
Los errores 429 RESOURCE_EXHAUSTED de Gemini Image casi siempre nacen de una de dos causas: el proyecto todavía no tiene acceso facturable para generación de imágenes, o el proyecto ya agotó una ventana de cuota que Google aplica a nivel de proyecto. A fecha de 15 de marzo de 2026, los modelos actuales de Gemini para imagen siguen una ruta de pago, el reinicio diario de solicitudes ocurre a la medianoche del horario del Pacífico y la documentación oficial sigue usando el historial de facturación del proyecto como puerta de entrada entre Free, Tier 1, Tier 2 y Tier 3.
La diferencia importa porque la solución no siempre es "reintenta más fuerte". Si la cuota efectiva de imagen es cero, el backoff exponencial solo retrasa exactamente el mismo fallo. Si la facturación ya está activa, la pregunta correcta pasa a ser otra: ¿chocaste con RPM, con RPD, con TPM o con IPM?, ¿el cambio todavía se está propagando al proyecto correcto?, ¿o el problema real es un 503 por sobrecarga o un 400 por región no compatible? Esta guía está escrita para llevarte primero al arreglo más barato y más rápido, y después mostrarte las rutas de escalado que siguen teniendo sentido cuando el remedio corto deja de bastar.
Resumen rápido
La API de Gemini para imagen puede devolver 429 RESOURCE_EXHAUSTED aunque el problema real no sea un pico temporal de tráfico, sino que ese proyecto todavía no tiene derecho de imagen de pago. La documentación oficial actual dice que las cuotas se aplican por proyecto y no por API key, que el RPD se reinicia a medianoche en horario del Pacífico, que Batch API ofrece un 50% de descuento con su propia bolsa de cuota, y que la elegibilidad para Tier 2 o Tier 3 sigue dependiendo del gasto acumulado y de una ventana de 30 días. El camino más rápido suele ser verificar la facturación en el proyecto correcto y solo después mirar el metadata del error o el panel de uso para decidir entre reintentos, espera, Batch API o una ruta alternativa.
| Síntoma | Causa probable | Arreglo más rápido | Tiempo de recuperación |
|---|---|---|---|
Las solicitudes de imagen fallan enseguida con cuota 0 o sin límite usable de imagen | El proyecto todavía no tiene acceso de pago para el modelo que llamas | Vincula la facturación al proyecto correcto y vuelve a revisar el panel vivo de cuotas | Normalmente minutos; a veces horas si la verificación de pago se retrasa |
| El 429 aparece solo durante picos de tráfico | Se agotó una ventana de RPM, TPM o IPM | Añade backoff exponencial con jitter y reduce la concurrencia del pico | Segundos o pocos minutos |
| El 429 llega después de horas de uso continuo | Se agotó el RPD | Espera al reinicio de medianoche en horario del Pacífico o manda el trabajo no urgente a Batch API | Horas hasta el reinicio |
| El 429 sigue apareciendo aún con facturación activa | Proyecto equivocado, propagación incompleta o tier insuficiente | Verifica project ID, billing account, estado del tier y página de cuota del modelo | Minutos si era propagación; más si el cuello es estructural |
| La respuesta real es 503 o un 400 de región | No es un problema de cuota | Reintenta brevemente los 503 o activa facturación / cambia a una región compatible para el 400 | Depende de la clase real del error |
Solución de problemas: relaciona tu síntoma con el arreglo correcto

Antes de entrar en detalles técnicos, identifica qué clase de fallo tienes delante. Parece obvio, pero es el paso que más se omite. Mucha gente ve el mismo envoltorio 429 RESOURCE_EXHAUSTED y concluye que todas las averías tienen la misma causa. En la práctica, las soluciones rápidas cambian mucho según se trate de un proyecto sin acceso pagado de imagen, de una ventana corta de cuota ya agotada o de un cubo diario vacío para el resto del día.
Si estás viendo 429 ahora mismo y necesitas un arreglo inmediato, empieza por una pregunta: ¿la facturación está asociada exactamente al Google Cloud project que está detrás de la API key en uso? La guía oficial de billing dice que configurar la facturación habilita el uso facturable de forma inmediata, pero los hilos reales muestran otro problema: el equipo activa billing en un proyecto y sigue llamando a otro. Si la página de uso sigue enseñando una cuota de imagen cero o inexistente para tu modelo, reintentar no servirá. Primero arregla el enlace entre proyecto, API key y cuenta de cobro.
