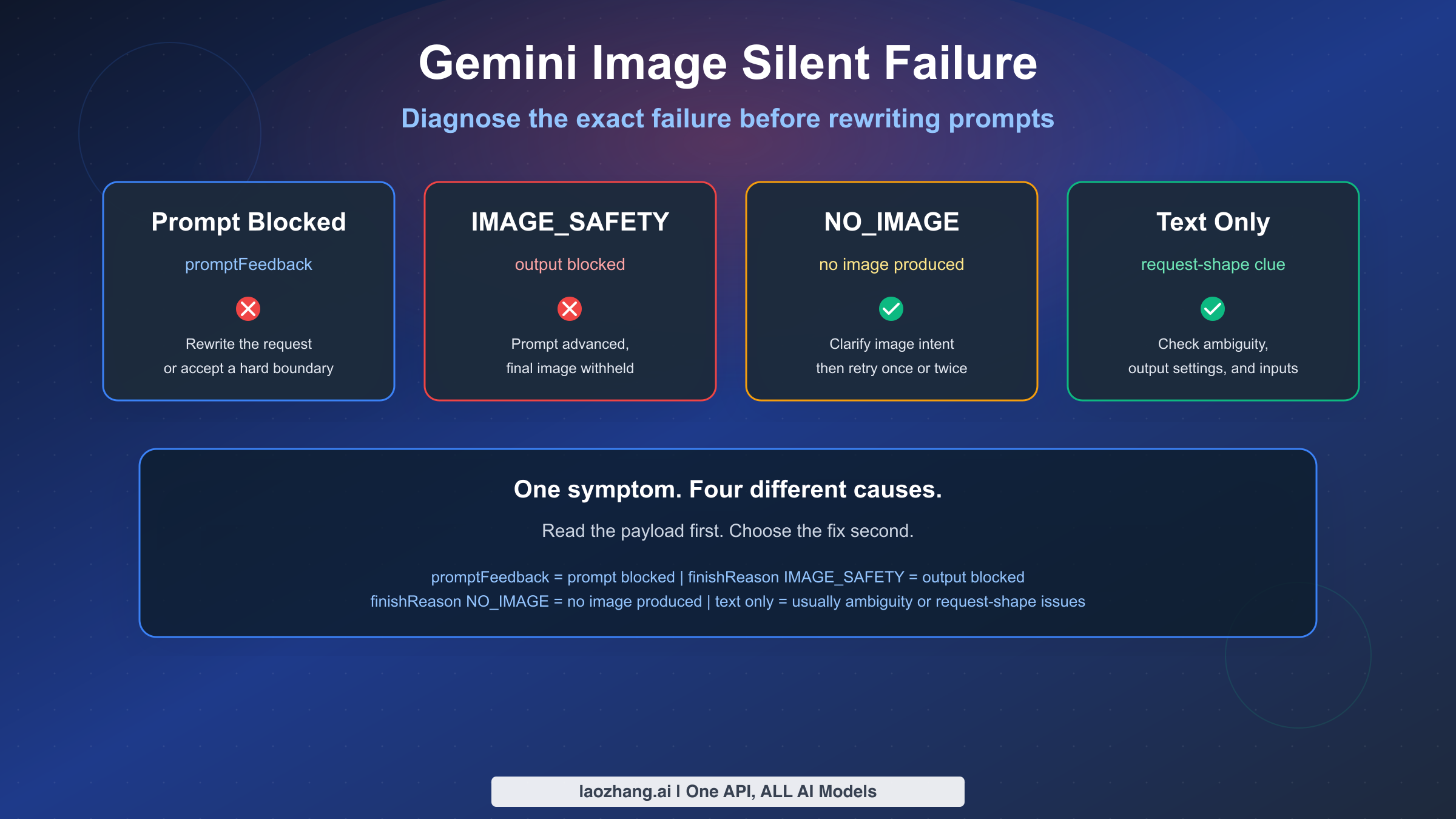
如果 Gemini 图片生成似乎静默失败,最重要的一点是:所谓"静默失败"通常并非单一问题。截至 2026 年 3 月 15 日,Google 官方文档明确区分了用户常常混为一谈的至少四种不同状态:提示词侧拦截、输出侧图片拦截、完全未生成图片,以及提示词模糊或请求格式错误等非政策类故障。如果把这四种情况都当作"Gemini 内容政策出问题了"来处理,你会一直在用错误的方法解决问题。
简单来说:当输入提示词被拦截时,promptFeedback 字段会有内容,且不会返回 candidates。当提示词被接受但生成的图片被拦截时,Google 说明 candidates 存在,content 缺失,finishReason 会告知响应被中止的原因。finishReason 为 IMAGE_SAFETY 与 NO_IMAGE 是两回事,这两者又与带有 STOP 的纯文字拒绝不同。这些区别至关重要,因为每种情况都指向不同的下一步操作。
本指南聚焦于用户搜索"Gemini 图片静默失败"、"IMAGE_SAFETY 修复"和"Gemini 图片内容政策"等关键词时所面临的具体场景。内容基于当前 Google 官方文档,而非关于 Gemini 人物生成争议的过时 2024 年资料。同时引用了 2025 年 11 月和 12 月 Google AI 开发者论坛的近期帖子,展示真实场景中用户仍然困惑的地方——尤其是当 AI Studio 或 Gemini API 在提示词看起来安全的情况下仍返回无图片时。
如果你面临的是跨模型提示词拒绝问题,而不仅限于 Gemini 图片输出,我们的提示词被拦截安全警告指南从政策层面涵盖了 ChatGPT、Gemini、Claude 和 Azure。本文更聚焦于技术层面:在重写提示词、放宽过滤器或认为平台故障之前,先正确诊断 Gemini 图片失败的原因。
要点速览
- 在修改提示词之前先检查响应结构。
promptFeedback表示提示词在图片生成完成之前就被拦截了。 - 如果
candidates存在但content缺失,且finishReason为IMAGE_SAFETY,说明图片输出在生成开始后被过滤。 - 如果
finishReason为NO_IMAGE,Gemini 接受了请求但没有生成图片。通常需要更明确的图片指令、重试,或排查请求格式问题。 - 纯文字回复不一定是政策故障。Google 当前图片生成限制页面明确说明,模糊的提示词可能只返回文字而无图片。
- 可配置的安全设置无法禁用所有保护。Google 安全设置文档说明,针对核心危害的内置保护始终有效且无法关闭。
- 不要将 404、429 和 503 错误当作内容政策问题处理。如果遇到这些错误,请参考我们的 Gemini 3 Pro Image 错误码指南。
| 快速诊断 | 首先检查 | 含义 |
|---|---|---|
| 提示词被拦截 | promptFeedback.blockReason | 请求在返回可用图片候选结果之前被过滤 |
| 输出被拦截 | candidates[0].finishReason = IMAGE_SAFETY 且 content 缺失 | 提示词通过,但最终图片被扣留 |
| 未生成图片 | finishReason = NO_IMAGE | Gemini 接受了请求但未生成图片输出 |
| 纯文字响应 | 有文字部分但无图片部分 | 通常是提示词模糊、输出设置问题或请求格式问题 |
如何判断 Gemini 是拦截了提示词、过滤了图片还是没有生成

大多数调试时间的浪费都源于跳过分类步骤。人们看到"无图片",就假设是"内容政策",然后花 20 分钟重写一个根本不是问题所在的提示词。Google 的被拦截响应文档给出了更好的工作流:先检查响应的结构,再决定采用哪种修复方案。
最快的判断方式如下:
| 你看到的现象 | 典型 API 信号 | 通常含义 | 首要修复 |
|---|---|---|---|
| 请求在返回任何可用候选结果前失败 | promptFeedback.blockReason 存在且 candidates 缺失 | 图片输出返回前的提示词侧拦截 | 重写提示词,如适当则添加安全上下文,或接受请求触及了禁止边界 |
| 返回文字拒绝而非图片 | candidates[0].finishReason = STOP 且响应包含文字而非图片数据 | 模型拒绝或安全重定向了请求 | 阅读文字内容,删除敏感视觉意图,或将任务拆分为更安全的步骤 |
