
截至 2026 年 3 月 20 日,这个关键词最实用的答案不是“谁绝对更强”,而是“谁该负责哪条工作流”。 对大多数新 API 项目而言,GPT-5.4 mini 已经是更合理的小模型默认值。它更便宜、当前工具面更宽,而且 OpenAI 在最新 GPT-5.4 指南里把它摆在高吞吐编码、computer use 与 agent workflow 的推荐位上。
但这并不意味着 GPT-5.3-Codex 已经失去价值。恰恰相反,如果你的工作主要发生在 Codex 里,而且你依赖 cloud tasks、GitHub code reviews 或明显偏终端型的工程循环,那么 GPT-5.3-Codex 仍然保留着更强的“专用编码位”。
这一点也是当前 SERP 最容易说糊的地方。很多页面只看 API 单价,于是得出 GPT-5.4 mini 必赢;也有一些页面只盯着 Codex 的专用定位,于是又会把 GPT-5.3-Codex 说成“更深的正确答案”。真正正确的做法,是把 API 选型、Codex 产品行为 和 ChatGPT 展示名称 分开看。
这篇文章基于 2026 年 3 月 20 日重新核对的 OpenAI 官方模型页、发布文、最新模型指南与 Codex 定价页,重点回答四件事:
- API 默认值到底该选谁
- 编码相关基准到底谁更占优
- Codex 为什么会把推荐结论“拧”出一个例外
- 团队该怎么把两个模型编排进同一套系统
要点速览
如果你只要一句结论,先记住这条规则:新 API 构建与子代理默认用 GPT-5.4 mini;Codex 里的云任务、代码审查与终端重型编码继续保留 GPT-5.3-Codex。
| 模型 | 最适合的场景 | 主要选择理由 | 主要不选理由 |
|---|---|---|---|
| GPT-5.4 mini | 新 API 编码助手、低成本子代理、截图密集 worker、Codex 本地高频任务 | API 更便宜、工具面更宽、当前推荐路线更明确 | 编码专用基准不如 GPT-5.3-Codex,且当前不支持 Codex cloud tasks 与 code reviews |
| GPT-5.3-Codex | 终端重型编码、Codex 云任务、Codex 代码审查、深度专用编码链路 | SWE-Bench Pro 与 Terminal-Bench 画像更强,Codex 产品位更完整 | API 成本明显更高,也不再是当前“小模型默认推荐” |
最实用的决策规则如下:
- 如果你在 OpenAI API 里做新的编码 worker、tool caller 或 subagent,先从 GPT-5.4 mini 开始。
- 如果你的工作主要在 Codex 内,而且要用到 cloud tasks 或 GitHub code reviews,就必须继续保留 GPT-5.3-Codex。
- 如果你的工程流强依赖 shell、CLI、repo-local debugging 这类终端回路,GPT-5.3-Codex 仍然有非常现实的优势。
- 如果你是从 ChatGPT 里的模型名称反推 API 选型,请先停下来。那是不同表面,不该混着判断。
GPT-5.4 mini 和 GPT-5.3-Codex 真正差在哪里
很多人会把这组对比误读成:“GPT-5.4 mini 是更便宜、更新的小一号 GPT-5.3-Codex。” 这其实并不准确。
按当前 OpenAI 官方模型页,两者有一组非常接近的顶层规格:
- 400K context window
- 128K max output
- 2025-08-31 knowledge cutoff
