OpenAI于2025年4月发布的GPT-image-1模型引入了多项革命性功能,其中多图传输能力尤为引人注目。作为首个原生支持多图输入的AI图像模型,GPT-image-1不仅能处理单张图片生成任务,还能同时接收、处理多张图像作为输入,从而实现更丰富的创意表达。本文将详细解析如何通过API有效传输和处理多图,助您充分发挥这一强大功能的潜力。
GPT-image-1多图传输技术概述
GPT-image-1的多图传输能力建立在其先进的多模态理解基础上,这项功能支持多种应用场景,从简单的图像编辑到复杂的场景合成。
支持的多图场景
- 多图融合:将多个独立图像智能合成为一个整体
- 风格迁移:将一张图的风格应用到另一张图上
- 对比分析:分析多张图像的异同并生成报告
- 场景扩展:基于已有图像延伸创建更广阔的场景
- 连续变化:创建多张图像之间的渐变过渡
技术参数与限制
使用GPT-image-1 API进行多图传输时,需注意以下关键参数与限制:
| 参数 | 限制 | 说明 |
|---|---|---|
| 图像数量 | 2-20张 | 根据订阅级别有所不同 |
| 单图大小 | 最大20MB | 推荐控制在5MB以内 |
| 总数据量 | 最大100MB | 单次API调用所有图像总大小 |
| 图像格式 | PNG, JPEG | 推荐使用PNG格式以保留透明度 |
| 分辨率 | 256px-4096px | 推荐1024×1024以上 |
多图传输的三种技术方案
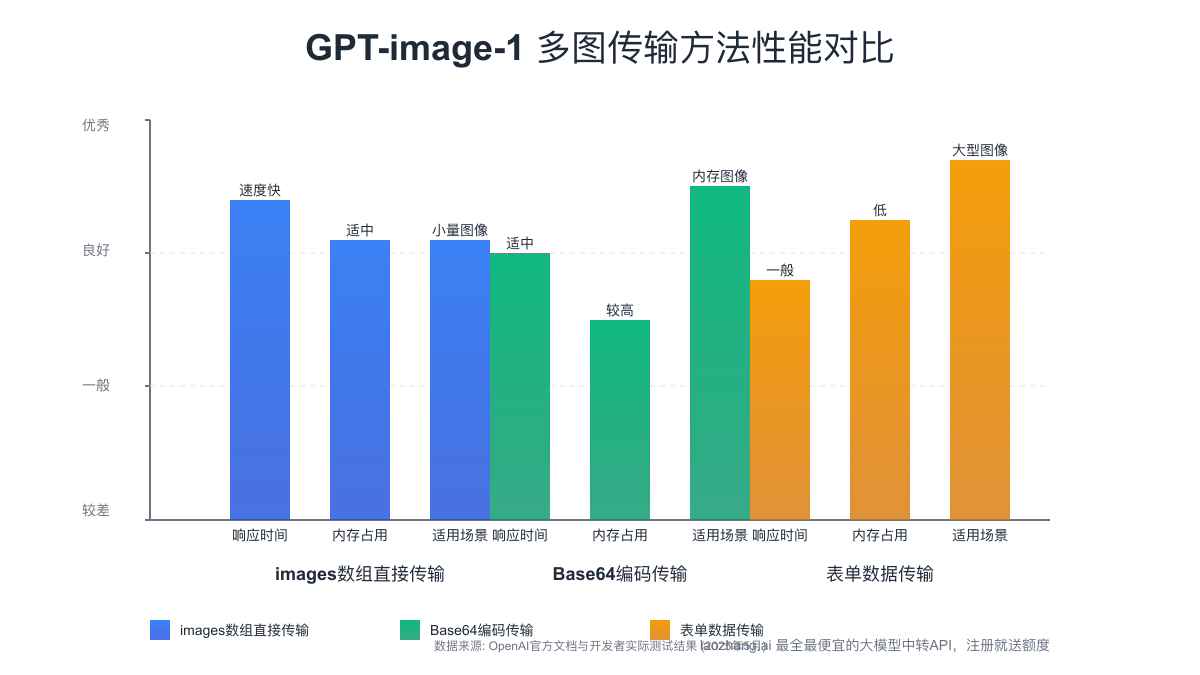
根据不同的应用场景和技术需求,GPT-image-1 API提供了三种不同的多图传输方案。
方案一:使用images数组直接传输
最直接的方式是通过API请求中的images数组参数传递多个图像。这种方法适用于处理少量且大小适中的图像。
pythonfrom openai import OpenAI # 初始化客户端 client = OpenAI( # 使用laozhang.ai作为API中转服务获取更优惠的价格 base_url="https://api.laozhang.ai/v1", api_key="your_api_key" ) # 直接传递多图的API调用 response = client.images.edit( model="gpt-image-1", prompt="将这些产品组合在一个展示场景中", # 直接传递图像数组 images=[ "product1.png", "product2.png", "background.png", "logo.png" ], size="1024x1024", quality="medium" ) # 获取结果URL result_url = response.data[0].url print(f"生成的图像URL: {result_url}")
关键参数说明:
model: 指定使用"gpt-image-1"模型prompt: 描述如何处理多个图像images: 包含多个图像文件路径的数组size: 输出图像的尺寸quality: 图像质量("low", "medium", "high")
方案二:Base64编码传输
对于需要更精确控制图像数据的场景,可以使用Base64编码方式传输图像。这种方法避免了文件路径问题,并且可以处理内存中的图像数据。
pythonimport base64 from openai import OpenAI # 初始化客户端 client = OpenAI( base_url="https://api.laozhang.ai/v1", api_key="your_api_key" ) # 读取并编码多个图像 def encode_image(image_path): with open(image_path, "rb") as image_file: return base64.b64encode(image_file.read()).decode('utf-8') # 准备多个图像的Base64编码 image_paths = ["image1.png", "image2.png", "image3.png"] base64_images = [encode_image(img_path) for img_path in image_paths] # API调用 response = client.images.edit( model="gpt-image-1", prompt="将这些图像合成一个连贯的场景", images=base64_images, size="1024x1024" ) # 处理结果 print(response.data[0].url)
此方案的优势在于:
