
OpenAI、Anthropic 和 Google 在 2025 年下半年相继发布了各自的最新旗舰模型,标志着大语言模型竞争进入了全新阶段。GPT-5.2 在推理能力上取得突破性进展,ARC-AGI-2 得分达到 52.9%,AIME 2025 数学竞赛更是拿下满分;Claude Opus 4.5 在编程领域独占鳌头,SWE-bench Verified 得分高达 80.9%;Gemini 3 Pro 则凭借 1M tokens 的超长上下文和 87.6% 的 Video-MMMU 得分,成为多模态处理的首选。本文将从基准测试数据、核心能力分析、价格成本对比和场景选型四个维度,帮助你在这三大模型中做出最优选择。
三大旗舰模型概述:2025年AI竞争格局
2025 年 11 月至 12 月,AI 行业迎来了历史性的"三大模型同期发布"现象。在短短六周内,Google、Anthropic 和 OpenAI 相继推出了各自的最新旗舰产品,竞争激烈程度前所未有。
发布时间线:
| 模型 | 发布日期 | 开发商 | 核心定位 |
|---|---|---|---|
| Gemini 3 Pro | 2025-11-18 | 多模态与长上下文专家 | |
| Claude Opus 4.5 | 2025-11-24 | Anthropic | 编程与 Agent 能力最强 |
| GPT-5.2 | 2025-12-11 | OpenAI | 推理与数学能力巅峰 |
根据 OpenAI 官方公告(https://openai.com/index/introducing-gpt-5/ ),GPT-5.2 是 GPT-5 系列的最新迭代版本,在原有基础上进一步强化了推理能力。Anthropic 在其技术博客(https://www.anthropic.com/news/claude-opus-4-5 )中表示,Claude Opus 4.5 专门针对开发者需求优化,Agent 和工具调用能力大幅提升。Google 的 Gemini 3 Pro 则延续了在多模态领域的优势,同时将上下文窗口扩展到了惊人的 1M tokens。
这三款模型的定位各有侧重:GPT-5.2 瞄准需要复杂推理的科研和分析场景;Claude Opus 4.5 面向专业开发者和 AI Agent 构建者;Gemini 3 Pro 则服务于需要处理长文档、视频等多模态内容的用户。没有哪个模型在所有方面都是最好的,选择取决于你的具体使用场景。
基准测试深度对比:八项核心能力评测
基准测试是衡量 AI 模型能力的客观标准。以下是三大模型在八个主流测试中的表现对比:
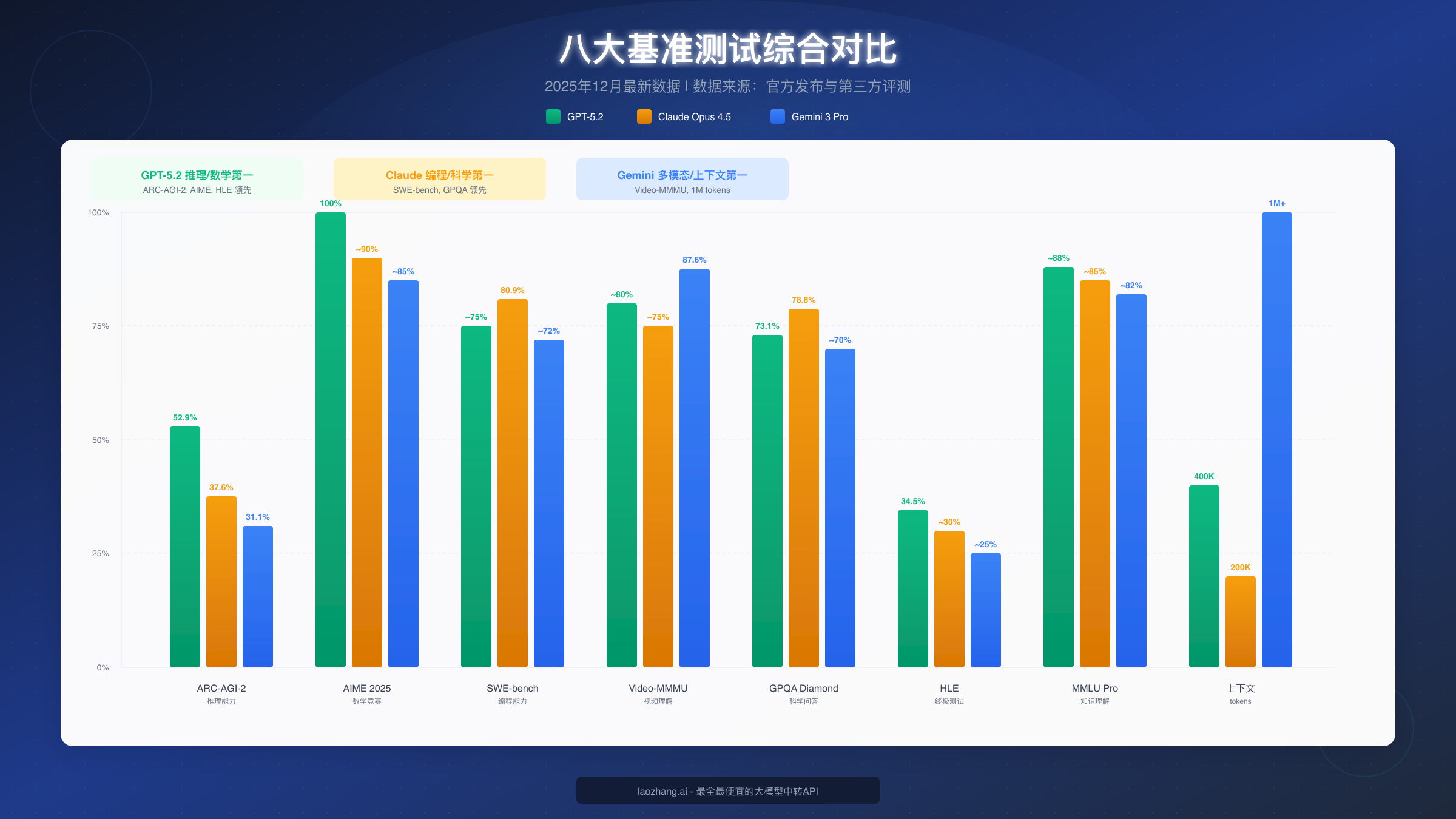
综合基准测试数据:
| 测试项目 | GPT-5.2 | Claude Opus 4.5 | Gemini 3 Pro | 测试说明 |
|---|---|---|---|---|
| ARC-AGI-2 | 52.9% | 37.6% | 31.1% | 抽象推理能力 |
| AIME 2025 | 100% | ~90% | ~85% | 数学竞赛 |
| SWE-bench Verified | ~75% | 80.9% | ~72% | 软件工程能力 |
| Video-MMMU | ~80% | ~75% | 87.6% | 视频理解 |
| GPQA Diamond | 73.1% | 78.8% | ~70% | 科学问答 |
