
Gemini 3 — новейшая флагманская серия AI-моделей Google, выпущенная в конце 2025 года, включающая мощную версию Pro для сложных рассуждений и сверхбыструю версию Flash. Для разработчиков и корпоративных пользователей понимание структуры цен и лимитов квот Gemini 3 API является ключевым шагом для принятия обоснованных технологических решений. Это руководство, основанное на проверенных данных Google AI Studio (2026-02-04), предоставляет полный анализ цен и квот Gemini 3 API, помогая максимизировать использование AI в рамках вашего бюджета.
Обзор Gemini 3 API
Подход Google к AI-моделям всегда делал акцент на мультимодальных возможностях и обработке длинного контекста, и Gemini 3 выводит оба аспекта на новый уровень. Как последнее достижение Google DeepMind, Gemini 3 не только продолжает преимущества предшественников в мультимодальном понимании, но и обеспечивает значительные улучшения в глубине рассуждений и эффективности ответов.
Gemini 3 API в настоящее время доступен через два канала: Google AI Studio и Vertex AI. Google AI Studio ориентирован на индивидуальных разработчиков и небольшие команды, предлагая бесплатный уровень и оплату по факту использования, тогда как Vertex AI обслуживает корпоративных пользователей с расширенными гарантиями безопасности и обслуживания. Стратегии ценообразования в основном согласованы между каналами, хотя лимиты квот и корпоративные функции различаются.
С точки зрения технической архитектуры, Gemini 3 вводит параметр thinking_level для управления глубиной рассуждений модели, позволяя разработчикам динамически настраивать «интенсивность мышления» модели в зависимости от сложности задачи, находя баланс между качеством рассуждений и скоростью ответа. Кроме того, Gemini 3 поддерживает контекстное окно до 1M токенов, предоставляя достаточно пространства для обработки длинных документов, анализа кодовой базы и многоходовых диалогов. Gemini 3 в настоящее время находится на этапе Preview, и некоторые функции и цены могут измениться при официальном выпуске.
Полное описание цен Gemini 3

Понимание структуры цен Gemini 3 требует внимания к нескольким ключевым измерениям: версия модели (Pro vs Flash), длина контекста (≤200K vs >200K) и типы ввода/вывода (текст, изображения, аудио/видео). Google применяет многоуровневое ценообразование, где цены увеличиваются при превышении контекста 200K токенов, отражая дополнительные вычислительные ресурсы, необходимые для обработки длинного контекста.
Цены Gemini 3 Pro
Gemini 3 Pro — флагманская модель, предназначенная для сложных задач рассуждения, и её цены отражают мощные возможности. Согласно официальной странице цен Google AI Studio (проверено 2026-02-04), цены Gemini 3 Pro следующие:
| Статья | ≤200K токенов контекст | >200K токенов контекст |
|---|---|---|
| Цена ввода (за миллион токенов) | $2.00 | $4.00 |
| Цена вывода (за миллион токенов) | $12.00 | $18.00 |
| Инструмент Google Search | $35.00 / 1K запросов | $35.00 / 1K запросов |
Gemini 3 Pro в настоящее время не имеет бесплатного уровня; все вызовы API требуют привязанного платёжного аккаунта. Эта стратегия соответствует позиционированию Pro для производственных приложений и корпоративных сценариев, обеспечивая качество обслуживания и стабильное предоставление ресурсов.
Цены Gemini 3 Flash
Gemini 3 Flash оптимизирован для высокочастотных сценариев с низкой задержкой, значительно снижая затраты при сохранении хорошей производительности. Ценовая стратегия Flash более доступна и включает щедрый бесплатный уровень:
| Статья | Бесплатный уровень | Платный уровень (за миллион токенов) |
|---|---|---|
| Текстовый ввод | ✅ Доступен | $0.50 |
| Текстовый вывод | ✅ Доступен | $3.00 |
| Аудио/Видео ввод | ✅ Доступен | $3.00 |
| Ввод изображений | ✅ Доступен | По токенам |
С точки зрения сравнения цен, стоимость ввода Gemini 3 Flash составляет всего 25% от Pro, и стоимость вывода также всего 25% от Pro. Для большинства случаев использования, не требующих экстремальных возможностей рассуждения, Flash предлагает исключительно конкурентоспособную ценность.
