
Gemini API 错误可以分为两大类,它们需要完全不同的处理策略:可重试错误(429、500、503、504),等待后重试最终会成功;以及不可重试错误(400、403、404),需要先修改代码或配置才能让请求正常工作。理解这一区别是 API 错误处理中最关键的概念——搞错了意味着要么在永远不会成功的请求上白白浪费时间重试,要么放弃了稍等片刻就能成功的请求。本指南覆盖你会遇到的每一种错误,并附带可以直接复制到项目中的可运行代码。
要点速览
每个 Gemini API 错误都对应两种处理策略之一:指数退避重试(针对 429、500、503、504)或修复后重新部署(针对 400、403、404)。429 RESOURCE_EXHAUSTED 错误约占 2026 年开发者投诉的 90%,主要原因是 Google 在 2025 年 12 月悄然将免费版速率限制下调了 50-80%。如果你在免费版上频繁遇到 429 错误,最快的解决方案是开通计费以解锁 Tier 1 限制,通常立即生效。对于服务端错误(500/503),请先检查 Google AI 状态页面 再排查自己的代码。下表提供了每个错误码的快速参考。
| HTTP 状态码 | gRPC 状态 | 可重试? | 首要操作 |
|---|---|---|---|
| 400 | INVALID_ARGUMENT | 否 | 检查请求体格式 |
| 400 | FAILED_PRECONDITION | 否 | 开通计费或更换区域 |
| 403 | PERMISSION_DENIED | 否 | 验证 API Key 和权限 |
| 404 | NOT_FOUND | 否 | 检查模型名称和资源路径 |
| 429 | RESOURCE_EXHAUSTED | 是 | 等待后使用退避策略重试 |
| 500 | INTERNAL | 是 | 等待 5-10 秒后重试 |
| 503 | UNAVAILABLE | 是 | 等待 30-60 秒后重试 |
| 504 | DEADLINE_EXCEEDED | 是 | 增加超时时间,减少输入量 |
故障排查决策树
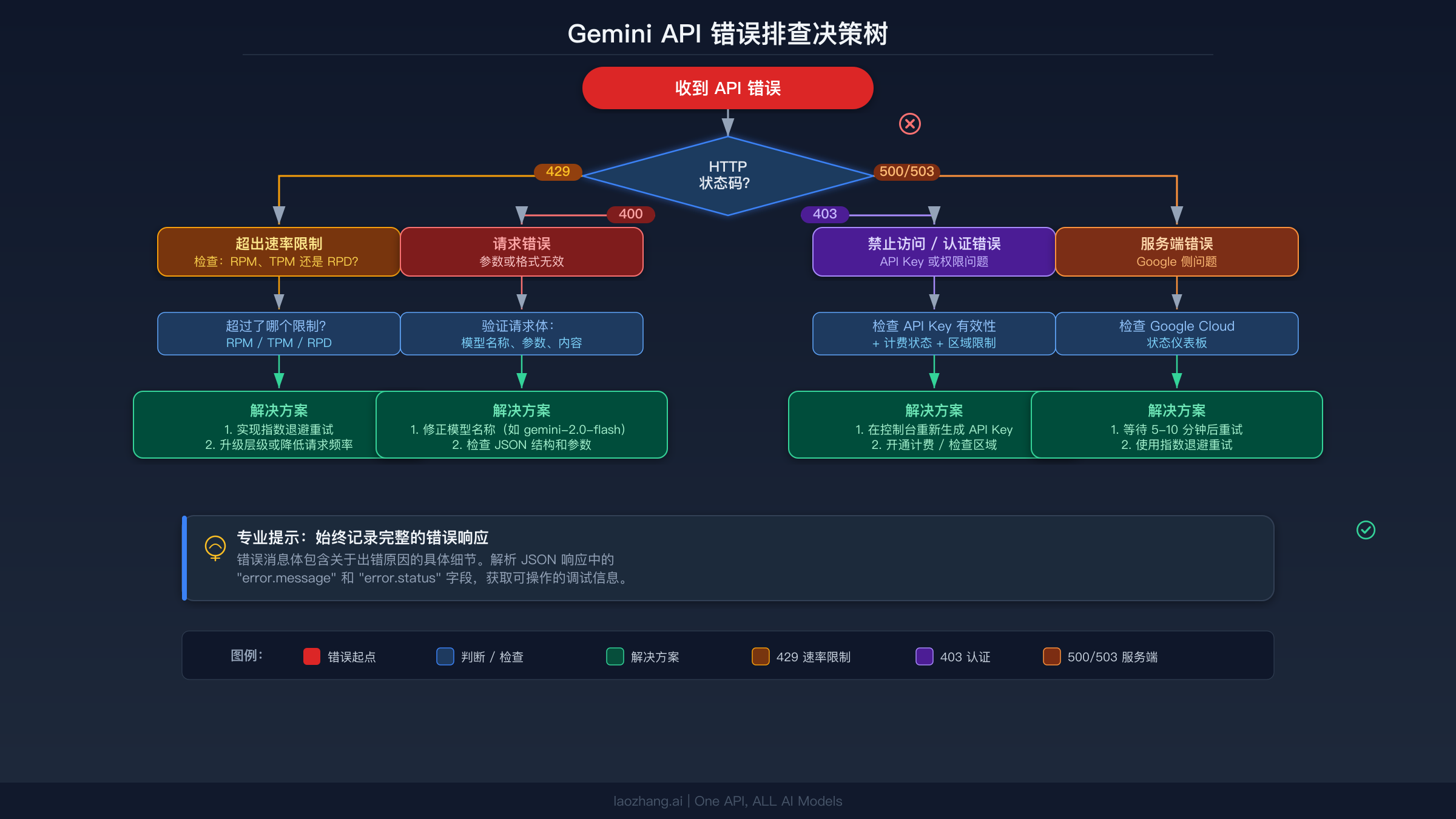
当一个 Gemini API 请求失败时,HTTP 状态码会准确告诉你应该沿着哪条诊断路径走。关键的第一步是读取完整的错误响应体,而不仅仅是状态码。每个 Gemini API 错误都会返回一个 JSON 对象,包含带有 gRPC 错误名称的 status 字段和带有人类可读详情的 message 字段,这些详情往往直接指向问题所在。许多开发者犯的错误是在 HTTP 层面捕获异常并丢弃这些细节,这会把一个五分钟就能修复的问题变成一个小时的盲目猜测。
诊断流程是这样的。 首先,检查状态码是在 4xx 范围还是 5xx 范围。如果是 4xx,问题出在你这一侧,重试不会有帮助。你需要检查错误消息,找出请求中的问题,修复它,然后重试。如果是 5xx,问题可能出在 Google 那一侧。先检查状态页面,如果服务看起来正常,就实现指数退避的重试逻辑。这个清晰划分的唯一例外是 429 错误,它虽然技术上是 4xx 状态码,但表现得像一个瞬态错误——等待足够长的时间或降低请求频率就会自行解决。
对于每种错误类型,遵循这个排查顺序。 首先记录完整的错误响应(包括请求头),特别是 429 错误的 Retry-After 头。然后检查你的日志中是否之前遇到过这个错误。同一个端点上反复出现 400 错误说明你构造请求的方式存在系统性问题。偶发的 429 错误说明你需要在客户端代码中实现速率限制。部署后持续出现的 403 错误说明环境变量或密钥管理出了问题。理解这些模式可以大大节省调试时间。如果你在使用 Gemini CLI 时遇到持续的 429 错误,请注意 CLI 有其独立于直接 API 调用的速率限制行为,详见 GitHub 上的 gemini-cli issue #10722。
