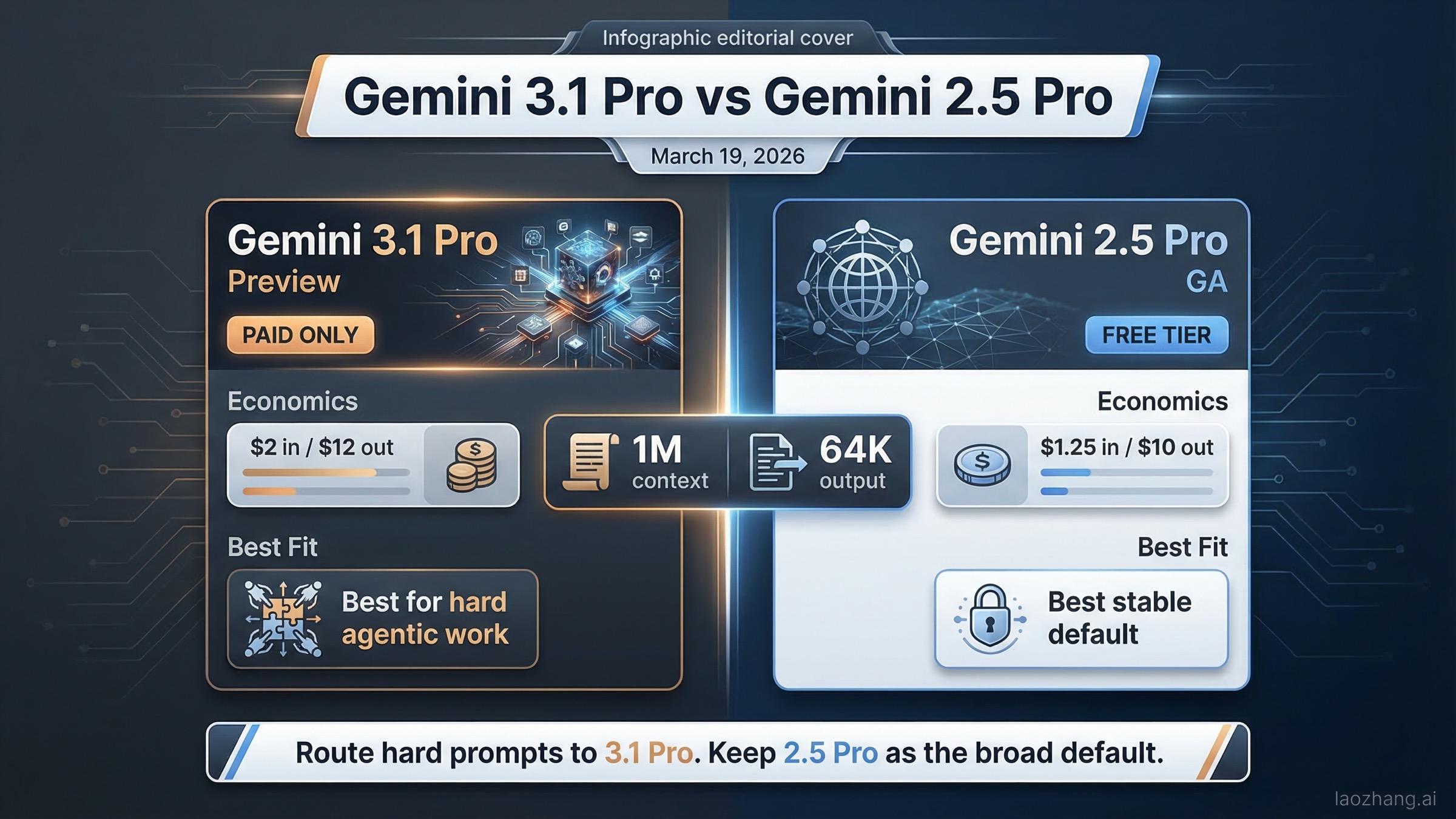
2026年3月19日時点で、最上位の性能だけを見るなら Gemini 3.1 Pro が優位です。ただし、実運用のデフォルトとしては Gemini 2.5 Pro の方が合理的なケースがまだ多く残っています。 一見すると矛盾ですが、Google公式ページを横並びで確認すると理由は明確です。Gemini 3.1 Pro は高難度推論向けの新しい Preview モデルで、価格設計も「難しい仕事用のプレミアムレーン」に寄っています。対して Gemini 2.5 Pro は GA(一般提供)済みで単価が低く、Gemini Developer API の無料枠も使えるため、運用の不確実性が小さいのが実情です。
つまり本当の問いは「紙の上でどちらが強いか」ではありません。問うべきは「2.5 Pro を全面的に置き換えるべきか、それとも 2.5 Pro を安定デフォルトに残し、難問だけ 3.1 Pro にエスカレーションすべきか」です。現状の比較記事は、ベンチマーク画像の再掲か、スペック羅列で終わるものが多く、この判断まで踏み込みません。この記事は逆に、最初に結論を示し、その結論を支える公式根拠を順番に確認します。
要点まとめ
先に結論だけ知りたい場合はここだけで十分です。ボトルネックが高難度推論・エージェント型コーディング・ツール連携の複合ワークフローにあるなら Gemini 3.1 Pro。GAの安定性、低単価、無料枠を重視するなら Gemini 2.5 Pro。 この切り分けが、2026年3月19日時点で最も実務的です。
公式情報を並べると、判断材料は次のようになります。
| 比較項目 | Gemini 3.1 Pro | Gemini 2.5 Pro | 実務での意味 |
