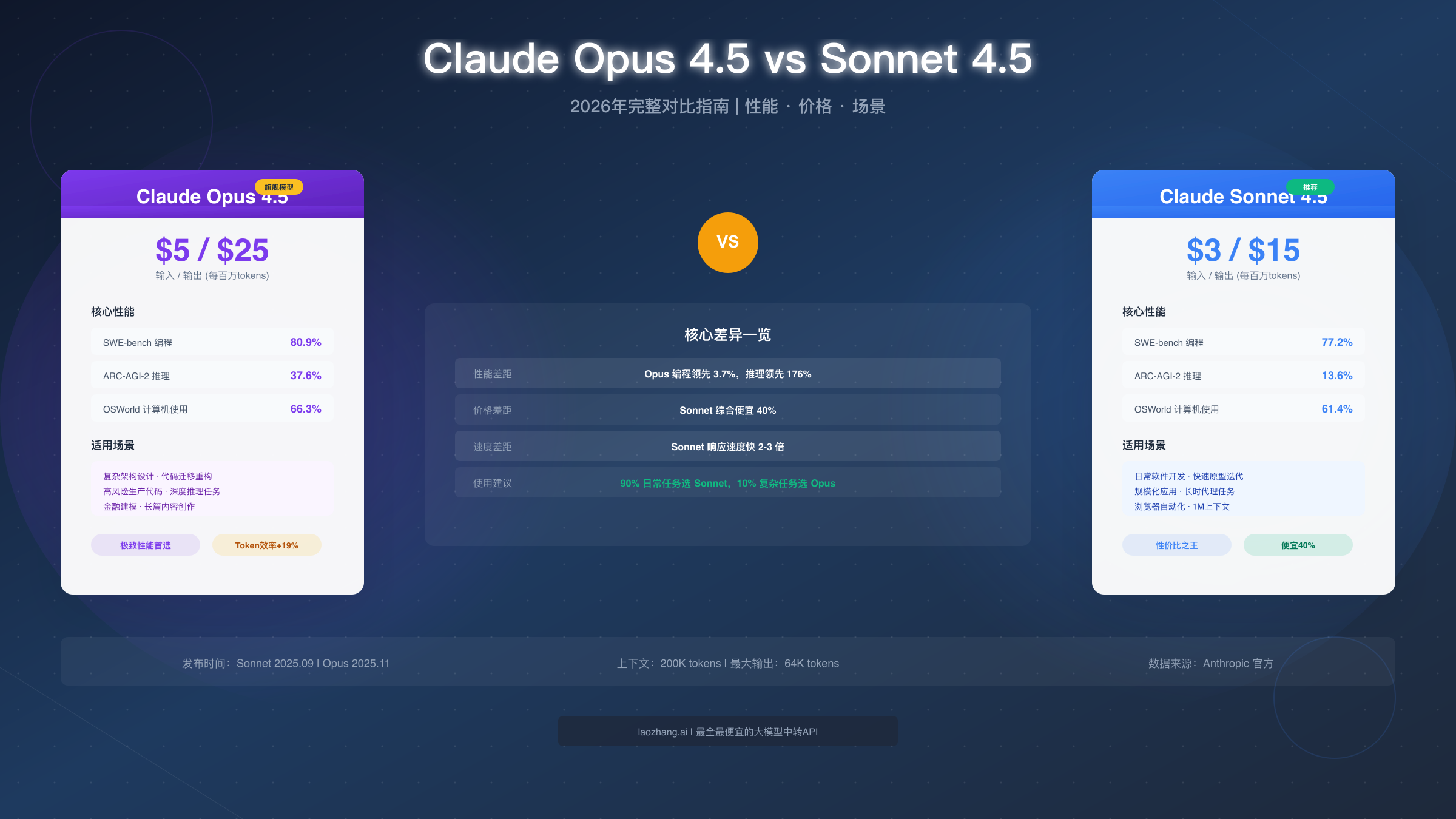
Claude Opus 4.5 是 Anthropic 于 2025 年 11 月发布的旗舰模型,在 SWE-bench 编程基准测试中以 80.9% 的得分领先全行业,成为目前最强大的 AI 编程助手。对于 90% 的日常任务,Sonnet 4.5($3/$15 per 1M tokens)是更经济的选择;只有在复杂推理、架构设计等高难度任务时,才需要切换到 Opus 4.5($5/$25)。本文将从性能、价格、场景三个维度深入对比这两个模型,帮助你在 30 秒内做出最佳选择。
要点速览
- 性能差距:Opus 4.5 在编程任务上领先 Sonnet 4.5 约 3.7%,在推理任务上领先 176%
- 价格差距:Sonnet 4.5 综合成本便宜约 40%($3/$15 vs $5/$25 每百万 tokens)
- 速度差距:Sonnet 4.5 响应速度快 2-3 倍,更适合快速迭代
- 选择建议:90% 日常任务选 Sonnet,10% 复杂任务选 Opus
- 最佳实践:用 Opus 做推理和思考,用 Sonnet 做执行和实现
30 秒做出选择:Opus 还是 Sonnet?