深入解析 — 429 RESOURCE_EXHAUSTED(最常见的错误)
429 RESOURCE_EXHAUSTED 是迄今为止最常遇到的 Gemini API 错误,其发生频率在 Google 于 2025 年 12 月 6-7 日悄然将免费版速率限制下调 50-80% 后急剧上升。在此之前,Gemini 2.0 Flash 在免费版上提供 10 RPM。调整后降至 5 RPM,所有模型的每日请求限制也经历了类似的缩减。这一变更没有通过官方渠道宣布,让数千名开发者措手不及。如果你的应用在 2025 年 11 月运行正常,但在 12 月开始抛出 429 错误而代码没有任何改动,这几乎可以确定就是原因。
Gemini API 从三个独立维度衡量你的使用量,超过任何一个维度都会触发 429 错误。这三个维度是 RPM(每分钟请求数)、TPM(每分钟输入 Token 数)和 RPD(每日请求数)。这意味着你可能远低于 RPM 限制,但由于几个大请求推高了 TPM 而被限流。以下是截至 2026 年 3 月 17 日根据官方文档验证的当前免费版限制。
| 模型 | 免费 RPM | 免费 RPD | 免费 TPM |
|---|---|---|---|
| Gemini 2.5 Pro | 5 | 100 | 250,000 |
| Gemini 2.5 Flash | 10 | 250 | 250,000 |
| Gemini 2.5 Flash-Lite | 15 | 1,000 | 250,000 |
来源:ai.google.dev/gemini-api/docs/rate-limits,2026-03-17 验证
速率限制是按项目而非按 API Key 执行的。这是一个关键区别,许多开发者在这里栽跟头。在同一个 Google Cloud 项目中创建多个 API Key 并不会给你额外的配额。如果需要更多容量,你需要一个独立项目(但这违反 Google 服务条款,如果是为了规避限制的话)或者升级到付费版。
诊断你触发了哪个限制
当收到 429 错误时,响应消息通常会告诉你具体超过了哪个限制,但并不总是清晰的。以下是系统性识别瓶颈的方法。首先,在 Google Cloud Console 的 APIs & Services > Gemini API > Quotas 中查看你的使用情况。如果 RPM 使用量飙升但 TPM 保持较低,说明你发送了太多小请求,应该合并它们。如果 TPM 飙升但 RPM 适中,说明你的请求包含过多输入数据,应该减少上下文长度或切换到更小的模型。如果 RPD 是限制因素,说明你已经触及每日上限,需要等到太平洋时间午夜重置,或者升级你的套餐。
"幽灵 429" 问题
2026 年初,多位付费 Tier 1 账户的开发者报告说,尽管他们的使用量仪表板显示为零或接近零的消耗,却仍然收到 429 RESOURCE_EXHAUSTED 错误。这种"幽灵 429"现象似乎是 Google 配额追踪系统的一个服务端 Bug。如果你遇到了这个问题,首先确认你的仪表板查看的是正确的项目。然后检查是否有正在运行的 Batch API 任务,因为批处理操作消耗独立的配额,可能不会显示在实时仪表板上。如果都不是,社区的共识是等待 15-30 分钟,因为这个问题通常会自行解决。如果持续超过一个小时,请通过 Google AI Developers Forum 提交工单。你可以在 Google AI Developers Forum 上的这个帖子 中找到相关讨论,多位开发者在其中分享了解决方案。
不升级也能减少 429 错误的实用方法
如果升级到付费版暂时不可行,有几种优化策略可以在免费版上大幅降低 429 错误率。最有效的方法是请求合并,即将多个小请求组合成更少的大请求。由于免费版对 RPM 的限制比 TPM 更严格,在一个请求中发送 10 个问题远比发送 10 个独立请求高效得多。Gemini API 支持在单个请求中进行多轮对话,使这种优化实现起来非常方便。
