
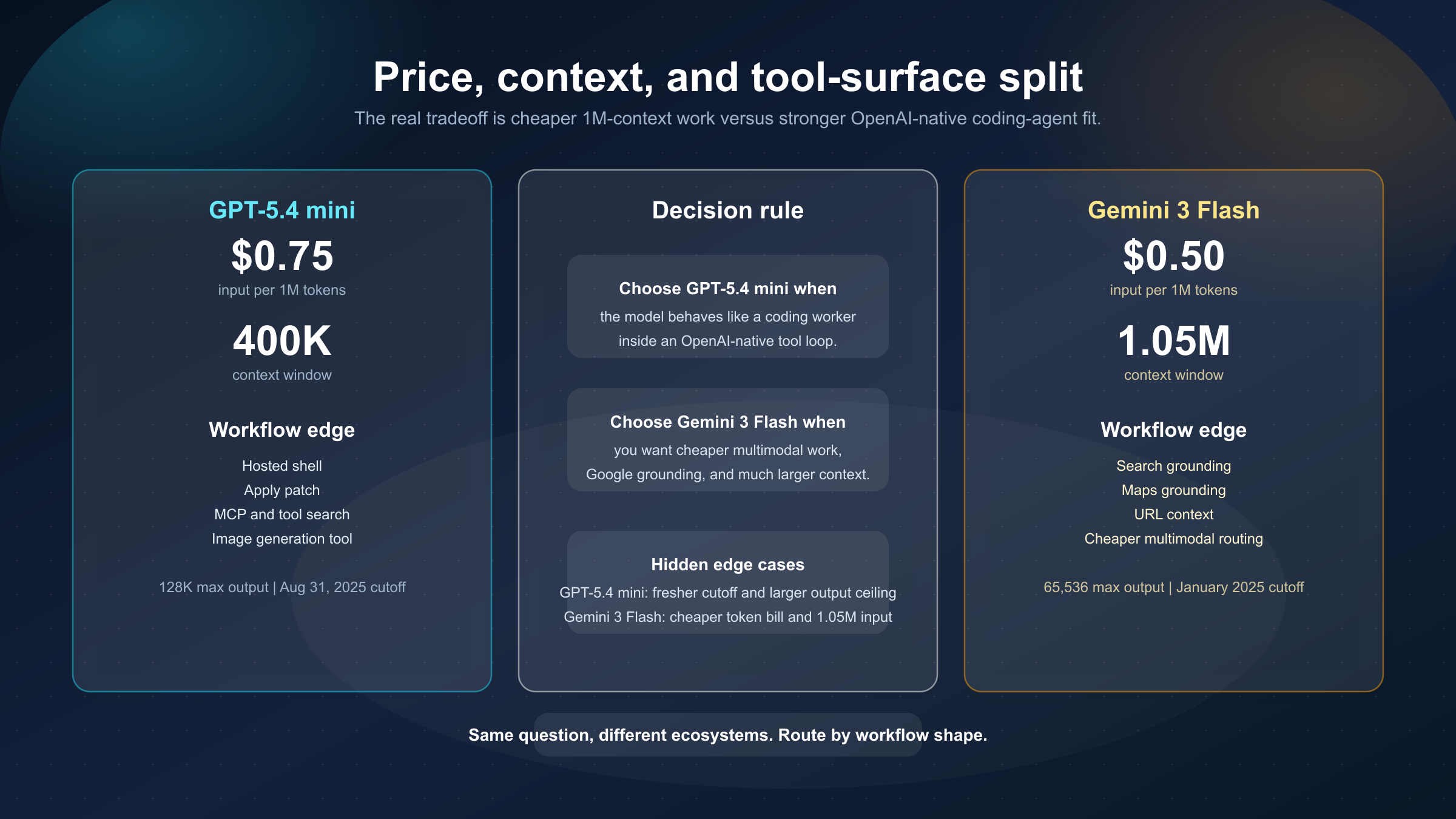
結論から言うと、 2026年3月21日 時点では、デフォルトモデルが coding subagent、repo 操作、patch loop、OpenAI ネイティブな tool chain を担うなら GPT-5.4 mini の方が実務的です。より安いマルチモーダル処理、1,048,576 トークンの入力コンテキスト、Google grounding を重視するなら Gemini 3 Flash の方が自然です。
この比較は、よくある「ベンチマーク表を並べて勝者を決める記事」にしてしまうと外しやすいテーマです。OpenAI の現行 latest model guide は GPT-5.4 mini を high-volume coding、computer use、agent workflows 向けの枝として位置づけています。Google の現行 Gemini 3 Flash モデルページ は、Gemini 3 Flash を最も強い fast multimodal lane として説明しています。そもそも前提にしている product surface が違います。
だから本当に答えるべき質問は、「どちらが抽象的に上か」ではなく、自分の fast default にどんな仕事を持たせたいかです。
要点まとめ
- GPT-5.4 mini を選ぶべき場面: モデルが OpenAI の tool-rich な環境で coding worker のように振る舞う必要があるとき。
- Gemini 3 Flash を選ぶべき場面: より安いマルチモーダル処理、1.05M コンテキスト、Search / Maps grounding を重視するとき。
- Google 側の重要な補足: コストだけが理由なら、次は Gemini 3.1 Flash-Lite vs Gemini 3 Flash も確認した方が安全です。
| 項目 | GPT-5.4 mini | Gemini 3 Flash | 実務上の読み方 |
|---|---|---|---|
| リリース日 | 2026年3月17日 | 2025年12月17日 | どちらも現行モデル |
| 公式ポジション | high-volume coding / computer use / agents | Google の strongest fast multimodal lane | 役割の違いが大きい |
| Input 価格 | $0.75 / 1M | $0.50 / 1M | Gemini の方が安い |
| Output 価格 | $4.50 / 1M | $3.00 / 1M | ここでも Gemini が安い |
| Context window | 400,000 | 1,048,576 | 長文脈は Gemini が有利 |
| Max output | 128,000 | 65,536 | 出力上限は GPT-5.4 mini が大きい |
| Knowledge cutoff | 2025-08-31 | 2025年1月 | GPT-5.4 mini の方が新しい |
| 差が出る surface | hosted shell、apply patch、MCP、tool search | grounding、URL context、1M input | ブランド差より product surface 差 |
OpenAI 内の default 分岐を見たいなら GPT-5.4 vs GPT-5.4 mini が次の読み物です。Google 側の cheaper lane を見たいなら Gemini 3.1 Flash-Lite vs Gemini 3 Flash が自然な続きです。
これは単純なベンチマーク対決ではない
この種の比較で雑な記事がやりがちなのは、ベンダーごとに別々の benchmark を無理やり 1 枚の表に押し込んで「勝者」を決めることです。ですが、このペアではそのやり方がかなり危険です。
