
As of March 20, 2026, Gemini 3 Flash is the better pick if you need the stronger Gemini 3-series model for coding, agentic workflows, and Computer Use. Gemini 3.1 Flash-Lite is the better pick if your workload is high-volume, latency-sensitive, and cost-sensitive, and you do not need the extra capability lane that 3 Flash is designed to provide. That is the real answer behind this keyword.
The confusing part is that this is not a neat same-tier comparison. Google does not currently publish one clean official benchmark page that pits gemini-3-flash-preview directly against gemini-3.1-flash-lite-preview in a single table. Instead, the official evidence is spread across the pricing page, the two official model pages for Gemini 3 Flash Preview and Gemini 3.1 Flash-Lite Preview, the Gemini API release notes, the rate-limits page, and separate DeepMind performance pages for Gemini 3 Flash and Gemini 3.1 Flash-Lite.
That means the safest way to answer the query is not to invent a fake benchmark winner. The safest way is to compare the official fields that matter in production: price, tool support, batch ceilings, model positioning, and where each model actually fits.
TL;DR
If you only need the decision, use this rule:
- Choose Gemini 3 Flash when stronger reasoning, better agentic coding, broader 3-series product support, and
Computer Usematter more than raw token cost. - Choose Gemini 3.1 Flash-Lite when your work is mostly translation, extraction, labeling, routing, or other high-volume lanes where lower price and higher throughput matter more than premium tooling.
- Use both if you run mixed workloads. This is the most defensible setup for many teams right now.
The current official comparison looks like this:
| Area | Gemini 3.1 Flash-Lite | Gemini 3 Flash | What it means |
|---|---|---|---|
| Status | Preview | Preview | Neither is the stable default lane yet |
| Launch date | March 3, 2026 | December 17, 2025 | Flash-Lite is newer, but not necessarily "higher tier" |
| Model ID | gemini-3.1-flash-lite-preview | gemini-3-flash-preview | Route explicitly, do not assume aliases |
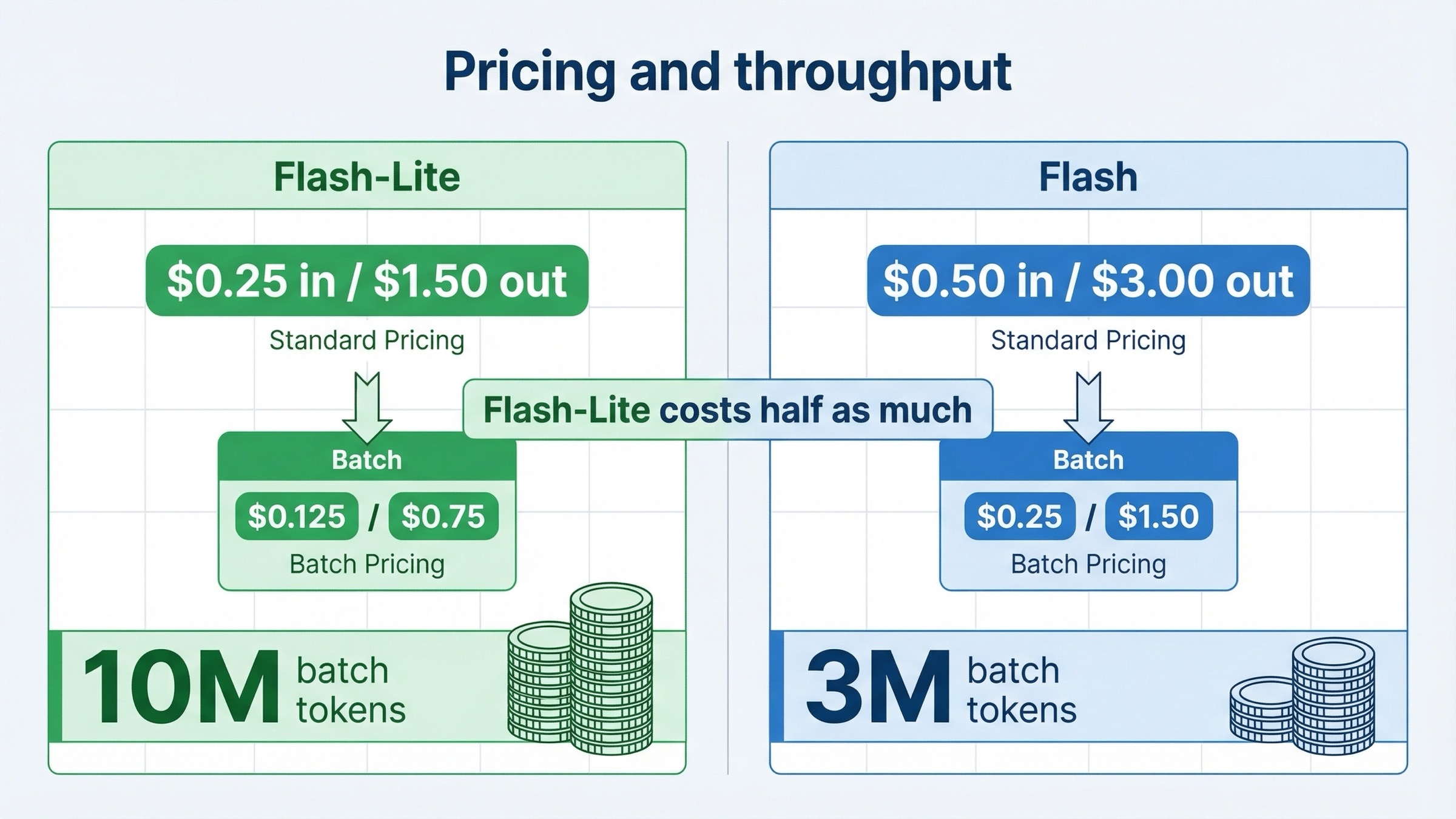
| Standard input price | Free, then $0.25 / 1M | Free, then $0.50 / 1M | Flash-Lite is half the input price |
| Standard output price | Free, then $1.50 / 1M | Free, then $3.00 / 1M | Flash-Lite is half the output price |
| Batch price | Free, then $0.125 in / $0.75 out | No free batch tier, then $0.25 in / $1.50 out | Flash-Lite is clearly better for cheap async throughput |
| Context window | 1,048,576 tokens | 1,048,576 tokens | Context size is not the differentiator |
| Max output | 65,536 tokens | 65,536 tokens | Output ceiling is also the same |
| Computer Use | Not supported | Supported | This is one of the biggest real workflow gaps |