另一个强大的技术是客户端速率限制,即让你的应用执行比 API 更严格的限制以维持安全余量。如果免费版允许 Gemini 2.5 Flash 10 RPM,就配置你的客户端每分钟最多发送 8 个请求。这个缓冲可以吸收时序波动,防止在突发请求的最后一个请求触发限制的烦人模式。你可以用简单的令牌桶或滑动窗口算法来实现。即使只是在连续请求之间添加 100-300 毫秒的延迟,通常就足以防止突发相关的 429 错误。
对于可以容忍更高延迟的应用,Batch API 提供了一种根本不同的配额管理方式。批处理请求有自己独立的速率限制(100 个并发请求、2GB 输入文件大小限制),并且是异步处理的,这意味着它们不会与你的实时 API 调用竞争配额。Google 明确推荐将 Batch API 用于不需要即时响应的工作负载,如数据处理流水线、内容生成队列和评估任务。这是一个经常被忽视的解决方案,对于适合的使用场景可以完全消除 429 错误。
如需了解专门针对 429 错误的更详细指南(包括高级优化技术),请参阅我们的 429 RESOURCE_EXHAUSTED 详细修复指南。要全面了解所有层级和模型的速率限制,请参阅我们的 各层级完整速率限制详解。
修复 400 和 403 错误(不可重试)
与 429 错误不同,400 和 403 错误表示你的请求或认证存在根本性问题,等待并不能解决。在不做任何改动的情况下重试这些错误毫无意义,只会浪费你的时间和 API 配额。
400 INVALID_ARGUMENT — 你的请求格式有误
带有 INVALID_ARGUMENT 状态的 400 错误意味着 Gemini API 收到了你的请求但无法处理,因为请求体中有些地方不对。最常见的原因包括:发送了不支持的参数值、超过了给定模型的最大输出 Token 限制、传入了无效的 temperature 或 topP 值、或者引用了一个不存在或已弃用的模型名称。
这里有一个让很多开发者中招的具体例子。Gemini 3.x 模型要求 temperature 参数保持其默认值 1.0。将其设置为 0.2 或 0.7(在 Gemini 2.5 模型上完全正常)可能会导致 Gemini 3 模型出现循环或性能下降,并可能触发 400 错误。请务必在 API 参考文档 中查看模型特定的参数约束。修复 400 错误遵循一致的模式:仔细阅读错误消息,将你的请求参数与文档进行对比,并修正不匹配之处。
python# 错误 - Gemini 3 Pro Preview 已于 2026 年 3 月 9 日关闭 model = "gemini-3-pro-preview" # 正确 - 使用当前模型 model = "gemini-2.5-flash" # 常见 400 错误:对模型使用了无效参数 # 错误 - temperature < 1.0 可能导致 Gemini 3.x 出问题 config = {"temperature": 0.3} # 正确 - Gemini 3.x 使用默认 temperature config = {"temperature": 1.0}
400 FAILED_PRECONDITION — 区域或计费限制
这个 400 错误的变体意味着你的账户不满足使用 API 的前提条件。两个最常见的原因是:在未开通计费的情况下从不支持的区域操作,以及尝试使用需要付费版的功能。如果你看到这个错误,请导航到 Google AI Studio 并检查你的项目是否已启用计费。即使你不打算花钱,开通计费通常也能立即解决这个问题,因为它会将你的项目从免费版升级到 Tier 1。
403 PERMISSION_DENIED — 认证和访问问题
403 错误意味着服务器理解了你的请求但拒绝授权。这几乎总是 API Key 的问题。常见原因包括:使用了错误项目的 API Key、使用了已被撤销或泄露的密钥(Google 会主动封禁在公开仓库中检测到的泄露密钥)、Google Cloud 项目中未启用 Generative Language API、或者在没有正确认证的情况下尝试访问微调模型。