Si la facturación ya está activada pero sigues chocando con límites, identifica cuál cubo cae primero. Los picos breves suelen apuntar a RPM, TPM o IPM. Un job que funciona durante horas y muere al final de la tarde apunta a RPD. Un workload aparentemente pequeño también puede fallar porque el cambio de billing todavía se propaga, porque el proyecto vivo está ligado a otra billing account o porque el modelo preview de imagen tiene un techo más estrecho que los modelos de texto con los que ya trabajabas. Por eso el metadata del error, el panel de uso y el project ID valen más que cualquier consejo genérico de "espera y reintenta".
Si estás diseñando un proyecto nuevo, asume la realidad de cuota desde el primer día. Arranca con billing activo, registra el project ID y el campo quota_limit cada vez que aparezca un 429, manda el trabajo no urgente a Batch API y deja a mano la página oficial de rate limits. Ese enfoque apenas aumenta el coste inicial, pero evita gran parte de la confusión que luego se resume como "Gemini Image no funciona".
Cómo funcionan los límites de Gemini Image en 2026

La API de Gemini mide el uso en cuatro dimensiones distintas, y entender cómo interactúan es fundamental para diagnosticar un cuello de botella de imagen. Mucha gente solo piensa en RPM, pero el panorama operativo es más amplio: cada dimensión se comprueba por separado, las cuotas cuelgan del proyecto y la tabla exacta puede variar según la familia del modelo y el tier. Por eso la página oficial de precios y el panel vivo de cuotas son más fiables que una captura vieja o un post con números congelados.
RPM (requests per minute) limita cuántas llamadas puedes hacer en una ventana de 60 segundos. En imagen suele ser el primer límite que se siente cuando un lote drena la cola, cuando varios usuarios disparan prompts al mismo tiempo o cuando un sistema mal configurado reintenta sin control. Si necesitas una referencia más amplia de todo el árbol de cuotas, puedes apoyarte en nuestra guía completa sobre límites de Gemini API junto con la tabla oficial del modelo que estés usando.
RPD (requests per day) marca el techo diario. La documentación oficial sigue diciendo que el RPD se reinicia a medianoche del horario del Pacífico. Eso lo convierte en el culpable más probable cuando el sistema funciona bien por la mañana y empieza a devolver 429 por la noche. Entender cuándo se reinician los límites de Gemini Image ayuda a decidir si conviene esperar, repartir la carga entre días o empujar el backlog a Batch API.
TPM (tokens per minute) mide caudal de tokens y no solo número de llamadas. En imagen importa cuando mezclas salida visual con prompts muy largos, múltiples referencias o llamadas híbridas texto+imagen. No suele ser el primer número que mira un desarrollador, pero sí puede explicar por qué dos requests al mismo ritmo no se comportan igual.
IPM (images per minute) es la dimensión que más se pasa por alto y, al mismo tiempo, la que más duele en los workloads de imagen. Solo existe para modelos capaces de generar imagen. De ahí viene la sorpresa de muchos equipos que migran desde uso puramente textual de Gemini: sus límites de texto parecen sanos, pero el proyecto no muestra una capacidad real de imagen utilizable.
El ajuste de cuotas del 7 de diciembre de 2025 explica por qué tantos tutoriales antiguos suenan desfasados. La documentación de Firebase avisa expresamente de que las apps pueden empezar a devolver 429 RESOURCE_EXHAUSTED después de ese cambio. Esa nota es importante porque obliga a tratar la frescura del dato como parte del arreglo, no como un detalle secundario.
