
결론부터 말하면, 2026년 3월 20일 기준 Gemini 3.1 Pro Preview는 어려운 에이전트 작업, 소프트웨어 엔지니어링, 도구 사용이 중요한 다단계 흐름에 적합하고, Gemini 3.1 Flash-Lite는 번역, 추출, 분류, 라우팅, 경량 에이전트 같은 저비용 대량 트래픽의 기본 모델로 두는 편이 합리적입니다. 이 비교는 바로 그 역할 분담으로 읽어야 합니다.
모델 이름만 보면 같은 계열의 상위판과 하위판처럼 보이지만, Google의 현재 공식 문서는 그렇게 설명하지 않습니다. Gemini 3.1 Pro Preview는 software engineering, precise tool use, reliable multi-step execution을 강조하는 프리미엄 레인으로 소개되고, Gemini 3.1 Flash-Lite는 고빈도 경량 작업, 번역, 분류, 단순 추출, 저지연 처리에 최적화된 가장 비용 효율적인 모델로 설명됩니다.
그래서 핵심 질문은 "누가 더 강한가"가 아니라 "어떤 작업에 Pro 가격을 지불할 가치가 있고, 어떤 작업은 Flash-Lite의 저렴한 기본 레인에 남겨야 하는가"입니다.
핵심 요약
실무 기준으로 가장 간단한 규칙은 아래와 같습니다.
- 어려운 에이전트 작업, 소프트웨어 엔지니어링, 툴 정확도가 중요한 흐름은 Gemini 3.1 Pro Preview
- 번역, 추출, 분류, 경량 라우팅, 고빈도 저비용 작업은 Gemini 3.1 Flash-Lite
- 부하가 섞여 있다면 한 모델로 몰지 말고 분리 라우팅
2026년 3월 20일 기준 공식 비교는 다음과 같습니다.
| 항목 | Gemini 3.1 Pro Preview | Gemini 3.1 Flash-Lite | 실무적 의미 |
|---|---|---|---|
| 현재 상태 | Preview | Preview | 둘 다 무조건적인 GA 기본값은 아님 |
| 무료 티어 | 없음 | 있음 | Flash-Lite가 테스트와 스테이징에 더 유리 |
| 표준 input 가격 | $2.00 / 1M tokens | $0.25 / 1M tokens | Pro는 input 기준 8배 비쌈 |
| 표준 output 가격 | $12.00 / 1M tokens | $1.50 / 1M tokens | output도 8배 차이 |
| Batch 가격 | $1.00 in / $6.00 out | 무료층 후 $0.125 in / $0.75 out | Flash-Lite가 저렴한 비동기 처리에 적합 |
| 입력 한도 | 1,048,576 tokens | 1,048,576 tokens | 컨텍스트 크기가 결정 요인이 아님 |
| 최대 output | 65,536 tokens | 65,536 tokens | 출력 한도도 차별점이 아님 |
| Tier 1 Batch queue ceiling | 5,000,000 tokens | 10,000,000 tokens | 큰 큐는 Flash-Lite가 더 다루기 쉬움 |
| 적합한 용도 | 어려운 에이전트, 소프트웨어 엔지니어링, 정밀한 tool flow | 번역, 추출, 분류, 경량 에이전트, 대량 트래픽 | 이것이 실제 역할 분담 |
이 정리는 공식 pricing, Gemini 3.1 Pro Preview 모델 페이지, Gemini 3.1 Flash-Lite 모델 페이지, 공개 rate limits 페이지, 그리고 DeepMind의 Gemini 3.1 Pro 및 Gemini 3.1 Flash-Lite model card를 바탕으로 합니다.
