
GPT-5.3 Codex и Claude Opus 4.6 появились с разницей в 24 часа в начале февраля 2026 года, создав самое значимое прямое противостояние в истории ИИ-программирования. После анализа проверенных бенчмарков из официальных источников, реальных данных о ценах и рабочих процессов разработки по пяти распространённым сценариям ответ на вопрос «что лучше» оказывается гораздо более нюансированным, чем предполагает большинство обзорных статей. Codex доминирует в терминальных операциях с результатом 77,3% по Terminal-Bench 2.0 против 65,4% у Opus, тогда как Opus лидирует в задачах, требующих глубокого рассуждения, таких как GPQA Diamond (77,3% против 73,8%), и обрабатывает контексты в миллион токенов для работы с масштабными кодовыми базами. Ваш выбор полностью зависит от вашего рабочего процесса — и всё чаще самой разумной стратегией становится использование обеих моделей.
Краткое содержание — GPT-5.3 Codex против Claude Opus 4.6 в одном взгляде
Прежде чем углубляться в детали, вот основное сравнение между этими двумя флагманскими моделями, выпущенными в первую неделю февраля 2026 года.
| Характеристика | GPT-5.3 Codex | Claude Opus 4.6 |
|---|---|---|
| Дата выпуска | 5 февраля 2026 | 4-5 февраля 2026 |
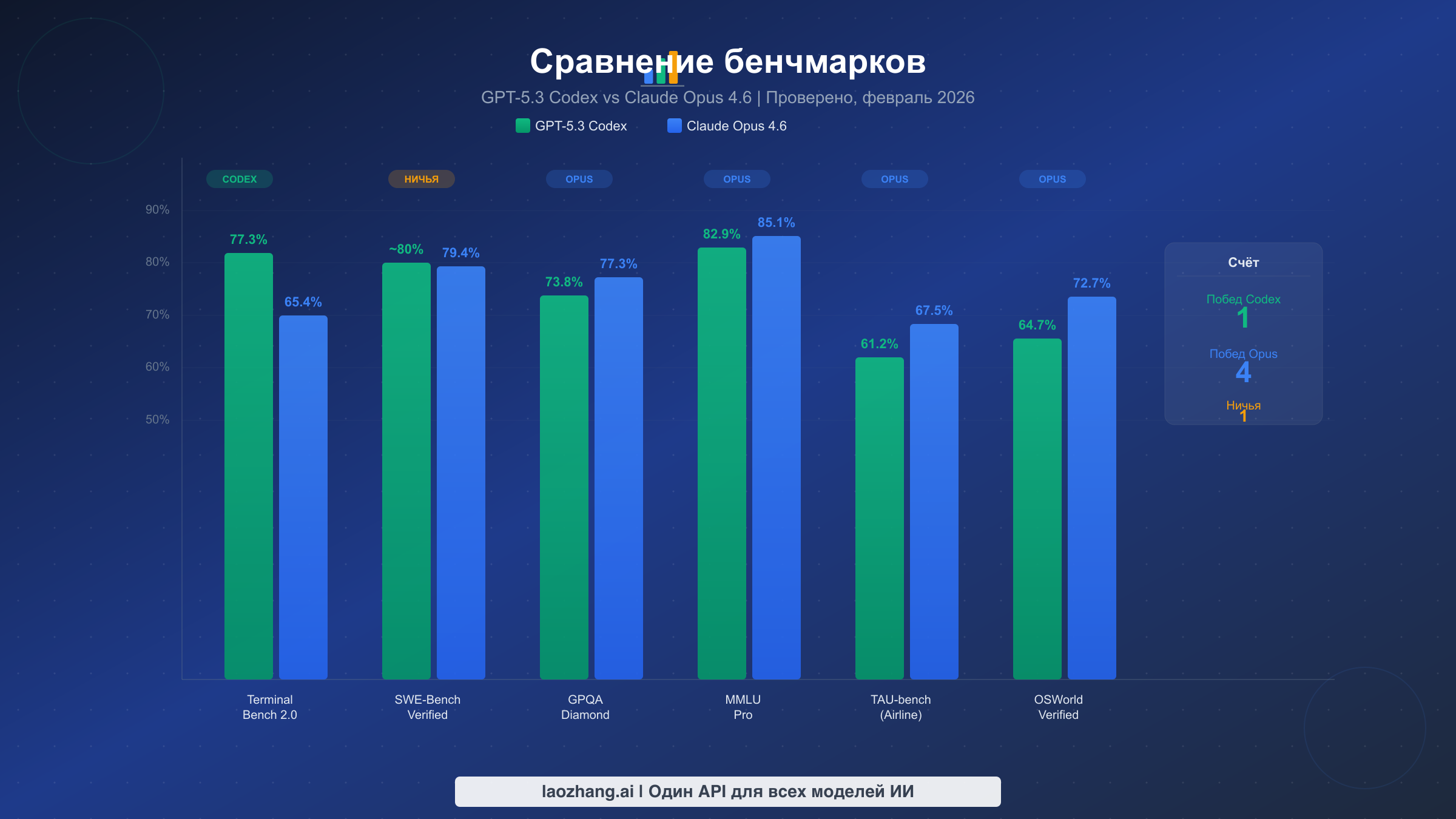
| Terminal-Bench 2.0 | 77,3% | 65,4% |