|---|---|---|---|
| 提供ステータス | Preview | GA(一般提供) | 3.1は新しいが、常に全案件のデフォルトにすべきとは限らない |
| モデルID | gemini-3.1-pro-preview | gemini-2.5-pro | 移行は盲目的な置換ではなく、明示的ルーティングが必要 |
| 無料枠 | なし | あり | 検証・ステージング・低リスク試験は2.5の方が回しやすい |
| 標準入力単価 | $2.00 / 1M(200kまで) | $1.25 / 1M(200kまで) | 3.1は入力で約60%高い |
| 標準出力単価 | $12.00 / 1M(200kまで) | $10.00 / 1M(200kまで) | 3.1は出力で約20%高い |
| 長文プロンプト単価 | 200k超で $4.00 in / $18.00 out | 200k超で $2.50 in / $15.00 out | 長文域でも価格差は継続 |
| コンテキスト上限 | 1M tokens | 1M tokens | 3.1で文脈長が増えるわけではない |
| 最大出力 | 64K tokens | 64K tokens | 出力天井も同等 |
| 向く用途 | 高難度推論、先端エージェント作業 | 本番の安定デフォルト、コスト重視運用、無料枠検証 | 3.1は「プレミアムレーン」として使うのが合理的 |
上記は Gemini Developer API pricing、Gemini API models、Vertex AI model catalog、Gemini 3.1 Pro model card、Gemini 2.5 Pro model card PDF の記載を基にしています。重要なのは、Googleが2.5から3.1への移行を「上限値の拡大」としては提示していない点です。両者とも 1M context / 64K output で、実際の差分は性能・価格・成熟度にあります。
