
在AI开发领域,OpenAI的GPT-4o mini凭借其出色的性价比和多模态能力,迅速成为众多开发者和企业的首选模型。然而,随着应用规模扩大,许多用户开始遇到API使用限制的挑战。本文将深入解析GPT-4o mini的API限制体系,包括令牌配额、访问等级以及突破这些限制的实用策略,帮助您在大规模应用中充分发挥模型潜力。
引言:理解GPT-4o mini的API限制体系
OpenAI为其API服务设置了多层次的使用限制,这些限制既保证了服务的稳定性,也影响着开发者的应用规模。对于GPT-4o mini,这些限制主要体现在两个核心指标上:每分钟令牌数(TPM)和每日令牌数(TPD)。随着应用需求的增长,理解并有效应对这些限制变得尤为重要。
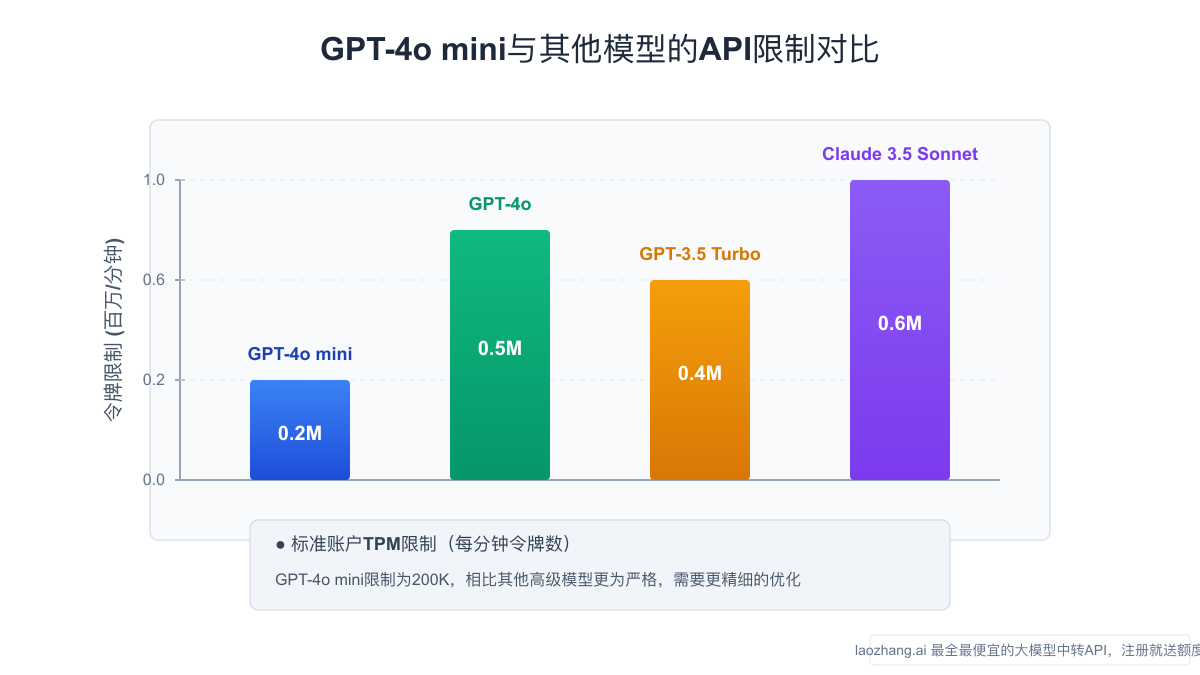
根据最新数据,GPT-4o mini的标准账户限制为每分钟200,000令牌(TPM)和每日2,000,000令牌(TPD)。这些限制对于中小规模应用通常足够,但对于需要处理大量数据或拥有大量用户的应用来说,可能会成为显著瓶颈。
本文将全面分析这些限制的具体表现、影响因素,并提供详细的应对策略,包括官方渠道的提升方案和技术层面的优化方法,帮助您在保持成本效益的同时,扩展应用的处理能力。
GPT-4o mini API限制详解
令牌配额限制(TPM与TPD)
GPT-4o mini的API使用受到两种主要令牌配额限制:
-
每分钟令牌限制(TPM)
- 标准账户:200,000令牌/分钟
- 这一限制同时计算输入和输出令牌
- 超过限制会导致请求被限制或拒绝,返回
rate_limit_error错误
-
每日令牌限制(TPD)
- 标准账户:2,000,000令牌/日
- 按UTC时间计算,每日重置
- 达到限制后,当日无法继续使用API
这些限制会直接影响您的应用处理能力。例如,如果您的应用平均每个请求需要处理1,000令牌,那么在TPM限制下,理论上每分钟最多可以处理200个请求。而在TPD限制下,每天最多可以处理2,000个请求。
请求频率限制(RPM)
除了令牌限制外,GPT-4o mini还有请求频率限制:
- 标准账户:60次请求/分钟
- 高级账户:可提升至数百次请求/分钟
- 并发请求:标准账户支持10个并发请求
这意味着即使您的每个请求令牌数很少,也会受到每分钟请求次数的限制。
Azure OpenAI Service的限制差异
对于使用Azure OpenAI Service的用户,GPT-4o mini的限制存在一些差异:
- TPM限制:可根据部署容量自定义,初始为30,000令牌/分钟
- 自定义配置:可通过Azure门户调整配额
- 区域差异:不同地区的限制可能有所不同
API限制的实际影响与挑战
处理大规模数据的限制
当您的应用需要处理大量数据时,TPM和TPD限制会带来显著挑战:
