
Короткий ответ: на 21 марта 2026 года GPT-5.4 mini обычно разумнее ставить default-маршрутом, если модель должна работать как coding subagent внутри OpenAI-native tool loop. Gemini 3 Flash обычно разумнее, если вы хотите более дешёвую мультимодальную fast lane с 1,048,576 входного контекста и grounding со стороны Google.
Эту тему легко испортить, если превратить её в фальшивую «битву бенчмарков». OpenAI в текущем latest model guide описывает GPT-5.4 mini как ветку для high-volume coding, computer use и agent workflows. Google на текущей странице Gemini 3 Flash описывает модель как свою strongest fast multimodal lane. Это уже разные продуктовые поверхности, а не просто два числовых ряда.
Поэтому полезный вопрос здесь другой: какую именно работу должен тянуть ваш fast model по умолчанию.
Краткое содержание
- Берите GPT-5.4 mini, если модель должна вести себя как coding worker внутри OpenAI-экосистемы, где важны
hosted shell,apply patch,MCPиtool search. - Берите Gemini 3 Flash, если важнее более дешёвая мультимодальность, большой контекст в 1.05M и Google grounding.
- Не пропускайте семейный split у Google: если вы склоняетесь к Gemini в основном из-за цены, следующим чтением должен быть материал Gemini 3.1 Flash-Lite vs Gemini 3 Flash.
| Область | GPT-5.4 mini | Gemini 3 Flash | Что это меняет |
|---|---|---|---|
| Дата запуска | 17 марта 2026 | 17 декабря 2025 | Обе модели актуальны |
| Официальная роль | high-volume coding, computer use, agents | strongest fast multimodal lane у Google | Разница в роли, а не только в цене |
| Input цена | $0.75 / 1M | $0.50 / 1M | Gemini дешевле |
| Output цена | $4.50 / 1M | $3.00 / 1M | И здесь Gemini дешевле |
| Context window | 400,000 | 1,048,576 | Gemini заметно сильнее на long context |
| Max output | 128,000 | 65,536 | GPT-5.4 mini может выдать больше |
| Knowledge cutoff | 2025-08-31 | январь 2025 | GPT-5.4 mini свежее |
| Отличающийся tool surface | hosted shell, apply patch, MCP, tool search, image generation | grounding, URL context, Maps, 1M input | Реальный split идёт по product surface |
Если после этого вы хотите закрыть вопрос внутри OpenAI, переходите к GPT-5.4 vs GPT-5.4 mini. Если важнее всего cheaper lane со стороны Google, логичный следующий шаг — Gemini 3.1 Flash-Lite vs Gemini 3 Flash.
Почему это не чистая битва бенчмарков
Быстрые comparison-страницы часто делают одну и ту же ошибку: берут benchmark-строки одного вендора, benchmark-строки другого, смешивают их в одну таблицу и назначают победителя. Для этого запроса такой подход слишком слабый.
OpenAI в запуске 17 марта 2026 года показывает для GPT-5.4 mini набор оценок вроде SWE-Bench Pro, Toolathlon, GPQA Diamond и OSWorld-Verified. Это хорошо показывает, на какой тип задач OpenAI делает ставку: coding, tool use, computer use, subagents.
Google, напротив, не публикует официальную одну таблицу «Gemini 3 Flash vs GPT-5.4 mini». Google даёт model page, pricing, rate limits, changelog и описание tool support. То есть у нас нет общей score ladder, зато есть достаточно данных, чтобы понять, какой workflow каждая модель тянет лучше.
Именно поэтому полезнее сравнивать:
- текущую официальную роль модели
- текущую цену и лимиты
- текущий tool surface
- реальное влияние на routing
Такой подход менее эффектный, но намного честнее для production-решения.
