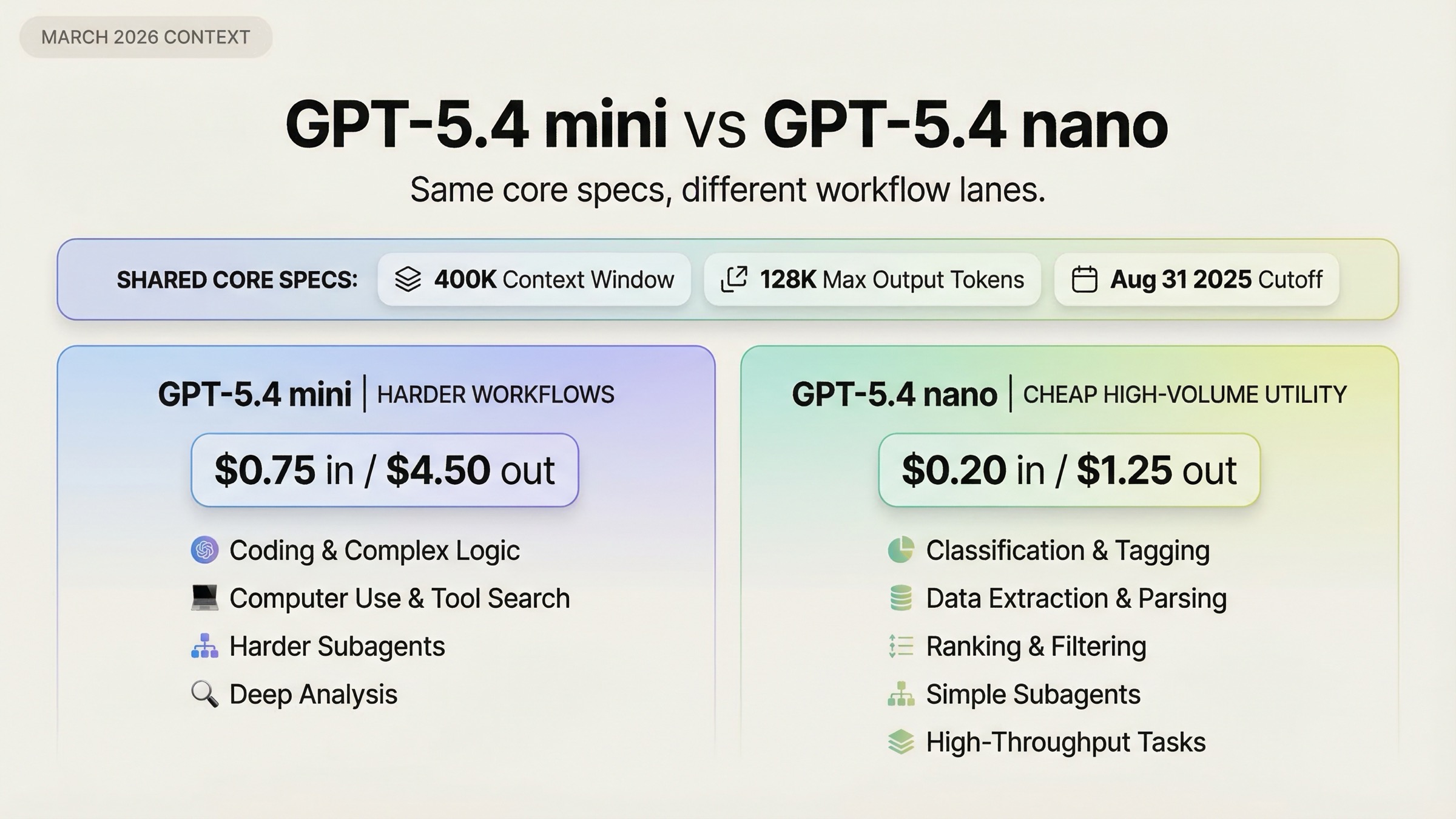
As of March 20, 2026, the fastest correct default is this: choose GPT-5.4 mini when your product needs stronger coding, computer use, or heavier agent behavior, and choose GPT-5.4 nano when cheap high-throughput work matters more than workflow depth. OpenAI's March 17, 2026 launch post positions GPT-5.4 mini as the stronger small model for coding and subagents, while GPT-5.4 nano is explicitly recommended for classification, data extraction, ranking, and simpler supporting subagents.