无图片数据且出现 IMAGE_SAFETY | candidates 存在,content 缺失,finishReason = IMAGE_SAFETY | 提示词被接受,但输出图片被过滤 | 减少敏感视觉细节,明确表达无害意图,不要认为安全设置可以覆盖一切 |
无图片数据且出现 NO_IMAGE | finishReason = NO_IMAGE | Gemini 实际上未生成图片 | 明确要求生成图片,减少歧义,重试一两次,检查请求格式 |
| 纯文字回复但无明显政策标记 | 响应包含文字但无 inlineData 图片部分 | 通常是提示词模糊、图片输出设置缺失或传输问题 | 明确请求图片输出并验证请求配置 |
| 404、429 或 503 | HTTP 错误而非图片候选结果 | 模型路由、配额或过载问题,而非内容政策 | 使用正确的运营指南,而非修改提示词 |
Google 当前的 Vertex AI 文档对提示词拦截和响应拦截做了清晰区分。如果提示词本身被拦截,promptFeedback 会有内容,且没有候选结果可检查。如果响应被拦截,promptFeedback 为空,candidates 存在,缺失的 content 加上 finishReason 会告诉你发生了什么。这就是为什么"无法生成图片"这样的界面提示信息太粗略,无法用来诊断问题。API 响应载荷通常比产品文案更有信息价值。
这也解释了为什么一些用户将问题称为"静默"失败。载荷本身可能并不静默,但用户使用的界面可能仍然感觉像静默失败。在 AI Studio、Gemini 应用或薄集成层中,产品可能只显示通用错误或根本不显示图片区域。如果能通过 API 或 Vertex 重现请求并检查完整响应,通常就能知道系统是拦截了提示词、拦截了图片,还是压根没有生成图片。
如果你只有 AI Studio 或应用的症状而没有原始载荷,在升级问题前可以使用以下快速回退步骤:
- 开启新会话,明确要求"生成一张……的图片",而不是发送简短的名词短语。
- 尝试一个简单无害的测试提示词,例如"生成一张木桌上红色陶瓷马克杯的图片"。
- 如果无害测试成功,原始提示词或之前的对话上下文很可能是问题所在。
- 如果无害测试也失败,检查相同请求通过 API 或 Vertex 是否有效,或者将问题作为更广泛的产品界面问题而非纯提示词问题来处理。
对于团队来说,这个分类步骤应该成为不变的规范。永远不要只记录"图片生成失败"。要记录模型 ID、请求界面、promptFeedback 是否存在、candidates 是否存在、最终的 finishReason、是否返回了任何 inlineData 图片部分,以及精确的 UTC 时间戳。没有这些数据,政策 bug、版本回退和普通提示词歧义在事后分析中看起来都是一样的。
IMAGE_SAFETY、NO_IMAGE 和 STOP 实际含义
Google 当前的 Gemini API 参考文档对这个话题尤为重要,因为它告诉你哪些枚举值属于提示词拦截,哪些属于候选结果完成状态。这个区分是正确诊断的基础。
提示词侧拦截使用 BlockReason 枚举值。根据 2026 年 1 月 12 日最后更新的官方参考文档,这些值包括 SAFETY、BLOCKLIST、PROHIBITED_CONTENT 和 IMAGE_SAFETY。候选结果侧的完成状态使用 FinishReason 枚举值。对于图片使用场景,最重要的值包括 IMAGE_SAFETY、IMAGE_PROHIBITED_CONTENT、IMAGE_OTHER、NO_IMAGE 和 IMAGE_RECITATION。即使这些词看起来相似,出现在不同位置时含义也完全不同。
先说 STOP,因为它最容易让人困惑。在 Google 的 Gemini 图片生成负责任 AI 页面上,Google 解释说潜在不安全的图片请求可能产生带有 FinishReason = STOP 的文字拒绝。换句话说,系统可能不是在说"过滤错误",而是用普通的模型文字说"我不打算创建那张图片"。这就是为什么纯文字回复需要阅读,而不是忽略。
IMAGE_SAFETY 不同。当你看到 finishReason = IMAGE_SAFETY 时,请求已经比提示词拦截走得更远。Google 将其记录为输出侧安全停止。提示词被接受到足够程度,产生了候选记录,但最终图片内容被扣留。这就是为什么很多用户感觉 Gemini"开始了,然后静默失败"。实际上,图片候选在概念上存在,但内容没有被释放。
