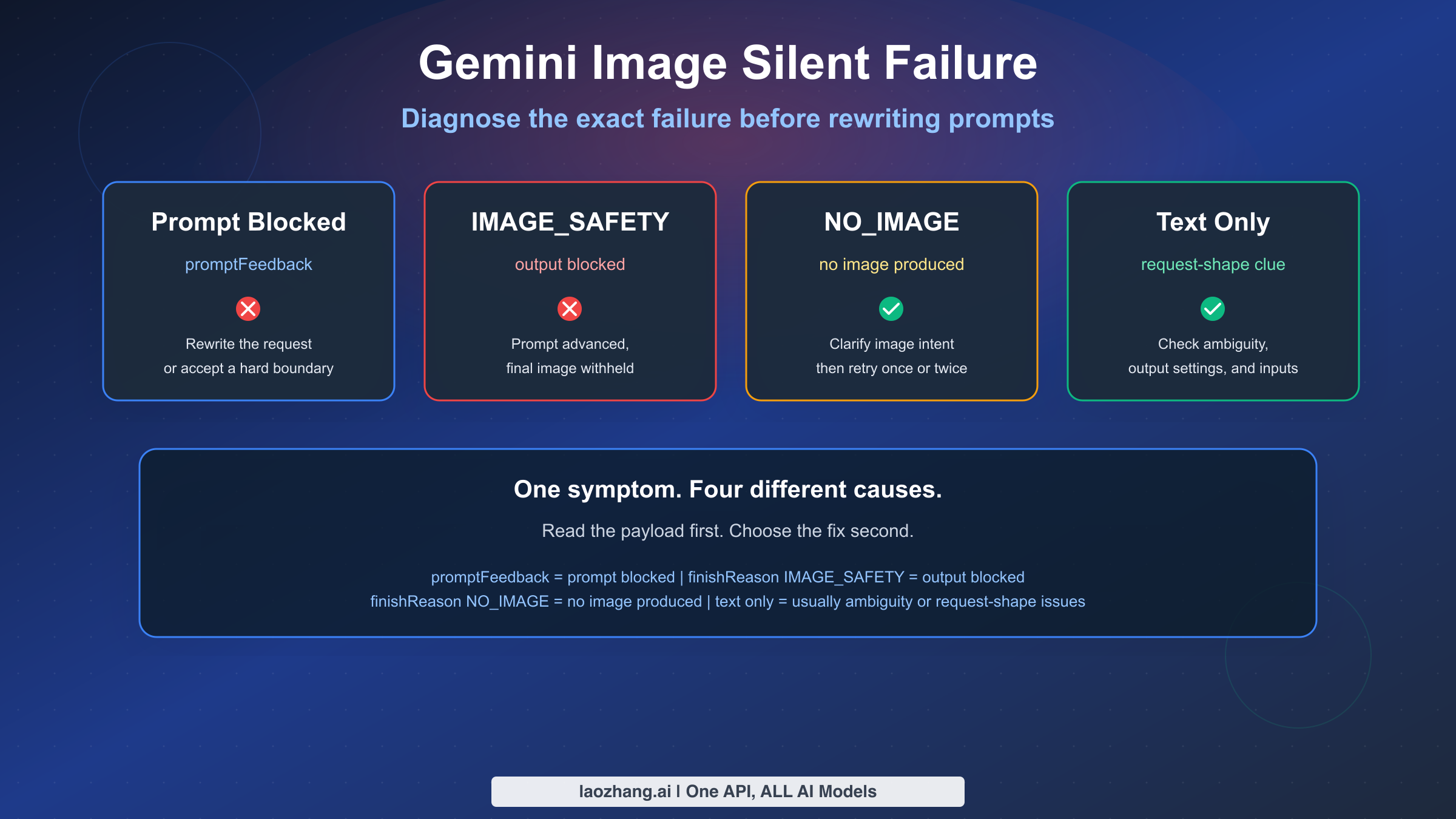
Si la generación de imágenes de Gemini parece fallar silenciosamente, lo más importante que debes entender es que el "fallo silencioso" casi nunca es un único problema. A partir del 15 de marzo de 2026, la documentación actual de Google distingue al menos cuatro estados diferentes que los usuarios suelen agrupar de forma incorrecta: bloqueo del lado del prompt, bloqueo de imagen del lado de salida, ninguna imagen producida en absoluto, y fallos no relacionados con políticas, como prompts ambiguos o errores en la estructura de la solicitud. Si tratas los cuatro casos como "la política de contenido de Gemini está rota", seguirás aplicando la corrección equivocada.
La versión resumida es esta: cuando el prompt de entrada es bloqueado, promptFeedback aparece en la respuesta y candidates no se devuelve. Cuando el prompt es aceptado pero la imagen generada en la salida es bloqueada, Google indica que candidates existe, content está ausente y finishReason explica por qué se detuvo la respuesta. Un finishReason con valor IMAGE_SAFETY no es lo mismo que NO_IMAGE, y ninguno de los dos equivale a una respuesta de solo texto con STOP. Estas diferencias importan porque cada una apunta a un siguiente paso distinto.
Esta guía se centra en los escenarios exactos que las personas buscan con frases como "fallo silencioso de imagen de Gemini", "corrección de IMAGE_SAFETY" y "política de contenido de imágenes de Gemini". Está basada en la documentación actual de Google, no en cobertura obsoleta de 2024 sobre la controversia de generación de personas de Gemini. También utiliza hilos recientes del Foro de Desarrolladores de Google AI de noviembre y diciembre de 2025 para mostrar dónde los fallos del mundo real siguen confundiendo a los usuarios, especialmente cuando AI Studio o la API de Gemini no devuelven ninguna imagen útil aunque el prompt parezca seguro.
Si estás tratando con un problema de rechazo de prompts más amplio que afecta a múltiples modelos, no solo a la salida de imágenes de Gemini, nuestra guía de advertencias de seguridad de prompts bloqueados cubre ChatGPT, Gemini, Claude y Azure a nivel de política. Este artículo es más específico y técnico: trata sobre cómo diagnosticar correctamente los fallos de imágenes de Gemini antes de reescribir prompts, aflojar filtros o asumir que la plataforma está caída.
Resumen rápido
- Inspecciona el payload antes de cambiar el prompt. La presencia de
promptFeedbacksignifica que el prompt fue bloqueado antes de que se completara la generación de imagen. - Si
candidatesexiste perocontentestá ausente yfinishReasonesIMAGE_SAFETY, la imagen de salida fue filtrada después de que comenzara la generación. - Si
finishReasonesNO_IMAGE, Gemini aceptó la solicitud pero no produjo ninguna imagen. Eso generalmente requiere instrucciones de imagen más claras, un reintento o depuración de la estructura de solicitud. - Una respuesta de solo texto no siempre es un fallo de política. La página de limitaciones de generación de imágenes actual de Google dice que los prompts ambiguos pueden devolver texto y ninguna imagen.