What makes this comparison tricky is that the two models look more similar than many readers expect. They have the same 400K context window, the same 128K max output, and the same Aug 31, 2025 knowledge cutoff. So if you only scan the top-level specs, the price gap feels like the whole story. It is not. The real question is whether your workload needs mini's better tool and benchmark profile, or whether nano is the better operating point because the hard parts of your system are actually simple, repetitive, and cost-sensitive.
TL;DR
If you want the short answer, use this rule:
| Model | Best for | Main reason to choose it | Main reason not to choose it |
|---|---|---|---|
| GPT-5.4 mini | Coding assistants, screenshot-heavy workflows, browser or desktop automation, deeper subagents | Better performance on coding, tool use, and computer-use tasks; supports computer use and tool search | Costs much more: $0.75 input / $4.50 output per 1M tokens |
| GPT-5.4 nano | Classification, extraction, ranking, cheap routing, simpler subagents | Much cheaper: $0.20 input / $1.25 output per 1M tokens; same context and cutoff as mini | No computer use or tool search, and weaker performance on harder tool-heavy work |
The simplest decision rule is:
- If the model needs to inspect code, recover from tool failures, use computer interfaces, or operate as a capable worker in a larger agent system, start with GPT-5.4 mini.
- If the model mostly labels, extracts, ranks, routes, or handles narrow support tasks at scale, start with GPT-5.4 nano.
- If you are building a mixed system, the best answer is often not "mini or nano" but "mini for the hard lane, nano for the cheap lane."
- If you are choosing based on ChatGPT model names, stop and separate that from API choice. This article is primarily about API and Codex-style routing, not the ChatGPT picker.
The Real Split Is Workflow Depth, Not Context
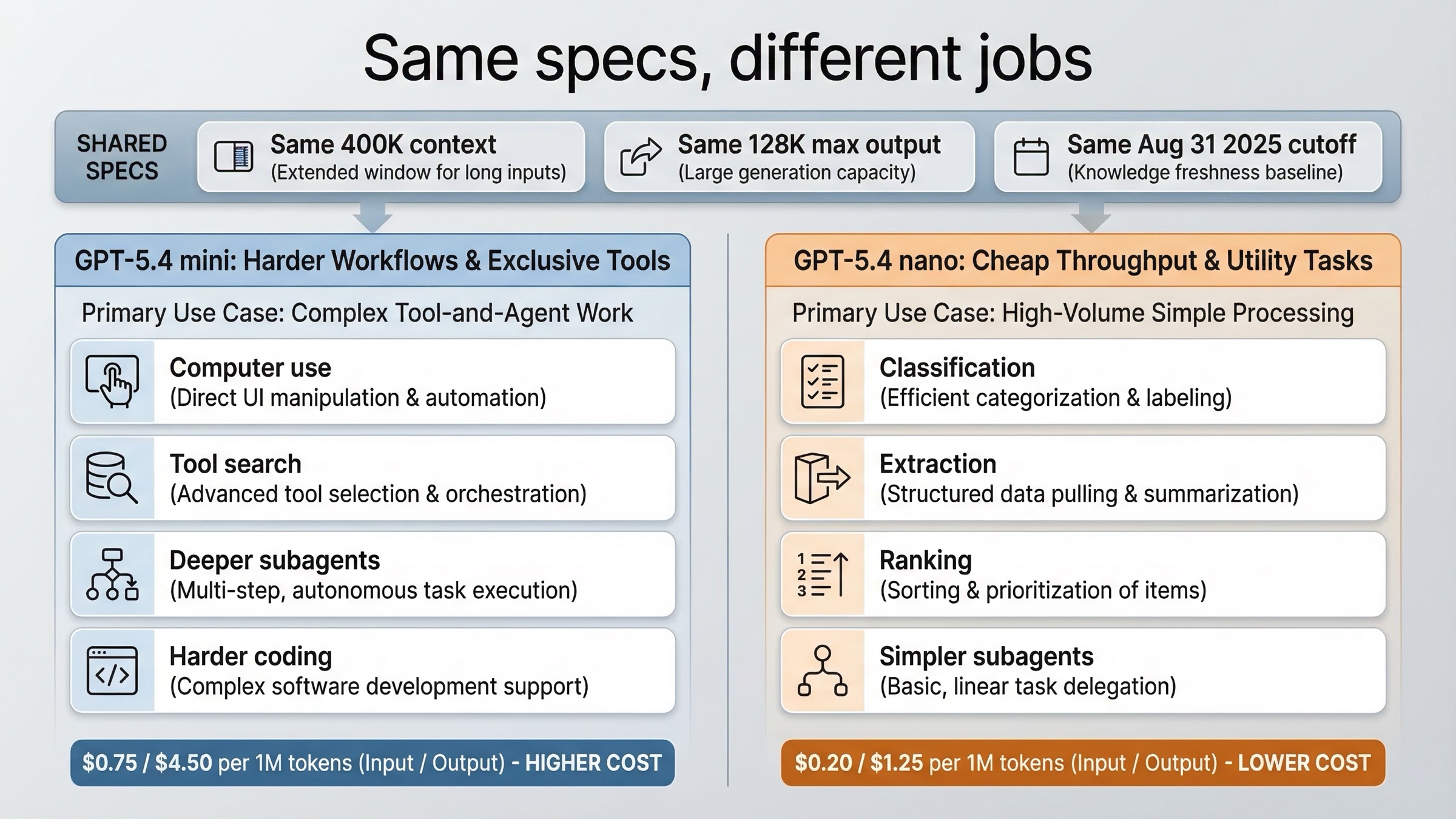