| Search / Maps grounding | Supported, but no free-tier grounding | Supported, but no free-tier grounding | Grounding does not rescue Flash-Lite into a full Flash replacement |
| Best fit | Cheap high-volume reasoning and routing | Stronger frontier-at-speed reasoning and agentic coding | This is the real routing split |
The short version is simple: Gemini 3 Flash is the premium fast lane. Gemini 3.1 Flash-Lite is the cheap fast lane.
Why This Comparison Feels Odd
This keyword feels odd because people usually expect product names to map neatly onto tiers. In practice, they often do not.
Google's own descriptions make the split clear. The official Gemini 3 Flash model page calls it the company's best model for multimodal understanding and its most powerful agentic and vibe-coding model yet. The official Gemini 3.1 Flash-Lite page describes Flash-Lite as the most cost-efficient multimodal model for high-frequency lightweight tasks, high-volume agentic work, simple data extraction, and extremely low-latency use cases.
Those are different jobs.
So the question is not really "is Flash-Lite the same thing but newer?" The question is:
Do you need Google's stronger fast model, or do you need Google's cheapest serious 3-series throughput lane?
That is also why so many shallow comparison pages miss the point. They treat the keyword like a direct benchmark shootout. The live official picture says this is closer to a routing decision between two different fast lanes:
- a stronger lane for harder work
- a cheaper lane for simpler work at scale
If you keep that frame in mind, the rest of the comparison gets much easier.
Pricing, Free Tier, Grounding, And Batch Throughput On March 20, 2026
Pricing is the cleanest official difference.
On the official Gemini Developer API pricing page, the current standard rates are:
- Gemini 3.1 Flash-Lite Preview: free tier, then
\$0.25input and\$1.50output per 1M tokens - Gemini 3 Flash Preview: free tier, then
\$0.50input and\$3.00output per 1M tokens
That means Gemini 3 Flash currently costs about 2x more on both input and output tokens.
For many teams, that alone is enough to narrow the answer. If your workload is dominated by:
- translation
- structured extraction
- document labeling
- routing
- summarization at scale
- other low-margin, high-volume tasks
then Flash-Lite starts with a major economic advantage before benchmarks even enter the conversation.
Batch pricing pushes the same conclusion harder:
- Gemini 3.1 Flash-Lite Batch: free tier, then
\$0.125input and\$0.75output - Gemini 3 Flash Batch: no free batch tier, then
\$0.25input and\$1.50output
That is not a tiny gap. It is another straight 2x delta, and the free-batch entry point is more generous on Flash-Lite.
There are two other money details worth noticing:
- Context caching is a little friendlier on 3 Flash.
