
Claude Opus 4.6 and GPT-5.3-Codex dropped on the same day — February 5, 2026 — creating the most consequential AI model showdown since GPT-4 challenged Claude 3 in early 2024. Anthropic's new flagship dominates reasoning benchmarks with a 1606 Elo on GPQA Diamond and 91.9% accuracy on tau-bench, while OpenAI's coding specialist leads terminal-based development with a 77.3% Terminal-Bench score. But the real story goes beyond benchmarks: pricing strategies, agentic workflows, and practical use cases determine which model actually delivers more value for your specific needs. This guide provides verified data, cost optimization analysis, and a concrete decision framework to help you choose.
TL;DR — The Quick Verdict
The simplest way to frame this comparison: Claude Opus 4.6 is a general-purpose powerhouse that happens to be excellent at coding, while GPT-5.3-Codex is a coding specialist that sacrifices breadth for terminal dominance. Neither is universally "better" — the right choice depends entirely on your workflow.
Five key differences that matter most:
- Reasoning depth: Opus 4.6 scores 68.8% on ARC-AGI 2 vs GPT-5.2's 54.2% — a 14.6 percentage point gap that translates to meaningfully better performance on complex analytical tasks, scientific research, and multi-step problem solving
- Terminal coding: GPT-5.3-Codex achieves 77.3% on Terminal-Bench 2.0, outpacing Opus 4.6's 65.4% by nearly 12 points — the largest gap in any benchmark category, making Codex the clear winner for CLI-heavy development workflows
- Pricing reality: Opus costs $5/$25 per million tokens (input/output) at standard rates vs GPT-5.2's $1.75/$14, but Opus's Batch API (50% off) and prompt caching (90% off on input) narrow the gap dramatically for high-volume users
- Context window: Both offer 1M token context, but Opus 4.6's is in beta with a 76% accuracy rate on MRCR v2 long-context retrieval — still the most capable long-context implementation available
- Workflow paradigm: Opus 4.6's Agent Teams enable multi-agent orchestration (frontend + backend + testing simultaneously), while Codex's CLI integration provides a terminal-native experience with self-debugging capabilities
Quick recommendation: Choose Opus 4.6 for research, complex analysis, code review, and full-stack development. Choose GPT-5.3-Codex for DevOps, rapid prototyping, and terminal-centric workflows. For mixed workloads, use both through a unified API.
The February 5 Showdown — Why This Comparison Matters
The simultaneous release of Claude Opus 4.6 and GPT-5.3-Codex on February 5, 2026 marks a pivotal moment in AI development. For the first time, Anthropic and OpenAI launched competing flagship-tier models on the exact same day, forcing the entire developer community into an immediate evaluation cycle. This wasn't coincidence — both companies had been racing toward similar capability thresholds, and the timing reflects how closely matched the frontier AI labs have become.
What makes this comparison particularly nuanced is the fundamental difference in positioning. Anthropic positioned Opus 4.6 as their most capable model across all dimensions — reasoning, coding, long-context understanding, and agentic task completion. The model earned the #1 spot on the Artificial Analysis overall ranking (artificialanalysis.ai, February 2026) and was described as "the first model that functions as a digital enterprise team member" by multiple reviewers. Its Agent Teams feature enables coordinating multiple AI agents on different parts of a project simultaneously, representing a new paradigm in AI-assisted development.
OpenAI took a different approach with GPT-5.3-Codex, doubling down on coding excellence. The model is described as "the most capable agentic coding model" with a focus on terminal-native workflows, self-debugging capabilities, and interactive steering. Notably, OpenAI revealed that GPT-5.3-Codex was "the first model instrumental in creating itself" — a milestone in AI-assisted AI development. The model is 25% faster than its predecessor GPT-5.2-Codex and introduces features specifically designed for developer workflows rather than general-purpose intelligence.
This positioning difference is crucial for understanding the benchmark results that follow. When every.to's evaluation found that Opus scored 9.25/10 on their LFG coding benchmark versus Codex's 7.5/10, the result surprised many who expected the coding specialist to dominate. The explanation lies in complexity: Opus excels at multi-file, multi-step coding tasks that require deep reasoning, while Codex shines in rapid, terminal-based execution scenarios. For context on how the previous generation compared, see our previous generation comparison — the gap has narrowed significantly in this generation.