| Qué cambia con la facturación y el tier | Guía oficial actual |
|---|---|
| Propietario de la cuota | Las cuotas se aplican por proyecto, no por API key |
| Entrada a Tier 1 | Vincular billing al proyecto correcto habilita uso facturable |
| Requisito de Tier 2 | Más de $250 de gasto acumulado y al menos 30 días desde un pago correcto |
| Requisito de Tier 3 | Más de $1,000 de gasto acumulado y al menos 30 días desde un pago correcto |
| Reinicio diario | El RPD se reinicia a medianoche, horario del Pacífico |
| Ruta batch | Bolsa de cuota separada, 50% de descuento y hasta 24 horas de turnaround |
Hay un malentendido que conviene corregir de forma frontal: la cuota es por proyecto, no por API key. Crear muchas claves dentro del mismo proyecto no multiplica nada. Otro error habitual es pensar que las cuatro dimensiones se agotan por separado y de forma visible. En realidad, una llamada puede cumplir con el RPM actual y ser rechazada porque IPM o RPD ya se agotaron. Esa interacción explica por qué los fallos intermitentes siguen apareciendo incluso cuando el número bruto de requests parece modesto.
Corrige el 429 en cinco minutos con backoff exponencial
Cuando necesitas que la generación vuelva a funcionar cuanto antes, el primer cambio de código más seguro es el backoff exponencial con jitter. La guía oficial de troubleshooting para 429 sigue recomendando "retry later" o pedir más cuota. En producción, la manera más sensata de convertir ese consejo en código es aplicar reintentos con demora progresiva. Eso da tiempo a que las ventanas cortas de cuota se recuperen y evita que todos los workers golpeen otra vez la API al mismo segundo.
La idea es simple: si una llamada devuelve 429, espera un tiempo base y reintenta. Si falla otra vez, duplica la espera. Repite hasta que el request pase o hasta que alcances un máximo de reintentos. El jitter mete una pequeña variación aleatoria para evitar el problema del "thundering herd", donde todos los clientes vuelven a la carga en el mismo instante y empeoran el atasco. Si necesitas profundizar más en el error y sus variantes, puedes revisar nuestra guía sobre 429 quota exceeded.
Aquí tienes una implementación en Python adaptada a generación de imagen:
pythonimport time import random from google import generativeai as genai def generate_image_with_retry(prompt, model_name="gemini-3.1-flash-image-preview", max_retries=5, base_delay=1.0): """Generate an image with exponential backoff retry logic. Args: prompt: The image generation prompt model_name: Gemini model to use max_retries: Maximum retry attempts (default 5) base_delay: Initial delay in seconds (default 1.0) Returns: Generated content response or raises after max retries """ model = genai.GenerativeModel(model_name) for attempt in range(max_retries): try: response = model.generate_content(prompt) return response except Exception as e: error_str = str(e) if "429" in error_str or "RESOURCE_EXHAUSTED" in error_str: if attempt == max_retries - 1: raise RuntimeError( f"Rate limit exceeded after {max_retries} retries. " f"Consider upgrading your tier or reducing request frequency." ) from e # Calculate delay with exponential backoff + jitter delay = base_delay * (2 ** attempt) jitter = delay * 0.25 * (random.random() - 0.5) wait_time = delay + jitter print(f"Rate limited (attempt {attempt + 1}/{max_retries}). " f"Waiting {wait_time:.1f}s before retry...") time.sleep(wait_time) else: # Non-rate-limit errors should propagate immediately raise
Esta versión incluye detalles que muchos snippets rápidos olvidan. El jitter del 25% evita reintentos sincronizados. La función distingue entre errores de cuota, que sí merecen reintento, y otros fallos que deben salir enseguida para no esconder bugs reales. El mensaje final, cuando agotas el máximo de intentos, empuja al lector hacia la decisión correcta: o subir de tier, o bajar frecuencia, o cambiar de arquitectura.
Si trabajas con JavaScript o TypeScript, el mismo patrón se traduce así:
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); async function generateImageWithRetry(prompt, { modelName = "gemini-3.1-flash-image-preview", maxRetries = 5, baseDelay = 1000 } = {}) { const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY); const model = genAI.getGenerativeModel({ model: modelName }); for (let attempt = 0; attempt < maxRetries; attempt++) { try { const result = await model.generateContent(prompt); return result.response; } catch (error) { const isRateLimit = error.message?.includes("429") || error.message?.includes("RESOURCE_EXHAUSTED"); if (isRateLimit && attempt < maxRetries - 1) { const delay = baseDelay * Math.pow(2, attempt); const jitter = delay * 0.25 * (Math.random() - 0.5); const waitTime = delay + jitter; console.log(`Rate limited (attempt ${attempt + 1}/${maxRetries}). ` + `Waiting ${(waitTime / 1000).toFixed(1)}s...`); await new Promise(resolve => setTimeout(resolve, waitTime)); } else { throw error; } } } }
Lo ideal es meter estas funciones en el cliente estándar de tu API, no dispersarlas por todo el código. Así mantienes una política coherente de reintentos y evitas que cada módulo improvise una estrategia distinta. Dicho esto, el backoff no resuelve problemas estructurales. Si el proyecto realmente consume más imágenes por minuto o por día de las que su tier soporta, solo vas a conseguir más latencia. En ese caso hace falta subir de tier, separar trabajos hacia Batch API o distribuir la carga entre varios proyectos.
