
Short answer: start with Claude Sonnet 4.6 unless you already know your work regularly needs deeper reasoning, longer autonomous execution, or larger single-pass outputs. That is the cleanest reading of Anthropic's current product ladder as of March 19, 2026. The most important thing many ranking pages still miss is that this comparison changed on March 13, 2026: Anthropic's current docs now treat both Opus 4.6 and Sonnet 4.6 as 1M-context models at standard pricing, so Opus is no longer the only practical long-context lane inside Claude.
That does not mean the two models are interchangeable. Anthropic's current model overview still gives Opus 4.6 the highest intelligence position, a 128k max output ceiling, and moderate comparative latency, while Sonnet 4.6 is framed as the best balance of speed and intelligence, with 64k max output and fast comparative latency. Pricing is also materially different: Opus 4.6 is currently listed at $5 input / $25 output per million tokens, while Sonnet 4.6 is $3 input / $15 output. If you are paying by API usage, that is not a rounding-error difference.
So the real answer is simple: Sonnet 4.6 should be your default Claude model, and Opus 4.6 should be the upgrade path you reach for intentionally. This guide explains why, using current Anthropic pages checked on March 19, 2026, and separates the three decisions most comparison posts blur together: app-plan access, Claude Code access, and API economics.
TL;DR
If you only want one recommendation, choose Claude Sonnet 4.6 as your everyday Claude model. Choose Claude Opus 4.6 when the work is expensive to get wrong, requires longer chains of reasoning, or benefits from Opus's higher output ceiling.
| Category | Claude Opus 4.6 | Claude Sonnet 4.6 | Practical takeaway |
|---|---|---|---|
| Launch date | February 5, 2026 | February 17, 2026 | Both are current-generation Claude 4.6 models |
| Official role | Anthropic's smartest model for agents and coding | Anthropic's best speed-and-intelligence balance | Opus is the premium lane; Sonnet is the default lane |
| Base API price | $5 input / $25 output per 1M | $3 input / $15 output per 1M | Sonnet is materially cheaper for steady usage |
| Batch price | $2.50 input / $12.50 output | $1.50 input / $7.50 output | The price gap stays real even in batch mode |
| Context window | 1M tokens | 1M tokens | As of March 13, 2026, both 4.6 models now get 1M context at standard pricing |
| Max output | 128k | 64k | Opus has more headroom for big single-pass rewrites and outputs |
| Comparative latency | Moderate | Fast | Sonnet is the better default for interactive work |
| Consumer-plan role | Available on paid tiers above Free | Default on Free and Pro | Sonnet is the easier entry point |
| Claude Code access | Supported, but Pro users need extra usage to use Opus models | Supported by default | Many developers hit this operational difference before they hit a model-quality difference |
| Best fit | Deep research, hard code review, long-running agents, premium final passes | Everyday coding, writing, analysis, high-volume pipelines, fast iteration | Start with Sonnet and escalate when the task proves it needs Opus |
The cleanest way to phrase the verdict is this: Sonnet 4.6 is the model you should start with, and Opus 4.6 is the model you should justify.
