
짧게 답하면, 더 높은 추론 품질과 긴 컨텍스트가 중요한 작업은 GPT-5.4, 더 싼 비용과 더 높은 처리량이 중요한 coding / agent 작업은 GPT-5.4 mini가 맞습니다.
이 키워드는 단순한 “상위 모델 vs 하위 모델” 비교로 쓰면 오히려 덜 유용해집니다. 실제로 필요한 답은 이것입니다. 어느 모델을 메인 기본 경로로 둘지, 어느 모델을 대량 작업용 경로로 둘지 말입니다.
OpenAI의 현재 latest-model guide는 gpt-5.4를 broad general-purpose work와 대부분의 coding 작업용 기본 모델로 두고, gpt-5.4-mini를 high-volume coding, computer use, agent workflows용 가지로 설명합니다. 즉, 이 비교의 본질은 “더 싸고 약한 축소판”이 아니라 한 가족 안에서의 역할 분리입니다.
핵심 요약
실무적으로는 아래 한 줄이면 충분합니다.
- GPT-5.4: 더 어려운 작업의 기본 경로
- GPT-5.4 mini: 더 많이 돌리는 작업의 기본 경로
| 항목 | GPT-5.4 | GPT-5.4 mini | 실무 해석 |
|---|---|---|---|
| 출시일 | 2026년 3월 5일 | 2026년 3월 17일 | 둘 다 현재 라인업 |
| 공식 역할 | 고품질 기본 경로 | high-volume coding / agent 경로 | 역할이 다르다 |
| Input 가격 | $2.50 / 1M | $0.75 / 1M | GPT-5.4가 약 3.3배 비쌈 |
| Cached input | $0.25 / 1M | $0.075 / 1M | 반복 컨텍스트는 mini가 유리 |
| Output 가격 | $15.00 / 1M | $4.50 / 1M | 출력도 차이가 큼 |
| Context window | 1,050,000 | 400,000 | 긴 문맥은 GPT-5.4가 유리 |
| Knowledge cutoff | 2025-08-31 | 2025-08-31 | 컷오프 차이 이야기는 아님 |
| Tool surface | 넓은 Responses API 도구 지원 | 동일하게 넓은 도구 지원 | mini는 tool-light 모델이 아님 |
| 공개 top-tier caps | 15,000 RPM / 40,000,000 TPM | 30,000 RPM / 180,000,000 TPM | mini가 대량 생산에 더 유리 |
결국 이 비교는 “누가 더 똑똑하냐”보다 품질을 먼저 최적화할지, 처리량과 비용을 먼저 최적화할지의 문제입니다.
진짜 갈림길은 flagship headroom vs production throughput
이 비교를 제대로 읽으려면 프레임을 바꿔야 합니다.
GPT-5.4가 맞는 경우:
- 400K로는 부족한 긴 컨텍스트가 필요할 때
- 추론 실패 한 번이 전체 워크플로를 망칠 수 있을 때
- planner, orchestrator, 고난도 coding review처럼 품질이 가장 중요할 때
GPT-5.4 mini가 맞는 경우:
- worker나 subagent를 많이 병렬 실행할 때
- coding / computer use 요청이 대량일 때
- 최신 tool surface를 유지하면서도 비용을 크게 낮추고 싶을 때
따라서 이 키워드의 핵심 질문은 “누가 더 좋은가”가 아니라, 어느 모델에 어려운 가지를 맡기고 어느 모델에 스케일 가지를 맡길 것인가입니다.
