
Claude Opus 4.6 и GPT-5.3-Codex вышли в один и тот же день --- 5 февраля 2026 года --- создав самое значимое противостояние ИИ-моделей со времён, когда GPT-4 бросил вызов Claude 3 в начале 2024 года. Новый флагман Anthropic доминирует в бенчмарках рассуждений с 1606 Elo на GPQA Diamond и 91,9% точности на tau-bench, тогда как специалист по кодингу от OpenAI лидирует в терминальной разработке с результатом 77,3% на Terminal-Bench. Но настоящая история выходит за рамки бенчмарков: именно ценовые стратегии, агентные рабочие процессы и практические сценарии использования определяют, какая модель действительно приносит больше пользы для ваших конкретных задач. Данное руководство предоставляет проверенные данные, анализ оптимизации затрат и конкретную систему принятия решений, которая поможет вам сделать выбор.
Краткое содержание
Самый простой способ описать это сравнение: Claude Opus 4.6 --- это универсальная модель высшего класса, которая отлично справляется с кодингом, тогда как GPT-5.3-Codex --- это специалист по кодингу, который жертвует широтой ради доминирования в терминале. Ни одна из моделей не является безусловно «лучше» --- правильный выбор полностью зависит от вашего рабочего процесса.
Пять ключевых различий, которые имеют наибольшее значение:
- Глубина рассуждений: Opus 4.6 набирает 68,8% на ARC-AGI 2 против 54,2% у GPT-5.2 --- разрыв в 14,6 процентных пункта, который выражается в существенно лучшей производительности при решении сложных аналитических задач, научных исследованиях и многошаговом решении проблем
- Терминальный кодинг: GPT-5.3-Codex достигает 77,3% на Terminal-Bench 2.0, опережая Opus 4.6 с его 65,4% почти на 12 пунктов --- самый большой разрыв среди всех категорий бенчмарков, что делает Codex безоговорочным победителем для рабочих процессов, ориентированных на CLI
- Реальные цены: Opus стоит $5/$25 за миллион токенов (вход/выход) по стандартным тарифам против $1,75/$14 у GPT-5.2, однако Batch API Opus (скидка 50%) и кэширование промптов (скидка 90% на вход) значительно сокращают разрыв для пользователей с большими объёмами
- Контекстное окно: обе модели предлагают контекст в 1 млн токенов, но у Opus 4.6 оно находится в бета-версии с 76% точностью на MRCR v2 для извлечения из длинного контекста --- и это по-прежнему самая мощная реализация работы с длинным контекстом
- Парадигма рабочего процесса: Agent Teams в Opus 4.6 обеспечивает мультиагентную оркестрацию (фронтенд + бэкенд + тестирование одновременно), тогда как CLI-интеграция Codex предоставляет нативный терминальный опыт с возможностями самоотладки
Быстрая рекомендация: выбирайте Opus 4.6 для исследований, сложного анализа, ревью кода и фулстек-разработки. Выбирайте GPT-5.3-Codex для DevOps, быстрого прототипирования и рабочих процессов, ориентированных на терминал. Для смешанных задач используйте обе модели через единый API.
Противостояние 5 февраля --- почему это сравнение важно
Одновременный выпуск Claude Opus 4.6 и GPT-5.3-Codex 5 февраля 2026 года знаменует поворотный момент в развитии ИИ. Впервые Anthropic и OpenAI выпустили конкурирующие модели флагманского уровня в один и тот же день, вынудив всё сообщество разработчиков немедленно приступить к сравнительной оценке. Это не было совпадением --- обе компании стремились к схожим порогам возможностей, и синхронность выпуска отражает то, насколько близки стали ведущие лаборатории ИИ.
Что делает это сравнение особенно нюансированным --- фундаментальное различие в позиционировании. Anthropic позиционировала Opus 4.6 как свою самую мощную модель по всем параметрам --- рассуждения, кодинг, понимание длинного контекста и выполнение агентных задач. Модель заняла первое место в общем рейтинге Artificial Analysis (artificialanalysis.ai, февраль 2026) и была описана как «первая модель, которая функционирует как цифровой член корпоративной команды» многочисленными обозревателями. Её функция Agent Teams позволяет координировать несколько ИИ-агентов, работающих над разными частями проекта одновременно, что представляет собой новую парадигму в разработке с помощью ИИ.
OpenAI выбрала другой подход с GPT-5.3-Codex, удвоив ставку на превосходство в кодинге. Модель описывается как «самая мощная агентная модель для кодинга» с фокусом на нативных терминальных рабочих процессах, возможностях самоотладки и интерактивном управлении. Примечательно, что OpenAI сообщила, что GPT-5.3-Codex стала «первой моделью, которая сыграла ключевую роль в создании самой себя» --- веха в разработке ИИ с помощью ИИ. Модель на 25% быстрее своего предшественника GPT-5.2-Codex и содержит функции, специально разработанные для рабочих процессов разработчиков, а не для универсального интеллекта.