이 비교는 컨텍스트 경쟁이 아니라 라우팅 경쟁이다
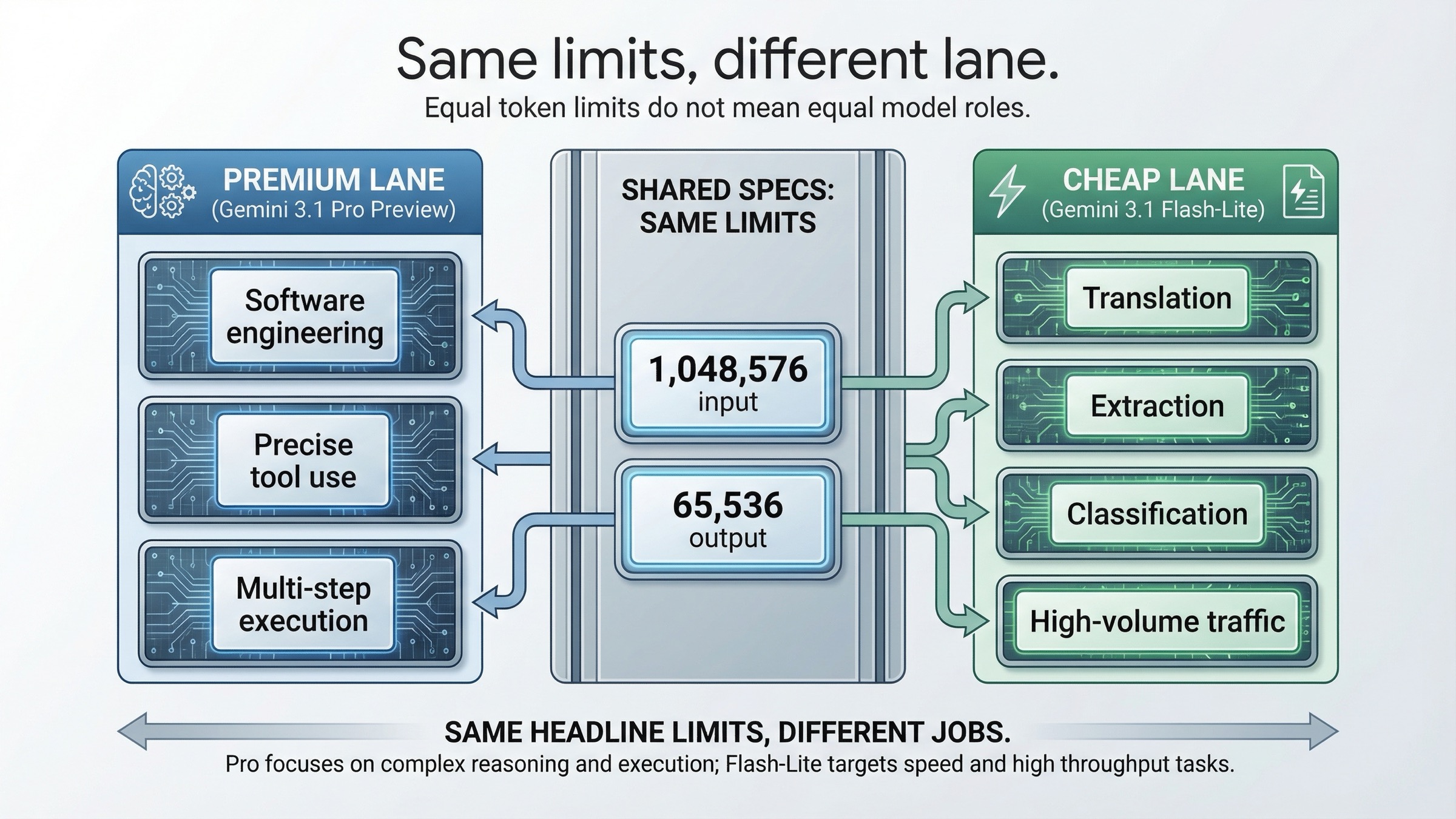
이 비교에서 가장 흔한 실수는 Pro가 더 비싸고 더 강하니 모든 트래픽을 Pro로 보내야 한다고 생각하는 것입니다. 반대로 Flash-Lite를 단순 축소판으로 보는 것도 마찬가지로 틀린 해석입니다. 현재 공식 문서는 어느 쪽도 지지하지 않습니다.
