
Короткий ответ: для большинства команд GPT-5.4 уже лучше в роли модели по умолчанию. OpenAI выпустила GPT-5.4 5 марта 2026 года и в актуальном гайде по выбору моделей уже ставит ее на место основного варианта для сложного reasoning и coding. Если вы сейчас сравниваете GPT-5.4 и GPT-5.2 именно как рабочий default для API или Codex, то официальный ответ уже сместился в сторону GPT-5.4.
Это не значит, что GPT-5.2 потерял смысл. GPT-5.2 вышла 11 декабря 2025 года, она до сих пор дешевле по input и cached input, а в некоторых ChatGPT Enterprise help-center страницах модель все еще фигурирует в лимитах, RBAC и legacy-логике доступа. Поэтому у GPT-5.2 остается узкая, но реальная роль.
Главный вопрос этой статьи не в том, какой launch был красивее. Главный вопрос такой: какую модель стоит поставить по умолчанию сегодня, а какую оставить как исключение?
Краткое содержание
Если нужен один практический вывод, он такой: для новых API и Codex-задач выбирайте GPT-5.4, а GPT-5.2 оставляйте только там, где критичнее стоимость или старые продуктовые поверхности.
| Параметр | GPT-5.4 | GPT-5.2 | Практический вывод |
|---|---|---|---|
| Дата запуска | 5 марта 2026 | 11 декабря 2025 | GPT-5.4 новее и ближе к текущему default |
| Текущая роль | Флагман для reasoning и coding | Предыдущая frontier-модель | GPT-5.4 уже заняла центральную позицию |
| Input цена | $2.50 / 1M | $1.75 / 1M | GPT-5.2 дешевле по input |
| Cached input | $0.25 / 1M | $0.175 / 1M | Для повторяющегося контекста GPT-5.2 выгоднее |
| Output цена | $15 / 1M | $14 / 1M | Разница небольшая |
| Контекст | 1,050,000 | 400,000 | GPT-5.4 лучше для больших репозиториев и длинных сессий |
| Публичные API-лимиты | Те же видимые tiers | Те же видимые tiers | Это не история про RPM/TPM |
| Лучший сценарий | Новый default для mixed workflows | Более дешевая узкая ветка | Держите GPT-5.4 главным маршрутом |
Самая важная мысль здесь простая: GPT-5.4 должен заменить GPT-5.2 как default, но GPT-5.2 не обязательно удалять из стека полностью.
Что реально изменилось между GPT-5.2 и GPT-5.4

Главное изменение связано не с одним конкретным benchmark, а с тем, как OpenAI теперь позиционирует продукт.
GPT-5.2 при запуске была моделью frontier-класса для профессиональной работы, длинного контекста и многошаговых агентных задач. Для многих команд она стала очевидным default-выбором: достаточно сильная в коде, документах, анализе и tool calling.
GPT-5.4 это положение изменила. OpenAI прямо пишет, что GPT-5.4 заменяет предыдущую frontier-модель GPT-5.2 в API и служит drop-in replacement для большинства интеграций. Это очень важный сигнал: компания не просто выпустила еще одну модель выше по баллам, а сдвинула саму точку старта для новых рабочих сценариев.
Кроме того, GPT-5.4 в официальном launch-посте подается как объединение reasoning, coding и agentic workflows в одной основной модели. Там же подчеркивается native computer use и контекст до 1M tokens. Это уже не просто "GPT-5.2, но немного лучше". Это более широкий рабочий default.
Поэтому правильная рамка для этого сравнения такая:
- старая frontier-модель по умолчанию против новой frontier-модели по умолчанию
- более дешевая и зрелая ветка против более широкой и сильной главной ветки
- cost-sensitive маршрут против default-маршрута для сложной работы
Именно в этой рамке ключевое решение становится понятным.
Какие бенчмарки и различия действительно важны
На официальной странице GPT-5.4 OpenAI напрямую сравнивает GPT-5.4 с GPT-5.2:
| Метрика | GPT-5.4 | GPT-5.2 | Что это значит на практике |
|---|---|---|---|
| GDPval | 83.0% | 70.9% | Лучше справляется с реальной профессиональной работой |
| SWE-Bench Pro | 57.7% | 55.6% | Чуть сильнее на сложных инженерных задачах |
| OSWorld-Verified | 75.0% | 47.3% | Намного сильнее в computer-use и GUI-задачах |
| Toolathlon | 54.6% | 46.3% | Лучше ведет себя в multi-tool workflows |
| BrowseComp | 82.7% | 65.8% | Лучше там, где важны поиск и синтез источников |
Самое важное здесь не то, что GPT-5.4 выше почти везде. Важно где именно она выше.
