
A fecha de 20 de marzo de 2026, Gemini 3 Flash es la mejor opción si necesitas la vía rápida con más capacidad, sobre todo para coding, workflows agentic y Computer Use. Gemini 3.1 Flash-Lite es la mejor opción si tu prioridad es coste bajo, baja latencia y mucho volumen en tareas como traducción, extracción o routing. Ese es el verdadero sentido de esta búsqueda.
La parte confusa es que Google no publica una tabla oficial única que compare gemini-3-flash-preview contra gemini-3.1-flash-lite-preview como si fueran un duelo limpio. La evidencia está repartida entre pricing, las páginas oficiales de Gemini 3 Flash Preview y Gemini 3.1 Flash-Lite Preview, las release notes, la página de rate limits y los perfiles de DeepMind para Gemini 3 Flash y Gemini 3.1 Flash-Lite.
Por eso esta guía no intenta inventar un ganador absoluto. Lo útil aquí es convertir precio, tooling, batch limits y posicionamiento oficial en una decisión práctica de routing.
Resumen rápido
Si solo quieres la respuesta corta:
- Elige Gemini 3 Flash si valoras más razonamiento, agentic coding, Computer Use y una lane rápida más fuerte.
- Elige Gemini 3.1 Flash-Lite si valoras más precio, throughput y tareas ligeras de mucho volumen.
- Usa ambos si tu stack mezcla trabajos premium y tráfico bulk.
La comparación oficial hoy se resume así:
| Área | Gemini 3.1 Flash-Lite | Gemini 3 Flash | Qué significa |
|---|---|---|---|
| Estado | Preview | Preview | Ninguno es la lane estable por defecto |
| Fecha de lanzamiento | 2026-03-03 | 2025-12-17 | Flash-Lite es más nuevo, no necesariamente más alto de gama |
| Model ID | gemini-3.1-flash-lite-preview | gemini-3-flash-preview | Conviene rutear explícitamente |
| Input estándar | Gratis, luego $0.25 / 1M | Gratis, luego $0.50 / 1M | Flash-Lite cuesta la mitad |
| Output estándar | Gratis, luego $1.50 / 1M | Gratis, luego $3.00 / 1M | Flash-Lite también cuesta la mitad aquí |
| Precio batch | Gratis, luego $0.125 / $0.75 | Sin free batch, luego $0.25 / $1.50 | Flash-Lite es más fuerte para async a gran escala |
| Context window | 1,048,576 tokens | 1,048,576 tokens | No es el punto diferencial |
| Max output | 65,536 tokens | 65,536 tokens | Tampoco |
| Computer Use | No | Sí | Esta es una diferencia real de workflow |
| Search / Maps grounding | Sí, pero sin free-tier grounding | Sí, pero sin free-tier grounding | El grounding no cambia el veredicto principal |
| Mejor encaje | Tareas baratas y masivas | Lane rápida más potente | La diferencia real es de lane, no de nombre |
Por qué esta comparación engaña tanto
El nombre hace pensar que Flash-Lite es simplemente una versión barata de Flash. Las propias páginas oficiales sugieren algo distinto.
Google presenta Gemini 3 Flash como su fast model más fuerte para multimodal understanding, advanced reasoning y agentic coding. En cambio, Gemini 3.1 Flash-Lite está descrito como el modelo más eficiente en coste para tareas ligeras, de alta frecuencia y baja latencia.
Eso cambia toda la lectura:
- Gemini 3 Flash es la lane rápida premium
- Gemini 3.1 Flash-Lite es la lane rápida barata
Si entiendes eso, ya no preguntas "cuál es más nuevo", sino "para qué tipo de tráfico merece la pena pagar más".