먼저 같은 점부터 봐야 합니다. 두 모델 페이지 모두 1,048,576 input tokens와 65,536 output tokens를 적고 있습니다. 즉, 이 비교는 더 큰 컨텍스트를 사느냐의 문제가 아닙니다. 그래서 단순 스펙 비교만으로 결론을 내리면 실제 운영 판단을 놓치게 됩니다.
진짜 차이는 더 비싼 모델이 무엇을 사다 주는지, 더 싼 모델을 고르면 무엇을 포기하는지에 있습니다.
Gemini 3.1 Pro Preview 페이지는 thinking, token efficiency, factual consistency, software engineering behavior, precise tool usage, reliable multi-step execution을 강조합니다. 전형적인 프리미엄 레인 설명입니다.
Gemini 3.1 Flash-Lite 페이지는 고빈도 경량 작업, 번역, 분류, 단순 추출, 저지연, high-volume agentic tasks를 강조합니다. 이것은 Pro의 축소판이 아니라 저렴한 레인에 대한 별도 최적화입니다.
따라서 실제로 유용한 질문은 다음입니다.
- 더 강한 reasoning과 안정적인 tool behavior가 진짜 필요한 작업은 무엇인가?
- 저렴한 레인으로 충분한 작업은 무엇인가?
- 부하가 단일한가, 아니면 Flash-Lite를 기본으로 두고 어려운 작업만 Pro로 올려야 하는가?
이 관점이 공식 가격, 한도, 용도 정보를 제대로 읽게 해 줍니다.
2026년 3월 20일 기준 가격, Batch 경제성, 공개 한도의 현실

이 비교에서 가장 무거운 사실은 가격입니다.
공식 pricing 페이지에 따르면 Gemini 3.1 Pro Preview에는 무료 티어가 없습니다. 200k prompt tokens 이하에서는 $2.00 / 1M input, $12.00 / 1M output입니다. 200k를 넘으면 $4.00 input, $18.00 output으로 올라갑니다. Batch에서는 줄어들지만 그래도 $1.00 input, $6.00 output입니다.
Flash-Lite는 전혀 다른 가격대입니다. 무료 티어가 있고, 표준 가격은 $0.25 input, $1.50 output입니다. Batch에서는 $0.125 input, $0.75 output까지 내려갑니다.
즉 Pro는 표준 input과 output 모두 8배 비쌉니다. 따라서 Pro는 그만큼의 비용을 품질로 회수해야 합니다. 품질 차이가 미미하다면 기본값으로 Pro를 두는 것은 대부분 과지출입니다. 반대로 더 강한 첫 응답이 인간 검수, 잘못된 tool call, 연쇄 실패를 크게 줄여 준다면 비싼 가격이 정당화될 수 있습니다.
공개 rate limits 페이지도 같은 방향을 보여 줍니다. 현재 페이지는 RPM과 TPM의 고정 표를 제공하지 않고, 실제 값은 AI Studio에서 확인하라고 안내합니다. 따라서 영구적인 공개 RPM 숫자를 본문에 고정하는 것은 적절하지 않습니다. 하지만 여전히 유용한 공개 숫자가 하나 있습니다. Tier 1 Batch enqueued token limit입니다.
현재 공개 값은 다음과 같습니다.
- Gemini 3.1 Pro Preview: 5,000,000
- Gemini 3.1 Flash-Lite: 10,000,000
이 차이는 실제 운영에서 중요합니다. 많은 생산 트래픽은 채팅이 아니라 백그라운드 작업이기 때문입니다.
- 대량 번역
- 문서 추출
- 분류와 라벨링
- 대규모 요약
- 비동기 라우팅
이런 작업에서는 Flash-Lite가 단순히 더 싼 것이 아니라, 큐 처리에도 더 잘 맞습니다.
grounding도 Pro에 유리하지 않습니다. pricing 페이지에는 두 모델 모두 유료 사용 시 월 5,000 grounding prompts 무료 후, Search와 Maps가 모두 $14 / 1,000 queries로 표시됩니다. 경제성의 결론은 변하지 않습니다.
