选择合适的 AI API 提供商已经不再只是一个技术决策。OpenAI 的 GPT-5.4 以每百万输入 token $2.50 的价格发布,Google 的 Gemini 3.1 Pro 以 $2.00 提供相当的智能水平,而 Anthropic 的 Claude Opus 4.6 凭借推理深度以 $5.00 的溢价占据高端市场——然而每 token 的价格只是故事的一部分。真正决定你月度账单的,是模型选择、工作负载特征和优化策略的组合,而大多数对比指南完全忽略了这些因素。本指南提供截至2026年3月的最新验证定价数据,为三种业务场景计算真实月度成本,并提供一套可将 API 支出削减60-80%的具体优化方案。
要点速览
Google Gemini 提供从 $0.10/MTok(Flash-Lite)到 $2.00/MTok(3.1 Pro)最宽的价格区间,使其成为最具成本灵活性的平台,并拥有慷慨的免费额度。OpenAI 的 GPT-5.4 定价为 $2.50/$15.00,拥有最成熟的生态系统,缓存输入定价约便宜十倍。Claude 采用高端定价(Sonnet 4.6 为 $3.00/$15.00,Opus 4.6 为 $5.00/$25.00),但提供卓越的推理质量和90%的缓存命中折扣。对于大多数生产工作负载,将模型分层与批处理和提示缓存结合使用,无论你选择哪个提供商,都可以将成本降低60-80%。
API 完整定价明细(2026年3月)
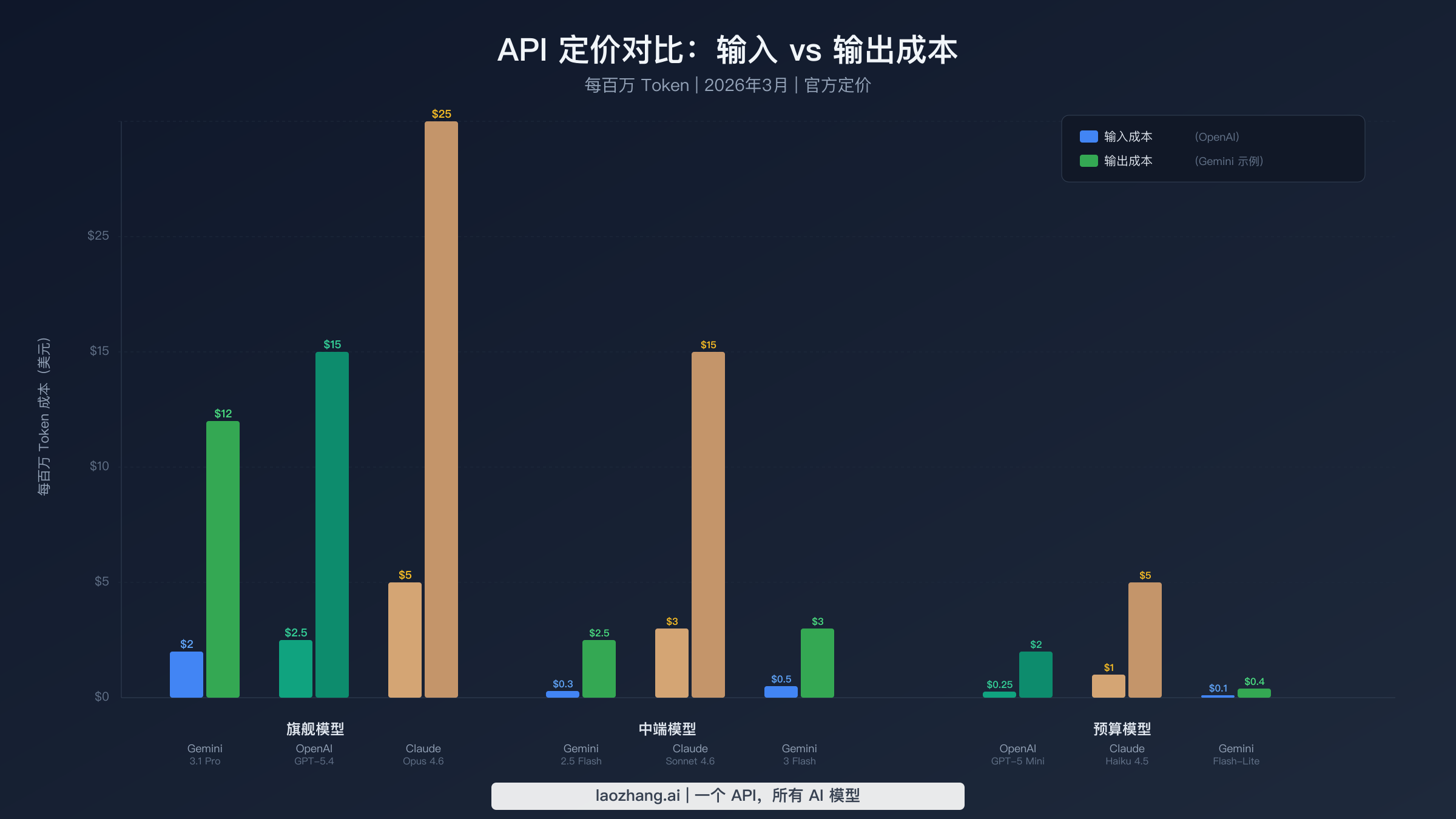
要全面了解定价格局,需要超越旗舰模型来审视。每个提供商都提供分层产品线,针对不同的质量-成本权衡而设计,其最便宜和最昂贵模型之间的价差通常超过50倍。以下数据均于2026年3月17日在官方定价页面验证,每个数据点都标注了来源。
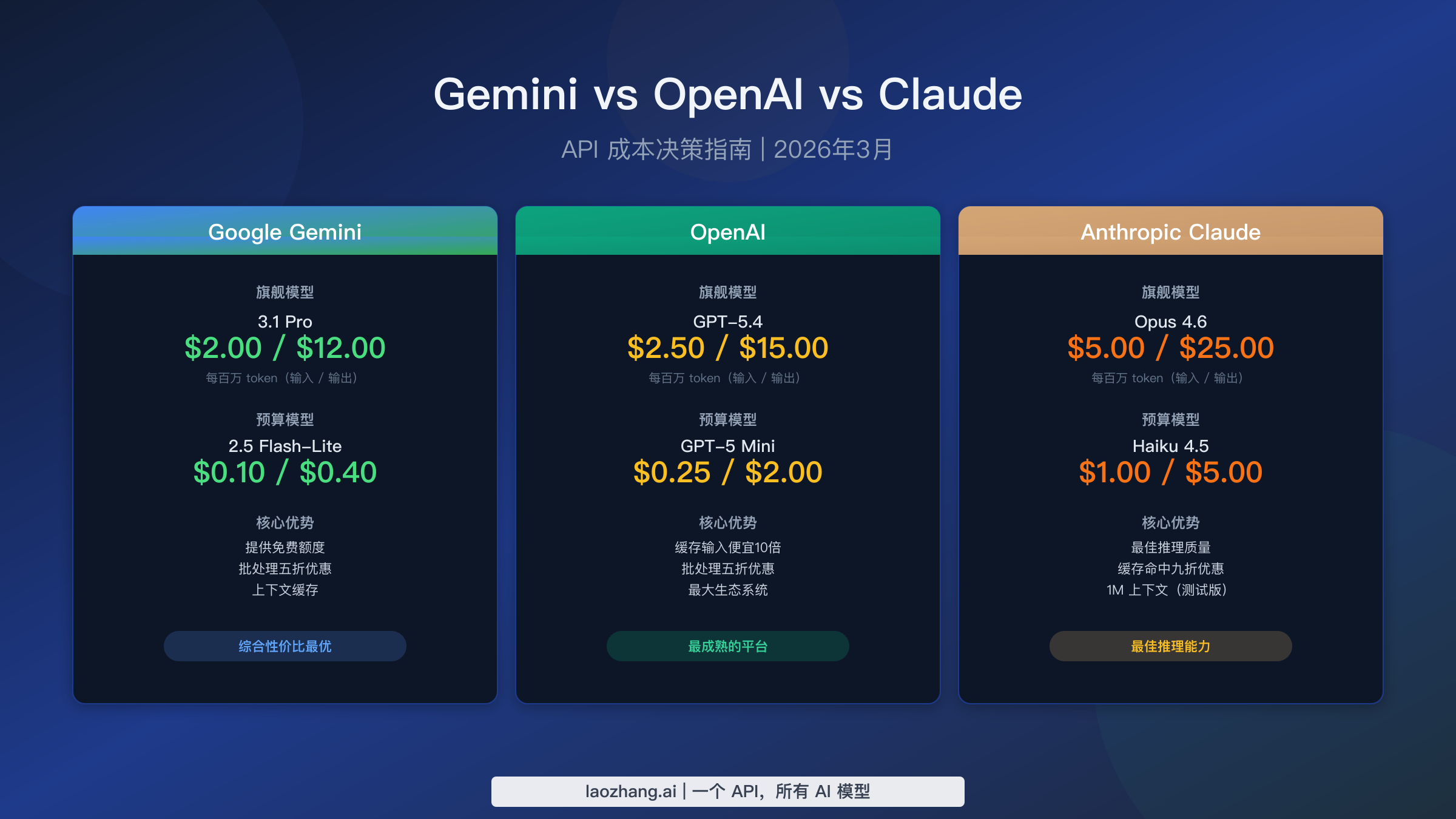
Google Gemini 拥有价格差异极大的最广泛模型系列。最近发布的 Gemini 3.1 Pro Preview 对200,000 token 以下的提示收取每百万输入 token $2.00、每百万输出 token $12.00 的费用,对更长上下文则升至 $4.00 和 $18.00(ai.google.dev,2026年3月)。在预算端,Gemini 2.5 Flash-Lite 仅以 $0.10 输入和 $0.40 输出每百万 token 提供生产级性能,比旗舰模型便宜约20倍。