OpenAI は 2026年3月17日 の GPT-5.4 mini 公開時に、SWE-Bench Pro、Toolathlon、GPQA Diamond、OSWorld-Verified など、coding や tool use に寄ったベンチマークを出しています。一方の Google は、Gemini 3 Flash を GPT-5.4 mini と head-to-head で並べた公式スコアカードを出していません。代わりに、モデルの役割、pricing、rate limits、tool support、changelog で説明しています。
だから安全な比較方法は、次の 4 点に分けて考えることです。
- 公式に想定されている workload は何か
- 現在の価格と token limit はどうか
- どんな tool surface と grounding を持つか
- その差が実際の routing をどう変えるか
このテーマでは、派手な総合点より routing judgment の方が価値があります。
価格、コンテキスト、ツール面の差の方が重要
まず価格です。2026年3月21日 時点で確認した公式ページでは、
- GPT-5.4 mini モデルページ に $0.75 input、$0.075 cached input、$4.50 output
- Gemini pricing ページ に Gemini 3 Flash $0.50 input、$3.00 output
が掲載されています。
標準価格だけで見ると GPT-5.4 mini は Gemini 3 Flash より約 1.5 倍 高い計算です。
次にコンテキストです。GPT-5.4 mini は 400,000、Gemini 3 Flash は 1,048,576。大きな repo、長いドキュメント、スクリーンショット、履歴を 1 つの working set に入れたいなら、この差はかなり大きいです。
ただし GPT-5.4 mini にも見逃せない利点があります。最大出力は 128,000 で、Gemini 3 Flash の 65,536 より大きいです。長い diff や大きな artifact を吐く worker では、この差が効くことがあります。
そして本当の分岐点は tool surface です。
GPT-5.4 mini は現在、
- web search
- file search
- image generation
- code interpreter
- hosted shell
- apply patch
- skills
- computer use
- MCP
- tool search
を列挙しています。
Gemini 3 Flash は現在、
- batch API
- caching
- code execution
- computer use
- file search
- Search grounding
- Maps grounding
- structured outputs
- thinking
- URL context
を列挙しています。
つまりこれは「どちらがツールを持っているか」ではなく、「どんな種類のシステムを組みやすいか」の比較です。GPT-5.4 mini は OpenAI の coding-agent surface と相性がよく、Gemini 3 Flash はより安い大規模コンテキストの multimodal fast lane として自然です。
GPT-5.4 mini をデフォルトにしやすい場面

GPT-5.4 mini が強いのは、モデルが単に速いテキスト生成器ではなく、OpenAI の tool-rich な環境で coding worker として動く ときです。
特に向いているのは次のようなケースです。
1. coding subagents や worker 群。 OpenAI 自身が high-volume coding と subagent 的な使い方を強く示しています。
2. repo inspection と patch loop。 hosted shell、apply patch、MCP、tool search が重要なら、GPT-5.4 mini の方が仕事そのものに近いです。
