
Короткий ответ: для большинства разработчиков GPT-5.4 теперь лучше в роли основной модели. OpenAI выпустила GPT-5.4 5 марта 2026 года и прямо описывает ее как первую основную модель рассуждения, которая вобрала в себя передовые возможности GPT-5.3-Codex для программирования. На практике это означает, что GPT-5.4 удобнее как единый дефолт для кодинга, длинного контекста, работы с инструментами, поиска и многошаговых агентных задач.
Это не делает GPT-5.3-Codex бессмысленной. GPT-5.3-Codex, представленная 5 февраля 2026 года, все еще сохраняет два важных преимущества: она дешевле по входным токенам и по-прежнему опережает GPT-5.4 на Terminal-Bench 2.0. Если ваши задачи почти целиком живут в CLI, shell-скриптах, CI или быстрых локальных исправлениях, GPT-5.3-Codex остается разумной специализированной линией.
Этот разбор основан на официальных страницах запуска OpenAI, текущих страницах моделей API и текущей странице цен, проверенных 19 марта 2026 года. Он также отделяет долговременные факты о продукте от шума вокруг временных сбоев в Codex, чтобы не путать проблемы поверхности доступа с выбором модели.
Краткое содержание
Если нужна одна рекомендация, сделайте GPT-5.4 моделью по умолчанию, а GPT-5.3-Codex оставьте для терминал-ориентированных и более дешевых запусков с тяжелыми промптами.
| Категория | GPT-5.4 | GPT-5.3-Codex | Практический вывод |
|---|---|---|---|
| Дата релиза | 5 марта 2026 | 5 февраля 2026 | GPT-5.4 новее и занимает основную позицию |
| Роль продукта | Основная reasoning-модель для кодинга и агентной работы | Специализированная coding-модель | GPT-5.4 шире, Codex уже |
| Цена input | $2.50 / 1M | $1.75 / 1M | GPT-5.3-Codex заметно дешевле по входу |
| Цена output | $15 / 1M | $14 / 1M | Разница по output небольшая |
| Cached input | $0.25 / 1M | $0.175 / 1M | При повторяющемся контексте Codex дешевле |
| Контекстное окно | 1,050,000 | 400,000 | GPT-5.4 лучше для repo-scale задач |
| Max output | 128,000 | 128,000 | Ничья |
| Инструменты | Поиск, hosted shell, apply patch, MCP, computer use и другое | Позиционирование вокруг coding-задач | GPT-5.4 лучше как универсальный маршрут |
| Сильнейший бенчмарк | GDPval, SWE-Bench Pro, OSWorld, Toolathlon, BrowseComp | Terminal-Bench 2.0 | GPT-5.4 выигрывает в целом, Codex сохраняет узкое преимущество |
| Кому подходит | Команда по умолчанию, длинный контекст, mixed workflows | CLI-heavy, более дешевые и узкие coding-задачи | Часто лучший ответ: держать обе |
Ключевой нюанс в том, что GPT-5.4 не сводится к формуле «GPT-5.3-Codex, только новее». Это более сильный общий default. Но и GPT-5.3-Codex не устарела полностью, потому что реальная инженерная работа по-прежнему зависит от формы workflow, а не только от общего лидерства по таблице.
Что реально изменилось между GPT-5.4 и GPT-5.3-Codex

Главное изменение касается позиционирования продукта. На странице запуска GPT-5.4 от OpenAI прямо сказано, что GPT-5.4 вобрала в себя frontier coding capabilities GPT-5.3-Codex. Это важнее, чем просто фраза из пресс-релиза: OpenAI показывает, что теперь рекомендует GPT-5.4 как основную модель для сложной reasoning-работы, программирования и агентных задач, а не как отдельную reasoning-линейку рядом с «настоящим» Codex.
GPT-5.3-Codex, напротив, была запущена как coding-first модель. На странице запуска GPT-5.3-Codex акцент сделан на скорости, agentic coding и реальных инженерных workflow. Это объясняет, почему после выхода GPT-5.4 часть разработчиков все равно не хочет полностью отказываться от Codex: у нее все еще более узкий, но очень узнаваемый профиль.