Precio, free tier, grounding y batch throughput
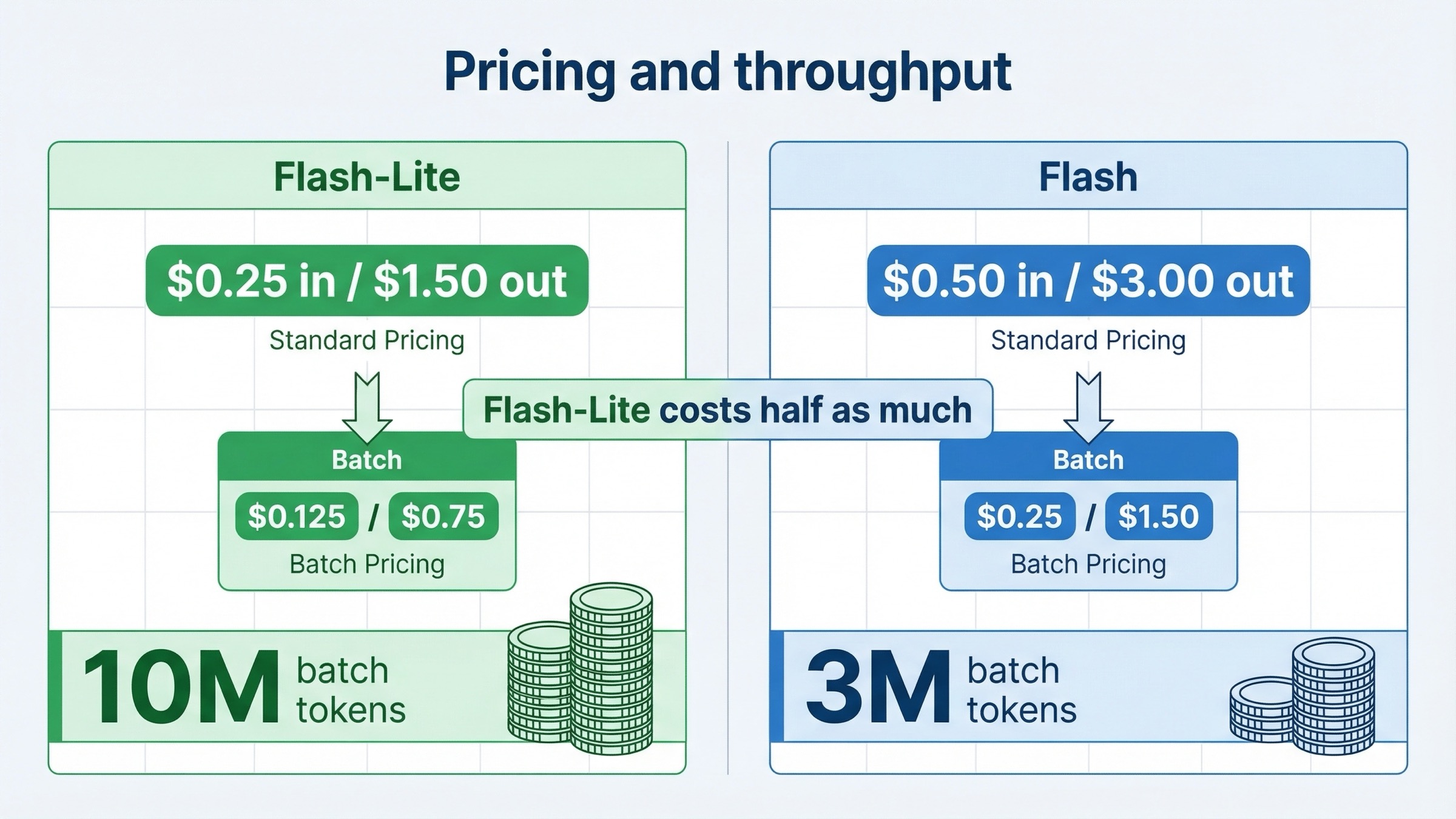
El precio es la diferencia oficial más limpia.
Según la página actual de Gemini Developer API pricing:
- Gemini 3.1 Flash-Lite Preview: free tier, luego
\$0.25input y\$1.50output por 1M tokens - Gemini 3 Flash Preview: free tier, luego
\$0.50input y\$3.00output por 1M tokens
En otras palabras, Gemini 3 Flash cuesta aproximadamente 2 veces más.
Si tu workload está dominado por:
- traducción
- extracción estructurada
- clasificación
- routing
- resúmenes en volumen
- pipelines async masivos
esa diferencia de precio ya empuja claramente a Flash-Lite.
La señal es todavía más fuerte en batch:
- Gemini 3.1 Flash-Lite Batch: free tier, luego
\$0.125input y\$0.75output - Gemini 3 Flash Batch: no free batch, luego
\$0.25input y\$1.50output
Además, la página de rate limits añade una diferencia práctica importante. En la tabla Tier 1 Batch API:
- Gemini 3.1 Flash-Lite Preview:
10,000,000enqueued batch tokens - Gemini 3 Flash Preview:
3,000,000enqueued batch tokens
Eso importa mucho más que muchos benchmarks si tu problema real es throughput.
