
結論から言うと、 強い推論、長いコンテキスト、失敗コストの高いタスクでは GPT-5.4 を選ぶべきです。逆に、coding や agent worker を大量に回したいなら GPT-5.4 mini の方が実務的です。
この比較で重要なのは、「どちらが絶対的に上か」ではありません。実際に知りたいのは、どちらを標準ルートにして、どちらをスケール用のルートに置くべきか です。
OpenAI の現行 latest-model guide では、gpt-5.4 は broad general-purpose work と most coding tasks のデフォルト、gpt-5.4-mini は high-volume coding、computer use、agent workflows 向けの小型ブランチとして位置付けられています。つまりこれは、同じ GPT-5.4 系列の中での役割分担です。
要点まとめ
最短で言うなら、次のルールで十分です。
- GPT-5.4 は難しい仕事のルート
- GPT-5.4 mini は量を回す仕事のルート
| 項目 | GPT-5.4 | GPT-5.4 mini | 実務上の見方 |
|---|---|---|---|
| リリース日 | 2026年3月5日 | 2026年3月17日 | どちらも現行モデル |
| 現在の役割 | 高品質な主力デフォルト | 高ボリューム coding / agent 用 | 価格差より役割差が大きい |
| Input 価格 | $2.50 / 1M | $0.75 / 1M | GPT-5.4 は約3.3倍高い |
| Cached input | $0.25 / 1M | $0.075 / 1M | 反復コンテキストは mini が有利 |
| Output 価格 | $15.00 / 1M | $4.50 / 1M | 出力でも差は大きい |
| Context window | 1,050,000 | 400,000 | 長文脈タスクは GPT-5.4 が有利 |
| Knowledge cutoff | 2025-08-31 | 2025-08-31 | 鮮度の差ではない |
| Tool surface | 幅広い Responses API ツール対応 | 同じく幅広い対応 | mini は tool-light ではない |
| 公開 top-tier caps | 15,000 RPM / 40,000,000 TPM | 30,000 RPM / 180,000,000 TPM | mini の方が量を回しやすい |
大事なのは、「品質を優先するか」「スループットとコストを優先するか」です。
本当の分岐点は flagship の headroom と production throughput
この比較を単なるスペック比較として読むと、判断を誤りやすくなります。
GPT-5.4 が向いているのは次のような場面です。
- 400K では足りない長いコンテキスト
- 多段の reasoning が壊れると全体が崩れるワークフロー
- 1回のミスのコストが高い仕事
GPT-5.4 mini が向いているのは次のような場面です。
- worker や subagent を大量に並列で回したい
- coding や computer use を大量に回す
- モダンな tool surface を保ったままコストを抑えたい
だから、この比較で本当に答えるべき問いは「どちらが強いか」ではなく、難しい枝と量の枝をどちらに持たせるかです。
実際に効くベンチマーク差
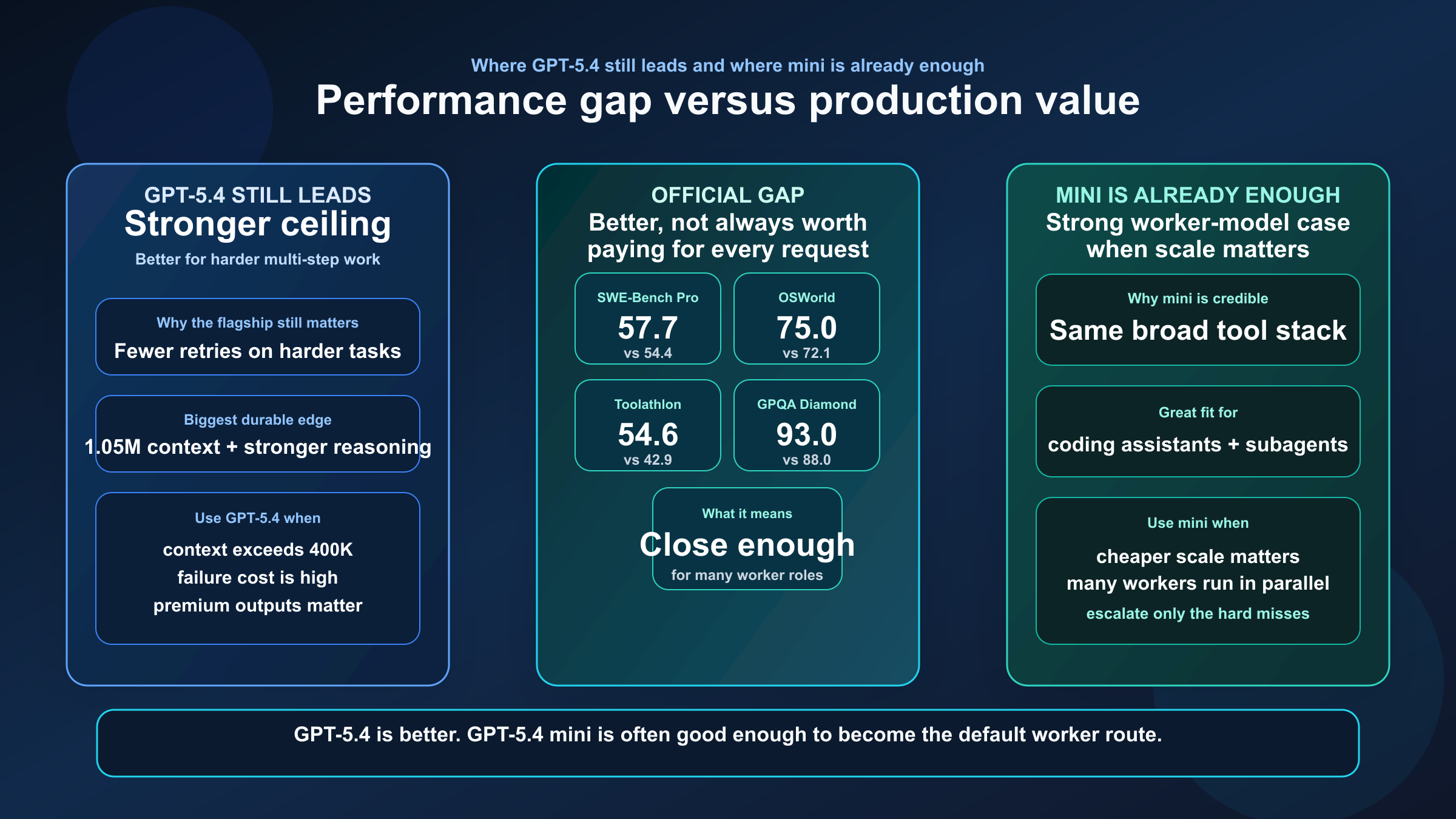
