По состоянию на 20 марта 2026 года практичное правило такое: выбирайте GPT-5.4 mini, если продукту нужны более сильные coding-, computer-use- или агентные workflow, и выбирайте GPT-5.4 nano, если важнее дешёвый high-throughput режим. В официальном анонсе от 17 марта 2026 года OpenAI позиционирует GPT-5.4 mini как более сильную малую модель для coding и subagents, а GPT-5.4 nano прямо рекомендует для classification, data extraction, ranking и более простых supporting subagents.
Подвох этого сравнения в том, что модели кажутся более похожими, чем они есть на практике. У них одинаковые 400K context window, одинаковый 128K max output и одинаковый knowledge cutoff от 31 августа 2025 года. Если смотреть только на табличку со спецификациями, кажется, что вся разница сводится к цене. Это неверно. Реальный вопрос звучит так: нужна ли вам дополнительная рабочая глубина mini, или nano является лучшей операционной точкой именно потому, что ваши задачи дешевле, проще и повторяемее.
Краткое содержание
Если нужен быстрый вывод, используйте такую схему:
| Модель | Лучший сценарий | Главная причина выбрать | Главная причина не выбирать |
|---|---|---|---|
| GPT-5.4 mini | coding assistants, screenshot-heavy workflows, browser/desktop automation, более тяжёлые subagents | Сильнее в coding, tool use и computer use; поддерживает computer use и tool search | Существенно дороже: $0.75 input / $4.50 output за 1M токенов |
| GPT-5.4 nano | classification, extraction, ranking, дешёвый routing, простые subagents | Намного дешевле: $0.20 input / $1.25 output за 1M токенов; те же context и cutoff | Нет computer use и tool search, а на более тяжёлых tool-driven задачах модель заметно слабее |
Самое простое правило выбора:
- Если модель должна читать код, восстанавливаться после tool failure, работать с интерфейсом или быть более сильным worker внутри агентной системы, стартуйте с GPT-5.4 mini.
- Если модель в основном классифицирует, извлекает, ранжирует, роутит или делает дешёвые supporting tasks, стартуйте с GPT-5.4 nano.
- Если вы строите смешанную систему, лучший ответ часто не «mini или nano», а «mini для тяжёлой ветки, nano для дешёвой».
