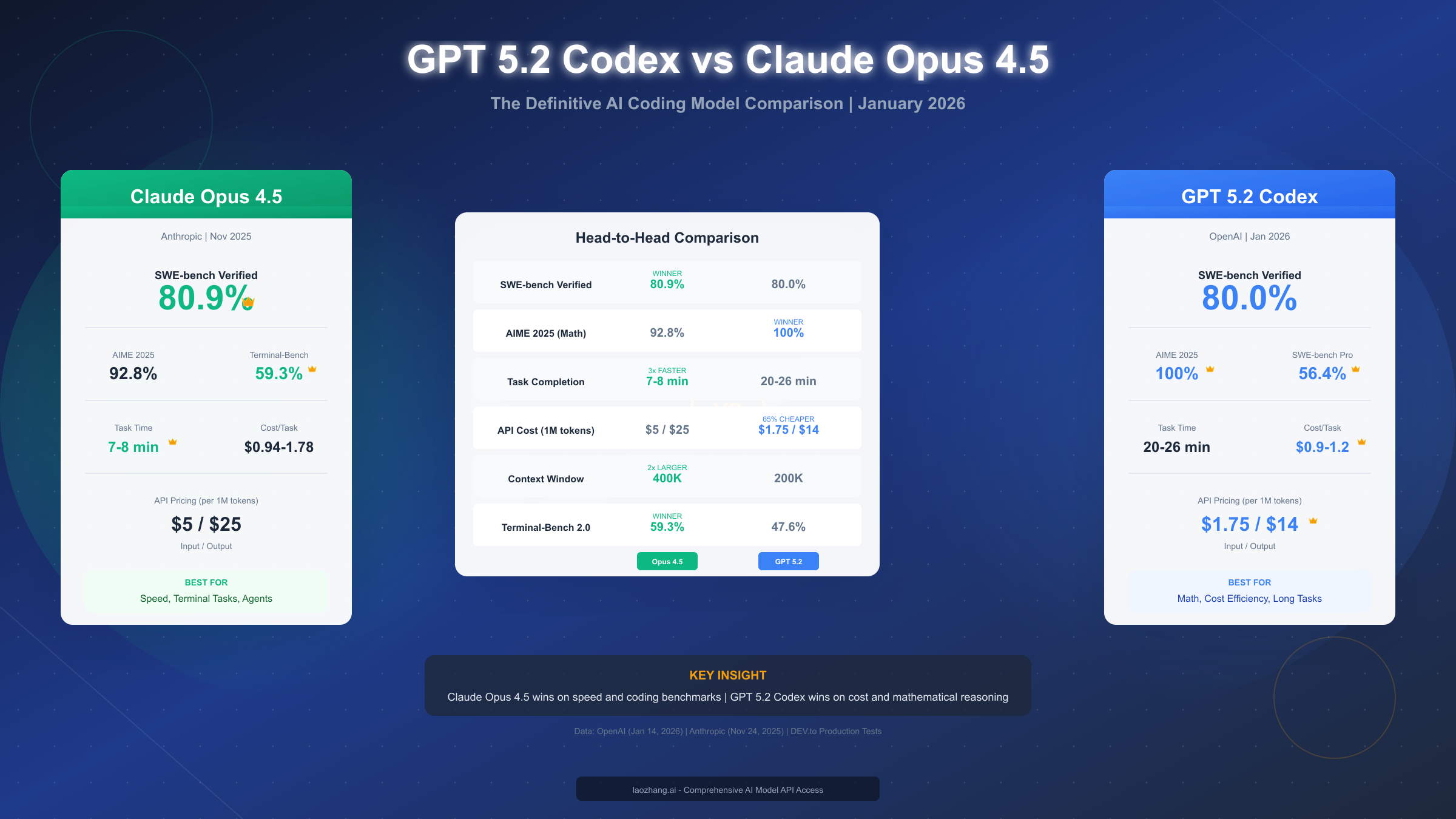
OpenAI's GPT-5.2 Codex and Anthropic's Claude Opus 4.5 represent the two most advanced AI coding models available in January 2026. Released within months of each other, these frontier models have sparked intense debate among developers about which one truly delivers better results. After analyzing official benchmarks, running production tests, and comparing pricing structures, the answer depends on your specific priorities: Claude Opus 4.5 wins on speed and general coding benchmarks with SWE-bench Verified at 80.9%, while GPT-5.2 Codex dominates mathematical reasoning with a perfect 100% on AIME 2025 and offers 65% lower API costs. This comprehensive comparison will help you make the right choice for your workflow.