What changed after the March 13, 2026 docs update
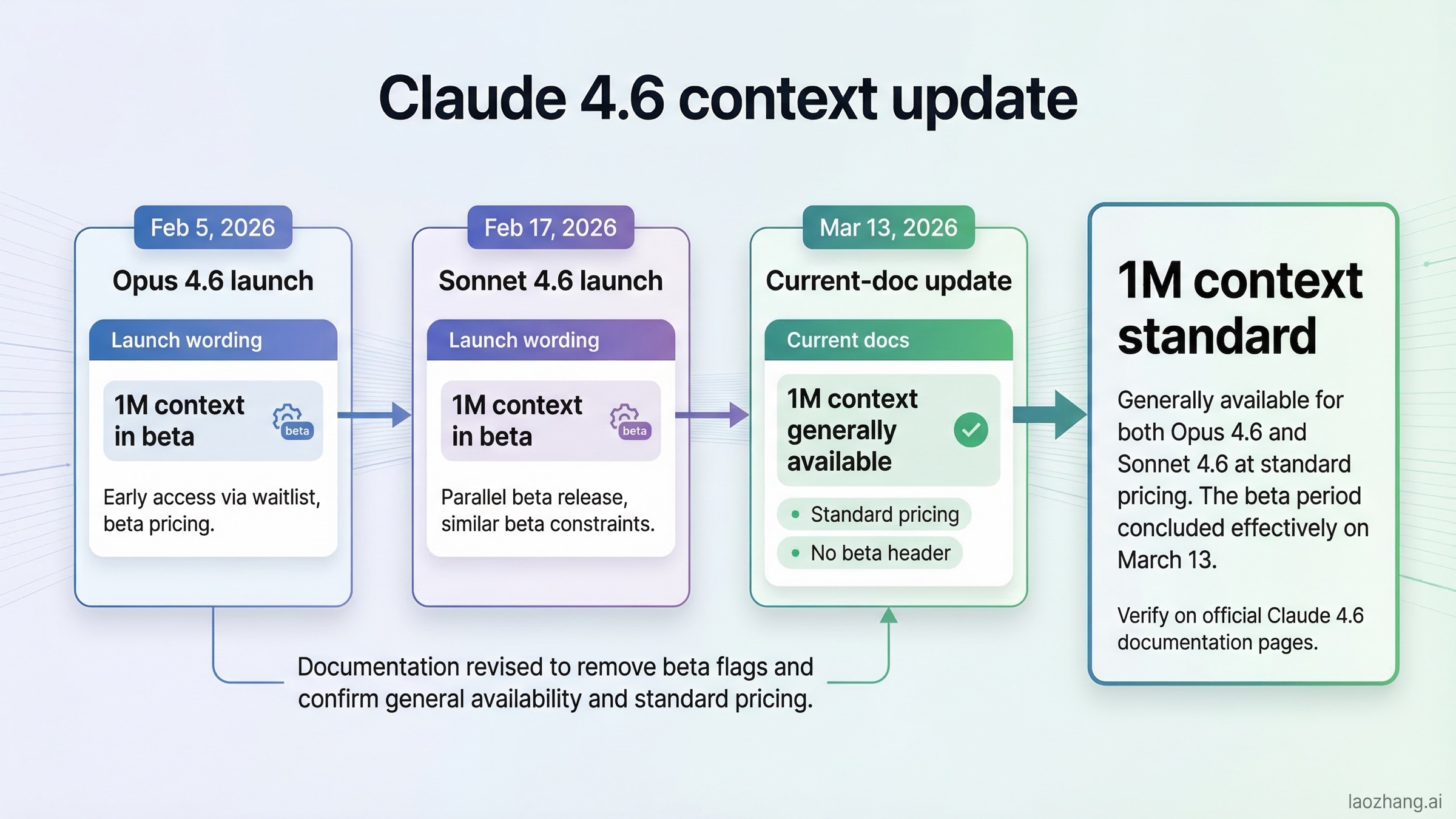
The most misleading thing on the current SERP is not a benchmark claim. It is a timeline problem.
Anthropic's original launch pages still preserve rollout-era wording. The Claude Opus 4.6 launch page from February 5, 2026 introduced Opus 4.6 with a 1M token context window in beta. The Claude Sonnet 4.6 launch page from February 17, 2026 also described Sonnet 4.6's 1M token context window in beta. If you stop there, the natural conclusion is that 1M context is still a special or limited rollout feature, and that Opus may still hold the stronger long-context position by default.
But Anthropic's current live docs tell a more up-to-date story. The current models overview lists both Opus 4.6 and Sonnet 4.6 with 1M-token context windows. The current context windows guide states plainly that Claude Opus 4.6 and Sonnet 4.6 have a 1M-token context window, while Sonnet 4.5 and Sonnet 4 still need the beta header beyond 200k tokens. Most importantly, Anthropic's release notes overview records that on March 13, 2026 the 1M-token context window became generally available for Claude 4.6 models at standard pricing, with no beta header required.
That update changes the shape of this comparison. Before March 13, context-window availability itself was a major divider. After March 13, it is not. You still need to care about long-context quality, yes, but the cleaner comparison now is:
- both models get 1M context
- both support adaptive thinking
- both sit in the same current-generation Claude family
- the remaining differences are price, latency, output cap, and reasoning ceiling
That is why older articles feel slightly off even when they are not technically dishonest. They are frozen at the launch-stage wording while the current docs have moved on.