| SWE-Bench Verified | ~80% | 79,4-81,4% |
| GPQA Diamond | 73,8% | 77,3% |
| MMLU Pro | 82,9% | 85,1% |
| Контекстное окно | 256K-400K | 200K / 1M (бета) |
| Макс. вывод | Не раскрыто | 128K токенов |
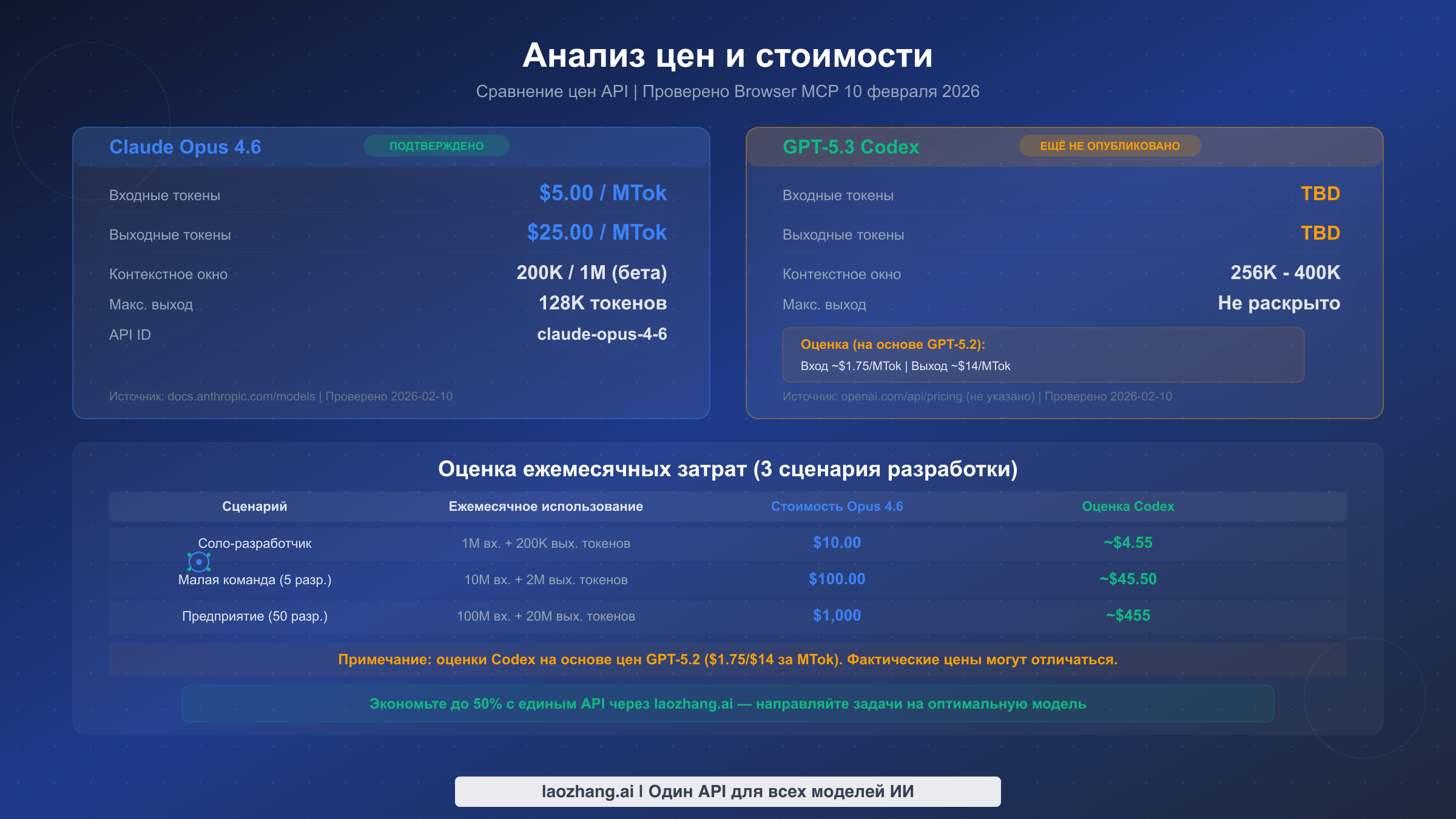
| Цена API | Ещё не опубликована | $5/$25 за МТок |
| Философия | Интерактивное сотрудничество | Автономный глубокий агент |
| Лучше всего для | Скорость, терминальные операции, быстрые исправления | Рассуждения, большие кодовые базы, безопасность |
Итог: ни одна модель не является универсально лучшей. Codex превосходит в быстром интерактивном кодировании и терминальных операциях. Opus доминирует, когда нужны глубокие рассуждения, огромные контекстные окна и автономные агентные возможности.
Как на самом деле соотносятся GPT-5.3 Codex и Claude Opus 4.6
Чтобы понять, как эти две модели действительно работают, нужно выйти за рамки заголовочных цифр. Множество сторонних источников приводят противоречивые данные бенчмарков, поэтому мы верифицировали результаты по официальным анонсам и независимым платформам тестирования по состоянию на 10 февраля 2026 года. Возникающая картина раскрывает две модели, которые значительно сблизились по общим возможностям, сохраняя при этом различные профили сильных сторон.