Benchmark Breakdown — What the Numbers Actually Mean
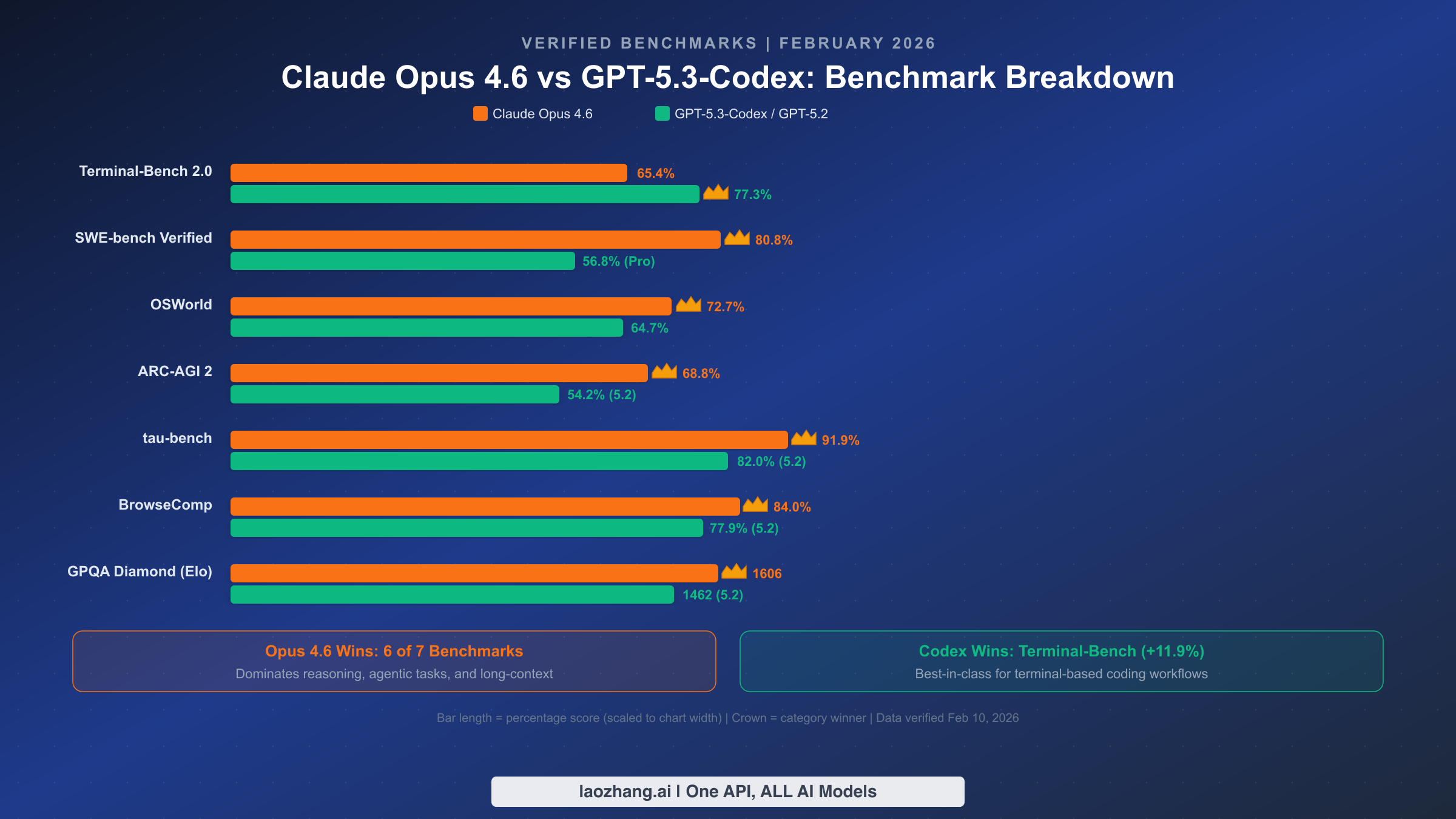
Raw benchmark numbers tell only part of the story. Understanding what each benchmark actually measures — and which ones matter for your specific use case — is far more valuable than knowing who "won" more categories. Here is the complete verified data with practical interpretation.