Текущая страница обзора моделей OpenAI API тоже усиливает этот сигнал. Сегодня OpenAI подталкивает разработчиков начинать с GPT-5.4 для сложного reasoning, coding и agentic work, а GPT-5.3-Codex оставляет как специализированную coding-модель. Это уже не стартовый маркетинг, а актуальная продуктовая логика.
На странице запуска GPT-5.4 от 5 марта 2026 года есть и еще одна важная деталь, которую SERP обычно размывает. GPT-5.4 Thinking в тот день начала выкатываться для ChatGPT Plus, Team и Pro, GPT-5.4 Pro пошла в Pro и Enterprise, а GPT-5.4 в Codex получила экспериментальную поддержку 1M контекста. Там же OpenAI отдельно пишет, что запросы в Codex выше стандартного окна 272K считаются по 2x нормальной rate. Это хорошо объясняет, почему рекомендация уже сместилась в сторону GPT-5.4, а surface-level опыт пользователей все еще может отличаться.
Правильный вывод звучит так: GPT-5.4 заменила GPT-5.3-Codex как рекомендацию по умолчанию, но не как ответ на каждый workflow. Если ваши задачи смешивают код, поиск, патчи, длинный контекст и принятие решений, GPT-5.4 почти всегда лучше. Если работа уже и ближе к терминалу, Codex все еще может выиграть как специализированный маршрут.
Одна из причин путаницы в SERP в том, что люди постоянно смешивают три разных поверхности: модельный каталог API, поведение Codex, и доступность в других интерфейсах OpenAI. Они связаны, но не обязаны обновляться одинаково быстро и не обязаны ломаться в одно и то же время. Поэтому для устойчивых выводов нужно опираться на официальные страницы моделей и запусков, а не на отдельные треды о сбоях.
Если вам нужен еще один ориентир по coding-моделям OpenAI, полезно посмотреть наш разбор GPT-5.3 Codex против Claude Opus 4.6, где хорошо видно, насколько сильная репутация Codex строилась именно на coding-специализации.
Какие бенчмарки действительно важны для реальной разработки
Большинство сравнений теряет читателя в тот момент, когда превращается в длинный список чисел без связи с реальной работой. Гораздо полезнее перевести бенчмарки в последствия для workflow.
| Бенчмарк | GPT-5.4 | GPT-5.3-Codex | Что это значит на практике |
|---|---|---|---|
| GDPval | 83.0% | 70.9% | GPT-5.4 надежнее в неоднозначных и смешанных задачах |
| SWE-Bench Pro | 57.7% | 56.8% | GPT-5.4 немного сильнее на тяжелых software engineering кейсах |
| OSWorld-Verified | 75.0% | 74.0% | GPT-5.4 чуть лучше в системных и computer-operation задачах |
| Toolathlon | 54.6% | 51.9% | GPT-5.4 лучше справляется с tool-driven workflow |
| BrowseComp | 82.7% | 77.3% | GPT-5.4 сильнее там, где важны поиск и сбор доказательств |
| Terminal-Bench 2.0 | 75.1% | 77.3% | GPT-5.3-Codex все еще лучше в CLI-heavy работе |
Главный вывод здесь не в том, что GPT-5.4 «разгромила» Codex. Важно другое: GPT-5.4 выигрывает большую часть доски, но GPT-5.3-Codex все еще удерживает самый понятный terminal-specific edge. Это не абстракция, а то, что реально чувствуют инженеры, чья работа состоит из shell-команд, файловых операций, CI-скриптов и быстрой диагностики.
Для всех остальных картина склоняется к GPT-5.4. Рост по GDPval особенно важен, потому что он говорит о лучшей устойчивости к смешанным задачам, где программирование переплетается с reasoning. Небольшое преимущество в SWE-Bench Pro само по себе не решает исход сравнения, но вместе с Toolathlon, BrowseComp и OSWorld усиливает тезис, что GPT-5.4 лучше как единый рабочий default.
Практический перевод получается простой:
- Если ваша работа в основном означает «изменить код, выполнить shell-команды и быстро закрыть задачу», GPT-5.3-Codex все еще заслуживает место.
- Если работа выглядит как «понять крупный кодовый массив, использовать несколько инструментов, разобраться в компромиссах и выдать надежный результат», GPT-5.4 лучше в роли главного маршрута.
