
짧은 답부터 말하면, 2026년 3월 21일 기준으로 기본 모델이 coding subagent, repo 검사, patch loop, OpenAI 네이티브 툴체인을 맡아야 한다면 GPT-5.4 mini가 더 자연스럽습니다. 더 저렴한 멀티모달 처리, 1,048,576 입력 컨텍스트, Google grounding을 더 중시한다면 Gemini 3 Flash가 더 맞습니다.
이 비교는 단순한 benchmark 전쟁처럼 쓰면 오히려 덜 정확해집니다. OpenAI의 현재 latest model guide는 GPT-5.4 mini를 high-volume coding, computer use, agent workflows를 위한 가지로 둡니다. Google의 현재 Gemini 3 Flash 모델 페이지는 Gemini 3 Flash를 가장 강한 fast multimodal lane으로 설명합니다. 출발점부터 product surface가 다릅니다.
그래서 진짜 질문은 “누가 더 강한가”가 아니라 내 fast default가 어떤 workflow를 주로 떠받쳐야 하는가입니다.
핵심 요약
- GPT-5.4 mini를 고를 때: 모델이 OpenAI 생태계 안에서 coding worker처럼 움직여야 하고
hosted shell,apply patch,MCP,tool search가 실제 가치일 때. - Gemini 3 Flash를 고를 때: 더 싼 멀티모달 처리, 1.05M 컨텍스트, Search / Maps grounding이 더 중요할 때.
- Google 쪽 추가 체크: 비용이 가장 큰 이유라면 다음으로 Gemini 3.1 Flash-Lite vs Gemini 3 Flash도 봐야 합니다.
| 항목 | GPT-5.4 mini | Gemini 3 Flash | 실무 해석 |
|---|---|---|---|
| 출시일 | 2026년 3월 17일 | 2025년 12월 17일 | 둘 다 현재 라인업 |
| 공식 역할 | high-volume coding, computer use, agents | Google의 strongest fast multimodal lane | 역할 차이가 더 큼 |
| Input 가격 | $0.75 / 1M | $0.50 / 1M | Gemini가 더 저렴 |
| Output 가격 | $4.50 / 1M | $3.00 / 1M | 여기서도 Gemini가 유리 |
| Context window | 400,000 | 1,048,576 | 긴 문맥은 Gemini가 우위 |
| Max output | 128,000 | 65,536 | 출력 상한은 GPT-5.4 mini가 큼 |
| Knowledge cutoff | 2025-08-31 | 2025년 1월 | GPT-5.4 mini가 더 최신 |
| 핵심 도구 차이 | hosted shell, apply patch, MCP, tool search, image generation | grounding, URL context, Maps, 1M input | 브랜드보다 product surface 차이 |
OpenAI 안에서 default를 어떻게 나눌지 보고 싶다면 GPT-5.4 vs GPT-5.4 mini를, Google 쪽 cheaper lane을 보고 싶다면 Gemini 3.1 Flash-Lite vs Gemini 3 Flash를 이어서 보는 편이 자연스럽습니다.
이 비교가 깔끔한 벤치마크 대결이 아닌 이유
빠른 비교 글들은 벤더마다 다른 benchmark 줄을 한 표에 모아 놓고 승자를 선언하곤 합니다. 이 키워드에서는 그 방식이 특히 위험합니다.
OpenAI는 2026년 3월 17일 GPT-5.4 mini 공개에서 SWE-Bench Pro, Toolathlon, GPQA Diamond, OSWorld-Verified 같은 coding·tool use 중심 지표를 강조합니다. 반면 Google은 Gemini 3 Flash를 GPT-5.4 mini와 정면 비교하는 공식 점수표를 내놓지 않습니다. 대신 model page, pricing, rate limits, tool support, changelog로 설명합니다.
그래서 이 주제에서 더 믿을 수 있는 비교 방식은 다음입니다.
- 공식적으로 어떤 workload를 상정하는지
- 현재 가격과 token limit가 어떤지
- 어떤 tool surface와 grounding을 제공하는지
- 그 차이가 실제 routing을 어떻게 바꾸는지
이렇게 보면 이 글은 benchmark 승부라기보다 routing 판단서에 더 가깝습니다.