Many comparison pages will lead with price, context, and cutoff because those fields are easy to scrape. For this keyword, that is exactly where weak content loses the reader.
According to the current OpenAI model pages, both GPT-5.4 mini and GPT-5.4 nano have:
- a 400K context window
- a 128K max output window
- an Aug 31, 2025 knowledge cutoff
- text and image input support
That means the decision is not really about "small context versus large context" or "old knowledge versus newer knowledge." Those paper specs are basically tied.
The real split is what each model is supposed to do inside a production system.
OpenAI's current GPT-5.4 guide says GPT-5.4 mini is best for high-volume coding, computer use, and agent workflows that still need strong reasoning. The same guide says GPT-5.4 nano is best for simple high-throughput tasks where speed and cost matter most. That is a much better framing than "one is the smaller version of the other."
So the first useful mental model is this:
| Question | If the answer is yes | Better fit |
|---|---|---|
| Does the model need to do real coding or codebase work? | You care about stronger coding benchmarks and agent reliability | GPT-5.4 mini |
| Does the model need built-in computer use or UI-grounded task execution? | You need screenshot-driven or interface-driven work | GPT-5.4 mini |
| Is the task mostly extraction, ranking, or classification at very high volume? | Cost and throughput dominate | GPT-5.4 nano |
| Are you routing simpler support tasks under a larger planner model? | You want the cheapest useful worker | GPT-5.4 nano |
That framing matters because it explains why the price delta exists at all. OpenAI is not charging more for mini because it has a larger context window. It is charging more because mini is the stronger tool-and-agent worker.
Price, Rate Limits, and Tool Support Side by Side
The pricing gap is large enough that you should make it explicit before you read any benchmark table.
