2026년 3월 20일 기준으로 가장 실무적인 결론은 이렇습니다. 더 강한 coding, computer use, 무거운 agent workflow가 필요하면 GPT-5.4 mini를, 비용 우선의 high-throughput 작업이면 GPT-5.4 nano를 선택하는 편이 맞습니다. OpenAI는 2026년 3월 17일 출시 글에서 GPT-5.4 mini를 coding과 subagents용 더 강한 소형 모델로, GPT-5.4 nano를 classification, data extraction, ranking, 더 단순한 supporting subagents용으로 명시했습니다.
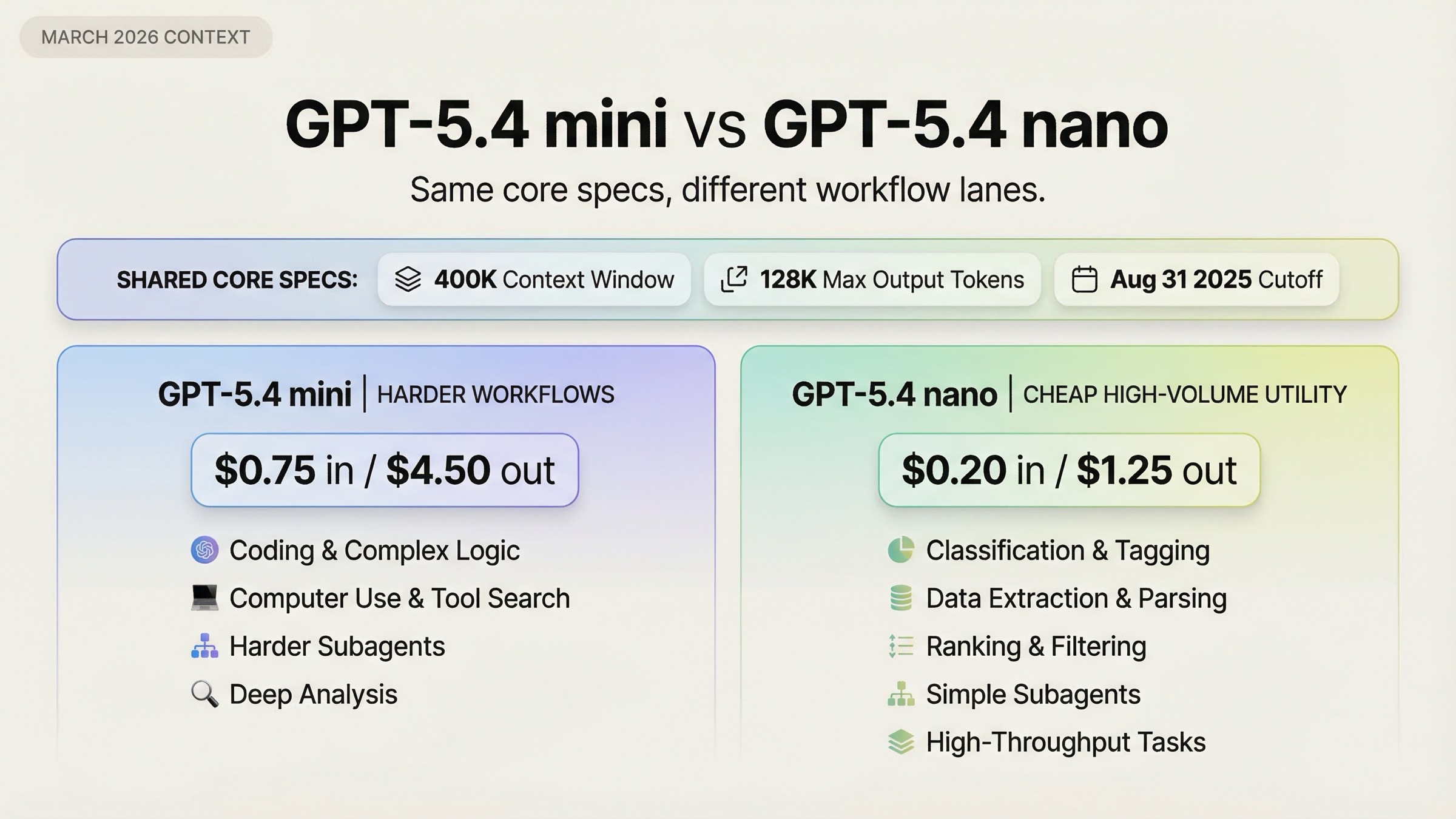
이 비교가 헷갈리는 이유는 두 모델이 실제보다 더 비슷해 보이기 때문입니다. 둘 다 400K context window, 128K max output, 2025-08-31 knowledge cutoff를 공유합니다. 그래서 스펙 표만 보면 차이는 가격뿐처럼 느껴집니다. 하지만 실제 질문은 다릅니다. 내 workload가 mini의 추가 도구·성능·workflow 깊이를 실제로 필요로 하는지, 아니면 충분히 단순해서 nano가 더 올바른 운영점인지가 핵심입니다.