如果你在从基于浏览器的应用访问 API 时收到 403 错误,请注意多个 Google 账户登录可能会导致认证冲突。浏览器可能会使用没有 API 访问权限的工作账户凭据进行认证,即使你的个人账户有。解决方法是退出所有 Google 账户,然后仅使用启用了 API 访问的账户重新登录。这是一个出乎意料地常见的问题,在 Google 支持论坛 中有记录。如需更多认证故障排查信息,请参阅我们的 401 认证错误排查指南,其中深入介绍了相关凭据问题。
构建稳健的重试逻辑
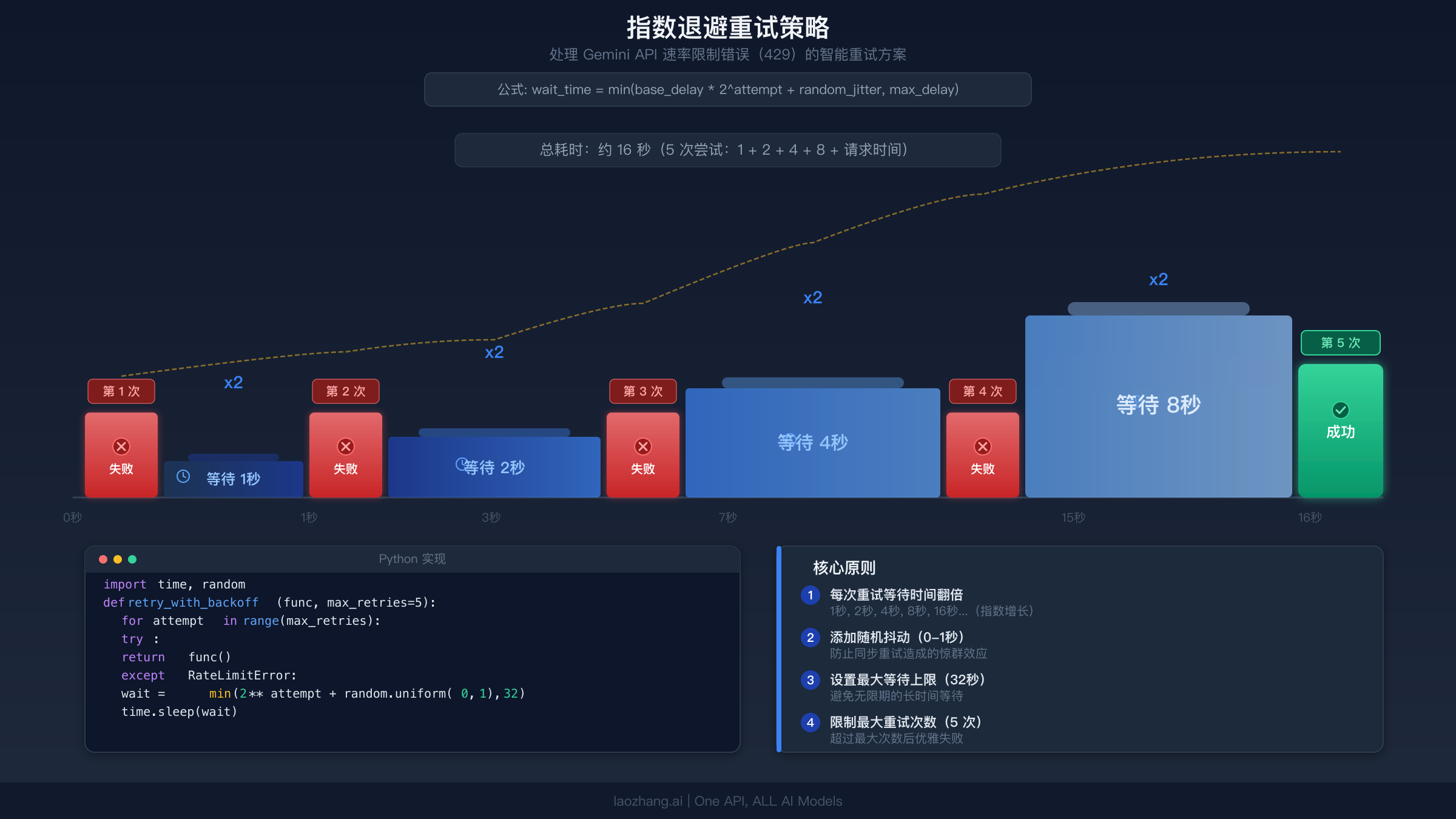
重试逻辑是对抗瞬态错误(429、500、503、504)的第一道防线。核心原则是指数退避:从较短的延迟开始,每次失败后延迟翻倍,并添加一个小的随机抖动以防止所有客户端同时重试。以下是一个生产级的 Python 实现,可以处理所有可重试的 Gemini API 错误。
pythonimport time import random import google.generativeai as genai from google.api_core import exceptions def call_gemini_with_retry( model_name: str, prompt: str, max_retries: int = 5, base_delay: float = 1.0, max_delay: float = 60.0 ): """Call Gemini API with exponential backoff retry logic.""" model = genai.GenerativeModel(model_name) for attempt in range(max_retries): try: response = model.generate_content(prompt) return response except exceptions.ResourceExhausted as e: # 429 - Rate limited delay = min(base_delay * (2 ** attempt), max_delay) jitter = random.uniform(0, delay * 0.1) wait_time = delay + jitter print(f"Rate limited (attempt {attempt + 1}/{max_retries}). " f"Waiting {wait_time:.1f}s...") time.sleep(wait_time) except exceptions.InternalServerError: # 500 - Server error delay = min(base_delay * (2 ** attempt), max_delay) jitter = random.uniform(0, delay * 0.1) print(f"Server error (attempt {attempt + 1}/{max_retries}). " f"Retrying in {delay + jitter:.1f}s...") time.sleep(delay + jitter) except exceptions.ServiceUnavailable: # 503 - Service unavailable wait_time = min(30 * (2 ** attempt), 300) print(f"Service unavailable. Waiting {wait_time}s...") time.sleep(wait_time) except exceptions.InvalidArgument as e: # 400 - Do NOT retry, fix the request raise RuntimeError(f"Invalid request (not retryable): {e}") except exceptions.PermissionDenied as e: # 403 - Do NOT retry, fix credentials raise RuntimeError(f"Permission denied (not retryable): {e}") raise RuntimeError(f"Failed after {max_retries} attempts")
使用官方 Google Generative AI SDK 的 Node.js 版本实现如下。
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); async function callGeminiWithRetry(modelName, prompt, maxRetries = 5) { const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY); const model = genAI.getGenerativeModel({ model: modelName }); for (let attempt = 0; attempt < maxRetries; attempt++) { try { const result = await model.generateContent(prompt); return result.response.text(); } catch (error) { const status = error.status || error.httpStatusCode; // Non-retryable errors — fail immediately if ([400, 403, 404].includes(status)) { throw new Error(`Non-retryable error ${status}: ${error.message}`); } // Retryable errors — wait and retry if ([429, 500, 503, 504].includes(status)) { const delay = Math.min(1000 * Math.pow(2, attempt), 60000); const jitter = Math.random() * delay * 0.1; console.log(`Error ${status}, attempt ${attempt + 1}/${maxRetries}. ` + `Waiting ${((delay + jitter) / 1000).toFixed(1)}s...`); await new Promise(r => setTimeout(r, delay + jitter)); continue; } throw error; // Unknown error, don't retry } } throw new Error(`Failed after ${maxRetries} attempts`); }
许多重试实现容易犯的三个关键错误。 第一,永远不要重试 400 或 403 错误。这些错误表示你的代码或配置有问题,不会随着时间自行解决。重试它们只会浪费配额并延迟你的实际修复。第二,在延迟中添加随机抖动。没有抖动的话,所有在同一时间触发速率限制的客户端会在同一时间重试,造成"惊群效应",触发新一轮的 429 错误。第三,设置最大延迟上限。没有上限的指数退避在多次失败后会产生荒谬的等待时间。对于交互式应用,60 秒通常是合理的上限。
处理 500 和 503 服务端错误