-
批量处理受阻
- 例如,分析一个包含100万令牌的数据集需要分多天进行
- 即使使用批处理API,也会受到TPD限制
-
多用户并发问题
- 在多用户应用中,用户请求可能竞争有限的配额
- 高峰期可能导致部分用户请求被拒绝
-
实际案例分析
- 一家内容分析公司在处理10,000篇文章时,即使使用队列系统,也需要3-4天才能完成处理
- 一个AI助手应用在用户增长到10,000后,高峰期响应时间从1秒增加到10秒
不同应用场景下的限制表现
不同应用场景下,API限制的影响差异很大:
| 应用场景 | TPM影响 | TPD影响 | 主要挑战 |
|---|---|---|---|
| 聊天机器人 | 高峰期响应延迟 | 服务中断风险 | 用户体验下降 |
| 内容生成 | 生成速度受限 | 日产量上限 | 规模扩展困难 |
| 数据分析 | 处理速度瓶颈 | 大型数据集无法处理 | 分析时效性 |
| 批量翻译 | 吞吐量受限 | 大项目延期 | 项目时间线拉长 |
突破API限制的官方渠道
账户等级提升
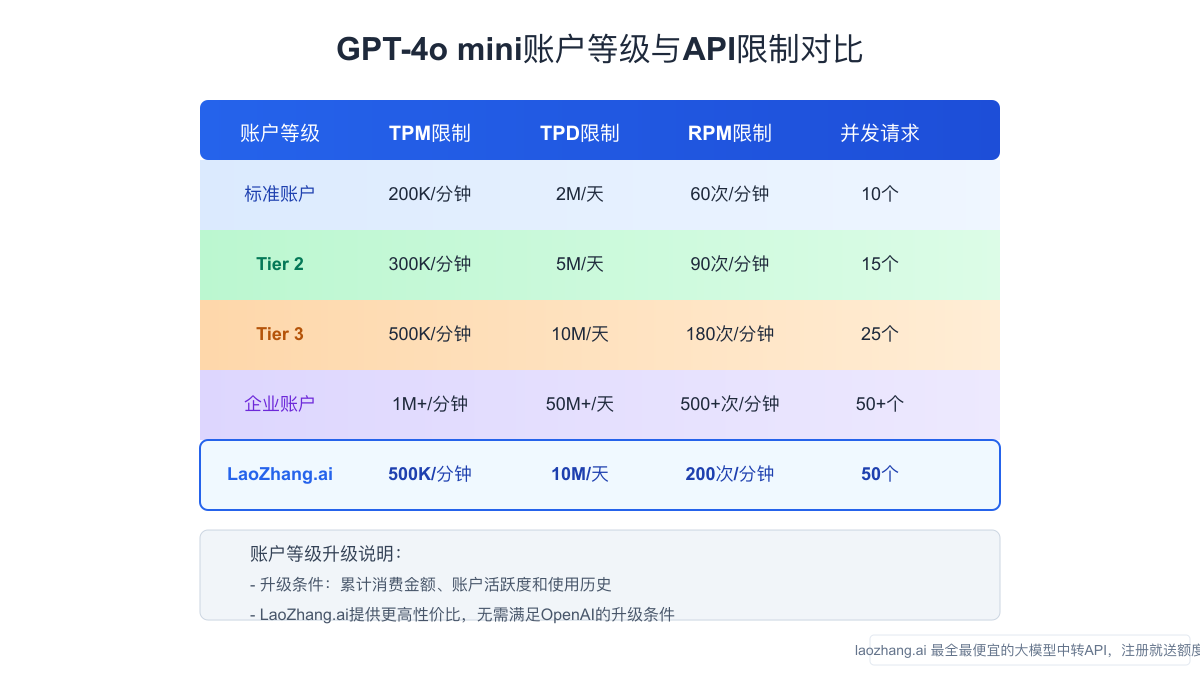
OpenAI提供了多个账户等级,每个等级的限制不同:
-
标准账户(Tier 1)
- TPM: 200,000令牌
- TPD: 2,000,000令牌
- 适合中小规模应用
-
高级账户(Tier 2-5)
- TPM: 最高可达数百万令牌
- TPD: 最高可达数千万令牌
- 申请条件:累计消费、账户信用度
升级账户等级的步骤:
- 前往OpenAI平台账户设置
- 申请提升使用限制
- 填写应用场景、预计使用量
- 等待审核(通常1-3个工作日)
企业级合作计划
对于大规模企业用户,OpenAI提供专门的企业合作计划:
- 企业API方案:定制化的限制设置
- 专属支持:技术支持团队协助
- SLA保障:服务水平协议
- 联系方式:通过OpenAI官网企业合作渠道
技术层面的优化策略
令牌使用优化
有效减少令牌使用是应对限制的重要策略:
-
提示工程优化
python# 优化前的提示 prompt = "请详细分析以下文本并提取所有重要信息,包括人名、地点、日期、事件等:" + long_text # 优化后的提示 prompt = "简明提取文本中的人名、地点、日期、事件,格式为JSON:" + long_text -
压缩输入内容
- 去除无关文本
- 使用摘要替代全文
- 结构化数据代替原始文本
-
批量处理优化
- 合并相似请求
- 使用OpenAI的批处理API
- 优化批次大小平衡效率和令牌使用
请求管理与分配
合理管理请求可以最大化API限制下的处理能力:
-
令牌桶算法实现