OpenAI の GPT-5.4 mini and nano では、次の比較が特に参考になります。
| ベンチマーク | GPT-5.4 | GPT-5.4 mini | 実務上の意味 |
|---|---|---|---|
| SWE-Bench Pro | 57.7% | 54.4% | GPT-5.4 が上だが、mini もかなり近い |
| Terminal-Bench 2.0 | 75.1% | 60.0% | 長い tool-heavy タスクでは差が大きい |
| Toolathlon | 54.6% | 42.9% | 複数ツール連携の安定性は GPT-5.4 が上 |
| GPQA Diamond | 93.0% | 88.0% | reasoning headroom は GPT-5.4 にある |
| OSWorld-Verified | 75.0% | 72.1% | computer use では mini も十分強い |
ここで重要なのは、GPT-5.4 mini が「弱すぎて worker にしか使えない」わけではないことです。逆に、多くの production workflow では mini で十分な場面がかなり多い、というのがこの比較の本質です。
ただし、難しい multi-step 作業や失敗コストの高い枝では GPT-5.4 の方が安心です。だから実務では、「全部 GPT-5.4」にするよりも「難しい枝だけ GPT-5.4」にした方がきれいに運用できることが多くなります。
言い換えると、このベンチマーク差は「全部 flagship にすべき」という意味ではありません。むしろ、どの失敗が高くつくかを先に決めて、その枝だけを GPT-5.4 に寄せる方が運用は安定します。
たとえば、planner が仕様を読み違えると下流 worker をまとめて壊すような構成なら GPT-5.4 の価値は高いです。一方で、単発のコード修正、要約、分類、定型 review のように再試行しやすい仕事は mini の方が全体最適になりやすいです。
価格・コンテキスト・スループットの差

現在の GPT-5.4 model page では、GPT-5.4 は次の条件です。
- Input: $2.50 / 1M
- Cached input: $0.25 / 1M
- Output: $15.00 / 1M
- Context window: 1,050,000
現在の GPT-5.4 mini model page では、GPT-5.4 mini は次の条件です。
- Input: $0.75 / 1M
- Cached input: $0.075 / 1M
- Output: $4.50 / 1M
- Context window: 400,000
つまり、コスト面では GPT-5.4 は mini よりかなり高いです。一方で 1.05M のコンテキストは、長いリポジトリ解析や大量の仕様書を1セッションに載せるような仕事では明確な価値があります。
ただし、GPT-5.4 のページには見落とされやすい注意点もあります。272K input tokens を超えると、セッション全体が 2x input / 1.5x output で課金されます。巨大コンテキストは確かに強みですが、無条件に使うべき無料ボーナスではありません。
また、公開 top-tier caps を見ると GPT-5.4 mini の方が throughput に強いのも大きなポイントです。これは、mini が worker や background jobs に向いている理由そのものです。
さらに、両方とも knowledge cutoff は 2025年8月31日 です。ここは意外に重要で、「mini は古いからダメ」という説明は現行 docs の読み方として正しくありません。