Цены Gemini 3 Pro Image
Помимо обработки текста, Gemini 3 также предлагает возможности генерации изображений, внутреннее кодовое имя Nano Banana Pro. Генерация изображений использует отдельную структуру цен на основе размера и сложности изображения:
| Операция с изображением | Цена (USD) | Эквивалент токенов |
|---|---|---|
| Ввод изображения | $0.0011/изобр. | ~560 токенов |
| Вывод изображения (1K-2K размер) | $0.134/изобр. | ~1,120 токенов |
| Вывод изображения (до 4K размер) | $0.24/изобр. | ~2,000 токенов |
Примеры расчёта затрат
Для лучшей оценки фактических затрат использования, вот расчёты затрат для типичных сценариев:
Сценарий 1: Умная служба поддержки Предположим, в среднем 500 входных токенов и 200 выходных токенов за раунд диалога, используя Gemini 3 Flash, обработка 10,000 раундов ежедневно. Месячная стоимость: Ввод = 500 × 10,000 × 30 / 1,000,000 × $0.50 = $75; Вывод = 200 × 10,000 × 30 / 1,000,000 × $3.00 = $180; Итого примерно $255/месяц.
Сценарий 2: Анализ длинных документов Используя Gemini 3 Pro для анализа технического документа на 150K токенов и генерации отчёта-резюме на 2,000 токенов. Стоимость за раз = 150,000 / 1,000,000 × $2.00 + 2,000 / 1,000,000 × $12.00 = $0.30 + $0.024 = $0.324.
Сценарий 3: Генерация и проверка кода Команда разработчиков использует Gemini 3 Pro для генерации кода, в среднем 50K токенов входного контекста и требований ежедневно, выводя 20K токенов кода. Месячная стоимость = (50,000 × $2 + 20,000 × $12) / 1,000,000 × 30 = $10.20/месяц.
Лимиты квот и уровни использования
Лимиты квот являются одними из наиболее недооценённых, но критически важных факторов при использовании Gemini 3 API. Google применяет многоуровневую систему квот, предоставляя различные уровни доступа к ресурсам на основе истории платежей и масштаба использования пользователей. Понимание этих лимитов помогает лучше планировать архитектуру приложения и распределение ресурсов.
Объяснение уровней использования
Google делит пользователей API на четыре уровня использования, каждый из которых соответствует различным лимитам квот:
| Уровень | Квалификация | Применимые сценарии |
|---|---|---|
| Бесплатный | Пользователи из подходящих стран/регионов | Обучение, тестирование, прототипирование |
| Уровень 1 | Привязан платёжный аккаунт | Небольшие производственные приложения |
| Уровень 2 | Накопленные расходы >$250 и ≥30 дней | Средние приложения |
| Уровень 3 | Накопленные расходы >$1,000 и ≥30 дней | Крупномасштабное производственное развёртывание |
Повышение уровня не требует ручной заявки; система автоматически корректируется на основе ваших записей о расходах. Однако обратите внимание, что повышение уровня имеет 30-дневный период ожидания, поэтому планируйте заранее для крупномасштабных развёртываний.
Объяснение измерений квот
Лимиты квот Gemini 3 API включают три основных измерения, каждое из которых потенциально может стать узким местом использования:
RPM (Requests Per Minute) представляет количество запросов, разрешённых в минуту, в основном влияет на сценарии высокой конкурентности. Если ваше приложение должно обрабатывать много одновременных запросов пользователей, RPM может стать основным узким местом.
TPM (Tokens Per Minute) представляет общий объём токенов, разрешённый в минуту, включая как ввод, так и вывод. Для приложений, обрабатывающих длинные документы или генерирующих обширный контент, лимиты TPM могут быть более критичными, чем RPM.