실제 의사결정에 영향을 주는 벤치마크 차이
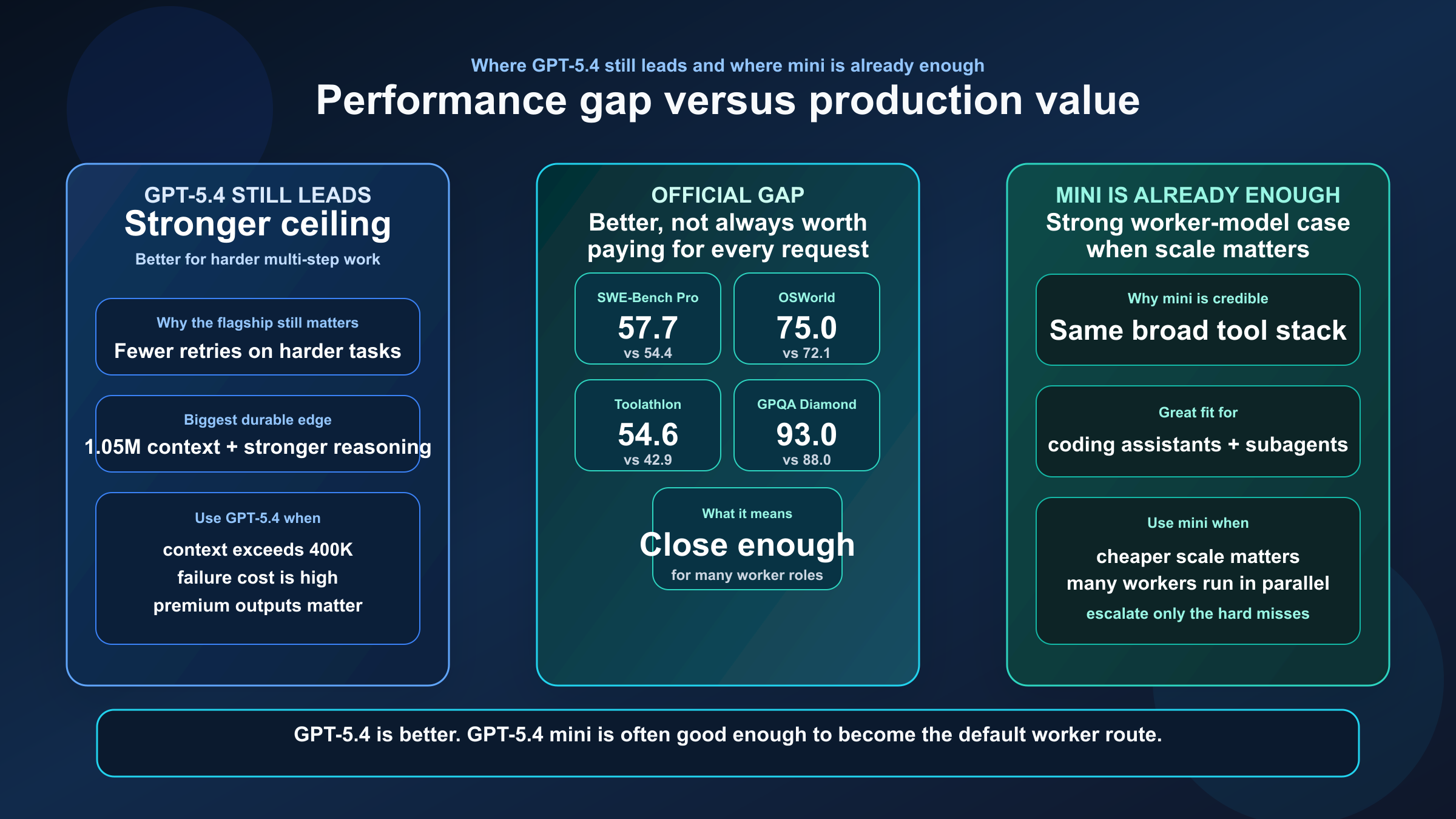
OpenAI의 GPT-5.4 mini and nano 발표에서 특히 중요한 비교는 다음입니다.
| 벤치마크 | GPT-5.4 | GPT-5.4 mini | 의미 |
|---|---|---|---|
| SWE-Bench Pro | 57.7% | 54.4% | GPT-5.4가 더 강하지만 mini도 충분히 근접 |
| Terminal-Bench 2.0 | 75.1% | 60.0% | 긴 tool-heavy 작업에서는 GPT-5.4 우위가 큼 |
| Toolathlon | 54.6% | 42.9% | 다중 도구 연결 안정성은 GPT-5.4가 더 좋음 |
| GPQA Diamond | 93.0% | 88.0% | 고난도 reasoning headroom은 GPT-5.4 쪽 |
| OSWorld-Verified | 75.0% | 72.1% | computer use에서는 mini도 꽤 강함 |
이 표에서 중요한 점은 GPT-5.4 mini가 “약해서 못 쓰는” 모델이 아니라는 것입니다. 오히려 coding과 computer use 같은 production 흐름에서는 mini가 충분히 강해서 비용 대비 훨씬 좋은 운영 지점이 될 수 있습니다.
반대로, multi-step reasoning이 길고 실패 비용이 높은 작업에서는 GPT-5.4 쪽이 더 안전합니다. 그래서 실무에서는 “무조건 한 모델”보다 “어려운 가지는 GPT-5.4, 많이 돌리는 가지는 mini”가 더 자연스럽습니다.
이 차이는 벤치마크 점수표를 보는 방식도 바꿉니다. 중요한 것은 몇 퍼센트 차이 자체보다, 그 차이가 실제 운영에서 재시도 비용과 사람 검수 비용으로 얼마나 커지느냐입니다.