핵심 요약
바로 써먹을 수 있는 답은 아래 표로 요약됩니다.
| 모델 | 더 잘 맞는 작업 | 고르는 이유 | 망설일 이유 |
|---|---|---|---|
| GPT-5.4 mini | coding assistant, 스크린샷 중심 workflow, browser/desktop automation, 무거운 subagents | coding·tool use·computer use가 더 강하고 computer use와 tool search를 지원 | 비싸다: 1M tokens 기준 input $0.75 / output $4.50 |
| GPT-5.4 nano | classification, extraction, ranking, 저비용 routing, 단순 subagents | input $0.20 / output $1.25로 훨씬 저렴하고 context와 cutoff는 mini와 동일 | computer use와 tool search가 없고, 무거운 tool-driven 작업에서는 더 약함 |
판단 규칙을 더 압축하면 다음과 같습니다.
- 코드를 읽고, tool failure에서 복구하고, UI를 다루는 worker라면 GPT-5.4 mini.
- 분류, 추출, 정렬, 라우팅, 값싼 지원 작업이 중심이면 GPT-5.4 nano.
- 시스템이 혼합형이라면 "둘 중 하나"보다 "mini는 heavy lane, nano는 cheap lane" 구조가 더 강하다.
- ChatGPT에서 보이는 모델 이름만 보고 API 선택을 하지 않는다.
핵심 분기점은 context가 아니라 workflow 깊이
많은 비교 글은 price, context, cutoff부터 시작합니다. 하지만 이 키워드에서는 그 정보만으로는 실무 판단이 되지 않습니다.
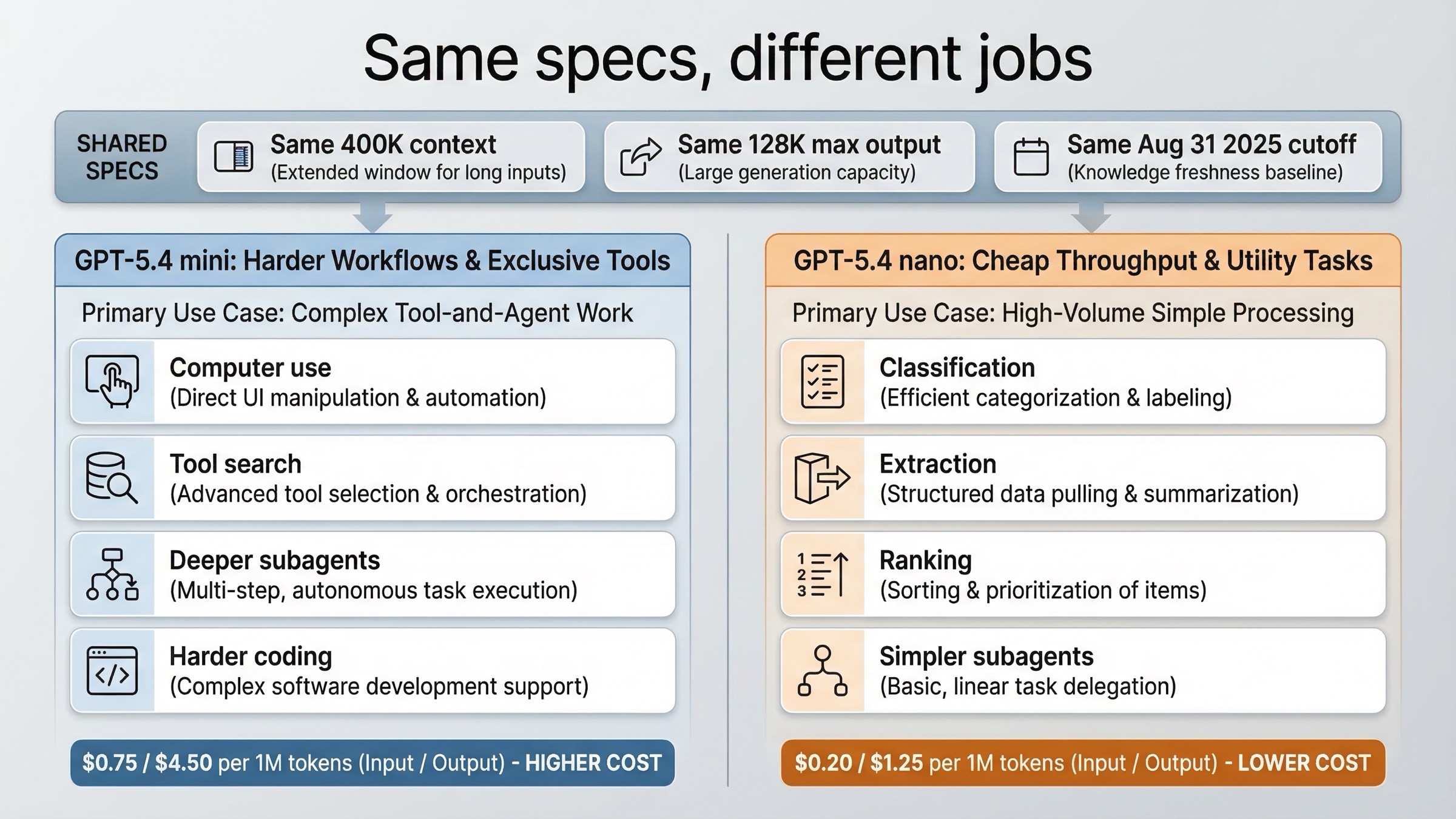
현재 OpenAI model page 기준으로 GPT-5.4 mini와 GPT-5.4 nano는 다음을 공유합니다.
- 400K context window
- 128K max output
- 2025년 8월 31일 knowledge cutoff
- text와 image input
즉, 여기서의 선택은 "누가 더 큰 context를 갖는가"가 아닙니다. 겉스펙은 거의 동률입니다.
차이는 생산 시스템 안에서 무엇을 시키느냐에서 벌어집니다.
