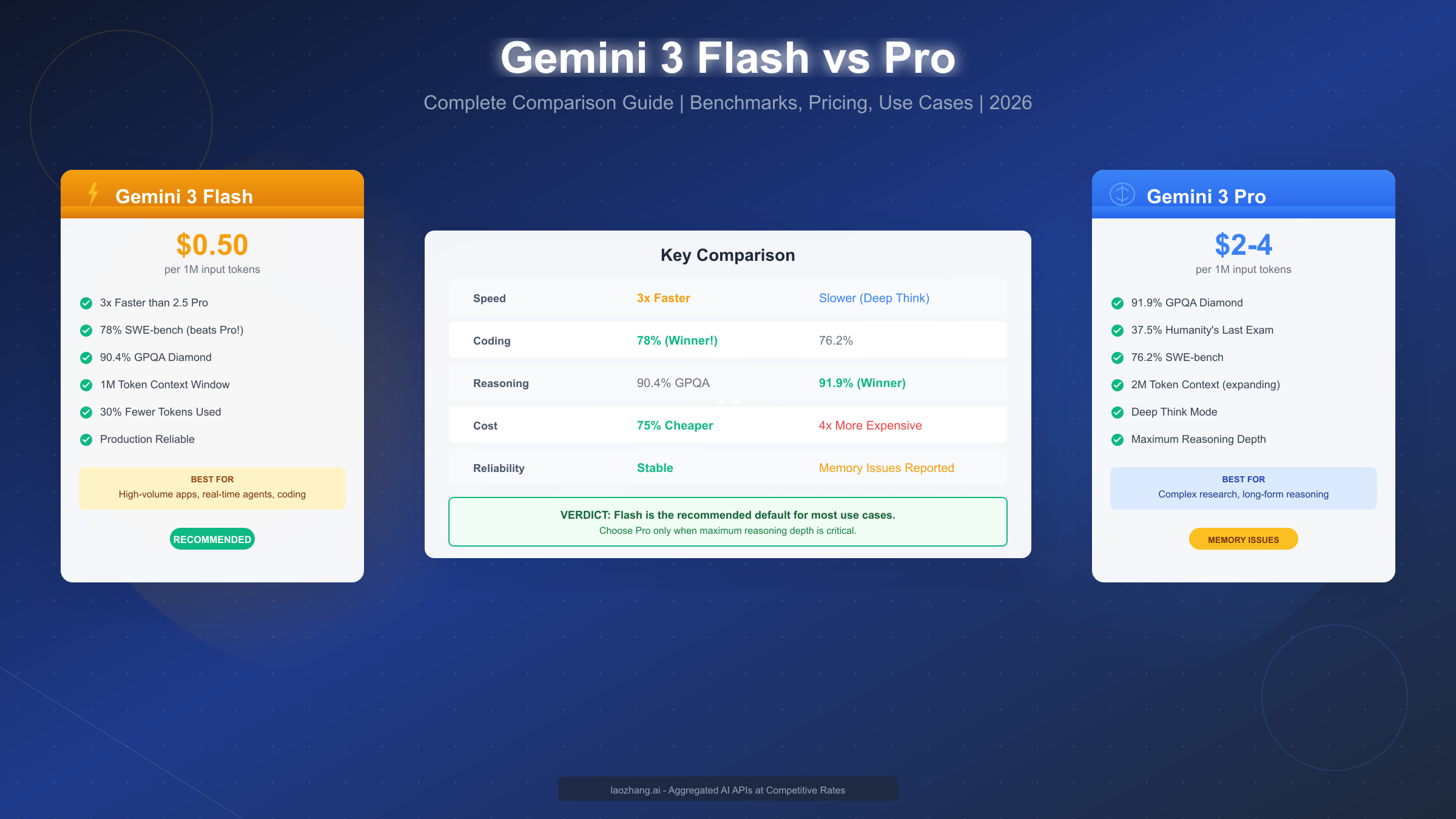
Google's Gemini 3 family represents a significant leap in AI model capabilities, but choosing between Flash and Pro can be confusing. Flash costs $0.50 per million input tokens versus Pro's $2-4, runs 3x faster, and surprisingly beats Pro on coding benchmarks (78% vs 76.2% on SWE-bench). As of January 2026, Flash is Google's recommended default for most applications, while Pro excels in scenarios requiring maximum reasoning depth. This comprehensive guide breaks down every difference to help you make the right choice.