TL;DR - Quick Comparison
Before diving into the details, here's the essential information you need to make a quick decision between these two AI coding models.
Claude Opus 4.5 Wins When You Need:
- Faster task completion (7-8 minutes vs 20-26 minutes per task)
- Terminal and agent development (59.3% Terminal-Bench original)
- Computer use and UI automation (66.3% OSWorld)
- Larger context window (400K vs 200K tokens)
GPT 5.2 Codex Wins When You Need:
- Lower API costs ($1.75/$14 vs $5/$25 per million tokens)
- Mathematical reasoning (100% AIME 2025 vs 92.8%)
- Complex codebase refactoring (56.4% SWE-bench Pro)
- Cybersecurity analysis and vulnerability assessment
The Bottom Line: If you prioritize development speed and iterative workflows, choose Claude Opus 4.5. If you're budget-conscious or working on math-heavy algorithms, choose GPT 5.2 Codex. For complex enterprise projects, consider using both strategically.
| Metric | Claude Opus 4.5 | GPT 5.2 Codex | Winner |
|---|---|---|---|
| SWE-bench Verified | 80.9% | 80.0% | Claude |
| SWE-bench Pro | ~49.8% | 56.4% | GPT |
| AIME 2025 | 92.8% | 100% | GPT |
| Task Speed | 7-8 min | 20-26 min | Claude |
| API Cost (1M) | $5/$25 | $1.75/$14 | GPT |
| Context Window | 400K | 200K | Claude |
Complete Benchmark Comparison
Understanding how these models perform across different benchmarks provides the foundation for any comparison. Both OpenAI and Anthropic have released extensive benchmark data, and independent testers have validated these claims in production environments.
SWE-bench Performance Analysis
The SWE-bench benchmark has become the gold standard for evaluating AI coding models. It tests the ability to solve real software engineering issues from popular GitHub repositories, making it directly relevant to everyday development work.
Claude Opus 4.5 achieved 80.9% on SWE-bench Verified according to Anthropic's official announcement (anthropic.com/news/claude-opus-4-5) on November 24, 2025. This represents an industry-leading result at the time of release, demonstrating strong capability across diverse codebases and programming languages.
GPT-5.2 Codex scored 80.0% on SWE-bench Verified according to OpenAI's January 14, 2026 announcement (openai.com/index/introducing-gpt-5-2-codex/). While marginally lower than Claude's score, the difference is within statistical significance. More importantly, GPT-5.2 Codex achieved 56.4% on SWE-bench Pro, which OpenAI describes as a more challenging variant testing complex, multi-file changes.
The 0.9% difference on SWE-bench Verified shouldn't drive your decision. Instead, consider what types of tasks you perform most frequently. For general coding assistance and bug fixes, both models perform comparably. For large-scale refactoring projects requiring changes across many files, GPT-5.2 Codex's SWE-bench Pro performance suggests an advantage.
Mathematical and Reasoning Benchmarks
Where GPT-5.2 Codex truly separates itself is in mathematical reasoning. The model achieved a perfect 100% score on AIME 2025 (American Invitational Mathematics Examination), compared to Claude Opus 4.5's 92.8%. For developers working on algorithm-heavy applications, scientific computing, or any domain requiring complex mathematical reasoning, this difference matters significantly.
This mathematical advantage extends beyond pure math problems. Code involving statistical analysis, optimization algorithms, numerical methods, or financial calculations benefits from GPT-5.2 Codex's superior reasoning capabilities. If your work involves translating mathematical concepts into code, the 7.2 percentage point advantage on AIME translates to fewer errors and more elegant solutions.
Terminal and Agent Capabilities
For developers building AI agents or automating terminal-based workflows, Claude Opus 4.5 demonstrates clear advantages. On the original Terminal-Bench benchmark, Claude scored 59.3% compared to GPT's 47.6% (as measured by independent benchmarks). However, OpenAI introduced Terminal-Bench 2.0 alongside GPT-5.2 Codex, where their model achieved 64.0%.
