
Respuesta corta: para la mayoría de desarrolladores, GPT-5.4 ya es la mejor opción por defecto. OpenAI lanzó GPT-5.4 el 5 de marzo de 2026 y la presenta como el primer modelo principal de razonamiento que incorpora las capacidades punteras de programación de GPT-5.3-Codex. En la práctica, eso significa que GPT-5.4 encaja mejor cuando quieres un solo modelo para código, contexto largo, búsqueda, herramientas y trabajo agéntico de varios pasos.
Eso no vuelve irrelevante a GPT-5.3-Codex. GPT-5.3-Codex, publicada el 5 de febrero de 2026, mantiene dos ventajas reales: es más barata en tokens de entrada y todavía supera a GPT-5.4 en Terminal-Bench 2.0. Si tu flujo vive sobre todo en CLI, shell, CI, automatización y sesiones cortas o medias donde importa mucho el coste por prompt, GPT-5.3-Codex sigue mereciendo un hueco en tu stack.
Esta guía usa páginas oficiales de lanzamiento de OpenAI, la documentación actual de modelos API y la página actual de precios, verificadas el 19 de marzo de 2026. También separa los hechos estables del producto del ruido operativo temporal, para no confundir fallos de acceso en Codex con el cambio real de recomendación entre modelos.
Resumen rápido
Si quieres una única recomendación, usa GPT-5.4 como modelo por defecto y conserva GPT-5.3-Codex solo para rutas más terminal-first o más sensibles al coste.
| Categoría | GPT-5.4 | GPT-5.3-Codex | Lectura práctica |
|---|---|---|---|
| Fecha de lanzamiento | 5 de marzo de 2026 | 5 de febrero de 2026 | GPT-5.4 es la opción más nueva y más central |
| Rol del producto | Modelo principal para reasoning y trabajo agéntico | Modelo especializado en coding | GPT-5.4 es más amplio; Codex, más estrecho |
| Precio input | $2.50 / 1M | $1.75 / 1M | GPT-5.3-Codex gana en coste de entrada |
| Precio output | $15 / 1M | $14 / 1M | La diferencia de salida es pequeña |
| Cached input | $0.25 / 1M | $0.175 / 1M | El contexto repetido sigue siendo más barato en Codex |
| Ventana de contexto | 1,050,000 | 400,000 | GPT-5.4 es mejor para trabajo a escala de repositorio |
| Max output | 128,000 | 128,000 | Empate |
| Herramientas | Search, hosted shell, apply patch, MCP, computer use y más | Posicionamiento más centrado en coding | GPT-5.4 funciona mejor como un único default |
| Ventaja más clara | GDPval, SWE-Bench Pro, OSWorld, Toolathlon, BrowseComp | Terminal-Bench 2.0 | GPT-5.4 gana el conjunto; Codex mantiene un nicho relevante |
| Mejor para | Ruta por defecto, contexto largo, trabajo mixto | CLI-heavy, más barato, rutas estrechas | Muchas veces conviene mantener ambos |
El matiz clave es que GPT-5.4 no es simplemente “GPT-5.3-Codex pero más nueva”. Es un default más fuerte en conjunto. Pero GPT-5.3-Codex tampoco está obsoleta, porque la forma real del workflow sigue importando más que una tabla general.
Qué cambió de verdad entre GPT-5.4 y GPT-5.3-Codex

El cambio más importante es de posicionamiento. En la página de lanzamiento de GPT-5.4, OpenAI dice que GPT-5.4 incorpora las capacidades frontier de coding de GPT-5.3-Codex. Eso importa porque ya no se trata de una reasoning model que “también programa bien”, sino de la ruta principal que OpenAI quiere recomendar para trabajo serio, incluido el coding.
GPT-5.3-Codex, en cambio, nació como un producto coding-first. En la página de GPT-5.3-Codex el énfasis está en velocidad, agentic coding y rendimiento en tareas reales de ingeniería. Por eso sigue teniendo defensores incluso después de la llegada de GPT-5.4: su valor ya no es ser “la más nueva”, sino seguir siendo una especialista clara.
