
随着Google于2025年推出并完善Gemini 2.5系列模型,其API服务为开发者提供了多种性能和价格选择。本文将全面解析Gemini 2.5 API的最新定价结构,帮助开发者做出最合适的选择,并提供实用的成本优化策略。无论您是刚开始接触AI API还是已经在大规模应用中使用它们,本指南都能帮您更好地规划预算和优化成本。
引言:Gemini 2.5 API价格体系概述
Google的Gemini 2.5 API采用了基于令牌的计费模式,分为输入令牌和输出令牌两种收费类型。相比其竞争对手,Google提供了更加灵活和丰富的模型选择,从高性能的Pro版本到经济实惠的Flash-Lite,满足不同应用场景和预算需求。
在深入了解具体价格之前,我们需要理解一些核心概念:
-
令牌(Token)计费基础:令牌是AI模型处理文本的基本单位,大约相当于4个字符或3/4个英文单词。Gemini API完全基于令牌计费,而非字符数或API调用次数。
-
输入与输出令牌差异:输入令牌(用户提供的内容)和输出令牌(模型生成的内容)有不同的计费标准,通常输出令牌价格更高。
-
多模态内容计费:不同类型的内容(文本、图像、视频、音频)有着不同的令牌计算方式,这会显著影响总体成本。
-
思考模式定价:Gemini 2.5系列引入了"思考"功能,这将影响输出令牌的计费。
让我们深入探讨Gemini 2.5系列的各个模型及其定价细节。
Gemini 2.5系列模型定价对比
Gemini 2.5 Pro:性能旗舰
Gemini 2.5 Pro是Google最强大的模型,专为需要高级推理能力和复杂任务处理的应用设计。其价格结构如下:
输入令牌:
- 200K令牌以内:$1.25/百万令牌
- 超过200K令牌:$2.50/百万令牌
输出令牌(包括思考过程):
- 200K令牌以内:$10.00/百万令牌
- 超过200K令牌:$15.00/百万令牌
上下文缓存:
- 200K令牌以内:$0.31/百万令牌
- 超过200K令牌:$0.625/百万令牌
- 存储费用:$4.50/百万令牌/小时
这一定价使Gemini 2.5 Pro成为市场上最高端的API选择之一,适合需要最高质量推理、复杂编程和多模态理解的应用场景。
Gemini 2.5 Flash:平衡之选
Gemini 2.5 Flash是Google首款混合推理模型,支持100万令牌的上下文窗口和思考预算控制,为大多数应用提供了理想的平衡点:
输入令牌:
- 文本/图像/视频:$0.30/百万令牌
- 音频:$1.00/百万令牌
输出令牌:$2.50/百万令牌
上下文缓存:
- 文本/图像/视频:$0.075/百万令牌
- 音频:$0.25/百万令牌
- 存储费用:$1.00/百万令牌/小时
Gemini 2.5 Flash是一个全能型选择,适用于需要平衡性能和成本的生产环境应用。
Gemini 2.5 Flash-Lite:经济之选
Gemini 2.5 Flash-Lite是目前系列中最具成本效益的选项,专为大规模使用场景设计:
输入令牌:
- 文本/图像/视频:$0.10/百万令牌
- 音频:$0.50/百万令牌
输出令牌:$0.40/百万令牌
上下文缓存:
- 文本/图像/视频:$0.025/百万令牌
- 音频:$0.125/百万令牌
- 存储费用:$1.00/百万令牌/小时
对于预算有限但需要处理大量数据的应用,Flash-Lite是最经济的选择。
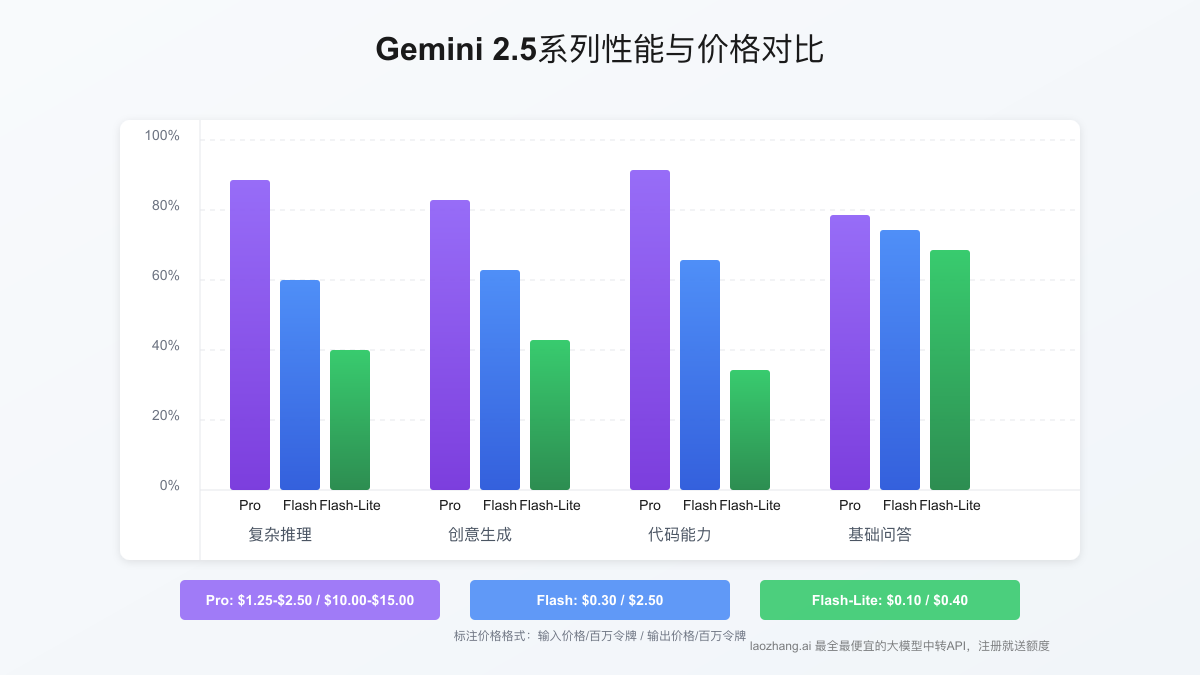
模型性能与价格效益分析