Именно поэтому обсуждение в сообществе выглядит расколотым, а не закрытым. Разработчики с разным набором задач видят разных победителей, потому что модели перекрываются, но не идентичны.
Цена, контекстное окно и покрытие инструментов

После бенчмарков реальное решение упирается в три вещи: стоимость input, длину контекста и ширину tool surface.
| Параметр | GPT-5.4 | GPT-5.3-Codex | Почему это важно |
|---|---|---|---|
| Input | $2.50 / 1M | $1.75 / 1M | Codex заметно выгоднее в prompt-heavy workflow |
| Cached input | $0.25 / 1M | $0.175 / 1M | Повторяющийся контекст дешевле на Codex |
| Output | $15 / 1M | $14 / 1M | По output разница слишком мала, чтобы решать выбор |
| Context window | 1,050,000 | 400,000 | GPT-5.4 лучше подходит для repo-scale и long-session работы |
| Max output | 128,000 | 128,000 | Ничья |
| Длинный контекст | Выше 272K input действует 2x input и 1.5x output на всю сессию | Похожий multiplier не опубликован | Большой контекст GPT-5.4 реален, но не бесплатен |
| Tools | Web search, file search, image generation, code interpreter, hosted shell, apply patch, skills, MCP, computer use, tool search | Coding-centric позиционирование | GPT-5.4 легче оправдать как одну модель по умолчанию |
Ценовая история сложнее, чем «GPT-5.4 слишком дорогая». Самая заметная разница находится во входных токенах, а не в output. Поэтому GPT-5.3-Codex особенно привлекательна там, где вы много раз отправляете большие prompt с кодом, контекстом репозитория или повторяющимися инструкциями, но не обязательно нуждаетесь в широкой инструментальной среде GPT-5.4.
История про контекст тоже легко превращается в неправильный вывод. Да, 1.05M токенов против 400K меняют то, что влезает в одну сессию. Для архитектурного обзора, большого репозитория, трассировки через несколько модулей и длинной агентной работы это очень ощутимая разница. Но текущая страница модели GPT-5.4 прямо предупреждает: при prompt выше 272K input tokens вся сессия становится дороже. Поэтому большой контекст — это потолок и запас по удобству, а не приглашение бездумно отправлять все самое тяжелое в GPT-5.4.