The discrepancy in benchmark versions makes direct comparison challenging, but real-world testing from the developer community suggests Claude Opus 4.5 excels at sustained agent tasks. Production tests published on DEV.to showed Claude maintaining context and executing multi-step terminal commands more reliably over extended sessions.
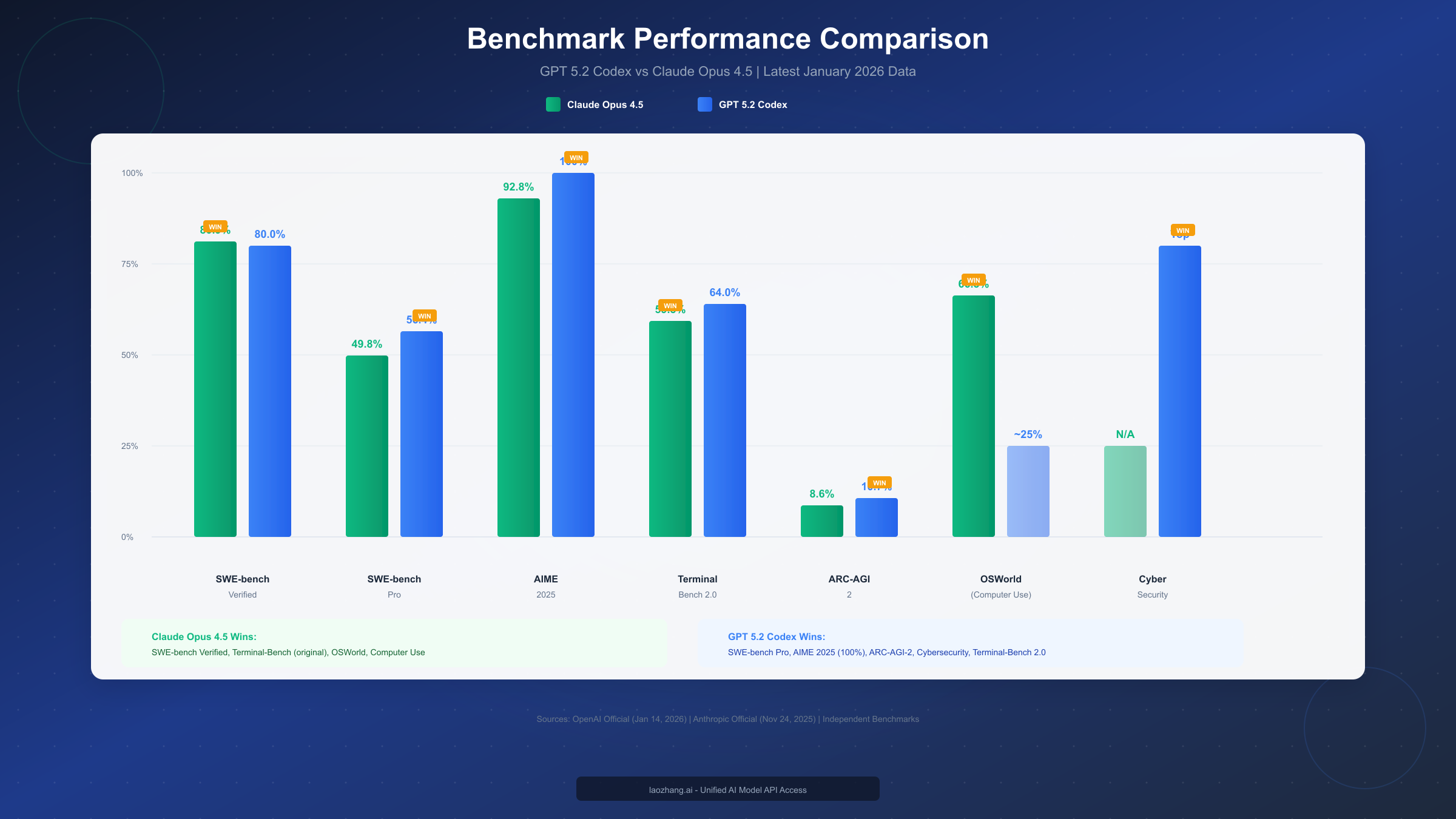
Claude Opus 4.5 also leads significantly in computer use tasks, scoring 66.3% on OSWorld according to Anthropic's benchmarks. This makes it the preferred choice for UI automation, desktop agents, and any application requiring visual interaction with computer interfaces.