服务端错误(5xx)意味着 Google 基础设施出了问题,不是你的代码的问题。正确的应对几乎总是延迟后重试,但每种错误类型有重要的细微差别会影响你应该如何响应。
500 INTERNAL 错误 可能是真正的瞬态错误,也可能表示你的输入对模型来说太大而无法处理。如果你在同一个请求上持续收到 500 错误而其他请求正常工作,尝试减少输入上下文长度。Gemini API 文档指出,过长的输入上下文是 500 错误的已知触发因素,尤其是支持 100 万 Token 上下文窗口的模型。如果你正在处理大型文档,考虑将其分成较小的块并发送多个请求,而不是一次性发送所有内容。
503 UNAVAILABLE 错误 通常表示 Gemini 服务处于高负载状态。这在高峰使用时段和模型发布期间更常见。当你遇到 503 时,首先应该检查 Google Cloud 状态仪表板 看是否有已知事故。如果有,只能等待。如果状态页面显示所有服务正常,就实现初始延迟更长的重试逻辑,从 30 秒开始而不是 429 错误使用的 1 秒起始延迟。
504 DEADLINE_EXCEEDED 错误 意味着你的请求处理时间超过了服务器允许的超时时间。这最常由非常大的提示词或触发大量模型计算的请求(如使用 Gemini 2.5 Pro 思考模式的复杂推理任务)引起。修复方法通常是增加客户端的超时设置。如果使用 Python SDK,可以传入 timeout 参数。如果发送原始 HTTP 请求,将 HTTP 客户端超时调整到至少 120 秒以应对大型请求。如果增加超时后 504 错误仍然存在,考虑切换到 Batch API,它没有单请求超时限制。
构建错误模式监控面板
理解你长期的错误模式远比调试单个错误更有价值。一个简单的监控设置(记录每个 API 响应的状态码、延迟和 Token 数量)可以揭示单次调试看不到的模式。例如,如果 429 错误集中在一天中的特定时间,你可能在高峰时段与你所在区域的其他用户竞争。如果 500 错误与特定的提示词长度相关,你就找到了上下文窗口的边界问题。
最实用的方法是将 API 响应记录为可查询的结构化格式。在每条日志中包含时间戳、HTTP 状态码、错误消息、模型名称、输入 Token 数和响应延迟。即使是简单的 CSV 文件或 SQLite 数据库也足以发现趋势。许多开发者发现他们的 429 错误来自一个产生意外大量请求的单一功能或端点,修复这一个瓶颈就能消除大部分错误。如果你偏好托管方案,Google Cloud Operations(前身 Stackdriver)可以通过 Cloud Console 自动监控你的 Gemini API 使用情况,但这需要你的项目关联到 Google Cloud 计费账户。
何时升级 — 免费版与付费版对比分析
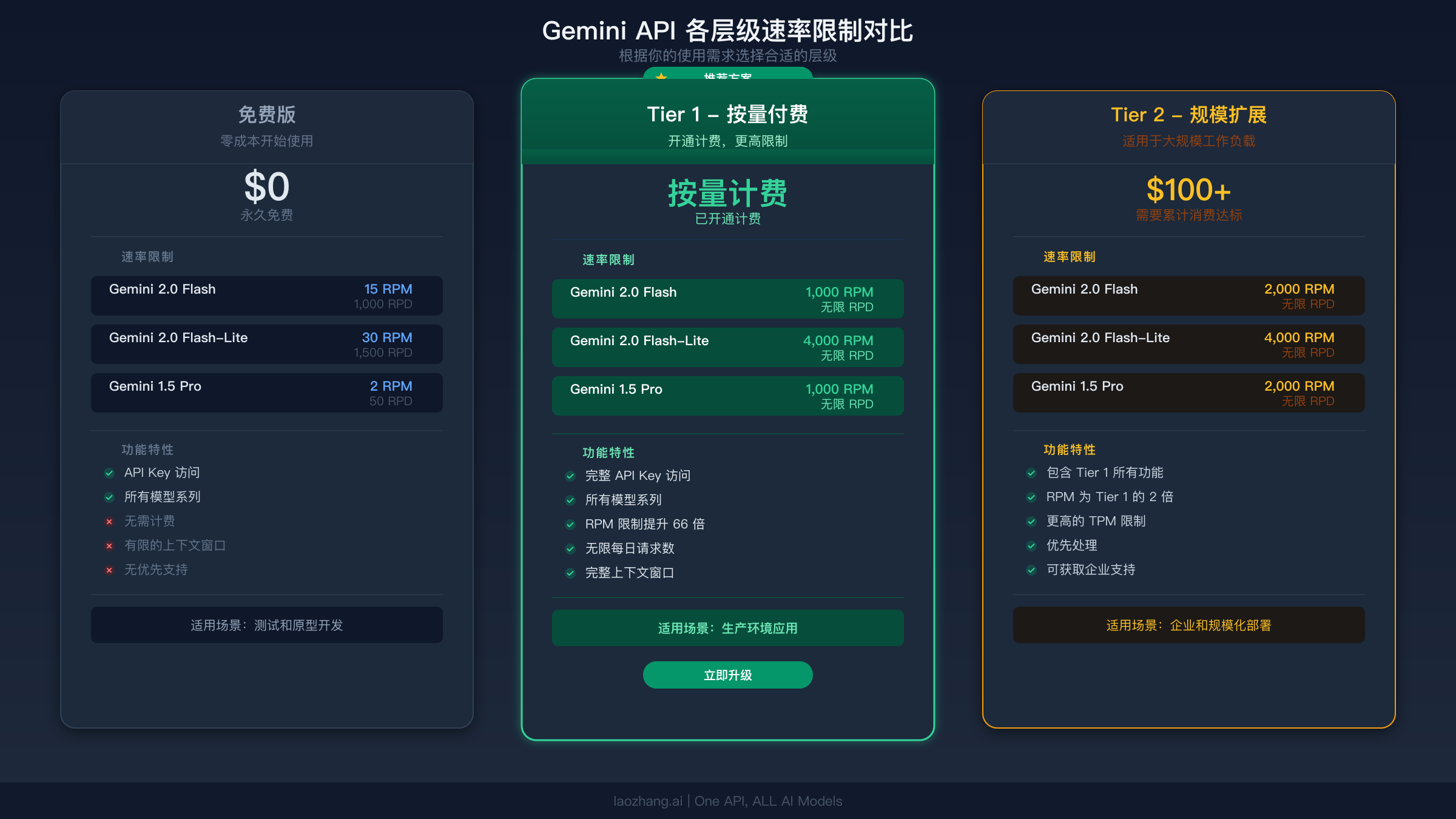
一旦理解了成本结构,从免费版升级到付费版的决定就变得很直接。Gemini API 使用分级系统,随着你的累计消费增长,速率限制会自动提升。以下是截至 2026 年 3 月 17 日根据官方文档验证的各层级详情。
| 层级 | 如何达到 | 核心收益 |
|---|---|---|
| 免费版 | 使用 Google 账户注册 | 有限但足够测试使用 |
| Tier 1 | 开通计费账户 | RPM/RPD 立即提升(通常 10-20 倍) |
| Tier 2 | 累计消费 $100 以上 + 3 天 | 足够支撑生产环境的容量 |
| Tier 3 | 累计消费 $1,000 以上 + 30 天 | 企业级限制 |
来源:ai.google.dev/gemini-api/docs/rate-limits,2026-03-17 验证
从免费版升级到 Tier 1 是你能做的影响最大的改变。 仅仅开通一个计费账户,甚至在花钱之前,就能解锁通常比免费版高 10-20 倍的 Tier 1 限制。升级立即生效。如果你频繁遇到 429 错误,这一步就能解决大多数情况。请注意,从 2026 年 4 月 1 日起,Google 将开始执行层级消费上限,请查阅计费文档了解可能适用于你账户的新限制。