Sobre grounding, conviene ser preciso. Ambas páginas de modelo muestran Search grounding y Maps grounding como capacidades soportadas. Pero la página de pricing indica hoy que:
- ninguna tiene free-tier grounding
- ambas ofrecen
5,000prompts gratuitos al mes en paid mode antes de cobrar grounding
Así que aquí no hay una ventaja clara de free grounding para ninguna de las dos.
La diferencia de capacidad importa más que el nombre

Donde mucha gente se equivoca no es en el precio, sino en la capacidad.
Los dos modelos comparten varios headline specs:
- output de texto
- inputs de texto, imagen, video, audio y PDF
1,048,576input tokens65,536output tokens- Batch, Function Calling, Structured Outputs, Code Execution y Caching
Si solo miras esa lista, parece que la elección se reduce a pagar más o menos. Pero el verdadero corte está en el workflow.
Gemini 3 Flash soporta Computer Use. Gemini 3.1 Flash-Lite no.
Para quien trabaja con agentes más pesados, browser automation o tool-use real, eso no es una diferencia menor. Es una separación clara entre una lane más completa y otra más barata.
La segunda diferencia es de posicionamiento. Google empuja 3 Flash hacia coding, agentic workflows y reasoning fuerte. Google empuja 3.1 Flash-Lite hacia translation, extraction, routing y tareas ligeras de alto volumen.
Por eso Flash-Lite no debería venderse como reemplazo ciego de 3 Flash. Es mejor entenderlo como una lane de volumen dentro de la familia Gemini 3.
Qué sugieren las páginas oficiales de performance, y qué no prueban
DeepMind tiene páginas oficiales sólidas para ambos modelos:
Son útiles, pero no equivalen a una sola página de benchmark head-to-head para este par exacto.
Además, la model card de 3.1 Flash-Lite advierte que los resultados actuales usan evaluaciones mejoradas y no deben compararse mecánicamente con model cards anteriores. Esa advertencia importa.
Aun así, la lectura direccional es bastante clara:
- Gemini 3 Flash tiene la narrativa oficial de capacidad más fuerte
- Gemini 3.1 Flash-Lite tiene la narrativa oficial de eficiencia de coste más fuerte
Ese es el punto. No se trata de "quién gana en todo", sino de si te compensa pagar por la lane premium.