Cómo subir de tier en Gemini API
Subir de tier sigue siendo la solución de largo plazo más directa, y el proceso es más simple de lo que muchos creen, aunque hay varios puntos ciegos que retrasan la activación. El sistema es acumulativo: avanzas automáticamente de Free a Tier 1, luego a Tier 2 y después a Tier 3 cuando cumples los requisitos de gasto y tiempo. No hace falta una solicitud manual para el camino estándar.
De Free a Tier 1 (instantáneo y decisivo). Para la mayoría de lectores este es el cambio con más impacto. La documentación oficial de billing dice que el uso facturable se habilita inmediatamente después de la configuración, y la guía de rate limits sigue tratando la facturación de pago como la puerta de entrada a Tier 1. En castellano simple: si el proyecto se comporta como si no tuviera acceso de imagen, activar billing es lo primero que debes corregir. Y no, activar billing no implica una cuota mensual fija: pagas el uso facturable que realmente consumas. Si necesitas el paso a paso completo, puedes revisar nuestra guía para subir a paid tier.
La ruta más rápida suele pasar por AI Studio: entra en aistudio.google.com, ve a Dashboard, abre Usage and Billing, entra en la pestaña Billing y pulsa "Set up Billing". Necesitarás un medio de pago, pero Google no cobra simplemente por tener billing activo. Otro detalle útil de la documentación oficial: las solicitudes fallidas con 400 y 500 no se cobran, aunque sí cuentan contra la cuota. Eso hace que activar billing pronto sea menos arriesgado de lo que parece, aunque un loop de reintentos mal hecho puede seguir malgastando cuota.
Problema frecuente número 1: la verificación de billing a veces tarda más de lo esperado, sobre todo en cuentas nuevas. Si el cambio no parece surtir efecto en una hora, revisa el correo por si hay un paso pendiente y confirma que la API key realmente pertenece al proyecto al que acabas de asignar la billing account. Suena trivial, pero ese es exactamente el patrón que aparece una y otra vez en foros y en issues de GitHub.
Si el 429 sigue vivo aún después de activar billing, pasa un checklist corto antes de rediseñar la arquitectura. Comprueba el project ID real en tus logs, confirma que la billing account está activa en ese proyecto, refresca la página oficial de uso para ver si el modelo ya muestra una capacidad de imagen facturable y relee el error exacto para asegurarte de que sigue siendo 429 y no un 503 o un 400 por región. La idea es tratar "billing ya está activado" como una afirmación que se verifica, no como una casilla que se asume resuelta.
De Tier 1 a Tier 2 ($250 + 30 días). La página oficial de rate limits sigue exigiendo dos condiciones: más de $250 de gasto acumulado en Google Cloud y al menos 30 días desde un pago correcto. La mejora llega de forma automática cuando ambos requisitos se cumplen. Un matiz importante: los créditos de prueba de Google Cloud no cuentan hacia ese umbral.
De Tier 2 a Tier 3 ($1,000 + 30 días). Tier 3 sigue pidiendo más de $1,000 de gasto acumulado y el mismo mínimo de 30 días. Las organizaciones que necesitan más que el techo publicado pueden entrar en conversaciones enterprise con Google, pero para la mayoría de equipos el mensaje práctico es más sencillo: si necesitas más capacidad esta misma semana, el reloj de Tier 2 y Tier 3 es demasiado lento para ser tu único plan.