La visión general de modelos en la API de OpenAI refuerza esta lectura. Hoy OpenAI orienta a los desarrolladores a empezar por GPT-5.4 para reasoning complejo, coding y trabajo agéntico, mientras que GPT-5.3-Codex queda como opción especializada de coding. Esa diferencia refleja la posición actual del producto, no solo la narrativa del día del lanzamiento.
La página de lanzamiento de GPT-5.4 del 5 de marzo de 2026 también aclara algo que muchas comparativas dejan borroso. GPT-5.4 Thinking empezó a desplegarse ese día para ChatGPT Plus, Team y Pro, GPT-5.4 Pro para Pro y Enterprise, y GPT-5.4 en Codex incluye soporte experimental para 1M de contexto. La misma página dice que las solicitudes en Codex por encima de la ventana estándar de 272K cuentan a 2x de uso normal. Eso ayuda a entender por qué GPT-5.4 ya es la nueva recomendación principal y, al mismo tiempo, por qué la experiencia concreta todavía puede variar según la superficie.
La forma correcta de leerlo es sencilla: GPT-5.4 reemplazó a GPT-5.3-Codex como recomendación por defecto, pero no como respuesta universal a todos los workloads. Si tu trabajo mezcla código, búsqueda, parches, contexto largo y toma de decisiones, GPT-5.4 es la mejor base. Si tu trabajo es más estrecho y muy centrado en terminal, GPT-5.3-Codex sigue teniendo sentido.
Parte de la confusión viene de mezclar tres superficies distintas: el catálogo de modelos API, el comportamiento en Codex y otros selectores de modelos. Están relacionadas, pero no siempre se actualizan ni fallan al mismo ritmo. Una comparación útil tiene que separar esas capas.
Qué benchmarks importan de verdad para programar
La manera más útil de comparar estos modelos no es preguntar cuál gana más gráficas, sino cuál cambia de verdad los resultados del desarrollador.
| Benchmark | GPT-5.4 | GPT-5.3-Codex | Que implica |
|---|---|---|---|
| GDPval | 83.0% | 70.9% | GPT-5.4 es más fiable en tareas ambiguas y mixtas |
| SWE-Bench Pro | 57.7% | 56.8% | GPT-5.4 tiene una ligera ventaja en tareas duras de software engineering |
| OSWorld-Verified | 75.0% | 74.0% | GPT-5.4 rinde algo mejor en tareas tipo computer operation |
| Toolathlon | 54.6% | 51.9% | GPT-5.4 maneja mejor los workflows con herramientas |
| BrowseComp | 82.7% | 77.3% | GPT-5.4 destaca más cuando toca navegar y reunir evidencia |
| Terminal-Bench 2.0 | 75.1% | 77.3% | GPT-5.3-Codex sigue siendo mejor en CLI puro |
La conclusión importante no es que GPT-5.4 “arrase” a Codex. Lo importante es que GPT-5.4 gana casi todo el tablero, pero GPT-5.3-Codex mantiene justo la ventaja que más se parece al trabajo terminal-heavy real. Para quien pasa el día entre comandos, scripts, archivos y debugging en shell, ese detalle vale más de lo que parece.
Para casi todos los demás, el patrón favorece a GPT-5.4. La mejora en GDPval importa porque sugiere una mejor respuesta cuando el trabajo deja de ser solo programar y se convierte en razonamiento, coordinación de herramientas, lectura de docs y búsqueda de pruebas. La diferencia en SWE-Bench Pro es pequeña, pero va en la misma dirección.
La traducción práctica es esta:
- Si tu flujo es principalmente “editar código, lanzar comandos y cerrar el problema rápido”, GPT-5.3-Codex sigue teniendo sentido.
- Si tu flujo es “entender un repo grande, usar varias herramientas, razonar sobre tradeoffs y producir una salida fiable”, GPT-5.4 es mejor como ruta por defecto.