The pricing page currently shows free-tier context caching for Gemini 3 Flash, while Gemini 3.1 Flash-Lite lists no free-tier caching and only paid caching rates. That does not erase the broader price gap, but it matters if your workload depends heavily on repeated long prompts and cache reuse. If caching cost is part of your architecture, our Gemini API context caching cost guide is worth checking before you switch.
- Grounding is not a free-tier advantage for either model.
Both model pages list Search grounding and Google Maps grounding as supported capabilities. But the pricing page currently shows no free-tier grounding for either model. In paid usage, both list 5,000 free prompts per month before charging for search or maps queries. So if you were hoping that one of these two models gives you a special free grounding lane, the answer is no.
The high-volume throughput story also favors Flash-Lite on the public rate-limits page. Google's Tier 1 Batch API table lists:
- Gemini 3.1 Flash-Lite Preview: 10,000,000 enqueued batch tokens
- Gemini 3 Flash Preview: 3,000,000 enqueued batch tokens
That is one of the most practical official differences in the whole comparison. If you run big asynchronous queues, the cheaper model is also the one with the larger public batch ceiling. That is exactly why Flash-Lite makes sense as a throughput lane even for teams that still keep 3 Flash around for harder tasks.
If price and quota planning are your main blockers, it is also worth cross-checking our Gemini 3 Flash API price guide and Gemini API rate-limits-per-tier guide.
Capability Gaps That Matter More Than Naming

Once price is out of the way, the next question is whether Gemini 3 Flash is actually more useful in the places where harder capability matters.
The official model pages say yes.
Both models share the same headline I/O shape:
- text output only
- text, image, video, audio, and PDF inputs
- 1,048,576 input tokens
- 65,536 output tokens
- Batch API support
- Search grounding
- Maps grounding
- File Search
- Function calling
- Structured outputs
- Code execution
- Thinking
- Caching
So if you stop reading at the capability checklist, the two pages look closer than they really are.
The difference shows up in what Google emphasizes and what it withholds.
Gemini 3 Flash supports Computer Use. Gemini 3.1 Flash-Lite does not.
That alone is enough to separate the models for a lot of agentic buyers. If your workflow includes real UI interaction or you are building toward tool-heavy browser automation, 3 Flash has a concrete product-surface advantage that Flash-Lite simply does not have today.
The second difference is positioning. Google frames Gemini 3 Flash as the stronger frontier-at-speed option for:
- agentic coding
- advanced reasoning
- multimodal understanding
- long-context understanding
Google frames Gemini 3.1 Flash-Lite as the cost-efficient lane for:
- translation
- simple extraction
- lightweight reasoning
- routing
- extremely low-latency applications
That is why I would not describe Flash-Lite as a direct replacement for 3 Flash. It is better understood as the 3-series value lane. It can absolutely be the right default for huge amounts of traffic. But the official positioning does not say it is the smarter model; it says it is the cheaper and faster-for-volume model.
There is also a distribution difference that helps explain user perception. DeepMind's Gemini 3 Flash page lists broad availability across the Gemini app, Gemini CLI, Gemini API, Google AI Studio, Vertex AI, Gemini Enterprise, Google AI Mode, Antigravity, and Android Studio. DeepMind's Gemini 3.1 Flash-Lite page is much narrower: Google AI Studio, Gemini API, and Vertex AI.
That does not matter for every API buyer, but it is another clue that Google treats 3 Flash as the broader flagship fast model and Flash-Lite as the narrower high-volume utility lane.
What Official Performance Pages Suggest, And What They Do Not Prove
This is the part where a lot of comparison pages become sloppy.
Google has excellent official performance pages for both models:
Those pages are useful, but they are not the same thing as one official head-to-head shootout page for this exact keyword.
The Gemini 3.1 Flash-Lite model card also adds an explicit methodology warning: Google says the reported performance results were computed with improved evaluations and are not directly comparable with performance results found in previous Gemini model cards. That is exactly why this article should stay careful.
With that caveat in place, the official DeepMind pages still tell a useful directional story.