According to the current official GPT-5.4 mini model page and GPT-5.4 nano model page, both checked on March 20, 2026:
| Spec | GPT-5.4 mini | GPT-5.4 nano |
|---|---|---|
| Input price | $0.75 / 1M tokens | $0.20 / 1M tokens |
| Cached input | $0.075 / 1M tokens | $0.02 / 1M tokens |
| Output price | $4.50 / 1M tokens | $1.25 / 1M tokens |
| Context window | 400K | 400K |
| Max output | 128K | 128K |
| Knowledge cutoff | Aug 31, 2025 | Aug 31, 2025 |
| Snapshot shown on model page | gpt-5.4-mini-2026-03-17 | gpt-5.4-nano-2026-03-17 |
So GPT-5.4 mini costs about 3.75x more on input, 3.75x more on cached input, and 3.6x more on output. That is a real architectural choice, not rounding noise.
Rate limits are closer than many people expect. On OpenAI's current compare models page, the big difference is mainly at lower paid tiers rather than across the whole line:
| Tier | GPT-5.4 mini TPM | GPT-5.4 nano TPM |
|---|---|---|
| Tier 1 | 500,000 | 200,000 |
| Tier 2 | 2,000,000 | 2,000,000 |
| Tier 3 | 4,000,000 | 4,000,000 |
| Tier 4 | 10,000,000 | 10,000,000 |
| Tier 5 | 180,000,000 | 180,000,000 |
That means the rate-limit story is not "nano always scales more." In paid production tiers, the choice is much more about task fit and unit cost than about raw TPM ceilings.
If you need the broader billing context behind token-based costs, our OpenAI API pricing guide is the better place to review account-level pricing basics. For this article, the decision is narrower: which of these two March 2026 small models should own which lane in your stack.
The more important comparison is tools:
| Capability | GPT-5.4 mini | GPT-5.4 nano |
|---|---|---|
| Web search | Yes | Yes |
| File search | Yes | Yes |
| Image generation tool | Yes | Yes |
| Code interpreter | Yes | Yes |
| Hosted shell | Yes | Yes |
| Apply patch | Yes | Yes |
| Skills | Yes | Yes |
| Computer use | Yes | No |
| MCP | Yes | Yes |
| Tool search | Yes | No |
This is where the comparison gets more interesting than most summaries allow.
Nano is not a stripped-down toy. It still supports a lot more than many people assume, including hosted shell, apply patch, skills, and image generation. If you stop reading at "cheapest small model," you miss that nano is still a capable worker for many narrow agent tasks.