NO_IMAGE 又不一样。它不自动意味着"政策问题"。它意味着没有生成图片。这可能是因为请求模糊、模型选择了文字而非图片行为、生成尝试没有有效完成,或者请求格式或传输中的某些因素阻止了有效的图片响应。Google 当前的图片生成限制页面明确说明,当提示词模糊时 Gemini 可能只生成文字而不生成图片,且模型可能在完成之前停止。这些是运营层面的修复,而非政策解读问题。
IMAGE_OTHER 是最不令人满意的枚举值,因为它过于宽泛。实际上,将其视为一个兜底分类,告诉你请求没有以正常图片输出结束,下一步是检查上下文:提示词措辞、模型界面、请求载荷、参考图片数量,以及问题是否可以跨地区或跨会话重现。它是记录更多上下文的信号,而不是随意猜测的理由。
IMAGE_PROHIBITED_CONTENT 比 IMAGE_SAFETY 更强。它指向禁止类别,而不仅仅是可调整的安全分类。Google 的 Vertex 安全过滤器指南更广泛地指出,某些类别是不可配置的,尤其是涉及禁止内容的情况。如果遇到 IMAGE_PROHIBITED_CONTENT,不应该考虑"如何让请求通过",而应该考虑"这个请求越过了政策边界"。
有一个微妙但重要的细节:相同的标签可能出现在不同的层级。IMAGE_SAFETY 可以出现在提示词侧的 BlockReason 和候选结果侧的 FinishReason 中。这就是为什么不能仅凭枚举字符串本身进行诊断。你需要知道它出现在哪里。模型是否返回了候选结果?promptFeedback 是否有内容?content 是否缺失?这些结构性线索比单词本身更重要。
实用规则很简单:
promptFeedback存在:从提示词侧分类开始。finishReason = STOP:阅读拒绝文字,将其视为模型拒绝。finishReason = IMAGE_SAFETY:将其视为输出过滤。finishReason = NO_IMAGE:在证明其他情况之前,将其视为已接受但未生成图片。
这个框架比任何通用的"重写提示词"建议都能解决更多案例。
纯文字回复和其他非政策静默失败的快速修复
Google 当前的 Gemini 图片生成限制页面是本节最有用的官方页面,因为它证实了很多开发者只能从试错中学到的东西:某些无图片结果根本不是政策拒绝,而是生成格式问题。如果跳过本节直接进行政策调整,会误诊大量故障。
第一个修复方法简单得令人尴尬,但效果出人意料:明确要求生成图片。如果你的提示词听起来像分析、头脑风暴或写说明文字,Gemini 可能会返回文字。Google 自己的文档说明,当提示词模糊时模型可能只生成文字而不生成图片。所以不要说"傍晚的平静日式店面",而要说"生成一张傍晚平静日式店面的图片,电影感照片风格,16:9 构图"。这一条额外指令就能改变模型的模式选择。
第二个修复方法是验证你确实按照 SDK 要求的方式请求了图片输出。不同 SDK 对同一字段的命名略有不同,但核心思路相同:请求图片输出,而不仅仅是通用的多模态完成。如果使用新版 Gemini SDK 时忘记设置图片响应模态,模型仍然可以用文字回答,因为从它的角度来看,你问的是通用内容生成问题,而不是严格的图片生成问题。
以下是一个明确表达图片意图的最简 Python 示例:
pythonfrom google import genai from google.genai import types client = genai.Client(api_key="YOUR_API_KEY") response = client.models.generate_content( model="gemini-2.5-flash-image", contents="Generate an image of a ceramic coffee cup on a walnut desk, soft morning light, editorial product photo.", config=types.GenerateContentConfig( response_modalities=["IMAGE"] ) )
如果响应只有文字,不要停在"Gemini 坏了"。检查返回的各个部分。如果只收到文字部分而没有 inlineData,在载荷证明其他情况之前,你面对的是模式选择或请求格式问题。
第三个修复方法是以受控方式重试未完成的生成。Google 图片生成限制页面(2026 年 3 月 14 日最后更新)说明,模型可能在未完成时停止生成内容,并特别建议重试或更改提示词。这不是允许盲目重试 30 次的许可。它的意思是,当载荷表明是不完整生成而非政策停止时,少量受控重试是合理的。实际上,一次立即重试和一次调整提示词的重试,足以判断失败是否为瞬态问题。