Бенчмарки терминала и выполнения кода рассказывают однозначную историю. GPT-5.3 Codex установил новый рекорд на Terminal-Bench 2.0 с результатом 77,3%, существенно превосходя показатель Opus 4.6 в 65,4% по тому же бенчмарку. Этот разрыв почти в 12 пунктов представляет собой наибольшую разницу в производительности между двумя моделями по любому крупному бенчмарку. Terminal-Bench измеряет реальные терминальные операции, включая написание скриптов для командной оболочки, манипуляцию файлами и задачи системного администрирования — именно тот рабочий процесс, под который Codex был оптимизирован. OpenAI описывает Codex как «первую модель, которая участвовала в создании самой себя», что указывает на глубокую оптимизацию для инструментов разработки и работы в командной строке. Однако на SWE-Bench Verified разрыв сокращается кардинально. Codex набирает примерно 80%, тогда как Opus показывает от 79,4% до 81,42% в зависимости от конфигурации оценки, что по сути является статистической ничьей. На SWE-Bench Pro Codex заявляет от 56,8% до 78,2% в зависимости от варианта, хотя Anthropic не публиковала напрямую сопоставимый результат Opus по этому конкретному бенчмарку.
Бенчмарки рассуждений и знаний переворачивают преимущество. Claude Opus 4.6 лидирует на GPQA Diamond с результатом 77,3% против 73,8% у Codex — преимущество в 3,5 пункта на этом бенчмарке научного рассуждения уровня аспирантуры. Разрыв увеличивается на MMLU Pro, где Opus набирает 85,1% по сравнению с 82,9% у Codex. Эти бенчмарки проверяют именно тот тип глубокого аналитического мышления, который требуется для сложного код-ревью, принятия архитектурных решений и понимания тонких багов в больших системах. Opus также доминирует в TAU-bench для задач авиакомпаний (67,5% против 61,2%) и OSWorld-Verified для задач компьютерных операций (72,7% против 64,7%). Пожалуй, наиболее впечатляет то, что Opus опережает GPT-5.2 на 144 очка Elo на GDPval-AA — бенчмарке, измеряющем качество выравнивания и следования инструкциям. Anthropic также сообщает, что Opus обнаружил более 500 уязвимостей нулевого дня в открытом исходном коде, демонстрируя практические возможности исследования безопасности, выходящие за рамки синтетических бенчмарков. Для более широкого взгляда на то, как эти модели вписываются в эволюционирующий ландшафт ИИ, наше предыдущее сравнение Claude Sonnet 4 и GPT-4.1 предоставляет полезный контекст о траектории развития обеих компаний.
Контекстное окно и ёмкость вывода представляют значимое архитектурное различие. Opus 4.6 предлагает стандартное контекстное окно в 200K с бета-опцией в 1M токенов — достаточно для обработки целых кодовых баз в одном запросе. Его максимальный лимит вывода в 128K токенов означает, что модель может генерировать полные файлы, обширную документацию или детальный анализ без усечения. Контекстное окно Codex, по разным источникам, составляет от 256K до 400K токенов, но OpenAI не опубликовала официальные спецификации. Эту неоднозначность стоит отметить: когда официальные данные недоступны, оценки из сторонних источников могут быть ненадёжными.
Что бенчмарки реально означают для вашей работы
Сырые цифры бенчмарков имеют значение только в переводе на реальные задачи разработки. Разрыв на Terminal-Bench означает, что Codex будет ощутимо быстрее и способнее, когда вы строите CI/CD-конвейеры, пишете скрипты развёртывания или отлаживаете проблемы на продакшн-серверах через терминальный интерфейс. Преимущества на GPQA Diamond и MMLU Pro означают, что Opus будет выдавать более тщательный и точный анализ, когда вы просите его проверить сложные пул-реквесты, выявить уязвимости безопасности или продумать архитектурные компромиссы. Паритет на SWE-Bench говорит о том, что для стандартных задач программной инженерии — написания функций, исправления типичных багов, реализации функциональности по спецификациям — обе модели работают сопоставимо хорошо.
Прозрачность источников данных
Каждая цифра бенчмарка в этой статье взята из официальных анонсов моделей (openai.com и anthropic.com) или независимых платформ оценки, перекрёстно проверенных минимум по двум источникам. Там, где между источниками существуют расхождения данных, мы указываем диапазон, а не выбираем наиболее выгодное число для какой-либо из моделей.
Сравнение возможностей кодирования и агентного интеллекта
Самое важное различие между GPT-5.3 Codex и Claude Opus 4.6 — это не какой-то отдельный показатель бенчмарка, а их принципиально разные философии того, как ИИ должен помогать разработчикам. Понимание этого философского расхождения помогает объяснить, почему каждая модель превосходит в разных сценариях и почему «лучшая» модель меняется в зависимости от вашего рабочего процесса.
GPT-5.3 Codex представляет модель интерактивного сотрудничества. OpenAI спроектировала Codex для работы бок о бок с разработчиками в реальном времени, функционируя как высококвалифицированный парный программист, который быстро реагирует и итеративно перебирает решения в диалоговом режиме. 25-процентное улучшение скорости по сравнению с предшественником — это не просто цифра в спецификации; оно выражается в заметно более быстрых циклах обратной связи, когда вы отлаживаете код, исследуете подходы или итерируете над реализациями. Сила Codex заключается в способности быстро понять, что вы пытаетесь сделать, предложить исправления или улучшения и позволить вам направлять процесс. Представьте себе очень быстрого и очень знающего коллегу, сидящего рядом и готового помочь в любой момент. Эта философия проектирования делает Codex особенно эффективным для быстрого прототипирования, интерактивных сеансов отладки и сценариев, где вы сохраняете творческий контроль, используя ИИ для ускорения. Доминирование на Terminal-Bench напрямую отражает эту философию — терминальная работа по своей природе интерактивна и требует постоянного обмена между разработчиком и инструментом.