TL;DR - Quick Decision Guide
Before diving into details, here's the bottom line: Gemini 3 Flash should be your default choice for most applications. It delivers Pro-grade intelligence at a fraction of the cost and actually outperforms Pro on coding tasks. Reserve Pro for scenarios where you need the absolute maximum reasoning capability and are willing to pay 4x more for a ~1.5% improvement on hard reasoning benchmarks.
The decision fundamentally comes down to whether you're optimizing for cost-efficiency or raw intelligence ceiling. Flash handles 95% of use cases as well as Pro, processes requests 3x faster, and costs 75% less. The main reason to choose Pro is for complex research tasks, long-horizon planning, or when you need the 2M token context window (compared to Flash's 1M tokens).
Quick Decision Matrix:
| Choose Flash If | Choose Pro If |
|---|---|
| Building production applications | Research requiring maximum accuracy |
| Need low latency (real-time) | Complex multi-step reasoning tasks |
| High-volume API usage | 2M token context window needed |
| Coding and agentic workflows | Cost is not a primary concern |
| Cost optimization is important | Scientific/academic applications |
One surprising finding that often confuses developers: Flash actually beats Pro on the SWE-bench Verified coding benchmark (78% vs 76.2%). This makes Flash the better choice for most development workflows, despite the naming suggesting Pro should be superior.
Performance & Benchmark Comparison
Understanding benchmark performance is crucial for making an informed decision, though raw numbers only tell part of the story. Google's official benchmarks reveal interesting patterns that challenge assumptions about which model is "better."
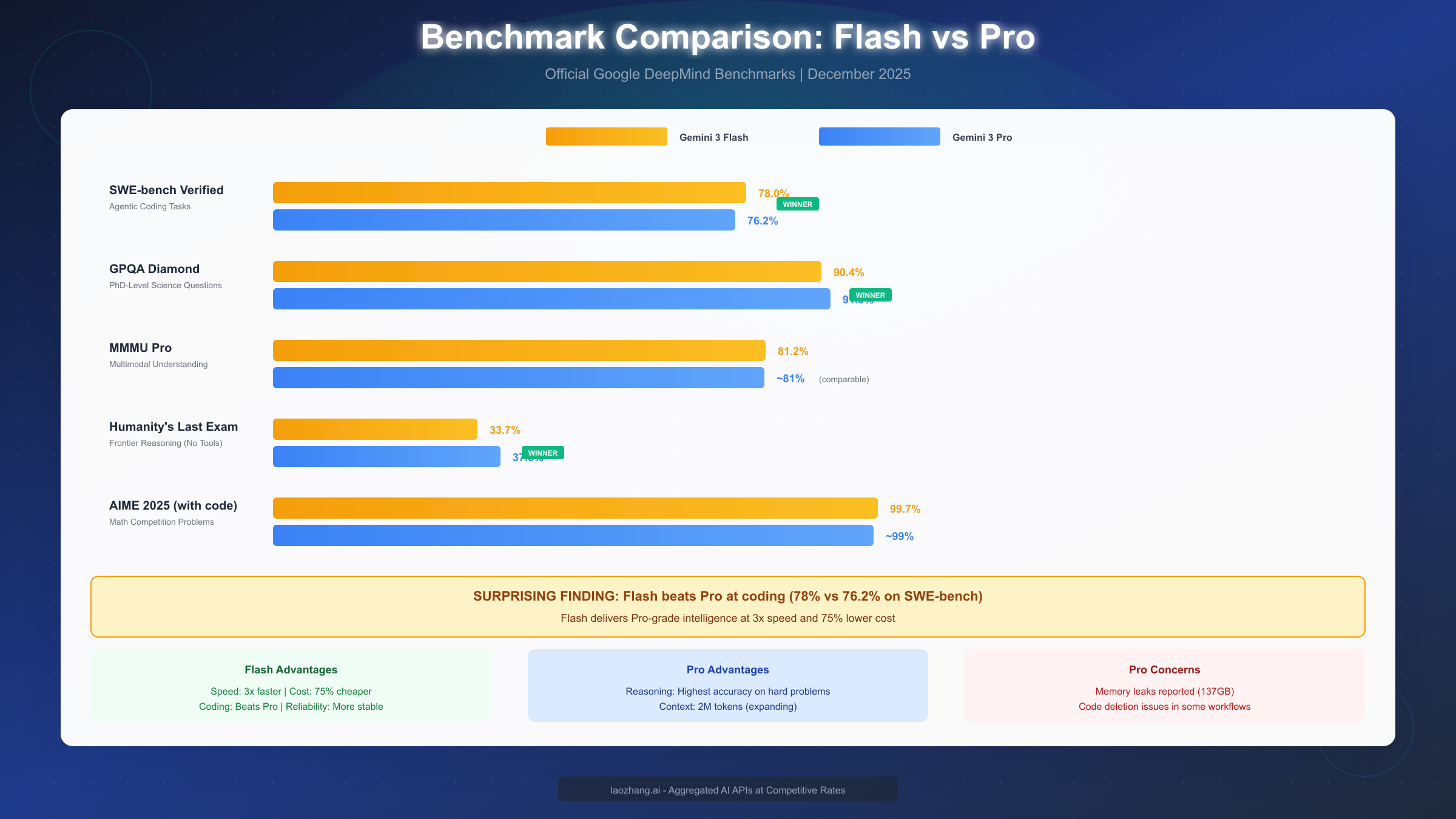
Core Benchmark Scores:
| Benchmark | Gemini 3 Flash | Gemini 3 Pro | Winner |
|---|---|---|---|
| SWE-bench Verified | 78.0% | 76.2% | Flash |
| GPQA Diamond | 90.4% | 91.9% | Pro |
| MMMU Pro | 81.2% | ~81% | Tie |
| Humanity's Last Exam | 33.7% | 37.5% | Pro |
| AIME 2025 (with code) | 99.7% | ~99% | Tie |