가격, 컨텍스트, 도구 면이 브랜드보다 더 중요하다
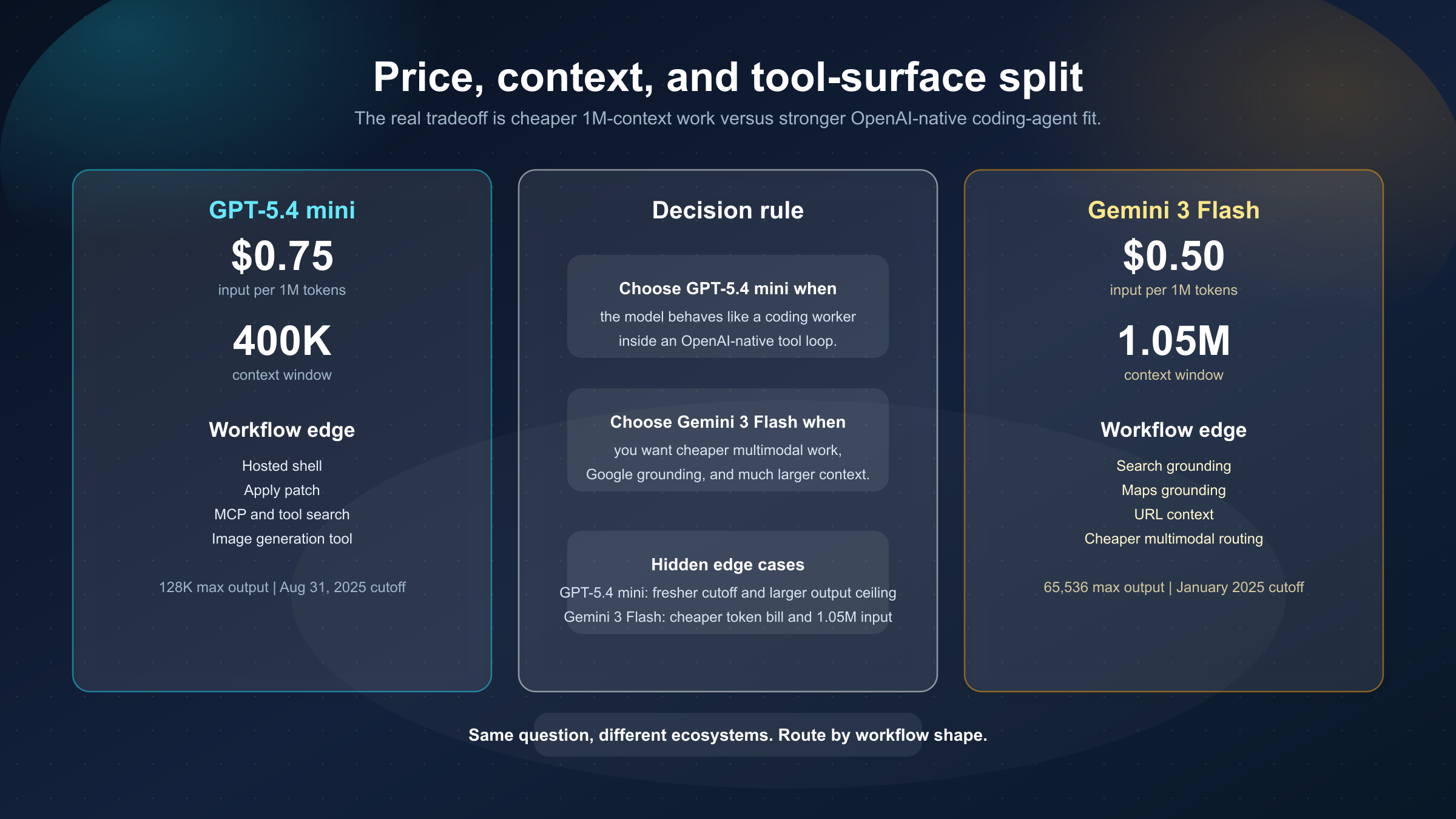
가장 쉽게 검증되는 차이는 가격입니다. 2026년 3월 21일 기준으로:
- GPT-5.4 mini 모델 페이지는 $0.75 input, $0.075 cached input, $4.50 output
- Gemini pricing 페이지는 Gemini 3 Flash에 $0.50 input, $3.00 output
을 적고 있습니다.
즉 GPT-5.4 mini는 표준 input / output 기준으로 Gemini 3 Flash보다 대략 1.5배 비쌉니다.
두 번째 큰 차이는 컨텍스트입니다. GPT-5.4 mini는 400,000, Gemini 3 Flash는 1,048,576 입력 토큰입니다. 긴 repo, 문서 묶음, 스크린샷, 로그, 긴 히스토리를 한 작업 세트에 올리고 싶다면 Gemini 3 Flash가 훨씬 편합니다.
하지만 GPT-5.4 mini도 완전히 밀리지는 않습니다. 최대 출력이 128,000이고 Gemini 3 Flash는 65,536입니다. 긴 diff나 큰 산출물을 뽑는 워크플로에서는 이 차이가 의외로 중요합니다.
그리고 진짜 갈림길은 tool surface입니다.
GPT-5.4 mini는 현재 다음을 지원 항목으로 보여줍니다.
- web search
- file search
- image generation
- code interpreter
- hosted shell
- apply patch
- skills
- computer use
- MCP
- tool search
Gemini 3 Flash는 현재 다음을 보여줍니다.