对于即使 Tier 1 限制也不够的生产工作负载,可以考虑使用像 laozhang.ai 这样的统一 API 网关,它能聚合多个提供商的请求,提供更高的速率限制而不受单个提供商的限流。当你的应用需要支持超过任何单一提供商限制的突发流量模式时,这种方式特别有价值。你可以在 docs.laozhang.ai 查看它如何透明地处理跨提供商的速率限制。如需了解所有层级和模型的 Gemini API 完整定价,请参阅我们的 Gemini API 定价和配额指南。你也可以在我们的 免费版速率限制指南 中详细了解免费版的限制。
个人开发者的成本实况。 Gemini 2.5 Flash 是成本敏感应用中最受欢迎的模型,付费版定价为每百万输入 Token $0.30,每百万输出 Token $2.50(ai.google.dev/gemini-api/docs/pricing,2026-03-17 验证)。对于一个每天发送 1,000 个请求、提示词大小适中的典型应用,月费大约在 $5-15 之间,取决于输出长度。对于任何产生实际价值的应用来说,这是一个微不足道的成本,而消除 429 错误带来的可靠性提升完全值得这笔支出。Gemini 2.5 Flash-Lite 变体以每百万输入 Token $0.10 的价格提供了更便宜的选择,适合对最高质量要求不那么严格的应用。
对于需要通过单一端点访问多个 AI 提供商(Gemini、OpenAI、Anthropic 等)的团队构建生产应用,像 laozhang.ai 这样的统一 API 网关可以简化你的基础设施,同时提供内置的速率限制、负载均衡和跨提供商自动故障转移。当你希望在触发某个提供商的速率限制时回退到另一个提供商,而不是简单地对同一个被限流的端点重试时,这特别有用。
2026 年影响错误处理的模型变更
Gemini 模型在 2026 年初发生了重大变化,其中几项直接影响错误处理。如果你遇到了最近才开始出现且你这边没有改动代码的错误,以下模型变更可能就是原因。
Gemini 3 Pro Preview 已于 2026 年 3 月 9 日弃用并关闭。 如果你的代码引用了 gemini-3-pro-preview 或类似的预览模型名称,你将收到 400 INVALID_ARGUMENT 或 404 NOT_FOUND 错误。推荐的迁移路径是使用 gemini-3.1-pro-preview 或 gemini-2.5-pro 作为稳定替代方案。预览模型本身就带有这种风险,生产应用应该始终使用稳定版本的模型。
Gemini 2.0 Flash 已弃用,计划于 2026 年 6 月 1 日关闭。 如果你目前在使用 gemini-2.0-flash 或 gemini-2.0-flash-lite,请在截止日期前规划迁移到 gemini-2.5-flash 或 gemini-2.5-flash-lite。新版模型以相同或更低的成本提供更好的性能,但它们可能有略有不同的参数行为,如果你的配置依赖于特定模型的默认值,可能会触发 400 错误。
Gemini Embedding 2 已发布,是首个完全多模态的嵌入模型。 如果你正在构建 RAG 应用,这个新模型可能会减少嵌入不同内容类型时因输入格式不匹配而产生的错误。当前的模型阵容包括 Gemini 3.1 Pro Preview、3.1 Flash-Lite Preview、3 Flash Preview,以及完整的 Gemini 2.5 系列(Pro、Flash、Flash-Lite)及其 TTS 变体。在生产代码中使用模型名称之前,务必根据 官方模型列表 验证确切的模型名称字符串,因为即使模型名称中的一个小拼写错误也会导致 404 错误。
常见问题 — Gemini API 错误 FAQ
如何修复 Gemini API 429 Too Many Requests 错误?