RPD (Requests Per Day) представляет общее количество запросов, разрешённых в день, кумулятивный лимит. Даже если требования RPM и TPM выполнены, превышение RPD означает невозможность дальнейших вызовов API в этот день.
Сравнение квот моделей
Согласно официальной документации Google AI Studio, вот лимиты квот для различных моделей по уровням (Источник: страница Rate Limits Google AI Studio, проверено 2026-02-04):
Квоты Gemini 3 Pro:
| Уровень | RPM | TPM | RPD |
|---|---|---|---|
| Уровень 1 | 1,000 | 4,000,000 | 10,000 |
| Уровень 2 | 2,000 | 8,000,000 | 50,000 |
| Уровень 3 | 4,000 | 16,000,000 | 100,000 |
Квоты Gemini 3 Flash:
| Уровень | RPM | TPM | RPD |
|---|---|---|---|
| Бесплатный | 15 | 1,000,000 | 1,500 |
| Уровень 1 | 2,000 | 4,000,000 | 10,000 |
| Уровень 2 | 4,000 | 8,000,000 | 50,000 |
| Уровень 3 | 10,000 | 16,000,000 | Без лимита |
Данные о квотах показывают, что лимит RPM бесплатного уровня Flash довольно строгий (всего 15 RPM), но TPM относительно щедрый (1 миллион токенов/минуту), подходит для обработки меньшего количества, но более длинных запросов. Переход на платный уровень значительно увеличивает квоты.
Как проверить текущие квоты
В Google AI Studio вы можете проверить текущее использование квот: войдите в консоль AI Studio, нажмите «Квоты» в левом меню, где система отображает текущий уровень, использованные квоты и оставшийся лимит для каждой модели. Для пользователей Vertex AI информация о квотах доступна в разделе IAM и администрирование консоли Google Cloud.
Pro vs Flash: Какой выбрать?
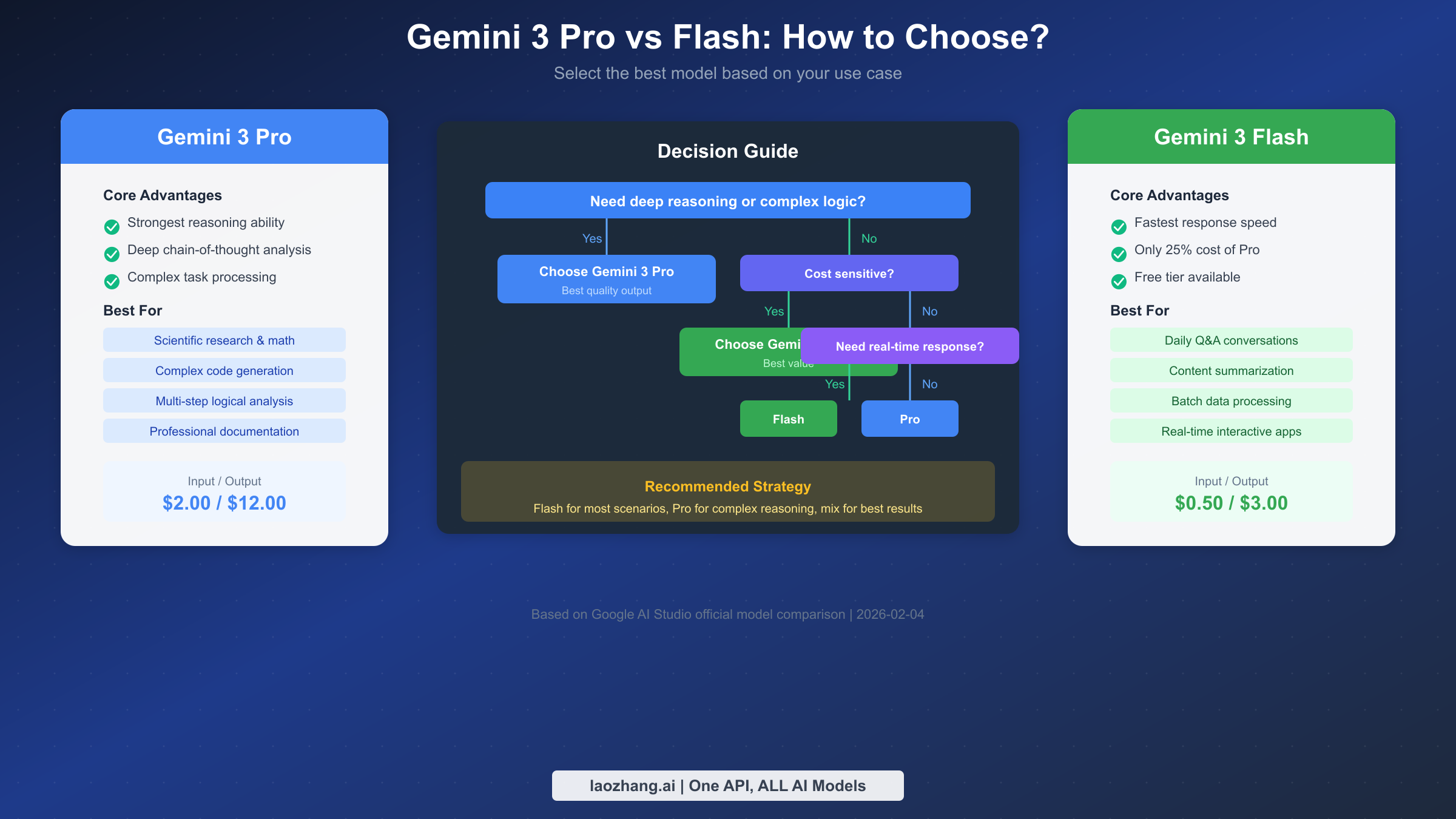