Precio, contexto y cobertura de herramientas

Más allá de los benchmarks, la decisión real suele depender de tres cosas: precio, contexto y herramientas.
| Factor | GPT-5.4 | GPT-5.3-Codex | Por qué importa |
|---|---|---|---|
| Input | $2.50 / 1M | $1.75 / 1M | Codex es bastante más barata en prompts pesados |
| Cached input | $0.25 / 1M | $0.175 / 1M | El contexto reutilizado sigue costando menos en Codex |
| Output | $15 / 1M | $14 / 1M | La salida está demasiado cerca como para decidir por sí sola |
| Context window | 1,050,000 | 400,000 | GPT-5.4 encaja mejor en trabajo de repositorio y sesiones largas |
| Nota de contexto largo | Por encima de 272K input, 2x input y 1.5x output para toda la sesión | No hay multiplicador equivalente publicado | El gran contexto existe, pero no es gratis |
| Tool breadth | Search, file search, image generation, code interpreter, hosted shell, apply patch, skills, MCP, computer use, tool search | Posicionamiento más centrado en coding | GPT-5.4 es más fácil de justificar como default único |
La historia del precio es más sutil que “GPT-5.4 es cara”. El hueco importante está en input, no en output. Si tu sistema envía mucho código o mucho contexto repetido, GPT-5.3-Codex se vuelve atractiva muy rápido. Si, en cambio, tu trabajo necesita con frecuencia herramientas, navegación, parches o contexto largo, el sobrecoste de GPT-5.4 se vuelve más fácil de defender.
Con la ventana de contexto pasa algo parecido. El salto a 1.05M es real y muy útil para arquitectura, análisis de repositorios y sesiones largas. Pero la propia documentación actual de GPT-5.4 avisa de que, por encima de 272K input tokens, la sesión completa se encarece. Es decir, la gran ventana es una ventaja operativa, no una invitación a mandar prompts gigantes sin control.