GPT-5.4 guide는 GPT-5.4 mini를 high-volume coding, computer use, strong reasoning이 필요한 agent workflows용으로, GPT-5.4 nano를 speed와 cost가 가장 중요한 simple high-throughput tasks용으로 설명합니다. 이 framing이 실제 선택에는 훨씬 도움이 됩니다.
정리하면 다음과 같습니다.
| 질문 | Yes라면 | 더 맞는 모델 |
|---|---|---|
| 실제 coding이나 codebase 작업이 필요한가 | coding benchmark와 agent reliability가 중요 | GPT-5.4 mini |
| built-in computer use나 UI 기반 작업이 필요한가 | 스크린샷과 인터페이스를 중심으로 움직임 | GPT-5.4 mini |
| extraction, ranking, classification이 중심이고 물량이 큰가 | throughput과 cost가 우선 | GPT-5.4 nano |
| 더 큰 planner 아래 cheap worker가 필요한가 | 가장 저렴하지만 쓸만한 실행기가 필요 | GPT-5.4 nano |
이 틀로 보면 가격 차이의 의미도 분명해집니다. mini는 context가 더 커서 비싼 것이 아니라, 더 강한 tool-and-agent worker이기 때문에 비싼 것입니다.
가격, rate limits, 도구 지원 비교
벤치마크를 보기 전에 먼저 가격 차이를 정면으로 봐야 합니다.
2026년 3월 20일 기준으로 확인한 GPT-5.4 mini 모델 페이지와 GPT-5.4 nano 모델 페이지의 핵심 항목은 다음과 같습니다.
| 항목 | GPT-5.4 mini | GPT-5.4 nano |
|---|---|---|
| Input 가격 | $0.75 / 1M tokens | $0.20 / 1M tokens |
| Cached input | $0.075 / 1M tokens | $0.02 / 1M tokens |
| Output 가격 | $4.50 / 1M tokens | $1.25 / 1M tokens |
| Context window | 400K | 400K |
| Max output | 128K | 128K |
| Knowledge cutoff | 2025-08-31 | 2025-08-31 |
| Snapshot | gpt-5.4-mini-2026-03-17 | gpt-5.4-nano-2026-03-17 |
즉 mini는 input 기준 약 3.75배, cached input 기준도 약 3.75배, output 기준 3.6배 비쌉니다. 이건 무시할 수준의 차이가 아닙니다.