第四个修复方法是减少混合任务造成的歧义。很多失败的提示词要求 Gemini 在一次对话轮次中同时分析、总结、比较并生成图片。这增加了以文字优先回答的概率,在聊天式集成中尤为如此。将这些任务分开。如果需要模型理解一张图片然后生成新图片,先做推理步骤,再做生成步骤。请求越单一,出问题时越容易诊断。
第五个修复方法是检查图片输入的发送方式。2025 年 11 月 3 日的一个有用论坛帖子报告说,图片到图片编辑在使用 inlineData 时有效,但以特定方式使用 fileData 时只返回文字。Google 论坛回答者展示了一个有效的上传模式,原始发帖者后来确认流程有效。关键不是"永远不要使用文件",而是请求传输方式会改变行为,纯文字结果不自动意味着内容政策问题。如果 fileData 失败而 inlineData 对相同的无害提示词有效,很可能是集成问题,而非审核判决。
第六个修复方法是遵守文档化的图片输入限制。Google 当前限制页面说明,Gemini 2.5 Flash Image 在最多 3 张输入图片时表现最佳,而 Gemini 3 Pro Image 应保持在 14 张输入图片以下。如果在一个请求中塞入过多参考图片,系统会更难解释和调试。即使没有触及硬性限制,复杂的参考图片堆叠也会增加输出格式错误或不可用的概率。对于静默失败的排查,参考图片越少越容易重现问题。
第七个修复方法是在修改内容之前检查明显的运营层问题。如果完全相同的提示词和载荷昨天还有效,现在却以 404、429 或 503 失败,这不是内容政策的变化,而是路由、配额或容量问题。这就是为什么我们建议在问题看起来是系统性而非提示词特有时,将本文与我们的 Gemini 3 Pro Image 稳定渠道指南配合使用。
最后,不要忽视时间线。如果一个安全的提示词在短时间窗口内突然停止工作,且多个论坛用户报告了类似症状,这是版本回退的线索。2025 年 11 月 25 日的一个 Google AI 开发者论坛帖子描述了无害照片工作流失败,几乎没有政策解释,然后在大约 48 小时内部分恢复。这不能证明所有案例,但它提醒我们平台行为会随时间变化。有时正确的修复方法不是"想出更好的委婉说法",而是"记录确切时间戳,创建最小可重现案例,验证回退是否比你的账户范围更广"。
针对 IMAGE_SAFETY 和提示词拦截的快速修复(保持在政策范围内)
这一节是很多网络建议变得粗糙的地方。告诉用户"绕过 Gemini 安全机制"既是错误指导,也与 Google 的生成式 AI 禁止使用政策不一致,该政策明确禁止试图规避滥用保护或安全过滤器的行为。正确的问题不是"如何绕过过滤器",而是"如何足够清晰地表达合法请求,让 Gemini 能够正确分类"。
从无害上下文入手,而不是用隐晦措辞。如果你的提示词实际上是用于电商、目录工作、医学教育或历史场景,直接说明。不要用委婉说法替换敏感词汇,寄望于模型猜测你的无害意图。直接但安全的上下文通常比巧妙的回避语言效果更好,因为模型有更多分类信号。
例如,如果你在编辑时装或产品图片,避免使用"让这个更性感"或"成人感"这样模糊的提示词,这些可能将无害请求拉向色情解读。更安全、更清晰的版本是:"在白色无缝背景上创建一张米色棉质运动内衣的工作室电商照片,目录灯光,无模特,无姿势强调,零售产品风格。"第二个版本在商业上同样有用,但去除了很多可能将请求推向 IMAGE_SAFETY 的模糊提示。
如果你在处理合法的医疗、安全或历史用例,将目标更靠近解释,远离图形描述。明确要求血腥、伤害细节、羞辱或色情框架的请求,即使你的整体项目是合法的,也很难被视为无害。尽可能要求图表、非图形插图、标注教育布局或前后过程视觉效果,而不是逼真的伤害表现。
在时装之外,另一种无害改写模式是用受众和格式替换场景级歧义。不要要求"来自历史的抗议伤亡场景"——这可能被归入暴力分类——而是尝试:"为博物馆面板创建一张关于 1960 年代民权历史的非图形教育插图,海报风格,无可见伤口,聚焦于人群标语和警察障碍。"这种改写不保证一定通过,但它为模型提供了比模糊戏剧性场景请求更安全、更清晰的输出目标。
提示词侧拦截和输出侧 IMAGE_SAFETY 停止需要略微不同的思维模式。当提示词本身被拦截时,系统告诉你请求不应该以当前形式推进。当提示词被接受但最终图片被拦截时,系统告诉你即使输入文字没有在入口被拒绝,生成的视觉结果也越过了边界。两种情况的实际应对都是去除模糊或敏感的视觉提示,但输出侧拦截尤其受益于降低真实感、减少感官框架、去除身体强调细节,或将场景重新聚焦于非敏感对象而非边缘视觉元素。