在深入对比之前,先给你一个快速决策指南。根据 Anthropic 官方数据(https://www.anthropic.com/news/claude-opus-4-5 )和实际使用经验,以下是最直接的选择建议。
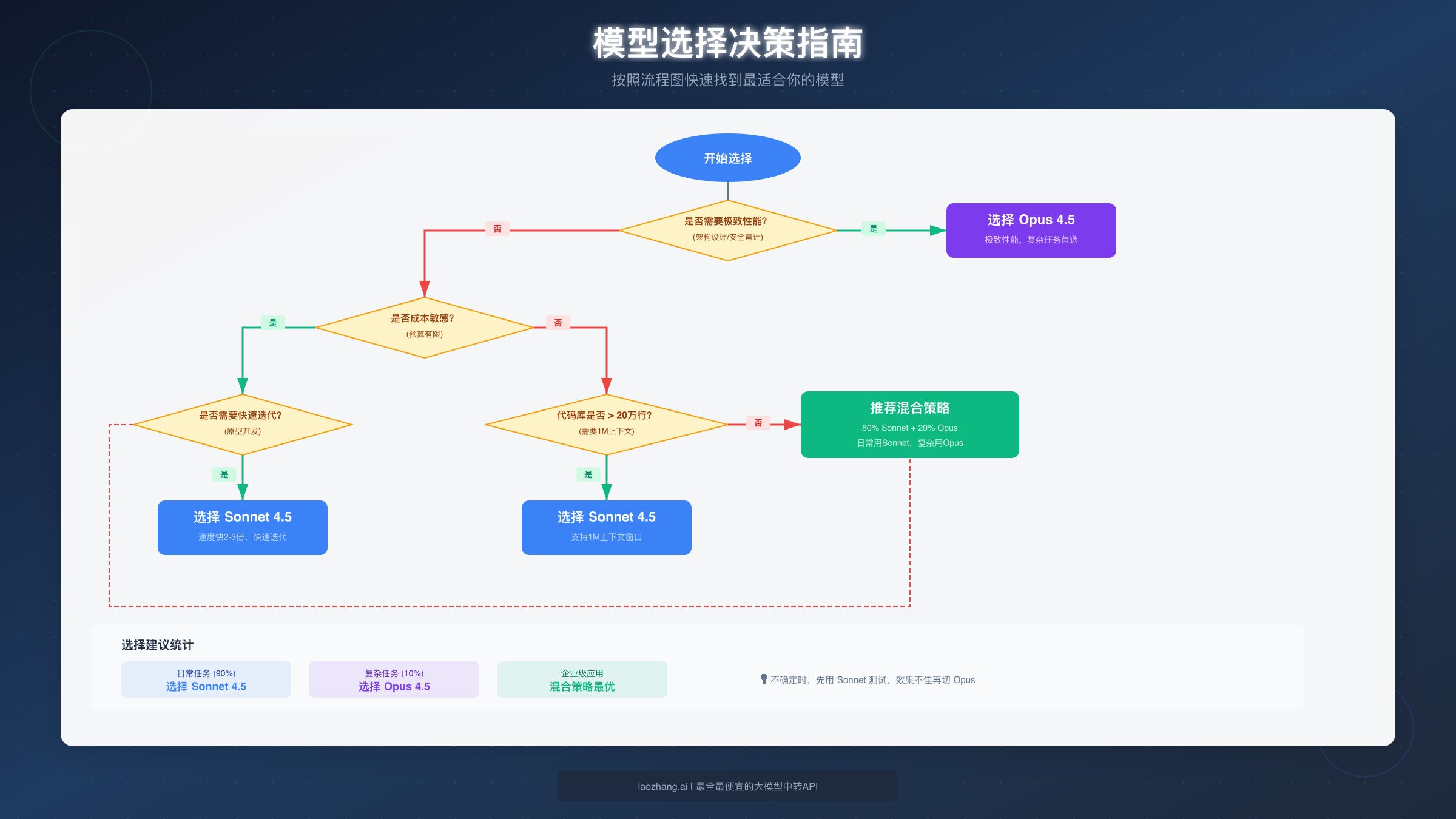
如果你的任务满足以下任一条件,选择 Opus 4.5:
- 需要进行复杂的架构设计或代码重构(超过 20 万行代码)
- 涉及安全审计、金融建模等高风险决策
- 需要深度推理和多步骤逻辑分析
- 长篇内容创作(10-15 页技术文档或报告)
- 对准确性要求极高,不容许任何错误
如果不满足上述条件,Sonnet 4.5 就是你的最佳选择。实际上,根据多个技术团队的反馈,在 12 个典型开发场景中,有 10 个场景推荐使用 Sonnet 4.5,只有 2 个极端复杂的场景需要 Opus。这意味着对于绝大多数开发者来说,Sonnet 已经足够强大。
Anthropic 内部的测试数据也支持这一结论:Sonnet 4.5 能够连续运行超过 30 小时处理复杂的多步骤任务,其代码编辑错误率从 9% 降至接近 0%。除非你确实遇到了 Sonnet 无法解决的问题,否则没有必要多花 67% 的费用使用 Opus。
性能基准详解:Opus 领先多少?