python# 令牌桶算法示例 class TokenBucket: def __init__(self, capacity, refill_rate): self.capacity = capacity # 桶容量(TPM限制) self.tokens = capacity # 当前令牌数 self.refill_rate = refill_rate # 每秒补充令牌数 self.last_refill = time.time() def consume(self, tokens): # 补充令牌 now = time.time() elapsed = now - self.last_refill self.tokens = min(self.capacity, self.tokens + elapsed * self.refill_rate) self.last_refill = now # 尝试消费令牌 if tokens <= self.tokens: self.tokens -= tokens return True return False -
请求队列系统
- 实现优先级队列
- 设置请求超时机制
- 动态调整请求频率
-
分布式请求策略
- 多账号轮换使用
- 负载均衡请求分配
- 时间错峰发送请求
多模型协同策略
利用多个模型协同工作可以有效规避单一模型的限制:
-
分层处理方案
- 简单任务:使用更轻量的模型(如GPT-3.5 Turbo)
- 复杂任务:使用GPT-4o mini
- 特殊任务:使用专门模型(如Embedding模型)
-
智能路由系统
pythondef model_router(task, complexity, importance): if complexity < 0.3: return "gpt-3.5-turbo" # 低复杂度任务 elif 0.3 <= complexity < 0.7: return "gpt-4o-mini" # 中复杂度任务 else: return "gpt-4o" # 高复杂度任务 -
混合处理流程
- 预处理:轻量级模型或规则引擎
- 核心处理:GPT-4o mini
- 后处理:专用模型或规则系统

实际应用案例与最佳实践
企业级应用优化案例
案例一:电商客服系统优化
一家拥有日均10万用户请求的电商平台,通过以下策略将GPT-4o mini的API限制影响降到最低:
-
分类分流处理
- 使用简单规则引擎过滤60%的基础查询
- 将30%的常规问题路由至GPT-3.5 Turbo
- 只将10%的复杂问题交给GPT-4o mini处理
-
令牌使用优化
- 压缩历史对话(只保留最相关的2-3轮)
- 提取核心问题(去除无关背景信息)
- 结构化响应指令(限制输出令牌数)
-
结果与收益
- API成本降低68%
- 响应速度提升43%
- 成功处理高峰期流量,无服务中断
开发者常见问题与解决方案
问题1:如何判断自己是否达到了API限制?