Выбор между Gemini 3 Pro и Flash — самое распространённое решение для разработчиков. Две модели значительно различаются по возможностям, ценам и квотам, и правильный выбор помогает значительно сократить затраты при сохранении качества.
Сравнение возможностей
Основное преимущество Gemini 3 Pro заключается в глубоких возможностях рассуждения. Он превосходно справляется с математическими задачами, логическим анализом, генерацией кода и пониманием сложных инструкций. Pro поддерживает более тонкий контроль thinking_level, позволяя увеличить «глубину мышления» для улучшения качества выполнения сложных задач. В бенчмарках Pro показывает заметно более высокие результаты, чем Flash на наборах MATH, HumanEval и MMLU.
Gemini 3 Flash оптимизирован для скорости ответа и экономической эффективности. Его Time To First Token (TTFT) на 40-60% ниже, чем у Pro, и общая скорость вывода выше. Хотя он уступает Pro в экстремально сложных задачах рассуждения, качество вывода Flash полностью соответствует требованиям для повседневных диалогов, суммаризации контента, простого дополнения кода и подобных сценариев.
Соотношение цена-производительность
С точки зрения экономической эффективности преимущество Flash очень очевидно. Для выполнения той же задачи Flash стоит всего около 25% от Pro. Если ваш случай использования не включает сложные рассуждения, использование Flash может сэкономить 75% затрат на API.
Но цена — не единственное соображение. Если качество выполнения задачи критически важно для бизнеса, улучшение качества от Pro может оправдать дополнительные инвестиции. Например, в высокорисковых сценариях, таких как анализ юридических документов или помощь в медицинской диагностике, более высокая точность Pro может снизить последующие затраты на ручную проверку.
