
Respuesta corta: a fecha de 21 de marzo de 2026, GPT-5.4 mini suele ser el mejor default cuando tu workflow gira de verdad alrededor de coding subagents, loops de repositorio y herramientas nativas de OpenAI. Gemini 3 Flash suele ser mejor cuando quieres una lane rápida multimodal más barata, con 1,048,576 tokens de contexto y grounding de Google.
Esta búsqueda se enreda rápido porque no es una comparación limpia de benchmark contra benchmark. OpenAI y Google no publican una hoja oficial compartida para este par. La latest model guide de OpenAI presenta GPT-5.4 mini como la rama de alto volumen para coding, computer use y agent workflows. La página oficial de Gemini 3 Flash lo presenta como la fast lane multimodal más fuerte de Google. Son ecosistemas distintos y superficies de producto distintas.
Por eso la pregunta correcta no es “quién gana en abstracto”, sino qué tipo de trabajo debe cargar tu fast model por defecto.
Resumen rápido
- Elige GPT-5.4 mini si el modelo debe comportarse como un coding worker dentro de un loop con
hosted shell,apply patch,MCPytool search. - Elige Gemini 3 Flash si lo que más te importa es pagar menos por trabajo multimodal serio, disponer de 1.05M de contexto y aprovechar Search / Maps grounding.
- No ignores la familia de Google: si el motivo principal es el precio, después deberías leer Gemini 3.1 Flash-Lite vs Gemini 3 Flash, porque Flash no es la opción más barata dentro de Google.
| Área | GPT-5.4 mini | Gemini 3 Flash | Qué cambia |
|---|---|---|---|
| Lanzamiento | 17 de marzo de 2026 | 17 de diciembre de 2025 | Ambos son actuales |
| Rol oficial | Coding, computer use y agent workflows de alto volumen | Fast lane multimodal más fuerte de Google | La diferencia es de workflow |
| Input estándar | $0.75 / 1M | $0.50 / 1M | Gemini es más barato |
| Output estándar | $4.50 / 1M | $3.00 / 1M | Gemini también gana aquí |
| Contexto | 400,000 | 1,048,576 | Gemini gana con claridad en long context |
| Max output | 128,000 | 65,536 | GPT-5.4 mini puede devolver más |
| Knowledge cutoff | 31 ago 2025 | enero 2025 | GPT-5.4 mini es más fresco en docs públicas |
| Surface diferencial | hosted shell, apply patch, MCP, tool search, image generation | grounding, URL context, Maps, contexto 1M | El producto importa más que la marca |
Si después quieres cerrar la decisión dentro de OpenAI, sigue con GPT-5.4 vs GPT-5.4 mini. Si lo que quieres es entender la ruta más barata de Google, la lectura lógica es Gemini 3.1 Flash-Lite vs Gemini 3 Flash.
Por qué esto no es una guerra limpia de benchmarks
Muchas comparativas rápidas mezclan benchmarks internos de un proveedor con benchmarks distintos del otro y luego publican un ganador. Eso es fácil de maquetar y difícil de defender.
OpenAI sí publica una narrativa muy concreta para GPT-5.4 mini: coding, tool use y computer use dentro de la familia GPT-5.4. Google, en cambio, enfatiza modelo, pricing, límites, soporte de herramientas y grounding, pero no una tabla head-to-head oficial contra GPT-5.4 mini.
La forma prudente de comparar este keyword es otra:
- usar el posicionamiento oficial para entender el trabajo previsto
- usar el pricing y los límites actuales para entender coste y escala
- usar la superficie de herramientas para entender qué sistema encaja mejor
- convertir eso en una decisión de routing
Eso hace la respuesta menos vistosa, pero bastante más útil si realmente tienes que elegir un default en producción.