Price, output headroom, and latency: the differences that still matter
Once you stop treating 1M context as the main divider, the practical tradeoff becomes much easier to understand.
First, price. Anthropic's current pricing page lists Opus 4.6 at $5 input / $25 output per million tokens and Sonnet 4.6 at $3 input / $15 output. Batch discounts preserve the same shape: Opus falls to $2.50 / $12.50, Sonnet to $1.50 / $7.50. In other words, Sonnet is not just slightly cheaper. It is the clearly cheaper model, whether you are running direct interactive calls or larger asynchronous batches.
Second, output headroom. Anthropic's current model table lists 128k max output for Opus 4.6 and 64k max output for Sonnet 4.6. That difference matters less for a quick answer in chat and much more for tasks like:
- large code rewrites that return a lot of generated output
- long structured reports
- wide refactors where the model needs to emit many coordinated edits
- workflows where you want one larger pass instead of breaking output into multiple turns
Third, latency posture. Anthropic explicitly labels Opus 4.6 as Moderate and Sonnet 4.6 as Fast in the current comparison table. That does not mean Sonnet wins every real benchmark or every workflow. It means Anthropic still wants users to think of Sonnet as the interactive default and Opus as the heavier lane you select when the task genuinely benefits from more model effort.
The table below captures the real decision levers better than most ranking pages do:
| Decision lever | Why Sonnet 4.6 wins | Why Opus 4.6 wins |
|---|---|---|
| Cost discipline | Lower base and batch pricing make it easier to keep as the default | Harder to justify as a blanket default if cost matters |
| Interactive speed | Fast latency is better for everyday iteration | Moderate latency is acceptable when correctness matters more than speed |
| Output size | Enough for normal coding, writing, and analysis loops | Better for bigger final outputs and longer single-pass rewrites |
| Hard reasoning | Often good enough for normal work | Better when the task is long-horizon, ambiguous, or high-stakes |
| Premium final pass | Less expensive for broad deployment | More defensible when you need the strongest Claude result, not just a fast one |
So if your team is asking, "Which is the better default?", price and latency make the answer lean toward Sonnet 4.6. If your team is asking, "Which is the better ceiling inside Claude?", output headroom and reasoning make the answer lean toward Opus 4.6.