Матрица рекомендаций по сценариям
На основе характеристик возможностей и соображений стоимости, вот рекомендации моделей для различных сценариев:
| Случай использования | Рекомендуемая модель | Причина |
|---|---|---|
| Ежедневные вопросы и диалоги | Flash | Быстрый ответ, низкая стоимость |
| Суммаризация и перевод контента | Flash | Простая задача, Flash достаточен |
| Математические и научные рассуждения | Pro | Требуется глубокий логический анализ |
| Сложная генерация кода | Pro | Высокие требования к качеству кода |
| Мультимодальное понимание контента | Flash | Похожие возможности, Flash экономичнее |
| Анализ длинных документов | Pro | Нужно понимание сложных контекстных связей |
| Пакетная обработка данных | Flash | Чувствительность к стоимости при большом количестве запросов |
| Приложения реального времени | Flash | Строгие требования к задержке |
На практике лучшая стратегия часто заключается в совместном использовании обеих моделей. Используйте Flash для первоначальной фильтрации и простых задач, затем передавайте контент, требующий глубокого анализа, в Pro, обеспечивая как качество, так и контроль затрат.
Практическое руководство по оптимизации затрат
Овладение техниками оптимизации затрат Gemini 3 может значительно сократить расходы на API. Google предоставляет несколько официальных механизмов оптимизации затрат, которые при правильном использовании могут значительно сократить расходы при сохранении качества обслуживания.
Объяснение Context Caching
Context Caching — самый мощный инструмент оптимизации затрат Gemini 3, способный сэкономить до 90% на оплате входных токенов. Он работает путём кэширования часто используемого контекстного контента на стороне сервера; последующие запросы, ссылающиеся на кэшированный контент, платят только минимальную плату за чтение кэша вместо пересчёта всех входных токенов.
Context Caching особенно подходит для: приложений, которые многократно анализируют один и тот же длинный документ, как системы проверки юридических документов; чат-ботов с фиксированными системными промптами; систем вопросов-ответов, которые постоянно ссылаются на контент базы знаний. Для включения Context Caching укажите содержимое кэша и время истечения при создании кэша, затем ссылайтесь на него в последующих запросах через параметр cached_content.
Плата за хранение кэша рассчитывается почасово, поэтому продолжительность кэширования должна определяться на основе частоты использования. Если контент вызывается десятки раз в час, долгосрочное кэширование целесообразно; при более низкой частоте вызовов краткосрочное кэширование или отсутствие кэширования может быть более экономичным.
Руководство по использованию Batch API
Batch API предоставляет 50% скидку на цену за счёт возможности ответа в реальном времени. Пакетные запросы обрабатываются во время простоя системы, обычно завершаясь в течение 24 часов после отправки. Этот режим идеален для задач, не требующих немедленных результатов, таких как анализ логов, модерация контента и пакетный перевод.
При использовании Batch API обратите внимание на несколько моментов: пакетные задания не имеют строгих гарантий SLA, и время обработки может варьироваться; отдельные пакетные задания имеют лимиты количества запросов; обработка ошибок пакетных запросов требует дополнительной логики, поскольку вы не можете немедленно повторить попытку при сбое.
Выбор платформы-посредника
Для разработчиков из регионов с ограниченным доступом прямой доступ к Google API может столкнуться с проблемами стабильности сети. Платформы-посредники API предоставляют надёжную альтернативу, развёртывая прокси-узлы за рубежом для пересылки запросов API на серверы Google, обеспечивая при этом стабильные интерфейсы внутреннего доступа.
При выборе платформ-посредников обратите внимание на несколько факторов: соответствует ли цена официальной или лучше, приемлема ли задержка ответа, поддерживаются ли все функции Gemini 3, а также стабильность платформы и качество технической поддержки. Такие платформы, как laozhang.ai, не только обеспечивают стабильный доступ к Gemini API, но и объединяют API от Claude, GPT-4o и других популярных моделей, что удобно для управления несколькими AI-сервисами на одной платформе. Документация API: https://docs.laozhang.ai/
Лучшие практики мониторинга затрат
Эффективный мониторинг затрат — ключ к предотвращению неожиданных счетов. Создайте комплексную систему мониторинга в начале проекта: установите пороги предупреждений о дневном и месячном бюджете; записывайте объёмы вызовов API и затраты для каждого функционального модуля; регулярно анализируйте шаблоны вызовов для выявления возможностей оптимизации; используйте счётчики токенов для оценки затрат перед запросами.