Gemini 3 Flash Preview 位于中间层,定价 $0.50/$3.00,以旗舰价格的一小部分提供强大的推理能力。最重要的是,Gemini 提供了覆盖大多数模型的真正实用的免费额度,使其成为唯一一个可以零成本进行原型开发和运行小规模应用的主要提供商。对于想要探索完整 Gemini API 定价选项的开发者,分层结构意味着几乎总有一个模型能满足任何预算约束。
| 模型 | 输入 ($/1M) | 输出 ($/1M) | 批量输入 | 批量输出 | 上下文 |
|---|---|---|---|---|---|
| Gemini 3.1 Pro | $2.00 / $4.00 | $12.00 / $18.00 | $1.00 / $2.00 | $6.00 / $9.00 | 1M |
| Gemini 3 Flash | $0.50 | $3.00 | $0.25 | $1.50 | 1M |
| Gemini 2.5 Pro | $1.25 / $2.50 | $10.00 / $15.00 | $0.625 / $1.25 | $5.00 / $7.50 | 1M |
| Gemini 2.5 Flash | $0.30 | $2.50 | $0.15 | $1.25 | 1M |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | $0.05 | $0.20 | 1M |
OpenAI 将 GPT-5.4 定位为当前旗舰,标准上下文使用的定价为每百万输入 token $2.50、每百万输出 token $15.00。一个重要的定价创新是短上下文与长上下文的价格分层:GPT-5.4 超过272,000 token 的提示会产生2倍输入和1.5倍输出的溢价($5.00/$22.50),这对 RAG 和文档分析工作负载的成本影响很大。GPT-5 Mini 仍然是首选的预算方案,定价 $0.25/$2.00,以极低的成本提供 GPT-4 级别的质量。OpenAI 的缓存输入定价是其最大的成本优势,通常可将重复系统提示的输入成本降低约90%,而 Batch API 为所有非实时处理提供统一的50%折扣。
| 模型 | 输入 ($/1M) | 输出 ($/1M) | 缓存输入 | 批量折扣 | 上下文 |
|---|---|---|---|---|---|
| GPT-5.4(短上下文) | $2.50 | $15.00 | $0.25 | 50% | 1.05M |
