
As of March 21, 2026, GPT-5.4 mini is usually the better default if your workflow is centered on coding subagents, Codex-style tool loops, and OpenAI's native agent surface. Gemini 3 Flash is usually the better default if you want a cheaper multimodal fast model with a 1M context window, Google grounding, and enough capability for serious work without paying OpenAI's premium.
That is the short answer, but this keyword gets messy fast because it is not a clean benchmark shootout. OpenAI and Google do not publish one shared official evaluation sheet for this pair. OpenAI's current latest model guide explains GPT-5.4 mini as the high-volume coding, computer-use, and agent-workflow branch inside the GPT-5.4 family. Google's current Gemini 3 Flash model page explains Gemini 3 Flash as its strongest fast multimodal and agentic coding lane. Those are different ecosystems, different tool stacks, and different product surfaces.
So the right way to answer the query is not to pretend the benchmark rows line up perfectly. The right way is to compare what the current official pages say about price, context, tooling, model role, and the kinds of work each model is actually built to carry.
This guide uses the current GPT-5.4 mini model page, Gemini pricing page, Gemini rate-limits page, and both vendors' release notes checked on March 21, 2026.
Quick Comparison
If you want the decision first, use this table.
| Area | GPT-5.4 mini | Gemini 3 Flash | What it changes |
|---|---|---|---|
| Launch date | March 17, 2026 | December 17, 2025 | GPT-5.4 mini is newer, but both are current |
| Official role | High-volume coding, computer use, and agent workflows that still need strong reasoning | Google's best model for multimodal understanding and most powerful agentic and vibe-coding model yet | This is workflow routing, not just a spec race |
| Standard input price | $0.75 / 1M | $0.50 / 1M | Gemini 3 Flash is cheaper |
| Standard output price | $4.50 / 1M | $3.00 / 1M | Gemini 3 Flash is cheaper here too |
| Batch price | Not the main story on the model page | $0.25 input / $1.50 output | Gemini gives a clearer cheap batch lane in its public pricing table |
| Context window | 400,000 | 1,048,576 | Gemini 3 Flash is the clear winner for long-context work |
| Max output | 128,000 | 65,536 | GPT-5.4 mini gives a larger output ceiling |
| Knowledge cutoff | Aug 31, 2025 | January 2025 | GPT-5.4 mini is clearly fresher on the published model pages |
| Computer use | Supported | Supported | Tie at headline level |
| Distinctive tool surface | Hosted shell, apply patch, MCP, tool search, image generation, strong Codex alignment | Search grounding, Maps grounding, URL context, 1M context, cheaper multimodal token pricing | The workflow surface is the real split |
| Best fit | OpenAI-native coding agents, subagents, repo work, tool-heavy software loops | Cheaper large-context multimodal work, Google-grounded tasks, teams already in Gemini / Vertex | Route by stack and workload, not by brand habit |
The practical rule is:
- choose GPT-5.4 mini when the product is really a coding agent or a subagent system and OpenAI's native tool stack is part of the value
- choose Gemini 3 Flash when you care more about cheaper multimodal throughput, much larger context, and Google's grounding surface
There is one caveat you should keep in mind from the start: if your real question is "what is Google's cheaper fast lane," then Gemini 3.1 Flash-Lite vs Gemini 3 Flash is the more important sibling comparison after this one.
Why This Is Not a Clean Benchmark War
Weak comparison pages usually start by grabbing whatever benchmark rows they can find and then crowning a winner. That approach is sloppy here.
OpenAI's March 17, 2026 launch post for GPT-5.4 mini shows official internal and public benchmark rows such as SWE-Bench Pro, Toolathlon, GPQA Diamond, and OSWorld-Verified. Those are useful because they show what OpenAI believes GPT-5.4 mini is good at: coding, tool use, and computer-use-heavy work while running much faster than GPT-5 mini.
Google, by contrast, does not publish one matching official "Gemini 3 Flash versus GPT-5.4 mini" scorecard. What Google does publish is a model page that positions Gemini 3 Flash as its strongest multimodal and agentic fast lane, along with pricing, token limits, and tool support. That is useful, but it is not a shared score system.
So if a page tells you that one of these models "wins" because it stacked unrelated vendor benchmarks into one chart, that page is usually doing something easier to publish than to defend.
The safer and more useful method is:
- use each vendor's current official positioning to understand intended workload
- use current official pricing and token limits to understand cost and scale
- use current official tool support to understand actual workflow fit
- then decide which model better matches the job you are trying to run
That makes the article less flashy, but much more trustworthy.