Это различие в позиционировании критически важно для понимания результатов бенчмарков, которые будут представлены далее. Когда оценка every.to показала, что Opus набрал 9,25/10 на их бенчмарке кодинга LFG против 7,5/10 у Codex, результат удивил многих, кто ожидал доминирования специалиста по кодингу. Объяснение кроется в сложности: Opus превосходит в задачах кодинга с множеством файлов и шагов, требующих глубоких рассуждений, тогда как Codex блистает в сценариях быстрого терминального исполнения. Для контекста того, как сравнивалось предыдущее поколение, смотрите наше сравнение предыдущего поколения --- разрыв значительно сократился в этом поколении.
Разбор бенчмарков --- что на самом деле означают цифры
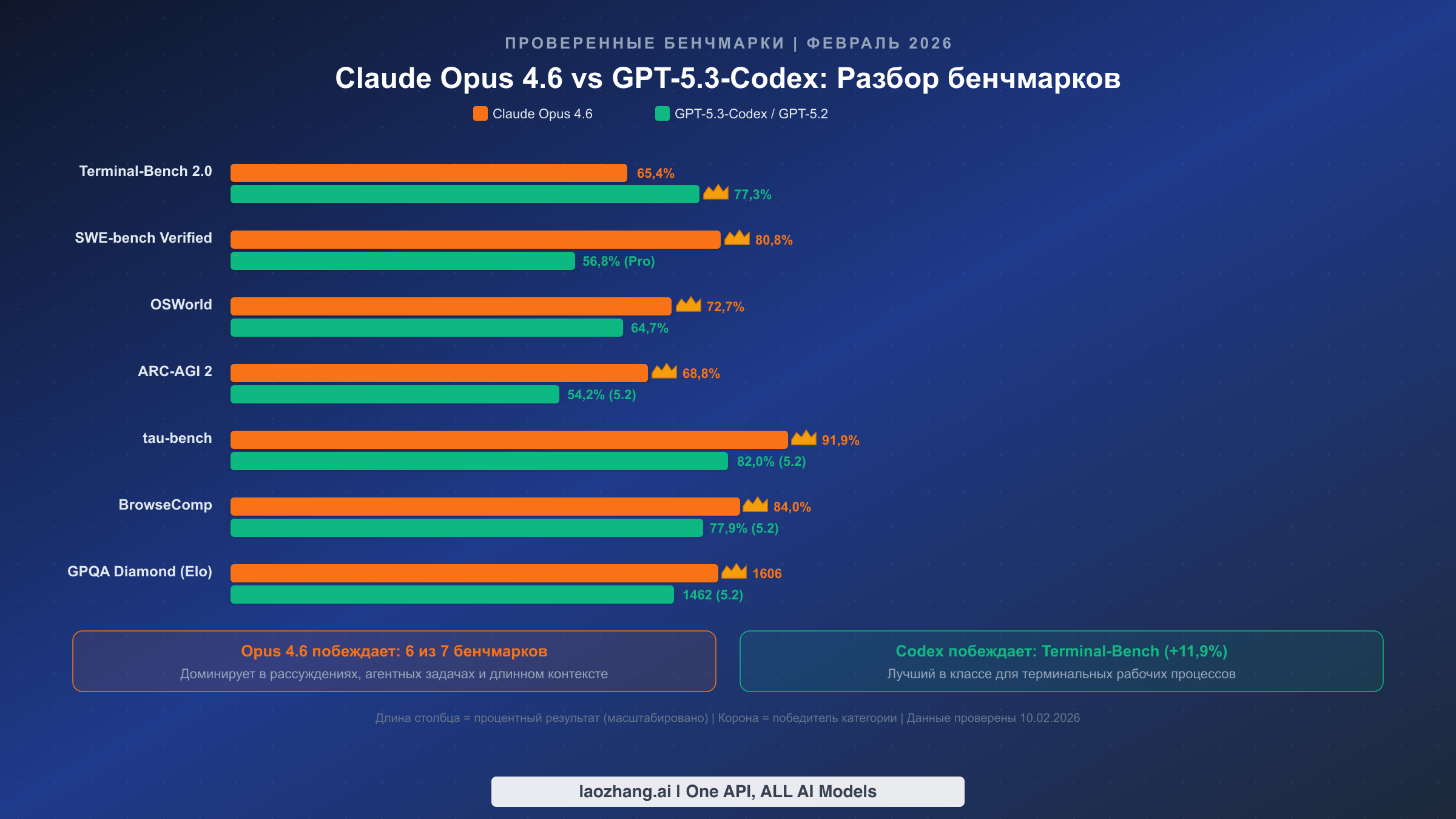
Сами по себе цифры бенчмарков рассказывают лишь часть истории. Понимание того, что именно измеряет каждый бенчмарк --- и какие из них важны для вашего конкретного сценария --- гораздо ценнее, чем знание того, кто «победил» в большем числе категорий. Вот полные проверенные данные с практической интерпретацией.