Terminal-Bench 2.0 measures a model's ability to complete complex tasks in a terminal environment, including system administration, debugging, and multi-step command sequences. GPT-5.3-Codex's 77.3% score versus Opus 4.6's 65.4% represents the largest single-benchmark gap in this comparison. If your daily work involves extensive terminal interaction — DevOps, infrastructure management, shell scripting — this benchmark directly predicts real-world performance. The 11.9 percentage point advantage is substantial and consistent across multiple independent evaluations.
SWE-bench Verified tests a model's ability to resolve real GitHub issues from popular open-source projects. Opus 4.6's 80.8% score is among the highest ever recorded, indicating exceptional ability to understand complex codebases, identify root causes, and generate correct patches. GPT-5.3-Codex scored 56.8% on the harder SWE-Bench Pro variant, which uses a different scoring methodology — the benchmarks are not directly comparable, but both demonstrate strong coding capabilities. For enterprise development teams working on large codebases, SWE-bench performance is arguably the most relevant predictor of practical utility.
ARC-AGI 2 and GPQA Diamond measure abstract reasoning and scientific knowledge respectively. Opus 4.6's advantages here — 68.8% vs 54.2% on ARC-AGI 2, and 1606 vs 1462 Elo on GPQA Diamond — are significant because they indicate superior performance on tasks requiring novel problem-solving approaches. These benchmarks matter most for research, data analysis, and any task where the model needs to reason through problems it hasn't seen in training data.
Agentic Performance Benchmarks
tau-bench (91.9% vs 82.0%) measures multi-turn task completion in realistic agent scenarios. Opus 4.6's nearly 10-point lead here directly translates to more reliable autonomous task execution — fewer failed steps, better error recovery, and more coherent multi-step plans. If you're building AI agents or using models for complex automated workflows, this is the single most important benchmark to consider.
BrowseComp (84.0% vs 77.9%) evaluates web browsing and information synthesis capabilities. Opus's advantage matters for research automation, competitive analysis, and any workflow involving extracting and synthesizing information from multiple web sources.
OSWorld (72.7% vs 64.7%) tests computer-use capabilities in realistic desktop environments. Despite GPT-5.3-Codex being positioned as a more "hands-on" tool, Opus 4.6 outperforms it by 8 points in general computer-use scenarios. This suggests Codex's advantage is specifically in terminal environments, not in broader computer interaction.
Coding and Agentic Workflows — Real-World Performance
The benchmark numbers paint a clear picture, but the actual developer experience of using these models differs in ways that numbers alone cannot capture. The fundamental difference comes down to workflow philosophy: Opus 4.6 operates as an orchestrator that manages complexity, while GPT-5.3-Codex operates as an accelerator that executes rapidly within a focused scope.
Agent Teams represent Opus 4.6's defining innovation for development. Instead of a single AI assistant processing requests sequentially, Agent Teams allow you to spin up multiple specialized agents that work on different aspects of a project simultaneously. In practice, this means you can have one agent handling frontend React components, another managing backend API endpoints, and a third writing database migrations — all coordinated by a lead agent that ensures consistency. Early benchmarks from Anthropic show this approach can reduce complex project completion times by 40-60% compared to sequential processing. The feature is exclusive to Opus 4.6 and leverages its Adaptive Thinking capability, which dynamically allocates reasoning resources based on task complexity.
GPT-5.3-Codex's terminal-native approach offers a different kind of efficiency. Rather than orchestrating multiple agents, Codex integrates directly into your terminal workflow with features like interactive steering (providing real-time guidance as the model works), self-debugging (automatically identifying and fixing errors in its own output), and context-aware suggestions based on your shell history and project structure. For developers who live in the terminal — writing deployment scripts, debugging production issues, managing infrastructure — this tight integration eliminates the cognitive overhead of switching between an AI interface and your actual work environment.