But mini does keep the two features that most clearly separate heavier agent workflows from simpler ones: built-in computer use and tool search. Those are not cosmetic extras. They matter if the model has to navigate software through screenshots or operate across larger tool ecosystems without loading everything up front.
That is why a serious comparison should not reduce the decision to "cheaper versus better." The better question is: does your product need those extra workflow surfaces badly enough to pay mini's cost?
Benchmark Gaps That Actually Matter
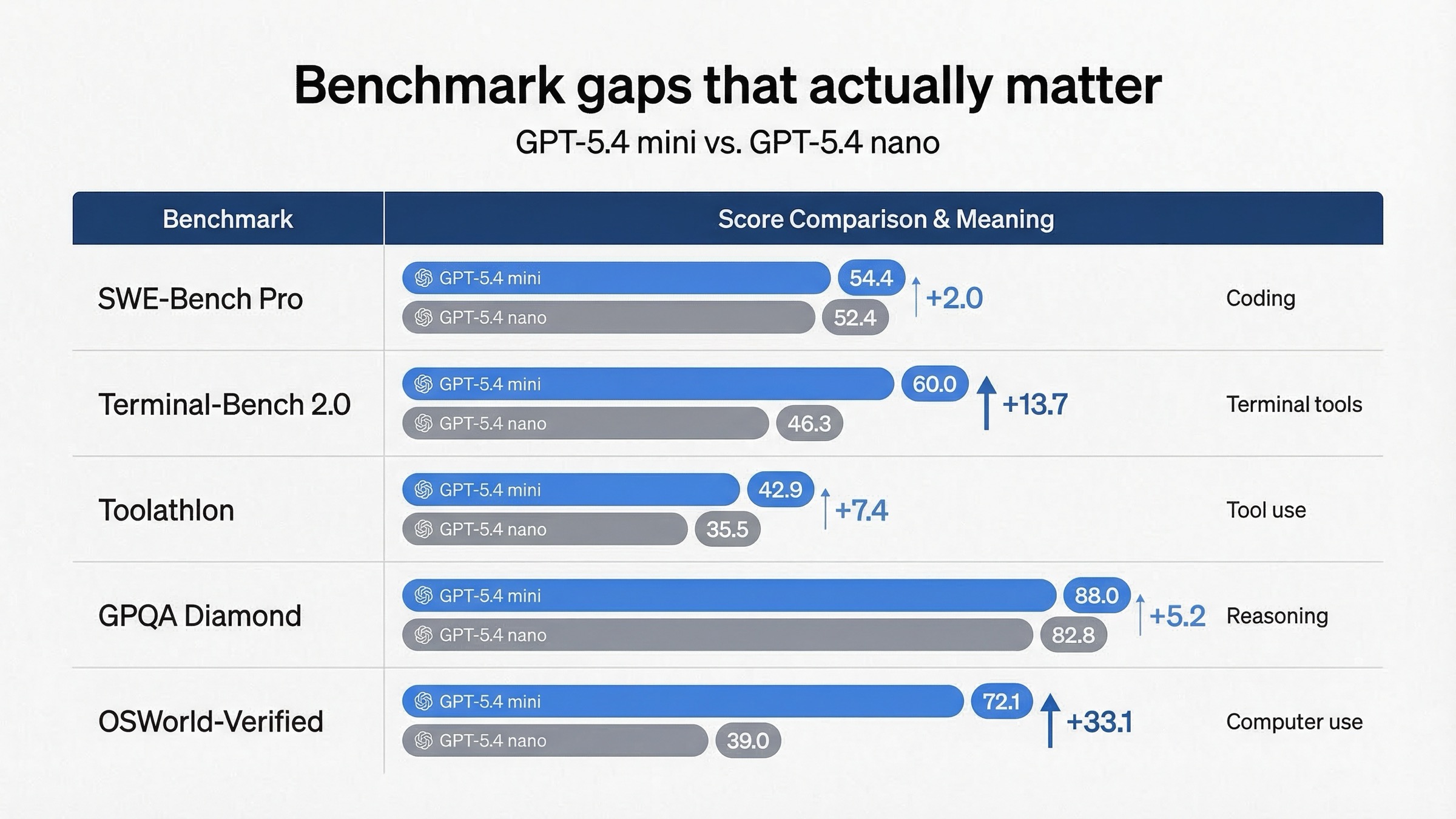
OpenAI's March 17, 2026 launch post gives the cleanest official side-by-side benchmark table:
| Benchmark from OpenAI's launch post | GPT-5.4 mini | GPT-5.4 nano | What it actually tells you |
|---|---|---|---|
| SWE-Bench Pro (Public) | 54.4% | 52.4% | Mini is better for real software issue resolution, but the gap is not huge |
| Terminal-Bench 2.0 | 60.0% | 46.3% | Mini is much stronger when terminal-style tool work gets harder |
| Toolathlon | 42.9% | 35.5% | Mini is better at tool use reliability |
| GPQA Diamond | 88.0% | 82.8% | Mini has more headroom on harder reasoning |
| OSWorld-Verified | 72.1% | 39.0% | Mini is on a different tier for computer-use-style workflows |
Three conclusions matter more than the raw table.
First, mini's edge is not equally important everywhere. The SWE-Bench gap is real, but it is not massive. If your workload is light code editing, small helper tasks, or cheap support subagents, nano may still be the better trade. The table does not force mini for every coding-related request.
Second, the places where mini really separates are terminal-heavy, tool-heavy, and computer-use-heavy work. That is exactly what the tool-support table already hinted at. The benchmark table and the supported-tools table point in the same direction, which is why the article can make a stronger recommendation than a generic spec aggregator can.
Third, nano still clears a surprisingly useful performance floor. If you read the table carefully, GPT-5.4 nano is not weak. It is just clearly aimed at the cheap lane. OpenAI is basically saying: use nano when you want a fast, inexpensive worker for simpler supporting tasks, and use mini when those supporting tasks are no longer simple.