rate limits는 생각보다 가깝습니다. OpenAI의 compare models page를 보면 차이는 주로 lower paid tiers에 몰려 있습니다.
| Tier | GPT-5.4 mini TPM | GPT-5.4 nano TPM |
|---|---|---|
| Tier 1 | 500,000 | 200,000 |
| Tier 2 | 2,000,000 | 2,000,000 |
| Tier 3 | 4,000,000 | 4,000,000 |
| Tier 4 | 10,000,000 | 10,000,000 |
| Tier 5 | 180,000,000 | 180,000,000 |
그래서 paid production에서는 TPM보다 task fit과 단가가 더 본질적입니다.
도구 차이는 더 중요합니다.
| 기능 | GPT-5.4 mini | GPT-5.4 nano |
|---|---|---|
| Web search | Yes | Yes |
| File search | Yes | Yes |
| Image generation tool | Yes | Yes |
| Code interpreter | Yes | Yes |
| Hosted shell | Yes | Yes |
| Apply patch | Yes | Yes |
| Skills | Yes | Yes |
| Computer use | Yes | No |
| MCP | Yes | Yes |
| Tool search | Yes | No |
여기서부터 의미가 확 달라집니다.
nano는 "심하게 깎인 값싼 장난감 모델"이 아닙니다. hosted shell, apply patch, skills, image generation까지 지원하므로, 좁은 agent task용 worker로는 꽤 유능합니다.
하지만 mini는 더 무거운 agent workflow를 가르는 핵심 capability 두 개를 갖고 있습니다. computer use와 tool search입니다. 스크린샷을 읽으며 software를 다루거나, 넓은 tool surface 안에서 적절한 도구를 찾아야 한다면 이 차이는 그대로 아키텍처 차이가 됩니다.
그래서 이 비교는 "더 싸냐, 더 세냐"로 끝나면 안 됩니다. 내 product가 그 추가 workflow capability에 비용을 낼 가치가 있는가가 핵심입니다.
의사결정을 바꾸는 benchmark 차이
OpenAI의 2026년 3월 17일 launch post는 mini와 nano를 가장 깔끔하게 비교한 공식 자료입니다.
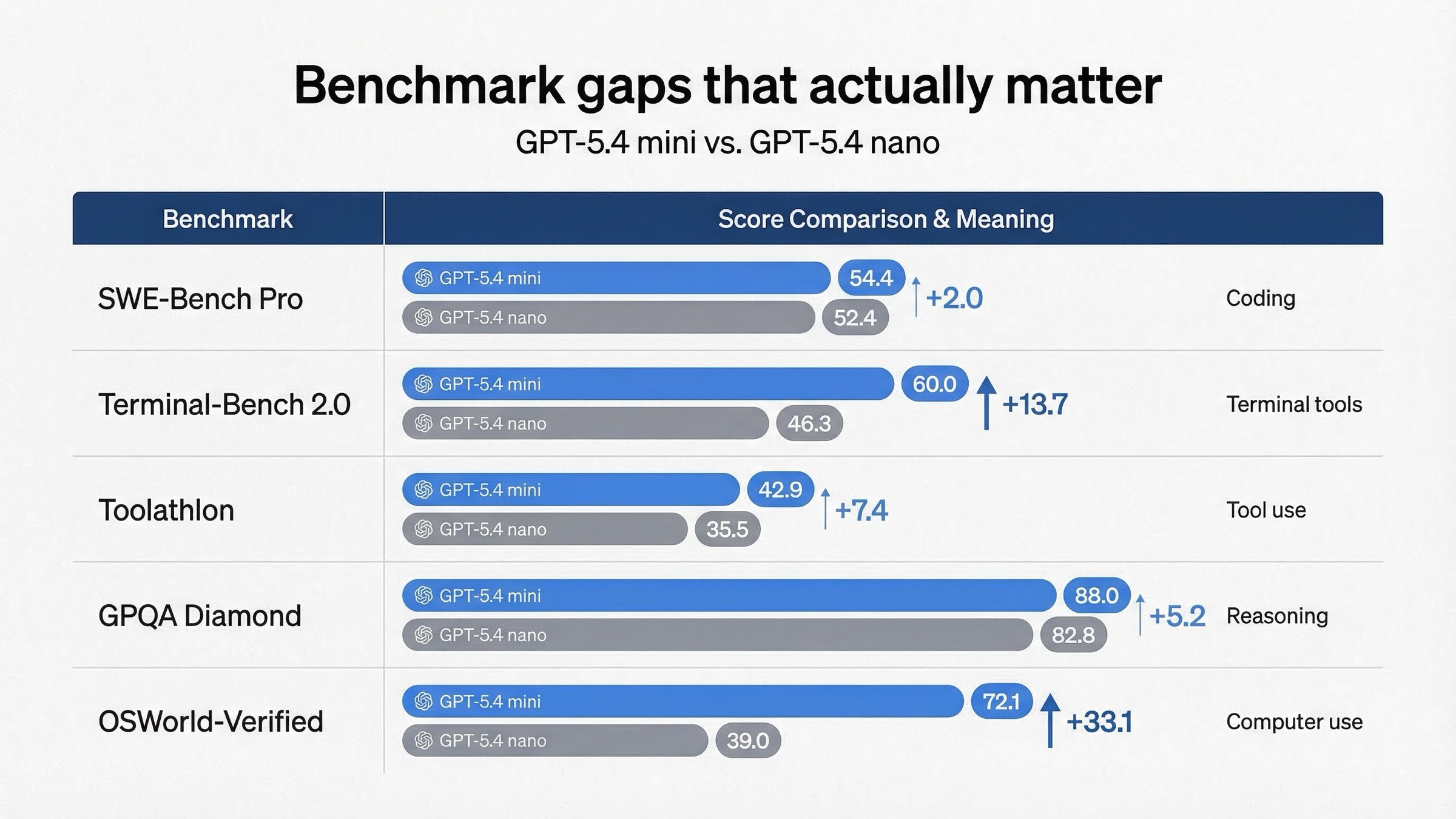
| Launch post의 benchmark | GPT-5.4 mini | GPT-5.4 nano | 실무 해석 |