The security dimension deserves special attention. Anthropic reported that Opus 4.6 discovered over 500 zero-day vulnerabilities in open-source code during its evaluation period. This capability has direct implications for code review workflows: Opus 4.6 can identify subtle security issues — race conditions, injection vulnerabilities, logic errors — that traditional static analysis tools miss. For teams where code security is a priority, this represents a significant practical advantage that no benchmark can fully quantify.
When Each Model Excels in Practice
Opus 4.6 consistently outperforms in scenarios requiring deep understanding of large codebases. When tasked with refactoring a 50,000-line application, Opus's 1M token context window (beta) and superior reasoning allow it to maintain coherence across the entire codebase, identifying dependencies and side effects that shorter-context models miss. Its SWE-bench Verified score of 80.8% reflects this capability — the benchmark specifically tests real-world bug fixing in complex projects.
GPT-5.3-Codex excels in rapid iteration cycles. Its 25% speed improvement over GPT-5.2-Codex, combined with self-debugging, means you get working code faster in terminal-driven workflows. For tasks like setting up CI/CD pipelines, writing shell scripts, or debugging container configurations, Codex's Terminal-Bench advantage translates directly to time saved. The interactive steering feature is particularly valuable here — you can course-correct in real-time rather than waiting for a complete response and then requesting changes.
Pricing Deep Dive — The True Cost of Each Model

Pricing is where this comparison gets genuinely complex, because the sticker prices tell a misleading story. At standard rates, Claude Opus 4.6 appears significantly more expensive than GPT-5.2 — but Anthropic's aggressive optimization features can dramatically change the calculus for high-volume users.
Standard API pricing (verified February 10, 2026, from official pricing pages):
| Model | Input | Output | Cache Hit | Batch Input | Batch Output |
|---|---|---|---|---|---|
| Claude Opus 4.6 | $5.00/MTok | $25.00/MTok | $0.50/MTok | $2.50/MTok | $12.50/MTok |
| GPT-5.2 | $1.75/MTok | $14.00/MTok | $0.175/MTok | N/A | N/A |
| GPT-5.3-Codex | TBD | TBD | TBD | TBD | TBD |
A critical caveat: GPT-5.3-Codex's API pricing has not been announced as of February 10, 2026. The model is currently available only through the Codex app, CLI, and IDE extensions, with API access "coming soon" according to OpenAI. This means direct price comparison is currently impossible for the Codex model specifically — we use GPT-5.2 pricing as a reference point.
Cost optimization strategies make Opus 4.6 more competitive than the sticker price suggests. The Batch API provides a flat 50% discount on both input and output tokens, bringing effective pricing to $2.50/$12.50 per MTok. For workloads that can tolerate asynchronous processing (code review batches, documentation generation, data analysis pipelines), this makes Opus 4.6 only slightly more expensive than GPT-5.2 standard pricing while delivering substantially better reasoning performance. For a deeper breakdown of Anthropic's prompt caching mechanics, see our prompt caching optimization guide.
Prompt caching delivers even more dramatic savings on input costs. When you send similar prompts repeatedly — common in development workflows where you're iterating on the same codebase — cached input tokens cost just $0.50 per MTok, a 90% reduction from standard pricing. For a typical development session with 80% cache hit rate, effective input cost drops to approximately $1.40 per MTok, approaching GPT-5.2's standard input rate. For comprehensive Claude pricing details, our detailed Claude Opus pricing breakdown covers all tiers and discount structures.
Monthly cost estimates at 10M output tokens (typical medium-volume usage):
| Configuration | Monthly Cost | Notes |
|---|---|---|
| GPT-5.2 Standard | ~$140 | Baseline comparison |
| Opus 4.6 Standard | ~$250 | 78% more than GPT-5.2 |
| Opus 4.6 Batch API | ~$125 | Actually cheaper than GPT-5.2 standard |
| Opus 4.6 Batch + Cache | ~$125 | Lowest effective cost for Opus |
The key insight: with Batch API, Opus 4.6 becomes competitive with or even cheaper than GPT-5.2 standard pricing, while delivering superior reasoning quality across most benchmarks. For teams already committed to Anthropic's ecosystem, the optimization features effectively eliminate the pricing disadvantage.