예를 들어 planner가 한 번 잘못 판단하면 뒤쪽 worker 여러 개가 같이 흔들리는 구조라면 GPT-5.4 쪽의 여유가 훨씬 가치 있습니다. 반대로 단건 수정, 분류, 초안 작성처럼 복구가 쉬운 작업은 mini가 더 나은 기본값이 될 가능성이 큽니다.
가격, 컨텍스트, 처리량 차이는 어디서 체감되나

현재 GPT-5.4 모델 페이지에 따르면 GPT-5.4는 다음과 같습니다.
- Input: $2.50 / 1M
- Cached input: $0.25 / 1M
- Output: $15.00 / 1M
- Context window: 1,050,000
현재 GPT-5.4 mini 모델 페이지에 따르면 GPT-5.4 mini는 다음과 같습니다.
- Input: $0.75 / 1M
- Cached input: $0.075 / 1M
- Output: $4.50 / 1M
- Context window: 400,000
즉 가격 기준으로 보면 GPT-5.4는 mini보다 훨씬 비쌉니다. 하지만 대신 1.05M 컨텍스트라는 강력한 장점이 있습니다. 대형 저장소, 긴 문서 세트, 여러 스펙을 한 세션에 묶어야 하는 작업에서는 이 차이가 체감됩니다.
다만 GPT-5.4 모델 페이지는 272K input tokens를 넘으면 전체 세션에 2x input / 1.5x output 과금이 적용된다는 점도 적어 두고 있습니다. 즉 큰 컨텍스트는 강점이지만, 무심코 항상 켜두기엔 비싼 기능입니다.
또 하나 실무적으로 중요한 점은 공개 top-tier caps입니다. 현재 공개된 수치만 봐도 GPT-5.4 mini가 더 높은 throughput에 유리합니다. 이는 worker, background pipeline, 대규모 coding assistant 시나리오에서 아주 실질적인 차이입니다.
그리고 두 모델 모두 knowledge cutoff가 2025년 8월 31일로 동일합니다. 따라서 이 비교는 최신성 차이보다 가격, 컨텍스트, throughput, quality ceiling 차이로 읽는 편이 맞습니다.
실제로 팀이 느끼는 비용은 토큰 단가보다 완료된 작업 한 건당 비용에 더 가깝습니다. mini가 약간 더 자주 재시도하더라도 전체 큐를 더 싸게 돌릴 수 있으면 production 관점에서는 충분히 이득입니다.
반대로 GPT-5.4의 1.05M 컨텍스트를 매 요청마다 풀로 쓰는 구조는 금방 비싸집니다. 긴 문맥이 꼭 필요한 가지에만 GPT-5.4를 붙이고, 나머지는 mini로 내려보내는 설계가 현실적인 운영 균형을 만듭니다.
mini는 도구가 약한 모델이 아니다
여기서 많은 사람이 mini를 과소평가합니다.
현재 model page 기준으로 GPT-5.4와 GPT-5.4 mini 모두 넓은 Responses API 도구면을 지원합니다.
- web search
- file search
- image generation
- code interpreter
- hosted shell
- apply patch
- skills
- computer use
- MCP
- tool search
즉 비교의 본질은 “도구가 있느냐 없느냐”가 아닙니다. 같은 product surface를 가진 두 모델 중에서, 얼마나 quality headroom을 더 살지의 문제에 가깝습니다.
그래서 mini는 “기능이 빠진 저가형”이 아니라 “거의 같은 제품 표면 위에서 더 좋은 운영 경제성을 주는 라우트”로 보는 편이 맞습니다.
언제 GPT-5.4에 비용을 더 써야 하나
GPT-5.4가 맞는 경우는, 추가 토큰 비용보다 실패 비용이 더 큰 경우입니다.
대표적으로:
- 긴 저장소 / 긴 문서 분석
- planner / orchestrator 역할
- 추론이 중간에 무너지면 전체가 흔들리는 작업
- 고객 노출 output이나 비즈니스 핵심 결과물
mini의 한 번의 실패가 재시도, 검수, 수동 보정으로 이어진다면 그 가지는 GPT-5.4로 올리는 편이 더 낫습니다.
언제 GPT-5.4 mini가 더 스마트한 기본값인가
GPT-5.4 mini는 bottleneck이 quality가 아니라 scale일 때 빛납니다.
이런 경우에 특히 잘 맞습니다.