Рост по GDPval означает, что GPT-5.4 лучше не только как "кодогенератор", но и как рабочая модель для задач вокруг кода: анализ документов, подготовка deliverables, длинные reasoning-цепочки и смешанные профессиональные сценарии. Рост по OSWorld и Toolathlon еще важнее для современных агентных workflows, где модель должна не только отвечать, но и реально пользоваться инструментами.
OpenAI также пишет, что у GPT-5.4 individual factual claims на 33% реже оказываются ложными, а полные ответы на 18% реже содержат ошибки по сравнению с GPT-5.2. Для команд, которые используют модель не только для кода, но и для технического анализа, это существенный аргумент.
Итог здесь прямой:
- GPT-5.4 сильнее как общая рабочая модель
- особенно заметно это в tool-heavy и long-horizon задачах
- GPT-5.2 остается достойной, но уже не определяет frontier default
Если вам нужен соседний ориентир внутри OpenAI coding-линейки, можно затем посмотреть наш материал GPT-5.4 vs GPT-5.3-Codex.
Цена, контекст и публичные API-лимиты

Именно здесь GPT-5.2 сохраняет главный аргумент в свою пользу.
| Параметр | GPT-5.4 | GPT-5.2 | Как это читать |
|---|---|---|---|
| Input | $2.50 / 1M | $1.75 / 1M | GPT-5.2 лучше для prompt-heavy cost-sensitive задач |
| Cached input | $0.25 / 1M | $0.175 / 1M | При повторяющемся контексте GPT-5.2 выгоднее |
| Output | $15 / 1M | $14 / 1M | Разница не критическая |
| Context window | 1,050,000 | 400,000 | GPT-5.4 дает гораздо больший запас |
| Max output | 128,000 | 128,000 | Существенной разницы нет |
| Long-context caveat | >272K input = 2x input и 1.5x output за всю сессию | Нет такого публичного коэффициента | Большой контекст GPT-5.4 полезен, но дорог |
На стороне цены история довольно трезвая. GPT-5.4 действительно дороже, но главная разница находится в input и cached input. Если ваш продовый поток постоянно отправляет большие prompts, большие куски репозитория и повторяющиеся блоки контекста, GPT-5.2 остается разумной экономичной веткой.
Зато разрыв по контексту очень большой: 1.05M против 400K. Для анализа большого codebase, больших документов и длинных agent-сессий это уже не косметическая разница. Она реально меняет то, что можно держать в одной рабочей сессии.
Но здесь важно не обмануть себя headline-цифрой. На модельной странице GPT-5.4 OpenAI прямо предупреждает: если prompt превышает 272K input tokens, вся сессия тарифицируется по повышенному коэффициенту. Значит, большой контекст стоит использовать осознанно, а не как бесплатный бонус.
Еще одна полезная деталь: опубликованные tier-таблицы API rate limits у GPT-5.4 и GPT-5.2 сейчас совпадают по видимым значениям. То есть это не спор о том, какая модель дает больше RPM или TPM. Это спор о default-качестве, инструментах, контексте и цене.
API и Codex против реальности ChatGPT и Enterprise
Именно здесь появляется большая часть путаницы вокруг этого ключевого слова.
Если говорить про API и Codex, картина простая:
- GPT-5.4 уже стала новым default
- OpenAI прямо говорит, что она заменила GPT-5.2 в API
- для новых сложных workflows разумно начинать именно с GPT-5.4
Но если говорить про ChatGPT и Enterprise, картина сложнее. В help-center документации GPT-5.2 все еще встречается в shared buckets, legacy access и RBAC-логике. Из-за этого пользователи нередко делают ложный вывод, что GPT-5.2 якобы по-прежнему равноправный основной выбор.
На самом деле это просто разные поверхности:
- одна поверхность описывает технический default для API
- другая описывает реальный model picker, лимиты и admin-настройки в Enterprise
Обе правды могут существовать одновременно. И если статья это не разделяет, она почти наверняка запутает читателя.