For teams that need access to both models — or want to compare them on real workloads before committing — a unified API approach simplifies the process. Services like laozhang.ai provide a single API endpoint that routes to both Anthropic and OpenAI models, eliminating the need to manage multiple API keys and billing relationships while offering potentially lower rates through aggregated volume pricing.
Getting Started — API Integration Guide
Getting up and running with either model takes minutes. Here are working code examples for both, plus a unified approach for teams that want flexibility.
Claude Opus 4.6 API
pythonimport anthropic client = anthropic.Anthropic(api_key="your-api-key") message = client.messages.create( model="claude-opus-4-6", max_tokens=4096, messages=[ {"role": "user", "content": "Analyze this codebase for security vulnerabilities..."} ] ) print(message.content[0].text)
For the 1M context window beta, add the header:
pythonmessage = client.messages.create( model="claude-opus-4-6", max_tokens=4096, extra_headers={"anthropic-beta": "context-1m-2025-08-07"}, messages=[...] )
GPT-5.2 API (GPT-5.3-Codex API pending)
pythonfrom openai import OpenAI client = OpenAI(api_key="your-api-key") response = client.chat.completions.create( model="gpt-5.2", messages=[ {"role": "user", "content": "Write a deployment script for..."} ] ) print(response.choices[0].message.content)
Since GPT-5.3-Codex API access hasn't launched yet, GPT-5.2 is the closest available model through the API. Codex-specific features (self-debugging, interactive steering) are currently accessible only through the Codex app and CLI tools.
Unified API Approach
For teams wanting to use both models through a single integration, laozhang.ai provides an OpenAI-compatible endpoint that routes to multiple providers:
pythonfrom openai import OpenAI client = OpenAI( api_key="your-laozhang-key", base_url="https://api.laozhang.ai/v1" ) # Use Opus for reasoning tasks opus_response = client.chat.completions.create( model="claude-opus-4-6", messages=[{"role": "user", "content": "Analyze this research paper..."}] ) # Use GPT-5.2 for cost-sensitive tasks gpt_response = client.chat.completions.create( model="gpt-5.2", messages=[{"role": "user", "content": "Generate test cases for..."}] )