3. すでに OpenAI 標準で運用しているチーム。 prompts、tools、evals、運用習慣が Responses API や Codex 風に寄っているなら、token 差より surface の一貫性の方が価値になることがあります。
4. 長い output が必要な worker。 128K の output ceiling は、長文の差分や詳細な artifact を返すケースで地味に効きます。
つまり GPT-5.4 mini を選ぶ理由は「OpenAI だから」ではありません。coding subagent としての product fit が一貫しているから です。
Gemini 3 Flash をデフォルトにしやすい場面
Gemini 3 Flash は、より安い fast lane、より大きいコンテキスト、Google grounding を重視するときに強くなります。
典型的には次のようなケースです。
1. large-context multimodal work。 1,048,576 input token は、長いレポート、複数ドキュメント、スクリーンショット付きの解析、長い履歴を同時に抱える場面で実用的です。
2. コストを抑えた serious throughput。 Gemini 3 Flash は cheapest lane ではありませんが、GPT-5.4 mini よりは確実に安いです。
3. grounding が product value の一部。 Search grounding と Maps grounding がアプリ価値に直結するなら、Gemini 3 Flash は単に安いだけではありません。
4. coding 専用ではなく broad multimodal fast lane が欲しい。 テキスト、画像、PDF、動画、音声をまたぐなら、Gemini 3 Flash の方が一貫した default になりやすいです。
要するに、
- GPT-5.4 mini は OpenAI 側の coding-subagent lane
- Gemini 3 Flash は Google 側の cheaper large-context multimodal lane
という理解が一番実務的です。
Google側で見落とされがちな注意点

この比較で多くのページが落とすのがここです。
もし Gemini を選びたくなる最大の理由が「GPT-5.4 mini より安いから」なら、もう一段だけ踏み込んで考えるべきです。本当に必要なのは Gemini 3 Flash か、それとも Gemini 3.1 Flash-Lite か。
Gemini pricing と rate limits を見ると、Flash-Lite の方が価格も安く、Tier 1 batch queue も大きいです。
これは Flash-Lite の方が強いという意味ではありません。Google の family 内でも fast lane が 2 つに割れている、という意味です。
- Gemini 3 Flash: より強い fast lane
- Gemini 3.1 Flash-Lite: より安く高スループットな lane
そのため、コストだけで Gemini 側に傾いているなら、本当に比較すべき相手は Flash ではなく Flash-Lite かもしれません。
本番導入前に何を測るべきか
どちらかを production default にする前に、token 単価や平均レイテンシだけを見るのは危険です。実際に見るべきなのは、1 件のタスクを成功させる総コスト です。そこには再試行、tool failure、人手レビュー、context 圧縮、fallback への切り替えまで含まれます。
判断しやすくするには、まず仕事を分けます。planner、repo worker、multimodal analysis、grounded answer、large-context synthesis は同じ軸で比べない方がいいです。どの枝が OpenAI-native coding loop に近いか、どの枝が Google-side large-context lane に近いかを先に決めた方が、モデル選定はかなり明確になります。