| GPT-5.4(长 >272K) | $5.00 | $22.50 | $0.50 | 50% | 1.05M |
| GPT-5 | $1.25 | $10.00 | $0.125 | 50% | 128K |
| GPT-5 Mini | $0.25 | $2.00 | $0.025 | 50% | 128K |
Anthropic Claude 占据高端层级,其定价反映了该平台对推理深度和安全性的重视。旗舰模型 Claude Opus 4.6 的输入成本为 $5.00、输出为 $25.00 每百万 token,使其成为三家提供商中最昂贵的选择,但在推理基准测试中始终排名最高。Claude Sonnet 4.6 定价 $3.00/$15.00,以强大的编程和分析能力提供了极具吸引力的中间方案,而 Haiku 4.5 以 $1.00/$5.00 提供入门选择。Claude 的提示缓存功能提供了显著的节省,缓存命中价格仅为标准输入成本的10%。正如我们在 Claude API 定价详解中所介绍的,关键的成本驱动因素是 Claude 详细回复所产生的大量输出 token。
| 模型 | 输入 ($/1M) | 输出 ($/1M) | 缓存命中 | 缓存写入 | 上下文 |
|---|---|---|---|---|---|
| Opus 4.6 | $5.00 | $25.00 | $0.50 | $6.25 | 200K |
| Sonnet 4.6(≤200K) | $3.00 | $15.00 | $0.30 | $3.75 | 200K-1M |
| Haiku 4.5 | $1.00 | $5.00 | $0.10 | $1.25 | 200K |
真实月度成本场景分析
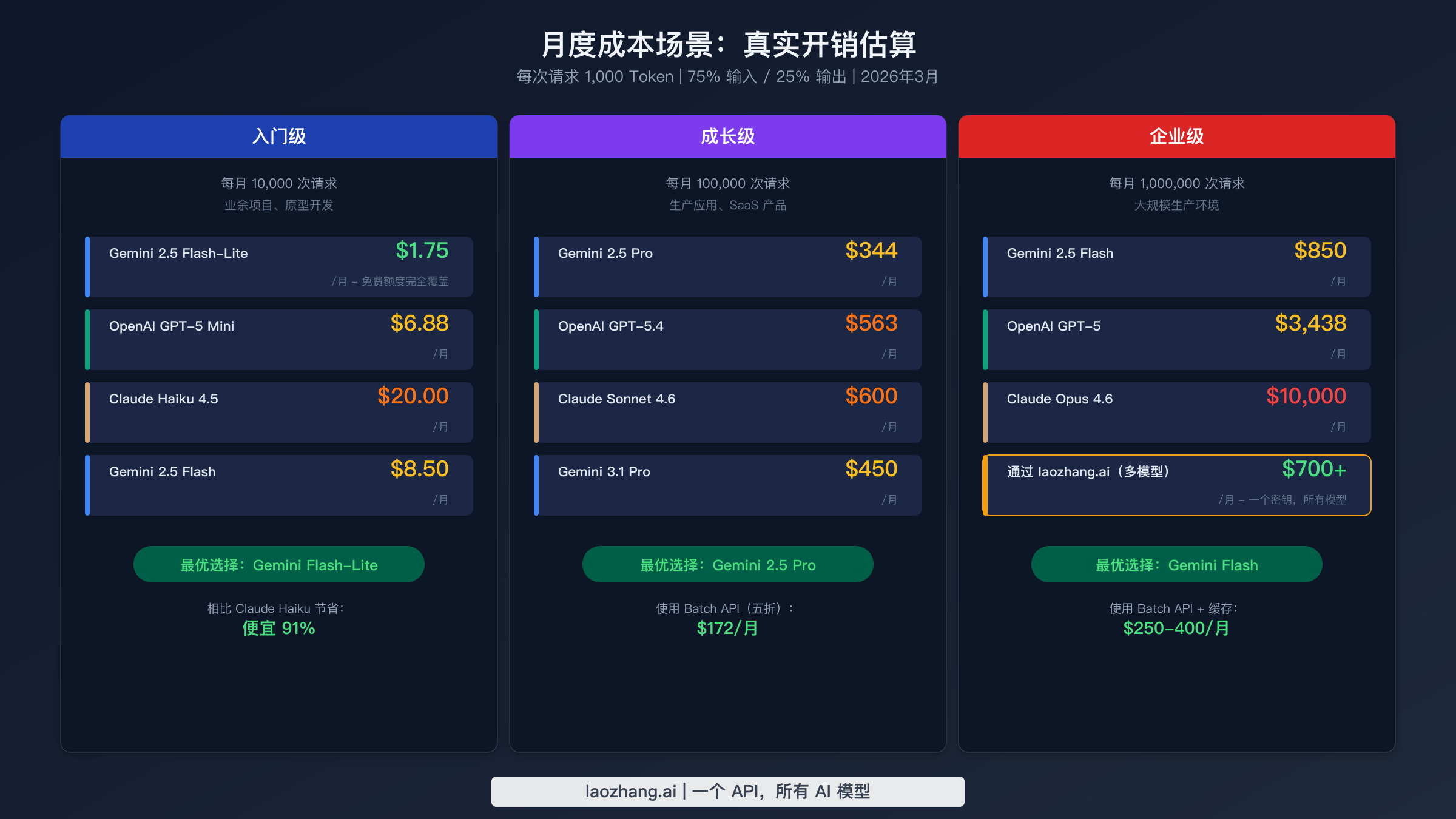
每 token 的价格只有转化为实际月度账单时才有意义。以下场景假设每次请求1,000个 token,输入输出比为75/25,这代表了典型的对话或分析类工作负载。这些计算使用标准定价,未计入优化折扣,提供了一个基准线——通过本指南后面介绍的策略可以大幅降低。
入门级(每月10,000次请求)代表个人开发者、业余项目和早期原型。在此规模下,Gemini 2.5 Flash-Lite 每月约 $1.75,而免费额度实际上完全覆盖了这个用量。OpenAI GPT-5 Mini 约 $6.88,而 Claude Haiku 4.5 约 $20.00。此规模下的绝对成本差异相对较小,这意味着你应该优先考虑模型质量和开发者体验,而非纯粹的价格。如果你的项目刚起步,Gemini 的免费额度是无可匹敌的起点,而且你可以在需求增长时轻松升级到付费模型,无需更换提供商。