This is the line most current pages fail to draw. They dump the benchmarks, but they do not tell you how to budget around them.
My rule of thumb is:
- Pay for mini when a mistake, failure, or slow recovery in a tool workflow is expensive.
- Use nano when the task is cheap enough, narrow enough, or repetitive enough that mini's extra headroom would mostly be wasted.
When GPT-5.4 mini Is Worth the Extra Spend
GPT-5.4 mini is worth paying for when your model is doing work that looks more like a junior operator than a cheap classifier.
The clearest case is coding assistants. OpenAI positions mini as the stronger fit for coding workflows, and the benchmark table supports that. If the model needs to navigate a codebase, inspect multiple files, recover after a failed tool call, reason about diffs, or behave well inside a coding harness, mini is the safer default.
The second case is computer-use or screenshot-heavy workflows. This is where mini pulls furthest away. If the system needs to inspect a UI, act through software, or reason over dense screenshots in a structured loop, mini is not just "a bit better." It is the only model in this pair with built-in computer use support, and the OSWorld-Verified gap is large enough to matter operationally.
The third case is deeper subagent work. OpenAI's launch post explicitly calls out Codex-style delegation, where a larger model handles planning and a smaller model handles narrower parallel subtasks. Mini is the better worker when those subtasks still require stronger coding judgment, search across many tools, or more robust tool behavior.
The fourth case is mixed tool ecosystems. Tool search is easy to overlook if you read only the headline specs. But if your system needs to choose among many tools, namespaces, or MCP surfaces, mini has a real workflow advantage over nano. Nano can still be useful when the toolset is small and known; mini is safer when the tool surface becomes messy.
Use GPT-5.4 mini if most of these are true:
- The model handles meaningful coding work rather than tiny edits.
- The model needs computer use or screenshot-grounded reasoning.
- Tool failure costs you latency, retries, or user trust.
- The worker is part of an agent system, but its subtasks are still fairly demanding.
- The extra spend is small compared with the engineering cost of weaker behavior.
That last point matters. People often compare model prices as if tokens were the only cost in the system. In real products, retries, fallbacks, prompt complexity, operator intervention, and user-visible delays also cost money. Mini is often justified when it reduces those hidden costs.
When GPT-5.4 nano Is the Better Default
GPT-5.4 nano is not just the model you choose when the budget is tiny. It is the model you choose when the task genuinely belongs on the cheap lane.
OpenAI directly recommends nano for classification, data extraction, ranking, and simpler coding subagents. That is a useful list because it translates nicely into common production workloads:
- classify user intent or support tickets
- extract structured fields from text
- rank or sort candidate results
- route requests to other systems
- run simple background checks or support tasks under a larger planner
In those situations, the product often wins more from lower cost and faster throughput than from higher benchmark ceilings.
Nano is also the better default when the task feels operationally shallow even if the surrounding product is sophisticated. For example, your main system might use a large planner or a stronger worker for hard branches, but still use nano to:
- summarize tool output before handing it back to a planner
- filter or prioritize candidate documents
- extract fields for a downstream rule engine
- handle cheap validation or routing work
That is the right way to think about nano: not as a weaker universal model, but as the cheaper specialist for simpler lanes.
If you are still comparing the current cheap lane against older small-model habits, it is also worth reading our GPT-5.4 mini vs GPT-5 mini comparison, because many teams are still carrying 2025-era assumptions into a 2026 routing decision.
Use GPT-5.4 nano if most of these are true:
- The task is narrow, repetitive, or structurally simple.
- You care more about unit economics than about edge-case tool depth.
- The model does not need built-in computer use.
- The model does not need tool search across a large tool universe.
- You are designing a support worker under a larger coordinating model.
In other words, nano is the right default when your question is not "Which small model is stronger?" but "What is the cheapest model that still does this job well enough?"