Problema frecuente número 2: el progreso de tier es por proyecto, no por cuenta. Si repartes carga entre varios proyectos, cada uno debe construir su propio historial de gasto. Esa es justo la razón por la que la estrategia multi-project puede ser potente para escalar, pero también la razón por la que tanta gente se confunde cuando espera que el gasto de un proyecto desbloquee otro.
Pedir una subida de cuota por encima del tier. Desde Tier 2 en adelante, Google sigue ofreciendo la opción de solicitar una ampliación de cuota desde Cloud Console. La ruta típica es IAM & Admin, luego Quotas, y ahí buscar generate_content_requests_per_minute. Añade un caso de uso claro, el volumen esperado y la razón de negocio. Los tiempos de revisión varían, y Google no promete aprobar aumentos, de modo que no conviene depender de esta vía como remedio urgente.
Cuánto cuesta realmente Gemini Image
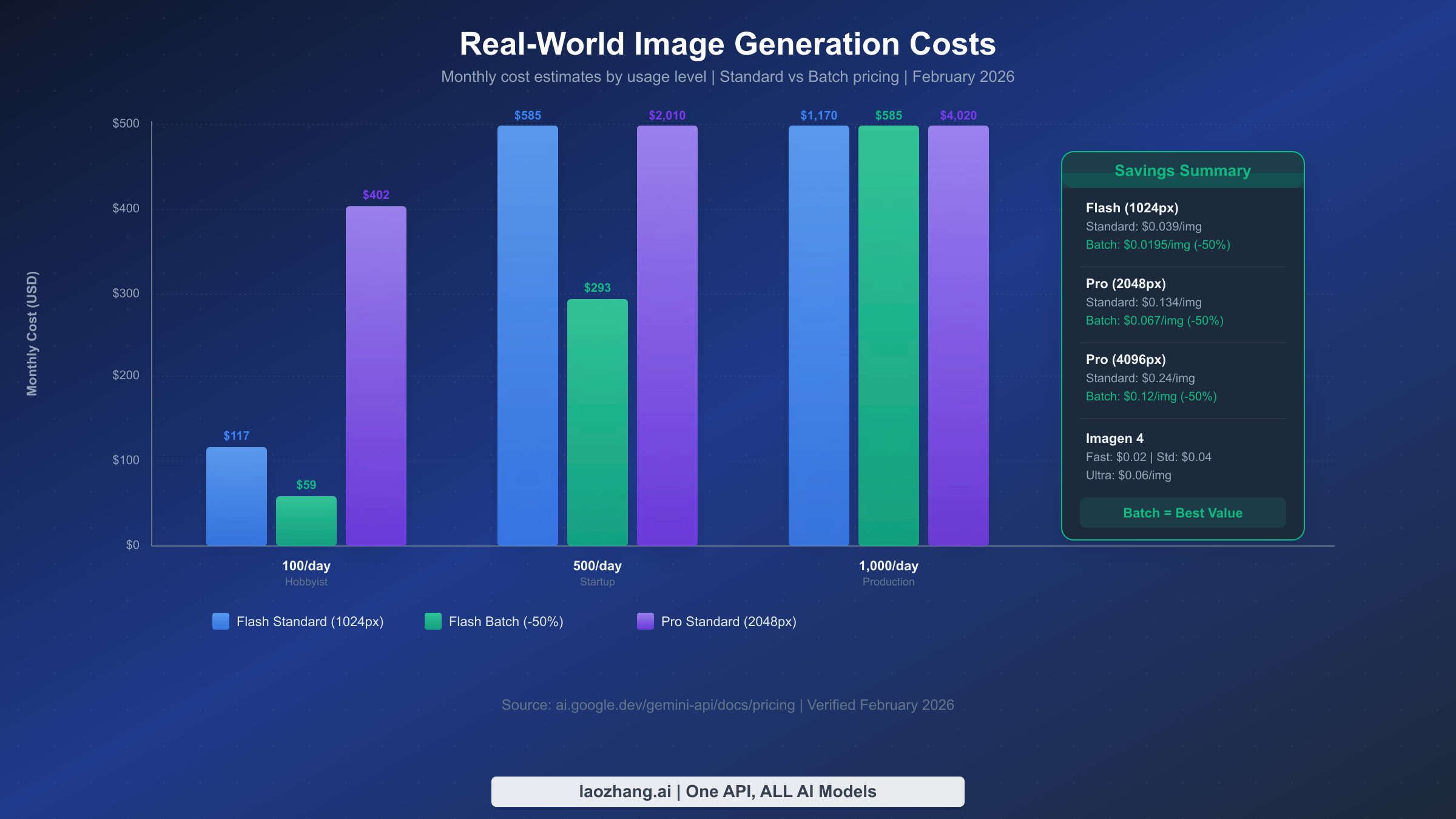
Entender el coste real de Gemini Image es imprescindible para decidir si la solución correcta es activar billing, esperar al siguiente tier o desviar trabajo a Batch API. La estructura de precios depende del modelo y del tamaño de salida, y todas las cifras de esta sección se revisaron contra la página oficial de precios de Google AI el 15 de marzo de 2026.