- Если вы ориентируетесь по именам из ChatGPT, сначала отделите ChatGPT-поверхность от API-выбора.
Настоящий водораздел - это не context, а глубина workflow
Многие comparison-страницы начинают с цены, контекста и cutoff, потому что эти поля проще всего собрать. Для этой темы это как раз то место, где слабый контент недодаёт читателю реальной пользы.
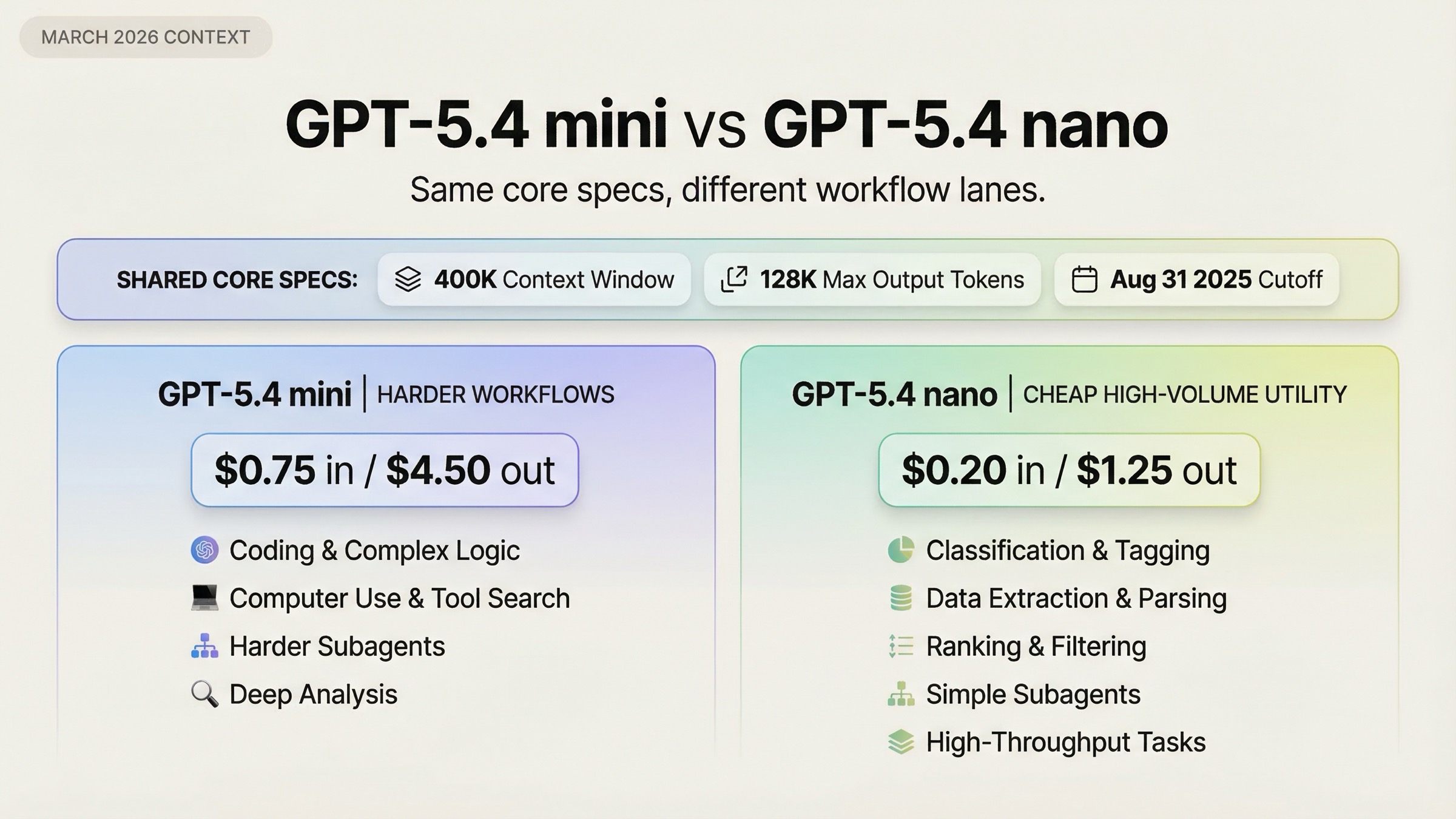
По текущим официальным model pages у GPT-5.4 mini и GPT-5.4 nano совпадают:
- 400K context window
- 128K max output
- knowledge cutoff на 31 августа 2025 года
- поддержка text и image input
Значит, выбор здесь не про «больше контекста» или «более свежую модель» в лоб. Эти бумажные характеристики у них почти одинаковые.
Разделение начинается там, где вы спрашиваете: что именно модель должна делать внутри production-системы.
В гайде по GPT-5.4 OpenAI описывает GPT-5.4 mini как вариант для high-volume coding, computer use и agent workflows, которым всё ещё нужен сильный reasoning. GPT-5.4 nano тот же гайд рекомендует для simple high-throughput tasks, где на первом месте speed и cost. Это гораздо полезнее, чем думать в парадигме «одна модель чуть сильнее другой».
Практический mental model выглядит так:
| Вопрос | Если ответ «да» | Лучший вариант |
|---|---|---|
| Нужно ли модели делать реальную coding-работу или codebase-level задачи? | Вам важны coding benchmarks и надёжность агента | GPT-5.4 mini |
| Нужны ли built-in computer use или UI-driven действия? | Работа идёт через скриншоты и интерфейс | GPT-5.4 mini |
| Основная задача - extraction, ranking или classification на очень больших объёмах? | Важнее throughput и cost | GPT-5.4 nano |
| Вы строите дешёвого worker под более крупным planner-моделью? | Нужен самый дешёвый, но всё ещё полезный исполнитель | GPT-5.4 nano |
Именно это объясняет цену. OpenAI не берёт больше за mini из-за большего окна контекста. Доплата идёт за более сильного tool-and-agent worker.
Цена, rate limits и поддержка tools бок о бок
Прежде чем смотреть на benchmarks, нужно честно увидеть ценовую разницу.