実務では次のようなテスト表が役立ちます。
| workload | まず試すモデル | 先に測るもの | 切り替え条件 |
|---|---|---|---|
| repo patch worker | GPT-5.4 mini | patch 品質、tool 呼び出し安定性、長い output 完了率 | 難所での失敗が高くつくなら上位へ |
| planner / orchestration | GPT-5.4 mini と Gemini 3 Flash の両方 | plan の一貫性、context 圧力、手戻り率 | working set が大きいなら Gemini 側へ |
| multimodal analysis | Gemini 3 Flash | long context 保持、画像理解、総コスト | code-edit が主目的なら mini を再検討 |
| grounded answer | Gemini 3 Flash | Search / Maps grounding の実利 | grounding が不要なら mini に戻す |
この表の意味は単純です。GPT-5.4 mini は coding worker として、Gemini 3 Flash は large-context multimodal lane として評価する方が正しい、ということです。どちらが「より高級か」を議論するより、どの枝での失敗が一番高くつくかを測る方が、運用にはずっと役立ちます。
さらに、context の扱い方も見直すべきです。Gemini 3 Flash の 1,048,576 は確かに魅力ですが、単にノイズまで大量投入すると逆に設計が雑になります。GPT-5.4 mini も同様で、入力窓が小さくても、仕事が明確な tool loop に収まるなら総コストはかなり良くなります。
よくある質問
GPT-5.4 mini は serious な coding agent に十分ですか。
多くのケースでは十分です。OpenAI 自身が high-volume coding と agent workflow 向けに位置づけており、repo inspection、patch、tool call、実行ループのような仕事にはかなり自然に乗ります。超長文脈の総合作業でなければ、default として十分に成立します。
Gemini 3 Flash の最大の武器は価格だけですか。
いいえ。価格差は重要ですが、それ以上に 1,048,576 の入力コンテキストと Google grounding が効きます。実際には「coding task」に見えても、失敗の原因が patch 品質より context 不足にあるケースは少なくありません。
1 つだけ選んで routing をやめてもいいですか。
可能ではありますが、最適とは限りません。単一 default は運用が簡単になる一方で、どこかの枝では過剰コストになり、別の枝では headroom 不足になります。多くのチームでは、coding execution を GPT-5.4 mini、large-context multimodal work を Gemini 3 Flash に分ける方が安定します。
結論
一番短い実務ルールは次の通りです。
- デフォルトが coding agent / subagent なら GPT-5.4 mini
- デフォルトが より安い multimodal fast lane + 1.05M context + Google grounding なら Gemini 3 Flash
多くのチームで一番 defensible なのは、1 つの普遍的勝者を決めることではなく routing です。
- code-edit worker、repo agent、tool-heavy 実行は GPT-5.4 mini
- 安価な multimodal analysis、long-context synthesis、grounded task は Gemini 3 Flash
この 2 つを同じ軸で無理に比べるより、どちらの workflow を default fast model に持たせたいかで決める方が、ずっとぶれにくいです。