요약하면 저렴한 레인에 속하는 작업은 Flash-Lite에 남겨 두는 것이 기본입니다.
Gemini 3.1 Pro Preview가 정말로 값을 하는 순간
이 글을 "싼 모델이 항상 옳다"로 읽는 것도 또 다른 오해입니다. Pro가 충분히 값을 하는 작업은 분명히 존재합니다.
Gemini 3.1 Pro Preview는 software engineering, precise tool use, reliable multi-step execution을 강하게 강조합니다. DeepMind의 Gemini 3.1 Pro model card는 2026년 2월 19일 공개되었고, Humanity's Last Exam, GPQA Diamond, Terminal-Bench 2.0, SWE-Bench Verified, APEX-Agents 같은 어려운 벤치마크에서 더 강한 상단 성능 스토리를 제공합니다.
물론 이런 벤치마크가 여러분의 production 시스템에 그대로 비례 적용되는 것은 아닙니다. 하지만 방향성 신호는 충분합니다. 다음과 같은 경우에는 Pro가 더 합리적일 수 있습니다.
- 다단계 에이전트 플랜
- tool-heavy coding workflow
- 한 번의 잘못된 tool decision이 긴 연쇄 실패를 만드는 처리
- 값싼 재시도도 결국 비싼 reasoning 작업
- 첫 응답 품질이 사람 검수 시간을 직접 줄여 주는 engineering 작업
또 하나의 실무 신호는 gemini-3.1-pro-preview-customtools 라인입니다. 모든 에이전트를 Pro로 옮기라는 뜻은 아니지만, Google이 더 무거운 tool workflow를 어느 쪽에 배치하는지는 분명히 보여 줍니다.
Reddit의 "I had to switch to 3.1 Pro Preview Custom Tools for my Agent" 같은 글도 공식 사양은 아니지만, 이 비교 뒤에 있는 실제 고민이 무엇인지 잘 보여 줍니다. 많은 사용자는 추상적인 벤치마크가 아니라 실제 tool workflow의 안정성을 고민합니다.
따라서 Pro의 올바른 이해는 이 문장으로 정리할 수 있습니다.
나쁜 답변의 비용이 토큰 비용보다 훨씬 클 때만 Pro를 기본 레인이 아니라 승격 레인으로 쓴다.
왜 Gemini 3.1 Flash-Lite를 저렴한 기본 레인으로 남겨야 하는가
Flash-Lite가 과소평가되는 이유는 많은 비교 글이 "더 똑똑한 모델을 기본값으로 둬야 한다"는 전제에서 출발하기 때문입니다. 하지만 현재 Google 문서는 Flash-Lite를 그렇게 놓고 있지 않습니다. Flash-Lite는 현실적인 대량 작업을 저렴하게 돌리기 위한 모델입니다.
Gemini 3.1 Flash-Lite Preview와 Gemini 3.1 Flash-Lite model card가 공통으로 가리키는 대표 작업은 다음과 같습니다.
- 번역
- 분류
- 단순 추출
- 저지연 처리
- 고빈도 호출
- 대규모 비동기 큐
- 경량 에이전트
이것은 실제 운영 트래픽의 아주 큰 비중을 차지합니다.
입력이 비교적 명확하고 출력도 제약되는 작업이 많다면, Flash-Lite는 단순히 "싼 대안"이 아니라 "맞는 기본값"입니다. 추출, 라벨링, 번역, 반복 요약, 단순 라우팅처럼 Pro의 상단 능력이 필요하지 않은 작업에서는 Pro가 더 좋다기보다 너무 비싼 경우가 많습니다.