Para muchos equipos que chocan hoy con 429 de imagen, la puerta de entrada pagada más realista es Gemini 3.1 Flash Image Preview. La página oficial mapea su precio de salida a $0.045 en 512, $0.067 en 1024, $0.101 en 2048 y $0.151 en 4096. Si necesitas mejor calidad o composiciones más exigentes, Gemini 3 Pro Image Preview aparece a $0.134 por imagen en 1024 y 2048, y a $0.24 en 4096. Poner estos precios en la mesa cambia por completo la conversación: activar billing deja de ser un riesgo abstracto y se convierte en un coste por imagen perfectamente acotado.
Batch API sigue siendo la mayor optimización oficial de coste: un 50% de descuento sobre el precio de tokens a cambio de aceptar procesamiento asíncrono con un turnaround documentado de hasta 24 horas. Para trabajos que no necesitan salida inmediata, Batch API no es solo una herramienta de ahorro: también es un alivio de cuota porque usa un pool separado. Si te interesa profundizar en caminos de acceso más baratos, puedes mirar nuestra guía sobre el acceso más económico a Gemini Image.
Así se traducen esos precios a gasto mensual en escenarios reales:
| Nivel de uso | Imágenes/mes | Flash 1024 estándar | Flash 1024 batch | Pro 2K estándar | Pro 2K batch |
|---|---|---|---|---|---|
| Hobby | 3,000 (100/día) | $201 | $100.50 | $402 | $201 |
| Startup | 15,000 (500/día) | $1,005 | $502.50 | $2,010 | $1,005 |
| Producción | 30,000 (1,000/día) | $2,010 | $1,005 | $4,020 | $2,010 |
| Empresa | 300,000 (10,000/día) | $20,100 | $10,050 | $40,200 | $20,100 |
Los ahorros se pueden apilar. Usar Flash en lugar de Pro reduce aproximadamente a la mitad el coste por imagen en muchos casos estándar. Si además mandas el trabajo a Batch API, vuelves a dividir a la mitad el gasto restante. En la tabla actual, Flash a 1024 baja de $0.067 a $0.0335 con batch. Eso significa que 1,000 imágenes por día se quedan cerca de $1,005 al mes en lugar de $2,010. Para proyectos sensibles a presupuesto, las alertas de Cloud Billing siguen siendo el freno más simple contra sorpresas.
El coste de acceso a los tiers también entra en el cálculo. Alcanzar Tier 2 sigue exigiendo más de $250 de gasto acumulado. A precios actuales de imagen, eso equivale aproximadamente a 3,731 imágenes Flash 1024 o 1,865 imágenes Pro 2K si todo ese gasto proviniera solo de generación visual. En proyectos reales el gasto puede venir de otros servicios de Google Cloud, así que la decisión de fondo no es solo "cuánto vale una imagen", sino también "¿me compensa esperar al umbral o me sale mejor usar una ruta intermedia como laozhang.ai mientras madura el tier oficial?".
Estrategias avanzadas para aumentar el throughput
Una vez que ya tienes reintentos sensatos y un tier apropiado, existen varias estrategias que multiplican el throughput efectivo por encima de lo que ofrece un solo proyecto. Son especialmente útiles cuando el producto necesita generar muchas imágenes con estabilidad, sin la latencia excesiva de un backoff agresivo.