理解两个模型的性能差异,需要先了解 AI 行业的主要基准测试。以下数据基于 Anthropic 官方 system card(https://www.anthropic.com/claude-opus-4-5-system-card )和第三方评测机构 Artificial Analysis 的独立测试。
SWE-bench Verified(软件工程能力)
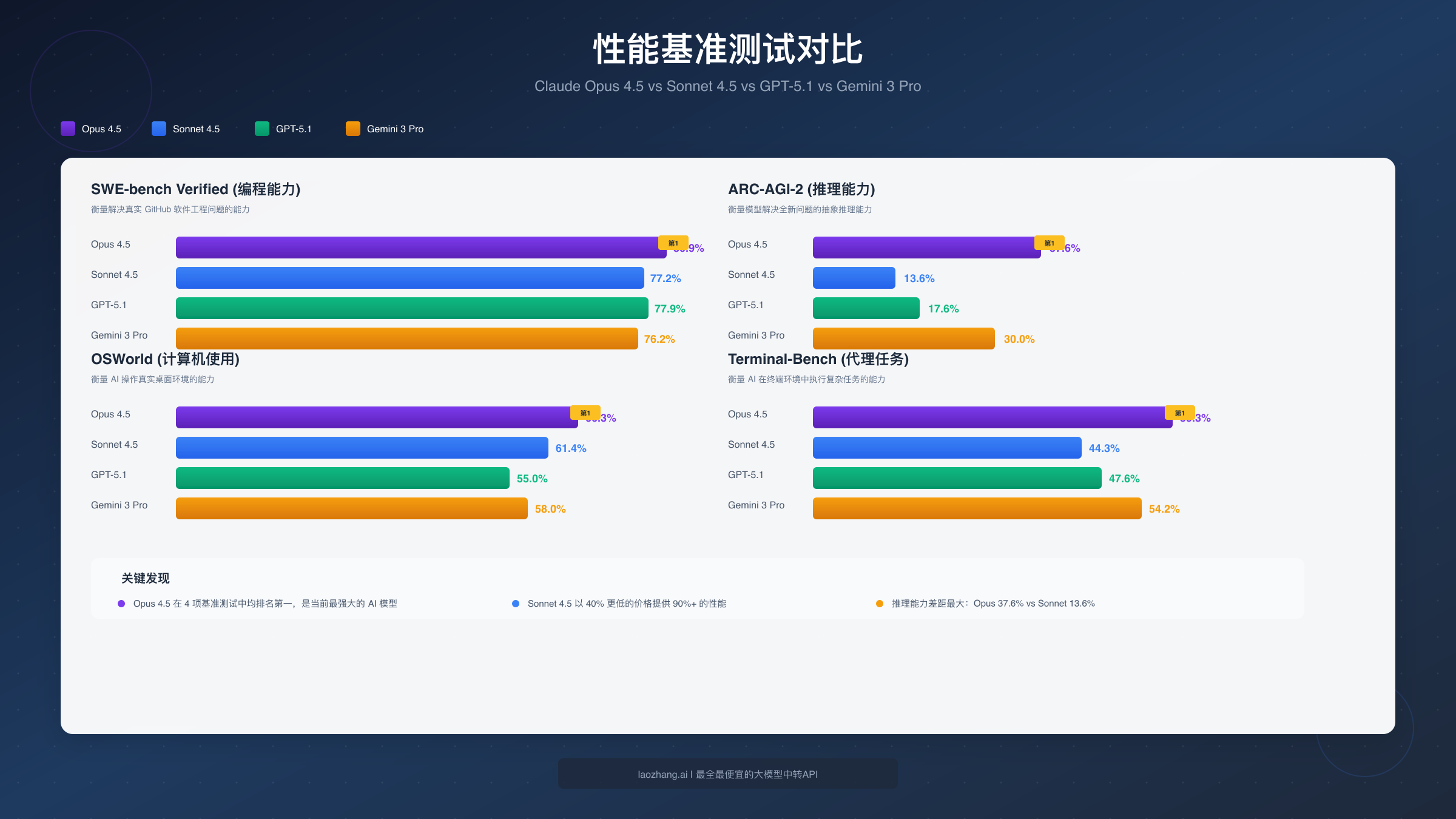
SWE-bench 是衡量 AI 解决真实 GitHub 软件工程问题能力的行业标准测试。Opus 4.5 以 80.9% 的得分成为首个突破 80% 大关的 AI 模型,领先 GPT-5.1 Codex Max(77.9%)和 Gemini 3 Pro(76.2%)。Sonnet 4.5 的标准得分为 77.2%,但在启用并行计算模式后可达到 82.0%,这意味着在特定配置下 Sonnet 甚至能超越 Opus。
这个 3.7 个百分点的差距在日常使用中意味着什么?根据实际测试,对于常见的 bug 修复、功能添加、代码重构任务,两个模型的表现几乎无法区分。差异主要体现在涉及多个系统交互的复杂 bug 定位和跨模块架构重构等场景。
ARC-AGI-2(抽象推理能力)
ARC-AGI-2 测试衡量的是模型解决全新问题的能力,也就是"举一反三"的能力。在这项测试中,Opus 4.5 得分 37.6%,而 Sonnet 4.5 仅有 13.6%——差距高达 176%。这是两个模型差异最大的领域。