- Los ajustes de seguridad configurables no desactivan toda la protección. La documentación de configuración de seguridad de Google indica que las protecciones integradas para daños fundamentales permanecen activas y no pueden desactivarse.
- No trates los fallos 404, 429 y 503 como problemas de política de contenido. Si estás viendo esos códigos, comienza con nuestra guía de códigos de error de Gemini 3 Pro Image.
| Diagnóstico rápido | Verifica esto primero | Significado |
|---|---|---|
| Prompt bloqueado | promptFeedback.blockReason | La solicitud fue filtrada antes de que se devolviera un candidato de imagen utilizable |
| Salida bloqueada | candidates[0].finishReason = IMAGE_SAFETY y content ausente | El prompt avanzó, pero la imagen final fue retenida |
| Ninguna imagen producida | finishReason = NO_IMAGE | Gemini aceptó la solicitud pero no produjo salida de imagen |
| Respuesta de solo texto | Partes de texto sin partes de imagen | Generalmente ambigüedad, configuración de salida o problemas de estructura de solicitud |
Cómo Determinar si Gemini Bloqueó el Prompt, Bloqueó la Imagen o No Generó Nada

La mayor parte del tiempo de depuración se desperdicia saltando la clasificación. Las personas ven "sin imagen", asumen "política de contenido" y luego pasan 20 minutos reescribiendo un prompt que en realidad no era el problema. La documentación de respuestas bloqueadas de Google proporciona un flujo de trabajo más útil: primero inspecciona la estructura de la respuesta y solo entonces decide qué tipo de corrección tiene sentido.
Esta es la forma más rápida de pensarlo:
| Lo que ves | Señal típica de la API | Lo que generalmente significa | Primera corrección |
|---|---|---|---|
| La solicitud falla antes de que aparezca algún candidato utilizable | promptFeedback.blockReason presente y candidates ausente | Bloqueo del lado del prompt antes de que se devuelva la salida de imagen | Reescribe el prompt, añade contexto seguro si es apropiado, o acepta que la solicitud alcanza un límite prohibido |
| Rechazo de texto en lugar de imagen | candidates[0].finishReason = STOP y la respuesta contiene texto en lugar de datos de imagen | El modelo rechazó o redirigió la solicitud de forma segura | Lee el texto, elimina la intención visual sensible o separa la tarea en etapas más seguras |
Sin datos de imagen e IMAGE_SAFETY | candidates existe, content está ausente, finishReason = IMAGE_SAFETY | El prompt fue aceptado, pero la imagen de salida fue filtrada | Reduce el detalle visual sensible, aclara la intención benigna y no asumas que los ajustes de seguridad pueden anular todo |
Sin datos de imagen y NO_IMAGE | finishReason = NO_IMAGE | Gemini no produjo realmente ninguna imagen | Solicita una imagen explícitamente, reduce la ambigüedad, reintenta una o dos veces y verifica la estructura de la solicitud |
| Respuesta de solo texto sin marcador de política obvio | La respuesta contiene texto pero ninguna parte inlineData de imagen | Frecuentemente un prompt ambiguo, una configuración de salida de imagen ausente o un error de transporte | Solicita explícitamente salida de imagen y verifica la configuración de tu solicitud |
| 404, 429 o 503 | Error HTTP en lugar de un candidato de imagen | Problema de enrutamiento del modelo, cuota o sobrecarga, no política de contenido | Usa la guía operativa correcta en lugar de reescribir prompts |
La documentación actual de Vertex AI de Google establece una distinción clara entre el bloqueo del prompt y el bloqueo de la respuesta. Si el propio prompt es bloqueado, promptFeedback aparece en la respuesta y no hay ningún candidato que inspeccionar. Si la respuesta es bloqueada, promptFeedback está ausente, candidates está presente, y el content ausente junto con finishReason te indica qué ocurrió. Por eso un mensaje a nivel de interfaz como "no se pudo generar la imagen" es demasiado impreciso para diagnosticar el problema por sí solo. El payload de la API suele ser más informativo que el texto del producto.
Esto también explica por qué algunos usuarios llaman al problema "silencioso". El payload puede no ser silencioso, pero la superficie que están usando puede aún sentirse silenciosa. En AI Studio, la aplicación Gemini o una capa de integración delgada, el producto puede mostrar un error genérico o ningún espacio para imagen en absoluto. Si puedes reproducir la solicitud a través de la API o Vertex e inspeccionar la respuesta completa, a menudo descubres si el sistema bloqueó el prompt, bloqueó la imagen o simplemente nunca produjo ninguna.
Si solo tienes síntomas de AI Studio o de la aplicación sin payload sin procesar, usa esta secuencia de respaldo rápida antes de escalar:
- Inicia una sesión nueva y pregunta explícitamente: "Genera una imagen de..." en lugar de enviar una frase nominal corta.
- Prueba con un prompt de prueba benigno pequeño, como "Genera una imagen de una taza de cerámica roja sobre una mesa de madera."
- Si la prueba benigna funciona, el prompt original o el contexto del chat anterior es probablemente la causa.
- Si la prueba benigna también falla, verifica si la misma solicitud funciona a través de la API o Vertex, o trata el problema como un fallo de la superficie del producto en lugar de un problema exclusivo del prompt.
Para equipos, este paso de clasificación debería convertirse en una práctica invariable. Nunca registres solo "falló la generación de imagen". Registra el ID del modelo, la superficie de la solicitud, si promptFeedback existía, si candidates existía, el finishReason final, si se devolvieron partes de imagen inlineData y la marca de tiempo UTC exacta. Sin esos datos, los errores de política, las regresiones de lanzamiento y la ambigüedad ordinaria del prompt tienen el mismo aspecto en la revisión de incidentes.
Qué Significan Realmente IMAGE_SAFETY, NO_IMAGE y STOP
La referencia de la API de Gemini actual de Google es inusualmente importante para este tema porque indica qué enums pertenecen al bloqueo del prompt y cuáles pertenecen a la finalización de candidatos. Esa distinción es la base de un diagnóstico correcto.
El bloqueo del lado del prompt utiliza valores de BlockReason. Según la referencia oficial actualizada por última vez el 12 de enero de 2026, estos incluyen SAFETY, BLOCKLIST, PROHIBITED_CONTENT e IMAGE_SAFETY. La finalización del lado del candidato utiliza valores de FinishReason. Para casos de uso de imagen, los más importantes son IMAGE_SAFETY, IMAGE_PROHIBITED_CONTENT, IMAGE_OTHER, NO_IMAGE e IMAGE_RECITATION. Aunque las palabras puedan parecer similares, no significan lo mismo en el mismo lugar.