If you only care about OpenAI's in-family decision after this cross-vendor pass, GPT-5.4 vs GPT-5.4 mini is the cleaner next read.
Pricing, Context, and Tool Surface Matter More Than Brand Prestige
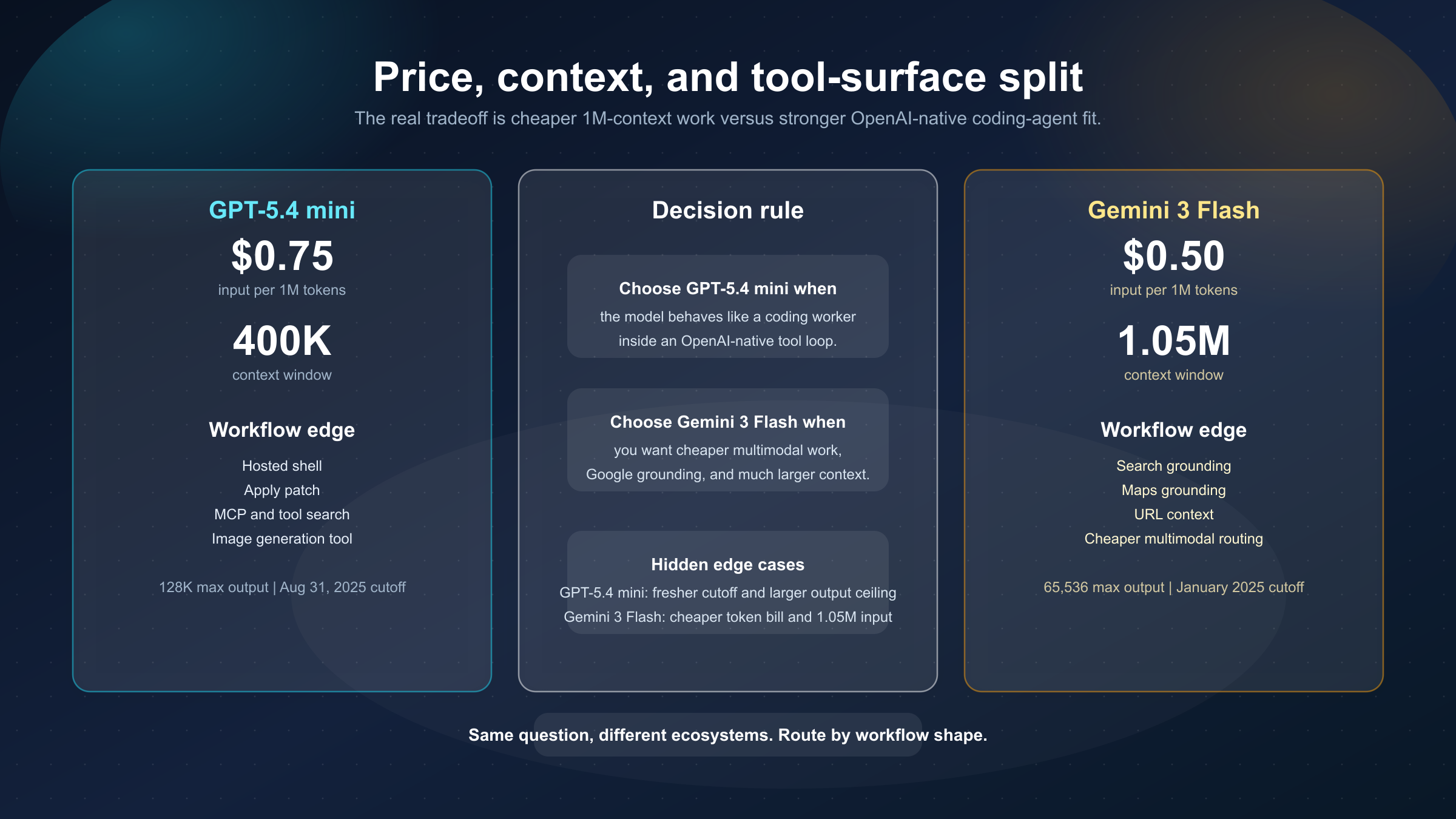
The easiest fact to verify is price. On the current official model pages and pricing pages checked March 21, 2026:
- GPT-5.4 mini lists $0.75 input, $0.075 cached input, and $4.50 output per 1M tokens
- Gemini 3 Flash lists $0.50 input and $3.00 output per 1M tokens
That means GPT-5.4 mini is about 1.5x the price of Gemini 3 Flash on both standard input and output tokens. If your workload is high-volume enough, that difference is not cosmetic.