実務では、1トークンあたりの価格よりも 1件の完了コスト で考えた方が判断しやすくなります。mini が少し多めに再試行しても、全体のキューを安くさばけるなら production default としては十分に合理的です。
逆に、巨大コンテキストを毎回そのまま渡す設計は GPT-5.4 の強みを活かしつつもコストを悪化させやすいです。難しい枝だけを長文脈で処理し、それ以外は mini に落とす設計の方が、品質とコストのバランスを取りやすくなります。
mini はツールが弱いモデルではない
このテーマでは、ここを読み違える人が多いです。
現行 model page では、GPT-5.4 も GPT-5.4 mini も次のような広い tool surface を持っています。
- web search
- file search
- image generation
- code interpreter
- hosted shell
- apply patch
- skills
- computer use
- MCP
- tool search
つまり比較の軸は「ツールがあるか、ないか」ではなく、同じような product surface の上で、どれだけ quality headroom を買うかです。
それが分かると、なぜ routing 設計が重要かも見えてきます。mini でもかなり多くの仕事は回るからです。
どんなときに GPT-5.4 にお金を払うべきか
GPT-5.4 が向いているのは、トークン差より失敗コストの方が高い場面です。
たとえば次のような仕事です。
- 大きな repo や長いドキュメントを読む
- planner / orchestrator の役割を持たせる
- multi-step で reasoning が崩れると全体が壊れる
- 顧客向けや business-critical な出力を作る
1回のミスで再実行や手戻りが大きくなるなら、その枝は GPT-5.4 に寄せた方が結果的に運用コストが下がることが多いです。
どんなときに GPT-5.4 mini が smarter default になるか
GPT-5.4 mini が真価を出すのは、ボトルネックが quality ではなく scale のときです。
向いている場面は次の通りです。
- subagent / worker
- 大量の coding assistant リクエスト
- screenshot-heavy な computer use loop
- バックグラウンドの review や triage
- flagship 価格を全リクエストに払いたくない production workload
多くのチームで実際にきれいに機能するのは、次の分担です。
- GPT-5.4 を planner と難しい枝に使う
- GPT-5.4 mini を workers に使う
この設計の方が、現行 OpenAI ラインの役割分担と自然に一致します。
特に現場では、「全件 GPT-5.4 でまず安全に始めてから後で削る」よりも、最初から二段ルートで設計した方がルールがぶれません。昇格条件を先に決めておけば、mini で足りる仕事を人間の感覚で毎回判断しなくて済むからです。
運用ルールとしては、長文脈、複雑な multi-tool 分岐、顧客向け最終出力だけを GPT-5.4 に固定し、それ以外の下流処理を mini に寄せる形が分かりやすいです。この方が、チーム内でも「なぜそのモデルを使うのか」を説明しやすくなります。