Согласно официальным страницам GPT-5.4 mini и GPT-5.4 nano, перепроверенным 20 марта 2026 года:
| Параметр | GPT-5.4 mini | GPT-5.4 nano |
|---|---|---|
| Input price | $0.75 / 1M tokens | $0.20 / 1M tokens |
| Cached input | $0.075 / 1M tokens | $0.02 / 1M tokens |
| Output price | $4.50 / 1M tokens | $1.25 / 1M tokens |
| Context window | 400K | 400K |
| Max output | 128K | 128K |
| Knowledge cutoff | 2025-08-31 | 2025-08-31 |
| Snapshot | gpt-5.4-mini-2026-03-17 | gpt-5.4-nano-2026-03-17 |
То есть GPT-5.4 mini примерно в 3.75 раза дороже по input, в 3.75 раза дороже по cached input и в 3.6 раза дороже по output. Это уже не «чуть дороже», а осмысленный архитектурный выбор.
С rate limits разница меньше, чем многие ожидают. На текущей compare-models странице основное отличие видно на младших paid tiers, а не по всей линейке:
| Tier | GPT-5.4 mini TPM | GPT-5.4 nano TPM |
|---|---|---|
| Tier 1 | 500,000 | 200,000 |
| Tier 2 | 2,000,000 | 2,000,000 |
| Tier 3 | 4,000,000 | 4,000,000 |
| Tier 4 | 10,000,000 | 10,000,000 |
| Tier 5 | 180,000,000 | 180,000,000 |
Поэтому на paid production tiers спор обычно не про TPM, а про unit economics и соответствие задаче.
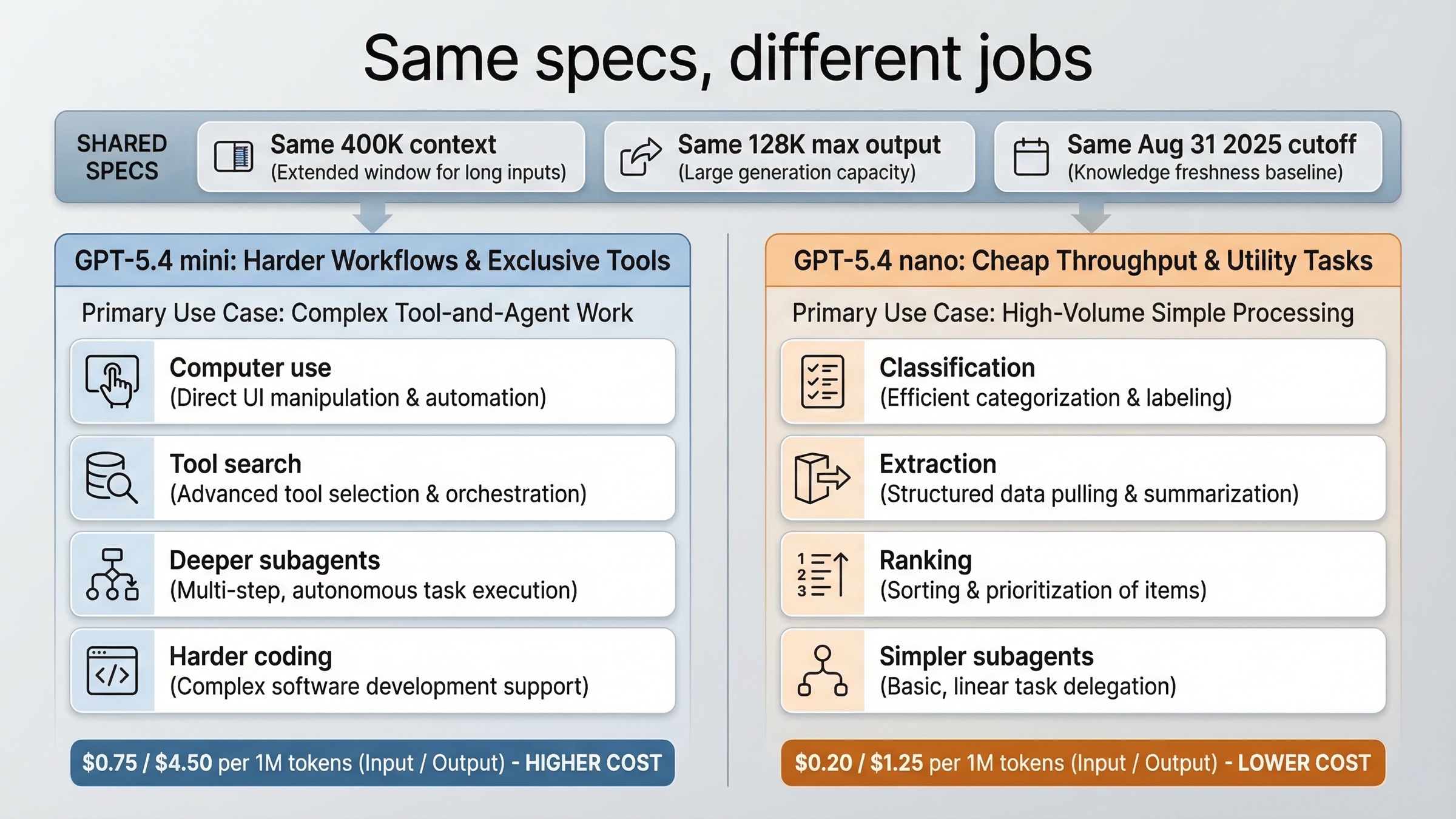
Гораздо важнее посмотреть на tools:
| Возможность | GPT-5.4 mini | GPT-5.4 nano |
|---|---|---|
| Web search | Yes | Yes |