为了帮助开发者做出合适选择,我们对三款模型的性能和价格进行了详细对比分析:
| 模型 | 输入价格(/M令牌) | 输出价格(/M令牌) | 推理能力 | 上下文窗口 | 最适合场景 |
|---|---|---|---|---|---|
| Gemini 2.5 Pro | $1.25-$2.50 | $10.00-$15.00 | 最强 | 100万令牌 | 复杂推理、创意生成、专业编程 |
| Gemini 2.5 Flash | $0.30 | $2.50 | 中等 | 100万令牌 | 通用AI应用、文档处理、客户服务 |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | 基础 | 100万令牌 | 大规模分类、摘要、基础问答 |
虽然在纯价格对比中,Flash-Lite每百万令牌的成本仅为Pro版本的约8-10%,但在复杂任务上其表现可能不尽如人意。因此,选择最适合的模型应综合考虑性能需求和预算限制。
多模态内容计费详解
Gemini 2.5系列支持多种输入类型,每种类型的计费方式不同:
1. 文本内容
文本是最基本的输入类型,大约4个字符等于1个令牌。例如,一个1000字的中文文档大约消耗500-600个令牌。
2. 图像内容
每张图像无论大小和分辨率,统一计为258个令牌。值得注意的是:
- 图像会被自动缩放至适合处理的尺寸
- 提高图像分辨率不会提升性能,但会增加带宽使用
- 每次请求最多支持3,000张图像
3. 视频内容
视频以每秒258个令牌计算(基于每秒1帧的采样率)。例如:
- 30秒视频:约7,740令牌
- 5分钟视频:约77,400令牌
4. 音频内容
音频内容以每秒25个令牌计费(无时间戳)。例如:
- 1分钟音频:约1,500令牌
- 1小时播客:约90,000令牌
了解这些计费标准有助于更准确地估算API使用成本,特别是在构建多模态应用时。
Google Search集成与额外功能定价
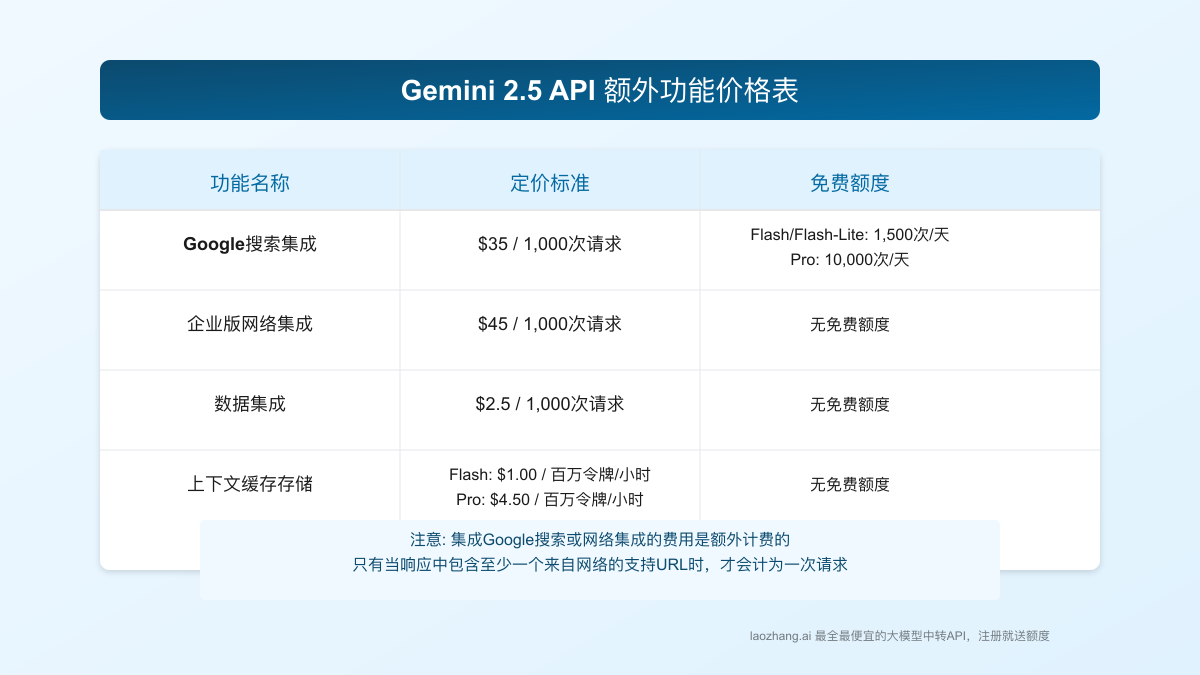
除了基础API调用外,Gemini 2.5还提供了一些额外功能,这些功能有单独的计费标准:
Google Search集成
Gemini与Google搜索的集成使AI回复能够引用最新网络数据,定价如下:
-
免费额度:
- Gemini 2.5 Flash和Flash-Lite共享每天1,500次请求
- Gemini 2.5 Pro每天10,000次请求
-
超出免费额度:每1,000次集成搜索请求$35
只有当响应中包含至少一个来自网络的支持URL时,才会计为一次集成搜索请求。
企业版网络集成
针对需要更高级企业级搜索功能的用户,Google提供了企业版网络集成:
- 定价:每1,000次集成请求$45
数据集成
从2025年6月16日起,使用自有数据进行集成的请求将按以下标准计费:
- 每1,000次请求$2.5
成本优化策略
了解了Gemini 2.5系列的定价结构后,以下是一些有效的成本优化策略:
1. 选择合适的模型
根据任务复杂性选择合适的模型可以显著节约成本:
- 简单任务(分类、摘要、基本问答):使用Flash-Lite
- 中等复杂度任务(内容生成、文档理解):使用Flash
- 复杂任务(专业编程、复杂推理、创意写作):使用Pro
2. 优化提示工程
良好的提示设计可以减少所需的令牌数量:
- 使用清晰、简洁的提示语言
- 避免不必要的上下文和冗余信息
- 使用结构化的提示模板提高效率
3. 合理使用上下文缓存
