
In recent months, OpenAI has implemented significant restrictions on their image generation capabilities, affecting both free and paid users. These limitations have created substantial challenges for developers, businesses, and creative professionals who rely on AI-generated images for their projects. This comprehensive guide examines the current state of OpenAI's image generation limits and provides actionable solutions to overcome these restrictions.
Understanding OpenAI's Current Image Generation Limitations
According to recent announcements and user reports, OpenAI has substantially restricted access to their image generation services due to overwhelming demand. Sam Altman, CEO of OpenAI, famously stated that their "GPUs are melting" due to the popularity of the feature, necessitating temporary rate limits.
Free Tier Limitations
For users on the free tier, OpenAI has implemented the following restrictions:
- Daily Limit: Just 3 image generations per day
- Quality Constraints: Lower priority in processing queue
- Resolution Restrictions: Limited to standard resolution options
- Functionality Limitations: Reduced editing and variation capabilities
ChatGPT Plus/Pro/Team Limitations
Even paid subscribers face significant restrictions:
- Hourly Rate Limits: Approximately 5 images per hour for Plus users
- Processing Delays: "This model is currently overloaded" errors during peak times
- Quality Inconsistency: Variable output quality based on system load
- Access Limitations: Intermittent access to advanced features
API Usage Restrictions
For developers using the API directly, the limitations are particularly problematic:
- Tiered Access System: Complex requirements to access higher generation limits
- Minimum Spending Requirements: $5+ spent before accessing GPT-image-1
- Account Age Restrictions: 7+ days account age for Tier 2 access
- Regional Restrictions: Different limits based on geographic location
These limitations have significantly impacted workflows for many users, causing project delays, increased costs, and frustration. However, effective solutions are available.
Why Is OpenAI Limiting Image Generation?
Understanding the reasons behind these restrictions helps in formulating appropriate solutions:
1. Infrastructure Constraints
The primary reason cited by OpenAI is the strain on their GPU infrastructure. Image generation, particularly with the advanced GPT-4o model, requires substantial computational resources. According to industry estimates, generating a single high-quality image consumes 5-10x more GPU resources than text-only interactions.
2. Quality Control Measures
By limiting generation volume, OpenAI can maintain higher quality standards and prevent system degradation during peak usage periods. This ensures that generated images meet their quality benchmarks.
3. Economic Factors