Terminal-Bench 2.0 измеряет способность модели выполнять сложные задачи в терминальной среде, включая системное администрирование, отладку и многошаговые последовательности команд. Результат GPT-5.3-Codex в 77,3% против 65,4% у Opus 4.6 представляет собой самый большой разрыв в рамках одного бенчмарка в данном сравнении. Если ваша повседневная работа включает интенсивное взаимодействие с терминалом --- DevOps, управление инфраструктурой, написание скриптов --- этот бенчмарк напрямую предсказывает реальную производительность. Преимущество в 11,9 процентных пункта существенно и подтверждается множеством независимых оценок.
SWE-bench Verified тестирует способность модели решать реальные задачи с GitHub из популярных open-source проектов. Результат Opus 4.6 в 80,8% --- один из самых высоких за всю историю, что указывает на исключительную способность понимать сложные кодовые базы, выявлять корневые причины проблем и генерировать правильные патчи. GPT-5.3-Codex набрал 56,8% на более сложной версии SWE-Bench Pro, которая использует другую методологию оценки --- бенчмарки не являются напрямую сопоставимыми, но оба демонстрируют сильные возможности кодинга. Для корпоративных команд разработки, работающих с большими кодовыми базами, результаты SWE-bench являются, пожалуй, наиболее релевантным предиктором практической полезности.
ARC-AGI 2 и GPQA Diamond измеряют абстрактное рассуждение и научные знания соответственно. Преимущества Opus 4.6 --- 68,8% против 54,2% на ARC-AGI 2 и 1606 против 1462 Elo на GPQA Diamond --- значительны, поскольку указывают на превосходную производительность в задачах, требующих новых подходов к решению проблем. Эти бенчмарки наиболее важны для исследований, анализа данных и любых задач, где модели необходимо рассуждать над проблемами, которых не было в обучающих данных.
Бенчмарки агентной производительности
tau-bench (91,9% против 82,0%) измеряет выполнение многошаговых задач в реалистичных агентных сценариях. Преимущество Opus 4.6 почти в 10 пунктов напрямую транслируется в более надёжное автономное выполнение задач --- меньше неудачных шагов, лучшее восстановление после ошибок и более последовательные многошаговые планы. Если вы создаёте ИИ-агентов или используете модели для сложных автоматизированных рабочих процессов, это самый важный бенчмарк для рассмотрения.
BrowseComp (84,0% против 77,9%) оценивает возможности веб-просмотра и синтеза информации. Преимущество Opus важно для автоматизации исследований, конкурентного анализа и любых рабочих процессов, связанных с извлечением и обобщением информации из множества веб-источников.
OSWorld (72,7% против 64,7%) тестирует возможности использования компьютера в реалистичных настольных средах. Несмотря на то что GPT-5.3-Codex позиционируется как более «практичный» инструмент, Opus 4.6 превосходит его на 8 пунктов в общих сценариях использования компьютера. Это свидетельствует о том, что преимущество Codex специфично для терминальных сред, а не для более широкого компьютерного взаимодействия.
Кодинг и агентные рабочие процессы --- реальная производительность
Цифры бенчмарков рисуют чёткую картину, но фактический опыт разработчика при использовании этих моделей отличается способами, которые невозможно передать только числами. Фундаментальное различие сводится к философии рабочего процесса: Opus 4.6 работает как оркестратор, управляющий сложностью, тогда как GPT-5.3-Codex работает как ускоритель, быстро выполняющий задачи в узкой области.
Agent Teams --- определяющая инновация Opus 4.6 для разработки. Вместо одного ИИ-помощника, обрабатывающего запросы последовательно, Agent Teams позволяют запускать несколько специализированных агентов, которые работают над разными аспектами проекта одновременно. На практике это означает, что один агент может заниматься фронтенд-компонентами React, другой --- бэкенд-эндпоинтами API, а третий --- миграциями базы данных --- и всё это координируется ведущим агентом, обеспечивающим согласованность. Ранние бенчмарки от Anthropic показывают, что такой подход может сократить время выполнения сложных проектов на 40-60% по сравнению с последовательной обработкой. Эта функция эксклюзивна для Opus 4.6 и использует его возможность Adaptive Thinking, которая динамически распределяет ресурсы рассуждения в зависимости от сложности задачи.