- 支持文本与图像输入
如果你只看这些参数,会以为它们几乎是同一类模型。但真正决定选型的,从来不是这些“看起来相似”的静态指标,而是产品角色。
OpenAI 当前的 Using GPT-5.4 指南 直接把 gpt-5.4-mini 放在 high-volume coding、computer use 和 agent workflows 的推荐位上。它是“现在的小模型默认路线”。
而当前的 GPT-5.3-Codex 模型页 仍然强调它是 the most capable agentic coding model to date,而且明确面向 Codex 或类似环境。这不是“全面默认”,而是“更窄、更深、更专用”的定位。
可以把这组差异理解成下面这张脑内路由表:
| 问题 | 更适合的模型 |
|---|---|
| 需要当前 API 小模型默认路线 | GPT-5.4 mini |
| 需要更深的专用编码位 | GPT-5.3-Codex |
| 需要 Codex cloud tasks / reviews | GPT-5.3-Codex |
| 需要便宜的日常本地编码流 | GPT-5.4 mini |
也就是说,这不是“一个模型彻底取代另一个模型”的故事,而是 API 默认位 与 Codex 专用位 的重新分工。
真正影响决策的基准差距

OpenAI 没有在同一张官方表里直接把 GPT-5.4 mini 和 GPT-5.3-Codex 放在一起对打,但两个模型各自的发布文已经足够把分工看清楚。
来自 2026 年 3 月 17 日官方 GPT-5.4 mini and nano 发布文 的关键分数是:
- 54.4% SWE-Bench Pro
- 60.0% Terminal-Bench 2.0
- 72.1% OSWorld-Verified
来自 2026 年 2 月 5 日官方 GPT-5.3-Codex 发布文 的关键分数是:
- 56.8% SWE-Bench Pro
- 77.3% Terminal-Bench 2.0
- 64.7% OSWorld-Verified
并排看,结论其实很稳定:
| 基准 | GPT-5.4 mini | GPT-5.3-Codex | 该怎么理解 |
|---|---|---|---|
| SWE-Bench Pro | 54.4% | 56.8% | GPT-5.3-Codex 仍然更像“专用编码强者” |
| Terminal-Bench 2.0 | 60.0% | 77.3% | GPT-5.3-Codex 在终端型工程循环上优势很大 |
| OSWorld-Verified | 72.1% | 64.7% | GPT-5.4 mini 更适合截图驱动、computer-use 邻近工作流 |
这里最重要的不是谁赢了几行,而是 赢在哪一类工作里。
如果你的真实工作像这样:
- shell 命令来回迭代
- 本地仓库调试
- CLI 工具链修修补补
- 构建脚本与测试循环
那 GPT-5.3-Codex 的优势不是象征性的,而是会真实体现在完成路径上。特别是 Terminal-Bench 2.0 的差距,已经大到不能被一句“新模型更新”掩盖。
但如果你的工作更像:
- 需要看截图或界面状态
- 是更广义的 tool use worker
- 在大 orchestrator 里承担便宜的 subagent 角色
- 更接近 computer use 而不是纯终端链路