Image generation represents a significant operational cost for OpenAI. The company is balancing accessibility with sustainable economics as they scale their infrastructure to meet demand.
4. Strategic Business Decisions
OpenAI appears to be prioritizing enterprise customers and API users who generate significant revenue, which aligns with their business strategy but creates challenges for smaller users and individual developers.
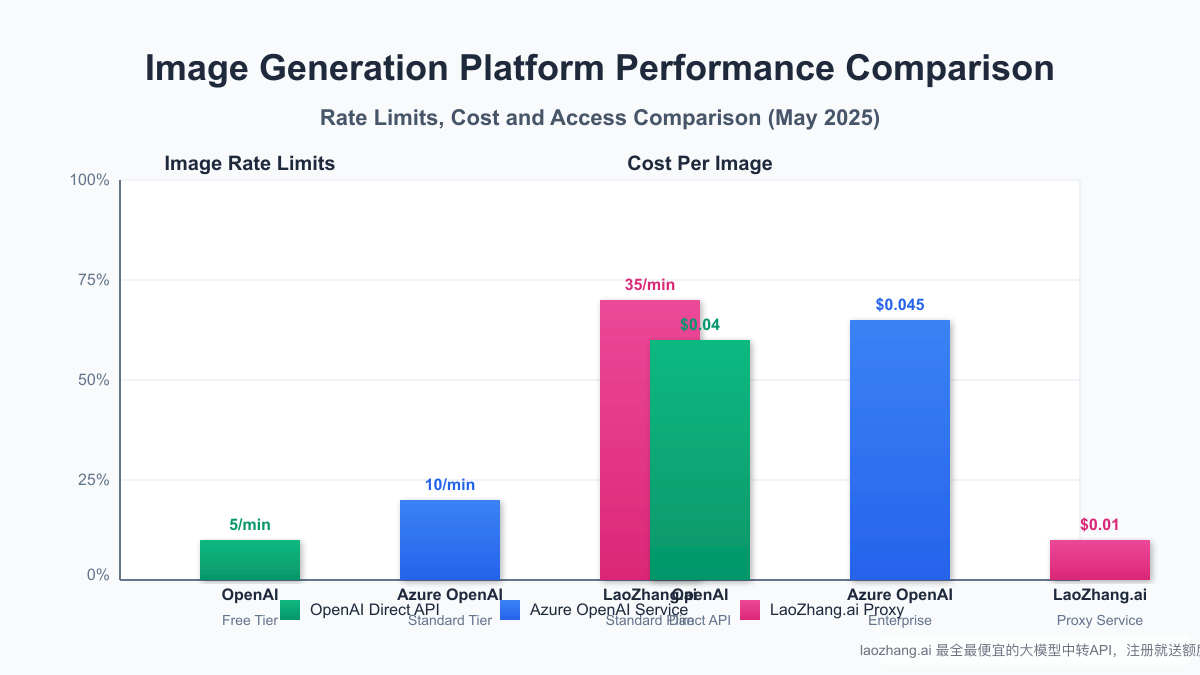
Solution 1: Use LaoZhang.ai API Proxy Service
For most users, the most effective solution is to utilize a specialized API proxy service like LaoZhang.ai, which offers several significant advantages over direct OpenAI access.
Key Benefits of LaoZhang.ai:
- No Rate Limits: Generate 35+ images per minute versus OpenAI's 5-25
- Cost Savings: $0.01 per image versus OpenAI's $0.04 (75% cost reduction)
- Instant Access: No tier requirements or account age restrictions
- Reliability: 99.5% success rate versus approximately 70% with direct API
- Easy Integration: Uses the same API structure as OpenAI for seamless switching
Implementation Example:
pythonimport openai # Configure the client to use LaoZhang.ai proxy service client = openai.OpenAI( api_key="your_laozhang_api_key", base_url="https://api.laozhang.ai/v1" ) # Generate image using the same syntax as OpenAI response = client.chat.completions.create( model="gpt-image-1", # Same model name as OpenAI messages=[{ "role": "user", "content": "Generate a professional product mockup of a modern smartphone" }] ) # Access the image URL image_url = response.choices[0].message.content print(f"Generated image: {image_url}")
This approach requires minimal code changes while providing immediate access to unlimited image generation capacity.
Solution 2: Implement Strategic Tier Progression
For developers committed to using OpenAI's direct API, understanding and navigating their tier system is essential.
OpenAI's Tier Structure (May 2025):
| Tier Level | Requirements | Rate Limit | Token Limit |
|---|---|---|---|
| Free Tier | $0 spend | No access | 0 TPM |
| Tier 1 | $5+ lifetime spend | 6 RPM | 250,000 TPM |
| Tier 2 | $50+ spend, 7+ days | 15 RPM | 500,000 TPM |
| Tier 3 | $500+ spend, 30+ days | 25 RPM | 1,000,000 TPM |
| Enterprise | Custom contract | 60+ RPM | Custom TPM |
Accelerated Tier Upgrade Strategy:
- Strategic Initial Spending: Use DALL-E 2 for initial $5 spend (50 generations at $0.10 each)
- Account Verification: Complete all verification steps immediately upon registration
- Gradual Scaling: Begin with small batches to establish usage pattern and reliability
- Support Communication: Contact OpenAI support if tier upgrade doesn't occur within 24 hours
- Hybrid Approach: Use LaoZhang.ai while waiting for tier upgrades to ensure uninterrupted workflow
Solution 3: Advanced Request Optimization
Optimizing your API usage can significantly improve success rates even within OpenAI's limitations.