Цена, контекст и tool surface важнее, чем бренд
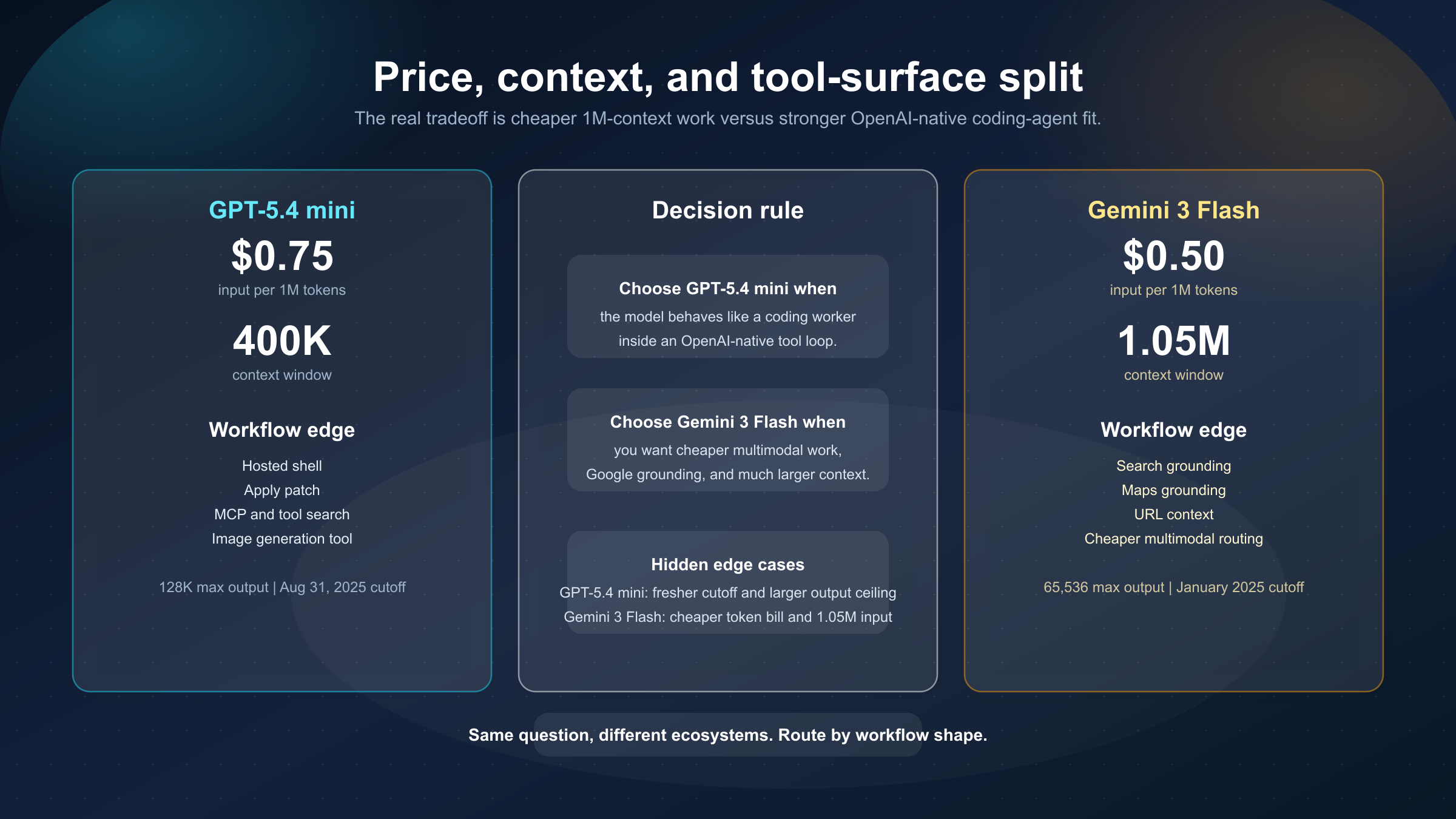
Самое простое для проверки — цена. На 21 марта 2026 года:
- страница GPT-5.4 mini указывает $0.75 input, $0.075 cached input, $4.50 output
- страница Gemini pricing указывает для Gemini 3 Flash $0.50 input и $3.00 output
То есть GPT-5.4 mini примерно в 1.5 раза дороже на стандартных токенах.
Второй большой разрыв — контекст. У GPT-5.4 mini это 400,000, у Gemini 3 Flash — 1,048,576 входных токенов. Если у вас длинные документы, большой repo, скриншоты, история и retrieval должны жить в одном контексте, Gemini 3 Flash даёт реальное преимущество.
Но у GPT-5.4 mini есть своя важная грань: максимум вывода 128,000, тогда как у Gemini 3 Flash — 65,536. Для больших diff, длинных структурированных ответов и объёмных артефактов это тоже может быть значимо.
Дальше начинается самое интересное — tool surface.