Precio, contexto y superficie de herramientas importan más que la marca
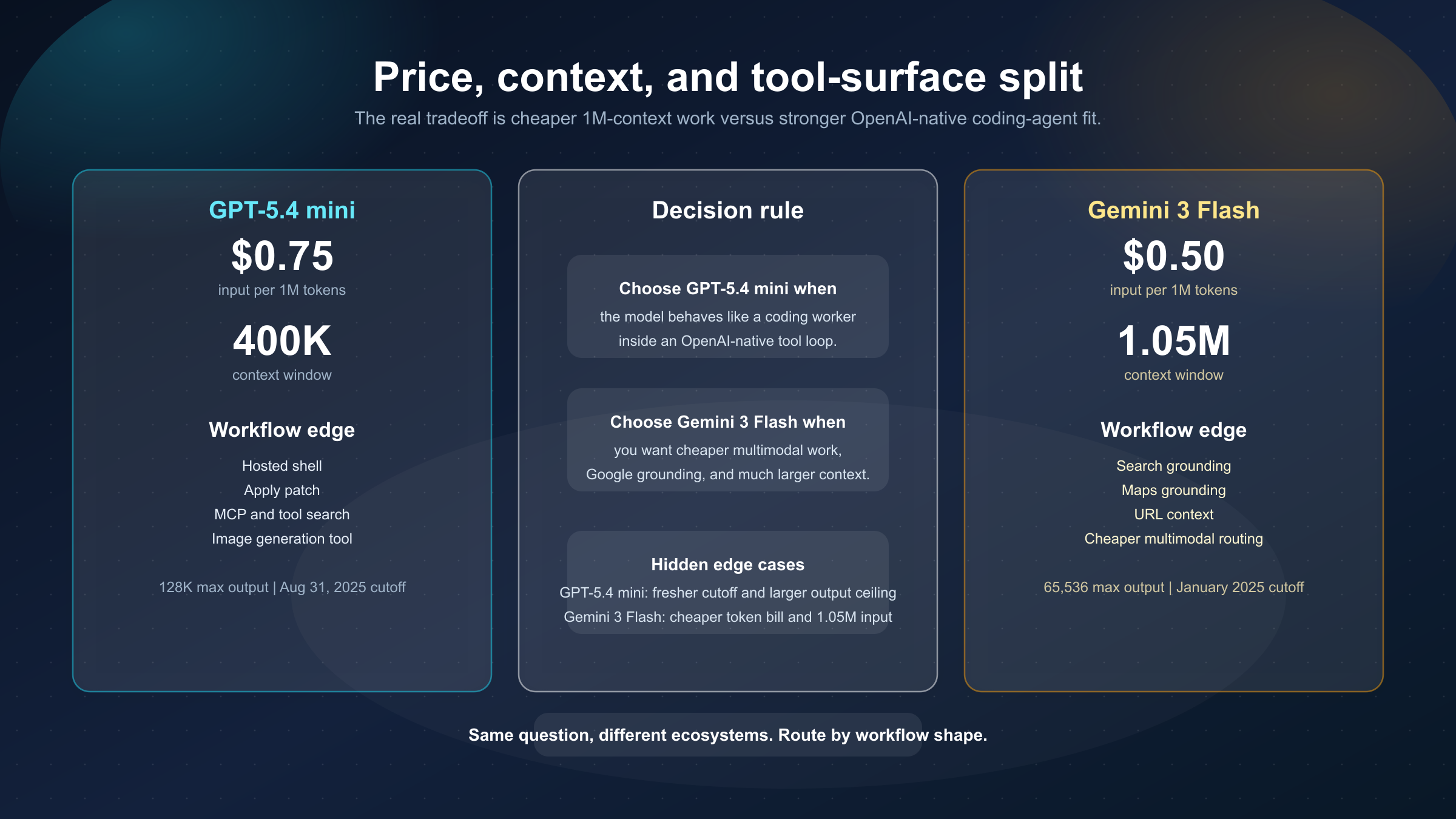
Empecemos por lo más verificable. A fecha de 21 de marzo de 2026:
- la model page de GPT-5.4 mini muestra $0.75 input, $0.075 cached input y $4.50 output por 1M tokens
- la página oficial de pricing de Gemini muestra para Gemini 3 Flash $0.50 input y $3.00 output por 1M tokens
Eso deja a GPT-5.4 mini aproximadamente 1.5x por encima de Gemini 3 Flash en input y output estándar.
El segundo diferencial es el contexto. GPT-5.4 mini llega a 400,000 tokens. Gemini 3 Flash llega a 1,048,576 tokens. Si tu sistema mantiene código, documentos, capturas, logs y recuperación en una misma sesión, esa diferencia es operativa, no cosmética.
Pero GPT-5.4 mini también conserva un ángulo importante: 128,000 tokens de salida máxima frente a 65,536 en Gemini 3 Flash. Si esperas diffs largos, artefactos grandes o respuestas estructuradas extensas, eso también pesa.
Luego está el verdadero corte: la superficie de herramientas.