成长级(每月100,000次请求)是定价决策开始产生重大影响的阶段。一个每月处理10万次请求的生产应用使用旗舰模型时,会呈现出明显的成本差距。Gemini 2.5 Pro 每月约 $344,GPT-5.4 约 $563,Claude Sonnet 4.6 达到 $600。这些数字基于标准定价,但实际上大多数生产应用都应该使用批处理和缓存,这可以将这些数字大致减半。在这个级别,提供商之间的选择往往取决于你的具体用例需要 Gemini 的成本与质量平衡、OpenAI 的生态成熟度,还是 Claude 的推理深度。
企业级(每月1,000,000次请求)将每一个定价差异放大为数千美元。通过 Gemini 2.5 Flash 运行100万次请求每月约 $850,GPT-5 约 $3,438,而 Claude Opus 4.6 在标准费率下达到每月 $10,000。在此规模下,模型分层变得至关重要。一个设计良好的系统将70%的简单查询路由到 Flash-Lite($175),25%路由到中端模型($860),仅5%路由到高端模型($500),总计约 $1,535 即可处理相同的工作负载,根据所选的高端模型不同,可节省55-85%。
改变成本格局的隐藏费用
官方定价页面上显示的每 token 价格讲述的是一个不完整的故事。多个成本乘数隐藏在文档深处,或只有在大量使用后才会显现,不计入这些因素可能导致30-100%的预算超支。了解这些隐藏成本对于准确的财务规划至关重要。
思维 token 是推理密集型工作负载中最大的隐藏成本。Gemini 2.5 Pro 和 Claude Sonnet 4.6 都会生成计入输出定价但不会出现在最终回复中的内部推理 token。一个产生500个可见回复 token 的请求,在包含思维过程后实际可能消耗2,000-5,000个输出 token,对于复杂推理任务,这实际上将你的输出成本乘以4-10倍。Gemini 的定价页面明确说明输出定价包含思维 token,Claude 的扩展思维功能也是类似机制。在为严重依赖推理的应用(如代码生成、数学分析或多步规划)编制预算时,应始终将预估的输出量至少乘以3倍来考虑思维开销。