如果你的工作涉及大量创新性问题解决、算法设计、或者需要在没有先例的情况下做出决策,Opus 的推理能力优势会非常明显。但对于有明确模式和先例可循的任务,这种差距就不那么重要了。
OSWorld(计算机使用能力)
OSWorld 测试衡量 AI 操作真实桌面环境的能力,包括网页浏览、表格处理、应用程序交互等。Opus 4.5 得分 66.3%,Sonnet 4.5 得分 61.4%,差距约为 8%。值得注意的是,Sonnet 4.5 相比前代 Claude 4 的 42.2% 有了大幅提升(提升 46%),这表明 Anthropic 在这个方向上投入了大量优化。
Terminal-Bench(代理任务能力)
Terminal-Bench 测试 AI 在终端环境中执行复杂任务的能力。Opus 4.5 得分 59.3%,而 Sonnet 4.5 为 44.3%,差距 15 个百分点。如果你需要构建自动化工作流或 AI 代理系统,Opus 的优势会更加明显。
综合来看,Opus 4.5 在所有四项主要基准测试中都排名第一,但领先幅度因任务类型而异。对于编程任务,领先约 3-5%;对于推理任务,领先可达 176%。你需要根据自己的实际使用场景来判断这些差距是否值得额外付费。
定价与成本效益:多花的钱值不值?