This approach is particularly valuable during the evaluation period — you can route identical prompts to both models and compare results before committing to a primary provider. It also enables a "best of both worlds" strategy where reasoning-heavy tasks go to Opus and rapid-iteration tasks go to GPT-5.2 (or GPT-5.3-Codex once its API launches).
Which One Should You Choose? — Decision Framework
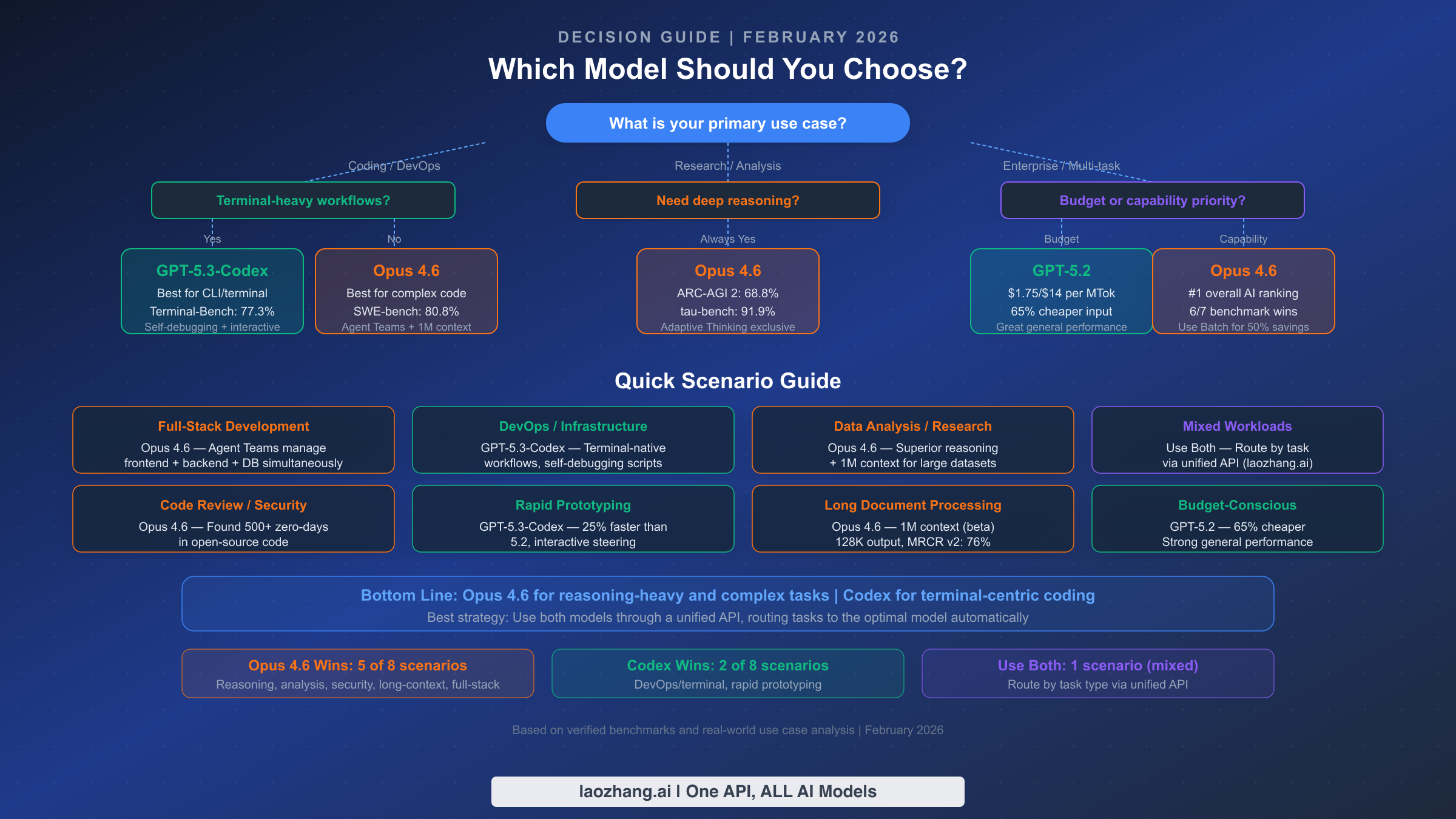
After analyzing benchmarks, pricing, and workflows, here is a practical decision framework organized by real-world scenarios. The goal is not to declare a winner but to match each model to the contexts where it delivers the most value.
Full-stack application development favors Opus 4.6. The Agent Teams feature enables parallel work across frontend, backend, and database layers, while the 1M context window handles entire codebases. SWE-bench Verified's 80.8% confirms superior performance on complex, multi-file coding tasks. The higher cost is offset by reduced iteration cycles and fewer errors in complex refactoring operations.
DevOps and infrastructure management favors GPT-5.3-Codex. Terminal-Bench 2.0's 77.3% score directly measures the skills needed for deployment scripts, container management, and CI/CD pipeline configuration. The self-debugging feature catches shell scripting errors before they propagate, and interactive steering lets you guide the model through complex infrastructure changes in real time. This is Codex's strongest competitive advantage.
Research and data analysis strongly favors Opus 4.6. With 68.8% on ARC-AGI 2, 91.9% on tau-bench, and 84.0% on BrowseComp, Opus dominates every benchmark relevant to research workflows. The 1M context window enables processing entire research papers, datasets, and documentation in a single pass. Adaptive Thinking dynamically allocates more reasoning resources to complex analytical questions — a feature exclusive to Opus 4.6 that has no equivalent in the GPT lineup.
Rapid prototyping and scripting favors GPT-5.3-Codex. The 25% speed improvement over GPT-5.2-Codex means faster iteration cycles, and the terminal-native workflow minimizes context-switching between your IDE and AI tools. For building quick proofs-of-concept, automation scripts, or one-off utilities, Codex's speed advantage outweighs Opus's reasoning depth.