- subagent / worker
- 대량 coding assistant 요청
- screenshot-heavy computer use loop
- 백그라운드 review, triage, 자동 처리
- flagship 가격을 전 트래픽에 적용하고 싶지 않을 때
그래서 많은 팀에서 가장 깔끔한 구조는 이렇습니다.
- GPT-5.4는 planner와 어려운 가지
- GPT-5.4 mini는 workers
이 구성이 현재 OpenAI가 보여 주는 제품 분리와도 가장 잘 맞습니다.
추가로 구형 budget mini와 비교하고 싶다면 GPT-5.4 mini vs GPT-5 mini를 함께 보는 편이 좋습니다.
현장에서는 처음부터 이중 라우팅 규칙을 정해 두는 편이 훨씬 덜 흔들립니다. 모든 요청을 GPT-5.4로 시작한 뒤 나중에 비용 때문에 잘라내는 방식은 예외가 쌓이기 쉽고, 팀마다 기준이 달라지기 쉽습니다.
반대로 승격 조건을 미리 정해 두면 운영이 단순해집니다. 긴 컨텍스트, 복잡한 multi-tool 분기, 고객 노출 최종 산출물만 GPT-5.4로 올리고, 나머지 대량 처리 경로는 mini에 남겨 두는 방식이 가장 설명 가능하고 유지보수도 쉽습니다.
여기에 운영 로그까지 붙이면 어떤 요청이 mini에서 GPT-5.4로 승격됐는지 추적할 수 있어 라우팅 규칙을 더 빨리 다듬을 수 있습니다. 단일 모델 고정 전략보다 개선 포인트가 훨씬 선명하게 보인다는 뜻입니다.
결국 좋은 운영 정책은 모델 이름이 아니라 기준으로 설명돼야 합니다. 컨텍스트 길이, 실패 비용, 사람 검수 필요성, 병렬 요청 수 같은 기준이 먼저 서 있으면 GPT-5.4와 GPT-5.4 mini의 역할도 자연스럽게 분리됩니다.
이렇게 기준을 문서화해 두면 새 워크로드가 들어와도 빠르게 분류할 수 있습니다. 모델 선택이 감각이 아니라 운영 규칙이 되면 비용 통제와 품질 통제가 함께 쉬워집니다.
이 점이 장기 운영에서 특히 크게 작동합니다.
팀이 커질수록 더 그렇습니다.
특히요.
API / Codex 결론과 ChatGPT 표면은 다르다
API와 Codex 관점에서는 정리가 쉽습니다.
- GPT-5.4 = main default
- GPT-5.4 mini = smaller / faster / cheaper branch
하지만 ChatGPT에서는 상황이 더 복잡합니다. 현재 release notes에 따르면 2026년 3월 18일 기준 GPT-5.4 mini는 Thinking 경로나 fallback으로 나타나지만, 일반적인 selectable model처럼 전면에 노출되는 것은 아닙니다.