长上下文溢价适用于 Gemini 和 OpenAI 提示超过特定阈值时的情况。Gemini 2.5 Pro 和 3.1 Pro 在提示超过200,000 token 时收取2倍输入和1.5倍输出的费用。OpenAI GPT-5.4 在超过272,000 token 后适用类似的2倍/1.5倍乘数。对于经常处理长上下文的 RAG 应用和文档分析工作流,这可能使你的有效每 token 成本翻倍。相比之下,Claude 在其200K标准窗口范围内保持统一定价,不受上下文长度影响,使其成为长上下文工作负载中最可预测的选择。
搜索落地费用为 Gemini 用户增加了另一层成本。Gemini 3.x 模型在使用 Google Search 落地功能时,每1,000次搜索查询收取 $14(前5,000次免费月度提示之后)。对于每次回复都需要网络搜索结果落地的应用,这在 token 成本之外每千次请求增加 $14。OpenAI 和 Claude 目前不在 API 层面提供集成搜索落地功能,因此这个成本是 Gemini 独有的,但同时也代表了其他提供商无法匹配的一项能力。
哪个提供商最适合你的用例

与其宣布单一的赢家,最优选择完全取决于你的工作负载特征。每个提供商在特定领域都有明确的优势,以下建议基于定价分析和生产部署中的实际性能观察。
面向客户的聊天机器人和客服自动化优先考虑速度、成本效率以及对话交互的足够质量。Gemini 2.5 Flash-Lite 定价 $0.10/$0.40 每百万 token,为高流量对话应用提供了最佳经济性,特别是结合免费额度进行开发和测试时。对于需要更高质量回复的应用,Gemini 2.5 Flash 定价 $0.30/$2.50,以仍然可负担的价格提供出色的推理能力。免费额度的可用性意味着你可以在投入任何预算之前验证你的聊天机器人架构。
RAG 和知识库应用需要精确检索、忠实摘要,通常涉及处理长文档上下文。Gemini 2.5 Pro 定价 $1.25/$10.00,提供了1M token 上下文窗口和标准长度提示合理定价的最佳组合,但超过200K token 的2倍溢价应纳入成本预估。Claude Sonnet 4.6 在 RAG 任务中的忠实度和指令遵循方面表现出色,但定价更高为 $3.00/$15.00。对于预算敏感的 RAG 部署,将检索增强查询路由到 Gemini,仅将最复杂的检索上下文综合保留给 Claude,可以构建一个有效的混合方案。