GPT-5.4 mini enumera actualmente:
- web search
- file search
- image generation
- code interpreter
- hosted shell
- apply patch
- skills
- computer use
- MCP
- tool search
Gemini 3 Flash enumera:
- batch API
- caching
- code execution
- computer use
- file search
- Search grounding
- Maps grounding
- structured outputs
- thinking
- URL context
La lectura práctica es muy clara: GPT-5.4 mini se siente más natural cuando el modelo debe actuar como un coding worker dentro del stack de OpenAI. Gemini 3 Flash se siente más natural cuando quieres una fast lane multimodal, barata, con gran contexto y con valor adicional del lado de Google.
Cuándo GPT-5.4 mini encaja mejor como default

GPT-5.4 mini gana cuando el valor del modelo no está solo en responder bien, sino en cómo trabaja dentro de herramientas.
Tiene mucho sentido como default en cuatro situaciones:
1. Flotas de subagentes de coding. OpenAI lo posiciona precisamente para ese tipo de carga. Si el sistema ya se parece a workers, repos y tools, mini encaja muy bien.
2. Loops de repositorio y parches. hosted shell, apply patch, MCP y tool search no son adornos. Si tu producto se apoya en esa superficie, mini está más cerca del trabajo real que Gemini 3 Flash.
3. Equipos ya normalizados en OpenAI. Cuando prompts, herramientas, evals y hábitos operativos ya viven en Responses API o en patrones tipo Codex, cambiar de ecosistema tiene coste. A veces más coste que la diferencia de precio por token.
4. Workflows que valoran más salida larga que entrada inmensa. El techo de 128K output puede importar bastante en workers que generan patches largos, análisis extensos o artefactos muy verbosos.
La razón fuerte para elegir GPT-5.4 mini no es “OpenAI gana”. La razón fuerte es que su encaje como coding subagent dentro del stack de OpenAI es mucho más coherente.
Cuándo Gemini 3 Flash encaja mejor como default
Gemini 3 Flash gana cuando te interesa más una lane rápida, amplia y multimodal que una lane especializada en coding dentro del ecosistema de OpenAI.
Los casos más claros son estos:
1. Trabajo multimodal con contexto enorme. El input de 1,048,576 tokens es una ventaja real para documentos largos, repos grandes, historiales extensos y análisis con varios tipos de entrada.
2. Throughput serio con menos coste. Gemini 3 Flash no es la ruta barata extrema dentro de Google, pero sí recorta claramente el coste frente a GPT-5.4 mini.
3. El grounding es parte del producto. Search grounding y Maps grounding cambian bastante la evaluación si tu aplicación vive de ese valor extra.
4. Quieres una fast lane multimodal más generalista. Si el sistema mezcla texto, imágenes, PDFs, vídeo o audio, Gemini 3 Flash puede ser una ruta más uniforme que GPT-5.4 mini.
Dicho de la forma más compacta posible:
- GPT-5.4 mini encaja mejor como coding subagent nativo de OpenAI
- Gemini 3 Flash encaja mejor como fast lane multimodal barata y de gran contexto dentro del stack de Google
La advertencia del lado de Google que muchos pasan por alto

Aquí está el matiz que suele faltar en la SERP.
Si Gemini te parece mejor principalmente porque “cuesta menos que GPT-5.4 mini”, conviene hacer una segunda pregunta: ¿de verdad necesitas Gemini 3 Flash o en realidad necesitas Gemini 3.1 Flash-Lite?
Las páginas oficiales de pricing y rate limits dejan claro que Flash-Lite es más barata y además ofrece una lane pública de batch más amplia.
Eso no convierte a Flash-Lite en mejor modelo. Lo que hace es aclarar la lógica interna de Google:
- Gemini 3 Flash para la fast lane más fuerte
- Gemini 3.1 Flash-Lite para la lane más barata y de mayor throughput
Por eso una comparativa honesta no debería resumirse en “Gemini es más barato”. Si el factor dominante es el coste, muchas veces el verdadero rival de GPT-5.4 mini en Google no es Flash, sino Flash-Lite.
Qué conviene medir antes de fijar un único default
Si de verdad vas a poner uno de estos modelos como ruta por defecto en producción, no basta con mirar precio por token o una tabla bonita de benchmarks. Lo que conviene medir es el coste real por tarea completada, incluyendo reintentos, fallos de herramientas, compresión de contexto, verificaciones humanas y escalados.