Comencemos con STOP, porque es el que más confunde a las personas. En la página de IA responsable de Gemini para generación de imágenes de Google, se explica que una solicitud de imagen potencialmente insegura puede producir un rechazo de texto con FinishReason = STOP. En otras palabras, el sistema puede no estar diciendo "error de filtro". Puede estar diciendo "no voy a crear esa imagen" en texto normal del modelo. Por eso las respuestas de solo texto deben leerse, no ignorarse.
IMAGE_SAFETY es diferente. Cuando ves finishReason = IMAGE_SAFETY, la solicitud llegó más lejos que un bloqueo de prompt. Google documenta esto como una parada de seguridad del lado de la salida. El prompt fue aceptado lo suficiente como para producir un registro de candidato, pero el contenido de la imagen final fue retenido. Por eso muchos usuarios sienten que Gemini "empezó y luego falló silenciosamente". En la práctica, el candidato de imagen existe conceptualmente, pero el contenido no fue liberado.
NO_IMAGE es diferente también. No significa automáticamente "política". Significa que no se produjo ninguna imagen. Eso puede ocurrir porque la solicitud era ambigua, porque el modelo eligió comportamiento de texto en lugar de imagen, porque un intento de generación no se completó de forma útil, o porque algo en la estructura de la solicitud o el transporte impidió una respuesta de imagen válida. La página de limitaciones de generación de imágenes actual de Google dice explícitamente que Gemini puede crear texto y ninguna imagen cuando el prompt es ambiguo, y que el modelo puede detenerse antes de terminar. Esas son correcciones operativas, no interpretaciones de política.
IMAGE_OTHER es el enum menos satisfactorio porque es amplio. En la práctica, trátalo como un depósito general que te indica que la solicitud no terminó en una salida de imagen normal y que el siguiente paso inmediato es inspeccionar el contexto: redacción del prompt, superficie del modelo, payload de la solicitud, número de imágenes de referencia y si el problema es reproducible entre regiones o sesiones. Es una razón para registrar más contexto, no una razón para hacer suposiciones a ciegas.
IMAGE_PROHIBITED_CONTENT es más fuerte que IMAGE_SAFETY. Apunta hacia una categoría prohibida, no simplemente hacia una clasificación de seguridad ajustable. La guía de filtros de seguridad de Vertex de Google establece el punto más amplio de que algunas categorías no son configurables, especialmente cuando se trata de material prohibido. Si te encuentras con IMAGE_PROHIBITED_CONTENT, no debes pensar en términos de "¿cómo hago para que esto pase?". Debes pensar en términos de "esta solicitud está cruzando una línea de política".
Un detalle sutil pero importante: la misma etiqueta puede aparecer en diferentes capas. IMAGE_SAFETY puede aparecer en BlockReason del lado del prompt y en FinishReason del lado del candidato. Por eso no puedes diagnosticar solo a partir del texto del enum. Necesitas saber dónde apareció. ¿El modelo devolvió alguna vez un candidato? ¿Estaba promptFeedback presente en la respuesta? ¿Faltaba content? Esas pistas estructurales importan más que la palabra por sí sola.
La regla práctica es simple:
promptFeedbackpresente: empieza con la clasificación del lado del prompt.finishReason = STOP: lee el texto de rechazo y trátalo como un rechazo del modelo.finishReason = IMAGE_SAFETY: trátalo como filtrado de salida.finishReason = NO_IMAGE: trátalo como aceptado-pero-sin-imagen-producida hasta que se demuestre lo contrario.
Ese marco resolverá más casos que cualquier consejo genérico de "reescribe tu prompt".
Correcciones Rápidas para Respuestas de Solo Texto y Otros Fallos Silenciosos no Relacionados con Políticas
La página de limitaciones de generación de imágenes de Gemini actual de Google es la página oficial más útil para esta sección porque confirma algo que muchos desarrolladores solo aprenden por ensayo y error: algunos resultados sin imagen no son rechazos de política en absoluto. Son problemas de estructura de generación. Si te saltas esta sección y vas directamente al ajuste de política, vas a diagnosticar mal muchos fallos.
La primera corrección es vergonzosamente simple pero funciona sorprendentemente a menudo: solicita explícitamente una imagen. Si tu prompt parece análisis, lluvia de ideas o redacción de títulos, Gemini puede devolver texto. La propia redacción de Google dice que el modelo podría crear solo texto sin imagen si el prompt es ambiguo. Así que en lugar de decir "Una tranquila fachada japonesa al atardecer", di "Genera una imagen de una tranquila fachada japonesa al atardecer, estilo fotografía cinematográfica, composición 16:9". Esa instrucción adicional puede cambiar la selección de modo del modelo.
La segunda corrección es verificar que realmente solicitaste salida de imagen de la manera que tu SDK espera. Diferentes SDK nombran el mismo campo de manera ligeramente diferente, pero la idea es la misma: solicita salida de imagen, no simplemente una finalización multimodal genérica. Si estás usando el nuevo SDK de Gemini y olvidas la modalidad de respuesta de imagen, el modelo puede seguir respondiendo con texto porque desde su perspectiva hiciste una pregunta general de generación de contenido, no una pregunta estricta de generación de imagen.
Aquí hay un ejemplo mínimo de Python que hace explícita la intención de imagen:
pythonfrom google import genai from google.genai import types client = genai.Client(api_key="YOUR_API_KEY") response = client.models.generate_content( model="gemini-2.5-flash-image", contents="Genera una imagen de una taza de café de cerámica sobre un escritorio de nogal, luz suave de mañana, foto de producto editorial.", config=types.GenerateContentConfig( response_modalities=["IMAGE"] ) )
Si tu respuesta es de solo texto, no te detengas en "Gemini está roto". Inspecciona las partes que regresaron. Si solo recibiste partes de texto y ningún inlineData, estás mirando un problema de selección de modo o de estructura de solicitud hasta que el payload demuestre lo contrario.
La tercera corrección es reintentar las generaciones incompletas de manera disciplinada. La página de limitaciones de generación de imágenes de Google, actualizada por última vez el 14 de marzo de 2026, dice que el modelo podría dejar de generar contenido incluso cuando no ha terminado y recomienda específicamente reintentar o cambiar el prompt. Eso no es un permiso para reintentar ciegamente 30 veces. Significa que un pequeño número de reintentos controlados es razonable cuando el payload sugiere una generación incompleta en lugar de una parada de política. En la práctica, un reintento inmediato y un reintento con el prompt ajustado son suficientes para saber si el fallo es transitorio.