If you want the broader frontier context around Anthropic's premium model, our Claude Opus 4.6 vs GPT-5.3 comparison goes deeper on where Opus sits against competing top-tier models.
When Sonnet 4.6 is enough and when Opus 4.6 is worth paying for
Anthropic itself gives the cleanest starting heuristic in its model-picking tutorial: Sonnet is the daily driver, and Opus is for tasks that genuinely need deeper sustained thinking. That guidance is broad, but it becomes much more useful when you translate it into workflow language.
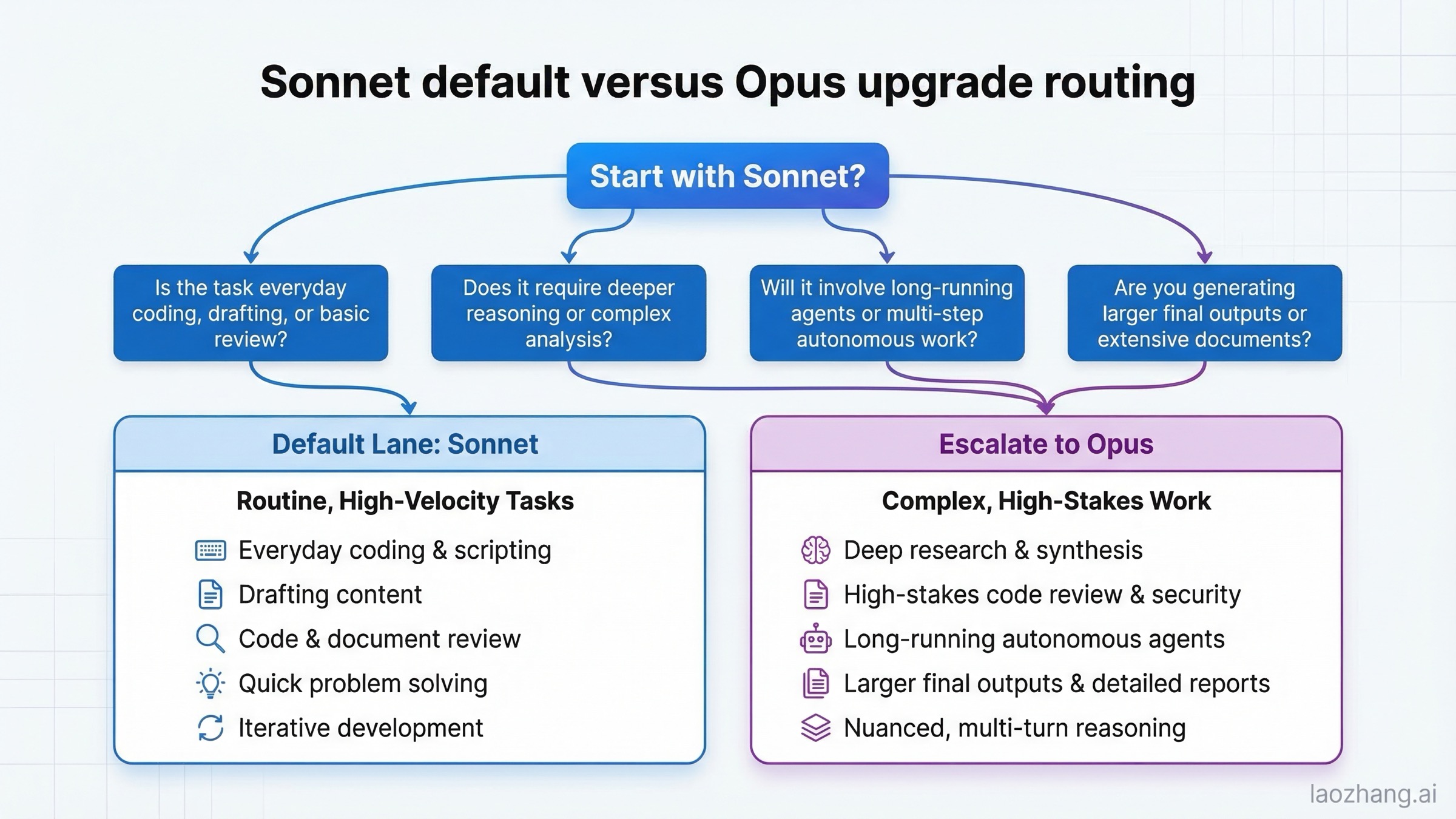
Sonnet 4.6 is enough for most everyday coding, writing, analysis, and review work. It is the better choice when the task is repeated often, when throughput matters, when you are iterating quickly, or when the cost of running the stronger model everywhere would add up with little practical gain. If you are reviewing normal pull requests, summarizing documents, drafting product copy, writing tests, or using Claude as a strong day-to-day coding assistant, Sonnet is usually the right first stop.
Opus 4.6 is worth paying for when the task is expensive to get wrong or hard to recover from. That includes deep research, difficult code review, large codebase migration work, multi-step planning with lots of branching, and tasks where the model needs to stay coherent over a longer chain without losing the thread. Anthropic's own Opus launch page emphasizes precisely those kinds of jobs: harder coding, longer-running agentic tasks, better debugging, and more reliable work in larger codebases.
This is also where the community friction starts to make sense. Some users are perfectly happy staying on Sonnet because it is cheaper, faster, and good enough most of the time. Others still pay for Opus because they care less about average-case throughput and more about failure tolerance on harder tasks. Those are not contradictory user experiences. They are evidence that the model split is real.
The most practical way to frame it is:
- use Sonnet 4.6 for the draft, the first implementation, or the daily conversation
- use Opus 4.6 for the final difficult pass, the harder code review, or the long-horizon problem
That is more defensible than either extreme of the current SERP: "always buy Opus" or "Sonnet makes Opus unnecessary." Both are too simplistic.
If your everyday workflow is Claude-native coding, it is also worth reading our Claude Code vs Codex guide, because the model choice and the product-surface choice are related but not identical.