代码生成和开发工具最受益于强大的推理和指令遵循能力。Claude Opus 4.6 与 GPT-5 的对比表明,Claude 在代码生成质量基准测试中始终领先。Claude Sonnet 4.6 定价 $3.00/$15.00,提供了编码能力与成本的最佳平衡点,使其成为开发工具公司中最受欢迎的选择。如果预算是主要约束,Gemini 3 Flash Preview 定价 $0.50/$3.00,以六分之一的价格提供了令人惊讶的强大代码生成能力。
智能体工作流和多步推理需要模型在扩展交互链中保持上下文、有效规划和可靠使用工具。Claude Opus 4.6 尽管定价高端为 $5.00/$25.00,但凭借其卓越的指令遵循和规划能力,仍然是智能体应用的黄金标准。思维 token 的开销使智能体工作负载特别昂贵,但对于关键任务自动化工作流,成本溢价因显著更高的任务完成率而得到合理证明。
批处理和离线分析应始终利用批处理 API 获得直接的50%成本降低。Gemini 的批量定价将 Gemini 2.5 Flash 降至 $0.15/$1.25,使大规模文档处理变得非常经济。OpenAI 的 Batch API 对所有模型适用相同的50%折扣,结果在24小时内返回。
真正有效的成本优化策略
从理解定价到主动降低成本,需要实施具体的策略。以下方法按影响力和实施难度排序,附有展示预期节省的具体计算。
模型分层为大多数应用带来最大的即时节省,只需要路由逻辑的更改。原理很简单:将请求路由到能够处理每个特定任务的最便宜模型。一个设计良好的分层系统将70%的简单查询发送到预算模型(Flash-Lite $0.10/$0.40 或 GPT-5 Mini $0.25/$2.00),25%的中等复杂度任务发送到中端模型(Gemini 2.5 Flash $0.30/$2.50 或 Claude Sonnet $3.00/$15.00),仅5%的真正复杂推理任务发送到高端模型(Opus $5.00/$25.00 或 GPT-5.4 $2.50/$15.00)。对于仅使用 Claude Sonnet 时成本为 $600 的10万次请求工作负载,分层可将账单降至约 $160,节省73%。
Batch API 处理为任何不需要实时响应的请求提供有保证的50%输入输出 token 折扣。三家提供商现在都提供批处理:Gemini 在每个模型上都明确显示批量定价,OpenAI 提供统一的50%折扣和24小时 SLA,Claude 提供类似的批处理能力。对于数据处理管道、内容分析和定时生成任务,几乎没有理由不使用批量定价。如果40%的工作负载可以容忍延迟处理,仅批处理 API 就可以将总账单削减20%。