上下文缓存可以在会话中保存信息,减少重复输入:
- 对于长对话场景,利用上下文缓存可以避免重复发送相同信息
- 注意合理管理缓存生命周期,避免不必要的存储费用
4. 批处理请求
使用批处理API可以显著降低成本,特别是对于大量相似请求:
- Gemini 2.5 Flash批处理价格可降低50%(输入$0.15/M,输出$1.25/M)
- 将多个单独请求合并为批处理请求
5. 控制输出令牌数量
由于输出令牌价格通常高于输入令牌,控制输出长度尤为重要:
- 设置合理的最大输出令牌限制
- 在提示中明确要求简洁回答
- 考虑使用结构化输出格式(如JSON)增加信息密度
实际应用场景成本计算示例
以下是几个常见应用场景的成本计算示例,帮助您更直观地了解实际使用成本:
场景1:客服聊天机器人
使用模型:Gemini 2.5 Flash-Lite 平均对话:
- 用户输入:200令牌/次
- AI回复:300令牌/次
- 每日对话:1,000次
每日成本计算:
- 输入:200令牌 × 1,000次 = 200,000令牌 = 0.2M令牌 × $0.10 = $0.02
- 输出:300令牌 × 1,000次 = 300,000令牌 = 0.3M令牌 × $0.40 = $0.12
- 总成本:$0.14/天 或 $4.20/月
场景2:内容生成平台
使用模型:Gemini 2.5 Flash 平均使用:
- 用户提示:500令牌/次
- 生成内容:2,000令牌/次
- 每日生成:200篇
每日成本计算:
- 输入:500令牌 × 200次 = 100,000令牌 = 0.1M令牌 × $0.30 = $0.03
- 输出:2,000令牌 × 200次 = 400,000令牌 = 0.4M令牌 × $2.50 = $1.00
- 总成本:$1.03/天 或 $30.90/月
场景3:高级代码助手
使用模型:Gemini 2.5 Pro 平均使用:
- 代码提交:2,000令牌/次
- 代码生成:1,500令牌/次
- 每日使用:50次
每日成本计算:
- 输入:2,000令牌 × 50次 = 100,000令牌 = 0.1M令牌 × $1.25 = $0.125
- 输出:1,500令牌 × 50次 = 75,000令牌 = 0.075M令牌 × $10.00 = $0.75
- 总成本:$0.875/天 或 $26.25/月

与竞争对手的价格对比
为了帮助开发者做出更全面的决策,我们将Gemini 2.5 API与其他主要大语言模型API进行了价格对比:
| 模型 | 输入价格(/M令牌) | 输出价格(/M令牌) | 上下文窗口 | 相对性能 |
|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | 100万 | 中等 |
| Gemini 2.5 Flash | $0.30 | $2.50 | 100万 | 良好 |
| Gemini 2.5 Pro | $1.25-$2.50 | $10.00-$15.00 | 100万 | 极佳 |
| GPT-4o | $5.00 | $15.00 | 12.8万 | 极佳 |
| Claude 3.5 Sonnet | $3.00 | $15.00 | 20万 | 极佳 |
| Mistral Large | $2.00 | $6.00 | 3.2万 | 良好 |