On overlapping benchmark names, Gemini 3 Flash posts stronger public numbers than Gemini 3.1 Flash-Lite on the DeepMind product pages:
| Directional official signal | Gemini 3.1 Flash-Lite | Gemini 3 Flash | Direction |
|---|---|---|---|
| GPQA Diamond | 86.9% | 90.4% | 3 Flash |
| MMMU-Pro | 76.8% | 81.2% | 3 Flash |
| CharXiv | 73.2% | 80.3% | 3 Flash |
| Video-MMMU | 84.8% | 86.9% | 3 Flash |
| FACTS | 40.6% | 61.9% | 3 Flash |
| SimpleQA | 43.3% | 68.7% | 3 Flash |
| MRCR v2 at 128k | 60.1% | 67.2% | 3 Flash |
| MRCR v2 at 1M | 12.3% | 22.1% | 3 Flash |
| Input price | $0.25 | $0.50 | Flash-Lite |
| Output price | $1.50 | $3.00 | Flash-Lite |
The clean reading is:
- Gemini 3 Flash has the stronger official capability story
- Gemini 3.1 Flash-Lite has the stronger official cost-efficiency story
That is exactly what the product names do not tell you by themselves.
If your task is closer to "I need the strongest fast model I can buy without moving up to Pro," the official evidence leans toward 3 Flash. If your task is closer to "I need a cheap, high-volume, fast-enough model that still belongs to the Gemini 3 family," the official evidence leans toward 3.1 Flash-Lite.
So the question is not whether one model "wins everywhere." It does not. The question is whether you want to pay a premium for the stronger capability lane.
Which Model To Use For Which Workload
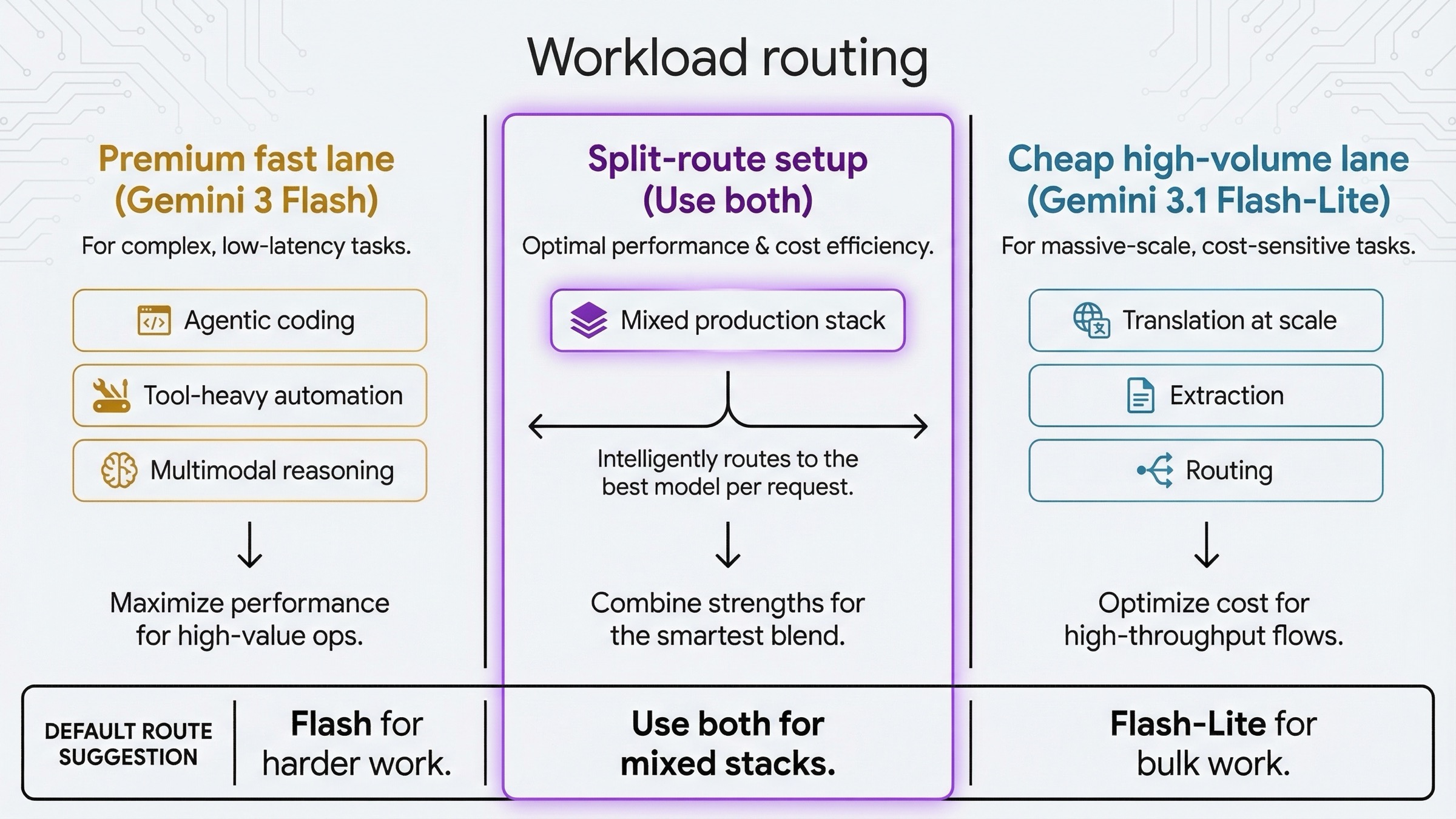
The most useful way to finish the comparison is to turn it into routing advice.