| File search | Yes | Yes |
| Image generation tool | Yes | Yes |
| Code interpreter | Yes | Yes |
| Hosted shell | Yes | Yes |
| Apply patch | Yes | Yes |
| Skills | Yes | Yes |
| Computer use | Yes | No |
| MCP | Yes | Yes |
| Tool search | Yes | No |
Здесь и начинается самая интересная часть.
Nano - не «урезанная игрушка». Он всё ещё поддерживает hosted shell, apply patch, skills и image generation. То есть для узких агентных задач это вполне рабочий исполнитель.
Но mini сохраняет две возможности, которые лучше всего отделяют тяжёлые agent workflows от более простых: built-in computer use и tool search. Это не второстепенные фишки. Они критичны, когда модель должна ориентироваться по скриншотам или выбирать нужные tools в более крупной экосистеме.
Именно поэтому сравнение не стоит сводить к «сильнее против дешевле». Правильный вопрос: нужны ли вашему продукту эти дополнительные workflow-surface настолько, чтобы платить цену mini.
Benchmark gaps, которые действительно меняют решение
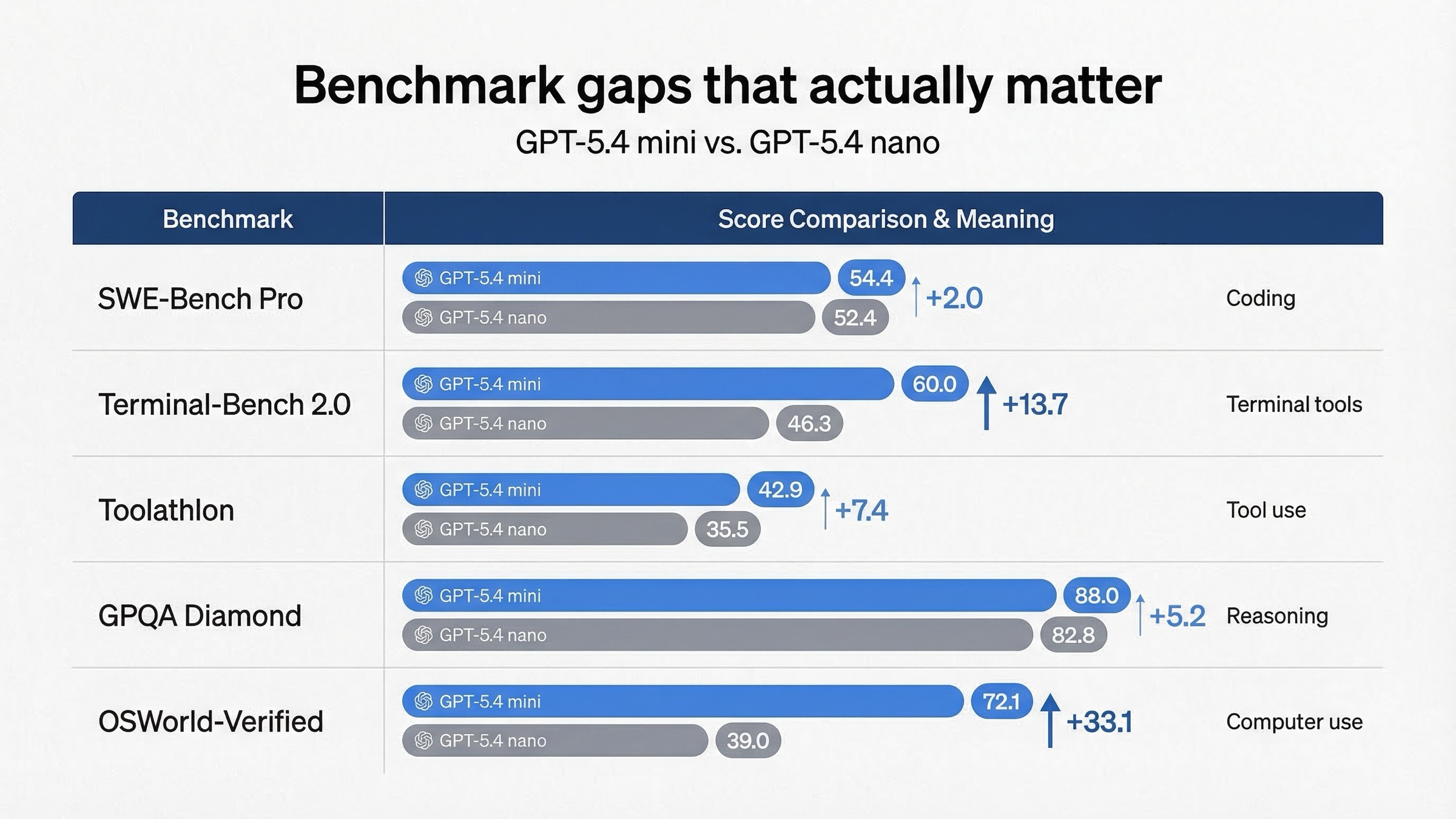
В launch post от 17 марта 2026 OpenAI даёт самую чистую официальную таблицу mini vs nano:
| Benchmark из launch post | GPT-5.4 mini | GPT-5.4 nano | Что это реально означает |
|---|---|---|---|
| SWE-Bench Pro (Public) | 54.4% | 52.4% | Mini лучше на реальных software-issue задачах, но разрыв не гигантский |