무료 티어도 이 결론을 더 강하게 만듭니다. 많은 팀에게 무료 티어는 단순 체험판이 아니라,
- 프롬프트 템플릿 검증
- staging smoke test
- routing 변경 검증
- 저용량 회귀 테스트
를 위한 저비용 운영 레인입니다. 그런 관점에서 Flash-Lite는 타협안이 아니라, 저렴한 레인 작업에 대한 정답에 가까운 기본 모델입니다.
전면 교체인가, 기본 유지인가, 분리 라우팅인가
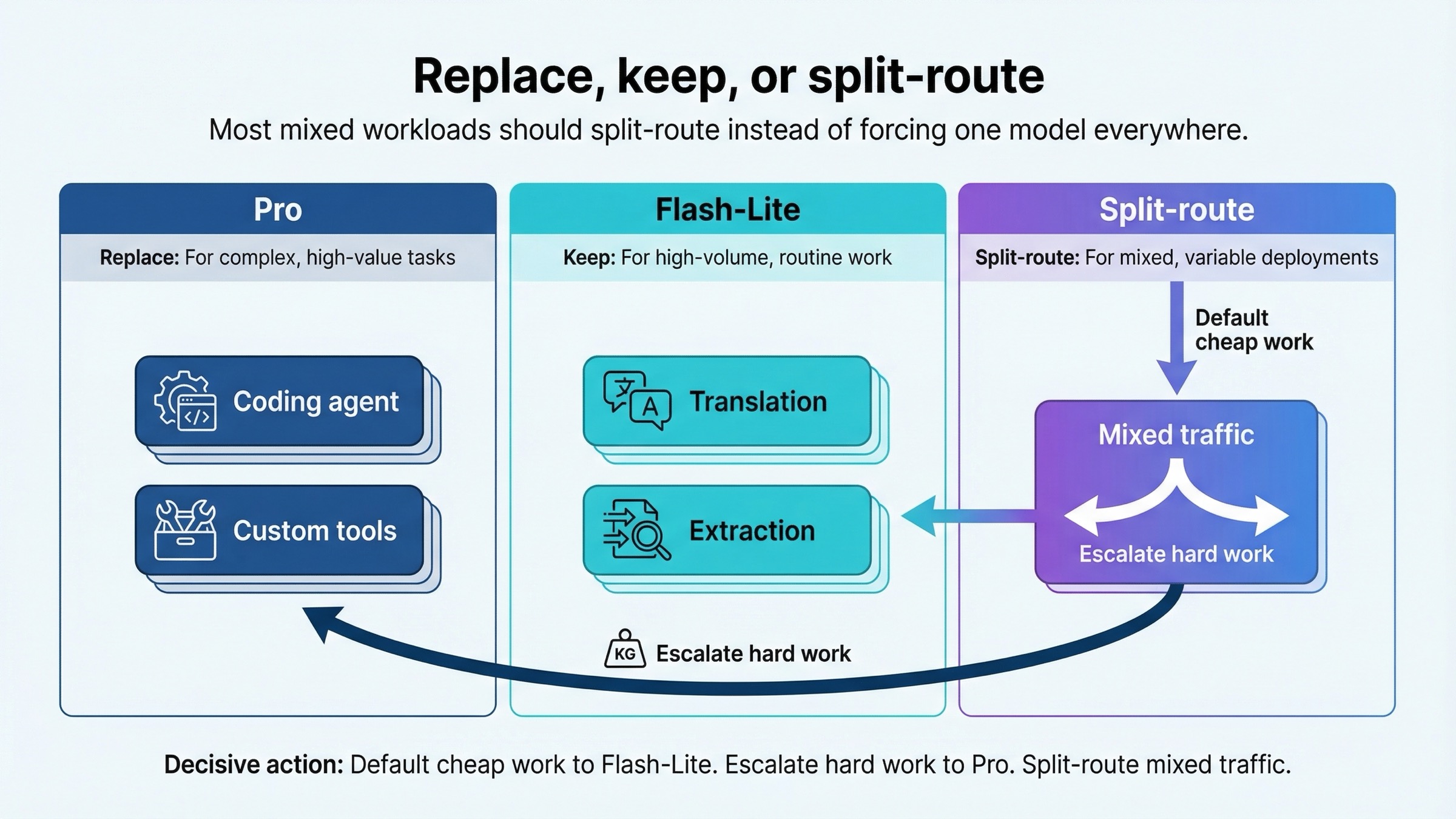
대부분의 팀에게 정답은 극단적 단일 선택이 아닙니다.