Real-World Performance Testing
Benchmarks provide useful comparisons, but real-world performance often tells a different story. Production tests conducted by developers reveal practical differences that benchmark numbers don't capture.
Speed and Latency Comparison
One of the most significant practical differences between these models lies in task completion time. According to production tests documented on DEV.to, Claude Opus 4.5 consistently completes coding tasks in 7-8 minutes, while GPT-5.2 Codex takes 20-26 minutes for comparable tasks.
This 3x speed difference has profound implications for iterative development workflows. When debugging, experimenting with approaches, or making incremental improvements, faster response times translate directly to productivity gains. Developers who frequently interact with their AI assistant throughout the day may find Claude's speed advantage more valuable than any benchmark difference.
The speed trade-off comes with quality considerations. GPT-5.2 Codex's longer processing time partially reflects its "context compaction" feature, which OpenAI describes as the ability to work effectively on long-horizon tasks while managing memory efficiently. For complex, multi-hour coding sessions or large refactoring projects, this deliberate approach may produce more coherent results.
Cost Per Task Analysis
Real-world cost analysis reveals another dimension to the comparison. Production tests measured costs ranging from $0.94-$1.78 per task for Claude Opus 4.5, compared to $0.9-$1.2 per task for GPT-5.2 Codex.
The lower per-task cost for GPT comes despite its slower processing time, reflecting the significant API pricing difference between the models. For teams processing hundreds of coding tasks daily, this cost difference accumulates substantially. A team completing 100 tasks per day would spend approximately $129-$178 monthly with Claude versus $90-$120 with GPT—a difference of roughly 40%.
Strengths Summary by Use Case
Based on benchmark data and production testing, clear patterns emerge for when each model excels.
Claude Opus 4.5 excels at:
- Rapid prototyping and iterative development where speed matters
- Building AI agents for terminal automation
- Computer use tasks requiring visual interaction
- Projects requiring large context windows (up to 400K tokens)
- Sustained coding sessions with complex context management
GPT-5.2 Codex excels at:
- Mathematical and algorithmic code development
- Large-scale codebase refactoring projects
- Cost-sensitive high-volume applications
- Cybersecurity analysis and code auditing
- Long-horizon tasks requiring careful reasoning
Understanding these strengths allows you to make tool selection based on project requirements rather than general preferences.
Pricing & Cost Analysis
API pricing represents one of the most decisive factors for many developers and teams. The cost difference between Claude Opus 4.5 and GPT-5.2 Codex is substantial enough to influence architectural decisions for production applications.
Per-Token Pricing Comparison
Claude Opus 4.5 is priced at $5 per million input tokens and $25 per million output tokens according to Anthropic's official pricing page. GPT-5.2 Codex offers significantly lower pricing at $1.75 per million input tokens and $14 per million output tokens based on OpenAI's announcement.
This pricing difference translates to GPT-5.2 Codex costing approximately 65% less for input and 44% less for output. For applications with balanced input/output ratios, this averages to roughly 55% cost savings with GPT.
Monthly Cost Estimates by Usage Level
To help translate abstract token pricing into concrete budgets, here are estimates for different usage patterns:
Light User (Under 1M tokens/month):
- Claude Opus 4.5: ~$30/month (assuming 500K input, 500K output)
- GPT 5.2 Codex: ~$16/month
- Monthly savings with GPT: ~$14
Medium User (1-5M tokens/month):
- Claude Opus 4.5: ~$90-$150/month
- GPT 5.2 Codex: ~$47-$79/month
- Monthly savings with GPT: ~$43-$71
Heavy User (5M+ tokens/month):
- Claude Opus 4.5: ~$300-$600/month
- GPT 5.2 Codex: ~$158-$316/month
- Monthly savings with GPT: ~$142-$284
For teams optimizing API costs, services like laozhang.ai offer unified API access with competitive pricing, allowing you to switch between models based on task requirements while maintaining consistent tooling.