La cuarta corrección es reducir la ambigüedad creada por tareas mixtas. Muchos prompts que fallan piden a Gemini que analice, resuma, compare y genere una imagen todo en un turno. Eso aumenta la probabilidad de una respuesta de texto primero, especialmente en integraciones estilo chat. Separa estas tareas. Si necesitas que el modelo entienda una imagen y luego genere una nueva, haz primero el paso de razonamiento y el paso de generación después. Cuanto más orientada a un único propósito sea la solicitud, más fácil es diagnosticar cuando algo sale mal.
La quinta corrección es examinar cómo se envían las entradas de imagen. Un hilo útil del foro del 3 de noviembre de 2025 informó que la edición imagen-a-imagen funcionaba con inlineData pero devolvía solo texto cuando la solicitud usaba fileData de una manera específica. El respondedor del foro de Google mostró un patrón de carga que funcionaba, y el autor original posteriormente confirmó que el flujo funcionó. La conclusión no es "nunca uses archivos". La conclusión es que el transporte de la solicitud puede cambiar el comportamiento, y un resultado de solo texto no significa automáticamente política de contenido. Si fileData falla e inlineData funciona con el mismo prompt benigno, probablemente estás tratando con un problema de integración, no con un veredicto de moderación.
La sexta corrección es respetar los límites documentados de entrada de imagen. La página de limitaciones actual de Google dice que Gemini 2.5 Flash Image funciona mejor con un máximo de 3 imágenes de entrada, mientras que Gemini 3 Pro Image debería mantenerse en 14 imágenes de entrada o menos. Si introduces demasiadas referencias en una solicitud, el sistema se vuelve más difícil de interpretar y de depurar. Incluso si no se alcanza el límite estricto, las pilas de referencias complejas aumentan la probabilidad de salidas malformadas o inutilizables. Para la clasificación de fallos silenciosos, menos imágenes de referencia facilitan la reproducción.
La séptima corrección es verificar la capa operativa obvia antes de revisar el contenido. Si el mismo prompt y payload exactos funcionaron ayer y ahora fallan con 404, 429 o 503, no estás ante un cambio de política de contenido. Estás ante enrutamiento, cuota o capacidad. Por eso recomendamos combinar este artículo con nuestra guía del canal estable de Gemini 3 Pro Image cuando el problema parece sistémico en lugar de específico del prompt.
Finalmente, no ignores la cronología. Si un prompt seguro de repente deja de funcionar en una ventana de tiempo estrecha y varios usuarios del foro reportan síntomas similares, eso es una pista de regresión. Un hilo del Foro de Desarrolladores de Google AI del 25 de noviembre de 2025 describió flujos de trabajo de fotos benignas que fallaban con poca o ninguna explicación de política y luego se recuperaban parcialmente en aproximadamente 48 horas. Eso no es una prueba para todos los casos, pero es un recordatorio de que el comportamiento de la plataforma cambia con el tiempo. A veces la corrección correcta no es "inventa un eufemismo mejor". Es "registra la marca de tiempo exacta, crea una reproducción mínima y verifica si la regresión es más amplia que tu cuenta".
Correcciones Rápidas para IMAGE_SAFETY y Bloqueos de Prompts que Permanecen Dentro de la Política
Esta sección es donde muchos consejos en línea se vuelven descuidados. Decirle a los usuarios que "eviten la seguridad de Gemini" es tanto una mala orientación como algo inconsistente con la Política de Uso Prohibido de IA Generativa de Google, que prohíbe explícitamente los intentos de eludir las protecciones contra abusos o los filtros de seguridad. La pregunta correcta no es "¿cómo esquivo los filtros?" La pregunta correcta es "¿cómo expreso una solicitud legítima con suficiente claridad para que Gemini pueda clasificarla correctamente?"
Comienza con contexto benigno, no con palabras codificadas. Si tu prompt es realmente para comercio electrónico, trabajo de catálogo, educación médica o una escena histórica, di eso directamente. No reemplaces términos sensibles con eufemismos y esperes que el modelo adivine tu intención benigna. El contexto directo pero seguro generalmente funciona mejor que el lenguaje de evasión inteligente porque el modelo tiene más señal para la clasificación.
Por ejemplo, si estás editando imágenes de moda o de producto, evita prompts vagos como "hazlo más sexy" o "ambiente adulto", que pueden arrastrar una solicitud benigna hacia una interpretación sexualmente explícita. Una versión más segura y clara sería algo así: "Crea una foto de comercio electrónico de estudio de un sujetador deportivo de algodón beis sobre un fondo blanco sin costuras, iluminación de catálogo, sin modelo, sin énfasis en la pose, estilo de producto de venta minorista". La segunda versión sigue siendo comercialmente útil, pero elimina muchas señales ambiguas que pueden empujar la solicitud hacia IMAGE_SAFETY.
Si estás trabajando en un caso de uso médico, de seguridad o histórico legítimo, mueve el objetivo más cerca de la explicación y más lejos de la representación gráfica. Las solicitudes que piden explícitamente sangre, detalles de lesiones, humillación o encuadre erótico son mucho más difíciles de defender como benignas incluso si tu proyecto más amplio es legítimo. Cuando sea posible, pide diagramas, ilustraciones no gráficas, diseños educativos etiquetados o visuales de proceso antes/después en lugar de daño fotorrealista.
Un segundo patrón de reescritura benigna fuera de la moda es reemplazar la ambigüedad a nivel de escena con audiencia y formato. En lugar de pedir "una escena de lesión de protesta de la historia", que puede colapsar hacia una clasificación de violencia, prueba con "Crea una ilustración educativa no gráfica para un panel de museo sobre la historia de los derechos civiles de los años 60, estilo póster, sin heridas visibles, enfoque en carteles de multitud y barreras policiales". Ese tipo de reescritura no promete aprobación, pero le da al modelo un objetivo de salida más seguro y claro que una solicitud vaga de escena dramática.
Los bloqueos del lado del prompt y las paradas de IMAGE_SAFETY del lado de la salida necesitan modelos mentales ligeramente diferentes. Cuando el propio prompt es bloqueado, el sistema te está diciendo que la solicitud no debería avanzar tal como está planteada. Cuando el prompt es aceptado pero la imagen final es bloqueada, el sistema te está diciendo que el resultado visual generado cruzó un límite aunque el texto de entrada no fue rechazado en la puerta. La respuesta práctica en ambos casos es eliminar señales visuales ambiguas o sensibles, pero el bloqueo del lado de la salida especialmente se beneficia de reducir el realismo, bajar el encuadre sensual, eliminar detalles de énfasis corporal o replantear la escena alrededor del objeto no sensible en lugar del visual de caso límite.