| Terminal-Bench 2.0 | 60.0% | 46.3% | На terminal-style tool work mini заметно сильнее |
| Toolathlon | 42.9% | 35.5% | Mini надёжнее в tool use |
| GPQA Diamond | 88.0% | 82.8% | У mini выше запас на сложном reasoning |
| OSWorld-Verified | 72.1% | 39.0% | Для computer-use workflows mini уже в другой весовой категории |
Из этой таблицы важнее всего три вывода.
Первый: преимущество mini не одинаково по всем направлениям. Разрыв в SWE-Bench реален, но не настолько велик, чтобы любую coding-задачу автоматически отправлять в mini. Если это простые supporting subtasks внутри большей системы, nano может быть рациональнее.
Второй: по-настоящему mini отрывается на terminal-heavy, tool-heavy и computer-use-heavy задачах. Это отлично совпадает с тем, что мы уже увидели в tool-support таблице.
Третий: nano не слабая модель, а дешёвая ветка с вполне достойным capability floor. OpenAI фактически говорит: используйте nano там, где нужны скорость и дешёвый рабочий исполнитель для простых задач; используйте mini, когда supporting tasks уже перестают быть простыми.
Это как раз та граница, которую текущая выдача часто не проговаривает. Там есть цифры, но нет бюджетного вывода.
Простое рабочее правило:
- Платите за mini там, где ошибка, медленное восстановление или неудачный tool flow действительно дорого стоят.