Нативный терминальный подход GPT-5.3-Codex предлагает иной вид эффективности. Вместо оркестрации нескольких агентов Codex напрямую интегрируется в ваш терминальный рабочий процесс с такими функциями, как интерактивное управление (предоставление рекомендаций в реальном времени по мере работы модели), самоотладка (автоматическое выявление и исправление ошибок в собственном выводе) и контекстно-зависимые подсказки на основе истории вашей оболочки и структуры проекта. Для разработчиков, живущих в терминале --- пишущих скрипты развёртывания, отлаживающих продакшн-проблемы, управляющих инфраструктурой --- эта тесная интеграция устраняет когнитивную нагрузку переключения между интерфейсом ИИ и вашей реальной рабочей средой.
Аспект безопасности заслуживает особого внимания. Anthropic сообщила, что Opus 4.6 обнаружил более 500 уязвимостей нулевого дня в open-source коде в ходе оценки. Эта возможность имеет прямые последствия для рабочих процессов ревью кода: Opus 4.6 способен выявлять тонкие проблемы безопасности --- состояния гонки, уязвимости инъекций, логические ошибки --- которые пропускают традиционные инструменты статического анализа. Для команд, где безопасность кода является приоритетом, это представляет значительное практическое преимущество, которое ни один бенчмарк не может полностью количественно оценить.
Когда каждая модель превосходит на практике
Opus 4.6 стабильно превосходит в сценариях, требующих глубокого понимания больших кодовых баз. При выполнении задачи по рефакторингу приложения из 50 000 строк контекстное окно Opus в 1 млн токенов (бета) и превосходные способности к рассуждению позволяют сохранять согласованность по всей кодовой базе, выявляя зависимости и побочные эффекты, которые упускают модели с более коротким контекстом. Результат SWE-bench Verified в 80,8% отражает именно эту способность --- бенчмарк специально тестирует исправление реальных ошибок в сложных проектах.
GPT-5.3-Codex превосходит в циклах быстрой итерации. Его 25%-ное улучшение скорости по сравнению с GPT-5.2-Codex в сочетании с самоотладкой означает, что вы получаете рабочий код быстрее в терминально-ориентированных рабочих процессах. Для таких задач, как настройка CI/CD-пайплайнов, написание shell-скриптов или отладка конфигураций контейнеров, преимущество Codex на Terminal-Bench напрямую транслируется в экономию времени. Функция интерактивного управления здесь особенно ценна --- вы можете корректировать курс в реальном времени, вместо того чтобы ждать полного ответа и затем запрашивать изменения.
Детальный анализ цен --- реальная стоимость каждой модели
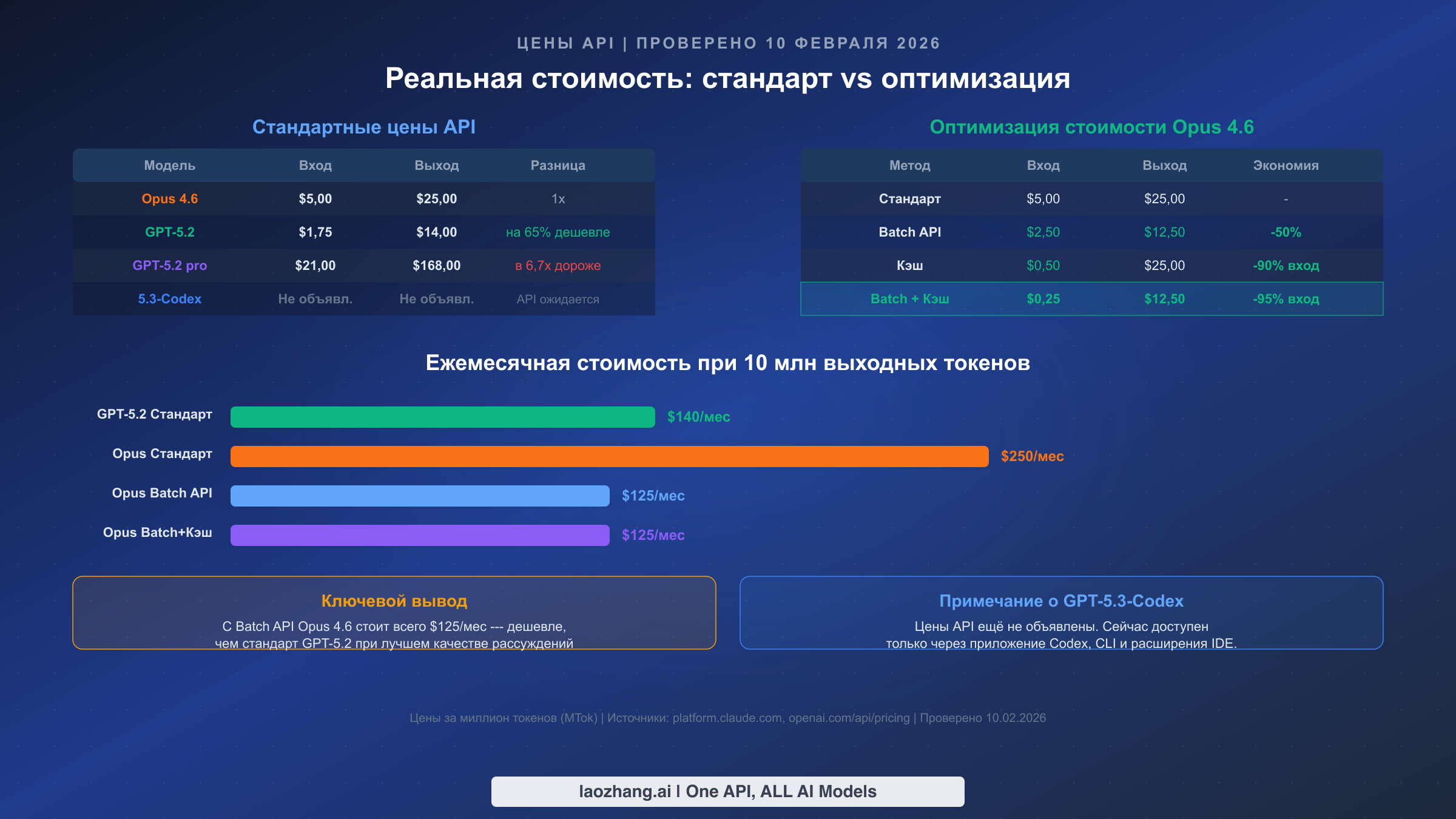
Ценообразование --- это та область, где сравнение становится по-настоящему сложным, потому что стандартные цены рассказывают обманчивую историю. По стандартным тарифам Claude Opus 4.6 выглядит значительно дороже GPT-5.2, но агрессивные функции оптимизации Anthropic могут кардинально изменить расчёты для пользователей с большими объёмами.