Практическое правило такое:
- для routing-решений в API и Codex ориентируйтесь на текущие model docs и latest-model guide
- для объяснения того, почему пользователь все еще видит GPT-5.2 в ChatGPT Enterprise, ориентируйтесь на help-center и admin reality
Когда GPT-5.4 явно лучше
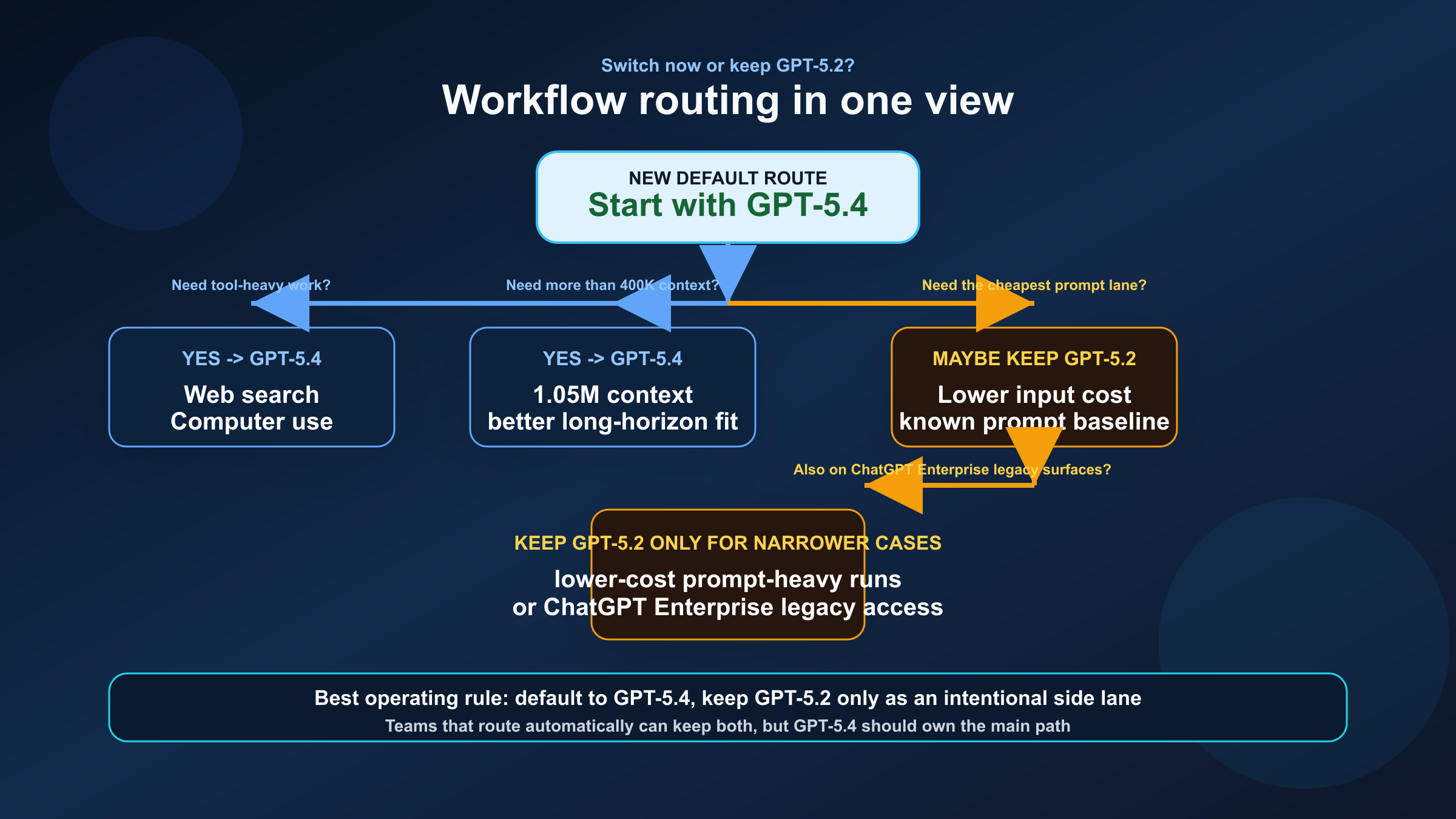
GPT-5.4 стоит выбирать по умолчанию, если работа выходит за пределы дешевого prompt processing.
Типичные случаи, где GPT-5.4 уже явно лучше:
- большие репозитории и длинный контекст
- multi-tool workflows
- browser, screenshots, computer use
- смешанная работа "код + анализ + документы + решение"
- желание держать одну сильную default-модель вместо нескольких частичных
Именно здесь GPT-5.4 выигрывает не только качеством, но и снижением сложности маршрутизации. У многих команд настоящая цена модели скрыта не в токенах, а в количестве специальных правил, исключений и ручных переключений. GPT-5.4 хороша именно тем, что может закрыть больше типов задач одной основной веткой.
Это особенно заметно в командах, где одна и та же сессия должна сначала прочитать длинную документацию, потом пройтись по репозиторию, затем вызвать инструменты, перепроверить факты и только после этого подготовить патч или вывод для человека. В таких смешанных цепочках GPT-5.4 удобнее не потому, что "чуть лучше пишет", а потому, что реже разваливает весь многошаговый процесс на стыках между поиском, reasoning и execution.