Ширина tool surface меняет решение еще сильнее. GPT-5.4 поддерживает web search, hosted shell, apply patch, MCP, computer use и другие инструменты, которые все чаще оказываются частью «обычной разработки». Именно это делает GPT-5.4 сильнее как default model. GPT-5.3-Codex выглядит скорее как specialist lane: отличная там, где форма задачи совпадает с ее профилем, но уже не столь убедительная как единственный маршрут для всей команды.
Если вы еще настраиваете более широкую логику затрат и маршрутизации, наш материал про OpenAI API key и альтернативы помогает посмотреть на выбор модели как на вопрос архитектуры расходов, а не только качества ответов.
Какую модель выбирать для разных рабочих процессов
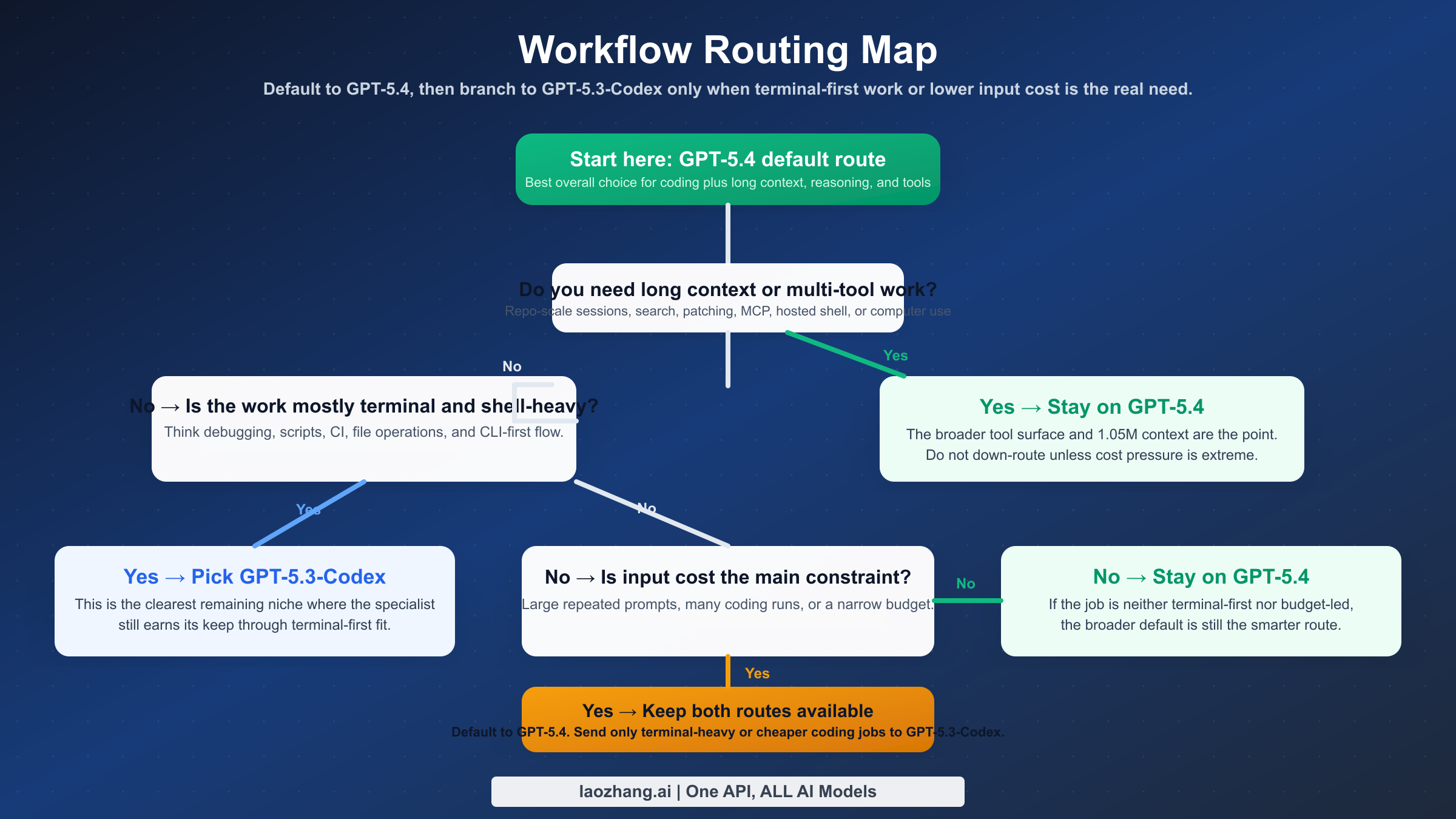
Это та часть, которую большинство страниц в выдаче объясняет хуже всего, хотя именно ради нее люди и вводят этот запрос.
| Workflow | Выбирать GPT-5.4 | Выбирать GPT-5.3-Codex | Почему |
|---|---|---|---|
| Основная модель в Codex или API для команды | Да | Нет | GPT-5.4 стала более надежным единым default |
| CLI-heavy инженерная работа | Иногда | Да | Terminal-Bench 2.0 все еще на стороне Codex |
| Длинный анализ репозитория | Да | Редко | 1.05M контекст реально помогает |
| Multi-tool агентные workflow | Да | Редко | GPT-5.4 предлагает более широкую tool surface |
| Бюджетно-чувствительный coding с тяжелыми prompt | Иногда | Да | Более низкая цена input все еще важна |
| Смешанная профессиональная работа за пределами кода | Да | Нет | GPT-5.4 лучше как одна модель на все |
Для обычного разработчика или небольшой команды безопаснее всего сделать GPT-5.4 моделью по умолчанию. Она уменьшает число ситуаций, когда приходится заранее угадывать, понадобится ли вам поиск, патчинг, большой контекст или инструменты за пределами «просто написать код».
Для platform, DevOps или infra-инженера ответ уже не такой однозначный. Если задачи регулярно сводятся к shell, CI, logs, scripts и CLI-debugging, GPT-5.3-Codex по-прежнему может ощущаться лучше на доллар и иногда даже лучше по форме ответа.