最快的修复方法是在请求之间添加延迟,即使 100-300 毫秒的延迟通常也足以防止高频突发。要获得更长期的解决方案,请实现指数退避重试逻辑(参见上面重试部分的 Python 和 Node.js 代码示例)。如果你在免费版上频繁遇到 429 错误,通过开通计费升级到 Tier 1 将立即将你的速率限制提升 10-20 倍。
Gemini API 403 PERMISSION_DENIED 错误是什么原因?
403 错误几乎总是 API Key 的问题。最常见的原因是:使用的 API Key 来自与启用了 Gemini API 的项目不同的 Google Cloud 项目、使用了 Google 因检测到在公开仓库中而封禁的密钥、项目中未启用 Generative Language API、或者多个 Google 账户登录时的浏览器认证冲突。在 Google AI Studio 中检查你的密钥,必要时重新生成。
为什么使用量仪表板显示为零我却收到 429 错误?
这是 2026 年初多位开发者报告的"幽灵 429"问题,似乎是 Google 配额追踪的一个服务端 Bug。首先确认你在仪表板中查看的是正确的项目。检查是否有运行中的 Batch API 任务消耗独立配额。如果都不是,等待 15-30 分钟,问题通常会自行解决。如果持续存在,请通过 Google AI Developers Forum 报告。
500 错误是我的问题还是 Google 的?
500 INTERNAL 错误几乎总是 Google 方面的问题,但有一个重要的例外。如果你的输入上下文非常大,接近或超过模型的上下文窗口,服务器可能无法处理并返回 500 错误而不是更具描述性的错误码。首先检查 Google Cloud 状态仪表板 看是否有已知事故。如果服务正常但你在同一个请求上持续收到 500 错误而其他请求正常,尝试减少输入大小。将提示词减半,看错误是否消失。如果消失了,你就找到了边界。对于影响随机请求的偶发 500 错误,简单实现指数退避的重试逻辑即可。Google 的服务器像任何分布式系统一样会经历瞬态故障,大多数 500 错误在几秒内就会解决。
503 UNAVAILABLE 和 504 DEADLINE_EXCEEDED 有什么区别?
503 错误意味着 Gemini 服务暂时过载,现在无法接受你的请求。这是 Google 方面的容量问题,类似于打电话时听到忙音。通常在几分钟内解决,在高峰使用时段或 Google 宣布新模型功能后最为常见。另一方面,504 错误意味着服务器接受了你的请求并开始处理,但无法在分配的时间内完成。这通常由非常大的提示词或复杂的推理任务引起,尤其是使用 Gemini 2.5 Pro 思考模式时。对于 503,等待 30-60 秒后重试。对于 504,将客户端超时设置增加到至少 120 秒以应对大型请求,或考虑将输入拆分成较小的块。
如何防止 API 错误影响到我的用户?
最佳策略是纵深防御。第一,为所有可重试的错误实现指数退避重试逻辑,使瞬态故障对用户不可见。第二,添加断路器模式,在连续多次失败后停止发送请求,防止级联错误。第三,配置降级行为,例如在主要模型不可用时返回缓存响应或切换到不同的模型。第四,设置监控和告警,在用户抱怨之前就知道错误激增。即使是一封简单的每日邮件(按状态码显示错误率)也能及早发现问题。对于生产应用,考虑通过多个提供商维护 API 访问,这样一个提供商的速率限制或中断不会导致整个应用瘫痪。
频繁触发 429 错误会被 Gemini API 封禁吗?
Google 不会仅仅因为触发速率限制就封禁账户,因为 429 错误是正常 API 使用的预期部分。但是,Google 确实会主动封禁在公开仓库中检测到的 API Key,因为这代表安全风险。如果你的 API Key 出现在公开的 GitHub 仓库中,Google 会封禁它,你会收到一条具体的错误消息说明你的密钥被报告为泄露。解决方法是通过 Google AI Studio 生成新的 API Key,并确保使用环境变量安全存储,而不是硬编码在源代码中。此外,创建多个 Google Cloud 项目来规避速率限制违反了 Google 的服务条款,可能导致账户级别的限制。