GPT-5.4 mini сейчас перечисляет:
- web search
- file search
- image generation
- code interpreter
- hosted shell
- apply patch
- skills
- computer use
- MCP
- tool search
Gemini 3 Flash перечисляет:
- batch API
- caching
- code execution
- computer use
- file search
- Search grounding
- Maps grounding
- structured outputs
- thinking
- URL context
Смысл тут не в том, что у одного «есть инструменты», а у другого «нет». Смысл в том, что GPT-5.4 mini лучше ложится на OpenAI-native coding-agent workflow, а Gemini 3 Flash — на более дешёвую large-context multimodal route внутри Google-стека.
Когда GPT-5.4 mini лучше как маршрут по умолчанию

GPT-5.4 mini выигрывает там, где модель должна не просто отвечать, а работать через инструменты как coding worker.
Наиболее типичные случаи такие:
1. Coding subagents и worker fleets. OpenAI буквально так и подаёт GPT-5.4 mini: high-volume coding и agents. Это не маленькая chat-модель, а рабочая ветка под production-нагрузку.
2. Repo и patch loops. Если ценность системы строится на hosted shell, apply patch, MCP и tool search, GPT-5.4 mini ближе к реальной задаче, чем Gemini 3 Flash.
3. Команды, уже стандартизированные на OpenAI. Если prompts, evals, tools и операционные привычки уже живут в Responses API или Codex-подобной модели, смена поверхности сама по себе стоит денег и времени.
4. Сценарии, где важен длинный output. Выходной потолок в 128K может быть важнее, чем сверхдлинный input, если worker генерирует большие патчи или длинные итоговые артефакты.
Сильнейший аргумент в пользу GPT-5.4 mini — не абстрактное «OpenAI лучше». Сильнейший аргумент — очень цельный product fit для coding-subagent работы.
Когда Gemini 3 Flash лучше как маршрут по умолчанию
Gemini 3 Flash лучше, когда вам нужнее дешёвая и широкая multimodal fast lane, чем coding-specialized route внутри OpenAI.
Самые очевидные сценарии:
1. Large-context multimodal work. 1,048,576 входных токенов — это серьёзный аргумент для длинных отчётов, больших repo, screenshot-heavy flows и длинной истории.
2. Более дешёвый serious throughput. Gemini 3 Flash не cheapest lane у Google, но он всё равно заметно дешевле GPT-5.4 mini.
3. Grounding как часть продукта. Search grounding и Maps grounding могут быть важнее, чем hosted shell и apply patch.
4. Один быстрый мультимодальный маршрут вместо coding-specialized route. Если нагрузка шире кода и включает текст, картинки, PDF, видео или audio, Gemini 3 Flash даёт более универсальную fast lane.
Сжатая формулировка выглядит так:
- GPT-5.4 mini — OpenAI-side coding subagent lane
- Gemini 3 Flash — Google-side cheaper large-context multimodal lane
Ключевая оговорка со стороны Google, которую часто пропускают

Здесь находится вывод, который чаще всего теряется в SERP.
Если вы склоняетесь к Gemini в основном потому, что он дешевле GPT-5.4 mini, полезно задать второй вопрос: вам правда нужен Gemini 3 Flash, или на самом деле нужен Gemini 3.1 Flash-Lite?
Текущие pricing и rate limits показывают, что Flash-Lite дешевле Flash и даёт более широкую batch lane на публичном Tier 1.
Это не значит, что Flash-Lite сильнее. Это значит, что Google уже сам разделил family на две fast lanes:
- Gemini 3 Flash — более сильная fast lane
- Gemini 3.1 Flash-Lite — более дешёвая и более throughput-heavy lane
Именно поэтому кросс-вендорный ответ нельзя сводить к тезису «Gemini дешевле, значит он лучше». Если главный фактор — цена, то реальным Google-side соперником GPT-5.4 mini часто оказывается именно Flash-Lite.
Что измерить перед тем, как сделать один default
Если вы собираетесь реально поставить одну из этих моделей маршрутом по умолчанию, смотреть только на цену токена или на среднюю задержку недостаточно. Практически важнее считать полную стоимость успешно завершённой задачи: повторные прогоны, ошибки инструментов, ручную проверку, компрессию контекста и стоимость fallback-маршрутов.
Полезнее всего сначала разрезать нагрузку по типам работ. Planner, repo worker, multimodal analysis, grounded answer и large-context synthesis не надо оценивать как одну и ту же работу. Сначала определите, какая ветка похожа на OpenAI-native coding loop, а какая — на Google-side large-context multimodal lane.