Стандартные цены API (проверено 10 февраля 2026, по данным официальных страниц):
| Модель | Вход | Выход | Кэш | Batch вход | Batch выход |
|---|---|---|---|---|---|
| Claude Opus 4.6 | $5,00/MTok | $25,00/MTok | $0,50/MTok | $2,50/MTok | $12,50/MTok |
| GPT-5.2 | $1,75/MTok | $14,00/MTok | $0,175/MTok | Н/Д | Н/Д |
| GPT-5.3-Codex | Не объявлено | Не объявлено | Не объявлено | Не объявлено | Не объявлено |
Важная оговорка: цены API GPT-5.3-Codex не были объявлены по состоянию на 10 февраля 2026 года. Модель в настоящее время доступна только через приложение Codex, CLI и расширения IDE, а доступ через API «скоро появится» по информации OpenAI. Это означает, что прямое сравнение цен для модели Codex в настоящее время невозможно --- мы используем цены GPT-5.2 в качестве ориентира.
Стратегии оптимизации затрат делают Opus 4.6 более конкурентоспособным, чем подсказывает стандартная цена. Batch API обеспечивает фиксированную скидку 50% как на входные, так и на выходные токены, снижая эффективную стоимость до $2,50/$12,50 за MTok. Для рабочих нагрузок, допускающих асинхронную обработку (пакеты ревью кода, генерация документации, пайплайны анализа данных), это делает Opus 4.6 лишь немного дороже стандартных цен GPT-5.2 при значительно лучшей производительности рассуждений. Для более детального разбора механики кэширования промптов Anthropic смотрите наше руководство по оптимизации кэширования промптов.
Кэширование промптов обеспечивает ещё более впечатляющую экономию на входных затратах. Когда вы отправляете похожие промпты повторно --- что часто встречается в рабочих процессах разработки при итерации над одной и той же кодовой базой --- кэшированные входные токены стоят всего $0,50 за MTok, что означает снижение на 90% от стандартной цены. Для типичной сессии разработки с 80% попаданий в кэш эффективная стоимость входа снижается примерно до $1,40 за MTok, приближаясь к стандартной входной цене GPT-5.2. Для полных деталей ценообразования Claude наше детальное руководство по ценам Claude Opus охватывает все уровни и структуры скидок.
Ежемесячные оценки затрат при 10 млн выходных токенов (типичное использование среднего объёма):
| Конфигурация | Стоимость в месяц | Примечания |
|---|---|---|
| GPT-5.2 Стандарт | ~$140 | Базовое сравнение |
| Opus 4.6 Стандарт | ~$250 | На 78% дороже GPT-5.2 |
| Opus 4.6 Batch API | ~$125 | Фактически дешевле стандарта GPT-5.2 |
| Opus 4.6 Batch + Кэш | ~$125 | Самая низкая эффективная стоимость для Opus |
Ключевой вывод: с Batch API Opus 4.6 становится сопоставимым по цене или даже дешевле стандартных цен GPT-5.2, при этом обеспечивая превосходное качество рассуждений по большинству бенчмарков. Для команд, уже работающих в экосистеме Anthropic, функции оптимизации фактически устраняют ценовое отставание.