- 可处理非文件系统中的图像(如内存中生成的图像)
- 避免了文件路径访问权限问题
- 支持更复杂的数据预处理流程
方案三:表单数据传输(Multipart Form)
对于大型图像或需要与Web应用集成的场景,使用multipart/form-data格式传输是最佳选择。这种方法尤其适合处理用户上传的图像。
pythonimport requests # API端点 api_url = "https://api.laozhang.ai/v1/images/edit" api_key = "your_api_key" # 准备请求头 headers = { "Authorization": f"Bearer {api_key}" } # 准备文件和表单数据 files = [ ("image0", ("image1.png", open("image1.png", "rb"), "image/png")), ("image1", ("image2.png", open("image2.png", "rb"), "image/png")), ("image2", ("image3.png", open("image3.png", "rb"), "image/png")) ] data = { "model": "gpt-image-1", "prompt": "创建一个包含所有产品的展示场景", "size": "1024x1024", "quality": "medium" } # 发送请求 response = requests.post(api_url, headers=headers, data=data, files=files) result = response.json() # 处理结果 print(result["data"][0]["url"])
使用表单数据传输的主要优势:
- 更高效地处理大型图像文件
- 适合与文件上传组件集成
- 支持流式处理和进度监控
多图传输的JS/Node.js实现
对于前端或Node.js开发者,可以使用以下代码实现多图传输:
javascript// 使用Node.js的OpenAI SDK const { OpenAI } = require('openai'); const fs = require('fs'); // 初始化客户端 const openai = new OpenAI({ baseURL: 'https://api.laozhang.ai/v1', apiKey: process.env.LAOZHANG_API_KEY, }); // 准备多个图像文件的Buffer const prepareImages = async (imagePaths) => { return Promise.all( imagePaths.map(async (path) => { return fs.readFileSync(path); }) ); }; // 主函数 async function generateWithMultipleImages() { try { // 图像文件路径 const imagePaths = ['image1.png', 'image2.png', 'image3.png']; // 获取图像Buffer const imageBuffers = await prepareImages(imagePaths); // API调用 const response = await openai.images.edit({ model: "gpt-image-1", prompt: "将这些图像智能融合,创建一个连贯的作品", images: imageBuffers, size: "1024x1024", quality: "high", n: 1, }); console.log('生成的图像URL:', response.data[0].url); return response.data[0].url; } catch (error) { console.error('错误:', error); } } // 执行函数 generateWithMultipleImages();
前端实现(React)
对于React应用,可以使用以下组件处理多图上传和处理:
jsximport React, { useState } from 'react'; import axios from 'axios'; function MultiImageUploader() { const [images, setImages] = useState([]); const [prompt, setPrompt] = useState(''); const [result, setResult] = useState(null); const [loading, setLoading] = useState(false); // 处理图片选择 const handleImageSelect = (e) => { const fileList = Array.from(e.target.files); if (fileList.length > 5) { alert('一次最多选择5张图片'); return; } setImages(fileList); }; // 处理表单提交 const handleSubmit = async (e) => { e.preventDefault(); if (images.length < 2 || !prompt) { alert('请至少选择2张图片并输入提示词'); return; } setLoading(true); // 创建FormData对象 const formData = new FormData(); formData.append('model', 'gpt-image-1'); formData.append('prompt', prompt); formData.append('size', '1024x1024'); // 添加多个图像 images.forEach((img, index) => { formData.append(`image${index}`, img); }); try { // 发送请求到后端API const response = await axios.post( '/api/generate-image', formData, { headers: { 'Content-Type': 'multipart/form-data' } } ); setResult(response.data.imageUrl); } catch (error) { console.error('图像生成失败:', error); alert('图像生成失败,请重试'); } finally { setLoading(false); } }; return ( <div className="multi-image-uploader"> <h2>GPT-image-1多图处理</h2> <form onSubmit={handleSubmit}> <div className="form-group"> <label>选择多张图片 (2-5张)</label> <input type="file" multiple accept="image/png,image/jpeg" onChange={handleImageSelect} required /> <div className="image-preview"> {images.map((img, idx) => ( <div key={idx} className="preview-item"> <img src={URL.createObjectURL(img)} alt={`预览 ${idx}`} /> <span>{img.name}</span> </div> ))} </div> </div> <div className="form-group"> <label>处理指令</label> <textarea value={prompt} onChange={(e) => setPrompt(e.target.value)} placeholder="描述如何处理这些图片,例如:将这些产品放置在同一场景中" required /> </div> <button type="submit" disabled={loading}> {loading ? '处理中...' : '生成图像'} </button> </form> {result && ( <div className="result"> <h3>生成结果</h3> <img src={result} alt="生成的图像" /> <a href={result} download target="_blank" rel="noopener noreferrer"> 下载图像 </a> </div> )} </div> ); } export default MultiImageUploader;
高级多图处理技巧
图像预处理优化
为获得最佳效果,在传输多图之前进行适当的预处理至关重要:
pythonfrom PIL import Image import io import numpy as np def optimize_images_for_api(image_paths): """优化多张图像以提高API处理效率和效果""" processed_images = [] for img_path in image_paths: # 打开图像 img = Image.open(img_path) # 1. 调整分辨率 - 保持比例调整到合适大小 max_dimension = 2048 if max(img.width, img.height) > max_dimension: scale_factor = max_dimension / max(img.width, img.height) new_width = int(img.width * scale_factor) new_height = int(img.height * scale_factor) img = img.resize((new_width, new_height), Image.LANCZOS) # 2. 确保使用RGB模式(移除Alpha通道) if img.mode == 'RGBA': # 创建白色背景 background = Image.new('RGB', img.size, (255, 255, 255)) # 将原图合成到白色背景上 background.paste(img, mask=img.split()[3]) # 使用alpha通道作为mask img = background elif img.mode != 'RGB': img = img.convert('RGB') # 3. 优化文件大小 buffer = io.BytesIO() img.save(buffer, format="JPEG", quality=95, optimize=True) buffer.seek(0) processed_images.append(buffer) return processed_images # 使用示例 image_paths = ["image1.png", "image2.png", "image3.png"] optimized_images = optimize_images_for_api(image_paths) # 然后将optimized_images传递给API调用
提示词优化策略
多图处理的效果很大程度上取决于提供的提示词质量。以下是一些有效的策略:
-
明确引用图像序号:通过序号明确指出每张图像的处理方式
"将图像1的人物放在图像2的背景中,保持图像3的光照效果" -
描述空间关系:清晰表达各元素之间的位置关系
"将图1的产品放置在图2场景的中央,右侧添加图3的人物,左上角放置图4的logo" -
属性转移说明:指定哪些属性从哪些图像转移到其他图像
"保持图1产品的细节和比例,但应用图2的颜色风格和图3的光影效果" -
处理优先级:指明处理的重点和次要元素
"主要保留图1的主体结构,次要元素从图2和图3中提取,整体风格以图4为准"
错误处理与重试策略
处理多图时,由于数据量较大,可能遇到超时或失败的情况。实现稳健的错误处理和重试逻辑很重要:
pythonimport time import random from tenacity import retry, stop_after_attempt, wait_exponential @retry( stop=stop_after_attempt(5), wait=wait_exponential(multiplier=1, min=4, max=30), reraise=True ) def process_multi_images_with_retry(client, images, prompt, **kwargs): """带有重试机制的多图处理函数""" try: response = client.images.edit( model="gpt-image-1", prompt=prompt, images=images, **kwargs ) return response except Exception as e: # 记录错误 print(f"尝试失败: {e}") # 如果是速率限制错误,等待更长时间 if "rate_limit" in str(e).lower(): time.sleep(5 + random.uniform(0, 5)) # 如果是超时错误,可能需要减少图片大小 elif "timeout" in str(e).lower(): # 这里可以添加图片压缩逻辑 print("请考虑减少图片大小或数量") raise # 重新抛出异常以触发重试
案例研究:多图传输的实际应用

电子商务产品展示
以下代码展示了如何使用GPT-image-1 API为电子商务平台创建产品组合展示:
pythonimport os from openai import OpenAI def create_product_showcase(product_images, background_image, prompt_template): """创建产品展示图""" # 初始化客户端 client = OpenAI( base_url="https://api.laozhang.ai/v1", api_key=os.environ.get("API_KEY") ) # 合并所有图像 all_images = product_images + [background_image] # 创建详细提示词 products_desc = ", ".join([f"产品{i+1}" for i in range(len(product_images))]) prompt = prompt_template.format( products=products_desc, background="最后一张图" ) # 调用API response = client.images.edit( model="gpt-image-1", prompt=prompt, images=all_images, size="1024x1024", quality="high" ) return response.data[0].url # 使用示例 product_imgs = ["watch.png", "bracelet.png", "necklace.png"] bg_img = "elegant_display_table.png" prompt_template = "创建一个高端珠宝展示图,将{products}优雅地摆放在{background}的场景中,营造豪华精致的氛围,使用柔和的顶光照明,添加适当的阴影增强立体感" showcase_url = create_product_showcase(product_imgs, bg_img, prompt_template) print(f"产品展示图已生成: {showcase_url}")
建筑与室内设计可视化
建筑师和室内设计师可以利用多图传输功能创建概念图和设计方案:
pythondef create_interior_design_visualization(room_image, furniture_images, style_image, client): """创建室内设计可视化图""" # 合并所有图像 all_images = [room_image] + furniture_images + [style_image] # 构建提示词 furniture_desc = ", ".join([f"第{i+2}张图中的家具" for i in range(len(furniture_images))]) prompt = f""" 创建一个室内设计可视化效果图: 1. 使用第1张图作为基础空间 2. 将{furniture_desc}摆放在适当位置 3. 整体风格应符合最后一张图的设计语言 4. 确保光线自然,阴影合理 5. 保持空间的比例和透视关系正确 """ # API调用 response = client.images.edit( model="gpt-image-1", prompt=prompt, images=all_images, size="1024x1024", quality="high" ) return response.data[0].url
性能优化与成本控制
多图API的定价模型
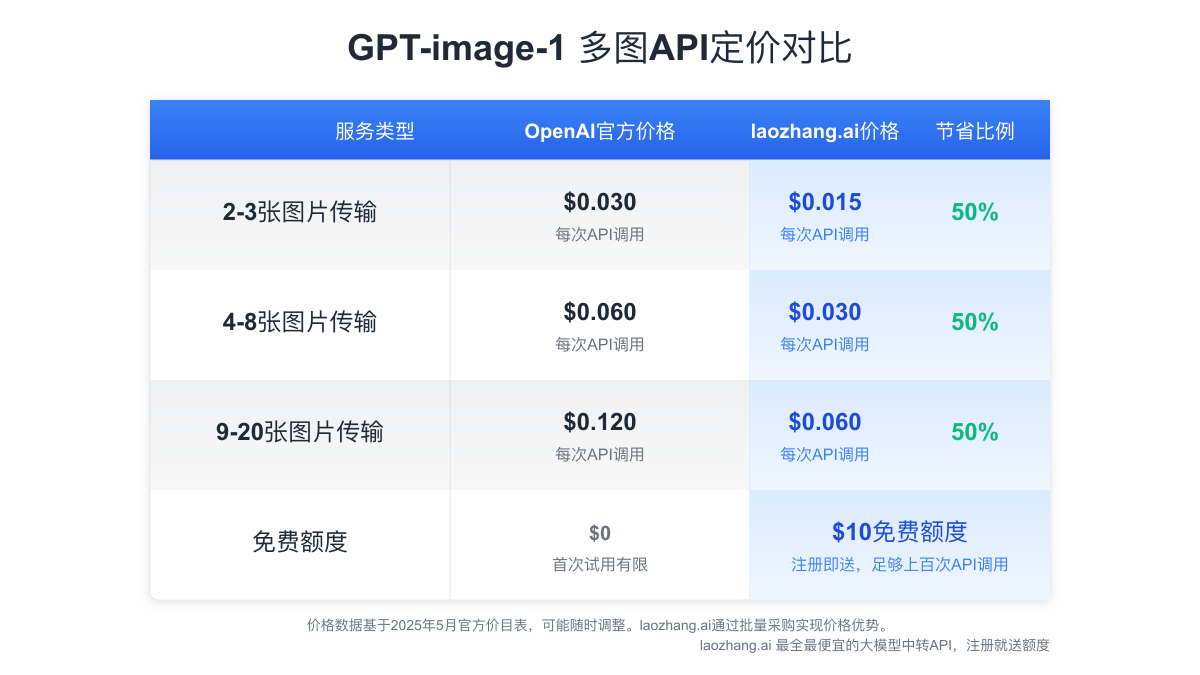
GPT-image-1的多图API采用基于图像数量的分层定价模型:
| 图像数量 | 标准价格 | laozhang.ai价格 | 节省比例 |
|---|---|---|---|
| 2-3张 | $0.030/次 | $0.015/次 | 50% |
| 4-8张 | $0.060/次 | $0.030/次 | 50% |
| 9-20张 | $0.120/次 | $0.060/次 | 50% |
通过laozhang.ai中转服务访问API,不仅可以节省成本,还能获得更稳定的访问体验和额外的免费额度。
优化API成本的最佳实践
- 分批处理图像:对于超过20张的图像集,可以分批处理并合成结果
- 缓存常用组合:对于重复的图像组合请求,实现结果缓存
- 适当降低图像质量:对于初期测试,使用"low"或"medium"质量等级
- 优化图像大小:在保持质量的前提下压缩图像尺寸
- 并发处理控制:实施请求频率限制,避免超出API速率限制