那 GPT-5.4 mini 会更顺手。它在 OSWorld-Verified 上的领先,本质上就是在提示你:GPT-5.4 mini 对 UI-grounded、screen-grounded、computer-use-like 的工作更友好。
所以这组基准真正给出的不是“单一冠军”,而是:
- GPT-5.3-Codex 赢更深的编码专用赛道
- GPT-5.4 mini 赢更便宜、更新、也更贴近现代 agent/电脑操作的小模型赛道
如果你还在犹豫是不是应该直接上大模型,而不是在这两个小模型里做取舍,可以继续看我们已写好的 GPT-5.4 vs GPT-5.3-Codex。
API 价格、工具支持与限额现实
价格是 GPT-5.4 mini 把“建议优先测试”变成“几乎应该默认先上”的关键原因。
按照 2026 年 3 月 20 日核对的官方模型页:
| 规格 | GPT-5.4 mini | GPT-5.3-Codex |
|---|---|---|
| 输入价格 | $0.75 / 1M tokens | $1.75 / 1M tokens |
| 缓存输入 | $0.075 / 1M tokens | $0.175 / 1M tokens |
| 输出价格 | $4.50 / 1M tokens | $14.00 / 1M tokens |
| Context window | 400K | 400K |
| Max output | 128K | 128K |
| Knowledge cutoff | 2025-08-31 | 2025-08-31 |
这跟不少人直觉相反。GPT-5.3-Codex 并不是更省钱的“老 Codex 选项”,相反,GPT-5.4 mini 在 API 里明显更便宜:
- 输入价格不到一半
- 缓存输入也不到一半
- 输出价格甚至不到三分之一
如果你是在做纯 API 路由,那么在绝大多数情况下,GPT-5.3-Codex 都不应该成为“默认先试”的那个模型。
工具面同样偏向 GPT-5.4 mini。当前 GPT-5.4 mini 模型页 给出的工具支持包括:
- web search
- file search
- image generation
- code interpreter
- hosted shell
- apply patch
- skills
- computer use
- MCP
- tool search
而 GPT-5.3-Codex 模型页 展示的是更窄的一组能力,更强调 structured outputs、function calling 与 Codex 型环境适配,而不是当前 GPT-5.4 mini 那种更完整的 Responses 工具矩阵。
连公开限额画像也对 GPT-5.4 mini 更友好。当前官方页面给出的 TPM 对比是:
| Tier | GPT-5.4 mini TPM | GPT-5.3-Codex TPM |
|---|---|---|
| Tier 1 | 500,000 | 500,000 |
| Tier 2 | 2,000,000 | 1,000,000 |
| Tier 3 | 4,000,000 | 2,000,000 |
| Tier 4 | 10,000,000 | 4,000,000 |
| Tier 5 | 180,000,000 | 40,000,000 |
所以如果你的问题是“新的 API 编码 worker 默认先试谁”,答案其实很直接:先试 GPT-5.4 mini,除非你非常确定自己的工作负载属于 GPT-5.3-Codex 的专用编码甜区。
如果你还在比较新的 mini 线和旧的通用 mini 线,可以连着看我们的 GPT-5.4 mini vs GPT-5 mini。