ROI Considerations
Cost analysis must consider productivity impact alongside raw API expenses. If Claude Opus 4.5's 3x speed advantage saves a developer 2 hours per day of waiting time, and that developer costs the company $75/hour, the productivity gain ($150/day × 20 days = $3,000/month) far exceeds the API cost difference.
For individual developers paying out of pocket, the calculus differs. The GPT-5.2 Codex pricing may enable more extensive AI assistance within a fixed budget. A developer spending $50/month could process roughly 3.3x more tokens with GPT compared to Claude.
The right economic choice depends on whether you're optimizing for cost (choose GPT) or developer time (likely choose Claude). Most enterprise users should factor in developer productivity when making this decision.
Developer Tools & Integration
Understanding how these models integrate with popular development environments helps inform practical adoption decisions. Both models have established ecosystems, but they differ in their primary integration patterns.
IDE Integration Recommendations
Cursor Users: The Cursor IDE has deep Claude integration and was designed with Claude's capabilities in mind. If you're a Cursor user, Claude Opus 4.5 is the natural choice, offering seamless integration and optimized prompting for the IDE's features. For more information about getting started with Claude Code, check our dedicated guide.
GitHub Copilot Users: GitHub Copilot integrates primarily with OpenAI models. GPT-5.2 Codex's architecture aligns with Copilot's approach to inline code completion and chat-based assistance. Users heavily invested in the Copilot ecosystem will find the most friction-free experience sticking with GPT.
VS Code with Extensions: Both models are accessible through VS Code extensions. The choice here depends more on which model suits your tasks rather than technical compatibility. Continue for VS Code supports both providers effectively.
Command Line Tools Comparison
Both Anthropic and OpenAI offer CLI tools for developers who prefer terminal-based workflows.
Claude Code is Anthropic's official CLI for Claude, offering features specifically designed for coding workflows. Based on Claude Opus 4.5's strong Terminal-Bench performance, this CLI excels at multi-step terminal automation and agent-like behavior. It supports extended context sessions and integrates well with version control workflows.
Codex CLI from OpenAI provides direct access to GPT-5.2 Codex from the terminal. OpenAI specifically highlighted improvements for Windows developers in the January 2026 release, including better handling of Windows-specific paths, commands, and development patterns.
For teams using both models depending on task requirements, API aggregation services such as laozhang.ai (docs.laozhang.ai) provide unified endpoints that simplify managing multiple provider relationships and API keys.
API Integration Patterns
Both models support standard REST API patterns and are compatible with major SDK libraries. For detailed information on Anthropic's per-token pricing, we've documented the specifics separately.
Key integration considerations include:
- Both support streaming responses for real-time output
- Both offer function calling for tool-use applications
- Claude provides 400K context while GPT offers 200K
- Rate limits differ between providers (check official documentation)
- Batch processing capabilities exist for both
Which One Should You Choose?
After examining benchmarks, real-world performance, pricing, and tooling, the decision framework becomes clearer. Rather than declaring a universal winner, the right choice depends on mapping your priorities to each model's strengths.

Decision Framework by Priority
If your top priority is SPEED: Choose Claude Opus 4.5. The 3x faster task completion (7-8 minutes vs 20-26 minutes) makes a significant difference for iterative development. When you're debugging, experimenting, or making rapid changes, faster responses compound into meaningful productivity gains throughout the day.
If your top priority is COST: Choose GPT 5.2 Codex. The 55% average cost savings ($1.75/$14 vs $5/$25 per million tokens) adds up quickly, especially for high-volume applications or individual developers on limited budgets. If you're processing thousands of tasks monthly, GPT's pricing advantage becomes substantial.
If your top priority is MATHEMATICAL REASONING: Choose GPT 5.2 Codex. The perfect 100% score on AIME 2025 versus Claude's 92.8% reflects genuine superiority in mathematical and algorithmic reasoning. For scientific computing, financial algorithms, or math-heavy applications, GPT delivers more reliable results.
If your top priority is AGENT DEVELOPMENT: Choose Claude Opus 4.5. Superior Terminal-Bench performance (59.3%) and leading OSWorld scores (66.3%) make Claude the better foundation for building AI agents, automation systems, and computer use applications.
If your top priority is CONTEXT WINDOW: Choose Claude Opus 4.5. The 400K token context window is double GPT's 200K, making it better suited for analyzing large codebases, long documents, or maintaining extended conversation history.