Code security auditing strongly favors Opus 4.6. The discovery of 500+ zero-day vulnerabilities in open-source code demonstrates a level of security analysis capability that no other model has publicly matched. For teams responsible for security reviews, compliance audits, or maintaining critical infrastructure, this capability alone may justify the higher per-token cost.
Budget-conscious general use favors GPT-5.2. At $1.75/$14 per MTok, GPT-5.2 offers strong general performance at 65% lower input cost than Opus standard pricing. For teams that don't need Opus's peak reasoning or Codex's terminal integration, GPT-5.2 provides the best value per dollar.
Long document processing favors Opus 4.6. The 1M token context window (beta), combined with 128K max output tokens, enables processing and generating content at scales no other model matches. MRCR v2's 76% accuracy means the model maintains reasonable retrieval accuracy even at extreme context lengths.
Mixed enterprise workloads benefit most from using both models. Route reasoning-heavy tasks (analysis, code review, strategic planning) to Opus 4.6 and execution-heavy tasks (deployment, scripting, terminal operations) to GPT-5.3-Codex or GPT-5.2. A unified API endpoint simplifies this routing without requiring separate integrations for each provider.
FAQ — Frequently Asked Questions
Is Claude Opus 4.6 better than GPT-5.3-Codex?
It depends on the dimension. Opus 4.6 wins 6 of 7 major benchmarks, including reasoning (ARC-AGI 2: 68.8% vs 54.2%), agentic tasks (tau-bench: 91.9% vs 82.0%), and general coding (SWE-bench: 80.8%). However, GPT-5.3-Codex leads on Terminal-Bench 2.0 by nearly 12 percentage points (77.3% vs 65.4%), making it the clear choice for terminal-centric development workflows. For most general-purpose applications, Opus 4.6 is the stronger model, but for specialized terminal coding, Codex has a meaningful edge.
How much does Claude Opus 4.6 cost compared to GPT-5.3-Codex?
Opus 4.6 costs $5/$25 per MTok (input/output) at standard rates. GPT-5.3-Codex API pricing hasn't been announced yet — it's currently available only through the Codex app, CLI, and IDE extensions. Using GPT-5.2 ($1.75/$14 per MTok) as a reference, Opus appears 2-3x more expensive at standard rates. However, Opus's Batch API (50% off) brings output cost to $12.50/MTok, and prompt caching can reduce input cost by 90% to $0.50/MTok. With these optimizations, high-volume Opus usage can actually cost less than GPT-5.2 standard pricing (Anthropic official pricing, verified February 10, 2026).
Can Opus 4.6 replace GPT-5.3-Codex for coding?
For most coding tasks, yes — Opus 4.6's SWE-bench Verified score of 80.8% and Agent Teams feature make it exceptionally capable for complex development work. The one area where Codex maintains a clear advantage is terminal-native workflows: if your development process is heavily centered on CLI tools, shell scripts, and terminal debugging, Codex's purpose-built features (self-debugging, interactive steering, 77.3% Terminal-Bench) provide a better experience. For full-stack development, code review, and multi-file refactoring, Opus 4.6 is the stronger choice.
What is Adaptive Thinking in Opus 4.6?
Adaptive Thinking is an exclusive Opus 4.6 feature that dynamically allocates reasoning resources based on task complexity. Rather than using a fixed amount of "thinking" for every request, the model automatically scales up its reasoning depth for complex analytical questions and scales down for straightforward tasks. This means you get GPT-5.2-level speed on simple queries and extended reasoning capabilities on hard problems — without needing to manually switch between models or configure thinking parameters. No other model currently offers equivalent functionality.
Should I wait for GPT-5.3-Codex API access?
If terminal-centric coding is your primary use case, waiting for Codex API access is worth considering — the Terminal-Bench advantage is substantial. However, if you need an API solution today, GPT-5.2 provides solid coding capabilities at competitive pricing, and Opus 4.6 delivers superior performance across most dimensions. You can start with one or both now and add Codex API when it becomes available, especially if using a unified API service that supports multiple providers.