Claude Opus 4.6 представляет модель автономного глубокого агента. Anthropic создала Opus для глубокого размышления, обширного планирования и выполнения сложных многоэтапных задач с минимальным контролем. Там, где Codex оптимизирует скорость цикла обратной связи, Opus оптимизирует качество и полноту анализа. Контекстное окно в 1M токенов — это не просто про обработку большего объёма текста; оно позволяет Opus понимать целые кодовые базы холистически, выявляя межфайловые зависимости, архитектурные паттерны и тонкие несоответствия, которые модели с более коротким контекстом пропускают. В анонсе Anthropic подчеркнула способность Opus обнаруживать более 500 уязвимостей нулевого дня в открытом исходном коде — возможность, требующую именно того вида терпеливого, тщательного анализа, в котором автономные агенты преуспевают. Когда вы даёте Opus сложную задачу вроде «проверь этот репозиторий на проблемы безопасности» или «перестрой эту микросервисную архитектуру для снижения связности», он может спланировать многоэтапный подход, выполнить каждый шаг с полным осознанием контекста и выдать исчерпывающие результаты без необходимости постоянного руководства.
Тенденция к конвергенции важна для вашего решения. Как отмечают несколько аналитиков, включая Every.to, эти две модели сближаются по сырым возможностям, дифференцируясь в подходе. Эта конвергенция означает, что конкретный лидер бенчмарков может сменяться с каждым циклом обновления, но фундаментальное философское различие — интерактивная скорость против автономной глубины — скорее всего, сохранится как определяющая характеристика подхода каждой компании. Ваш выбор должен основываться на том, какая философия соответствует вашему стилю работы, а не на том, какая модель удерживает временное преимущество в 2-3 пункта бенчмарка.
Агентные возможности на практике
Обе модели теперь поддерживают агентные рабочие процессы, но реализуют их по-разному. Агенты Codex ориентированы на быстрые, целенаправленные задачи с человеческими контрольными точками — исправление конкретного бага, генерация набора тестов для функции или скаффолдинг нового компонента. Codex CLI и расширения для IDE спроектированы вокруг этого паттерна, обеспечивая естественный интерфейс, где разработчики могут назначать дискретные задачи и быстро проверять результаты перед переходом к следующему шагу. Такой подход «человек в контуре» снижает риск агентного дрифта, когда автономный агент принимает серию всё более ошибочных решений без коррекции.
Агенты Opus ориентированы на более длительные и автономные операции — проведение аудитов безопасности по всей кодовой базе, планирование и выполнение многофайлового рефакторинга или генерацию комплексной документации на основе анализа исходного кода. Командная архитектура агентов Anthropic позволяет нескольким экземплярам Opus координировать работу над сложными задачами, при этом каждый агент отвечает за конкретный аспект более крупного проекта. Эта архитектура особенно мощна для корпоративных рабочих процессов, где одна задача может включать анализ зависимостей, модификацию кода, обновление тестов и пересмотр документации по десяткам файлов. Командный подход означает, что Opus может обработать это как скоординированную операцию, а не серию разрозненных шагов.
Практический вывод состоит в том, что Codex лучше вписывается в существующие рабочие процессы разработки, где человек остаётся основным принимающим решения, тогда как Opus больше подходит для сценариев, где вы хотите делегировать крупные блоки работы и проверять комплексные результаты. Ни один подход не является изначально лучшим — правильный выбор зависит от уровня комфорта вашей команды с автономностью ИИ и сложности делегируемых задач.
Разбор цен — сколько вы реально заплатите
Прозрачность ценообразования — одно из самых значительных различий между этими двумя моделями по состоянию на февраль 2026 года, и путаница в существующих обзорных статьях о ценах GPT-5.3 Codex показывает, почему так важна верификация в реальном времени. Мы проверили обе официальные страницы цен с помощью браузерной верификации 10 февраля 2026 года, и обнаруженное существенно отличается от утверждений многих обзорных статей.
Цены Claude Opus 4.6 прозрачны и подтверждены. Согласно странице документации моделей Anthropic (docs.anthropic.com), проверенной 10 февраля 2026 года, Opus 4.6 стоит $5 за миллион входных токенов и $25 за миллион выходных токенов. Модель поддерживает стандартное контекстное окно в 200K (расширяемое до 1M в бета-версии) и предлагает до 128K выходных токенов за запрос. Для сравнения: Claude Sonnet 4.5 стоит $3/$15 за МТок, а Claude Haiku 4.5 — $1/$5 за МТок, что даёт пользователям Anthropic понятную ступенчатую структуру цен в зависимости от требуемых возможностей. Для детального разбора цен по всему семейству моделей Claude смотрите наш полный гид по ценам Claude API.