- batch API
- caching
- code execution
- computer use
- file search
- Search grounding
- Maps grounding
- structured outputs
- thinking
- URL context
핵심은 “누가 도구가 있느냐”가 아닙니다. GPT-5.4 mini는 OpenAI-native coding agent loop에 더 잘 붙고, Gemini 3 Flash는 더 저렴한 대규모 컨텍스트 멀티모달 fast lane에 더 잘 붙는다는 점입니다.
GPT-5.4 mini가 기본값으로 더 나은 경우

GPT-5.4 mini는 모델이 단순히 빠른 텍스트 생성기가 아니라 OpenAI 툴 환경 안에서 coding worker처럼 움직여야 할 때 강합니다.
대표적인 경우는 다음과 같습니다.
1. coding subagents와 worker fleet. OpenAI가 애초에 그렇게 포지셔닝하고 있습니다. high-volume coding과 agent workflows에 맞춘 가지라는 뜻입니다.
2. repo / patch loop. hosted shell, apply patch, MCP, tool search가 중요하다면 GPT-5.4 mini가 실제 작업 형태에 더 가깝습니다.
3. 이미 OpenAI 쪽으로 표준화된 팀. prompts, evals, tools, 운영 습관이 Responses API나 Codex 스타일에 이미 맞춰져 있다면, 생태계를 바꾸는 비용이 token 차이보다 더 클 수 있습니다.
4. 긴 output이 필요한 worker. 128K output ceiling은 긴 patch, 상세 artifact, verbose structured result에서 꽤 실용적입니다.
즉 GPT-5.4 mini를 고르는 가장 강한 이유는 “OpenAI가 더 낫다”가 아니라, coding subagent로서의 workflow fit이 훨씬 일관되다는 점입니다.
Gemini 3 Flash가 기본값으로 더 나은 경우
Gemini 3 Flash는 더 저렴한 fast lane, 더 큰 컨텍스트, Google grounding을 우선할 때 더 자연스럽습니다.
대표적으로는 이런 경우입니다.
1. large-context multimodal work. 1,048,576 입력 창은 긴 문서, 큰 repo, screenshot-heavy flow, 긴 대화 히스토리에서 큰 장점입니다.
2. 더 저렴한 serious throughput. Gemini 3 Flash는 Google 안에서 가장 싼 fast lane은 아니지만 GPT-5.4 mini보다는 분명히 싸게 나옵니다.
3. grounding이 제품 가치의 핵심일 때. Search grounding과 Maps grounding이 중요하다면 Gemini 3 Flash는 단순히 “싼 모델”이 아닙니다.
4. coding 전용이 아닌 broad multimodal fast lane이 필요할 때. 텍스트, 이미지, PDF, 영상, 오디오를 두루 다루는 앱이라면 Gemini 3 Flash가 더 자연스러운 default일 수 있습니다.
한 줄로 줄이면:
- GPT-5.4 mini는 OpenAI 쪽 coding subagent lane
- Gemini 3 Flash는 Google 쪽 cheaper large-context multimodal lane
많은 사람이 놓치는 Google 쪽 caveat

이 부분은 SERP에서 자주 빠집니다.
Gemini 쪽으로 기울게 만드는 가장 큰 이유가 “GPT-5.4 mini보다 싸다”라면, 한 번 더 물어봐야 합니다. 정말 Gemini 3 Flash가 필요한가, 아니면 사실 Gemini 3.1 Flash-Lite가 필요한가?
pricing과 rate limits를 보면 Flash-Lite는 Flash보다 더 싸고, 공개 Tier 1 batch lane도 더 큽니다.
이건 Flash-Lite가 더 강하다는 뜻이 아닙니다. Google 안에서도 fast lane이 이미 둘로 갈라져 있다는 뜻입니다.
- Gemini 3 Flash: 더 강한 fast lane
- Gemini 3.1 Flash-Lite: 더 저렴하고 throughput-heavy한 lane
그래서 비용이 핵심 이유라면, GPT-5.4 mini의 진짜 Google-side 대안은 Flash일 수도 있지만 Flash-Lite일 가능성도 큽니다.
실제 배포 전에 무엇을 측정해야 하나
이 둘 중 하나를 실제 production default로 올릴 생각이라면, 토큰 단가나 평균 지연 시간만 보는 것으로는 부족합니다. 더 중요한 것은 성공적으로 끝난 작업 1건당 총비용입니다. 여기에는 재시도, tool 실패, 사람 검수, 컨텍스트 압축, fallback 전환 비용까지 들어갑니다.
가장 실용적인 방법은 작업을 먼저 나누는 것입니다. planner, repo worker, multimodal analysis, grounded answer, long-context synthesis는 같은 축에서 평가하면 안 됩니다. 어떤 가지가 OpenAI-native coding loop에 가깝고, 어떤 가지가 Google 쪽 large-context multimodal lane에 가까운지 먼저 구분해야 합니다.