The SWE-bench result deserves special attention because it contradicts expectations. SWE-bench Verified evaluates real-world coding tasks extracted from GitHub issues—the kind of work developers actually do daily. Flash's 78% score versus Pro's 76.2% means that for practical coding workflows, Flash is not just cheaper and faster, but actually more capable.
Understanding What Each Benchmark Measures
GPQA Diamond tests PhD-level science knowledge across physics, chemistry, and biology. The 1.5% gap (90.4% vs 91.9%) represents Pro's slight edge on extremely difficult scientific reasoning. For most applications, this difference is negligible, but for scientific research requiring maximum accuracy, it matters.
Humanity's Last Exam is perhaps the most challenging benchmark, specifically designed to test reasoning at the frontier of AI capability. Pro's lead (37.5% vs 33.7%) suggests it handles the most difficult reasoning challenges better. However, both scores show these are genuinely hard problems where neither model performs particularly well.
MMMU Pro evaluates multimodal understanding—the ability to reason about images, documents, and visual content alongside text. Both models score around 81%, indicating comparable performance on real-world multimodal tasks.
The Coding Paradox Explained
Why does Flash beat Pro at coding despite being the "lighter" model? The answer lies in how these models are optimized. Flash is designed for agentic workflows—tasks requiring multiple iterations, tool use, and real-time feedback loops. Coding is fundamentally an agentic task: you write code, run tests, interpret errors, and iterate.
According to Google's official documentation (https://blog.google/products/gemini/gemini-3-flash/ ), Flash "modulates thinking depth based on task complexity," which actually makes it more efficient for iterative coding tasks where quick responses enable faster iteration cycles. Pro's deeper reasoning can sometimes be overkill for coding, adding latency without improving outcomes.
Pricing Deep Dive
Pricing is where Flash truly shines, offering dramatic cost savings compared to Pro and significant advantages over competing models like GPT-4o and Claude 3.5 Sonnet.