Codex 会把推荐结论改写掉

这一段才是当前很多比较页真正漏掉的部分。
在 Codex 里,GPT-5.4 mini 不是 GPT-5.3-Codex 的完整替代品。
当前 Codex pricing 页面 给出的关键信息是:
- GPT-5.4 mini 的本地消息额度最多可达 3.3 倍
- GPT-5.4 mini 平均本地任务大约消耗 2 credits
- GPT-5.3-Codex 平均本地任务大约消耗 5 credits
这让 GPT-5.4 mini 非常适合:
- Codex 里的日常本地编码任务
- 高频小修小改
- 本地快速读写文件
- 需要把本地消息额度拉得更长的支撑型工作
但同一页面也明确写了另外一半事实:
| Codex 能力 | GPT-5.4 mini | GPT-5.3-Codex |
|---|---|---|
| Local messages | Yes | Yes |
| Cloud tasks | No | Yes |
| Code reviews | No | Yes |
这正是为什么本文不能用一句“新模型更便宜,所以直接替代”来结束。
如果你的 Codex 工作流依赖:
- cloud tasks
- GitHub code reviews
- 更重的专用编码回路
那 GPT-5.3-Codex 现在仍然是必须保留的那条路。
所以 Codex 里的推荐结论应该拆成两半:
- Codex 本地日常任务:优先 GPT-5.4 mini
- Codex 云任务与代码审查:继续 GPT-5.3-Codex
这也是为什么 2026 年 3 月很多社区讨论会让人觉得“模型好像被换来换去”。Reddit 上的讨论更多反映的是不同产品面与套餐里的可见性变化,不改变眼下这个更稳定的事实:GPT-5.4 mini 和 GPT-5.3-Codex 目前在 Codex 里承担的是不同工作。
每种工作流到底该怎么选
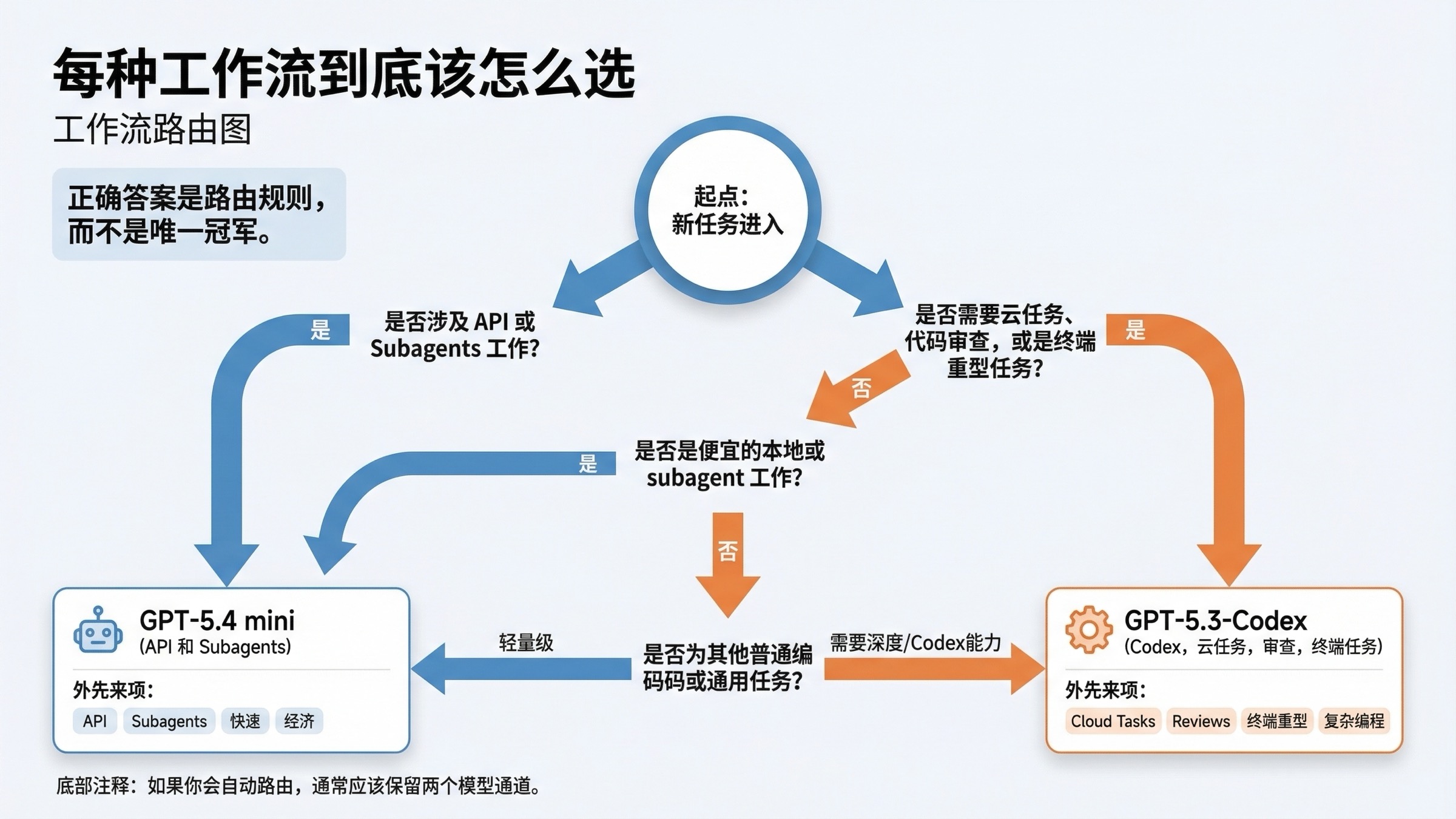
如果你要把这篇文章压缩成可执行路由,可以直接按下面这张表来:
| 工作流 | GPT-5.4 mini | GPT-5.3-Codex | 为什么 |
|---|---|---|---|
| 新 API 默认编码 worker | Yes | Rarely | GPT-5.4 mini 更便宜、更新、工具更宽 |
| 大模型下的便宜 subagent | Yes | Rarely | 这正是 mini 当前被推荐的工作 |
| 截图密集或 computer-use 邻近 worker | Yes | Sometimes | GPT-5.4 mini 的 OSWorld 画像更强 |
| 终端重型工程循环 | Sometimes | Yes | GPT-5.3-Codex 的 Terminal-Bench 优势非常明显 |
| Codex 本地日常任务 | Yes | Sometimes | GPT-5.4 mini 本地额度更划算 |
| Codex cloud tasks | No | Yes | GPT-5.3-Codex 仍然是当前支持位 |
| Codex GitHub code reviews | No | Yes | GPT-5.3-Codex 仍然是当前支持位 |
| 深度专用编码链路 | Sometimes | Yes | GPT-5.3-Codex 仍然更像“编码专家模型” |
对多数 API 团队而言,最好的设计不是强行只留一个模型,而是:
- 先让 GPT-5.4 mini 承担默认低成本编码与子代理任务