从价格效益比来看,Gemini 2.5系列提供了更丰富的选择范围,特别是Flash和Flash-Lite版本在性价比上具有明显优势。此外,所有Gemini 2.5模型都支持100万令牌的上下文窗口,这在处理长文本和复杂场景时具有显著优势。
免费层级与API密钥
Google为开发者提供了免费使用Gemini API的机会:
免费层级权益
- Google AI Studio:所有可用地区均可免费使用
- Gemini 2.5 Flash和Flash-Lite:提供免费的输入和输出令牌配额
- Google Search集成:每天500次免费请求(Flash和Flash-Lite共享)
API密钥获取
要开始使用Gemini API,您可以通过以下方式获取API密钥:
- 访问Google AI Studio
- 注册或登录Google账户
- 创建新项目并生成API密钥
- 配置API使用权限和配额
免费层级非常适合初学者和小型项目,随着项目规模增长,可以无缝过渡到付费层级。
开发者接入最佳实践
以下是使用Gemini 2.5 API的一些最佳实践,可以帮助您获得更好的开发体验:
1. 令牌计数工具
在发送请求前使用令牌计数工具估算成本。Google提供了countTokens API和SDK tokenizer工具来帮助开发者计算令牌数:
pythonimport google.generativeai as genai # 配置API密钥 genai.configure(api_key='YOUR_API_KEY') # 计算文本的令牌数 result = genai.count_tokens(model="gemini-2.5-flash", contents="要计算的文本内容") print(f"令牌数量: {result.total_tokens}")
2. 批处理API使用
对于需要处理大量类似请求的场景,使用批处理API可以显著降低成本:
pythonimport google.generativeai as genai # 配置API和批处理请求 genai.configure(api_key='YOUR_API_KEY') # 准备批量请求 contents = [ "第一个问题", "第二个问题", "第三个问题" ] # 发送批处理请求 responses = genai.generate_content_batch( model="gemini-2.5-flash", contents=contents, generation_config={"max_output_tokens": 500} ) # 处理结果 for i, response in enumerate(responses): print(f"问题 {i+1} 回答: {response.text}")
3. 思考模式控制
Gemini 2.5系列引入的"思考"功能可以提高复杂任务的处理质量,但也会影响成本:
pythonimport google.generativeai as genai genai.configure(api_key='YOUR_API_KEY') # 启用思考模式 model = genai.GenerativeModel('gemini-2.5-flash') response = model.generate_content( "分析以下代码的时间复杂度:\n```python\ndef find_duplicate(nums):\n for i in range(len(nums)):\n for j in range(i+1, len(nums)):\n if nums[i] == nums[j]:\n return nums[i]\n return -1\n```", generation_config={ "thinking": True, # 启用思考模式 "thinking_budget": 0.5 # 设置思考预算(0-1之间) } ) print(response.text)