Aquí hay patrones de reescritura de prompts seguros que generalmente ayudan sin derivar hacia la evasión:
| Patrón arriesgado | Por qué causa problemas | Patrón de reescritura más seguro |
|---|---|---|
| Encuadre adulto o sensual vago | El modelo tiene que adivinar si la solicitud es erótica o comercial | Especifica catálogo, estudio, editorial, sin maniquí, sin énfasis en pose o encuadre solo de producto |
| Detalles de violencia gráfica | Incluso proyectos legítimos pueden leerse como generación de visual dañino | Solicita un diagrama no gráfico, ilustración sin secuelas o diseño educativo |
| Análisis y generación mezclados | Gemini puede devolver texto o un rechazo en lugar de un flujo limpio de imagen | Separa la planificación en un turno y la generación de imagen en un segundo turno |
| Prompt mínimo con sustantivos emocionalmente cargados | Los prompts cortos dan al sistema de seguridad poco contexto benigno | Añade sujeto, entorno, iluminación, propósito, audiencia y estilo en lenguaje sencillo |
Otra corrección importante es aislar la tarea de imagen del contexto de conversación circundante. En chats largos, el modelo ve más que tu última línea. Si los turnos anteriores discutieron violencia, sexualidad, trauma, crimen o temas sensibles a la seguridad, una solicitud de imagen posterior puede heredar ese contexto. Si un prompt inesperadamente comienza a fallar, prueba una sesión nueva con solo la instrucción exacta de generación de imagen y la imagen fuente mínima requerida. Esta es una de las formas más limpias de distinguir la contaminación de contexto de un límite de política estricto.
También recuerda que "funcionó antes" no es lo mismo que "siempre debería funcionar". La evidencia de la comunidad del 24 de diciembre de 2025 muestra que prompts legítimos de ropa interior para comercio electrónico aún podían terminar en IMAGE_SAFETY en Vertex AI Studio, incluso después de que el usuario dijera que los ajustes de contenido sexual configurable estaban relajados. Eso no significa que los documentos de Google estén equivocados. Significa que el filtrado del lado de la salida aún puede anular lo que un usuario espera que cubran los ajustes configurables. La postura correcta del artículo no es "Google ignora sus propios controles". La postura correcta es "los ajustes configurables existen, pero las protecciones integradas y a nivel de salida aún pueden decidir que la imagen no debe ser devuelta".
Si tu caso de uso está claramente dentro de una categoría prohibida, detente ahí. Los límites de política de Google no están para ser sorteados con ingeniería de prompts. Si tu caso de uso es legítimo y sigue siendo bloqueado, documenta el modelo exacto, la región, la fecha, la señal del payload y el prompt desensibilizado, luego escala con esa información. La precisión es más útil que diez intentos más de reescritura.
Qué Pueden Cambiar los Ajustes de Seguridad de Gemini y Qué No

Esta es la sección donde muchas páginas de clasificación se quedan a medias y por lo tanto se vuelven engañosas. Sí, Gemini tiene ajustes de seguridad configurables. No, eso no significa que todos los rechazos de imagen sean ajustables.
La documentación de configuración de seguridad actual de Google, actualizada por última vez el 15 de enero de 2026, dice que las categorías ajustables cubren cuatro áreas: acoso, discurso de odio, contenido sexualmente explícito y contenido peligroso. Eso suena amplio, pero la misma página también dice que existen protecciones integradas contra daños fundamentales que no se pueden ajustar en absoluto. En términos sencillos, puedes ajustar algunos filtros, pero no puedes desactivar todo el sistema de seguridad.
La misma página oficial también dice que si no estableces explícitamente un umbral, el umbral de bloqueo predeterminado es Off para los modelos Gemini 2.5 y 3. Este detalle importa porque muchos tutoriales más antiguos aún dicen a los usuarios que establezcan el umbral más permisivo manualmente solo para que la generación de imagen básica funcione. Según el estado actual de la documentación, esa suposición está desactualizada. Si no estás viendo el resultado que quieres, la causa frecuentemente no es "olvidaste relajar los umbrales". Es más probable que sea un prompt ambiguo, filtrado del lado de la salida o una protección no ajustable.
Usa la tabla de superficies de control a continuación como verificación de la realidad:
| Superficie de control | Qué puedes cambiar | Qué no puedes cambiar | Error común |
|---|---|---|---|
| Ajustes de seguridad de la API de Gemini | Umbrales para acoso, discurso de odio, contenido sexualmente explícito y contenido peligroso | Protecciones integradas para daños fundamentales | Asumir que BLOCK_NONE desactiva todo |
| Filtros de seguridad de Vertex AI | Umbrales de daño y algunos comportamientos de manejo de filtros dependiendo de la superficie | Categorías de contenido prohibido no configurables | Tratar cada imagen bloqueada como un error de umbral |
| Configuración de interfaz de usuario del producto en herramientas como AI Studio | Alternadores de conveniencia o valores predeterminados específicos de la superficie | Límites de política a nivel de plataforma subyacente | Asumir que las etiquetas de la interfaz se corresponden 1:1 con el comportamiento bruto de la API |
| Reescritura de prompts | Contexto, especificidad, encuadre benigno, énfasis visual | Solicitudes prohibidas por política | Confundir claridad con evasión |
La documentación de seguridad de Vertex AI de Google añade otro matiz importante: los códigos de rechazo de prompts pueden incluir PROHIBITED_CONTENT, y las respuestas bloqueadas pueden terminar en razones de finalización relacionadas con la seguridad mientras el contenido bloqueado en sí es retenido. Eso significa que hay capas en la aplicación. Una solicitud puede fallar por una categoría configurable, una categoría no configurable, o la propia salida generada final. Si solo estás mirando un control, estás viendo solo una parte del sistema.
Esta es la forma correcta de hablar sobre BLOCK_NONE u otros umbrales permisivos en 2026: pueden reducir el bloqueo configurable adicional para ciertas categorías, pero no son un control maestro para todo el comportamiento de seguridad de imagen. Si ves una solicitud legítima que sigue devolviendo IMAGE_SAFETY, eso no es automáticamente evidencia de una configuración rota. Puede simplemente significar que el clasificador a nivel de salida o una protección integrada aún decidió no liberar la imagen.
Para equipos que construyen flujos de producto sobre Gemini, la implicación de ingeniería es clara. Trata los ajustes de seguridad como una entrada al sistema, no como todo el sistema. Construye registros y UX que puedan explicar "Esta solicitud alcanzó un bloqueo de seguridad de imagen del lado de la salida", no simplemente "La generación falló". Cuanto más con precisión nombre tu producto el fallo, menos probable es que los usuarios asuman que tu aplicación es poco confiable o deshonesta.