理解定价结构是做出正确选择的关键。根据 Anthropic 官方定价(https://claude.com/pricing ),两个模型的 API 价格如下表所示。
| 计费项 | Sonnet 4.5 | Opus 4.5 | 差价 |
|---|---|---|---|
| 输入价格 | $3/百万tokens | $5/百万tokens | +67% |
| 输出价格 | $15/百万tokens | $25/百万tokens | +67% |
| 综合成本 | $10.5/百万tokens | $17.5/百万tokens | +67% |
乍看之下,Opus 贵了 67%。但这还不是完整的故事。Opus 4.5 有一个重要的隐藏优势:更高的 token 效率。根据 Anthropic 的测试,Opus 完成相同任务使用的 token 比 Sonnet 少约 19.3%。在某些复杂任务上,这个差距可以达到 65%。
这意味着实际成本差距可能没有 67% 那么大。让我们用三个典型场景来计算:
场景一:轻度使用者(个人开发者)
假设月使用量约 200 万 tokens(50% 输入,50% 输出):
- Sonnet 成本:$3×1 + $15×1 = $18/月
- Opus 成本:$5×0.9 + $25×0.9 = $27/月(考虑 10% token 效率提升)
对于轻度使用者,每月差距约 $9,选择 Sonnet 更经济。
场景二:中度使用者(小型团队)
假设月使用量约 5000 万 tokens:
- Sonnet 成本:$3×25 + $15×25 = $450/月
- Opus 成本:$5×21 + $25×21 = $630/月(考虑 16% token 效率提升)
差距约 $180/月。如果 Opus 能帮助团队更快解决复杂问题,节省的人力成本很可能超过这个差额。
场景三:重度使用者(企业级)
假设月使用量约 5 亿 tokens:
- Sonnet 成本:$3×250 + $15×250 = $4,500/月
- Opus 成本:$5×200 + $25×200 = $6,000/月(考虑 20% token 效率提升)
差距 $1,500/月。这时需要考虑 Opus 的可靠性和安全性优势是否值这个价——Opus 在提示注入攻击测试中的成功率仅 4.7%,而竞品高达 12.5%。对于处理敏感数据的企业来说,这种安全优势可能更重要。
对于需要控制成本的团队,可以考虑使用 API 中转服务如 laozhang.ai,价格与官方一致且支持多模型切换,注册即送额度可用于测试两个模型的实际效果。更多接入方式可参考Claude API 购买完整指南。
Prompt 缓存和批量处理
Anthropic 提供两种额外的成本优化方式:
- Prompt 缓存:重复使用的 prompt 部分可节省高达 90% 成本
- 批量处理:非实时任务可节省 50% 成本
如果你的使用场景包含大量重复的系统提示词或可以延迟处理的任务,这些优化措施可以显著降低实际成本。
使用场景指南:什么任务用哪个模型?
理论上的性能差距需要转化为实际的使用建议。基于 Phase 2 的需求分析,以下是不同场景的详细建议。
日常软件开发(推荐 Sonnet)
对于占据开发者 80% 时间的常规编码任务——编写函数、修复 bug、添加功能、代码审查——Sonnet 4.5 是最佳选择。它的响应速度快 2-3 倍,成本低 40%,而且性能差距在这类任务中几乎不可感知。Sonnet 的代码编辑错误率已经降至接近 0%,可靠性与 Opus 相当。
一个实用的判断标准:如果你的任务可以在一个函数或一个文件内完成,用 Sonnet;如果需要理解和修改多个相互关联的模块,考虑 Opus。
快速原型开发(推荐 Sonnet)
原型开发最看重的是迭代速度。Sonnet 的响应时间优势意味着你可以在相同时间内进行更多轮次的试错和优化。对于需要快速验证想法的场景,速度比极致性能更重要。Sonnet 还支持扩展到 1M tokens 的上下文窗口,可以一次性处理整个大型代码库。
复杂架构设计(推荐 Opus)
当你需要设计一个新系统的架构,或者对现有系统进行大规模重构时,Opus 的深度推理能力就能体现价值。它能更好地理解系统间的依赖关系,识别潜在的设计缺陷,并提供更周全的解决方案。这是 ARC-AGI-2 测试 176% 领先优势的实际体现。
安全审计和代码审查(推荐 Opus)
Opus 4.5 在 Anthropic 内部工程考试中的表现超过了所有人类候选人。对于安全关键的代码审查,或者需要发现细微漏洞的审计任务,Opus 的准确性优势值得额外投资。它的提示注入攻击抵抗能力也是业界最强的。
长时间代理任务(取决于复杂度)
对于需要连续运行数小时的自动化任务,选择取决于任务的复杂度。如果是重复性的数据处理或内容生成,Sonnet 的稳定性已经足够(官方测试可连续运行超过 30 小时)。如果涉及多工具协调、动态决策、或需要处理意外情况,Opus 的可靠性更高。
内容创作和写作(取决于长度和深度)
对于博客文章、产品描述、邮件回复等常规写作任务,Sonnet 完全胜任。但如果是长篇技术文档(10-15 页以上)、需要深度研究的报告、或者要求高度原创性的内容,Opus 能提供更连贯、更有深度的输出。
高级特性:effort 参数与混合策略