실무에서는 다음 같은 테스트 표가 유용합니다.
| workload | 먼저 시험할 모델 | 우선 볼 지표 | 갈아타는 조건 |
|---|---|---|---|
| repo patch worker | GPT-5.4 mini | patch 품질, tool 호출 안정성, 긴 output 완성률 | 어려운 분기 실패 비용이 커지면 상향 |
| planner / orchestration | GPT-5.4 mini와 Gemini 3 Flash 병행 | 계획 일관성, 컨텍스트 압박, 되돌림 비율 | working set이 커지면 Gemini 쪽 유지 |
| multimodal analysis | Gemini 3 Flash | 긴 문맥 유지, 이미지 이해, 총비용 | code-edit loop가 핵심이면 mini 재검토 |
| grounded answer | Gemini 3 Flash | Search / Maps grounding의 실제 가치 | grounding이 약하면 mini 재평가 |
이 표의 의미는 단순합니다. GPT-5.4 mini는 coding worker로, Gemini 3 Flash는 large-context multimodal fast lane으로 평가해야 한다는 것입니다. 어느 모델이 더 “고급”인지 따지는 것보다, 어떤 가지에서의 실패가 가장 비싼지를 먼저 측정하는 편이 운영에는 훨씬 도움이 됩니다.
또 하나는 컨텍스트 전략입니다. Gemini 3 Flash의 1,048,576 입력 창은 분명 큰 장점이지만, 노이즈까지 잔뜩 넣는 설계라면 오히려 prompt 품질이 무너집니다. GPT-5.4 mini는 창이 더 작아도 작업이 명확한 tool loop에 잘 맞으면 총비용과 안정성 면에서 더 좋은 기본값이 될 수 있습니다.
자주 묻는 질문
GPT-5.4 mini로 serious한 coding agent를 돌려도 충분한가?
많은 경우 충분합니다. OpenAI가 애초에 high-volume coding, computer use, agent workflows를 위해 내놓은 모델이기 때문입니다. giant-context synthesis보다 repo 작업, patch, tool 실행이 더 중요한 체인이라면 mini가 충분히 실전적입니다.
Gemini 3 Flash의 핵심 장점은 가격뿐인가?
그렇지 않습니다. 가격도 중요하지만 1,048,576 입력 컨텍스트와 Google grounding이 실제로 더 큰 차이를 만들 수 있습니다. 겉으로는 coding task처럼 보여도, 실제 실패 원인은 patch 품질이 아니라 문서와 히스토리를 한 번에 충분히 보지 못하는 데 있을 때가 많습니다.
라우팅 없이 하나만 골라도 되나?
가능은 하지만 보통 최적은 아닙니다. 단일 default는 운영을 단순하게 만들지만, 어떤 가지에서는 과하게 비싸고 다른 가지에서는 headroom이 부족해질 수 있습니다. 많은 팀에서는 coding execution은 GPT-5.4 mini, long-context multimodal 분석은 Gemini 3 Flash로 나누는 편이 더 안정적입니다.
추가로 rollout 전에 봐야 할 것은 평균 성능보다 실패 꼬리입니다. GPT-5.4 mini가 대부분의 요청을 잘 처리하더라도, 특정 어려운 patch chain에서 한 번 실패할 때마다 사람 검수와 재실행 비용이 크게 붙는다면 그 가지는 더 이상 싸지 않습니다. 반대로 Gemini 3 Flash가 큰 컨텍스트를 잘 유지하더라도 실제 workload가 그 headroom을 거의 쓰지 않는다면, 팀은 필요 없는 능력에 비용을 내는 셈입니다. 결국 중요한 것은 모델 이름보다 어떤 failure mode가 가장 비싼지 먼저 파악하는 일입니다.
좋은 운영 기준은 “더 똑똑한 모델”이 아니라 “더 비싼 실패를 줄여 주는 모델”입니다.
결론
가장 실무적인 규칙은 이렇습니다.
- 기본 모델이 coding agent / subagent라면 GPT-5.4 mini
- 기본 모델이 더 싼 멀티모달 fast lane + 1.05M 컨텍스트 + Google grounding이라면 Gemini 3 Flash
많은 팀에서 가장 방어 가능한 답은 하나의 절대 승자를 정하는 것이 아니라 작업 유형별 routing입니다.
- code-edit worker, repo loop, tool-heavy execution은 GPT-5.4 mini
- 더 저렴한 multimodal analysis, long-context synthesis, grounded task는 Gemini 3 Flash
결국 이 비교가 명확해지는 순간은 “누가 더 좋나”를 묻는 대신 “내 fast default가 어떤 workflow를 들어야 하나”를 묻는 순간입니다.