|---|---|---|---|
| SWE-Bench Pro (Public) | 54.4% | 52.4% | 실제 software issue 해결에서는 mini가 약간 더 강함 |
| Terminal-Bench 2.0 | 60.0% | 46.3% | terminal-heavy tool work에서는 mini 우위가 큼 |
| Toolathlon | 42.9% | 35.5% | tool use reliability는 mini가 더 높음 |
| GPQA Diamond | 88.0% | 82.8% | 어려운 reasoning에서 mini의 여유가 더 큼 |
| OSWorld-Verified | 72.1% | 39.0% | computer-use workflow는 mini가 훨씬 강함 |
여기서 중요한 것은 세 가지입니다.
첫째, mini의 우위가 모든 방향에서 같은 무게를 갖지는 않습니다. SWE-Bench 차이는 실제지만, 모든 coding task가 자동으로 mini 필수라는 뜻은 아닙니다. 단순한 보조 subtask라면 nano도 가능합니다.
둘째, mini가 실제로 크게 벌리는 지점은 terminal-heavy, tool-heavy, computer-use-heavy 작업입니다. 이는 tool-support 차이와도 정확히 맞닿아 있습니다.
셋째, nano는 약한 모델이 아니라 cheap lane에 충분한 성능 바닥을 가진 모델입니다. OpenAI의 메시지는 명확합니다. 간단한 supporting task를 싸게 많이 돌리고 싶으면 nano, 그 supporting task조차 무거워지면 mini입니다.
현재 검색결과의 약점은 이 부분을 설명하지 않는다는 데 있습니다. 숫자는 보여주지만, 어떤 숫자가 budget decision을 움직이는지까지는 연결하지 못합니다.
실무 규칙은 간단합니다.
- tool failure나 slow recovery가 UX나 engineering cost를 직접 건드리면 mini에 비용을 지불할 가치가 큽니다.
- task가 충분히 싸고 좁고 반복적이라면 nano가 더 옳은 답입니다.
GPT-5.4 mini에 추가 비용을 낼 만한 경우
GPT-5.4 mini가 진짜 값을 하는 곳은, 모델이 cheap classifier가 아니라 더 강한 operator처럼 움직여야 하는 경우입니다.
가장 쉬운 예는 coding assistants입니다. OpenAI는 mini를 coding workflows용으로 위치시키고 있고, benchmarks도 이를 지지합니다. codebase를 가로지르고, 여러 파일을 읽고, failed tool call에서 회복하고, diff를 이해하고, coding harness 안에서 안정적으로 돌아야 한다면 mini가 더 방어적인 default입니다.