The second big gap is context. GPT-5.4 mini's model page lists 400,000 context. Gemini 3 Flash's model page lists 1,048,576 input tokens. That is not a small edge. It means Gemini 3 Flash is far more comfortable when your workflow needs to keep giant codebases, multiple documents, screenshots, logs, and long histories in the same working set.
There is also a less obvious I/O difference. GPT-5.4 mini's model page lists 128,000 max output tokens, while Gemini 3 Flash lists 65,536. That does not matter on every request, but it can matter for workflows that expect long diffs, large generated artifacts, or verbose structured results. In other words, Gemini wins decisively on input context, while GPT-5.4 mini quietly keeps an edge on output ceiling.
The third gap is where the comparison gets more interesting: tool surface.
GPT-5.4 mini's current model page lists support for:
- web search
- file search
- image generation
- code interpreter
- hosted shell
- apply patch
- skills
- computer use
- MCP
- tool search
Gemini 3 Flash's current model page lists support for:
- batch API
- caching
- code execution
- computer use
- file search
- search grounding
- Google Maps grounding
- structured outputs
- thinking
- URL context
These are both serious product surfaces, but they push you toward different kinds of systems.
GPT-5.4 mini feels more natural when the model is expected to behave like a coding worker inside an OpenAI-native agent loop. Hosted shell, apply patch, MCP, and tool search are not marketing flourishes. They are part of the product shape. They matter if your model is supposed to inspect repos, modify files, work across tools, and act like a reliable software subagent.
Gemini 3 Flash feels more natural when you want a cheaper general fast lane that still supports multimodal input, computer use, Google grounding, and large context. It is especially appealing if your product already leans toward Google's stack or if grounding and context size matter more than OpenAI's coding-agent affordances.
There is one more practical distinction worth surfacing. GPT-5.4 mini's current model page lists image generation in the supported Responses API tool set. Gemini 3 Flash's current model page explicitly lists image generation not supported. That will not matter for every buyer, but it does matter for teams trying to keep more of their workflow inside one agent surface instead of handing off to a separate model.
One more practical detail many comparison pages miss: the published knowledge cutoffs are different. GPT-5.4 mini currently shows Aug 31, 2025. Gemini 3 Flash currently shows January 2025. That does not automatically make GPT-5.4 mini "better," but it is a real freshness edge if your task depends heavily on what the base model already knows before web search or retrieval enters the picture.
When GPT-5.4 mini Is the Better Default

GPT-5.4 mini is the better default when the workflow is really a software agent workflow and the value is not only in the raw answer but in how the model operates across tools.
Choose GPT-5.4 mini when your team cares most about these scenarios:
1. Coding subagents and worker fleets. OpenAI explicitly positions GPT-5.4 mini for high-volume coding and subagents. That matters because the product surface, launch messaging, and current tool support all point in the same direction.
2. OpenAI-native repo and automation loops. If your workflow depends on hosted shell, apply patch, tool search, or MCP-heavy orchestration, GPT-5.4 mini is closer to the job you are actually running than Gemini 3 Flash. It does not just answer questions about code. It fits a more developed coding-agent environment.
3. Teams already standardized on Responses API or Codex-style patterns. Migration and operational simplicity matter. If your prompts, tools, evals, and mental model already live inside OpenAI's ecosystem, the extra token cost can be easier to justify than the cost of switching surfaces.
4. You want a strong small-model lane that still looks close to the flagship family. OpenAI's own launch post frames GPT-5.4 mini as a model that approaches GPT-5.4 on some coding and computer-use evaluations while remaining much faster. That is exactly the pitch many software teams want from a small model.
The strongest reason to pick GPT-5.4 mini is not "OpenAI is better." That is too vague to survive contact with a real budget. The strongest reason is that its workflow fit for coding agents is unusually coherent. The pricing, tool stack, launch message, and surrounding OpenAI ecosystem all tell the same story.
That is why a lot of teams can rationally pay more for GPT-5.4 mini even though Gemini 3 Flash is cheaper on paper. The model is not only a cheaper text engine inside the OpenAI lineup. It is a purpose-built small model for coding and agent loops.
When Gemini 3 Flash Is the Better Default
Gemini 3 Flash is the better default when you want the strongest Google fast lane, cheaper multimodal pricing, and much more context without moving up to a more expensive premium model.