The Best Architecture Is Often Both, Not One
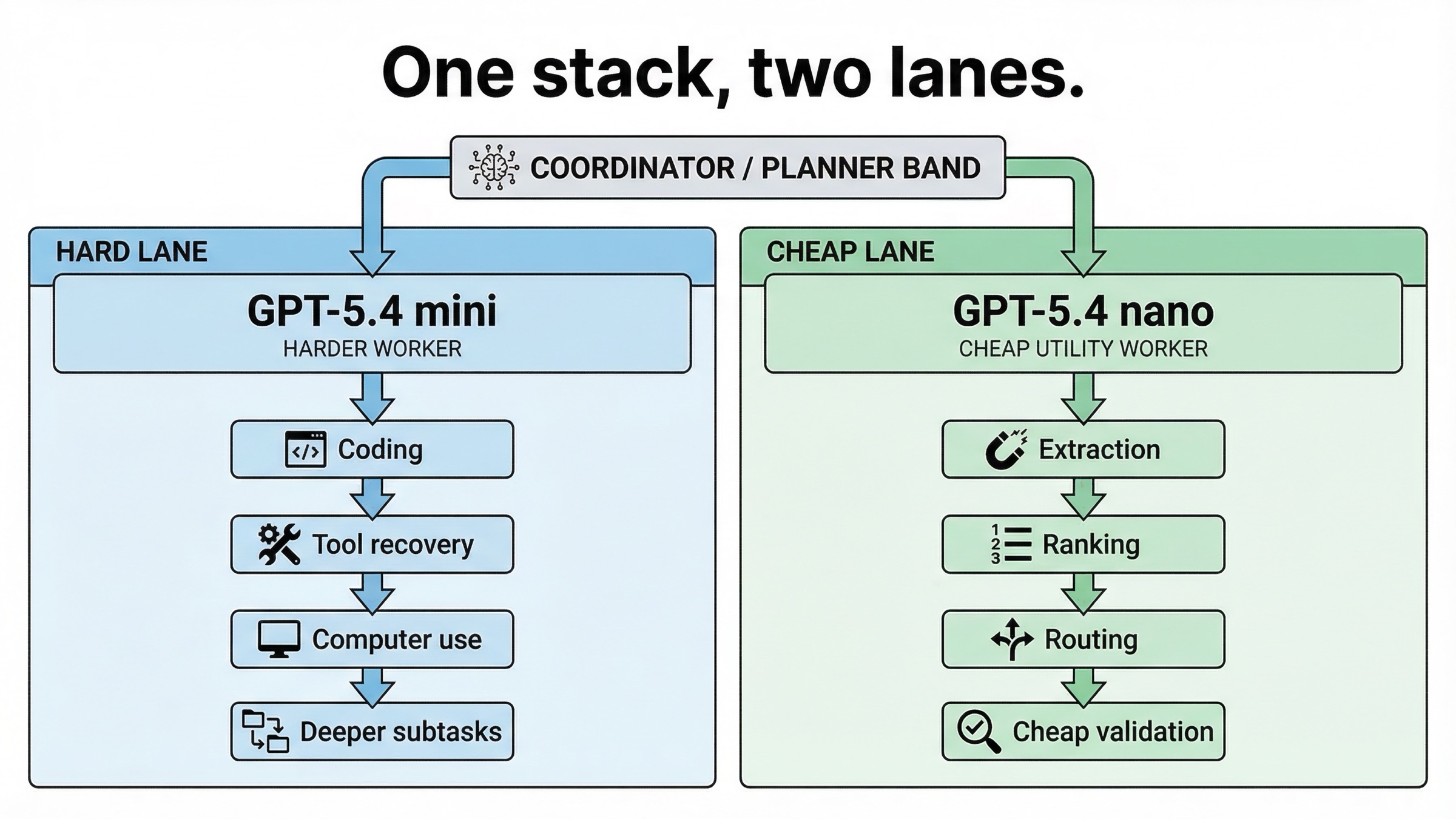
This is the part most comparison pages skip, even though it is often the most useful decision.