다음은 computer use와 screenshot-heavy workflows입니다. 여기서 mini는 특히 크게 앞섭니다. UI를 읽고, software를 통해 동작하고, 밀도 높은 스크린샷을 구조적 루프 안에서 해석해야 한다면 mini는 단순 상위 버전이 아니라, 이 pair 안에서 유일하게 built-in computer use를 가진 모델입니다.
세 번째는 heavier subagent tasks입니다. launch post는 Codex형 위임 구조를 직접 언급합니다. 큰 모델이 planning을 하고, 작은 모델이 subtasks를 병렬 처리하는 구조에서, 그 subtasks가 여전히 coding judgment나 tool choice를 요구한다면 mini가 더 적합한 worker입니다.
네 번째는 더 복잡한 tool ecosystem입니다. tool search는 쉽게 간과되지만, tools, namespaces, MCP surfaces가 많아지면 중요해집니다. toolset이 작고 고정돼 있으면 nano도 가능하지만, 복잡해질수록 mini가 안전합니다.
아래 조건이 많을수록 GPT-5.4 mini를 선택할 가치가 큽니다.
- 모델이 실질적인 coding 작업을 한다.
- computer use나 screenshot-grounded reasoning이 필요하다.
- tool failure가 retries, latency, trust loss로 이어진다.
- agent system의 worker이지만 subtask도 결코 얕지 않다.
- 순수 token 단가보다 hidden engineering cost가 더 크다.
마지막 항목이 특히 중요합니다. 재시도, fallback, 복잡한 prompts, 수동 개입, 사용자 대기 시간도 다 비용입니다. mini는 이런 hidden cost를 줄일 수 있을 때 가치가 커집니다.
GPT-5.4 nano가 더 올바른 default가 되는 경우
GPT-5.4 nano는 "예산이 없을 때 어쩔 수 없이 쓰는 모델"이 아닙니다. 애초에 cheap lane에 둬야 할 task라면 오히려 가장 올바른 default가 됩니다.
OpenAI는 nano를 classification, data extraction, ranking, simpler coding subagents용으로 직접 추천합니다. 운영 작업으로 바꾸면 대략 다음과 같습니다.
- user intent나 support ticket 분류
- 텍스트에서 구조화 필드 추출
- 후보 결과 ranking 및 filtering
- 후속 시스템으로 request routing
- 큰 planner 아래 cheap supporting task 수행
이런 업무에서는 높은 benchmark ceiling보다 낮은 비용과 throughput이 제품 가치에 더 직접적으로 연결됩니다.
nano는 전체 시스템은 복잡하지만 특정 task는 얕을 때도 잘 맞습니다. 예를 들어 더 큰 planner나 강한 worker가 어려운 분기를 맡고, nano는 다음만 처리하는 식입니다.
- tool output을 요약해 planner에게 되돌려주기
- candidate documents 선별
- downstream rule engine용 field extraction
- cheap validation이나 routing
따라서 nano는 "약한 범용 모델"이 아니라 "단순 lane용 저비용 specialist"로 보는 편이 정확합니다.
다음 조건이 많다면 GPT-5.4 nano가 더 좋은 기본값입니다.
- task가 좁고 반복적이며 구조적으로 단순하다.
- edge-case capability보다 unit economics가 중요하다.
- built-in computer use가 필요 없다.
- 넓은 tool surface에 대한 tool search가 필요 없다.
- 더 큰 coordinator 아래 supporting worker를 설계하고 있다.
즉, 질문이 "누가 더 강하냐"가 아니라 "가장 싸면서도 이 작업을 충분히 해내는 모델이 뭐냐"라면 nano가 답입니다.
많은 시스템에서 정답은 하나가 아니라 둘 다다
이 부분이야말로 많은 비교 글이 빠뜨리지만, 실제로는 가장 실용적인 파트입니다.