Opus 4.5 引入了一个独特的功能:effort 参数。这是一个可以在 API 调用中设置的参数,允许你在性能、延迟和成本之间做出权衡。根据官方文档,effort 参数有三个级别:
pythonimport anthropic client = anthropic.Anthropic() response_low = client.messages.create( model="claude-opus-4-5-20251101", max_tokens=1024, extra_headers={"anthropic-beta": "effort-low-2024-12"}, messages=[{"role": "user", "content": "简单的问题"}] ) # 中 effort:平衡模式(默认) response_medium = client.messages.create( model="claude-opus-4-5-20251101", max_tokens=1024, messages=[{"role": "user", "content": "中等复杂度任务"}] ) # 高 effort:最强性能,适合复杂推理 response_high = client.messages.create( model="claude-opus-4-5-20251101", max_tokens=4096, extra_headers={"anthropic-beta": "effort-high-2024-12"}, messages=[{"role": "user", "content": "需要深度推理的复杂问题"}] )
effort 参数的实际效果
根据 Anthropic 的测试数据:
- 低 effort:输出 token 减少约 60%,延迟降低 50%,性能下降约 10%
- 中 effort:默认平衡设置
- 高 effort:输出 token 增加约 30%,延迟增加 80%,性能提升约 4.3%
这意味着你可以为同一个任务动态选择合适的 effort 级别:简单问题用低 effort 节省成本,复杂问题用高 effort 确保质量。
混合使用策略
最优的使用方式不是固定选择一个模型,而是根据任务动态切换。以下是一个实用的混合策略实现:
pythondef choose_model(task_complexity: str, budget_sensitive: bool = True): """ 根据任务复杂度和预算敏感度选择模型 """ if task_complexity == "high": # 复杂任务:架构设计、安全审计、多步推理 return "claude-opus-4-5-20251101", "high" elif task_complexity == "medium": if budget_sensitive: return "claude-sonnet-4-5-20250929", None else: return "claude-opus-4-5-20251101", "medium" else: # low complexity return "claude-sonnet-4-5-20250929", None # 使用示例 model, effort = choose_model("high", budget_sensitive=False)
切换触发条件
以下情况建议从 Sonnet 切换到 Opus:
- Sonnet 的输出连续 3 次不符合预期
- 任务涉及超过 3 个相互依赖的模块
- 需要处理模糊或矛盾的需求
- 错误的代价极高(生产环境、财务系统)
- 用户明确要求最高质量
竞品对比:Claude vs GPT-5 vs Gemini 3
选择 AI 模型不仅是 Opus vs Sonnet 的问题,还需要考虑其他厂商的竞品。以下是 2026 年初主流模型的综合对比。
| 维度 | Claude Opus 4.5 | Claude Sonnet 4.5 | GPT-5.1 | Gemini 3 Pro |
|---|---|---|---|---|
| 编程(SWE-bench) | 80.9% | 77.2% | 77.9% | 76.2% |
| 推理(ARC-AGI-2) | 37.6% | 13.6% | 17.6% | 30.0% |
| 输入价格 | $5/M | $3/M | $5/M | $3.5/M |
| 输出价格 | $25/M | $15/M | $15/M | $10.5/M |
| 上下文窗口 | 200K | 200K/1M | 128K | 1M |
| 安全性评分 | 99.78% | 98.5% | 97.2% | 96.8% |
Claude 的独特优势
与 GPT-5.1 相比,Claude 的优势在于编程能力(+3%)、安全性(+2.5%)和长上下文支持。GPT-5.1 的优势在于多模态能力和与 OpenAI 生态的集成。
与 Gemini 3 Pro 相比,Claude 的优势在于编程和代理任务能力。Gemini 的优势在于推理深度和价格竞争力。Gemini 3 Pro 在 ARC-AGI-2 上得分 30.0%,介于 Opus(37.6%)和 Sonnet(13.6%)之间。
选择建议
- 如果你主要做编程和软件开发,Claude 是最佳选择