Distribución multi-project. Como las cuotas se aplican por proyecto, repartir las peticiones entre varios Google Cloud projects puede multiplicar la capacidad efectiva. La implementación habitual consiste en mantener un pool de API keys, una por proyecto, y repartir tráfico con round-robin o con pesos según carga. El beneficio real es que un 429 en un proyecto no paraliza a los demás. El coste, claro, es administrativo: cada proyecto construye su propia historia de gasto y su propio progreso de tier.
pythonimport itertools from google import generativeai as genai class MultiProjectImageGenerator: def __init__(self, api_keys: list[str], model_name: str = "gemini-3.1-flash-image-preview"): self.clients = [] for key in api_keys: genai.configure(api_key=key) self.clients.append(genai.GenerativeModel(model_name)) self.key_cycle = itertools.cycle(range(len(self.clients))) def generate(self, prompt: str): """Generate image using next available project in rotation.""" project_idx = next(self.key_cycle) client = self.clients[project_idx] try: return client.generate_content(prompt) except Exception as e: if "429" in str(e): # Try next project on rate limit next_idx = next(self.key_cycle) return self.clients[next_idx].generate_content(prompt) raise generator = MultiProjectImageGenerator([ "AIzaSy-project1-key", "AIzaSy-project2-key", "AIzaSy-project3-key", ])
En la práctica, el umbral de Tier 2 de $250 por proyecto significa que tres proyectos en Tier 2 suponen $750 de gasto acumulado. Para algunos workloads eso compensa porque evita caídas; para otros, esa complejidad es la señal de que conviene mover trabajo a batch o mirar un agregador.
Batch API para trabajo en segundo plano. La documentación oficial describe Batch API como un sistema con cuota separada, turnaround de 24 horas, 50% de descuento, límite de 100 jobs concurrentes, 2 GB máximos por archivo de entrada y 20 GB de almacenamiento total de batch. Si el trabajo no es interactivo, esta es una de las rutas más limpias para liberar cuota en tiempo real.
Queue local con rate limiting. En lugar de esperar a que la API te frene, puedes imponer un token bucket o una cola local que solo despache solicitudes cuando haya capacidad disponible. Esto reduce el número de 429 que llegan a producción y evita que el usuario final experimente un mosaico de fallos aleatorios.
Caché de imágenes generadas. Se subestima mucho. Si tu producto genera recursos parecidos, variaciones de los mismos prompts o thumbnails de clases repetidas, una capa de caché sencilla puede recortar 30% o 50% del consumo sin tocar el modelo ni el tier. Es una manera muy barata de "comprar" cuota adicional.
Programar la carga alrededor del reinicio. Como el RPD se reinicia a medianoche del horario del Pacífico, lanzar los trabajos pesados poco después de ese momento da la ventana diaria más amplia posible. No resuelve todos los cuellos, pero sí evita que un trabajo por lotes nazca condenado a mitad de una jornada ya casi agotada.
Cadenas de fallback entre modelos. Cuando el producto no puede pararse, un 429 no debería significar silencio. Puedes usar Gemini 3 Pro Image Preview como primera opción, Gemini 2.5 Flash Image como opción más barata y algún modelo alternativo como Imagen 4 en el tercer escalón. No siempre tendrás la misma calidad, pero sí ganas continuidad operativa.
Observabilidad de verdad. Registra el project ID, el modelo, el código de error y el quota_limit cada vez que aparezca un 429. Cruza eso con el panel de AI Studio o de Cloud y crea alertas sencillas al 70% y 90% del uso diario. Esa información te dirá si necesitas un tier mayor, un queue, Batch API o un cambio de ruta. Sin esos datos, casi todo se convierte en intuición.
Cuándo conviene una alternativa externa y cuál debería ser tu siguiente paso
Aunque la ruta oficial de Gemini API es la adecuada para muchos equipos, hay escenarios donde una alternativa externa tiene más sentido que pelearse con el calendario de tiers. La decisión no es solo de coste. También entra en juego la velocidad de entrega, la sencillez operativa y la tolerancia del proyecto a la complejidad de infraestructura.
Servicios agregadores de API como laozhang.ai ofrecen acceso a modelos de Gemini Image desde un endpoint unificado y, en algunos casos, con un throughput más flexible que el flujo directo de Google. El intercambio es claro: reduces el trabajo operativo de gestionar proyectos, billing accounts y progresión de tiers, pero añades una dependencia externa y aceptas una estructura de precios distinta.