Choose Gemini 3 Flash when these scenarios sound closer to your workload:
1. Large-context multimodal work. The 1,048,576-token input window is a real advantage for long reports, big repos plus documentation, screenshot-rich workflows, or applications that need to keep a lot of material in play.
2. Cheaper serious throughput. Gemini 3 Flash is still a serious fast model, but it undercuts GPT-5.4 mini on standard token pricing. If your model needs to do a lot of decent work quickly without carrying OpenAI's premium, that cost gap matters.
3. Google grounding matters to the product. Gemini 3 Flash supports Search grounding and Maps grounding. If your application value comes from that Google-side integration, the model does more than just "generate text cheaper." It fits the rest of the system better.
4. You want one fast multimodal lane instead of a coding-specialized lane. Google's official positioning treats Gemini 3 Flash as its most powerful agentic and vibe-coding fast model, but also as a broad multimodal understanding model. If your workload spans text, image, video, audio, PDFs, and grounded responses, Gemini 3 Flash can be the cleaner all-purpose fast route.
This is also where the context gap becomes decisive. A lot of teams say they are buying "a coding model," but what they really need is a model that can see a big enough slice of the environment at once. If that is your bottleneck, Gemini 3 Flash can be the better choice even if GPT-5.4 mini feels more purpose-built for code-edit loops.
The cleanest way to say it is this:
- GPT-5.4 mini is better when the model needs to feel like a coding subagent inside OpenAI's ecosystem
- Gemini 3 Flash is better when the model needs to feel like a cheaper large-context multimodal fast lane inside Google's ecosystem
The Google-Side Caveat Most Readers Miss

This is the part many quick comparisons skip.
If your instinct is leaning toward Gemini mainly because it is cheaper than GPT-5.4 mini, you should slow down and ask a second question:
Do you really need Gemini 3 Flash, or do you actually need Gemini 3.1 Flash-Lite?
Google's own current pricing and rate-limit pages make this important. Gemini 3.1 Flash-Lite is cheaper than Gemini 3 Flash on both standard and batch pricing, and Google's public Tier 1 batch queue number is also larger for Flash-Lite than for Flash.
That does not make Flash-Lite a better model. It means Google's family already contains its own routing split:
- Gemini 3 Flash for the stronger fast lane
- Gemini 3.1 Flash-Lite for the cheaper, higher-throughput lane
So if your real buying logic is "I mostly need low-cost translation, extraction, labeling, or routing at scale," the more honest Google-side alternative to GPT-5.4 mini may be Flash-Lite, not Flash. That is why the cross-vendor answer here should not be oversimplified into "Gemini is cheaper." You still need to decide which Gemini lane you actually mean.
This caveat does not weaken Gemini 3 Flash. It sharpens the comparison. It prevents the article from treating Google's stronger fast lane as if it were also Google's cheapest lane.
Bottom Line
If you need one blunt recommendation, use this:
- pick GPT-5.4 mini when your product is fundamentally a coding-agent or subagent workflow and OpenAI's native tooling is part of the reason you are buying
- pick Gemini 3 Flash when you want cheaper multimodal fast-model pricing, a much larger context window, and Google's grounding surface
For a lot of teams, the real answer is not to force a single universal winner.
Use GPT-5.4 mini for:
- code-edit agents
- repo workers
- tool-heavy software loops
- OpenAI-native automation
Use Gemini 3 Flash for:
- cheaper large-context work
- grounded multimodal tasks
- broad Google-stack applications
- cases where 1M context is more valuable than OpenAI's coding-specific surface
If your workload is mixed, the most defensible answer is often to route instead of forcing one winner everywhere. A common split is to keep GPT-5.4 mini on code-edit workers, repo agents, and tool-heavy execution paths, while using Gemini 3 Flash for cheaper multimodal analysis, large-context synthesis, and grounded user-facing tasks. That kind of mixed routing is often simpler than trying to argue that one vendor's fast lane dominates every dimension.
The good news is that the decision is clearer than it looks once you stop asking the wrong question. The wrong question is "which model is universally better?" The better question is "which workflow do I need my default fast model to carry?" Once you ask that, the split stops being vague:
- if the workflow wants to feel like a native coding subagent, GPT-5.4 mini usually wins
- if the workflow wants to feel like a cheaper, grounded, large-context multimodal fast lane, Gemini 3 Flash usually wins
And if your reason for leaning toward Gemini is mostly cost, read Gemini 3.1 Flash-Lite vs Gemini 3 Flash next before you commit. That article answers the question many teams eventually realize they were really asking.