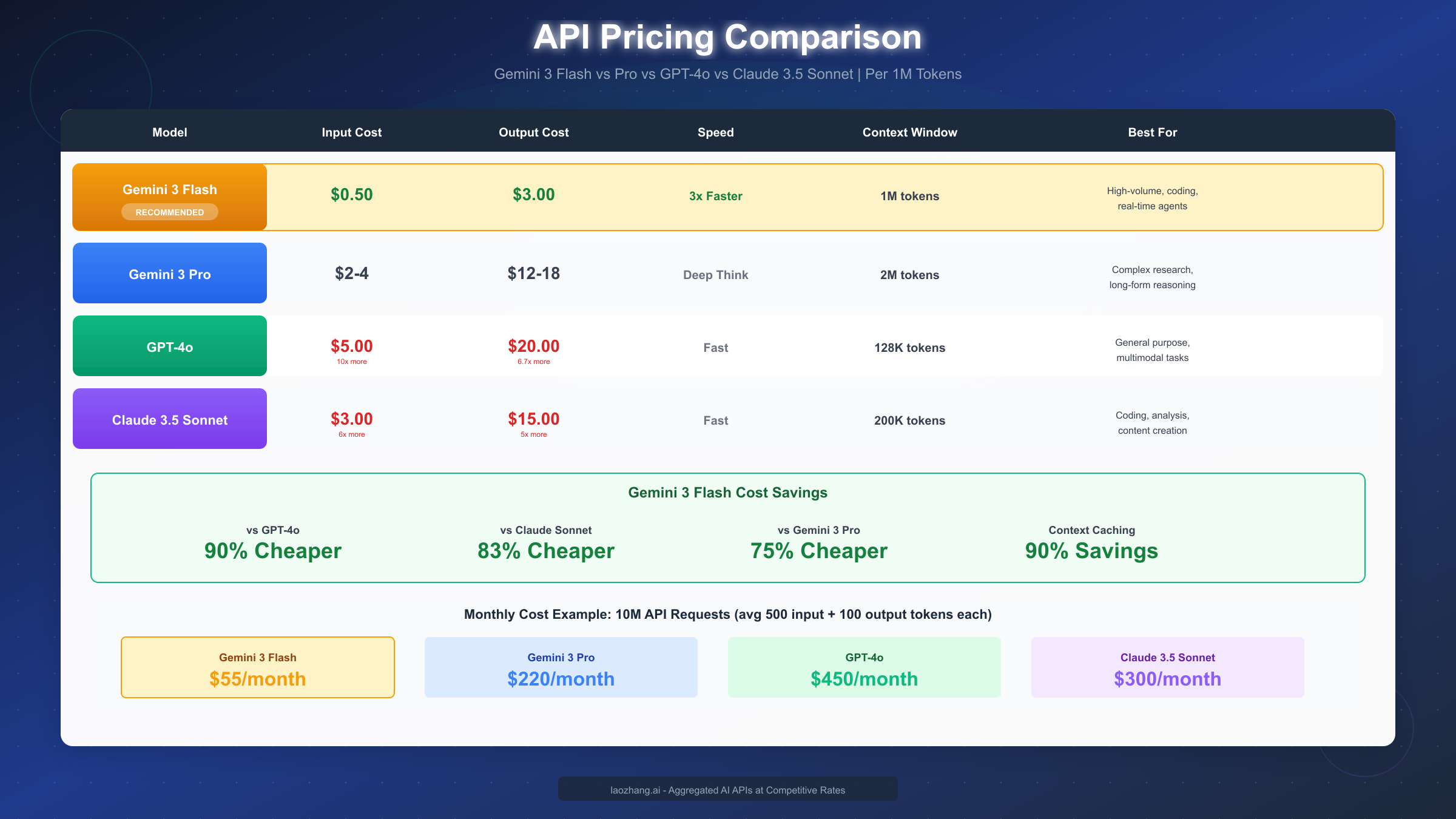
Gemini 3 Flash Pricing:
- Input tokens: $0.50 per million tokens
- Output tokens: $3.00 per million tokens
- Audio input: $1.00 per million tokens
- Context caching: Up to 90% cost reduction for repeated tokens
Gemini 3 Pro Pricing:
- Input tokens: $2.00-$4.00 per million tokens (varies by context length)
- Output tokens: $12.00-$18.00 per million tokens
- Context-length dependent pricing structure
Pro's variable pricing structure deserves explanation. Unlike Flash's flat rates, Pro charges more for longer context windows. This reflects the computational cost of processing and maintaining attention across larger contexts. For short prompts, you're closer to the lower end; for prompts approaching the 2M token limit, expect higher rates.