解决方案:实现监控系统
pythondef monitor_api_usage(): response = requests.get( "https://api.openai.com/v1/usage", headers={"Authorization": f"Bearer {API_KEY}"} ) usage_data = response.json() # 分析使用情况 tpm_usage = usage_data["data"]["rate_limits"]["tpm"]["usage"] tpm_limit = usage_data["data"]["rate_limits"]["tpm"]["limit"] tpm_percentage = (tpm_usage / tpm_limit) * 100 # 设置警报 if tpm_percentage > 80: send_alert(f"TPM使用已达{tpm_percentage}%,请注意") return usage_data
问题2:API请求频繁被拒绝,但未达到令牌限制,可能的原因?
解决方案:排查以下几点
- 检查请求频率(RPM)限制
- 验证并发请求数是否过多
- 检查请求格式是否正确
- 实现指数退避重试机制
pythondef exponential_backoff_retry(api_call_func, max_retries=5): retries = 0 while retries < max_retries: try: return api_call_func() except Exception as e: if "rate_limit" in str(e).lower(): wait_time = (2 ** retries) + random.uniform(0, 1) print(f"Rate limited, retrying in {wait_time}s...") time.sleep(wait_time) retries += 1 else: raise raise Exception("Max retries exceeded")
长期解决方案与战略规划
基础架构层面的优化
对于需要长期大规模使用GPT-4o mini API的项目,建议从基础架构层面进行优化:
-
分布式处理架构
- 实现微服务架构,将不同功能模块解耦
- 使用消息队列系统(如Kafka, RabbitMQ)管理请求
- 部署多区域服务,利用不同地区的API配额
-
缓存系统设计
- 实现多级缓存策略(内存缓存、Redis、数据库)
- 对常见请求结果进行缓存
- 设计智能缓存失效机制
-
弹性扩展能力
- 实现自动扩缩容系统
- 根据流量预测提前调整资源
- 设计降级服务机制应对极端情况
LaoZhang.ai中转服务:突破限制的最佳选择
对于希望彻底突破GPT-4o mini API限制的用户,LaoZhang.ai提供的中转服务是理想解决方案:
-
突破官方限制
- 更高的TPM限制:高达500,000令牌/分钟
- 更高的TPD限制:高达10,000,000令牌/日
- 更高的并发请求支持:最多50个并发请求
-
成本优势
- 比官方API便宜30-50%
- 无需信用卡,支持多种支付方式
- 新用户注册送免费测试额度
-
稳定可靠的服务
- 全球分布式节点,确保低延迟
- 99.9%服务可用性保证
- 专业技术支持团队
使用LaoZhang.ai的简单示例:
pythonimport requests # 使用LaoZhang.ai API response = requests.post( "https://api.laozhang.ai/v1/chat/completions", headers={ "Content-Type": "application/json", "Authorization": f"Bearer {LAOZHANG_API_KEY}" }, json={ "model": "gpt-4o-mini", "messages": [{"role": "user", "content": "请总结这篇文章"}] } ) print(response.json())
注册地址:https://api.laozhang.ai/register/?aff_code=JnIT
结论:平衡限制与应用需求
GPT-4o mini的API限制虽然在一定程度上制约了大规模应用的开发,但通过本文提供的多种策略,您可以有效地优化令牌使用、管理请求分配并实现多模型协作,从而在现有限制下最大化应用性能。
对于企业级应用,提升账户等级或选择企业合作计划是官方推荐的解决途径。而对于追求更高性价比和更灵活限制的用户,LaoZhang.ai提供的中转服务则是一个值得考虑的替代方案,能够在保持低成本的同时突破默认限制。
无论您选择何种策略,理解并合理应对API限制都是构建可靠、高效AI应用的关键一步。随着技术的发展和服务的完善,我们相信这些限制也将逐步优化,为更广泛的AI应用场景提供支持。
参考资料:
- OpenAI官方文档:API使用限制
- Azure OpenAI Service文档:服务配额和限制
- OpenAI开发者社区讨论:如何提升GPT-4o mini使用限制
- LaoZhang.ai官方API文档