Google Cloud предоставляет встроенную функцию предупреждений о бюджете, которая отправляет уведомления при достижении заданных порогов затрат. Для более детального анализа затрат записывайте количество токенов и затраты для каждого вызова API на уровне приложения для создания подробных отчётов о затратах.
Сравнение цен с Claude/GPT-4o
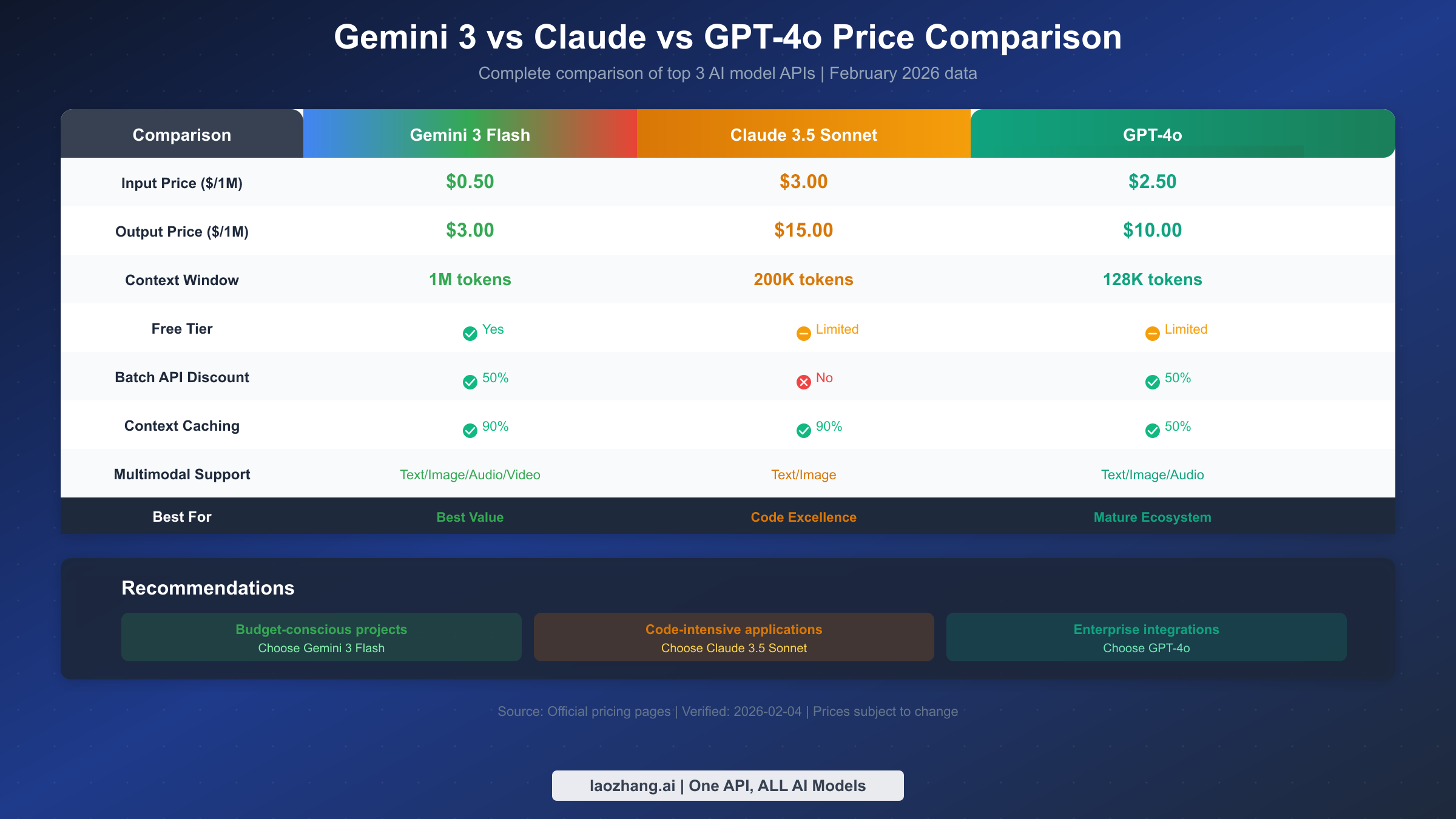
При выборе AI API-сервисов понимание различий в ценах между основными моделями помогает принимать более разумные решения. Здесь мы сравниваем Gemini 3 Flash с Anthropic Claude 3.5 Sonnet и OpenAI GPT-4o — тремя моделями одного уровня возможностей, которые в настоящее время являются самыми популярными вариантами AI API.