- Используйте nano там, где задача настолько дешевая, узкая или повторяемая, что дополнительный запас mini скорее будет переплатой.
Когда GPT-5.4 mini действительно стоит своих денег
GPT-5.4 mini оправдывает цену тогда, когда модель работает не как дешёвый классификатор, а скорее как более сильный оператор.
Самый понятный сценарий - coding assistants. OpenAI прямо позиционирует mini под coding workflows, и benchmarks это подтверждают. Если модель должна перемещаться по codebase, читать несколько файлов, восстанавливаться после failed tool call, понимать diff и стабильно работать в coding harness, mini будет более надёжным default.
Второй сценарий - computer use и screenshot-heavy workflows. Здесь mini отрывается особенно заметно. Если системе нужно читать UI, действовать через software interface или работать по плотным скриншотам в структурированном цикле, mini не просто «чуть лучше». Это единственная модель в этой паре с built-in computer use.
Третий сценарий - более тяжёлые subagent-задачи. Launch post прямо описывает паттерн Codex, где большая модель планирует, а малая выполняет более узкие subtasks. Если subtasks всё ещё требуют ощутимого coding-judgment, выбора tools или более надёжного tool-behavior, mini здесь уместнее.
Четвёртый сценарий - более сложные tool ecosystems. Tool search легко недооценить, но если у вас много tools, namespaces или MCP surfaces, mini даёт реальное преимущество. Nano лучше там, где toolset небольшой и фиксированный.
GPT-5.4 mini стоит выбирать, если большинство пунктов ниже про вас:
- модель делает содержательную coding-работу, а не крошечные правки;
- требуется computer use или screenshot-grounded reasoning;
- tool failure приводит к лишней задержке, ретраям и потере доверия;
- worker встроен в agent-систему, но subtasks всё ещё не простые;
- скрытые инженерные издержки важнее чистой цены токена.
Именно последний пункт команды чаще всего недооценивают. Повторные попытки, fallback-ветки, сложные prompts, ручные вмешательства и пользовательская задержка тоже стоят денег. Mini оправдан там, где он снижает эти скрытые расходы.
Когда GPT-5.4 nano - правильный default
GPT-5.4 nano - это не просто выбор на случай маленького бюджета. Это модель, которую стоит брать, когда задача изначально должна жить в дешёвой ветке.
OpenAI прямо рекомендует nano для classification, data extraction, ranking и более простых coding subagents. В практическом переводе это означает:
- классификацию user intent или support tickets;
- извлечение структурированных полей из текста;
- ранжирование кандидатов или результатов;
- routing запросов дальше по системе;
- простые supporting tasks под более крупным planner-моделью.
В таких случаях продукт обычно выигрывает именно от более низкой цены и более дешёвого throughput, а не от максимальных benchmark ceilings.
Nano также хорош, когда общая система сложна, но конкретная подзадача операционно неглубока. Например, у вас есть крупный planner или более сильный worker для сложных веток, но nano можно отдать такие вещи:
- краткое summary tool output перед возвратом planner'у;
- фильтрацию или приоритизацию candidate documents;
- extraction полей для downstream rules engine;
- дешёвую validation или routing-работу.
Поэтому о nano лучше думать не как о «более слабой универсальной модели», а как о более дешёвом специалисте для простых lanes.
GPT-5.4 nano - лучший default, если большинство пунктов совпадает:
- задача узкая, повторяемая и структурно простая;
- важнее unit economics, чем edge-case capability;
- не нужен built-in computer use;
- не нужен tool search по большой tool surface;
- вы проектируете supporting worker под более крупным coordinator'ом.
Иначе говоря, nano - правильный ответ, когда ваш настоящий вопрос не «какая модель сильнее», а «какая самая дешёвая модель всё ещё делает эту работу достаточно хорошо».
Во многих системах лучший ответ - не одна модель, а обе
Именно этот кусок чаще всего отсутствует в comparison-статьях, хотя на практике он самый полезный.