Los Fallos de API, AI Studio, Vertex AI y la Aplicación No Son Idénticos
Muchos artículos deficientes hablan de "Gemini" como si hubiera una superficie de producto universal única. No es así. La misma familia de modelos subyacente puede sentirse muy diferente dependiendo de si estás usando la API de Gemini sin procesar, Vertex AI, AI Studio o la aplicación de consumo Gemini.
La API sin procesar y Vertex AI son los mejores lugares para depurar porque te permiten inspeccionar la estructura del payload. Puedes ver promptFeedback, candidates, content ausente y finishReason. Por eso el diagnóstico técnico debería comenzar allí siempre que sea posible. Si solo estás usando una capa de interfaz de usuario, estás depurando a partir de síntomas en lugar de evidencia.
AI Studio se encuentra en el medio. Está lo suficientemente cerca de la plataforma como para ser útil, pero sigue siendo una superficie de producto con sus propias elecciones de UX, cadencia de lanzamiento y regresiones ocasionales. Por eso dos personas pueden reportar "Gemini falló silenciosamente" cuando solo una de ellas en realidad está alcanzando un bloqueo de política. La otra puede estar alcanzando un error de estructura de solicitud, una regresión del producto o un comportamiento específico de la superficie que la API haría más claro.
La aplicación de consumo Gemini está incluso más alejada del payload. La disponibilidad de la aplicación, los derechos del plan, el estado de lanzamiento de características y los límites a nivel de interfaz de usuario pueden afectar si la creación de imagen parece funcionar. Si estás depurando un flujo de trabajo serio, no te fíes solo de los síntomas de la aplicación. Reproduce a través de la API o AI Studio cuando sea posible para poder ver si el problema es política, capacidad o comportamiento de la superficie del producto.
La disponibilidad de región y modelo también complica el panorama. Un hilo de la comunidad del 20 de abril de 2025 informó que cambiar a la ubicación del servidor us resolvió un error de no-encontrado de gemini-2.0-flash-exp-image-generation. Eso no es un problema de política de contenido, pero los usuarios a menudo lo experimentan como "las imágenes de Gemini no funcionan". La lección es más amplia que el modelo experimental específico: la región, el enrutamiento y el estado de implementación pueden imitar fallos de política en la percepción del usuario.
Lo mismo ocurre con la cuota y la sobrecarga. Un usuario que alcanza 429 o 503 aún puede describir el resultado como "no se generó nada". Si tus registros muestran agotamiento de cuota o indisponibilidad del servicio, deja de pensar en política de contenido. Comienza con cuota y capacidad. Los cubrimos por separado en nuestra guía de límites de velocidad de la API de Gemini y en el artículo de códigos de error de imagen de Gemini mencionado anteriormente.
La mejor práctica para los equipos de soporte es hacer tres preguntas antes de sugerir cualquier corrección del prompt:
- ¿Qué superficie estás usando: API, Vertex AI, AI Studio o aplicación?
- ¿Tienes el payload sin procesar o solo un mensaje de la interfaz de usuario?
- ¿El fallo es reproducible con un prompt benigno mínimo en una sesión nueva?
Esas tres preguntas separan la mitad de los tickets falsos de "política de contenido" de los verdaderos falsos positivos de seguridad.
Flujo de Trabajo de Solución de Problemas Reutilizable
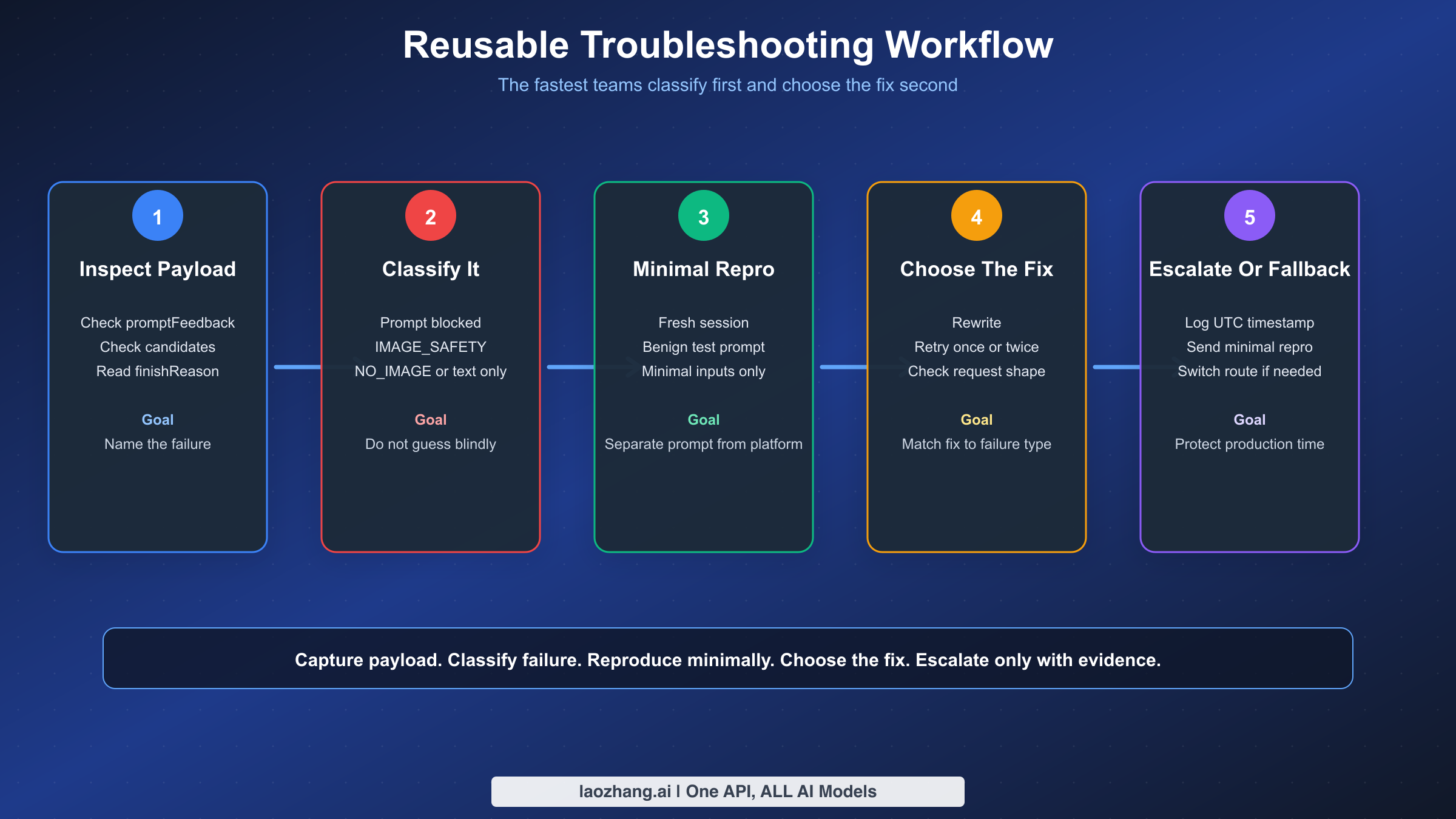
Una vez que la generación de imágenes de Gemini importa a un flujo de trabajo real, necesitas un proceso repetible en lugar de intuición. Los equipos más rápidos no son los que tienen los mejores trucos de prompt. Son los que clasifican los fallos de manera consistente y recopilan suficiente evidencia para distinguir los problemas de prompt de los problemas de plataforma.