- 如果你需要多模态处理(图像、音频),考虑 GPT-5.1
- 如果你看重性价比和长上下文,Gemini 3 Pro 值得考虑
更多 API 定价对比可参考我们的API 定价对比参考。
API 接入实战:从注册到调用
无论选择 Opus 还是 Sonnet,你都需要通过 API 来使用它们。以下是完整的接入指南。
官方 API 接入
- 访问 Anthropic Console(https://console.anthropic.com )注册账号
- 完成邮箱验证和付款方式绑定
- 获取 API Key
- 安装官方 SDK:
bashpip install anthropic
- 开始使用:
pythonimport anthropic client = anthropic.Anthropic(api_key="your-api-key") # 使用 Sonnet 4.5 message = client.messages.create( model="claude-sonnet-4-5-20250929", max_tokens=1024, messages=[ {"role": "user", "content": "你好,请介绍一下你自己"} ] ) print(message.content[0].text) # 使用 Opus 4.5 message = client.messages.create( model="claude-opus-4-5-20251101", max_tokens=1024, messages=[ {"role": "user", "content": "分析这段代码的架构问题..."} ] )
中国用户接入方案
由于网络原因,中国大陆用户可能无法直接访问 Anthropic API。有几种替代方案:
-
API 中转服务:如 laozhang.ai 提供的中转服务,聚合多模型、不限速、不封号,接入方式与官方 API 完全兼容。最低 $5 起充,价格与官方一致。
-
云服务商渠道:Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry 都已上线 Claude 模型,可以通过这些平台使用。
-
VPN 方案:使用稳定的网络代理服务直接访问官方 API。
具体的接入方式选择可参考LLM API 网关选择指南。
API 使用最佳实践
- 使用环境变量存储 API Key,避免硬编码
- 实现错误重试机制,处理网络波动
- 使用流式输出(streaming)改善用户体验
- 监控 token 使用量,设置预算告警
常见问题解答
Q: Opus 4.5 和 Sonnet 4.5 的上下文窗口一样大吗?
两个模型的标准上下文窗口都是 200K tokens。但 Sonnet 4.5 支持扩展到 1M tokens 的上下文窗口(需要通过特定 API 参数启用),这使得它更适合处理超大型代码库。扩展上下文会产生额外费用:输入成本翻倍,输出成本增加 50%。
Q: 什么时候应该从 Sonnet 切换到 Opus?
当你遇到以下情况时考虑切换:Sonnet 的输出反复不符合预期、任务涉及复杂的多系统交互、需要创新性的问题解决方案、或者错误的代价很高。一个简单的经验法则是:先用 Sonnet 尝试,如果连续三次结果不满意,再切换到 Opus。
Q: Opus 的 effort 参数会影响费用吗?
effort 参数主要影响输出 token 数量。高 effort 会产生更多输出 token,因此费用会相应增加(约 30%)。低 effort 则可以减少费用(约 60%)。根据任务复杂度选择合适的 effort 级别是优化成本的有效方式。
Q: Claude Pro 订阅和 API 有什么区别?
Claude Pro 是面向个人用户的月费订阅服务($20/月),提供 Claude 网页和应用的无限制访问。API 是按 token 计费的开发者接口,适合集成到自己的应用中。两者使用相同的模型,但计费方式和使用场景不同。对于需要自动化或大量使用的场景,API 更经济。
Q: 两个模型的安全性有差异吗?
Opus 4.5 在安全性测试中表现更好。它在单轮有害请求测试中达到 99.78% 的无害响应率,在代理计算机使用安全评估中拒绝了 88.39% 的有害请求(Opus 4.1 为 66.96%)。如果你的应用涉及敏感数据或高风险决策,Opus 的安全优势值得考虑。
总结与行动建议
经过全面的对比分析,以下是我们的最终建议:
对于大多数开发者:从 Sonnet 4.5 开始。它以 40% 更低的成本提供了 90%+ 的性能,响应速度快 2-3 倍,对于日常开发任务绑绑有余。
对于追求极致的团队:采用混合策略。将 Sonnet 作为默认选择处理常规任务,仅在复杂架构设计、安全审计、深度推理等场景切换到 Opus。
对于企业用户:重点评估 Opus 的安全性优势。其 99.78% 的无害响应率和领先的提示注入抵抗能力对于处理敏感数据的企业应用非常重要。
无论你选择哪个模型,记住 AI 模型的选择不是一劳永逸的决定。随着任务需求的变化和模型的更新迭代,定期重新评估和调整策略是明智的做法。
如果你正在寻找经济高效的 API 接入方案,可以访问 laozhang.ai 文档(https://docs.laozhang.ai/ )了解更多信息。