Рабочая матрица может выглядеть так:
| Тип нагрузки | С чего начать | Что мерить первым | Когда переключать |
|---|---|---|---|
| repo patch worker | GPT-5.4 mini | качество патча, стабильность tool use, завершение длинного output | повышать, если дорогие многошаговые фейлы |
| planner / orchestration | параллельный тест GPT-5.4 mini и Gemini 3 Flash | согласованность плана, цена ошибки, давление контекста | уходить в Gemini, если working set стабильно велик |
| multimodal analysis | Gemini 3 Flash | удержание длинного контекста, чтение скриншотов, total cost | возвращаться к mini, если нужен именно code-edit loop |
| grounded answer | Gemini 3 Flash | реальная ценность Search / Maps grounding | если grounding не даёт пользы, пересматривать mini |
Логика этой таблицы проста. GPT-5.4 mini имеет смысл оценивать как coding worker, а Gemini 3 Flash — как large-context multimodal fast lane. Для production важнее понять, где ошибка обходится дороже всего, чем спорить о том, какая модель «круче вообще».
Отдельно стоит измерять стратегию работы с контекстом. У Gemini 3 Flash преимущество в 1,048,576 токенов действительно велико, но только если система умеет использовать большой working set без превращения prompt в свалку. У GPT-5.4 mini окно меньше, зато в ясных tool-heavy цепочках это часто даёт более выгодную экономику и более предсказуемый operational profile.
Частые вопросы
Достаточно ли GPT-5.4 mini для серьёзных coding agents?
Во многих случаях да. OpenAI позиционирует её именно для high-volume coding, computer use и agent workflows. Если ваша цепочка больше похожа на repo work, patching и tool execution, чем на giant-context synthesis, GPT-5.4 mini часто оказывается вполне достаточной и при этом значительно более экономичной.
Главное преимущество Gemini 3 Flash — только цена?
Нет. Цена важна, но не менее важны 1,048,576 входных токенов и Google grounding. Многие задачи выглядят как «coding-задачи», хотя на деле ломаются не из-за качества patching, а из-за того, что модель не удерживает достаточно документов, скриншотов и длинной истории одновременно.
Можно ли выбрать одну модель и вообще отказаться от routing?
Можно, но это редко бывает лучшим operational решением. Один default упрощает схему, но заставляет либо переплачивать на одних ветках, либо терпеть нехватку headroom на других. Для многих команд стабильнее держать GPT-5.4 mini на coding execution, а Gemini 3 Flash — на multimodal и long-context ветках, повышая маршрут только там, где ошибка действительно дорога.
Ещё одна практическая проверка перед rollout — смотреть не только на средний результат, но и на хвост неудач. Если GPT-5.4 mini девять раз из десяти отлично проходит задачу, а на десятый ломает patch chain и вызывает дорогую ручную проверку, эта ветка быстро перестаёт быть дешёвой. И наоборот, если Gemini 3 Flash удерживает огромный контекст, но ваш workload почти не использует это преимущество, вы платите за запас, который системе не нужен. Поэтому решение стоит доводить до уровня конкретных очередей, веток и failure mode, а не оставлять на уровне общей таблицы.
Хороший production-тест в этой паре всегда заканчивается не вопросом «какая модель умнее», а вопросом «какая ветка даёт меньше дорогих провалов при моём типе нагрузки».
В реальной эксплуатации именно это отличие обычно важнее красивого vendor narrative или одной удачной демонстрации.
Чем раньше команда переведёт выбор модели в язык наблюдаемых затрат и сбоев, тем быстрее routing перестанет быть спором о вкусе и станет нормальным инженерным правилом.
И это почти всегда даёт лучший итог, чем выбор по бренду.
На практике так надёжнее.
Итог
Если нужен один прямой совет, он такой:
- ставьте GPT-5.4 mini, когда продукт по сути является coding-agent или subagent workflow внутри OpenAI-экосистемы
- ставьте Gemini 3 Flash, когда вам нужна более дешёвая multimodal fast lane с гораздо большим контекстом и grounding от Google
Для многих команд самый защищаемый ответ — не «выбрать одного победителя», а маршрутизировать по типу работы:
- GPT-5.4 mini для code-edit workers, repo loops и tool-heavy execution
- Gemini 3 Flash для более дешёвого multimodal analysis, long-context synthesis и grounded tasks
Решение становится намного яснее, когда вы перестаёте спрашивать «кто лучше вообще» и начинаете спрашивать «какой workflow должен нести мой fast default».