さらに、運用ログを見返すと「どの枝で mini から GPT-5.4 へ昇格したか」が残るため、あとから routing ルールを改善しやすくなります。最初から単一モデルに固定するより、改善余地を可視化しやすいのも二段設計の利点です。
結果として、コスト調整と品質調整を同じルールの中で回しやすくなります。
API / Codex の結論と ChatGPT の見え方は別の話
API と Codex の観点では話は比較的明快です。
- GPT-5.4 が主力 default
- GPT-5.4 mini が smaller / faster / cheaper branch
ただし ChatGPT では事情が違います。現行の release notes によると、2026年3月18日時点で GPT-5.4 mini は Thinking 用の経路や fallback として使われていますが、通常の selectable model として前面に出ているわけではありません。
つまり、ChatGPT で見えるモデル名から API の routing を逆算しない方がいい、ということです。
チーム向けの実用ルール
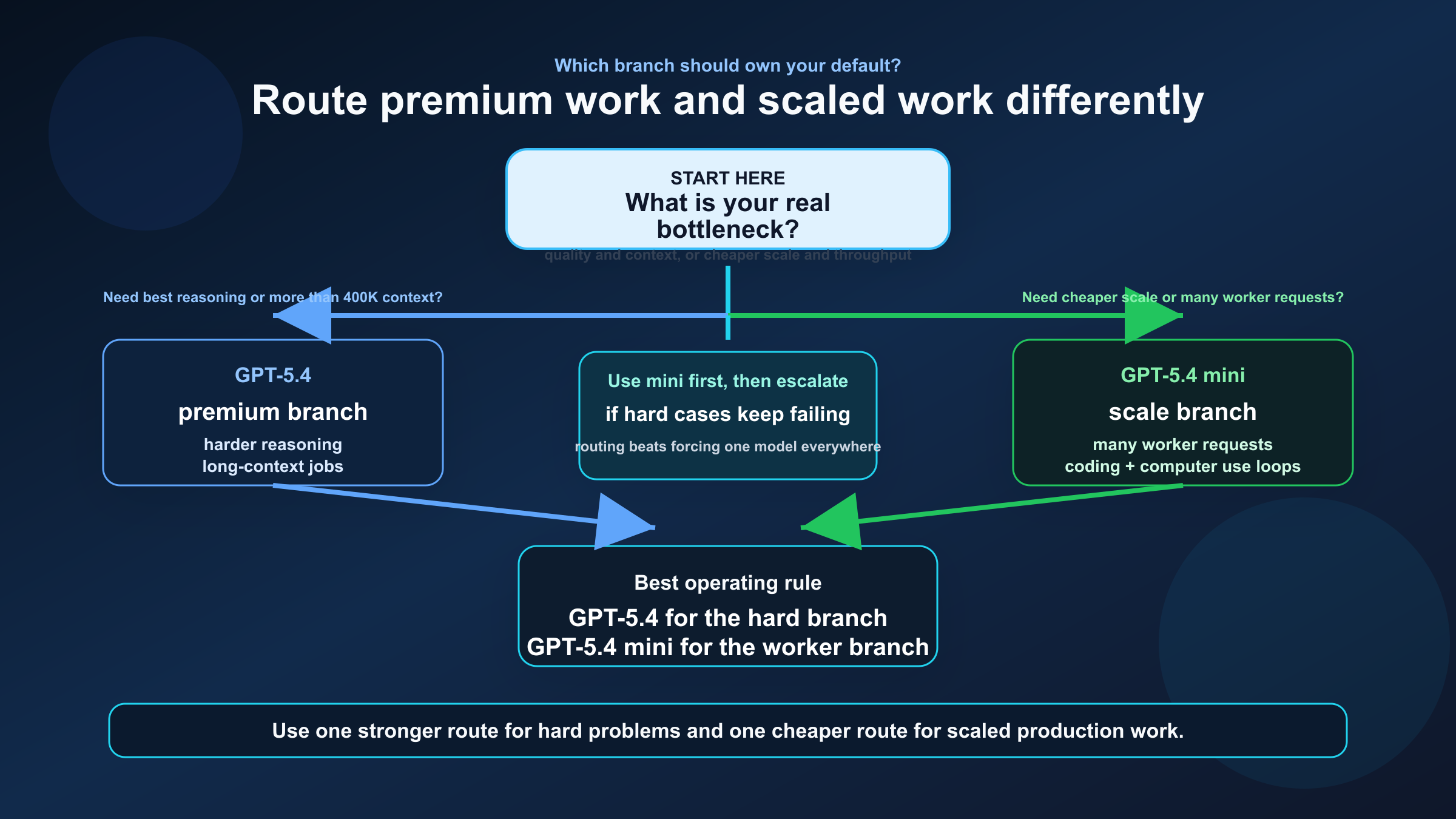
実務で使いやすいルールは次の通りです。
| ワークロード | デフォルト | 理由 | 上げ下げの目安 |
|---|---|---|---|
| Long-context repo analysis | GPT-5.4 | コンテキストと reasoning の余裕が大きい | 400K に十分収まり、強いコスト制約があるときだけ mini |
| Planner / orchestration | GPT-5.4 | 難しい分岐に強い | planner が軽いなら mini をテスト |
| Worker / subagent | GPT-5.4 mini | throughput とコストが良い | 難しいケースだけ GPT-5.4 に昇格 |
| Coding assistant at scale | GPT-5.4 mini | 十分強く、しかも安い | repair や review の難所は GPT-5.4 |
一番分かりやすい運用ルールは、難しい枝は GPT-5.4、量を回す枝は GPT-5.4 mini です。
FAQ
GPT-5.4 mini は serious coding agents に十分ですか?
多くのケースでは十分です。SWE-Bench Pro や OSWorld-Verified でもかなり近く、コストと throughput の面で明確に有利です。
GPT-5.4 mini はツールが少ないのですか?
現行 model page ベースではそうではありません。大きな違いはツールの有無ではなく、quality headroom、context、cost です。
GPT-5.4 に払う価値はありますか?
はい。長文脈、難しい reasoning、失敗コストの高い枝ならあります。逆に、量を回すだけの処理なら mini の方が合理的です。
1.05M context は GPT-5.4 を選ぶ最大の理由ですか?
かなり大きい理由のひとつですが、それだけではありません。難しい tool-heavy work での安定性も重要です。
Codex-style subagents にはどちらが向いていますか?
多くの subagent には GPT-5.4 mini が向いています。GPT-5.4 は planner や escalation branch に置く方がきれいです。
要するに、GPT-5.4 は難しい仕事、GPT-5.4 mini は量を回す仕事 と覚えておけば、この比較で迷う時間はかなり減ります。