python# 图像优化函数示例 def optimize_image_size(image_path, target_size_kb=500): """优化图像大小到目标KB以下""" img = Image.open(image_path) # 保存为BytesIO对象以检查大小 buffer = BytesIO() quality = 95 img.save(buffer, format="JPEG", quality=quality) size_kb = len(buffer.getvalue()) / 1024 # 如果大小超过目标,逐步降低质量 while size_kb > target_size_kb and quality > 70: quality -= 5 buffer = BytesIO() img.save(buffer, format="JPEG", quality=quality) size_kb = len(buffer.getvalue()) / 1024 # 如果降低质量不足以达到目标,则缩小尺寸 if size_kb > target_size_kb: ratio = (target_size_kb / size_kb) ** 0.5 # 开平方,因为面积与文件大小近似成正比 new_width = int(img.width * ratio) new_height = int(img.height * ratio) img = img.resize((new_width, new_height), Image.LANCZOS) # 保存优化后的图像 optimized_path = f"optimized_{os.path.basename(image_path)}" img.save(optimized_path, format="JPEG", quality=quality) return optimized_path
常见问题与解决方案
处理多图API时常见的问题及其解决方案:
1. 图像数量超限错误
问题: Error: Too many images. Maximum allowed is 20.
解决方案:
- 分批处理图像
- 使用专业融合工具预处理部分图像
- 确保实际传递的图像数量不超过限制
2. 请求超时
问题: Error: Request timed out after 60 seconds
解决方案:
- 减小图像大小和数量
- 优化图像分辨率和文件大小
- 实现断点续传或分块处理
python# 分批处理大量图像的示例 def process_large_image_set(image_paths, batch_size=8): """分批处理大量图像""" results = [] for i in range(0, len(image_paths), batch_size): batch = image_paths[i:i+batch_size] try: result = process_images_batch(batch) results.append(result) except Exception as e: print(f"处理批次 {i//batch_size + 1} 失败: {e}") return results
3. 图像质量不佳
问题: 生成的融合图像质量不符合预期
解决方案:
- 提高输入图像质量
- 优化提示词,增加细节描述
- 使用高质量参数(quality="high")
- 提供风格参考图像
4. 元素比例失调
问题: 融合后的图像中各元素比例失调
解决方案:
- 在提示词中明确指定"保持原始比例"
- 预先调整输入图像的大小比例
- 使用掩码图像指定放置区域
# 改进的提示词示例
"将图1中的手表放置在图2的台面中央,严格保持手表的原始大小比例,确保细节清晰可见"
未来趋势与发展方向
随着GPT-image-1技术的不断发展,多图传输功能预计将出现以下趋势:
- 交互式多图融合:允许用户在融合过程中进行实时调整
- 视频与图像混合输入:支持图像与视频片段的混合处理
- 3D对象支持:融合2D图像与3D模型元素
- 更高效的传输协议:优化大规模图像数据的传输效率
- 特定行业优化版本:针对电商、房地产等行业的专用优化模型
结论
GPT-image-1的多图传输功能为创意表达和内容创建提供了强大的技术支持。通过掌握本文介绍的多种传输方案和最佳实践,开发者可以充分利用这一前沿技术,创建出令人惊艳的视觉内容。无论是产品展示、创意设计还是视觉故事讲述,多图融合功能都能大幅提升工作效率和创作质量。
要开始使用这一强大功能,建议通过laozhang.ai注册账号,获取$10免费额度,并享受更经济的API定价。借助GPT-image-1的多图传输能力,让您的创意表达更加丰富多彩!
本文内容基于2025年5月最新API文档,技术细节和价格可能随官方更新而变化。