以下是通常有帮助且不会走向规避的安全提示词改写模式:
| 风险模式 | 为什么会造成问题 | 更安全的改写模式 |
|---|---|---|
| 模糊的成人或感官框架 | 模型必须猜测请求是色情的还是商业的 | 指定目录、工作室、编辑、无人台、无姿势强调或纯产品框架 |
| 图形化暴力细节 | 即使合法的项目也可能被解读为有害视觉生成 | 要求非图形图表、无后果插图或教育布局 |
| 分析和生成混合 | Gemini 可能返回文字或拒绝而非干净的图片流 | 将规划放在一个轮次,图片生成放在第二个轮次 |
| 带有情绪化名词的极简提示词 | 短提示词给安全系统提供的无害上下文很少 | 用通俗语言添加主题、场景、灯光、用途、受众和风格 |
另一个重要修复是将图片任务与周围对话上下文隔离。在长对话中,模型看到的不只是你的最后一行。如果早期对话轮次讨论了暴力、性、创伤、犯罪或安全敏感话题,后续的图片请求可能会继承那个上下文。如果一个提示词意外开始失败,尝试只包含精确图片生成指令和最少所需源图片的新会话。这是区分上下文污染和硬性政策边界最简洁的方法之一。
还要记住,"之前能用"不等于"应该永远能用"。2025 年 12 月 24 日的社区证据显示,即使用户说可配置的性内容设置已放宽,合法的内衣电商提示词在 Vertex AI Studio 上仍然可能以 IMAGE_SAFETY 结束。这不意味着 Google 的文档有误,而是意味着输出侧过滤仍然可以覆盖用户期望可调设置所能覆盖的范围。正确的立场不是"Google 忽视了自己的控制",而是"可调设置存在,但内置和输出级保护仍然可能决定不返回图片"。
如果你的用例明显属于禁止类别,在这里停下来。Google 的政策边界不是用来被提示词工程绕过的。如果你的用例是合法的但仍然被拦截,记录确切的模型、地区、日期、载荷信号和脱敏提示词,然后携带这些信息进行升级。精确性比再试十次改写更有用。
Gemini 安全设置能改变什么,不能改变什么

这一节是很多排名靠前的页面只说对了一半因而产生误导的地方。是的,Gemini 有可配置的安全设置。不,这并不意味着每次图片拒绝都是可调整的。
Google 当前的安全设置文档(2026 年 1 月 15 日最后更新)说明可调整类别涵盖四个方面:骚扰、仇恨言论、色情内容和危险内容。这听起来范围很广,但同一页面也说明,针对核心危害的内置保护根本无法调整。用通俗语言说,你可以调整某些过滤器,但无法关闭整个安全系统。
同一官方页面还说明,如果你没有明确设置阈值,对于 Gemini 2.5 和 3 系列模型,默认拦截阈值为 Off。这个细节很重要,因为很多旧教程仍然告诉用户手动设置最宽松的阈值,只是为了让基本的图片生成能工作。根据当前文档状态,这个假设已经过时。如果你没有得到想要的结果,原因通常不是"你忘了放宽阈值",更可能是提示词模糊、输出侧过滤,或不可调整的保护。
使用下面的控制界面表格作为现实检验:
| 控制界面 | 你能改变的 | 你无法改变的 | 常见误解 |
|---|---|---|---|
| Gemini API 安全设置 | 骚扰、仇恨言论、色情内容和危险内容的阈值 | 针对核心危害的内置保护 | 认为 BLOCK_NONE 禁用了所有设置 |
| Vertex AI 安全过滤器 | 危害阈值和某些依赖界面的过滤处理行为 | 不可配置的禁止内容类别 | 将每次图片拦截视为阈值问题 |
| AI Studio 等工具中的产品 UI 设置 | 界面特定的便捷开关或默认值 | 底层平台级政策边界 | 认为 UI 标签与原始 API 行为一一对应 |
| 提示词改写 | 上下文、具体性、无害框架、视觉强调 | 政策禁止的请求 | 将清晰度与规避混淆 |
Google 的 Vertex AI 安全文档还补充了一个重要细节:提示词拒绝代码可以包括 PROHIBITED_CONTENT,被拦截的响应可以以安全相关的完成原因结束,同时被拦截的内容本身被扣留。这意味着执行是分层的。一个请求可能因可配置类别、不可配置类别或最终生成的输出本身而失败。如果你只关注一个旋钮,你只看到了系统的一部分。
在 2026 年谈论 BLOCK_NONE 或其他宽松阈值的正确方式是:它们可以减少某些类别的额外可配置拦截,但不是所有图片安全行为的主控开关。如果你看到合法请求仍然返回 IMAGE_SAFETY,这不自动是设置损坏的证据。它可能只是意味着输出级分类器或内置保护仍然决定不释放该图片。