Comienza con un clasificador pequeño en los registros de tu aplicación. Esto no es teoría elegante. Es higiene operativa.
pythondef classify_gemini_image_result(resp): if getattr(resp, "prompt_feedback", None): return { "kind": "prompt_blocked", "block_reason": getattr(resp.prompt_feedback, "block_reason", "UNKNOWN"), } candidates = getattr(resp, "candidates", None) or [] if not candidates: return {"kind": "no_candidates"} candidate = candidates[0] finish_reason = getattr(candidate, "finish_reason", "UNKNOWN") content = getattr(candidate, "content", None) parts = getattr(content, "parts", None) if content else None has_inline_image = False has_text = False if parts: for part in parts: if getattr(part, "inline_data", None): has_inline_image = True if getattr(part, "text", None): has_text = True return { "kind": "candidate_returned", "finish_reason": finish_reason, "has_inline_image": has_inline_image, "has_text": has_text, "content_missing": content is None, }
El código no necesita ser sofisticado. Solo necesita responder seis preguntas cada vez:
- ¿Estaba
promptFeedbackpresente? - ¿Se devolvieron
candidates? - ¿Cuál fue el
finishReasonfinal? - ¿Faltaba
content? - ¿Regresaron partes de imagen
inlineData? - ¿El modelo devolvió texto en lugar de una imagen?
Una vez que tienes esa clasificación, el resto del flujo de trabajo se vuelve mucho más confiable.
| Si ves | Haz esto a continuación | No hagas esto |
|---|---|---|
promptFeedback con una razón de bloqueo | Revisa la semántica del prompt y su adecuación a la política | Seguir reintentando exactamente el mismo prompt a ciegas |
finishReason = IMAGE_SAFETY | Reduce el detalle visual sensible y verifica que el caso de uso sea claramente benigno | Asumir que los umbrales de seguridad anularán todo |
finishReason = NO_IMAGE | Haz explícita la intención de imagen, simplifica el prompt, reintenta una vez e inspecciona la estructura de la solicitud | Tratarlo como un bloqueo garantizado de política de contenido |
| Respuesta de solo texto | Lee la respuesta, confirma la configuración de salida de imagen y separa las tareas mixtas | Concluir que el modelo ignoró tu prompt a propósito |
| 404, 429 o 503 | Pasa a la solución de problemas de enrutamiento, cuota o capacidad | Dedicar una hora a reescribir términos de política de contenido |
Aquí está el flujo de trabajo que recomendamos en producción:
- Captura el payload de respuesta sin procesar, no solo la cadena de error visible al usuario.
- Clasifica el fallo usando los campos estructurales anteriores.
- Reproduce con un prompt benigno mínimo en una sesión nueva.
- Si el prompt benigno mínimo funciona, el problema probablemente es la redacción del prompt o el contexto del chat.
- Si el prompt benigno mínimo falla de la misma manera, inspecciona la estructura de la solicitud, la región, el ID del modelo y el estado actual de la plataforma.
- Si el comportamiento cambió de repente en el mismo payload, registra la hora UTC exacta y la superficie para la escalada.
- Solo después de la clasificación debes decidir si reescribir, reintentar, esperar o cambiar de ruta.
También registra las variables que realmente ayudan en el análisis de causa raíz:
- ID del modelo
- superficie utilizada
- región o endpoint
- número de imágenes de referencia
- si las entradas eran
inlineDatao archivos - si se solicitó la modalidad de salida de imagen
- hash del prompt
- marca de tiempo UTC
- versión del SDK o versión del cliente
Esos datos te salvarán cada vez que aparezca una regresión. Cuando el soporte pregunte "¿puedes reproducirlo?", ya lo sabrás. Cuando un hilo del foro sugiera un error de lanzamiento, sabrás si tus fallos se alinean por fecha y superficie. Y cuando un fallo resulte ser un simple problema de estructura de solicitud, no perderás una semana llamándolo un problema de seguridad.
Cuándo Esperar, Escalar o Usar una Ruta de Respaldo
No todos los fallos merecen la misma respuesta. Algunos merecen una reescritura del prompt. Algunos merecen un reintento. Algunos merecen escalada. Y algunos merecen un respaldo arquitectónico para que tu producto siga funcionando incluso cuando el comportamiento de imagen de Google cambia.
Espera y reintenta cuando la evidencia apunta a una generación incompleta en lugar de un bloqueo firme. La página de limitaciones de imagen de Google dice explícitamente que la generación puede detenerse antes de terminar. Eso es luz verde para una estrategia de reintento limitada. La versión correcta de esto es controlada: reintenta una vez inmediatamente, luego una vez con un prompt ligeramente más claro. Si el mismo fallo clasificado se repite, deja de tratarlo como transitorio.
Reescribe cuando el payload muestra un bloqueo de prompt o un resultado de IMAGE_SAFETY del lado de la salida en un caso de uso que sigue siendo legítimo y potencialmente clasificable como benigno. Aquí es donde añadir contexto, encuadre visual menos ambiguo y señales de sensibilidad reducidas puede ayudar. Si el caso de uso está cerca de una línea prohibida, la reescritura puede no ayudar y no debería tratarse como un juego de evasión.
Escala cuando un flujo de trabajo benigno que funcionaba previamente falla de repente, especialmente si:
- el mismo prompt mínimo solía funcionar
- el fallo comenzó dentro de una ventana de tiempo estrecha
- múltiples usuarios o hilos del foro reportan comportamiento similar
- el problema se reproduce en sesiones nuevas
Al escalar, envía una reproducción mínima pero completa:
- nombre del modelo
- superficie
- región
- marca de tiempo exacta
- prompt desensibilizado
- si
promptFeedbackexistía finishReason- si
contentestaba ausente
Eso hace que tu reporte sea utilizable. "Gemini falló silenciosamente de nuevo" no lo es.