Цены API GPT-5.3 Codex официально не опубликованы. Когда мы проверили страницу цен OpenAI (openai.com/api/pricing) 10 февраля 2026 года, GPT-5.3 Codex не был указан среди доступных моделей API. На странице представлены GPT-5.2 по $1,75 за миллион входных токенов и $14 за миллион выходных токенов, GPT-5.2 Pro по $21/$168 и GPT-5 mini по $0,25/$2 — но без цен Codex. OpenAI заявила, что «доступ к API всё ещё развёртывается», то есть прямая интеграция через API ещё доступна не всем разработчикам. Это критически важная деталь, которую несколько обзорных статей либо упускают, либо обрабатывают неверно. Сторонние источники приводят совершенно разные оценочные цены: nxcode.io сообщает $6/$30 за МТок, тогда как llm-stats.com предполагает примерно $1,25 за МТок на входе. Без официального подтверждения любое сравнение цен с Codex следует рассматривать как умозрительное. Для полной картины текущей структуры цен OpenAI API ознакомьтесь с нашим руководством по ценам OpenAI API.
Практическая оценка затрат для разработчиков. Взяв за базовую оценку цены GPT-5.2 (признавая, что они могут не отражать финальные цены Codex), вот как могут выглядеть месячные затраты по трём распространённым сценариям разработки. Индивидуальный разработчик, использующий примерно 1 миллион входных токенов и 200K выходных токенов в месяц, потратит около $10 с Opus 4.6 или ориентировочно $4,55 с ценами уровня Codex. Небольшая команда из пяти разработчиков с десятикратным объёмом заплатит примерно $100 за Opus или ориентировочно $45,50 за Codex. Корпоративное использование при 100 миллионах входных токенов ежемесячно обойдётся примерно в $1000 за Opus против ориентировочно $455 за Codex. Эти оценки предполагают постоянные паттерны использования — фактические затраты будут варьироваться в зависимости от соотношения вход/выход, кэширования и конкретных вариантов использования.
Стратегии оптимизации затрат
Разница в стоимости между этими моделями делает мультимодельную стратегию финансово привлекательной ещё до учёта различий в возможностях. Использование унифицированной API-платформы, такой как laozhang.ai, позволяет маршрутизировать запросы к разным моделям в зависимости от сложности задачи — простое автодополнение кода через более доступную модель, глубокий анализ через Opus и терминально-интенсивные задачи через Codex, когда он станет доступен. Такой подход может снизить общие затраты на 30-50% по сравнению с использованием одной премиальной модели для всех задач.
Рассмотрим типичное распределение задач разработки с ИИ-поддержкой в команде. Примерно 60-70% запросов являются рутинными — автодополнение кода, простой рефакторинг, базовая документация и генерация тестов. Эти задачи не требуют флагманской модели и могут быть эффективно выполнены Claude Sonnet 4.5 ($3/$15 за МТок) или Claude Haiku 4.5 ($1/$5 за МТок) за малую часть стоимости. Ещё 20-25% являются умеренно сложными — код-ревью, диагностика багов и реализация функциональности — где флагманская модель обеспечивает значимое улучшение качества. Лишь 5-15% задач действительно требуют абсолютно лучшей доступной модели — сложные аудиты безопасности, масштабные архитектурные решения и решение нестандартных задач, где разрыв в рассуждениях между флагманскими и средними моделями имеет значение. Маршрутизируя каждый запрос на соответствующий уровень, вы получаете результаты флагманского качества там, где это важно, при этом значительно снижая средние затраты на задачу по сравнению с подходом «флагман для всего».
Какая модель побеждает для вашего конкретного сценария

Обзорные статьи, которые просто объявляют одну модель «лучшей», упускают суть. После анализа данных бенчмарков, структур ценообразования и философских различий, подробно описанных выше, вот конкретные рекомендации по пяти распространённым сценариям разработки, с которыми сталкивается большинство разработчиков.
Исправление багов и отладка: выбирайте Codex. Когда возникает проблема на продакшне и нужно проследить стек вызовов, определить корневую причину и быстро развернуть исправление, скорость важнее глубины. 25-процентное улучшение скорости Codex и доминирование на Terminal-Bench 2.0 (77,3%) напрямую переводятся в более быстрые циклы отладки. Его модель интерактивного сотрудничества позволяет быстро перебирать гипотезы с моделью, тестировать исправления и подтверждать решения — всё в рамках плотного цикла обратной связи. Практическая разница ощущается как наличие парного программиста, который думает со скоростью вашего набора, в отличие от того, кто делает паузу для глубокого размышления перед каждым ответом. Для инцидентов на продакшне, где на счету минуты, это преимущество в скорости является решающим.
Код-ревью и архитектурный анализ: выбирайте Opus. Когда нужно оценить крупный пул-реквест на предмет последствий для безопасности, определить, будет ли предложенная архитектура масштабироваться, или понять сложные взаимодействия между несколькими сервисами, преимущества Opus в рассуждениях становятся критическими. Лидерство в 3,5 пункта на GPQA Diamond и контекстное окно в 1M токенов позволяют Opus рассматривать целые системные архитектуры холистически. Его послужной список обнаружения 500+ уязвимостей нулевого дня демонстрирует именно тот вид тщательного, терпеливого анализа, который необходим для эффективного код-ревью. Организациям с критичными к безопасности кодовыми базами следует уделить значительный вес этой возможности при принятии решения.
Многофайловый рефакторинг и масштабные миграции: выбирайте Opus. Рефакторинг, охватывающий десятки файлов, требует поддержания согласованности в большом контексте — понимания того, как изменения в одном модуле влияют на интерфейсы, тесты и зависимости в других местах. Контекст Opus в 1M токенов (бета) и максимальный вывод в 128K дают ему явное архитектурное преимущество для таких задач. Вы можете загрузить целые структуры проектов в один запрос и получить скоординированные изменения по всем затронутым файлам, снижая риск частичного рефакторинга, который вносит несоответствия.