Cuándo quedarse con la API oficial. Si tu sistema necesita garantías de SLA, integración nativa con otros servicios de Google Cloud, controles corporativos o un recorrido fuerte de compliance, la ruta oficial sigue siendo la correcta. También es la opción lógica cuando el producto ya vive dentro del ecosistema de Google y quieres simplificar red, latencia y seguridad.
Cuándo plantearte una alternativa. Si el proyecto tiene una fecha de salida muy cercana y esperar 30 días por Tier 2 te bloquea, si el tráfico llega en ráfagas muy desiguales o si necesitas combinar varios modelos de imagen bajo una sola capa técnica, un agregador puede quitar mucho peso operativo. Esto se vuelve especialmente atractivo en agencias, estudios o equipos que gestionan varios clientes y no quieren repetir una configuración completa de Google Cloud para cada uno.
No te quedes solo con Gemini. Imagen 4, OpenAI, Stability o Midjourney exponen sus propias reglas de cuota y pueden servir como red de seguridad. Para equipos que valoran resiliencia por encima de pureza de proveedor, el enrutado multi-modelo es muchas veces la respuesta más elegante: si un proveedor estrecha límites de repente, el producto sigue vivo.
El siguiente paso depende del horizonte que manejes. Para salir del paso hoy, verifica billing y añade backoff. Para el próximo mes, progresa hacia Tier 2 y mueve el trabajo no urgente a Batch API. Para escala real, trata los límites como un problema de arquitectura: cola, observabilidad, reparto entre proyectos cuando compense y decisión consciente sobre si te conviene más el tier oficial o una capa como laozhang.ai.
FAQ
¿Cuántas imágenes puedo generar al día con el tier gratuito de Gemini?
La respuesta práctica hoy es cero salida fiable de imagen de pago por API mientras no haya billing en el proyecto. La tabla exacta puede variar por modelo, pero el flujo actual de Gemini Image es de pago. Por eso el primer arreglo útil casi nunca es tocar reintentos; es activar facturación en el proyecto correcto.
¿Cuánto tarda pasar de Free a Tier 1?
Normalmente minutos. La documentación de billing dice que el uso facturable se habilita de inmediato, aunque en cuentas nuevas o con ciertos medios de pago puede haber retrasos de verificación. Si una hora después sigues fallando, revisa proyecto, billing account y panel de cuotas antes de asumir que la API está rota.
¿Tener varias API keys aumenta el limite?
No. Las cuotas se aplican por proyecto, no por clave. Diez keys en el mismo proyecto apuntan al mismo cubo. Para aumentar capacidad necesitas un tier mayor, otro proyecto, Batch API para tráfico asíncrono o una estrategia de routing distinta.
¿Cuando se reinician los limites de Gemini?
Las ventanas por minuto se recuperan solas según su rolling window. El límite diario de requests se reinicia a medianoche del horario del Pacífico. Si el backlog puede esperar, programar el trabajo justo después del reinicio es la salida sin código más barata.
¿Vale la pena Batch API para imagen?
Si puedes tolerar asincronía, sí. La documentación sigue prometiendo 50% de descuento y una ventana de hasta 24 horas, además de un pool de cuota separado del tráfico interactivo. Para thumbnails, catálogos, re-renderizados o pipelines de fondo es una de las mejores respuestas oficiales al 429 repetido.
¿Por que sigo viendo 429 aunque ya active billing?
Porque "billing activo" no siempre significa "el proyecto y el modelo exactos ya están listos para esta carga". Las causas más comunes son propagación incompleta, proyecto equivocado, tier insuficiente para el volumen o incluso otro error que se mezcló en la investigación. Vuelve a comprobar project ID, página viva de cuota y metadata bruto antes de tocar arquitectura.
¿Pido aumento de cuota o construyo un workaround primero?
Si necesitas alivio esta semana, construye primero el workaround. Pedir más cuota tiene sentido para una carga estable en producción, pero rara vez es el rescate más rápido. Backoff, Batch API, observabilidad y mejor higiene de proyecto suelen dar resultado antes que una cola de aprobación o un reloj de 30 días.