La cobertura de herramientas cambia aún más la recomendación. GPT-5.4 soporta web search, hosted shell, apply patch, MCP, computer use y otras superficies que hoy forman parte del trabajo real de desarrollo. Por eso es un default más fuerte. GPT-5.3-Codex sigue pareciendo una especialista clara, no la mejor candidata para ser la única ruta para todo.
Otra diferencia práctica es la fricción operativa. Cuando un flujo de trabajo empieza siendo “arreglar una función” y termina convirtiéndose en “leer documentación, buscar evidencia, comparar opciones, editar varios archivos y validar el cambio”, GPT-5.4 aguanta mejor la transición sin obligarte a cambiar de modelo a mitad de camino. Ese detalle no siempre aparece en las tablas, pero en equipos reales ahorra bastante tiempo y reduce errores de routing.
Qué modelo conviene en cada workflow
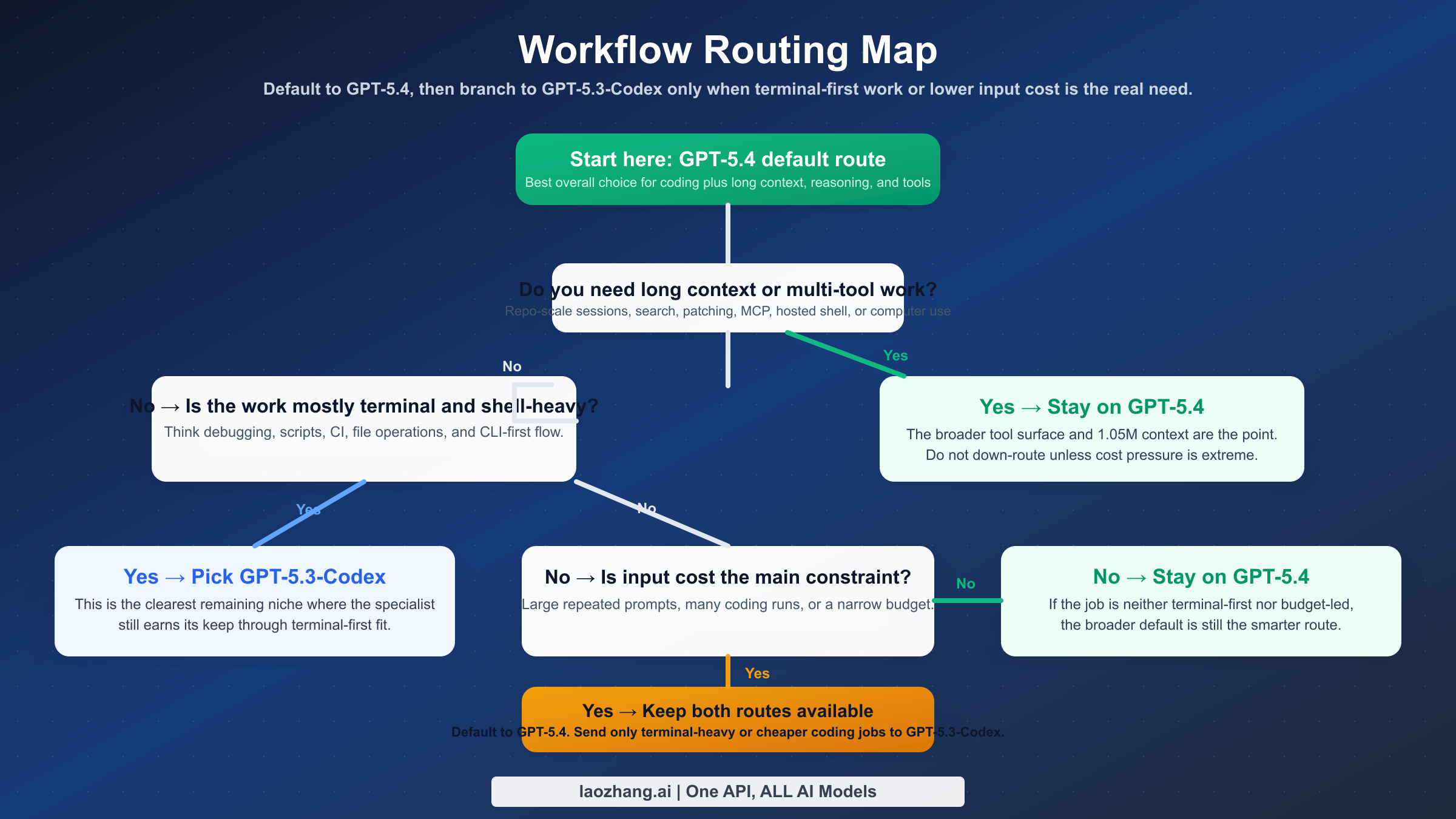
Esta es la sección que más suele faltar en la SERP, aunque es la que realmente responde a la consulta.
| Workflow | Usa GPT-5.4 | Usa GPT-5.3-Codex | Motivo |
|---|---|---|---|
| Modelo por defecto en Codex o API | Sí | No | GPT-5.4 encaja mejor como default único |
| Ingeniería muy centrada en terminal | A veces | Sí | Codex conserva una ventaja real en CLI |
| Análisis de repositorios grandes | Sí | Rara vez | 1.05M de contexto cambia lo que cabe en una sesión |
| Workflows agénticos con varias herramientas | Sí | Rara vez | GPT-5.4 tiene una tool surface mucho más amplia |
| Coding sensible al coste de entrada | A veces | Sí | El ahorro de input sigue importando |
| Trabajo profesional mixto más allá del código | Sí | No | GPT-5.4 es mejor “modelo único” |
Para un desarrollador individual o un equipo pequeño, lo más sensato suele ser poner GPT-5.4 por defecto. Reduce la complejidad de enrutado y deja menos casos en los que tienes que adivinar si luego necesitarás search, patching o contexto largo.
Para un ingeniero de plataforma, DevOps o infra, la respuesta es menos absoluta. Si la mayoría de tus tareas viven en shell, scripts, CI, logs y debugging en terminal, GPT-5.3-Codex puede seguir sintiéndose mejor por dólar.