Competitive Pricing Comparison:
| Model | Input Cost | Output Cost | vs Flash |
|---|---|---|---|
| Gemini 3 Flash | $0.50 | $3.00 | Baseline |
| Gemini 3 Pro | $2-4 | $12-18 | 4-6x more |
| GPT-4o | $5.00 | $20.00 | 10x / 6.7x more |
| Claude 3.5 Sonnet | $3.00 | $15.00 | 6x / 5x more |
For teams considering API options, these cost differences compound significantly at scale. If you're looking for cost-effective access to multiple AI models including Gemini, platforms like laozhang.ai offer aggregated API access at competitive rates, allowing you to switch between models without managing multiple accounts.
Real-World Cost Examples
To understand what these prices mean in practice, consider a typical high-volume application making 10 million API requests monthly, with each request averaging 500 input tokens and 100 output tokens:
- Gemini 3 Flash: ~$55/month
- Gemini 3 Pro: ~$220/month
- GPT-4o: ~$450/month
- Claude 3.5 Sonnet: ~$300/month
The savings become even more dramatic when leveraging context caching. Flash supports built-in context caching that can reduce costs by up to 90% when you're repeatedly sending the same context (like system prompts or document chunks). Combined with the Batch API offering 50% savings for asynchronous processing, organizations can achieve costs well below the base rates.
For a detailed breakdown of Gemini API pricing tiers and optimization strategies, see our detailed Gemini API pricing breakdown.
Speed, Latency & Technical Specifications
Speed often matters more than benchmark scores for production applications. Flash's performance characteristics make it suitable for real-time use cases where Pro would be too slow.
Speed Comparison:
| Metric | Gemini 3 Flash | Gemini 3 Pro |
|---|---|---|
| First token latency | 0.21-0.37 seconds | 0.5-1.5 seconds |
| Output speed | 163 tokens/second | ~60 tokens/second |
| Relative speed | 3x faster | Baseline |
| Token efficiency | 30% fewer tokens | Baseline |
According to Artificial Analysis benchmarking, Flash delivers responses 3x faster than Gemini 2.5 Pro while maintaining comparable quality. The 30% token efficiency improvement means Flash not only costs less per token but uses fewer tokens to accomplish the same tasks.
Technical Specifications:
| Specification | Gemini 3 Flash | Gemini 3 Pro |
|---|---|---|
| Context window | 1M tokens | 2M tokens (expanding) |
| Max output | 64K tokens | 64K tokens |
| Knowledge cutoff | January 2025 | January 2025 |
| Input formats | Text, image, video, audio, PDF | Text, image, video, audio, PDF |
| Output formats | Text (structured outputs via function calling) | Text (structured outputs via function calling) |
Both models support identical input modalities—text, images, video, audio, and PDF documents. This means you can build multimodal applications with either model without changing your architecture. The key differentiator is Pro's larger context window, which enables processing longer documents or maintaining longer conversation histories.
Deep Think Mode
Pro offers an optional "Deep Think" mode that trades latency for improved reasoning on complex problems. When enabled, Pro takes additional time to work through multi-step reasoning chains before responding. This makes Pro more suitable for research applications where getting the right answer matters more than getting a fast answer.
Flash, by contrast, applies reasoning depth dynamically based on query complexity—spending more effort on hard problems and less on straightforward requests. This adaptive approach optimizes the speed-accuracy tradeoff automatically.
Which Model Should You Use?
The right choice depends on your specific use case, budget constraints, and performance requirements. Here's a practical framework for making the decision.
Choose Gemini 3 Flash for:
High-Volume Production Applications - If you're building a customer-facing product that needs to handle thousands or millions of requests, Flash's cost and speed advantages compound dramatically. At 10M requests/month, Flash saves you ~$165/month compared to Pro—and that's before considering the faster response times that improve user experience.
Real-Time and Interactive Applications - Chatbots, voice assistants, live coding assistants, and any application where users expect immediate responses. Flash's 0.21-0.37 second first-token latency keeps interactions feeling natural, while Pro's longer latency can make conversations feel sluggish.
Coding and Development Workflows - Despite intuition suggesting Pro should be better at coding, the benchmarks show Flash actually outperforms Pro on SWE-bench. For code generation, debugging, refactoring, and code review tasks, Flash delivers better results faster and cheaper.
Agentic Systems - Applications that use multiple AI calls in sequence—like autonomous agents, multi-step workflows, or tool-using systems—benefit from Flash's faster iteration cycles. The compounding speed advantage across multiple calls makes Flash the clear choice for agentic architectures.