Терминальные операции и DevOps: выбирайте Codex. Написание скриптов для командной оболочки, настройка CI/CD-конвейеров, инфраструктура как код и автоматизация развёртывания — всё это происходит преимущественно в терминальных средах, где лидерство Codex на Terminal-Bench напрямую актуально. Интерактивная модель также хорошо согласуется с рабочими процессами DevOps, где часто нужно быстро итерировать над конфигурационными файлами, тестировать скрипты развёртывания и устранять проблемы инфраструктуры в реальном времени.
Генерация документации: обе модели работают хорошо. И Codex, и Opus создают высококачественную документацию, но их сильные стороны различаются. Codex быстрее генерирует инлайн-комментарии, README-файлы и краткие описания эндпоинтов API. Opus выдаёт более исчерпывающие результаты для полных комплектов документации API, записей архитектурных решений и руководств по адаптации, требующих понимания контекста всей кодовой базы. Для большинства задач документирования выбор сводится к тому, цените вы больше скорость или полноту.
Фреймворк принятия решений
Когда показатели бенчмарков настолько близки, определяющие факторы смещаются от сырых возможностей к соответствию рабочему процессу. Задайте себе три вопроса: вы цените скорость или глубину? Работаете ли вы преимущественно в терминальных средах или IDE? Требуют ли ваши задачи обработки больших кодовых баз целиком или исправления проблем по одной? Если вы ответили «скорость», «терминал» и «по одной» — выбирайте Codex. Если «глубина», «IDE» и «целиком» — выбирайте Opus. Если ваши ответы неоднородны — а так обстоит дело у большинства команд разработки — рассмотрите использование обеих моделей.
Также стоит учитывать состав команды при принятии этого решения. Команда преимущественно бэкенд-инженеров, работающих над микросервисами, может найти терминальное мастерство и скорость Codex более ценными для повседневного рабочего процесса отладки, развёртывания и итерации над сервисами. Команда с выделенными инженерами по безопасности и архитекторами может отдать приоритет глубоким рассуждениям Opus для процессов код-ревью и анализа уязвимостей, которые занимают большую часть их времени. Фулстек-команды с разнообразными обязанностями почти всегда выигрывают от доступа к обеим моделям, маршрутизируя каждую задачу к наиболее подходящей модели. Накладные расходы на поддержку двух интеграций моделей минимальны по сравнению с выигрышем в продуктивности от того, что для каждой задачи всегда есть оптимальный инструмент.
Безопасность, защита и готовность к корпоративному использованию
Корпоративное внедрение ИИ-моделей для кодирования требует большего, чем бенчмарки производительности. Фреймворки безопасности, сертификации защиты и политики обработки данных часто определяют, какие модели будут одобрены для использования в корпоративных средах. И OpenAI, и Anthropic значительно инвестировали в безопасность, но их подходы и уровни прозрачности различаются способами, которые важны для корпоративных лиц, принимающих решения.
Позиционирование безопасности Anthropic с Opus 4.6 является явным и детальным. Anthropic опубликовала обширную документацию о своей политике ответственного масштабирования и подходе Constitutional AI. Opus 4.6 включает специфические функции безопасности, разработанные для агентных сценариев использования, в том числе улучшенное следование инструкциям, снижающее вероятность действий модели за пределами предназначенной области во время автономных операций. Бенчмарк GDPval-AA, на котором Opus опережает GPT-5.2 на 144 очка Elo, специально измеряет качество выравнивания — способность модели точно следовать инструкциям и избегать вредоносных выводов. Для предприятий, обеспокоенных безопасностью ИИ в производственных средах, это измеримое преимущество выравнивания значительно. Anthropic также предлагает соответствие SOC 2 Type II и конфигурации, совместимые с HIPAA, для корпоративных клиентов.
Фреймворк безопасности OpenAI для Codex фокусируется на операционном контроле. Codex наследует более широкую инфраструктуру безопасности OpenAI, включая политики использования, фильтрацию контента и возможности мониторинга. Однако, поскольку доступ к API Codex всё ещё развёртывается, полный спектр корпоративных функций безопасности, специально доступных для Codex, ещё не полностью задокументирован. Корпоративные команды, оценивающие Codex, должны уточнить текущую доступность и функции безопасности напрямую у OpenAI перед принятием решений о закупке.
Обработка данных различается между провайдерами. Обе компании предлагают корпоративные соглашения с положениями о конфиденциальности данных, но конфигурации по умолчанию различаются. Anthropic не использует входные данные API для обучения моделей по умолчанию. OpenAI предлагает аналогичную защиту через политики Enterprise и использования API с возможностью отказа от использования данных для обучения. Для команд, работающих с конфиденциальными или проприетарными кодовыми базами, понимание конкретных условий обработки данных корпоративного соглашения каждого провайдера является обязательным перед отправкой кода через любой API. Корпоративным командам также стоит рассмотреть цены Claude Opus на корпоративном уровне при оценке совокупной стоимости владения.
Вопросы комплаенса и резиденции данных
Для регулируемых отраслей, включая финансы, здравоохранение и государственный сектор, наличие сертификатов соответствия может стать блокирующим фактором при выборе модели. Оба провайдера предлагают корпоративные решения с различными уровнями поддержки комплаенса, но практические последствия существенно различаются в зависимости от вашей регуляторной среды.