对于在 Gemini 上构建产品流程的团队,工程含义很清晰。将安全设置视为系统的一个输入,而非整个系统。构建能够解释"这个请求触发了输出侧图片安全拦截"的日志和 UX,而不仅仅是"生成失败"。你的产品对失败的命名越准确,用户就越不可能认为你的应用不稳定或不诚实。
API、AI Studio、Vertex AI 和应用失败并不相同
很多糟糕的文章将"Gemini"当作一个统一的产品界面来讨论,实际上并非如此。即使是相同的底层模型系列,根据你使用的是原始 Gemini API、Vertex AI、AI Studio 还是消费者 Gemini 应用,感受也可能大相径庭。
原始 API 和 Vertex AI 是最好的调试场所,因为它们允许你检查载荷结构。你可以看到 promptFeedback、candidates、缺失的 content 和 finishReason。这就是为什么技术诊断应该尽可能从那里开始。如果你只使用 UI 层,你是在从症状而非证据来调试。
AI Studio 处于中间位置。它足够接近平台因而有用,但它仍然是一个产品界面,有自己的 UX 选择、发布节奏和偶发回退。这就是为什么两个人都能报告"Gemini 静默失败",但只有其中一个实际上触发了政策拦截。另一个可能触发了请求格式 bug、产品回退,或者 API 会更清楚地呈现的界面特有行为。
消费者 Gemini 应用距离载荷更远。应用可用性、计划权益、功能上线状态和 UI 级限制都可能影响图片创建是否看起来有效。如果你在调试重要工作流,不要仅依赖应用症状。尽可能通过 API 或 AI Studio 重现,这样你才能看清问题是政策、能力还是产品界面行为。
地区和模型可用性也使情况更复杂。2025 年 4 月 20 日的一个社区帖子报告说,切换到 us 服务器位置解决了 gemini-2.0-flash-exp-image-generation 未找到错误。这不是内容政策问题,但用户经常将其体验为"Gemini 图片不工作"。这个教训比特定的实验性模型更普遍:地区、路由和部署状态可能在用户感知中模拟政策失败。
配额和过载同理。遇到 429 或 503 的用户仍然可能将结果描述为"什么都没有生成"。如果你的日志显示配额耗尽或服务不可用,停止考虑内容政策,从配额和容量开始排查。我们在我们的 Gemini API 限速指南和前面链接的相关 Gemini 图片错误码文章中单独介绍了这些内容。
对于支持团队,在建议任何提示词修复之前,最好先问三个问题:
- 你使用的是哪个界面:API、Vertex AI、AI Studio 还是应用?
- 你有原始载荷还是只有 UI 消息?
- 在新会话中用最简无害提示词能重现失败吗?
这三个问题能将一半的虚假"内容政策"工单与真正的安全误报区分开来。
可复用的故障排除工作流
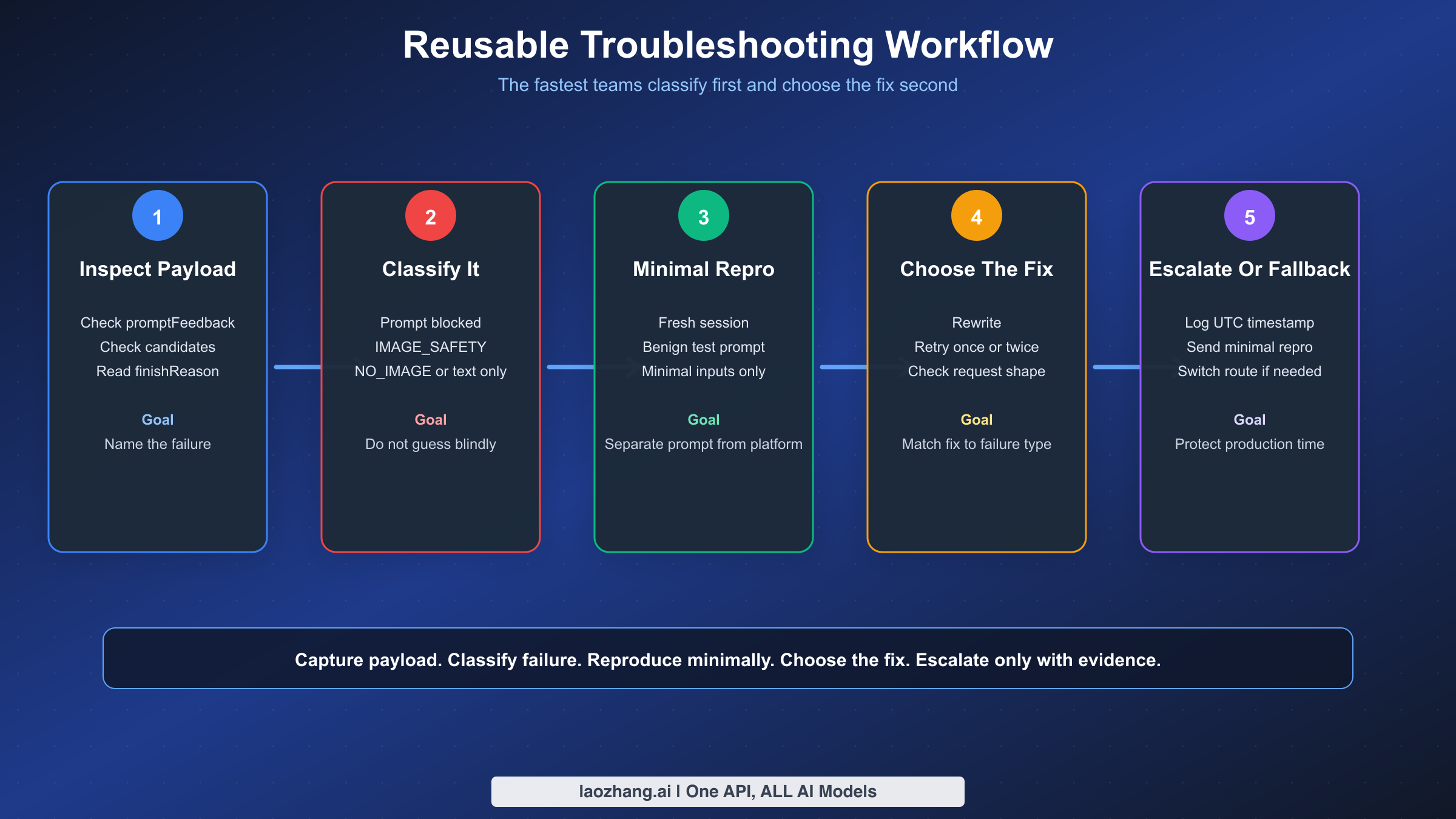
一旦 Gemini 图片生成对真实工作流很重要,你需要可重复的流程而非直觉。最快的团队不是那些有最好提示词技巧的团队,而是那些能够一致地分类失败并收集足够证据来区分提示词问题与平台问题的团队。
从应用日志中的一个小型分类器开始。这不是优雅的理论,而是运营卫生。
pythondef classify_gemini_image_result(resp): if getattr(resp, "prompt_feedback", None): return { "kind": "prompt_blocked", "block_reason": getattr(resp.prompt_feedback, "block_reason", "UNKNOWN"), } candidates = getattr(resp, "candidates", None) or [] if not candidates: return {"kind": "no_candidates"} candidate = candidates[0] finish_reason = getattr(candidate, "finish_reason", "UNKNOWN") content = getattr(candidate, "content", None) parts = getattr(content, "parts", None) if content else None has_inline_image = False