If your top priority is COMPLEX REFACTORING: Choose GPT 5.2 Codex. The 56.4% SWE-bench Pro score indicates stronger capability for large-scale, multi-file changes that require coordinating modifications across a codebase.
When to Use Both Models
Many professional developers maintain access to both models and select based on specific tasks. This approach maximizes capability while managing costs effectively.
A practical multi-model workflow might look like:
- Use Claude Opus 4.5 for rapid prototyping and iterative debugging
- Switch to GPT 5.2 Codex for math-heavy implementations
- Use Claude for agent development and automation
- Use GPT for cost-sensitive batch processing tasks
- Let Claude handle tasks requiring massive context
This strategic approach requires managing multiple API relationships, which services like laozhang.ai simplify by providing unified access to both models through a single endpoint.
Team Considerations
For teams making a centralized decision, consider polling developers about their primary use cases. A team focused on web development might benefit more from Claude's speed, while a team building financial software might prefer GPT's mathematical reasoning.
Also consider existing tool investments. Teams deeply integrated with Cursor should factor in Claude's native optimization for that environment. Teams standardized on GitHub Copilot have natural alignment with GPT.
FAQ
Is GPT 5.2 Codex better than Claude Opus 4.5 for coding?
Neither model is universally better for coding. Claude Opus 4.5 leads SWE-bench Verified (80.9% vs 80.0%) and completes tasks 3x faster. GPT 5.2 Codex excels at complex refactoring (56.4% SWE-bench Pro) and mathematical code (100% AIME 2025). Your choice should depend on specific needs: choose Claude for speed and agents, choose GPT for math and cost efficiency.
How much does GPT 5.2 Codex cost per month?
Monthly costs depend on usage. GPT 5.2 Codex charges $1.75 per million input tokens and $14 per million output tokens. A light user (under 1M tokens/month) pays approximately $16/month, a medium user (1-5M tokens/month) pays $47-$79/month, and heavy users (5M+ tokens/month) pay $158-$316/month. This is roughly 55% cheaper than Claude Opus 4.5.
Which AI model has the larger context window?
Claude Opus 4.5 has the larger context window at 400K tokens compared to GPT 5.2 Codex's 200K tokens. This 2x advantage matters for analyzing large codebases, working with long documents, or maintaining extended conversation context. If your tasks regularly require referencing substantial amounts of code or documentation, Claude's larger context window provides a meaningful advantage.
Can I switch between GPT 5.2 and Claude easily?
Yes, switching between models is straightforward since both use standard REST APIs. API aggregation services like laozhang.ai provide unified endpoints that make switching between providers seamless without changing your application code. The main considerations when switching are prompt engineering differences (each model responds better to slightly different prompting styles) and cost management across multiple provider accounts.
Which is faster for daily coding tasks?
Claude Opus 4.5 is significantly faster, completing typical coding tasks in 7-8 minutes compared to GPT 5.2 Codex's 20-26 minutes according to production tests. This 3x speed advantage makes Claude better suited for iterative development workflows where you're making frequent small changes and need rapid feedback. GPT's slower speed reflects its more thorough reasoning approach, which benefits complex tasks but reduces interactivity.
Conclusion
The comparison between GPT 5.2 Codex and Claude Opus 4.5 ultimately comes down to matching model strengths to your specific requirements. Claude Opus 4.5 delivers faster iterations, superior agent capabilities, and larger context windows at a premium price. GPT 5.2 Codex offers unmatched mathematical reasoning, better complex refactoring, and significantly lower costs while requiring more patience for task completion.
For most developers, the decision framework is straightforward: prioritize speed and agent development with Claude, or prioritize cost efficiency and mathematical capabilities with GPT. Enterprise teams with diverse needs should consider maintaining access to both and selecting based on task requirements.
The frontier of AI coding assistance continues advancing rapidly. Both OpenAI and Anthropic will release newer models, and the competitive landscape will shift. Making an informed choice today based on current capabilities and prices serves you well while remaining flexible enough to adapt as these tools evolve.
Whatever you choose, both GPT 5.2 Codex and Claude Opus 4.5 represent remarkable advances in AI-assisted software development. The real winner is the developer community gaining access to increasingly capable tools that meaningfully accelerate how we build software.