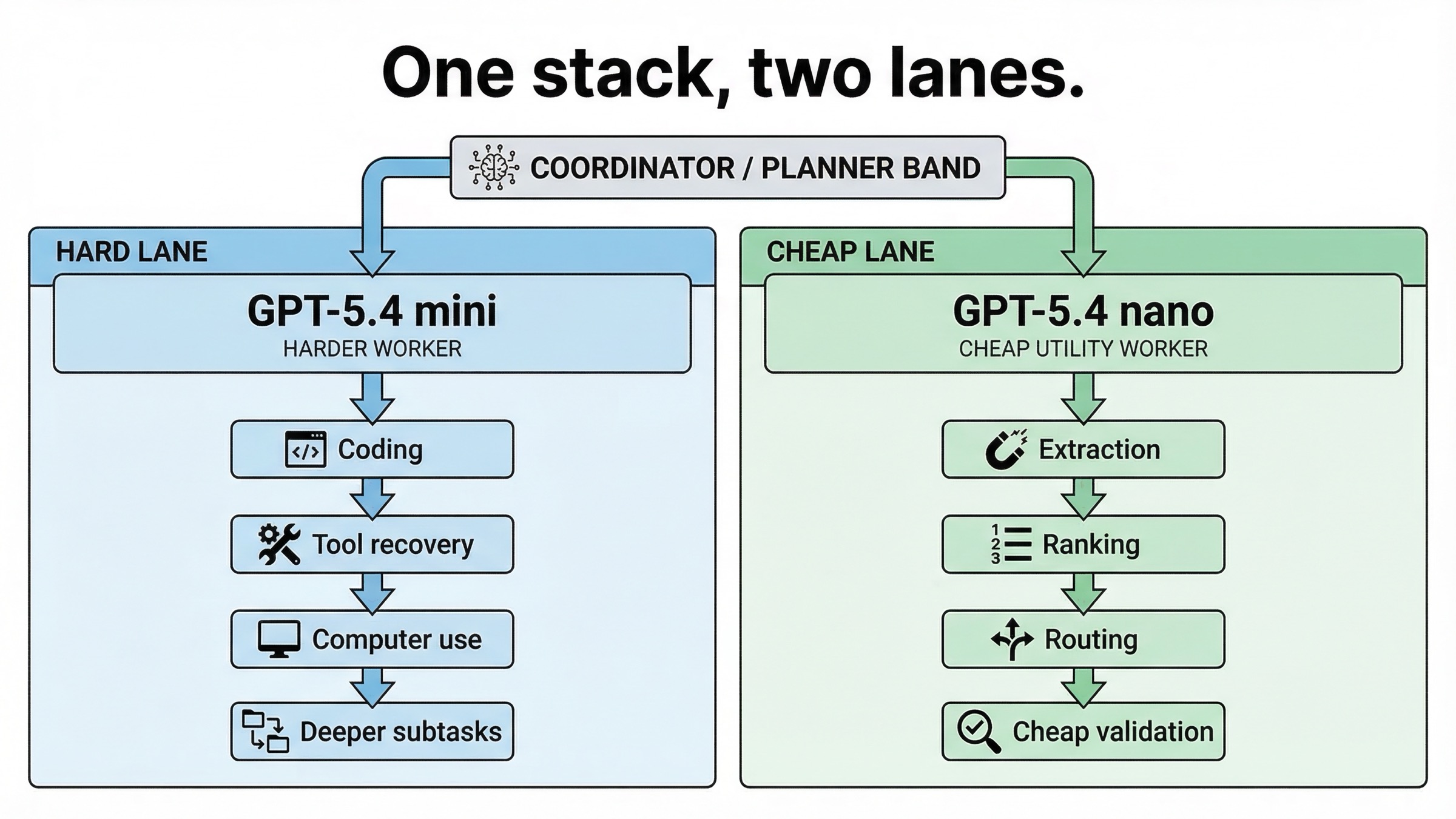
Если у продукта один тип запроса, можно выбирать между mini и nano напрямую. Но большинство реальных систем имеют как минимум две ветки:
- тяжёлую ветку, где важны coding, tool recovery, screenshot interpretation или более глубокий reasoning;
- дешёвую ветку, где доминируют extraction, ranking, classification или support tasks.
В таком случае принуждать одну модель закрывать обе роли часто хуже, чем разнести их по разным lanes.