has_text = False if parts: for part in parts: if getattr(part, "inline_data", None): has_inline_image = True if getattr(part, "text", None): has_text = True return { "kind": "candidate_returned", "finish_reason": finish_reason, "has_inline_image": has_inline_image, "has_text": has_text, "content_missing": content is None, }
代码不需要复杂。它只需要每次回答六个问题:
promptFeedback是否存在?- 是否返回了任何
candidates? - 最终的
finishReason是什么? content是否缺失?- 是否返回了任何图片
inlineData? - 模型是否返回了文字而非图片?
一旦有了这个分类,其余的工作流就变得可靠得多。
| 如果你看到 | 下一步做这个 | 不要做这个 |
|---|---|---|
promptFeedback 带有拦截原因 | 检查提示词语义和政策适配性 | 盲目地反复重试完全相同的提示词 |
finishReason = IMAGE_SAFETY | 减少敏感视觉细节,验证用例明确属于无害范围 | 假设安全阈值会覆盖所有情况 |
finishReason = NO_IMAGE | 明确图片意图,简化提示词,重试一次,检查请求格式 | 将其视为保证的内容政策拦截 |
| 纯文字回复 | 阅读回复,确认图片输出设置,分离混合任务 | 得出模型故意忽略你提示词的结论 |
| 404、429 或 503 | 转向路由、配额或容量排查 | 花一小时重写内容政策措辞 |
以下是我们在生产中推荐的工作流:
- 捕获原始响应载荷,而不仅仅是面向用户的错误字符串。
- 使用上述结构字段对失败进行分类。
- 在新会话中用最简无害提示词重现。
- 如果最简无害提示词有效,问题很可能是提示词措辞或对话上下文。
- 如果最简无害提示词以相同方式失败,检查请求格式、地区、模型 ID 和当前平台状态。
- 如果行为在相同载荷上突然改变,记录确切的 UTC 时间和界面以便升级。
- 只有在分类之后,才应该决定是重写、重试、等待还是切换路由。
同时记录在根因分析中真正有帮助的变量:
- 模型 ID
- 使用的界面
- 地区或端点
- 参考图片数量
- 输入是
inlineData还是文件 - 是否请求了图片输出模态
- 提示词哈希
- UTC 时间戳
- SDK 版本或客户端版本
每次出现回退时,这些数据都会救你于水火。当支持团队问"你能重现吗",你已经知道答案。当论坛帖子提示发布回退时,你会知道你的失败是否按日期和界面与之对应。当失败结果是简单的请求格式问题时,你不会浪费一周时间称其为安全问题。
何时等待、升级或使用回退路由
并非所有失败都需要相同的应对方式。有些值得重写提示词,有些值得重试一次,有些值得升级。还有一些值得构建架构回退,这样即使 Google 的图片行为发生变化,你的产品也能继续运行。
当证据指向不完整生成而非硬性拦截时,等待并重试。Google 的图片限制页面明确说明生成可能在完成之前停止。这是有限重试策略的绿灯。正确的做法是受控的:立即重试一次,然后用稍微更清晰的提示词再试一次。如果相同的分类失败重复出现,停止将其视为瞬态问题。
当载荷显示提示词拦截或输出侧 IMAGE_SAFETY 结果,而用例仍然合法且可能被分类为无害时,进行改写。这是添加上下文、减少视觉框架歧义和降低敏感提示的地方。如果用例接近禁止边界,改写可能没有帮助,不应被视为一种规避游戏。
当之前运行的无害工作流突然中断时进行升级,尤其是:
- 相同的最简提示词之前能用
- 失败在短时间窗口内开始
- 多个用户或论坛帖子报告了类似行为
- 问题在新会话中可以重现
升级时,发送最简但完整的重现信息:
- 模型名称
- 界面
- 地区
- 确切时间戳
- 脱敏提示词
promptFeedback是否存在finishReasoncontent是否缺失
这样你的报告才有用。"Gemini 又静默失败了"没有用。
当你的业务无法忍受平台不确定性时,使用回退路由。对于某些团队,这意味着将某些类型的图片任务路由到不同的 Gemini 图片模型。对于其他人,这意味着维护第二个提供商或中转路径。关键不在于另一条路由魔法般地不那么安全,而在于如果静默失败直接影响客户体验,生产系统不应该对所有图片工作只有一个狭窄的依赖。