| Humanity's Last Exam | 34.5% | ~30% | ~25% | 综合极限测试 |
| MMLU Pro | ~88% | ~85% | ~82% | 知识理解 |
| 上下文窗口 | 400K | 200K | 1M+ | tokens |
ARC-AGI-2 推理测试解读
ARC-AGI-2 是衡量 AI 抽象推理能力的黄金标准。GPT-5.2 以 52.9% 的得分大幅领先,这意味着它在处理需要类比、推理和逻辑分析的任务时表现最佳。对于需要解决复杂问题、进行科学研究或做数据分析的用户来说,这个指标尤为重要。
SWE-bench 编程能力解读
SWE-bench Verified 测试模型解决真实 GitHub issue 的能力。Claude Opus 4.5 以 80.9% 的得分遥遥领先,这个成绩意味着它能够独立完成超过 80% 的真实软件开发任务。如果你是开发者,需要一个编程助手来帮助代码生成、调试和重构,Claude 是最佳选择。关于 Claude 模型的详细能力对比,可以参考Claude Opus 4.5 与 Sonnet 4 的详细对比。
上下文窗口实际意义
Gemini 3 Pro 的 1M tokens 上下文窗口是什么概念?这相当于约 75 万个中文字符,足以一次性处理一本完整的小说、数十篇学术论文或几小时的视频转录文本。对于需要分析长文档、做大规模文献综述的研究人员来说,这是不可替代的优势。
核心能力解析:推理、编程与多模态
了解了基准测试数据后,让我们深入分析三大模型在关键能力维度上的具体表现。
推理能力:GPT-5.2 独占鳌头
GPT-5.2 在推理能力上的突破令人印象深刻。除了 ARC-AGI-2 的领先成绩,它在 AIME 2025 数学竞赛中取得了 100% 的满分成绩,这在 AI 历史上尚属首次。这种推理能力体现在实际使用中的优势包括:能够处理多步骤的复杂问题分解、在数学证明和逻辑推导中表现出色、对因果关系的理解更加准确。
对于从事科研工作、需要进行复杂数据分析或解决数学问题的用户,GPT-5.2 是首选。它能够理解问题的深层结构,提供更有条理的推理过程,而不仅仅是给出答案。
编程能力:Claude Opus 4.5 专业级表现
Claude Opus 4.5 在编程领域的优势不仅体现在 SWE-bench 得分上,更体现在实际开发场景中。Anthropic 专门针对开发者需求进行了优化,使其在以下方面表现突出:代码生成准确率高,支持 Python、JavaScript、Rust、Go 等主流语言;Debug 能力强,能够准确定位问题并给出修复建议;Agent 和工具调用能力业界最强,适合构建自动化工作流。
此外,Claude Opus 4.5 的成本相比前代降低了约 67%,这使得它在企业级应用中更具性价比。对于需要大量使用 AI 辅助编程的开发团队来说,Claude 提供了最佳的能力与成本平衡。
多模态能力:Gemini 3 Pro 全面领先
Gemini 3 Pro 在多模态处理方面的优势是全方位的。Video-MMMU 87.6% 的得分表明它在视频内容理解方面远超竞争对手,而 1M tokens 的上下文窗口则使其能够处理其他模型无法胜任的长内容任务。具体应用场景包括:分析长视频内容并提取关键信息、处理大型代码库或文档库、进行跨多个文档的综合分析、Google 生态产品的深度整合。
对于内容创作者、研究人员或需要处理大量多媒体内容的用户,Gemini 3 Pro 提供了独特的价值。