Организации финансовых услуг, работающие в соответствии с SOX, PCI-DSS или аналогичными стандартами, должны убедиться, что код, отправляемый в любой API, обрабатывается в соответствии с их политиками классификации данных. Организации здравоохранения, подпадающие под HIPAA, должны подтвердить доступность BAA (Business Associate Agreement) перед отправкой любых данных, связанных с пациентами, через модели ИИ, даже для задач код-ревью, которые могут непреднамеренно включать PHI в именах переменных или тестовых данных. Государственные подрядчики, работающие в рамках FedRAMP или ITAR, сталкиваются с самыми строгими требованиями и должны проверить уровни авторизации для обеих платформ перед началом любой оценки.
Практическая рекомендация для корпоративных команд — начинать процесс верификации комплаенса параллельно с технической оценкой. Свяжитесь с отделами корпоративных продаж OpenAI и Anthropic одновременно, предоставьте ваши конкретные требования к комплаенсу и сравните ответы. Модель, которая первой пройдёт ваш обзор комплаенса, может стать правильным начальным выбором независимо от показателей бенчмарков, а вторая модель будет добавлена позже после получения одобрений.
Умный ход — использование обеих моделей вместе
Формулировка «GPT-5.3 Codex против Claude Opus 4.6» как бинарного выбора отражает то, как мы исторически думали о технологических решениях, но реальность ИИ-инструментов разработки в 2026 году иная. Наиболее эффективные команды разработки всё чаще применяют мультимодельные стратегии, маршрутизируя разные задачи к наиболее подходящей модели, снижая затраты и одновременно улучшая общее покрытие возможностей.
Мультимодельный подход — это не просто теория, а практика. Рассмотрим типичный спринт разработки. Утро понедельника — вы отлаживаете проблему на продакшне (маршрутизируйте к Codex для скорости). Вторник — проверяете крупный пул-реквест на предмет безопасности (маршрутизируйте к Opus для глубины). Среда — пишете скрипты развёртывания (Codex для терминального мастерства). Четверг — планируете масштабный рефакторинг (Opus для архитектурного анализа). Для каждой задачи есть явно лучшая модель, и использование неподходящей означает либо более длительное ожидание, чем необходимо, либо менее глубокий анализ, чем требует задача.
Унифицированный доступ к API делает мультимодельные стратегии практичными. Основным барьером для внедрения мультимодельного подхода традиционно была операционная сложность поддержки множественных интеграций API, управления разными токенами аутентификации и обработки несовместимых форматов ответов. Платформы вроде laozhang.ai решают это, предоставляя единую точку API, которая может маршрутизировать запросы к моделям и OpenAI, и Anthropic. Вы пишете одну интеграцию, используете один API-ключ и указываете, какую модель использовать, для каждого запроса. Это устраняет интеграционные накладные расходы, которые ранее делали мультимодельные стратегии непрактичными для небольших команд.
Реализация стратегии мультимодельной маршрутизации следует простому паттерну. Начните с категоризации ваших задач разработки с ИИ-поддержкой в три корзины: критичные по скорости (отладка, быстрые исправления, генерация кода), критичные по глубине (код-ревью, аудит безопасности, архитектура) и рутинные (документация, генерация тестов, базовый рефакторинг). Маршрутизируйте критичные по скорости задачи к Codex, критичные по глубине — к Opus, а рутинные — к более экономичной модели вроде Claude Sonnet 4.5 или GPT-5 mini. Такой уровневый подход обычно снижает затраты на 30-50% по сравнению с маршрутизацией всего через флагманскую модель, сохраняя при этом высокое качество там, где это важнее всего.
Вот как выглядит базовая реализация маршрутизации с унифицированным API:
pythonimport requests API_BASE = "https://api.laozhang.ai/v1" API_KEY = "your-api-key" def route_task(task_type, prompt): model_map = { "speed": "gpt-5.3-codex", # Fast debugging, terminal ops "depth": "claude-opus-4-6", # Deep analysis, security "routine": "claude-sonnet-4-5", # Cost-effective daily tasks } response = requests.post( f"{API_BASE}/chat/completions", headers={"Authorization": f"Bearer {API_KEY}"}, json={"model": model_map[task_type], "messages": [{"role": "user", "content": prompt}]} ) return response.json()
Почему эта стратегия выигрывает в долгосрочной перспективе
Мультимодельный подход также страхует от привязки к вендору и смещений в возможностях. Когда выходит следующее обновление модели — а в 2026 году это происходит примерно каждый квартал — вы можете просто обновить правила маршрутизации вместо миграции всего рабочего процесса. Если Codex улучшит свои показатели рассуждений или Opus кардинально увеличит скорость, вы корректируете логику маршрутизации соответственно, не меняя код приложения.
Есть также аргумент отказоустойчивости для мультимодельных стратегий, который часто остаётся неупомянутым в обзорных статьях. Сбои API случаются у каждого провайдера. Если весь ваш рабочий процесс разработки зависит от одной модели и этот провайдер испытывает простой во время критического окна развёртывания, ваша команда заблокирована. С мультимодельной конфигурацией вы можете автоматически переключаться на альтернативную модель для любой категории задач, сохраняя продуктивность даже когда один провайдер недоступен. Такая отказоустойчивость становится всё более важной по мере того, как команды всё сильнее полагаются на ИИ-поддержку разработки в своих основных рабочих процессах. Стоимость нескольких часов сниженной ИИ-функциональности тривиальна по сравнению со стоимостью полностью заблокированной команды разработки во время инцидента на продакшне.