If your product has one single request type, then yes, you can choose mini or nano. But many real systems have at least two lanes:
- a harder lane where coding, tool recovery, screenshot interpretation, or deeper reasoning matter
- a cheaper lane where extraction, ranking, classification, or support tasks dominate
In those cases, forcing one model to do both jobs is often worse than routing them separately.
A practical split looks like this:
| Lane | Better model | Why |
|---|---|---|
| Planner or harder worker | GPT-5.4 mini | Better for coding depth, tool reliability, and computer-use-style work |
| Cheap helper or support worker | GPT-5.4 nano | Better economics for narrow, repeatable tasks |
This is exactly the kind of architecture OpenAI's launch post implies when it talks about subagents. Mini can own the more capable worker role, while nano can own the cheaper utility role when the subtasks are truly simple.
So if your team keeps asking, "Should we standardize on mini or standardize on nano?" the better answer may be "standardize on routing logic instead."
API vs Codex vs ChatGPT: Do Not Mix These Up
This keyword attracts a lot of confusion because users search from multiple product surfaces at once.
For API work, the official picture is straightforward:
- GPT-5.4 mini is available in the API.
- GPT-5.4 nano is available in the API.
For Codex, the launch post says GPT-5.4 mini is available across the Codex app, CLI, IDE extension, and web, and that Codex can delegate to GPT-5.4 mini subagents. GPT-5.4 nano is not presented as a Codex surface model in the same way.
For ChatGPT, the situation is much easier to misread. The launch post says GPT-5.4 mini is available through certain ChatGPT paths, but the current Help Center article also says GPT-5.3 is the default ChatGPT line for logged-in users and that paid users manually select GPT-5.4 Thinking. That means a ChatGPT user experience is not the same thing as an API model-selection recommendation.
So if your real question is "Which API model should I pay for?" use the model pages and the launch post. If your real question is "Which model do I see in ChatGPT?" use the Help Center. The names overlap, but the product decisions are not the same.
FAQ
Is GPT-5.4 mini always better than GPT-5.4 nano?
It is stronger, but not always the better choice. For simple high-volume tasks, nano can be the better model because its cost is much lower and its official best-fit workloads are exactly those simpler lanes.
Which one should I use for coding?
If the coding task is real coding work, choose mini. If the task is a simple supporting subagent inside a larger coding system, nano may still be good enough. The harder the tool flow and the more recovery or judgment you need, the more the answer shifts toward mini.
Which one should I use for extraction and ranking?
OpenAI explicitly recommends nano for classification, data extraction, and ranking. That makes nano the right place to start unless your tests show the task is harder than it looks.
Does GPT-5.4 nano support tools at all?
Yes. Nano still supports web search, file search, image generation, code interpreter, hosted shell, apply patch, skills, and MCP. The most important missing pieces versus mini are computer use and tool search.
Should a new team start with mini or nano?
Start with the actual job. If the job is coding-heavy or agent-heavy, start with mini. If the job is cheap throughput work, start with nano. If your product clearly has both lanes, plan to use both.
Final Recommendation
If you need one sentence to take back to your team, use this one: GPT-5.4 mini is the right small-model default for harder coding and agent workflows, while GPT-5.4 nano is the right default for cheap high-volume utility work.
That recommendation rests on five facts checked on March 20, 2026:
- Both models share the same context window, max output, and knowledge cutoff.
- Nano is dramatically cheaper.
- Mini has stronger benchmarks where coding, tool use, and computer-use behavior matter.
- Mini supports computer use and tool search; nano does not.
- OpenAI explicitly recommends nano for classification, extraction, ranking, and simpler supporting subagents.
So the real decision is not "Which one is better?" Mini is stronger. The real decision is whether your task is hard enough to need mini, or simple enough that paying for mini would mostly waste money. In many production systems, the correct answer is to let each model own a different lane.
If you are just getting your API environment ready before you test either model, start with the setup steps in our OpenAI API key guide. If your cheaper branch used to be framed as an o4-mini-style lane, our o4-mini API guide is also a useful background read before you redesign the routing split.