Choose Gemini 3 Pro for:
Complex Research and Analysis - When you need the absolute highest accuracy on difficult reasoning problems, Pro's slight edge on benchmarks like Humanity's Last Exam and GPQA Diamond may justify the additional cost. Academic research, scientific analysis, and high-stakes decision-making fall into this category.
Long-Context Applications - If your use case requires processing documents or conversations exceeding 1M tokens, Pro's 2M token context window is essential. This includes analyzing lengthy legal documents, processing entire codebases, or maintaining very long conversation histories.
Maximum Intelligence Ceiling - For applications where being 1-2% more accurate on the hardest problems outweighs cost and speed considerations. This is relatively rare in practice, but some enterprise and research use cases fit this profile.
Persona-Based Recommendations:
Startup Founder Building an MVP: Use Flash. The cost savings let you iterate faster and serve more users with your limited budget. You can always switch to Pro for specific features later if needed.
Enterprise AI Architect: Start with Flash as your default, use Pro selectively for specific high-value workflows. Monitor which requests actually benefit from Pro's deeper reasoning and route accordingly.
Independent Developer: Flash for everything unless you're building research tools or need the 2M context window. The 90% cost savings compared to GPT-4o makes experimentation much more accessible.
AI Researcher: Consider Pro for evaluation and benchmarking work where maximum capability matters, Flash for data processing, preprocessing, and iteration during development.
Known Issues & Honest Assessment
No AI model is perfect, and transparency about limitations helps you avoid production surprises. Both Flash and Pro have documented issues worth understanding.
Gemini 3 Pro Known Issues:
Multiple developers have reported memory-related problems with Pro, particularly in long-running sessions or complex agentic workflows. Reports indicate Pro sometimes exhibits memory leaks reaching 137GB, which can crash applications or require expensive cloud instances.
Pro has also been reported to delete code unexpectedly during refactoring tasks. According to developer feedback on technical forums, Pro has a "high tendency to wipe out large chunks of code," sometimes removing sections completely unrelated to the requested changes. This makes Pro risky for automated code modification pipelines without careful review.
These issues appear more pronounced in Pro than Flash, possibly due to Pro's deeper reasoning creating more complex internal states that are harder to manage across long sessions.
Gemini 3 Flash Limitations:
Flash's main limitation is its reasoning ceiling on the most difficult problems. The ~4% gap on Humanity's Last Exam (33.7% vs 37.5%) indicates Flash struggles more with problems requiring extended multi-step reasoning chains.
Flash's 1M token context window, while large, is half of Pro's capacity. If your application genuinely requires processing content exceeding 1M tokens, Flash cannot accommodate this.
Practical Reliability Assessment:
For production applications, Flash appears more reliable based on developer reports. Its simpler architecture and faster processing seem to avoid the memory management issues that plague Pro in some scenarios. If stability is critical for your use case, Flash is the safer choice.
Both models share common LLM limitations: potential hallucinations, inconsistent behavior on edge cases, and the need for careful prompt engineering. Neither model should be deployed in high-stakes scenarios without appropriate guardrails and human review.
Getting Started with Gemini API
Setting up access to Gemini models is straightforward through Google AI Studio or Vertex AI. Here's a quick guide to get started.
Prerequisites:
- Google Cloud account (for Vertex AI) or Google AI Studio account
- API key from Google AI Studio or service account for Vertex AI
- Python 3.10+ or Node.js 18+ for client libraries
For a complete walkthrough of obtaining your credentials, see our guide on how to get your Gemini API key.
Python Quick Start:
pythonimport google.generativeai as genai genai.configure(api_key="YOUR_API_KEY") # Use Gemini 3 Flash (recommended default) model = genai.GenerativeModel('gemini-3-flash') response = model.generate_content("Explain quantum computing in simple terms") print(response.text) # Use Gemini 3 Pro for complex reasoning pro_model = genai.GenerativeModel('gemini-3-pro') complex_response = pro_model.generate_content( "Analyze the implications of quantum supremacy on current cryptographic systems" ) print(complex_response.text)
Using Context Caching for Cost Optimization:
python# Create a cached context for repeated system prompts cache = genai.caching.CachedContent.create( model='gemini-3-flash', system_instruction="You are a helpful coding assistant...", contents=[long_reference_document] ) # Use the cached context for multiple requests cached_model = genai.GenerativeModel.from_cached_content(cache) # These requests use the cached context at 90% reduced cost for query in user_queries: response = cached_model.generate_content(query)
Best Practices:
-
Start with Flash - Use Flash as your default and only switch to Pro when you've identified specific tasks that genuinely benefit from deeper reasoning.