Claude app, Claude Code, and API: why the right answer changes by surface
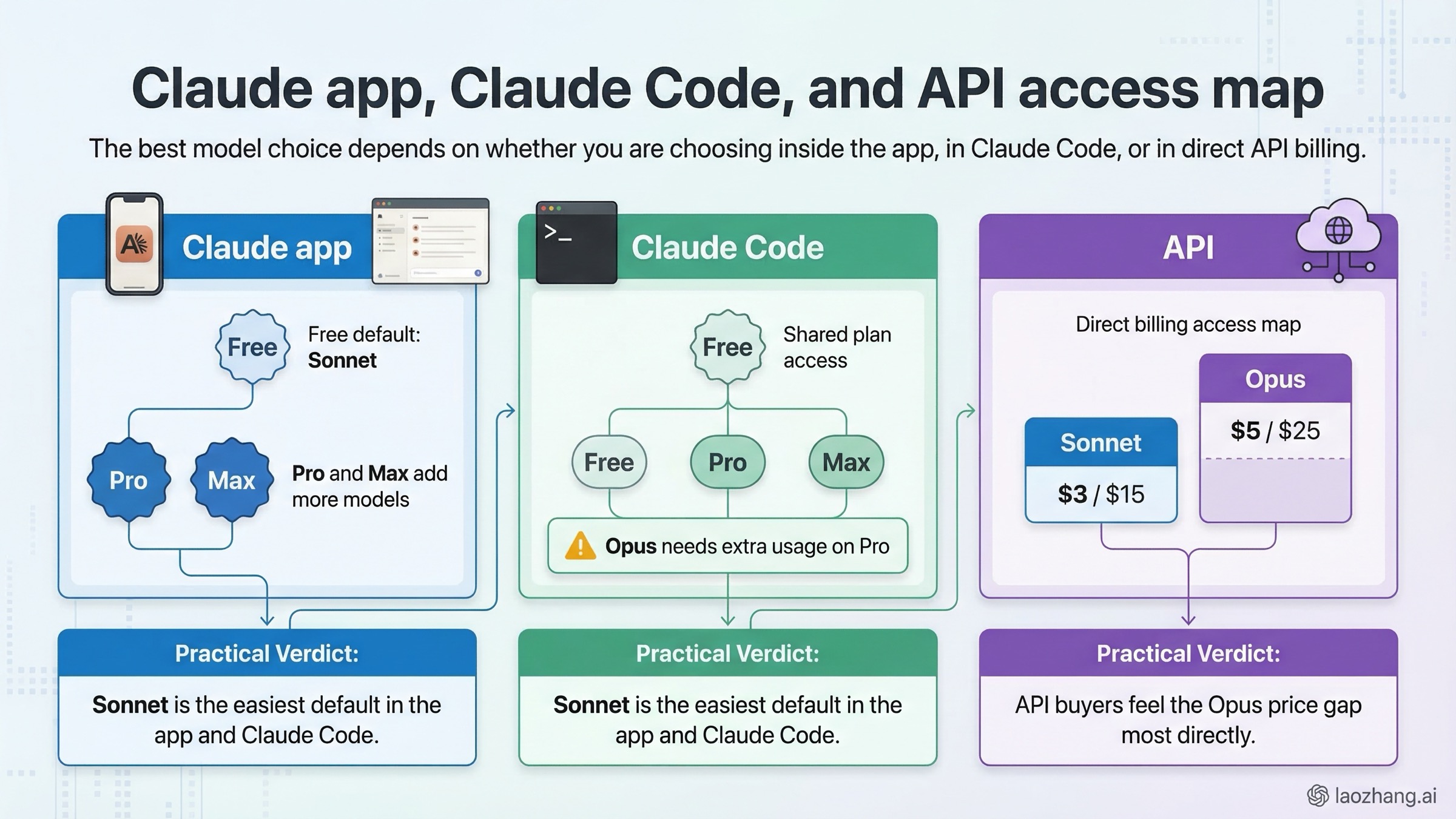
Many comparison pages silently assume that every reader is making the choice in the API. That is wrong. A lot of users making this search are actually deciding in claude.ai or Claude Code, and the answer changes depending on surface.
Inside the Claude app, the ladder is relatively clear. Anthropic's current pricing page and its choosing-the-right-model guide show that Free includes Sonnet, while Pro and Max add access to more models, including Opus. That means the default non-technical answer is already biased toward Sonnet. For many users, Sonnet is not just the better-value model. It is the first model they can meaningfully use at all.