4. 上下文缓存优化
对于多轮对话场景,合理使用上下文缓存可以提高效率并优化成本:
pythonimport google.generativeai as genai genai.configure(api_key='YOUR_API_KEY') # 创建聊天会话 chat = genai.chat(model='gemini-2.5-flash') # 第一轮对话,将信息缓存到上下文中 response = chat.send_message("我是一名Python开发者,需要学习异步编程") print(response.text) # 后续对话不需要重复之前的上下文 response = chat.send_message("请给我一个简单的asyncio例子") print(response.text)
常见问题解答
以下是开发者经常提问的关于Gemini 2.5 API定价的问题:
Q1: Gemini 2.5 API是否有免费层级?
是的,Google AI Studio提供完全免费的Gemini API使用体验,而通过API服务的免费层级则有更低的速率限制,适合测试目的。但需要注意,免费层级不提供某些高级功能,如Gemini 2.5 Pro的访问。
Q2: 如何计算图像和PDF的令牌消耗?
无论图像大小和分辨率如何,每张图像固定消耗258个令牌。PDF则按页计费,每页相当于一张图像(258令牌)。例如,10页的PDF文档将消耗2,580个令牌。
Q3: 什么是"思考"功能,它如何影响价格?
"思考"是Gemini 2.5系列的新功能,允许模型进行更深入的推理。启用此功能会增加输出令牌的使用量,因为思考过程中产生的所有令牌都计入输出费用。对于Flash和Pro模型,默认启用思考功能,而Flash-Lite则默认关闭。
Q4: 上下文缓存存储费用如何计算?
上下文缓存存储费用基于保存在缓存中的令牌数量和持续时间,例如Gemini 2.5 Flash每小时每百万令牌收费$1.00。这意味着如果您在缓存中存储了50万令牌并保留2小时,费用将为$1.00。
Q5: 批处理API如何节省成本?
批处理API允许您一次发送多个请求,价格比单独请求降低约50%。这对于需要处理大量相似查询的应用场景特别有利,如批量内容分类或摘要生成。
总结与建议
Gemini 2.5 API提供了一系列从高性能到经济实惠的模型选择,使开发者能够根据具体需求和预算做出最合适的选择。基于我们的分析,以下是针对不同场景的建议:
- 预算有限的初创公司:从Flash-Lite开始,逐步测试是否满足您的质量需求
- 中等规模应用:Flash模型提供了很好的性能与成本平衡
- 企业级应用:结合使用Pro(复杂任务)和Flash(常规任务)可以优化整体成本
- 大规模部署:考虑使用批处理API和自定义功能优化令牌使用
无论您选择哪种模型,理解令牌计费机制、优化提示工程、合理使用批处理和上下文缓存都是控制成本的有效策略。随着AI技术的快速发展和更多模型的推出,定期评估您的API使用策略也是必要的。
本文将持续更新以反映Google Gemini API的最新定价变化和功能。最后更新于2025年6月20日。