La forma más útil de hacerlo es separar la carga por tipo de trabajo. No es lo mismo un worker que edita código, un planner que decide la siguiente acción, una tarea multimodal con capturas y PDFs, o una respuesta grounded donde Search o Maps forman parte del valor del producto.
Una matriz práctica podría ser esta:
| Tipo de workload | Modelo para empezar | Qué medir primero | Cuándo escalar o cambiar |
|---|---|---|---|
| worker de repo y patches | GPT-5.4 mini | calidad del patch, estabilidad de tool use, output largo | súbelo si fallan varias ramas difíciles |
| planner / orchestration | GPT-5.4 mini y Gemini 3 Flash en paralelo de prueba | consistencia del plan, coste de error, presión de contexto | deja Gemini si el working set crece mucho |
| análisis multimodal | Gemini 3 Flash | retención de contexto, coste total, lectura de imágenes | vuelve a GPT-5.4 mini si prima el code-edit loop |
| respuestas grounded | Gemini 3 Flash | valor real de grounding, latencia y estabilidad | si grounding no aporta, revisa mini |
La idea de fondo es simple: GPT-5.4 mini suele ganar como coding worker y Gemini 3 Flash suele ganar como multimodal fast lane de gran contexto. En producción, lo importante es descubrir en qué rama te sale más caro un error, no cuál “suena” más avanzado.
También conviene vigilar la estrategia de contexto. El millón de tokens de Gemini 3 Flash es una ventaja real, pero solo si el sistema aprovecha ese working set con sentido. Si solo añades ruido, el resultado no mejora. Del mismo modo, GPT-5.4 mini puede dar una economía mucho mejor cuando la tarea ya está bien encajada en un loop de herramientas claro y no necesita cargar tanta historia a la vez.
Preguntas frecuentes
¿GPT-5.4 mini alcanza para agentes de coding serios?
En muchos casos, sí. OpenAI la está posicionando precisamente para coding de alto volumen, computer use y agent workflows. Si tu cadena depende más de repo work, tools y ejecución controlada que de mantener un contexto inmenso, mini suele ser suficientemente fuerte y más fácil de justificar en coste.
¿La gran ventaja de Gemini 3 Flash es solo el precio?
No. El precio ayuda, pero la diferencia grande de verdad está en el contexto de 1,048,576 tokens y en el grounding de Google. Hay workflows que parecen “de coding”, pero en realidad fallan porque el modelo no puede retener suficiente documentación, historial o señales multimodales a la vez.
¿Tiene sentido elegir un único modelo y olvidarse del routing?
Se puede, pero rara vez es lo mejor. Un único default simplifica la operación, aunque también te obliga a pagar de más en unas ramas o a quedarte corto en otras. Para muchos equipos, la arquitectura más estable es dejar GPT-5.4 mini en la ejecución de coding y Gemini 3 Flash en análisis multimodal y contexto largo, con escalado solo donde el coste del error lo justifica.
Otra comprobación útil antes del rollout es mirar no solo la media, sino también la cola de fallos. Si GPT-5.4 mini resuelve nueve casos bien pero en el décimo rompe una cadena de patches y dispara revisión humana, esa rama deja de ser realmente barata. Y si Gemini 3 Flash mantiene contexto largo, pero tu workload apenas aprovecha esa ventaja, puedes acabar pagando por headroom que no estás usando. Por eso la comparación madura no termina en la tabla: termina cuando mides colas concretas, ramas concretas y el coste real de cada fallo.
En producción, esa diferencia pesa más que cualquier slogan de marca.
Conclusión
Si necesitas una recomendación directa, usa esta:
- elige GPT-5.4 mini cuando tu producto sea, en esencia, un workflow de coding agents o subagents con fuerte dependencia del stack nativo de OpenAI
- elige Gemini 3 Flash cuando quieras pagar menos por una fast lane multimodal con mucho más contexto y valor de grounding del lado de Google
Para bastantes equipos, la respuesta más defendible no es forzar un único ganador universal. Es rutear por tipo de carga:
- GPT-5.4 mini para code-edit workers, repo loops y ejecución tool-heavy
- Gemini 3 Flash para análisis multimodal más baratos, síntesis de contexto largo y tareas grounded
La diferencia parece confusa solo si haces la pregunta equivocada. La pregunta útil no es “qué modelo es mejor en general”, sino “qué workflow debe cargar mi modelo rápido por defecto”. Cuando planteas así la decisión, la separación deja de ser ambigua.