| Workload | Pick first | Why |
|---|---|---|
| Agentic coding | Gemini 3 Flash | Google's own positioning and benchmark story are strongest here |
| Tool-heavy automation | Gemini 3 Flash | Computer Use support is the clearest decisive feature gap |
| Harder multimodal reasoning | Gemini 3 Flash | Official DeepMind signals lean higher across overlapping reasoning and multimodal rows |
| Translation at scale | Gemini 3.1 Flash-Lite | This is one of Google's own highlighted Flash-Lite use cases |
| Structured extraction and labeling | Gemini 3.1 Flash-Lite | Cheaper output and higher batch ceilings matter more than premium tooling |
| High-volume routing and classifier layers | Gemini 3.1 Flash-Lite | The economics and throughput story are better |
| Latency-sensitive but simple support pipelines | Gemini 3.1 Flash-Lite | This is exactly the kind of cheap fast lane Flash-Lite is built for |
| Mixed production stacks | Both | Premium lane for hard tasks, cheap lane for bulk traffic |
There is one more practical point here: both models are still Preview. So the question is not which one is the stable long-term safe default. The question is which preview lane is worth your budget and rollout risk for the task you have.
If you want to understand how thinking controls affect that choice, our Gemini API thinking-level guide is a useful companion read.
How To Roll This Out Without Regretting It
The safest March 2026 answer is not "standardize on one model everywhere."
The safest answer is:
- Put Gemini 3.1 Flash-Lite on the cheap lane first.
Use it for translation, extraction, routing, tagging, summarization, and other tasks where the 2x price savings and larger public batch ceiling help immediately.
- Keep Gemini 3 Flash for the premium fast lane.
Use it where you actually benefit from the stronger official capability story: coding, harder multimodal reasoning, tool-heavy agents, and workflows where Computer Use matters.
- Benchmark your failure cases, not just your happy path.
Because both models are preview models, do not stop at average latency or average quality. Check:
- structured-output reliability
- retry behavior
- tool-call correctness
- long-context drift
- cost per successful task, not just cost per token
If your rollout process is weak here, our Gemini API troubleshooting guide is a better next read than another benchmark screenshot.
- Do not let the word "Lite" mislead you.
Flash-Lite is not just a toy or a fallback. It is a serious production option for cheap high-volume traffic. But it is also not the same product lane as 3 Flash, and treating it like a blind hot swap is how teams create avoidable regressions.
For many teams, the best architecture on March 20, 2026 is simple:
gemini-3-flash-previewfor premium fast workgemini-3.1-flash-lite-previewfor bulk fast work
That is cleaner than trying to force one preview model to do both jobs equally well.
FAQ
Is Gemini 3 Flash better than Gemini 3.1 Flash-Lite?
Yes if you mean stronger capability, better official agentic positioning, and Computer Use support. No if you mean price efficiency. Flash-Lite is clearly cheaper.
Is Gemini 3.1 Flash-Lite just a cheaper version of Gemini 3 Flash?
No. It is better understood as a separate high-volume value lane inside the Gemini 3 family. It overlaps on many core capabilities, but Google positions 3 Flash as the stronger model and gives it features like Computer Use that Flash-Lite does not have.
Do both models have a free tier?
Yes for standard token usage. But their free-tier details differ in important ways, especially around batch and caching, and neither model currently offers free-tier grounding on the pricing page.
Do both models support Search and Maps grounding?
Yes, both official model pages list those capabilities. But the pricing page shows no free-tier grounding for either one, with paid usage getting 5,000 free prompts per month before grounding charges apply.
Which one is better for coding?
Gemini 3 Flash. Google's own positioning, product testimonials, and DeepMind performance page all point more strongly toward coding, agentic workflows, and harder reasoning.
Which one is better for translation, extraction, or routing?
Gemini 3.1 Flash-Lite. That is where the lower cost, higher batch ceiling, and explicit product positioning all line up.
Should I replace Gemini 3 Flash with Gemini 3.1 Flash-Lite everywhere?
No. Replace it only on the cheap lane. Keep 3 Flash where stronger capability and tooling are actually worth paying for.