提示缓存从根本上改变了具有重复系统提示的应用的经济模型。Claude 的提示缓存系统将缓存命中的输入成本降低到标准定价的仅10%,而 Gemini 的上下文缓存提供类似的降幅,并附带额外的基于存储的定价。如果你的应用在所有请求中使用4,000 token 的系统提示,缓存该提示可以在这些输入 token 上节省约90%。对于10万次请求的应用,这意味着每月约 $300-500 的节省,具体取决于所用模型。
API 聚合平台如 laozhang.ai 为希望使用多个提供商而无需管理单独 API 密钥、计费账户和集成代码的团队提供了务实的解决方案。这些平台提供单一的 OpenAI 兼容 API 端点,可将请求路由到 Gemini、OpenAI 或 Claude 的任何模型,定价通常与直接提供商费率持平或更低。除了定价之外,运营上的优势也很显著:一个 API 密钥即可即时访问每个模型,你可以在不更改代码的情况下切换提供商。对于评估多个模型或运行混合架构的团队,减少的集成开销和供应商灵活性通常足以证明聚合方案的合理性。
做出决策:实用的下一步行动
大量的定价数据和优化策略可能让人感到不知所措,但当你聚焦于自己的核心约束时,决策框架实际上非常简明。
如果成本是你的首要约束,从 Gemini 开始。免费额度让你无需任何支出就能验证应用,从 Flash-Lite($0.10/$0.40)到 Flash($0.30/$2.50)再到 Pro($1.25/$10.00)的渐进路径提供了随质量需求增长的自然升级方案。Gemini 还提供了最激进的批量定价,将本已实惠的模型降至极低的每 token 成本。
如果质量和推理能力至关重要,投资 Claude。Sonnet 4.6 为要求准确、细致和深度推理输出的应用提供了最佳的质量成本比。提示缓存系统使重复交互显著降低成本,1M 扩展上下文测试版为长文档分析开辟了其他提供商在类似质量水平上无法匹配的可能性。每月 $20 的 Pro 订阅还包含用于原型开发的慷慨用量。
如果生态系统和工具链最重要,OpenAI 仍然是最安全的选择。最广泛的第三方集成支持、最成熟的 SDK 生态系统和最大的开发者社区意味着更快的开发速度。缓存输入定价(便宜10倍)和 Batch API(打五折)提供了强大的成本优化杠杆,GPT-5.4 定价 $2.50/$15.00 与 Gemini 的旗舰产品具有竞争力。
对于构建需要灵活性的生产应用的团队,探索像 laozhang.ai 这样的 API 聚合平台可以通过单一集成点测试所有三个提供商。凭借与直接提供商费率持平的定价和即时模型切换功能,它消除了过早承诺单一提供商所带来的供应商锁定风险。你可以在 docs.laozhang.ai 以仅 $5 起的充值额度开始使用。