Qué modelo usar para cada workload
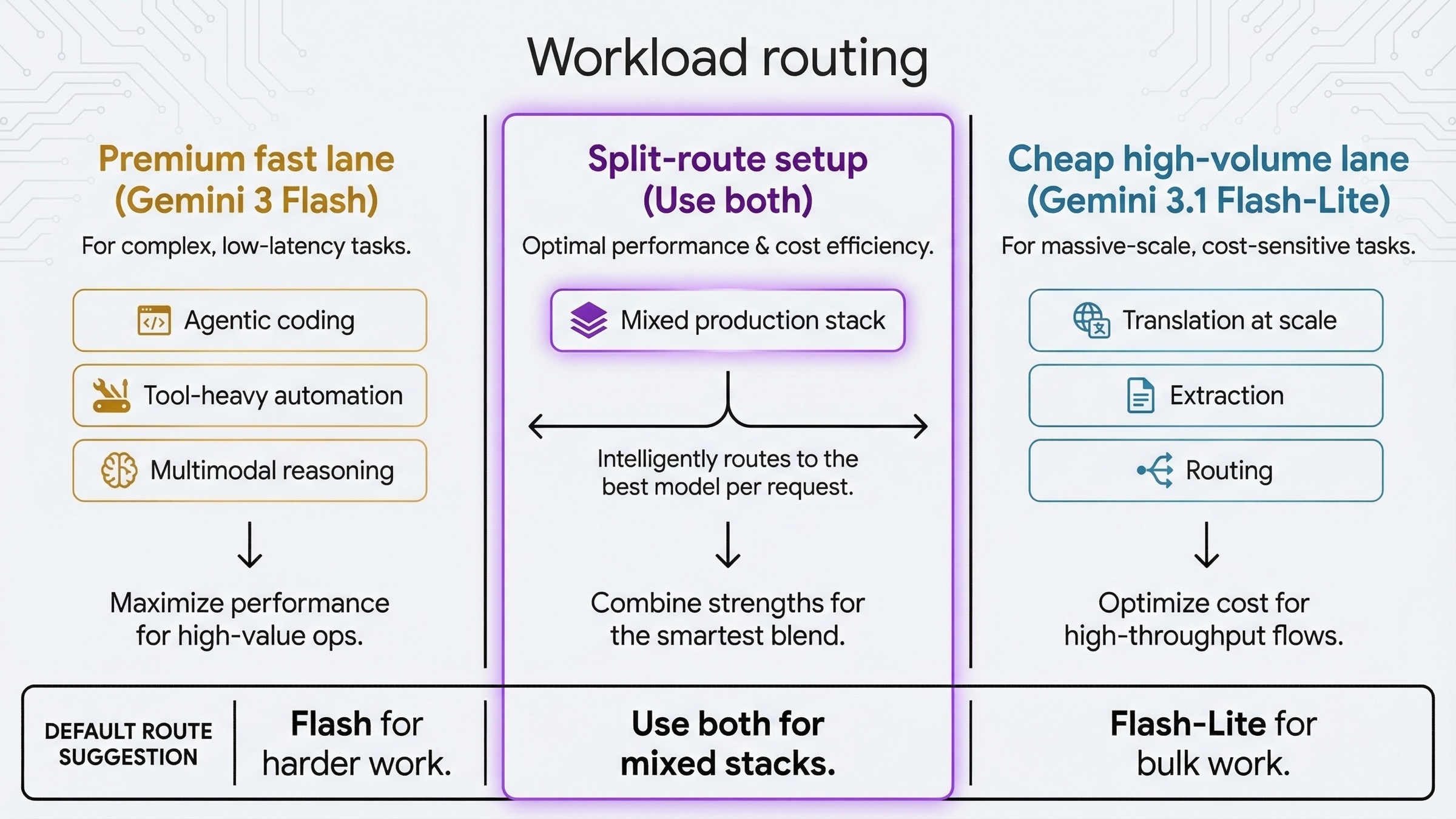
La mejor forma de cerrar la comparación es convertirla en una regla de routing:
| Workload | Elige primero | Motivo |
|---|---|---|
| agentic coding | Gemini 3 Flash | Más capacidad y mejor encaje oficial |
| tool-heavy automation | Gemini 3 Flash | Computer Use marca la diferencia |
| multimodal reasoning más duro | Gemini 3 Flash | Es la lane rápida premium |
| traducción a escala | Gemini 3.1 Flash-Lite | Más barato y mejor alineado con el uso |
| extracción estructurada | Gemini 3.1 Flash-Lite | El coste y el throughput pesan más |
| routing y clasificación | Gemini 3.1 Flash-Lite | Es uno de sus casos más naturales |
| batch async de gran volumen | Gemini 3.1 Flash-Lite | Mejor precio y mayor batch ceiling |
| stack mixto de producción | Ambos | 3 Flash para lo premium, Flash-Lite para el bulk traffic |
Cómo desplegarlo sin arrepentirte después
La respuesta prudente no es "migrar todo a un solo modelo".
La respuesta prudente es:
- Pon Flash-Lite en la lane barata
Mueve traducción, extracción, tagging, routing y otros trabajos bulk a gemini-3.1-flash-lite-preview.
- Reserva 3 Flash para la lane premium
Usa gemini-3-flash-preview para coding, tool-use pesado, Computer Use y reasoning más exigente.
- Evalúa fallos, no solo medias
Como ambos siguen en Preview, no basta con mirar latencia media. Mira también:
- estabilidad de structured outputs
- fiabilidad de tool calling
- drift en contextos largos
- coste por tarea exitosa, no solo por token
Si tu rollout todavía es frágil, te conviene leer también nuestra guía de troubleshooting de Gemini API.
El resumen operativo sería:
- trabajo difícil: 3 Flash
- trabajo bulk: 3.1 Flash-Lite
- producción mixta: ambos
Qué conviene medir antes de convertir uno en tu ruta por defecto
Muchos equipos se equivocan justo aquí. Ven una tabla oficial fuerte o una diferencia de precio clara y convierten esa señal en una migración completa. Para esta pareja de modelos, eso suele ser demasiado agresivo.
Antes de promocionar uno de los dos como ruta por defecto, yo mediría al menos cinco cosas.