-
Implement request routing - For applications requiring both models, implement logic to route simple requests to Flash and complex reasoning tasks to Pro.
-
Monitor and iterate - Track which requests actually benefit from Pro versus Flash using A/B testing or quality evaluations on representative samples.
-
Use context caching - For applications with repeated context (system prompts, reference documents), enable caching to achieve up to 90% cost reduction.
-
Consider the Batch API - For non-time-sensitive workloads, the Batch API offers 50% cost savings with higher rate limits.
For developers working with multiple AI providers, aggregated API services like laozhang.ai can simplify access management while offering competitive pricing across Gemini, OpenAI, and Anthropic models through a unified interface.
FAQ
Is Gemini 3 Flash really better than Pro for coding?
Yes, on the SWE-bench Verified benchmark, Flash scores 78% compared to Pro's 76.2%. This benchmark evaluates real-world coding tasks from GitHub issues, making it highly representative of actual development work. Flash's optimization for agentic, iterative workflows makes it particularly effective for coding where quick feedback loops matter.
Why is Pro more expensive if Flash often performs better?
Pro's higher price reflects its larger context window (2M tokens), deeper reasoning capability on the hardest problems, and the computational resources required for extended thinking. For the ~5% of tasks that genuinely need maximum reasoning depth, Pro delivers measurably better results.
Can I switch between Flash and Pro mid-conversation?
Yes, both models share the same API structure and accept identical input formats. You can implement routing logic to use Flash for most requests and Pro for specific complex queries. Just be aware that conversation history from one model won't automatically transfer to the other.
What about Gemini 3 Pro's memory issues?
Memory issues have been reported in long-running sessions and complex agentic workflows. If you're building applications with extended sessions, implement timeouts, session management, and consider Flash as a more stable alternative. Monitor memory usage in production and implement circuit breakers if needed.
How does Gemini compare to GPT-4o pricing?
Gemini 3 Flash is dramatically cheaper: $0.50/1M input vs GPT-4o's $5.00/1M input (10x difference). Even Gemini 3 Pro at $2-4/1M input is cheaper than GPT-4o. For output tokens, Flash at $3/1M is about 6.7x cheaper than GPT-4o's $20/1M.
Should I migrate from Claude to Gemini?
It depends on your use case. Flash offers significant cost savings compared to Claude API pricing, with Flash at $0.50/$3.00 per million input/output tokens versus Claude 3.5 Sonnet's $3.00/$15.00. If cost is a primary concern and your workload doesn't specifically require Claude's particular strengths, Flash is worth testing.
What's the practical difference between 1M and 2M context windows?
The 1M token context window in Flash handles approximately 750,000 words—enough for most books, codebases, or document collections. The 2M token context in Pro doubles this capacity, which matters for truly massive documents, entire repository analysis, or maintaining very long conversation histories. Most applications don't need more than 1M tokens.
Conclusion
The choice between Gemini 3 Flash and Pro comes down to a simple heuristic: use Flash unless you have a specific reason to use Pro.
Flash delivers Pro-grade intelligence at 75% lower cost and 3x faster speed. It actually outperforms Pro on coding tasks, handles multimodal inputs identically, and offers better production reliability based on developer reports. For 95% of use cases, Flash is the correct choice.
Pro earns its place for specific scenarios: when you need the maximum reasoning capability on the hardest problems, when the 2M token context window is essential, or when you're willing to pay for the ~1.5% improvement on benchmarks like GPQA Diamond.
For organizations evaluating AI model choices, Flash represents a paradigm shift—frontier capability is no longer expensive. The economics favor experimentation, iteration, and high-volume deployment in ways that weren't possible with previous pricing structures.
Start with Flash, measure your results, and upgrade to Pro only for the specific workflows that genuinely benefit from it. Your users will experience faster responses, your engineers will appreciate the simpler reliability story, and your finance team will appreciate the cost savings.