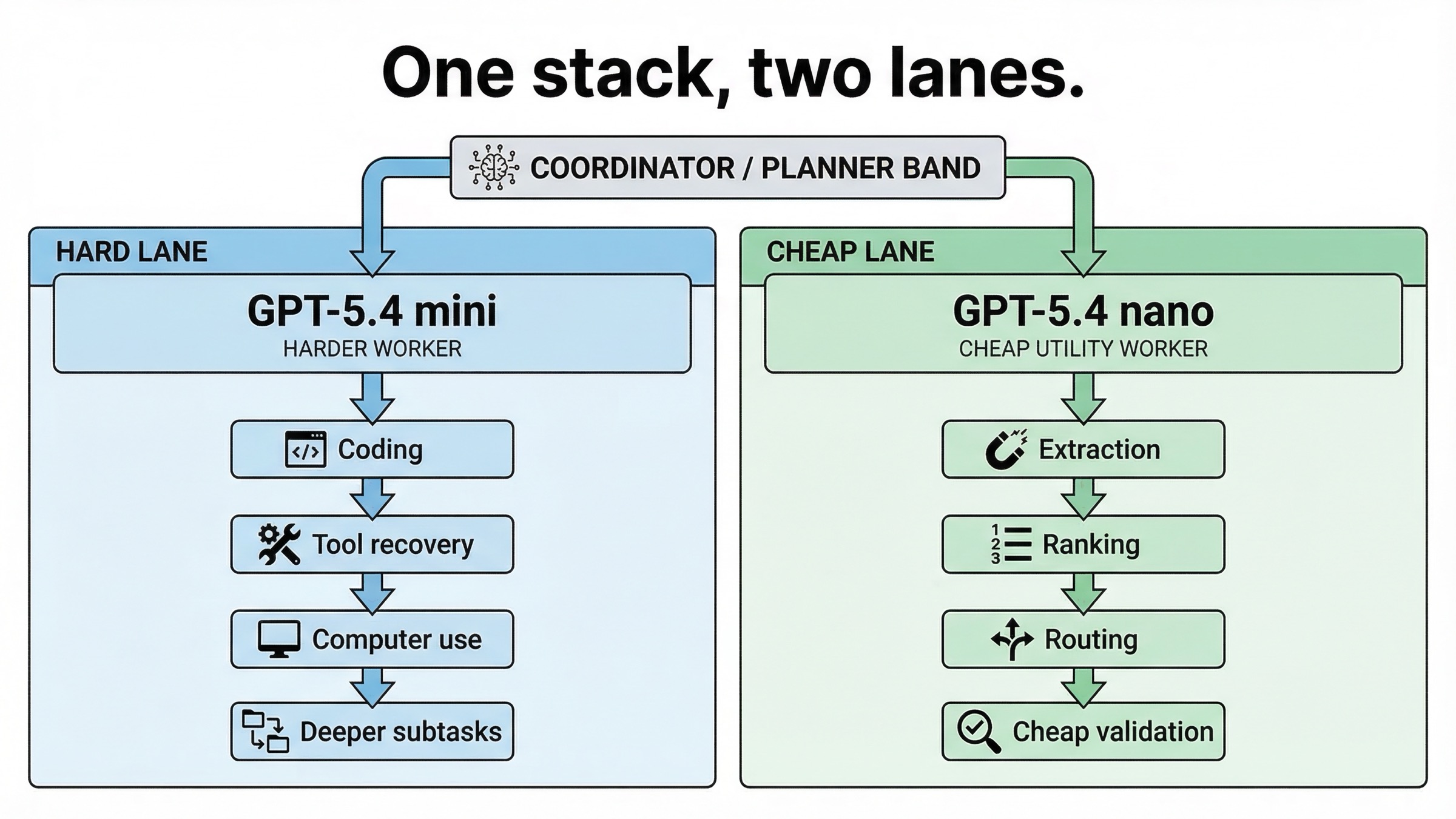
제품에 request type이 하나뿐이라면 mini와 nano 중 하나를 고르면 됩니다. 하지만 실제 시스템은 최소 두 개의 lane을 가지는 경우가 많습니다.
- coding, tool recovery, screenshot interpretation, 더 깊은 reasoning이 들어가는 heavy lane
- extraction, ranking, classification, support task가 많은 cheap lane
성격이 이렇게 다르면 한 모델로 모두 처리하려 하기보다, lane별로 나누는 편이 더 낫습니다.
실무적인 split은 대체로 다음과 같습니다.
| Lane | 더 잘 맞는 모델 | 이유 |
|---|---|---|
| planner 옆에서 도는 stronger worker | GPT-5.4 mini | coding depth, tool reliability, computer-use 성향에서 우위 |
| cheap helper / support worker | GPT-5.4 nano | 좁고 반복적인 task에서 economics가 더 좋음 |
이것이 launch post가 subagents를 설명하면서 실제로 암시하는 구조이기도 합니다. mini는 더 강한 worker 역할, nano는 더 싼 utility lane 역할을 맡는 방식입니다. subtask가 충분히 단순하다면 이 분리가 가장 자연스럽습니다.