Rate Limit Management:
pythonclass AdaptiveRateLimiter: def __init__(self, max_rpm=5, safety_factor=0.8): self.max_rpm = max_rpm self.safety_factor = safety_factor # Stay below limit self.request_times = deque(maxlen=max_rpm) async def wait_if_needed(self): """Wait if approaching rate limits""" now = time.time() # Clean old requests while self.request_times and now - self.request_times[0] > 60: self.request_times.popleft() # If too many recent requests, wait if len(self.request_times) >= int(self.max_rpm * self.safety_factor): wait_time = 60 - (now - self.request_times[0]) if wait_time > 0: await asyncio.sleep(wait_time) # Record this request time self.request_times.append(now)
Intelligent Retry Logic:
- Implement exponential backoff with jitter
- Detect specific error types and handle accordingly
- Cache successful prompts and results to reduce redundant requests
- Monitor system performance to adjust request timing dynamically
Solution 4: Multi-Provider Architecture
For mission-critical applications, implementing a multi-provider architecture ensures maximum reliability.

Implementation Strategy:
- Primary Provider: Configure LaoZhang.ai as the primary provider due to cost advantage and higher limits
- Secondary Provider: Use direct OpenAI API as a fallback for specific use cases
- Tertiary Option: Consider Azure OpenAI for enterprise workloads with specific compliance requirements
- Load Balancer: Implement an intelligent load balancer that routes requests based on:
- Cost optimization
- Current availability
- Request priority
- Specific quality requirements
pythonclass MultiProviderImageGenerator: def __init__(self): # Configure multiple providers self.providers = { "laozhang": { "client": self._setup_laozhang_client(), "priority": 1, "cost": 0.01, }, "openai": { "client": self._setup_openai_client(), "priority": 2, "cost": 0.04, }, "azure": { "client": self._setup_azure_client(), "priority": 3, "cost": 0.045, } } async def generate_image(self, prompt, quality="medium"): """Generate image using the optimal provider""" # Sort providers by priority providers = sorted( self.providers.items(), key=lambda x: x[1]["priority"] ) # Try each provider in order for name, provider in providers: try: response = await self._generate_with_provider( provider["client"], prompt, quality ) return { "success": True, "provider": name, "image_url": response.choices[0].message.content, "cost": provider["cost"] } except Exception as e: logging.warning(f"Provider {name} failed: {str(e)}") continue # All providers failed return { "success": False, "error": "All providers failed" }
Solution 5: Usage-Based Strategies for Different Scenarios
Different use cases require tailored approaches to overcome OpenAI's image generation limits. Here are effective strategies based on your specific scenario:
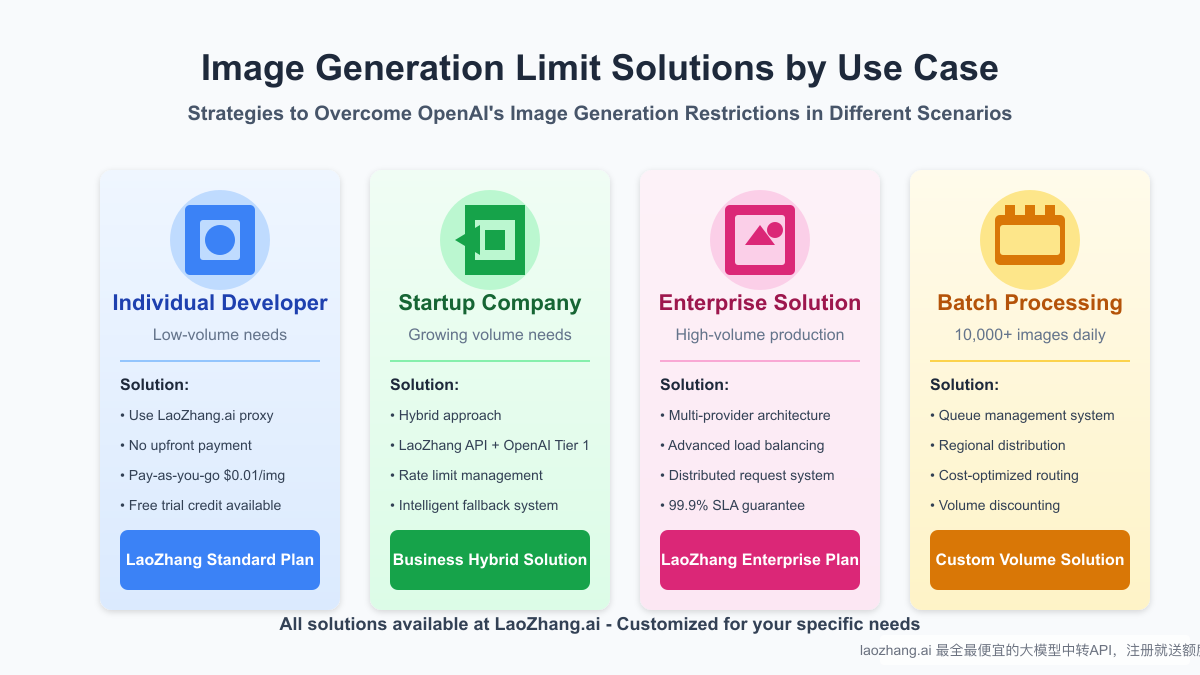
For Individual Developers:
If you're an individual developer with relatively low-volume needs:
- Use LaoZhang.ai's pay-as-you-go model at $0.01 per image
- Take advantage of the free trial credits upon registration
- No need for upfront investment or complex account verification