- 再让 GPT-5.3-Codex 承担终端重型与 Codex 云任务任务
这比“因为它更旧或更专用,所以默认一直用它”要健康得多。
GPT-5.3-Codex 仍然合理的四种情况
很多页面会把文章写成一句话:“GPT-5.4 mini 更新,所以直接用它。” 这么写虽然省事,但并不够准确。
GPT-5.3-Codex 现在仍然有四种非常现实的存在理由。
第一,终端重型工作。如果你的真实任务像 repo-local debugging、shell loop、脚本修复、构建链排错,那 GPT-5.3-Codex 的基准优势不只是“名义上的强”,而是直接对应工作流。
第二,Codex 云任务。这条理由最干净。如果你要 cloud tasks,GPT-5.3-Codex 不是“也许更好”,而是“当前就是支持位”。
第三,Codex 代码审查。只要团队依赖 GitHub review 流程,这一点就不是可选项。
第四,作为第二路 fallback routing。有些团队最不该问的问题就是“谁是永远的冠军”。更好的问法是:
- 默认的小模型工作由谁承担
- 真正偏专用编码的任务该分流给谁
在这个框架下,GPT-5.4 mini 与 GPT-5.3-Codex 最自然的关系不是替代,而是分工。
如果你还想看 GPT-5.3-Codex 和其他旗舰编码模型相比是什么位置,可以继续看 GPT-5.3 Codex 与 Claude Opus 4.6 对比。
FAQ
GPT-5.4 mini 的编码能力已经全面超过 GPT-5.3-Codex 了吗?
没有。按官方发布文,GPT-5.3-Codex 在 SWE-Bench Pro 和 Terminal-Bench 2.0 上仍然更强。GPT-5.4 mini 的优势在于 API 成本、工具面、当前推荐位,以及对 computer-use 邻近任务的更好适配。
既然 GPT-5.3-Codex 编码基准更强,为什么默认还是建议先试 GPT-5.4 mini?
因为默认建议并不是只由一行基准决定。真正决定默认值的是整张运营图:API 成本、工具支持、公开限额、当前产品方向,以及大量“编码系统其实也是工具系统和 agent 系统”的现实。
GPT-5.4 mini 会在 Codex 里完全替代 GPT-5.3-Codex 吗?
不会。至少就 2026 年 3 月 20 日官方 Codex pricing 页面而言,GPT-5.4 mini 还不支持 cloud tasks 和 code reviews,所以它不能完整接管 GPT-5.3-Codex 的工作。
新团队第一轮测试应该先测谁?
如果你是 API 团队,先测 GPT-5.4 mini。如果你是 Codex 重度团队,最有效率的做法通常是同时保留两条路:GPT-5.4 mini 跑本地日常任务,GPT-5.3-Codex 跑 cloud tasks、reviews 和更重的终端编码流。
最终建议
如果你只想带一句话回去给团队,就用这句:新的 API 编码与子代理,先上 GPT-5.4 mini;但只要你的工作流涉及 Codex 云任务、代码审查或终端重型工程,GPT-5.3-Codex 仍然必须保留。
这个结论之所以比“新旧模型之争”更可靠,是因为它更接近 2026 年 3 月的真实产品状态:
- GPT-5.4 mini 在 API 里更便宜、也更有默认位
- GPT-5.3-Codex 仍然保留更强的专用编码画像
- Codex 的产品支持差异意味着两者今天并不互相等价
真正成熟的选型方式,不是逼自己只信一个赢家,而是把两个模型放回它们各自最合适的工作流里。