Для команд, которым нужен доступ к обеим моделям --- или которые хотят сравнить их на реальных задачах перед принятием решения --- унифицированный API-подход упрощает процесс. Сервисы вроде laozhang.ai предоставляют единую точку доступа API, которая маршрутизирует запросы как к Anthropic, так и к OpenAI, устраняя необходимость управлять несколькими API-ключами и биллинговыми аккаунтами, и при этом потенциально предлагая более низкие тарифы за счёт агрегированного объёма.
Начало работы --- руководство по интеграции API
Начать работу с любой из моделей можно за несколько минут. Вот рабочие примеры кода для обеих, а также унифицированный подход для команд, которым нужна гибкость.
API Claude Opus 4.6
pythonimport anthropic client = anthropic.Anthropic(api_key="your-api-key") message = client.messages.create( model="claude-opus-4-6", max_tokens=4096, messages=[ {"role": "user", "content": "Analyze this codebase for security vulnerabilities..."} ] ) print(message.content[0].text)
Для бета-версии контекстного окна в 1 млн токенов добавьте заголовок:
pythonmessage = client.messages.create( model="claude-opus-4-6", max_tokens=4096, extra_headers={"anthropic-beta": "context-1m-2025-08-07"}, messages=[...] )
API GPT-5.2 (API GPT-5.3-Codex ожидается)
pythonfrom openai import OpenAI client = OpenAI(api_key="your-api-key") response = client.chat.completions.create( model="gpt-5.2", messages=[ {"role": "user", "content": "Write a deployment script for..."} ] ) print(response.choices[0].message.content)
Поскольку API-доступ к GPT-5.3-Codex ещё не запущен, GPT-5.2 является ближайшей доступной моделью через API. Специфические функции Codex (самоотладка, интерактивное управление) в настоящее время доступны только через приложение Codex и CLI-инструменты.
Унифицированный API-подход
Для команд, желающих использовать обе модели через единую интеграцию, laozhang.ai предоставляет OpenAI-совместимую точку доступа, которая маршрутизирует запросы к нескольким провайдерам:
pythonfrom openai import OpenAI client = OpenAI( api_key="your-laozhang-key", base_url="https://api.laozhang.ai/v1" ) # Opus для задач рассуждения opus_response = client.chat.completions.create( model="claude-opus-4-6", messages=[{"role": "user", "content": "Analyze this research paper..."}] ) # GPT-5.2 для задач, чувствительных к стоимости gpt_response = client.chat.completions.create( model="gpt-5.2", messages=[{"role": "user", "content": "Generate test cases for..."}] )
Этот подход особенно ценен в период оценки --- вы можете отправлять одинаковые промпты обеим моделям и сравнивать результаты перед тем, как определиться с основным провайдером. Он также позволяет реализовать стратегию «лучшее из двух миров», когда задачи, требующие глубоких рассуждений, направляются к Opus, а задачи быстрой итерации --- к GPT-5.2 (или GPT-5.3-Codex после запуска его API).