常见问题解答
2026年哪个 AI API 最便宜?
截至2026年3月,Google Gemini 2.5 Flash-Lite 以每百万 token $0.10 输入和 $0.40 输出成为主要提供商中最便宜的生产级 API。结合批处理 API(50%折扣)后,价格降至 $0.05/$0.20,免费额度还能以零成本覆盖小规模用量。OpenAI 最便宜的选择是 GPT-5 Mini,定价 $0.25/$2.00,而 Claude Haiku 4.5 以 $1.00/$5.00 成为 Anthropic 最实惠的模型。
每月运行100,000次 API 请求要花多少钱?
10万次请求(假设每次1,000个 token,75/25输入输出比)的月度成本从 Gemini Flash-Lite 的约 $18 到 Claude Opus 4.6 的 $1,000 不等。最受欢迎的中端选项成本分别为 $344(Gemini 2.5 Pro)、$563(GPT-5.4)和 $600(Claude Sonnet 4.6)。应用批处理 API 和缓存优化通常可将这些数字降低40-60%。
思维 token 会影响 API 成本吗?
是的,影响显著。Gemini 2.5 Pro 和 Claude 的模型都会生成按输出 token 费率计费但不会出现在可见回复中的内部推理 token。对于推理密集型任务,思维 token 可以将你的有效输出成本乘以3-10倍。应始终通过提供商的用量仪表板监控实际 token 消耗,而不是仅根据回复长度进行估算。
从 OpenAI 切换到 Gemini 值得吗?
对于成本敏感的工作负载,切换到 Gemini 可以根据你当前的模型使用情况将 API 成本降低30-70%。权衡在于 Gemini 的模型质量虽然在快速提升,但在特定用例上可能与 OpenAI 有所不同。一个实用的方法是将成本敏感的批量操作路由到 Gemini,同时将质量关键的流程保留在当前提供商上。API 聚合平台使这种混合方案的实施变得简单直接。
如何将 AI API 成本降低50%或更多?
三种策略组合使用通常可实现60-80%的成本降低:(1)模型分层将70%的请求路由到预算模型,节省40-60%。(2)Batch API 处理为非实时工作负载提供统一的50%折扣。(3)提示缓存将重复输入成本降低75-90%。建议从模型分层开始,因为它不需要 API 更改,只需要路由逻辑。