Для staff engineers, tech leads и архитектурных ролей GPT-5.4 почти всегда легче защитить. Их работа редко сводится к узкому terminal-first режиму. Обычно она включает синтез, анализ компромиссов, длинный контекст и многошаговые задачи с инструментами.
Если у вас уже есть автоматическая маршрутизация, лучший ответ часто не «или-или», а обе модели сразу: GPT-5.4 как default route, GPT-5.3-Codex как deliberate exception для terminal-heavy и cost-sensitive веток.
Когда GPT-5.3-Codex по-прежнему имеет смысл
Часть материалов в выдаче упрощает картину до фразы «GPT-5.4 полностью заменила GPT-5.3-Codex». На уровне общего позиционирования это близко к правде. На уровне реальной инженерной эксплуатации — уже нет.
GPT-5.3-Codex все еще имеет смысл в четырех случаях. Первый — terminal-first работа. Если задача ближе к shell-командам и файловым операциям, чем к широкому agentic workflow, у Codex все еще есть официальный benchmark-based аргумент. Второй — контроль входной стоимости. Разница между $2.50 и $1.75 за миллион input токенов становится ощутимой, когда тяжелые prompt идут весь день. Третий — узкие coding workflow, где вам не нужны computer use, search или другие расширенные инструменты GPT-5.4. Четвертый — fallback routing, где наличие второй сильной coding-модели повышает устойчивость системы.
Именно здесь полезно правильно читать community signals. Треды марта 2026 года о проблемах доступа к GPT-5.4 и GPT-5.3-Codex в Codex важны как сигнал трения, но они не отменяют продуктовую картину из официальных документов. Они показывают, что surface behavior может быть шумным. Они не доказывают, что GPT-5.3-Codex «убирают» или что GPT-5.4 перестала быть правильным default.
Лучшее операционное правило сейчас звучит так: считать GPT-5.4 главным маршрутом, а GPT-5.3-Codex — тактическим исключением.
Чек-лист миграции с GPT-5.3-Codex на GPT-5.4
Если у вашей команды GPT-5.3-Codex уже стоит по умолчанию, переход лучше делать не идеологически, а пошагово.
- Переключите default route на GPT-5.4 для общего coding, long-context задач и multi-tool workflow.
- Оставьте GPT-5.3-Codex для terminal-heavy debugging, shell automation и более дешевых input-heavy запусков.
- Добавьте контроль затрат на длинные prompt, особенно для сессий GPT-5.4 выше 272K input tokens.
- Переоцените три ключевых сценария отдельно: один repo-scale анализ, один terminal workflow и одну multi-tool задачу.
- Зафиксируйте fallback rule на случай временных регрессий в поверхностях доступа, чтобы не путать проблемы сервиса с проблемой выбора модели.
Такой подход сильнее, чем жесткое «перенести все сразу». Он отражает реальную специализацию моделей, а не только рекламную логику релиза.
FAQ
GPT-5.4 строго лучше GPT-5.3-Codex?
Нет. GPT-5.4 лучше в целом и должна быть моделью по умолчанию для большинства команд, но GPT-5.3-Codex все еще выигрывает по Terminal-Bench 2.0 и дешевле по входным токенам. Для terminal-centric или budget-sensitive coding-задач она сохраняет смысл.
Стоит ли переплата за GPT-5.4 своих денег?
Обычно да, если вы действительно используете более широкий tool surface и длинный контекст. Если работа сводится к коротким coding-сеансам и CLI, дополнительная стоимость выглядит менее убедительно. Если же работа регулярно превращается в длинный разбор, поиск, патчинг и смешанные шаги, переплата обычно оправдана.
Заменяет ли GPT-5.4 GPT-5.3-Codex в Codex и API?
На уровне позиционирования OpenAI — да, GPT-5.4 уже заняла место основной frontier-модели для coding и agentic work. На уровне реального workflow — не полностью. GPT-5.3-Codex остается узкой, но легитимной специализированной линией.
Нужно ли учитывать мартовские проблемы доступа при выборе?
Да, но не нужно переоценивать их значение. Такие треды полезны как operational context, а не как доказательство долгосрочной смены политики. Для главного решения опирайтесь на официальные страницы моделей и цен, а сообщения о сбоях используйте лишь как аргумент в пользу нормального fallback routing.