Прямое сравнение цен
| Параметр сравнения | Gemini 3 Flash | Claude 3.5 Sonnet | GPT-4o |
|---|---|---|---|
| Цена ввода ($/1M) | $0.50 | $3.00 | $2.50 |
| Цена вывода ($/1M) | $3.00 | $15.00 | $10.00 |
| Контекстное окно | 1M токенов | 200K токенов | 128K токенов |
| Бесплатный уровень | ✅ Да | ⚠️ Ограничен | ⚠️ Ограничен |
| Скидка Batch | 50% | Нет | 50% |
| Скидка кэширования | 90% | 90% | 50% |
С точки зрения чистой цены, Gemini 3 Flash предлагает наиболее конкурентоспособные цены — стоимость ввода составляет одну шестую от Claude и одну пятую от GPT-4o. По цене вывода Gemini 3 Flash также самый низкий — одна пятая от Claude и 30% от GPT-4o.
Сравнение бесплатных уровней
Три платформы имеют различные стратегии бесплатного уровня. Бесплатный уровень Gemini 3 Flash наиболее щедрый, предлагая 15 запросов в минуту и 1,500 запросов в день — вполне достаточно для индивидуальных разработчиков и тестирования. Claude и GPT-4o имеют более строгие лимиты бесплатного уровня, в основном предоставляемые через веб-интерфейс чата, доступ к API обычно требует оплаты.
Сильные стороны каждого
Хотя Gemini 3 Flash лидирует по ценам, разные модели превосходят в конкретных задачах. Gemini 3 Flash лидирует в мультимодальной обработке (поддержка аудио, видео ввода) и сверхдлинном контексте (1M токенов); Claude 3.5 Sonnet превосходит в генерации кода и написании длинных текстов, его функция «Artifacts» особенно удобна для разработчиков; GPT-4o имеет наиболее зрелую экосистему с богатейшими сторонними инструментами и интеграциями, плюс более полные корпоративные функции.
Для проектов с ограниченным бюджетом Gemini 3 Flash — лучший выбор по соотношению цена-качество; для приложений с интенсивным использованием кода Claude 3.5 Sonnet может стоить дополнительных инвестиций; для корпоративных приложений, требующих глубокой интеграции с существующими инструментами, преимущества экосистемы GPT-4o могут быть важнее. Использование агрегирующих платформ, таких как laozhang.ai, позволяет удобно переключаться между моделями для тестирования и поиска наилучшего варианта для ваших нужд.
Распространённые проблемы и обработка ошибок
При использовании Gemini 3 API проблемы, связанные с квотами, являются наиболее распространёнными трудностями разработчиков. Понимание причин ошибок и методов их обработки помогает создавать более надёжные приложения.
Причины и обработка ошибки 429
HTTP-код 429 означает «Слишком много запросов» и является стандартным ответом при превышении квоты. Распространённые причины срабатывания ошибки 429 включают: превышение RPM (слишком плотные запросы за короткое время), превышение TPM (общий объём токенов превышает лимит), превышение RPD (дневное общее количество запросов достигло лимита).