즉 ChatGPT에서 보이는 모델명만 보고 API 라우팅 결론을 만들면 안 됩니다.
팀용 실전 라우팅 규칙
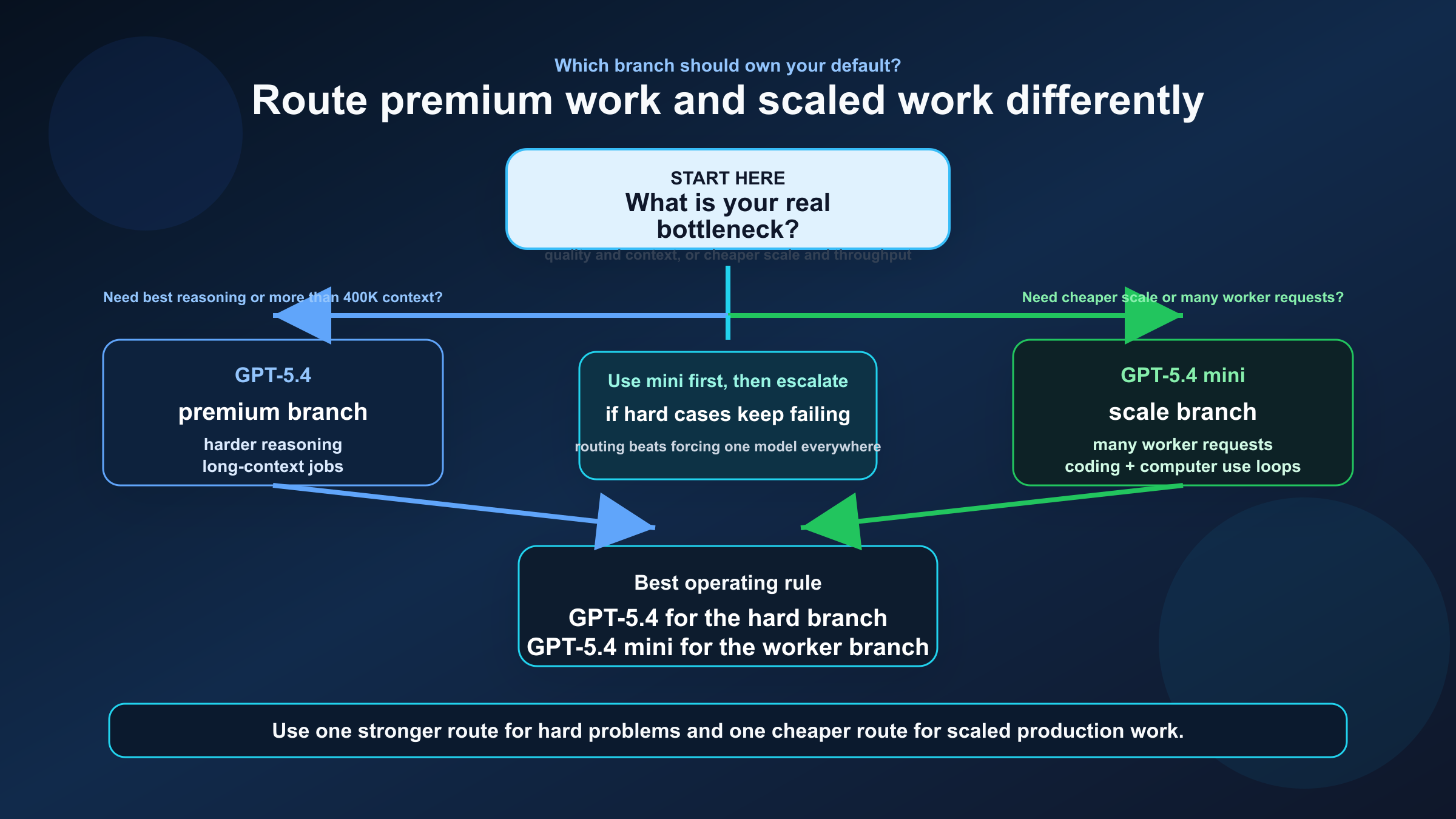
가장 쓰기 쉬운 규칙은 아래와 같습니다.
| 워크로드 | 기본 모델 | 이유 | 언제 바꿀까 |
|---|---|---|---|
| Long-context repo analysis | GPT-5.4 | 더 큰 컨텍스트와 더 높은 품질 여유 | 400K 안에 충분히 들어오고 비용이 더 중요할 때만 mini |
| Planner / orchestration | GPT-5.4 | 복잡한 분기에서 더 안정적 | planner가 가벼우면 mini 테스트 가능 |
| Worker / subagent | GPT-5.4 mini | 비용과 throughput이 좋음 | 어려운 케이스만 GPT-5.4로 승격 |
| Coding assistant at scale | GPT-5.4 mini | 충분히 강하면서 훨씬 저렴 | repair / review의 어려운 분기만 GPT-5.4 |
결국 가장 실용적인 운영 원칙은 어려운 가지는 GPT-5.4, 양을 돌리는 가지는 GPT-5.4 mini입니다.
FAQ
GPT-5.4 mini는 serious coding agents에 충분한가?
많은 경우 충분합니다. 여러 핵심 벤치마크에서 GPT-5.4에 꽤 근접하고, 비용과 throughput 면에서는 훨씬 유리합니다.
GPT-5.4 mini는 도구가 적은가?
현재 model page 기준으로는 아닙니다. 차이는 도구 수보다 quality ceiling, context, cost 쪽에 있습니다.
GPT-5.4에 더 돈을 쓸 가치가 있는가?
긴 컨텍스트, 높은 reasoning 품질, 비싼 실패 비용이 실제로 중요하다면 있습니다. 반대로 대량 작업이 중심이라면 mini가 더 합리적입니다.
1.05M 컨텍스트가 가장 큰 이유인가?
아주 큰 이유 중 하나입니다. 하지만 그 외에도 어려운 tool-heavy 작업에서 더 높은 headroom을 준다는 점이 중요합니다.
Codex 스타일 subagent에는 무엇이 맞는가?
많은 subagent 역할에는 GPT-5.4 mini가 맞습니다. GPT-5.4는 planner나 escalation branch에 두는 편이 더 깔끔합니다.
정리하면, GPT-5.4는 어려운 일, GPT-5.4 mini는 많이 돌리는 일에 두면 됩니다.