따라서 팀이 "mini로 통일할지 nano로 통일할지"를 두고 고민한다면, 더 좋은 답은 먼저 routing logic을 정하고 그다음 lane마다 model을 배치하는 것입니다.
API, Codex, ChatGPT를 섞어서 판단하면 안 되는 이유
이 키워드는 서로 다른 product surface에서 들어오는 검색이 섞여 있어서 혼란이 큽니다.
API 기준으로는 답이 단순합니다.
- GPT-5.4 mini는 API에서 사용 가능
- GPT-5.4 nano도 API에서 사용 가능
Codex 쪽은 launch post가 더 구체적입니다. GPT-5.4 mini는 Codex app, CLI, IDE extension, web에서 사용 가능하고, Codex는 GPT-5.4 mini subagents에 subtasks를 위임할 수 있다고 설명합니다. 반면 GPT-5.4 nano는 같은 방식으로 Codex의 주 surface model로 다뤄지지 않습니다.
ChatGPT는 더 쉽게 오해됩니다. launch post에는 GPT-5.4 mini가 일부 ChatGPT path에서 이용 가능하다고 쓰여 있지만, 현재 Help Center 문서는 logged-in users의 default line이 GPT-5.3이고, paid tiers가 수동 선택하는 것은 GPT-5.4 Thinking이라고 설명합니다. 즉 ChatGPT에서 보이는 경험을 그대로 API recommendation에 대응시키면 안 됩니다.
정말 API 모델을 고르는 문제라면 model pages와 launch post를 보세요. ChatGPT에서 무엇이 보이는지 알고 싶다면 Help Center를 보세요. 이름은 겹쳐도 의사결정 면은 다릅니다.
FAQ
GPT-5.4 mini가 항상 GPT-5.4 nano보다 더 좋은가요?
성능은 더 강하지만, 항상 더 적합한 것은 아닙니다. 단순 high-volume task에서는 nano가 더 낮은 비용으로 충분한 답이 될 수 있습니다.
coding에는 무엇을 써야 하나요?
실제 coding work라면 mini입니다. 더 큰 coding system 안의 단순 supporting subagent라면 nano도 가능할 수 있습니다. tool flow가 복잡해질수록 답은 mini 쪽으로 갑니다.
extraction이나 ranking에는 무엇을 써야 하나요?
OpenAI가 nano를 classification, data extraction, ranking용으로 직접 권장합니다. 따라서 기본은 nano부터 테스트하는 것이 맞습니다.
GPT-5.4 nano도 tools를 쓸 수 있나요?
예. nano도 web search, file search, image generation, code interpreter, hosted shell, apply patch, skills, MCP를 지원합니다. mini와의 핵심 차이는 computer use와 tool search입니다.
새 팀은 mini와 nano 중 어디서 시작해야 하나요?
이름이 아니라 실제 job-to-be-done에서 시작해야 합니다. coding-heavy, agent-heavy 작업이면 mini, cheap throughput이면 nano, 둘 다 있으면 둘 다 lane별로 쓰는 것이 맞습니다.
최종 권장안
팀에 한 줄로 전달해야 한다면 이렇게 말하면 됩니다. 무거운 coding과 agent workflow에는 GPT-5.4 mini, 저렴한 high-volume utility work에는 GPT-5.4 nano가 올바른 기본값입니다.
이 결론은 2026년 3월 20일 기준 확인한 다섯 가지 사실 위에 서 있습니다.
- 두 모델은 같은 context window, max output, knowledge cutoff를 공유합니다.
- nano는 훨씬 저렴합니다.
- mini는 coding, tool use, computer use 관련 benchmarks에서 더 강합니다.
- mini는 computer use와 tool search를 지원하고 nano는 지원하지 않습니다.
- OpenAI는 nano를 classification, extraction, ranking, 단순 supporting subagents용으로 권장합니다.
그래서 실제 질문은 "누가 더 강하냐"가 아닙니다. 더 강한 것은 mini입니다. 진짜 질문은 내 task가 mini를 필요로 할 만큼 무거운지, 아니면 nano로 충분할 만큼 단순한지입니다. 많은 production system에서 정답은 두 모델이 서로 다른 lane을 맡는 구조입니다.