价格与成本分析:API定价与月度预算
价格是选择 AI 模型时的重要考量因素。以下是三大模型的官方 API 定价对比:
API 定价对比(每百万 tokens):
| 模型 | 输入价格 | 输出价格 | 备注 |
|---|---|---|---|
| GPT-5.2 | $1.75-3 | $7-21 | 按版本和功能分层 |
| Claude Opus 4.5 | $5 | $25 | 统一定价 |
| Gemini 3 Pro | ~$2 | ~$12 | 相对最便宜 |
月度使用成本估算
为了帮助你做预算决策,我们按三种使用强度估算了月度成本:
轻度使用(每天 50 次对话):
- GPT-5.2:约 $15-30/月
- Claude Opus 4.5:约 $20-40/月
- Gemini 3 Pro:约 $10-20/月
中度使用(每天 200 次对话 + 代码生成):
- GPT-5.2:约 $50-100/月
- Claude Opus 4.5:约 $80-150/月
- Gemini 3 Pro:约 $40-80/月
重度使用(API 集成 + 大规模处理):
- GPT-5.2:约 $200-500/月
- Claude Opus 4.5:约 $300-600/月
- Gemini 3 Pro:约 $150-350/月
从纯成本角度看,Gemini 3 Pro 是最经济的选择,而 Claude Opus 4.5 最贵。但成本决策不能只看价格,还要考虑模型在你的使用场景中的效率。如果 Claude 能在编程任务中节省 50% 的调试时间,那么更高的价格可能是值得的。关于 ChatGPT API 的详细定价信息,可以参考ChatGPT API 定价详解。
对于需要同时使用多个模型的开发者,更稳妥的思路是先把任务分类和模型路由策略设计清楚,再分别基于官方定价和官方能力评估不同模型的投入产出比。
场景选型指南:什么场景用什么模型
基于以上分析,我们为不同用户角色和任务类型提供具体的选型建议:

开发者与程序员
首选 Claude Opus 4.5。无论是日常的代码生成、复杂项目的架构设计,还是 Debug 和代码审查,Claude 都能提供最专业的支持。特别是在构建 AI Agent 和自动化工作流方面,Claude 的工具调用能力远超其他模型。
具体推荐:
- Python/JavaScript 开发:Claude Opus 4.5
- 复杂算法设计:GPT-5.2(推理能力更强)
- 大型项目代码分析:Gemini 3 Pro(上下文窗口大)
内容创作者与写作者
首选 GPT-5.2。在文案写作、创意脑暴和内容优化方面,GPT-5.2 的表现最为出色。它能够理解更细微的语言风格差异,生成更具创意和吸引力的内容。
具体推荐:
- 营销文案与社媒内容:GPT-5.2
- 逻辑性强的技术文章:Claude Opus 4.5
- 需要配图的内容创作:Gemini 3 Pro
研究员与学者
首选 Gemini 3 Pro。1M tokens 的上下文窗口使其能够一次性分析多篇论文,进行大规模文献综述。Video-MMMU 的领先成绩也意味着它能够有效分析讲座视频、会议录像等多媒体内容。
具体推荐:
- 文献综述与论文分析:Gemini 3 Pro
- 数学推导与证明:GPT-5.2
- 实验设计与方法论:Claude Opus 4.5
企业与团队用户