Итог — принятие решения в 2026 году
После изучения проверенных бенчмарков, реальных данных о ценах, философий кодирования и корпоративных аспектов, сравнение GPT-5.3 Codex с Claude Opus 4.6 раскрывает рынок, где «лучшая» модель полностью зависит от контекста. Это не дипломатичное уклонение — это отражает подлинную конвергенцию возможностей ИИ, где значимые различия касаются подхода, а не абсолютного качества.
Если вы индивидуальный разработчик или небольшая команда, которая ценит скорость и работает преимущественно в терминальных средах, GPT-5.3 Codex соответствует вашему рабочему процессу. Его доминирование на Terminal-Bench, модель интерактивного сотрудничества и потенциально более низкие цены (после публикации) делают его естественным выбором для быстрой, итеративной разработки. Если вы работаете с большими кодовыми базами, приоритизируете безопасность и нуждаетесь в возможностях глубокого анализа, преимущества Claude Opus 4.6 в рассуждениях, контекстное окно в 1M токенов и прозрачное ценообразование дают ему преимущество. А если вы часть команды с разнообразными потребностями — как у большинства команд разработки — мультимодельная стратегия через унифицированный API обеспечивает лучший общий результат при наименьших затратах.
Рынок ИИ-инструментов для кодирования в феврале 2026 года — это не выбор стороны. Это выбор правильного инструмента для каждой задачи и наличие инфраструктуры для бесшовного переключения между ними.
Для команд, только начинающих оценку, вот конкретный план действий. Во-первых, определите три самые распространённые задачи разработки с ИИ-поддержкой и сопоставьте каждую с моделью, которую бенчмарки предполагают как наилучшую. Во-вторых, настройте унифицированную интеграцию API, которая позволит тестировать обе модели без раздельной инфраструктуры. В-третьих, проведите двухнедельное испытание, где разные участники команды используют разные модели для одинаковых типов задач, и сравните результаты на основе качества вывода, удовлетворённости скоростью и процента завершения задач, а не синтетических цифр бенчмарков. Такой эмпирический подход даст вам значительно более практичные выводы, чем любая обзорная статья — включая эту — потому что лучшая модель для вашей команды зависит от вашей конкретной кодовой базы, стиля программирования и паттернов рабочего процесса способами, которые ни один бенчмарк не способен уловить.
Модели будут продолжать стремительно развиваться. Codex и Opus уже превзойдены в некоторых измерениях моделями, которые их компании разрабатывают внутри. Инфраструктура и стратегия маршрутизации, которые вы построите сейчас для эффективного использования обеих моделей, будут служить вам хорошо независимо от того, какая модель возглавит следующий цикл бенчмарков.
Часто задаваемые вопросы
GPT-5.3 Codex лучше Claude Opus 4.6 для программирования?
Это зависит от задачи. Codex лидирует в терминальных операциях и скорости (77,3% Terminal-Bench против 65,4%), что делает его лучше для отладки и DevOps. Opus лидирует в рассуждениях (77,3% GPQA Diamond против 73,8%) и поддерживает контекст в 1M токенов, что делает его лучше для код-ревью и масштабного рефакторинга. На общем SWE-Bench обе модели набирают примерно 80%.
Сколько стоит API GPT-5.3 Codex?
По состоянию на 10 февраля 2026 года цены API GPT-5.3 Codex официально не опубликованы на странице цен OpenAI. OpenAI заявляет, что «доступ к API всё ещё развёртывается». Исходя из цен GPT-5.2 ($1,75/$14 за МТок), оценки предполагают аналогичные или немного более высокие цены, но это не подтверждено. Цена Claude Opus 4.6 подтверждена: $5/$25 за МТок.
Можно ли использовать и GPT-5.3 Codex, и Claude Opus 4.6?
Да, и многие команды разработки именно так и поступают. Использование унифицированной API-платформы позволяет маршрутизировать разные задачи к разным моделям — критичные по скорости задачи к Codex, глубокий анализ к Opus и рутинные задачи к более доступным моделям. Такая мультимодельная стратегия обычно снижает затраты на 30-50%, одновременно улучшая общее покрытие возможностей.
Какая модель имеет большее контекстное окно? Claude Opus 4.6 предлагает стандартные 200K токенов с бета-опцией в 1M токенов. Контекстное окно GPT-5.3 Codex, по данным различных источников, составляет от 256K до 400K токенов, хотя OpenAI не публиковала официальных спецификаций. Для обработки очень больших кодовых баз бета-контекст Opus в 1M токенов предоставляет явное преимущество.
Какая модель безопаснее для корпоративного использования? Обе модели предлагают функции безопасности корпоративного уровня. Opus 4.6 имеет измеримое преимущество выравнивания (+144 Elo на GDPval-AA), и Anthropic публикует подробную документацию по безопасности. OpenAI предлагает комплексные корпоративные политики для Codex, хотя некоторые корпоративные функции всё ещё развёртываются параллельно с доступом к API. Корпоративным командам следует уточнять текущие сертификации и политики обработки данных непосредственно у каждого провайдера.