Inside Claude Code, the operational difference becomes more specific. Anthropic's current Claude Code model configuration help page lists both claude-sonnet-4-6 and claude-opus-4-6 as supported models, but it also states that Pro users only get Opus models after enabling and purchasing extra usage. That is a real blocker, and it is one most generic model comparison posts never mention. If your team is standardizing on Claude Code, Sonnet often wins by default simply because it is the easier model to deploy broadly without extra spending friction.
Inside the API, the decision becomes more economic. There, you are paying directly for each token, and the gap between $3 / $15 and $5 / $25 matters immediately. In API-heavy workflows, "just use Opus everywhere" is often the wrong answer unless the task quality actually justifies the difference. If you are running high-volume automated workflows, Sonnet is much easier to keep as the default lane and Opus is much easier to reserve for the smaller slice of requests that genuinely benefit.
This is why two smart teams can look at the same two models and make different choices:
- a Claude app user may say "Opus is worth it for hard work"
- a Claude Code team may say "Sonnet is the better operational default"
- an API buyer may say "Sonnet should handle 80% of traffic, with Opus only on escalated jobs"
All three can be right, because they are optimizing for different surfaces.
For teams planning longer-running Claude workflows, our Claude Code Agent Teams guide is also relevant because multi-agent or multi-session work magnifies both rate-limit pressure and model-cost differences.
Best-practice routing for teams: default, premium, and hybrid lanes
The most useful conclusion from all of this is not "pick one forever." It is to build a simple routing rule that matches cost to task difficulty.
For most teams, the cleanest setup is:
- default lane: Sonnet 4.6 for everyday coding, drafting, document analysis, and first-pass implementation
- premium lane: Opus 4.6 for complex review, ambiguous planning, larger final outputs, and expensive-to-fail tasks
- hybrid lane: Sonnet first, Opus second when the first pass stalls, misses edge cases, or needs a stronger final review
That hybrid approach fits Anthropic's own published model ladder better than treating Opus as the mainline default. It also scales better financially, especially in API or Claude Code workflows where heavy usage can surface cost or limit pressure quickly. If you are already dealing with quota pressure, our Claude Code rate limit guide explains why using the heavier model as the default can make those problems appear much sooner.
The article-level recommendation can therefore stay crisp:
Use Sonnet 4.6 by default.
Escalate to Opus 4.6 when one of these is true:
- the task requires deeper reasoning over a longer chain
- the model needs to stay coherent over a harder multi-step job
- the output is large enough that 128k headroom helps
- the work is costly enough that a stronger final pass is worth the extra spend
That is a much better buyer answer than pretending the premium model should always be the standard model.
FAQ
Is Claude Opus 4.6 better than Sonnet 4.6?
Yes at the top end, but not as a universal default. Anthropic's current docs still place Opus 4.6 above Sonnet 4.6 on intelligence, and Opus has the larger 128k output ceiling. But Sonnet 4.6 is cheaper, faster, and now shares the same 1M-token context window at standard pricing. So Opus is the better premium model, while Sonnet is the better default model.
Should I start with Sonnet 4.6 or Opus 4.6?
Start with Sonnet 4.6 unless you already know your work regularly needs deeper reasoning or larger outputs. Anthropic's own model-picking guide says Sonnet is the versatile default and Opus should be reserved for tasks that genuinely need sustained thinking.
Does Opus 4.6 still have a context advantage over Sonnet 4.6?
Not in the simple headline way many older pages suggest. As of the current official docs checked on March 19, 2026, both Opus 4.6 and Sonnet 4.6 have 1M-token context windows at standard pricing. The real remaining differences are price, latency, max output, and reasoning ceiling.
Is Opus 4.6 worth the extra API cost?
Sometimes, yes. It is worth it for high-stakes reasoning, difficult code review, long-running agentic work, and larger final outputs. It is usually not worth using as a blanket default for all everyday traffic when Sonnet 4.6 can handle the majority of normal work for materially less money.
Can I use Opus 4.6 in Claude Code on a Pro plan?
Not automatically. Anthropic's current Claude Code help page says that on a Pro plan you only get Opus models in Claude Code after enabling and purchasing extra usage. That is one reason many developers effectively default to Sonnet even when they like Opus in theory.