Para staff engineers, tech leads y trabajo más arquitectónico, GPT-5.4 es más fácil de defender. Esas tareas rara vez son solo terminal. Suelen mezclar interpretación, análisis, contexto largo y decisiones entre opciones.
Si ya tienes routing automático, la mejor solución muchas veces no es elegir una, sino mantener ambas: GPT-5.4 como ruta por defecto y GPT-5.3-Codex como excepción deliberada para tareas terminal-heavy o más baratas.
Cuando sigue teniendo sentido GPT-5.3-Codex
Muchas páginas reducen la historia a “GPT-5.4 reemplaza a GPT-5.3-Codex”. A nivel de posicionamiento general eso es más o menos cierto. A nivel de ingeniería diaria, es demasiado brusco.
GPT-5.3-Codex sigue teniendo sentido en cuatro casos. El primero es trabajo terminal-first. El segundo es control estricto del coste de input. El tercero es workflows de coding estrechos, donde no necesitas la amplitud de herramientas de GPT-5.4. El cuarto es routing de respaldo, donde disponer de una segunda gran ruta de coding aumenta la resiliencia.
También hay un motivo organizativo. Algunas empresas prefieren no mover todo su tráfico a una sola ruta nueva en la primera semana o el primer mes de disponibilidad, aunque la recomendación general ya haya cambiado. Mantener GPT-5.3-Codex como carril secundario permite comparar costes, registrar diferencias en productividad y absorber mejor cualquier regresión temporal de superficie sin paralizar al equipo.
Los hilos de marzo de 2026 sobre problemas de acceso a GPT-5.4 y GPT-5.3-Codex son útiles como señal de fricción, pero no cambian la historia central del producto. Sirven para recordar que el surface behavior puede ser ruidoso. No sirven como prueba de que GPT-5.4 ya no deba ser el default.
La regla operativa más sólida hoy es esta: trata GPT-5.4 como ruta principal y GPT-5.3-Codex como excepción táctica.
Checklist de migración de GPT-5.3-Codex a GPT-5.4
Si tu equipo ya usa GPT-5.3-Codex como modelo por defecto, la mejor migración es gradual.
- Cambia la ruta predeterminada a GPT-5.4 para coding general, contexto largo y trabajo con varias herramientas.
- Mantén GPT-5.3-Codex para debugging terminal-heavy, shell automation y rutas de coding más baratas.
- Añade control de costes para sesiones GPT-5.4 que superen 272K input tokens.
- Vuelve a probar tres tareas clave: un caso de repo grande, un workflow de terminal y una tarea multi-tool.
- Define una regla de fallback para no confundir un fallo temporal de acceso con una decisión de modelo.
Ese patrón es mejor que un corte total, porque refleja la diferenciación real entre ambas rutas.
FAQ
¿GPT-5.4 es estrictamente mejor que GPT-5.3-Codex?
No. GPT-5.4 es mejor en conjunto y debería ser el default para la mayoría, pero GPT-5.3-Codex sigue ganando en Terminal-Bench 2.0 y sigue siendo más barata en input tokens. Si tu trabajo es muy terminal-centric o muy sensible al coste, Codex sigue teniendo valor.
¿Vale la pena pagar más por GPT-5.4?
Normalmente sí, siempre que realmente aproveches el contexto largo y la tool surface más amplia. Si tus tareas son sobre todo runs cortos de coding y shell, el extra cuesta más justificarlo.
¿GPT-5.4 reemplaza de verdad a GPT-5.3-Codex en Codex y la API?
A nivel de posicionamiento oficial, sí. A nivel de workflow, no por completo. GPT-5.3-Codex sigue siendo una ruta estrecha pero legítima.
¿Debo preocuparme por los problemas recientes de acceso?
Conviene tenerlos presentes, pero no sobredimensionarlos. Son contexto operativo, no el centro de la decisión. Lo que debe mandar es la documentación oficial actual y la forma real de tu workflow.