Стандартный подход к обработке ошибок 429 — реализация стратегии экспоненциального отступа при повторе. Конкретно: первый повтор ждёт 1 секунду, второй — 2 секунды, третий — 4 секунды и так далее, с максимальным временем ожидания не более 60 секунд. Также проверяйте заголовок Retry-After в ответе; если присутствует, используйте это значение как время ожидания.
Для производственных сред реализуйте ограничение запросов на уровне приложения для проактивного контроля частоты запросов в пределах квотных лимитов, а не полагайтесь на реактивные повторы после ошибок 429. Алгоритмы token bucket или sliding window могут реализовать плавное ограничение запросов.
Стратегии реагирования на превышение квоты
Когда лимиты квот становятся узким местом бизнеса, доступно несколько стратегий реагирования. Во-первых, подтвердите текущий уровень использования и оцените, можно ли повысить уровень за счёт увеличения расходов — квота значительно увеличивается после повышения уровня. Во-вторых, оптимизируйте архитектуру приложения: используйте Context Caching для уменьшения дублирования потребления токенов, объединяйте похожие запросы для уменьшения общего количества запросов.
Для ситуаций превышения RPD рассмотрите создание нескольких проектов Google Cloud, каждый с независимыми квотами. Обратите внимание, что этот подход должен использоваться в рамках Условий обслуживания Google; злоупотребление может привести к ограничениям аккаунта.
Распространённые вопросы о биллинге
Разработчики часто имеют вопросы о деталях биллинга. Во-первых, относительно использования данных бесплатного уровня, Google чётко заявляет, что данные вызовов API бесплатного уровня могут использоваться для улучшения модели, тогда как данные платного уровня получают более строгую защиту конфиденциальности. Во-вторых, относительно расчёта токенов, Gemini использует токенизатор, отличный от серии GPT — один и тот же текст может иметь разное количество токенов в разных моделях, поэтому используйте официальный инструмент подсчёта токенов Google для оценки затрат.
Другой распространённый вопрос касается биллинга thinking tokens. При использовании параметра thinking_level для усиления глубины рассуждений, сгенерированный моделью «процесс мышления» также учитывается в выходных токенах; этот контент возвращается через поле thought_signatures. В сценариях, чувствительных к затратам, балансируйте глубину мышления и расходы.
Резюме и следующие шаги
Благодаря этому подробному анализу вы теперь должны иметь полное понимание системы цен и лимитов квот Gemini 3 API. Ключевые выводы: цены Gemini 3 Pro составляют $2/$12 (ввод/вывод за миллион токенов), нет бесплатного уровня, подходит для сложных задач рассуждения; цены Gemini 3 Flash составляют $0.50/$3, с щедрым бесплатным уровнем, лучший выбор по соотношению цена-качество для большинства сценариев; Context Caching может сэкономить 90% затрат на ввод, Batch API предлагает 50% скидку; квоты управляются через уровни использования, которые автоматически повышаются при достижении пороговых значений расходов.
Для разных типов пользователей вот целевые рекомендации. Индивидуальные разработчики и учащиеся могут полностью использовать бесплатный уровень Gemini 3 Flash для исследования и прототипирования, временно переключаясь на Pro при необходимости глубоких рассуждений. Стартапам и небольшим проектам следует использовать Flash в качестве основной модели, установить мониторинг затрат, затем постепенно внедрять Pro для высокоценных задач после подтверждения ROI. Корпоративным пользователям следует рассмотреть Vertex AI для более полных корпоративных функций и поддержки, одновременно оценивая потенциал оптимизации Context Caching и Batch API.
Если вы готовы начать использовать Gemini 3 API, следующие шаги включают посещение Google AI Studio для создания аккаунта и получения API Key, обращаясь к нашему Руководству по получению API Key Gemini 3 для подробных шагов. Разработчики из регионов с ограничениями доступа также могут рассмотреть использование платформ-посредников, таких как laozhang.ai, для стабильного доступа. Какой бы подход вы ни выбрали, мы надеемся, что информация о ценах и квотах в этом руководстве поможет вам принять обоснованные технологические решения.