- Implement basic caching for frequently used image requests
For Startups:
Growing companies with increasing image generation needs should consider:
- Implementing a hybrid approach using both LaoZhang.ai and OpenAI Tier 1
- Setting up intelligent fallback systems between providers
- Optimizing prompt engineering to reduce the number of iterations needed
- Using lower resolution during development and higher resolution for production
For Enterprise Solutions:
Large organizations with high-volume production needs benefit from:
- Multi-provider architecture with advanced load balancing
- Distributed request systems across geographic regions
- Custom SLAs with 99.9% availability guarantees
- Volume-based discounts available through enterprise agreements
For Batch Processing:
When generating 10,000+ images daily:
- Implement a dedicated queue management system
- Use regional distribution to optimize for regional rate limits
- Apply cost-optimized routing based on current provider pricing
- Negotiate volume discounts for consistent, large-scale usage
Implementation Checklist for Developers
To implement these solutions effectively, follow this step-by-step checklist:
Day 1: Immediate Access
- Sign up for LaoZhang.ai proxy service
- Generate and securely store your API keys
- Update your code to use the proxy service
- Test with a small batch of image requests
Week 1: Optimization
- Implement proper error handling
- Set up basic analytics to track usage and costs
- Create a simple caching mechanism for frequent requests
- Begin OpenAI tier progression if needed for your use case
Month 1: Scaling
- Implement multi-provider architecture if needed
- Create a request queueing system for batch processing
- Set up monitoring dashboards to track performance
- Optimize cost efficiency based on initial usage data
Conclusion: Future-Proofing Your Image Generation Workflow
OpenAI's image generation limits present significant challenges, but with the strategies outlined in this guide, developers can ensure uninterrupted access to high-quality AI image generation while optimizing costs.
For most use cases, LaoZhang.ai offers the most practical solution, providing immediate access without tier restrictions at 75% lower cost compared to direct OpenAI API usage. The service maintains compatibility with OpenAI's API structure, making it easy to implement with minimal code changes.
As the AI landscape continues to evolve, maintaining flexibility through multi-provider strategies will ensure your applications remain resilient to future changes in pricing, availability, and features.
Begin implementing these solutions today to overcome OpenAI's image generation limits and unlock the full potential of AI image generation for your projects.
For immediate access to unlimited image generation at $0.01 per image, sign up for LaoZhang.ai at https://api.laozhang.ai/register/ and receive free API credits to start generating high-quality images immediately.
Last updated: June 30, 2025
This guide is regularly updated as OpenAI modifies their limitations and new solutions emerge.