Какую модель выбрать? --- Система принятия решений
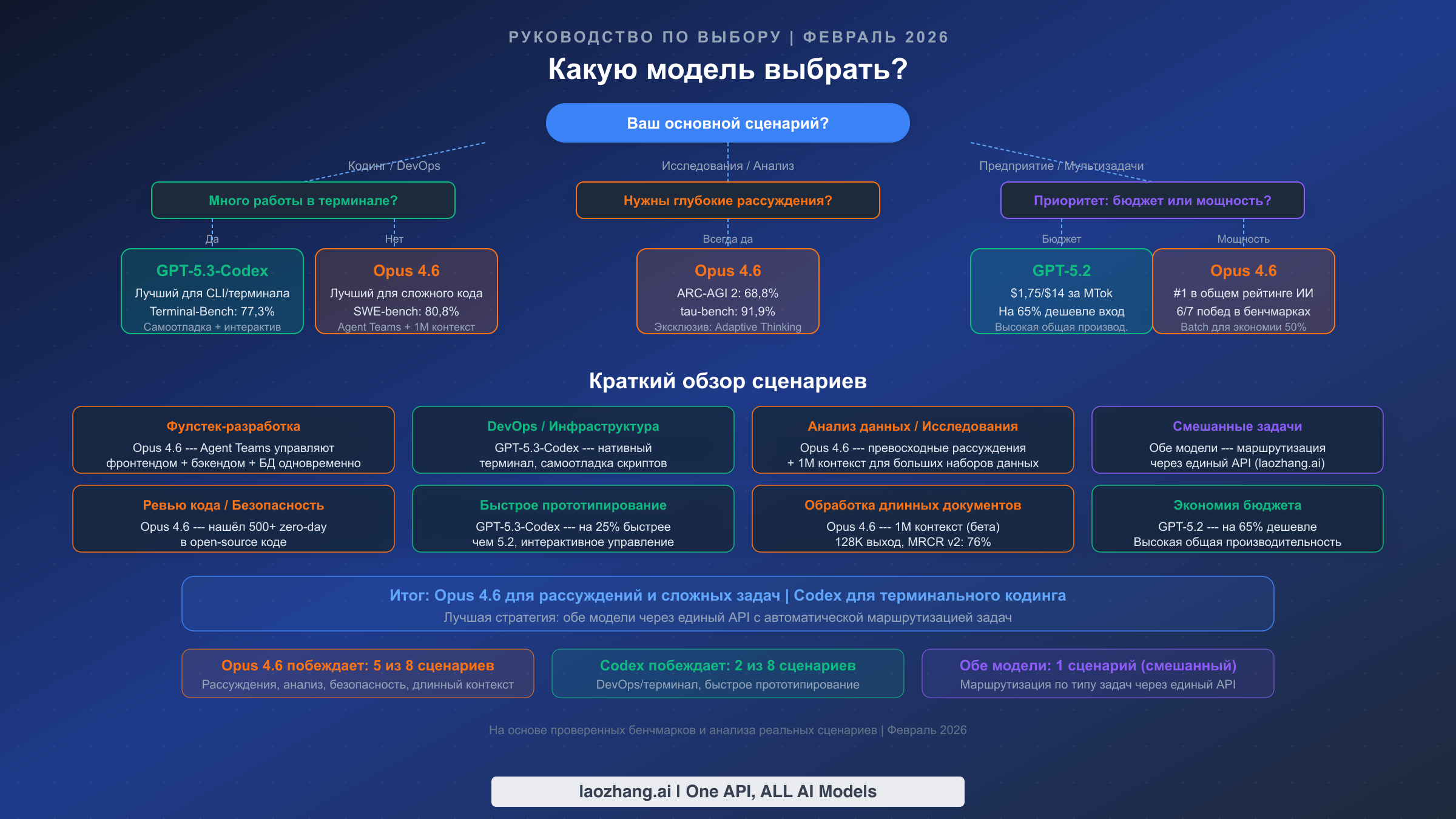
После анализа бенчмарков, цен и рабочих процессов представляем практическую систему принятия решений, организованную по реальным сценариям. Цель не в том, чтобы объявить победителя, а в том, чтобы сопоставить каждую модель с контекстами, в которых она приносит наибольшую ценность.
Фулстек-разработка приложений благоприятствует Opus 4.6. Функция Agent Teams обеспечивает параллельную работу над фронтендом, бэкендом и уровнем базы данных, а контекстное окно в 1 млн токенов охватывает целые кодовые базы. Результат SWE-bench Verified в 80,8% подтверждает превосходную производительность при работе со сложными задачами кодинга на множестве файлов. Более высокая стоимость компенсируется сокращением итерационных циклов и меньшим количеством ошибок при сложном рефакторинге.
DevOps и управление инфраструктурой благоприятствует GPT-5.3-Codex. Результат Terminal-Bench 2.0 в 77,3% напрямую измеряет навыки, необходимые для скриптов развёртывания, управления контейнерами и настройки CI/CD-пайплайнов. Функция самоотладки выявляет ошибки в shell-скриптах до их распространения, а интерактивное управление позволяет направлять модель через сложные изменения инфраструктуры в реальном времени. Это самое сильное конкурентное преимущество Codex.
Исследования и анализ данных определённо благоприятствуют Opus 4.6. С 68,8% на ARC-AGI 2, 91,9% на tau-bench и 84,0% на BrowseComp Opus доминирует во всех бенчмарках, релевантных для исследовательских рабочих процессов. Контекстное окно в 1 млн токенов позволяет обрабатывать целые научные статьи, наборы данных и документацию за один проход. Adaptive Thinking динамически выделяет больше ресурсов рассуждения для сложных аналитических вопросов --- эксклюзивная функция Opus 4.6, не имеющая аналогов в линейке GPT.
Быстрое прототипирование и написание скриптов благоприятствует GPT-5.3-Codex. 25%-ное улучшение скорости по сравнению с GPT-5.2-Codex означает более быстрые итерационные циклы, а нативный терминальный рабочий процесс минимизирует переключение контекста между IDE и ИИ-инструментами. Для создания быстрых прототипов, скриптов автоматизации или одноразовых утилит преимущество Codex в скорости перевешивает глубину рассуждений Opus.
Аудит безопасности кода определённо благоприятствует Opus 4.6. Обнаружение более 500 уязвимостей нулевого дня в open-source коде демонстрирует уровень возможностей анализа безопасности, с которым публично не сравнилась ни одна другая модель. Для команд, ответственных за проверку безопасности, аудит соответствия требованиям или поддержку критической инфраструктуры, одна эта возможность может оправдать более высокую стоимость за токен.