모든 트래픽을 Pro로 보내면 루틴 작업에서 거의 확실하게 과지출합니다. 모든 트래픽을 Flash-Lite로 보내면 가장 어려운 작업에서 품질 부족을 느끼게 됩니다. 그래서 부하가 섞여 있다면 split-routing이 가장 자연스러운 해답입니다.
실무 규칙은 이렇게 정리할 수 있습니다.
| 워크로드 | 더 적합한 기본 모델 | 이유 |
|---|---|---|
| tool-heavy coding agent | Gemini 3.1 Pro Preview | 소프트웨어 엔지니어링과 다단계 품질이 더 중요 |
| custom tools orchestration | Gemini 3.1 Pro Preview | 툴 workflow 맥락이 더 강함 |
| 대량 번역 | Gemini 3.1 Flash-Lite | 더 싸고 volume에 강함 |
| 구조화 추출과 분류 | Gemini 3.1 Flash-Lite | 전형적인 저비용 레인 작업 |
| 대규모 batch queue | Gemini 3.1 Flash-Lite | Batch 가격과 queue ceiling이 유리 |
| 혼합 production traffic | split-route | Flash-Lite를 기본, 어려운 것만 Pro로 승격 |
운영 순서로는 보통 이렇게 갑니다.
- 새로운 대량 트래픽은 우선 Flash-Lite에 둔다.
- Pro는 어려운 코딩, 복잡한 도구 흐름, 난도가 높은 reasoning에만 시험한다.
- 거기서 분명한 ROI가 나오면 그 요청군만 Pro 레인으로 분리한다.
이것이 "Pro는 품질, Lite는 가격" 같은 얕은 요약보다 훨씬 실전적입니다. 운영 규칙으로는 다음 한 줄이 가장 유용합니다.
저렴한 루틴 작업은 Flash-Lite를 기본값으로 두고, 어렵고 비싼 작업만 Pro로 올린다. 혼합 부하는 분리 라우팅한다.
Flash-Lite를 더 강한 고속 모델과 비교해서 보고 싶다면 Gemini 3.1 Flash-Lite vs Gemini 3 Flash를, Pro를 더 안정적인 상위 모델과 비교하고 싶다면 Gemini 3.1 Pro vs Gemini 2.5 Pro를 읽어 보세요.
FAQ
Gemini 3.1 Pro Preview가 항상 Gemini 3.1 Flash-Lite보다 낫나요?
어려운 작업에서는 그렇습니다. 하지만 저렴한 루틴 처리에서는 Flash-Lite가 기본값으로 더 합리적입니다.
어느 쪽이 더 저렴한가요?
Flash-Lite입니다. 2026년 3월 20일 기준 Pro는 $2.00 input / $12.00 output, Flash-Lite는 $0.25 input / $1.50 output입니다.
토큰 한도는 같은가요?
같습니다. 두 모델 모두 1,048,576 input tokens와 65,536 output tokens를 제공합니다. 그래서 이 비교는 컨텍스트 크기 경쟁이 아닙니다.
coding agents에는 무엇을 써야 하나요?
복잡하고 도구 의존성이 높다면 Pro부터 시작하는 편이 안전합니다. 단순하고 반복적인 처리라면 Flash-Lite를 baseline으로 둘 수 있습니다.
대규모 번역이나 추출에는 무엇이 더 적합한가요?
Flash-Lite입니다. 공식 포지셔닝, 가격, Batch 경제성이 모두 그 방향을 가리킵니다.