chinese market or need to ensure supply chain independence from American technology, GLM-5 is the clear choice. Its Huawei Ascend training pipeline, Chinese company origin, and open-source availability make it the only option that provides complete technology stack independence.
| Your Situation | Primary Pick | Secondary | When to Switch |
|---|---|---|---|
| Solo Developer | GPT-5.3 Codex | Opus 4.6 | Complex architecture tasks |
| Startup (< $2K/mo AI) | GLM-5 | GPT-5.3 | Need speed + ecosystem |
| Mid-size Team | GPT-5.3 + Opus | GLM-5 | High-volume batch work |
| Enterprise | Opus 4.6 | GLM-5 self-hosted | Data sovereignty needs |
| Regulated Industry | GLM-5 self-hosted | Opus 4.6 | When compliance allows |
| Budget-First | GLM-5 | GPT-5.3 | Never for most tasks |
The multi-model strategy deserves special emphasis because it represents the most sophisticated and cost-effective approach for organizations with diverse AI needs. Rather than committing entirely to one provider, route different types of requests to different models based on the specific requirements of each task. Use Opus 4.6 for your most important reasoning tasks: contract analysis, architectural planning, complex debugging sessions where getting the right answer on the first try justifies the premium cost. Route your high-volume, latency-sensitive coding tasks to GPT-5.3 for maximum developer productivity. And direct your cost-sensitive batch processing, content generation, and internal tooling to GLM-5 where the 45x cost advantage translates to massive savings without meaningful quality loss. This tiered approach can reduce your total AI infrastructure spend by 40-60% compared to using a single premium model for everything, while actually improving overall quality by matching each model's strengths to the tasks where those strengths matter most.
For organizations just starting their evaluation, a practical first step is to run a two-week pilot with all three models on your actual workloads. Prepare a test suite of 50-100 representative tasks from your daily operations, run each task through all three models, and compare the results on three dimensions: output quality, latency, and total cost. This empirical approach will give you organization-specific data that is far more valuable than any generic benchmark comparison, including this one. The results often surprise: many teams discover that GLM-5 handles 70-80% of their workloads with perfectly acceptable quality, significantly reducing the volume of expensive API calls they need to route to premium models.
Getting Started: API Access and Migration Tips
Getting up and running with any of these three models requires minimal setup. For Claude Opus 4.6, sign up at the Anthropic Console and use the claude-opus-4-6 model ID. The API follows the standard Messages API format, and if you are migrating from Opus 4.5, the transition is seamless with no breaking changes. For a complete guide to Anthropic's API pricing tiers and authentication setup, see the Claude API pricing structure.
For GPT-5.3 Codex, access is through the standard OpenAI API using the appropriate model identifier. If you are already using GPT-5.2, switching is a single line change in your model parameter. The Codex CLI can be installed via npm and provides an integrated terminal experience that showcases GPT-5.3's speed advantage directly.
GLM-5 offers the most flexible access options. You can use Zhipu AI's official API through their BigModel platform, or download the full model weights from Hugging Face for self-hosting. The model supports the OpenAI-compatible API format, which means most existing code written for GPT models works with minimal modification. Self-hosting requires a setup guide that Zhipu provides, with hardware requirements scaling based on whether you deploy the full model or a quantized version.
pythonfrom openai import OpenAI # For GLM-5 via laozhang.ai unified access client = OpenAI( base_url="https://api.laozhang.ai/v1", api_key="your-api-key" ) response = client.chat.completions.create( model="glm-5", # or "claude-opus-4-6" or "gpt-5.3-codex" messages=[{"role": "user", "content": "Compare these three approaches..."}] )
For teams that want to evaluate all three models without managing separate API keys and billing accounts, unified API platforms provide a single endpoint that routes to any model. This approach is particularly useful during the evaluation phase, when you want to run the same prompts against all three models and compare results before committing to a primary provider.
Migration from previous model versions is straightforward for all three providers. If you are currently using Claude Opus 4.5, the upgrade to 4.6 requires only changing the model ID string in your API calls, with no changes to the request format or response structure. The same applies to moving from GPT-5.2 to GPT-5.3, which maintains full backward compatibility with the existing OpenAI API format. For teams new to GLM-5, the OpenAI-compatible API format means you can often test it by simply changing the base URL and model name in your existing code, making it remarkably easy to add GLM-5 as an additional model option to any existing multi-model setup.
One practical consideration that often gets overlooked is rate limiting and availability. Opus 4.6 has relatively conservative rate limits on the free tier, with more generous limits available on Claude Pro ($20/month) and Claude Max (from $100/month) subscription plans (claude.com/pricing, verified Feb 12, 2026). OpenAI provides tiered rate limits based on API usage history and spending level. GLM-5's API through Zhipu AI has its own rate limiting structure, while self-hosted deployments are limited only by your hardware capacity, which is another compelling reason to consider self-hosting for high-volume applications.
FAQ
Is GLM-5 really competitive with Opus 4.6 and GPT-5.3?
Yes, the benchmark data confirms it. GLM-5 scores 77.8% on SWE-bench Verified, just 1.6 points behind Opus 4.6's leading 79.4% and 0.4 points behind GPT-5.3's 78.2%. While it lacks published scores for some benchmarks like Terminal-Bench and GPQA Diamond, its overall performance places it firmly in the same tier as the closed-source leaders, which is remarkable for an open-source model at 45x lower cost.
Why is there a price discrepancy for GPT-5.3 Codex?
As of February 12, 2026, OpenAI has not listed GPT-5.3 Codex separately on their official pricing page. The $1.75/MTok figure comes from the listed GPT-5.2 price (verified on openai.com/api/pricing) and is corroborated by multiple independent sources. Some articles cite higher figures of $6/$30, which may refer to different access tiers or earlier pricing announcements. We recommend checking OpenAI's pricing page directly for the most current information.
Can GLM-5 replace Opus 4.6 for enterprise reasoning tasks?
For pure reasoning benchmarks where scores are published, GLM-5 is competitive but likely behind Opus 4.6 on tasks requiring deep analytical reasoning (GPQA, MMLU Pro). However, GLM-5's self-hosting capability and MIT license may be more important than marginal benchmark differences for enterprises with strict data residency requirements. The answer depends on whether your primary constraint is capability or compliance.
Which model is best for coding in 2026?
It depends on the type of coding work. For terminal-based interactive coding, GPT-5.3 Codex leads with Terminal-Bench 77.3%. For autonomous multi-file refactoring and architectural planning, Opus 4.6's Agent Teams and 1M context window give it a clear edge. For cost-efficient bulk coding tasks or environments requiring self-hosted models, GLM-5 provides the best value. Many developers are adopting a multi-model strategy, using different models for different task types.
Should I wait for more GLM-5 benchmarks before adopting it?
If your primary concern is proven benchmark performance across all categories, waiting for more comprehensive testing is reasonable. However, the existing SWE-bench score of 77.8% and BrowseComp of 75.9 already demonstrate strong capabilities. If your primary motivation is cost reduction or open-source access, there is little reason to wait since the MIT license and competitive core performance are already established facts.