Usa una ruta de respaldo cuando tu negocio no puede tolerar la ambigüedad de la plataforma. Para algunos equipos eso significa enrutar ciertas clases de trabajos de imagen a un modelo de imagen de Gemini diferente. Para otros significa mantener un segundo proveedor o ruta de retransmisión. El punto no es que otra ruta sea mágicamente menos segura. El punto es que un sistema de producción no debería tener exactamente una dependencia estrecha para todo el trabajo de imagen si los fallos silenciosos afectan directamente la experiencia del cliente.
Si tu problema real es la continuidad de producción en lugar del uso de la aplicación de consumo, una capa de retransmisión puede ser razonable. laozhang.ai es una opción de retransmisión compatible con OpenAI para equipos que quieren enrutamiento de API unificado en lugar de un único endpoint oficial. Eso no es una corrección para solicitudes prohibidas, y no debería enmarcarse de esa manera. Es una elección operativa para confiabilidad, consistencia de integración o enrutamiento de múltiples modelos. Si esa es tu preocupación, compara primero los compromisos del canal en lugar de tratar la política y el enrutamiento como el mismo problema.
La lección más amplia es que "el fallo silencioso de imagen de Gemini" no es una sola clase de error. A veces la respuesta correcta es "tu prompt cruzó una línea". A veces la respuesta correcta es "la forma de tu payload está equivocada". A veces la respuesta correcta es "Google aceptó el prompt pero filtró la imagen final". Y a veces la respuesta correcta es "el modelo no produjo ninguna imagen en absoluto". Cuanto más rápido nombres la clase correcta, más rápido dejas de perder tiempo en la corrección equivocada.
Un hábito de producción más vale la pena adoptar: mantén un paquete de reproducción desensibilizado para cada incidente de seguridad de imagen que llega a un cliente. El paquete debería contener el nombre del modelo, la marca de tiempo UTC, la región, la superficie de la solicitud, si la solicitud utilizó solo texto o edición de imagen, el número de imágenes de referencia, si esas referencias se enviaron como archivos cargados o datos de imagen en línea, la razón final de bloqueo o finalización, y un hash del prompt más un prompt redactado legible por humanos. Eso suena tedioso, pero convierte una queja vaga en un artefacto de ingeniería accionable. También te permite comparar incidentes a lo largo de semanas y ver si un cambio está vinculado a una superficie, una familia de modelos, una plantilla de prompt o un nuevo lanzamiento del producto.
El mismo paquete de reproducción es útil cuando necesitas decidir si quedarte en la ruta oficial o añadir capacidad de respaldo. Si el 95% de tus fallos son claramente bloqueos del lado del prompt, más capas de enrutamiento no resolverán el problema subyacente. Si los fallos se agrupan alrededor de generaciones incompletas, respuestas de solo texto o regresiones repentinas de la superficie que desaparecen en una ruta diferente, entonces la redundancia operativa comienza a tener sentido. Esta distinción protege a los equipos de comprar infraestructura para resolver lo que es realmente un problema de diseño de prompts y los protege de culpar a los prompts por lo que es realmente un problema de disponibilidad.
Preguntas Frecuentes
El modelo mental más útil es simple: clasifica primero, corrige después. La documentación actual de Google, verificada entre el 12 de enero de 2026 y el 14 de marzo de 2026, ya nos dice que los fallos de imagen de Gemini se dividen en bloqueos del lado del prompt, bloqueos del lado de la salida, resultados sin imagen y problemas de generación no relacionados con políticas. Una vez que lees el payload a través de ese prisma, IMAGE_SAFETY, NO_IMAGE y las respuestas de solo texto dejan de parecer un único e misterioso conjunto de política de contenido.
El otro punto clave es que los ajustes de seguridad configurables son solo parte del panorama. La página oficial de configuración de seguridad de Google dice que existen umbrales ajustables para cuatro categorías principales, pero las protecciones integradas para daños fundamentales permanecen activas y no son ajustables por el usuario. Por eso un ajuste relajado no garantiza que un caso límite de apariencia segura pase, y por qué algunos flujos de trabajo legítimos aún necesitan encuadre cuidadoso del prompt o escalada cuando el comportamiento cambia.
Si solo recuerdas una cosa de este artículo, recuerda esto: promptFeedback te dice que el prompt fue bloqueado, finishReason = IMAGE_SAFETY te dice que la imagen de salida fue bloqueada, y finishReason = NO_IMAGE te dice que Gemini en realidad no produjo ninguna imagen. Esas son tres ramas operativas diferentes, y tratarlas como una es la razón por la que tantas sesiones de solución de problemas de imagen de Gemini dan vueltas en círculos.
¿Por qué Gemini devuelve texto en lugar de una imagen?
Las razones más comunes son prompts ambiguos, configuración de salida de imagen ausente o una tarea mixta que invita a una respuesta de texto. La página de limitaciones de imagen actual de Google dice explícitamente que Gemini puede crear texto y ninguna imagen si el prompt es ambiguo.
¿Por qué BLOCK_NONE o un ajuste de seguridad relajado no corrige IMAGE_SAFETY?
Porque la documentación oficial de configuración de seguridad de Google dice que las protecciones integradas para daños fundamentales no se pueden ajustar. Relajar los umbrales configurables no desactiva todo el filtrado de imagen del lado de la salida.
¿Cuál es la diferencia entre IMAGE_SAFETY y NO_IMAGE?
IMAGE_SAFETY significa que la imagen de salida fue bloqueada después de que la solicitud avanzó lo suficiente como para producir un registro de candidato. NO_IMAGE significa que no se produjo ninguna imagen. La corrección correcta para NO_IMAGE a menudo es claridad o reintento, no reinterpretación de política.
¿Por qué un prompt que funcionó la semana pasada de repente dejó de funcionar?
Las causas posibles incluyen regresiones de plataforma, cambios en el comportamiento del modelo, valores predeterminados de superficie alterados, contexto de chat acumulado o un nuevo problema de estructura de solicitud. Hilos recientes del foro de finales de 2025 muestran que los flujos de trabajo de imagen benignas pueden cambiar de comportamiento a través de las actualizaciones, así que registra la fecha exacta, la superficie y los detalles del payload antes de asumir que el propio prompt es el culpable.
¿Es seguro seguir reintentando la misma solicitud fallida?
Para resultados sin imagen incompletos o ambiguos, uno o dos reintentos controlados son razonables. Para bloqueos de prompt o paradas claras de IMAGE_SAFETY, los reintentos idénticos repetidos generalmente no aportan ningún valor. Reclasifica, reescribe o escala en su lugar.
Fuentes oficiales utilizadas: respuestas bloqueadas en Vertex AI, referencia de la API de Gemini, configuración de seguridad de Gemini, limitaciones de generación de imágenes de Gemini, generación de imágenes de Gemini e IA responsable, y la Política de Uso Prohibido de IA Generativa de Google.