Еще один практический плюс в том, что GPT-5.4 лучше подходит для унификации внутренних рекомендаций. Если у вас несколько продуктовых команд, документация для выбора модели становится проще: одна основная модель для сложной работы, и только один-два понятных carve-out случая для более дешевого маршрута. Это обычно ценнее, чем кажется в сравнительных таблицах.
Когда GPT-5.2 все еще имеет смысл
Смысл GPT-5.2 сейчас уже не в том, чтобы оставаться "основной" моделью. Ее роль теперь скорее тактическая.
GPT-5.2 стоит оставлять, если:
- input cost важнее frontier-качества
- ваш текущий прод уже хорошо настроен под GPT-5.2
- задачи помещаются в 400K context и не требуют широкого tool posture
- вы сталкиваетесь именно с legacy surface realities в ChatGPT Enterprise
- вам нужна дешевая fallback-ветка рядом с GPT-5.4-first маршрутом
То есть GPT-5.2 сейчас имеет смысл по намерению, а не по инерции. Ее надо держать потому, что у нее есть конкретная работа, а не потому, что она когда-то была лучшим default.
На практике это хорошо работает как отдельный cost-lane. Команда может сознательно отправлять в GPT-5.2 предсказуемые задачи с большим объемом повторяющегося input, где не нужен агентный цикл, большие tool chains или длинная склейка контекста. Тогда GPT-5.4 перестает быть "моделью для всего подряд" и становится действительно главной линией для более дорогой и более сложной работы, где ее преимущества окупаются.
Чек-лист миграции с GPT-5.2 на GPT-5.4
Если команда до сих пор использует GPT-5.2 как default, разумнее всего мигрировать поэтапно.
- Сделайте GPT-5.4 основным маршрутом для новых API и Codex-задач.
- Оставьте GPT-5.2 для более дешевых prompt-heavy сценариев и legacy-кейсов.
- Перетестируйте не только coding benchmark, но и три реальные категории задач: long-context, multi-tool и cost-sensitive.
- Добавьте cost-monitoring для сессий GPT-5.4 с input выше 272K.
- Если пользователи работают через ChatGPT Enterprise, отдельно задокументируйте разницу между API default и model-picker reality.
Такая миграция дает вам преимущества новой модели без ненужного "all-in" риска.
Важно и то, что миграцию лучше оценивать не только по средней цене за запрос. Если после перехода на GPT-5.4 команда реже перезапускает длинные задачи, реже дробит контекст между несколькими вызовами и реже вручную добивает шаги, то итоговая стоимость workflow может выглядеть лучше, чем голое сравнение "$2.50 против $1.75". Для инженерной команды это обычно и есть правильный уровень оценки.
Хорошая практическая схема выглядит так: сначала перевести на GPT-5.4 те задачи, где ошибка дорого стоит по времени, затем оставить GPT-5.2 для понятных, повторяемых и дешевых маршрутов, а уже потом пересобирать routing-политику целиком. Такой порядок снижает риск, потому что вы сначала улучшаете качество на самых чувствительных участках, а не пытаетесь одним днем переписать всю экономику модели.
FAQ
Можно ли считать GPT-5.4 полной заменой GPT-5.2?
Для большинства новых API и Codex-задач да. OpenAI уже позиционирует GPT-5.4 как замену GPT-5.2 в API. Но это не значит, что GPT-5.2 исчезла из всех поверхностей или перестала быть полезной для cost-sensitive маршрутов.
GPT-5.4 дороже. Это реально оправдано?
Обычно да, если вы действительно используете ее более широкий tool posture, больший context window и лучшую агентную устойчивость. Если же у вас в основном дешевые повторяющиеся prompts, GPT-5.2 может остаться экономически более разумной.
Есть ли заметная разница по API rate limits?
Судя по текущим опубликованным model pages, нет. Видимые tier-таблицы совпадают, поэтому ключевое различие не в throughput, а в качестве default-маршрута.
Почему в ChatGPT Enterprise люди все еще видят GPT-5.2?
Потому что Enterprise help-center описывает shared limits, RBAC и legacy access, а не только frontier-рекомендации для API. Это объясняет присутствие GPT-5.2 на отдельных поверхностях, но не отменяет того факта, что GPT-5.4 уже стала главным default.
Когда GPT-5.2 стоит оставить?
Когда вам важнее input cost, когда ваш tuned production flow уже стабилен на GPT-5.2, или когда вы обязаны учитывать Enterprise legacy surface reality. Во всех остальных случаях основной маршрут лучше смещать на GPT-5.4.