Бюджетное общее использование благоприятствует GPT-5.2. При $1,75/$14 за MTok GPT-5.2 предлагает высокую общую производительность при на 65% более низкой стоимости входа по сравнению со стандартными ценами Opus. Для команд, которым не нужны пиковые рассуждения Opus или терминальная интеграция Codex, GPT-5.2 обеспечивает лучшую ценность за каждый потраченный доллар.
Обработка длинных документов благоприятствует Opus 4.6. Контекстное окно в 1 млн токенов (бета) в сочетании с максимальным выходом в 128K токенов позволяет обрабатывать и генерировать контент в масштабах, с которыми не может сравниться ни одна другая модель. Точность MRCR v2 в 76% означает, что модель сохраняет разумную точность извлечения даже при экстремальных длинах контекста.
Смешанные корпоративные задачи получают наибольшую выгоду от использования обеих моделей. Направляйте задачи, требующие глубоких рассуждений (анализ, ревью кода, стратегическое планирование), к Opus 4.6, а задачи исполнения (развёртывание, скрипты, терминальные операции) --- к GPT-5.3-Codex или GPT-5.2. Единая API-точка доступа упрощает такую маршрутизацию без необходимости отдельных интеграций для каждого провайдера.
FAQ --- Часто задаваемые вопросы
Лучше ли Claude Opus 4.6, чем GPT-5.3-Codex?
Зависит от аспекта. Opus 4.6 побеждает в 6 из 7 основных бенчмарков, включая рассуждения (ARC-AGI 2: 68,8% против 54,2%), агентные задачи (tau-bench: 91,9% против 82,0%) и общий кодинг (SWE-bench: 80,8%). Однако GPT-5.3-Codex лидирует на Terminal-Bench 2.0 почти на 12 процентных пунктов (77,3% против 65,4%), что делает его очевидным выбором для рабочих процессов разработки, ориентированных на терминал. Для большинства задач общего назначения Opus 4.6 --- более мощная модель, но для специализированного терминального кодинга у Codex есть значимое преимущество.
Сколько стоит Claude Opus 4.6 по сравнению с GPT-5.3-Codex?
Opus 4.6 стоит $5/$25 за MTok (вход/выход) по стандартным тарифам. Цены API GPT-5.3-Codex ещё не объявлены --- модель в настоящее время доступна только через приложение Codex, CLI и расширения IDE. Используя GPT-5.2 ($1,75/$14 за MTok) как ориентир, Opus выглядит в 2-3 раза дороже по стандартным тарифам. Однако Batch API Opus (скидка 50%) снижает стоимость выхода до $12,50/MTok, а кэширование промптов может уменьшить стоимость входа на 90% до $0,50/MTok. С этими оптимизациями использование Opus в больших объёмах может фактически обойтись дешевле стандартных цен GPT-5.2 (официальные цены Anthropic, проверено 10 февраля 2026).
Может ли Opus 4.6 заменить GPT-5.3-Codex для кодинга?
Для большинства задач кодинга --- да. Результат Opus 4.6 в 80,8% на SWE-bench Verified и функция Agent Teams делают его исключительно мощным для сложной разработки. Единственная область, где Codex сохраняет явное преимущество --- нативные терминальные рабочие процессы: если ваш процесс разработки в значительной степени сосредоточен на CLI-инструментах, shell-скриптах и терминальной отладке, специально созданные функции Codex (самоотладка, интерактивное управление, 77,3% Terminal-Bench) обеспечивают лучший опыт. Для фулстек-разработки, ревью кода и рефакторинга множества файлов Opus 4.6 --- более мощный выбор.
Что такое Adaptive Thinking в Opus 4.6?
Adaptive Thinking --- это эксклюзивная функция Opus 4.6, которая динамически распределяет ресурсы рассуждения в зависимости от сложности задачи. Вместо использования фиксированного объёма «размышлений» для каждого запроса модель автоматически увеличивает глубину рассуждения для сложных аналитических вопросов и снижает её для простых задач. Это означает, что вы получаете скорость уровня GPT-5.2 на простых запросах и расширенные возможности рассуждения на сложных задачах --- без необходимости вручную переключаться между моделями или настраивать параметры мышления. Ни одна другая модель в настоящее время не предлагает эквивалентной функциональности.
Стоит ли ждать API-доступа к GPT-5.3-Codex?
Если терминально-ориентированный кодинг --- ваш основной сценарий использования, ожидание API-доступа к Codex стоит рассмотреть --- преимущество на Terminal-Bench существенно. Однако если вам нужно API-решение уже сегодня, GPT-5.2 предоставляет надёжные возможности кодинга по конкурентным ценам, а Opus 4.6 обеспечивает превосходную производительность по большинству параметров. Вы можете начать с одной или обеих моделей сейчас и добавить API Codex, когда он станет доступен, особенно если вы используете единый API-сервис, поддерживающий нескольких провайдеров.