建议采用混合使用策略。根据任务类型灵活切换模型:代码开发用 Claude,分析报告用 GPT-5.2,文档处理用 Gemini。这样可以在各个维度都获得最佳效果。
订阅方案对比:Plus vs Pro vs Premium
除了 API 使用,许多用户也关心订阅方案的选择。以下是三家的订阅服务对比:
| 项目 | ChatGPT Plus | Claude Pro | Google One AI Premium |
|---|---|---|---|
| 月费 | $20 | $20 | $19.99 |
| 模型访问 | GPT-5.2 + GPT-4o | Claude Opus 4.5 + Sonnet | Gemini 3 Pro + Advanced |
| 消息限制 | 每 3 小时约 80 条 | 5 倍于免费版 | 无明确限制 |
| 附加权益 | DALL-E、GPTs | Artifacts、Projects | 2TB 存储、Gmail 集成 |
| 优先访问 | 高峰期优先 | 高峰期优先 | Google 服务集成 |
订阅方案选择建议:
选择 ChatGPT Plus 如果你:主要需要推理和分析能力,经常使用 DALL-E 生成图片,习惯 OpenAI 的生态系统。
选择 Claude Pro 如果你:主要工作是编程开发,需要使用 Artifacts 功能,频繁进行长对话和复杂项目。
选择 Google One AI Premium 如果你:深度使用 Google 生态产品(Gmail、Docs、Drive),需要处理大量文档和邮件,同时需要云存储空间。
值得注意的是,订阅方案虽然使用方便,但对于重度用户来说,API 调用通常更经济。如果你每天的使用量超过订阅限制,建议考虑 API 方案。
接入决策建议
对于这类三方模型横向对比文章,更适合保留的内容是:
- 哪个模型更适合你的任务类型
- 官方订阅和官方 API 的成本差异
- 在同一业务里如何做模型分层和预算控制
如果你需要正式接入,请以各家官方页面、官方账户设置和官方定价说明为准。对大多数团队来说,比“找替代入口”更重要的是先把任务分类、上下文长度、输出长度和缓存策略做好。
总结与快速推荐
经过全面的对比分析,我们可以得出以下结论:
模型选择决策树:
-
如果你主要做编程开发 → 选择 Claude Opus 4.5
- SWE-bench 80.9%,编程能力无出其右
- Agent 和工具调用能力最强
-
如果你需要复杂推理和数学分析 → 选择 GPT-5.2
- ARC-AGI-2 52.9%,推理能力第一
- AIME 2025 满分,数学能力巅峰
-
如果你处理长文档或多模态内容 → 选择 Gemini 3 Pro
- 1M tokens 上下文,处理超长内容
- Video-MMMU 87.6%,多模态理解最强
-
如果你是企业用户或需要混合使用 → 采用多模型策略
- 根据任务类型灵活切换
- 用自己的路由层和预算规则统一管理
一句话总结:
- 推理选 GPT-5.2:复杂问题分析、数学推导、逻辑推理
- 编程选 Claude:代码生成、Debug、Agent 开发
- 长文档选 Gemini:论文分析、视频理解、大规模处理
2025 年的 AI 模型竞争已经进入专业化分工阶段。没有一个模型在所有方面都是最好的,选择最适合你使用场景的模型,才能获得最佳的使用体验和效率。
希望这篇对比评测能够帮助你做出正确的选择。如果你有任何问题,欢迎在评论区讨论。