Primero, la estabilidad de salidas estructuradas. Si tu sistema depende de JSON, schemas o argumentos de función, no basta con que el texto "suene bien". Hay que mirar cuántas veces falla el formato, cuántas veces faltan campos y cuántos reintentos necesitas para obtener una respuesta usable.
Segundo, la fiabilidad real del tool calling. Que ambos soporten Function Calling no significa que se comporten igual cuando los prompts son largos, cuando hay varias herramientas o cuando hay que recuperarse de un error parcial. En escenarios de agentes, esto importa más que muchas métricas vistosas.
Tercero, el comportamiento en contexto largo. Las dos páginas oficiales muestran la misma context window headline, pero eso no garantiza el mismo rendimiento cuando trabajas con documentos largos, recuperación interna o planificación multietapa.
Cuarto, el coste por tarea exitosa, no solo por token. Un modelo más barato puede salir más caro si obliga a más reintentos, más postprocesado o más fallback. El cálculo real tiene que incluir tiempo, correcciones y tasa de error.
Quinto, la opción split-route. Para esta comparación, la arquitectura más sensata muchas veces no es "elegir uno", sino separar lanes: Gemini 3 Flash para tareas premium y Gemini 3.1 Flash-Lite para tráfico bulk.
Ese checklist no complica la decisión. La vuelve más honesta. Y justamente ahí esta comparativa puede ganarle a la SERP media: no se queda en precio o benchmark; te dice cómo no equivocarte al desplegar.
Por qué un equipo de API y un usuario de la app no toman la misma decisión
Este matiz casi siempre falta en la SERP. Un equipo que integra la API decide según coste por tarea, batch throughput, tool calling, estabilidad de salidas y routing. Un usuario de Gemini app suele decidir por visibilidad del modelo, límites de uso, comportamiento cotidiano y claridad del plan.
Eso significa que Gemini 3.1 Flash-Lite puede ser la mejor lane barata para un backend, aunque no sea la respuesta más intuitiva para alguien que solo mira la app. Y Gemini 3 Flash puede justificar su precio para un pipeline de agentes, aunque desde fuera parezca simplemente "el modelo más caro".
Por eso conviene leer esta comparativa como una guía de routing para API y producción, no como una verdad universal sobre cuál modelo "es mejor" en cualquier contexto.
Qué elegir desde la primera semana
Si tu equipo necesita un default barato para traducción, extracción, tagging, clasificación o tareas repetitivas, el punto de partida más lógico suele ser Gemini 3.1 Flash-Lite. Te permite diseñar la economía del tráfico masivo desde el principio y encaja mejor como lane de volumen que como sustituto universal de todo lo demás.
Si tu prioridad es levantar workflows de agentes con tool use, generación de código y razonamiento más exigente, el primer candidato suele ser Gemini 3 Flash. El precio es más alto, sí, pero en una ruta crítica a veces compensa con menos reintentos, menos degradación y menos sorpresas operativas.
Y si ya sabes que vas a convivir con dos familias de trabajo muy distintas, no pierdas una semana buscando un ganador único. Te conviene más arrancar con split-route: Flash para las tareas premium y Flash-Lite para el bulk traffic. En la práctica, ese diseño suele escalar mejor que una migración total hecha demasiado pronto.
FAQ
¿Gemini 3 Flash es mejor que Gemini 3.1 Flash-Lite?
Sí, si "mejor" significa más capacidad, mejor encaje para agentic coding y soporte para Computer Use. No, si "mejor" significa eficiencia de precio.
¿Gemini 3.1 Flash-Lite es solo una versión barata de Gemini 3 Flash?
No. Es mejor verlo como la lane de alto volumen y bajo coste dentro de la familia Gemini 3.
¿Ambos tienen free tier?
Sí para uso estándar, aunque los detalles de batch, caching y grounding no son idénticos.
¿Ambos soportan grounding?
Sí, pero ninguno ofrece hoy free-tier grounding según la página de pricing.
¿Cuál es mejor para coding?
Gemini 3 Flash.
¿Cuál es mejor para traducción, extracción y routing?
Gemini 3.1 Flash-Lite.
¿Debería reemplazar Gemini 3 Flash por Gemini 3.1 Flash-Lite en todo?
No. Lo sensato es sustituir solo la lane barata y mantener 3 Flash para las tareas premium.