Практическая схема выглядит так:
| Lane | Лучшая модель | Почему |
|---|---|---|
| Более сильный worker рядом с planner | GPT-5.4 mini | Лучше coding depth, tool reliability и computer-use работа |
| Дешёвый helper или supporting worker | GPT-5.4 nano | Лучшая экономика на узких повторяемых задачах |
Именно такую архитектуру фактически подразумевает launch post, когда говорит о subagents. Mini может брать более сильную worker-роль, а nano - дешёвую utility-ветку, если subtasks действительно простые.
Поэтому если команда спорит «нам стандартизироваться на mini или на nano», более правильный ответ часто звучит так: сначала стандартизируйтесь на routing logic, а уже потом закрепляйте model-per-lane.
API, Codex и ChatGPT: не смешивайте эти поверхности
Этот keyword часто приводит людей с разных product surfaces, отсюда и путаница.
Для API картина проста:
- GPT-5.4 mini доступен в API.
- GPT-5.4 nano доступен в API.
Для Codex launch post даёт более конкретную формулировку: GPT-5.4 mini доступен в Codex app, CLI, IDE extension и web, а сам Codex может делегировать subtasks в GPT-5.4 mini subagents. GPT-5.4 nano так же явно как surface-модель для Codex не описывается.
С ChatGPT всё проще перепутать. Launch post действительно говорит, что GPT-5.4 mini доступен через некоторые ChatGPT paths, но текущая Help Center статья одновременно объясняет, что logged-in users по умолчанию видят GPT-5.3, а вручную на paid tiers выбирается GPT-5.4 Thinking. Значит, опыт внутри ChatGPT нельзя автоматически трактовать как рекомендацию по API.
Если вы решаете вопрос «какой API model покупать», ориентируйтесь на model pages и launch post. Если решаете вопрос «что видно в ChatGPT», ориентируйтесь на Help Center. Названия пересекаются, но продуктовые решения здесь разные.
FAQ
GPT-5.4 mini всегда лучше GPT-5.4 nano?
Он сильнее, но не всегда лучше как решение. Для простых high-volume задач nano часто правильнее именно потому, что его стоимость ниже, а OpenAI и рекомендует его для таких jobs.
Что выбрать для coding?
Если это реальная coding-работа, берите mini. Если это простой supporting subagent внутри большей coding-системы, nano может быть вполне достаточным. Чем глубже tool flow и чем больше требуется judgement, тем сильнее ответ смещается к mini.
Что выбрать для extraction и ranking?
OpenAI прямо рекомендует nano для classification, data extraction и ranking. Поэтому разумный default - начинать тест именно с nano, если только ваш кейс не оказывается сложнее, чем выглядит.
Поддерживает ли GPT-5.4 nano tools вообще?
Да. Nano всё ещё поддерживает web search, file search, image generation, code interpreter, hosted shell, apply patch, skills и MCP. Ключевые отсутствующие по сравнению с mini возможности - computer use и tool search.
С чего новой команде начинать: mini или nano?
Начинайте не с названия, а с реальной job-to-be-done. Если это coding-heavy или agent-heavy работа - с mini. Если это дешёвый throughput - с nano. Если в продукте явно есть обе ветки, планируйте обе.
Финальная рекомендация
Если нужно одно предложение для команды, пусть оно будет таким: GPT-5.4 mini - правильный default для более тяжёлых coding и agent workflows, а GPT-5.4 nano - правильный default для дешёвой high-volume utility-работы.
Этот вывод опирается на пять фактов, перепроверенных 20 марта 2026 года:
- У моделей одинаковые context window, max output и knowledge cutoff.
- Nano значительно дешевле.
- Mini сильнее в benchmarks, когда речь идёт о coding, tool use и computer use.
- Mini поддерживает computer use и tool search, а nano - нет.
- OpenAI прямо рекомендует nano для classification, extraction, ranking и более простых supporting subagents.
Поэтому настоящий вопрос не в том, «какая модель сильнее». Сильнее mini. Настоящий вопрос в том, достаточно ли проста ваша задача, чтобы платить за mini было уже избыточно. Во многих production-системах правильный ответ состоит в том, чтобы дать двум моделям разные lanes.