如果你的真实问题是生产连续性而非消费者应用使用,中转层可能是合理的。laozhang.ai 是一个兼容 OpenAI 接口的中转选项,适合想要统一 API 路由而非一个官方端点的团队。这不是禁止请求的修复方法,也不应该以那种方式描述。它是出于可靠性、集成一致性或多模型路由的运营选择。如果这是你的关注点,先比较渠道权衡,而不是将政策和路由视为同一个问题。
更广泛的教训是,"Gemini 图片静默失败"不是单一的 bug 类别。有时正确答案是"你的提示词越过了边界"。有时是"你的载荷格式有问题"。有时是"Google 接受了提示词但过滤了最终图片"。有时是"模型根本没有生成图片"。越快命名正确的类别,就越快停止在错误的修复上浪费时间。
还有一个值得养成的生产习惯:为每个影响到客户的图片安全事件保留一个脱敏的重现包。这个包应包含模型名称、UTC 时间戳、地区、请求界面、请求是否仅使用文字或涉及图片编辑、参考图片数量、这些参考图片是以上传文件还是内联图片数据发送、最终拦截或完成原因,以及提示词哈希加上人类可读的已编辑提示词。这听起来繁琐,但它将一个模糊的投诉变成了可操作的工程产物。它还让你可以跨周比较事件,看清变化是否与某个界面、某个模型系列、某个提示词模板或某个新产品发布相关。
同样的重现包在你需要决定是继续使用官方路由还是增加回退容量时也很有用。如果 95% 的失败明显是提示词侧拦截,更多路由层不会解决根本问题。如果失败集中在不完整生成、纯文字回复或在另一条路由上消失的突然界面回退,那么运营冗余开始有意义。这种区分保护团队不会用购买基础设施来解决实际上是提示词设计问题,也保护他们不会将实际上是可用性问题归咎于提示词。
常见问题
最有用的思维模型很简单:先分类,后修复。Google 当前文档(2026 年 1 月 12 日至 3 月 14 日间核查)已经告诉我们,Gemini 图片失败分为提示词侧拦截、输出侧拦截、无图片结果和非政策生成问题。一旦你通过这个视角阅读载荷,IMAGE_SAFETY、NO_IMAGE 和纯文字回复就不再看起来像一个神秘的内容政策谜团。
另一个关键洞察是,可配置的安全设置只是图片的一部分。Google 官方安全设置页面说明,四个主要类别存在可调整阈值,但针对核心危害的内置保护始终有效且不可由用户调整。这就是为什么放宽设置不能保证看起来安全的边缘案例会通过,以及为什么一些合法工作流在行为变化时仍然需要仔细的提示词框架或升级。
如果你只从这篇文章记住一件事,记住这个:promptFeedback 告诉你提示词被拦截,finishReason = IMAGE_SAFETY 告诉你输出图片被拦截,finishReason = NO_IMAGE 告诉你 Gemini 实际上没有生成图片。这是三个不同的运营分支,将它们视为一个是许多 Gemini 图片排查会话在原地打转的原因。
为什么 Gemini 返回文字而不是图片?
最常见的原因是提示词模糊、缺少图片输出配置,或者混合任务导致了文字回答。Google 当前的图片限制页面明确说明,当提示词模糊时 Gemini 可能只生成文字而不生成图片。
为什么 BLOCK_NONE 或放宽安全设置无法修复 IMAGE_SAFETY?
因为 Google 官方安全设置文档说明,针对核心危害的内置保护无法调整。放宽可配置阈值不会禁用所有输出侧图片过滤。
IMAGE_SAFETY 和 NO_IMAGE 有什么区别?
IMAGE_SAFETY 意味着在请求推进到足够程度产生候选记录之后,输出图片被拦截。NO_IMAGE 意味着没有生成图片。NO_IMAGE 的正确修复通常是提高清晰度或重试,而不是政策解读。
为什么上周还能用的提示词突然停止工作了?
可能的原因包括平台回退、模型行为变化、界面默认值改变、累积的对话上下文或新的请求格式问题。2025 年末的近期论坛帖子显示,无害图片工作流可能在更新间发生行为变化,因此在认为提示词本身有问题之前,记录确切的日期、界面和载荷详情。
反复重试同一个失败请求安全吗?
对于不完整或模糊的无图片结果,一两次受控重试是合理的。对于提示词拦截或明确的 IMAGE_SAFETY 停止,反复重试相同的提示词通常没有价值。重新分类、改写或升级。
使用的官方来源: Vertex AI 上的被拦截响应、Gemini API 参考文档、Gemini 安全设置、Gemini 图片生成限制、Gemini 图片生成与负责任 AI,以及 Google 的生成式 AI 禁止使用政策。