実務上の推奨はシンプルです。
- 高難度でレビュー工数が重いタスクは Gemini 3.1 Pro を使う。
- 日常開発や広い本番トラフィックは Gemini 2.5 Pro をデフォルトにする。
- ルーティング可能なら単一モデルに固定せず、2.5を本線・3.1を難問用に分離する。
「新モデルなのに、なぜ全置換ではないのか」という違和感はここで解消できます。3.1 Pro は万能置換というより、現時点ではプレミアムレーンと見る方が正確です。
2.5 Pro から 3.1 Pro で実際に変わったこと
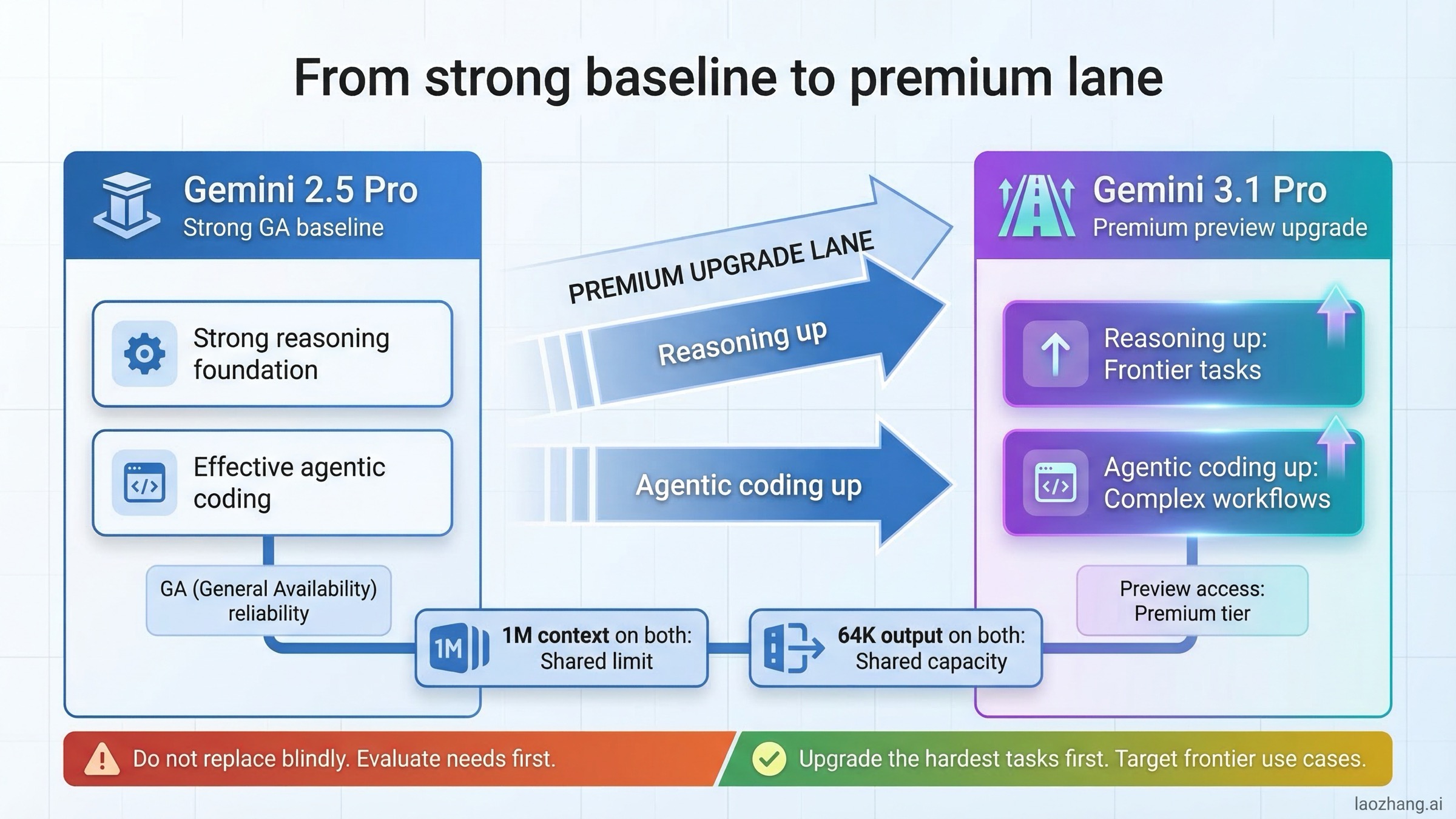
この比較で起きやすい誤解は、「2.5から3.1への移行は、主にコンテキスト長や出力上限の拡大だ」という見方です。実際は違います。最大の変化は Google 側のモデル位置づけです。
Vertex AI models ページでは、Gemini 3.1 Pro は Preview 枠で「複雑なエージェント型ワークフローとコーディング向けの最新推論モデル」として説明されています。一方で Gemini 2.5 Pro は GA 枠の高能力モデルとして整理されています。この書き分けは重要です。つまり Google 自身が、3.1を先端性能レーン、2.5を安定標準レーンとして提示していることになります。
Gemini 3.1 Pro model card(公開日: 2026-02-19)も同じ方向性です。3.1 Pro を「公開時点で最も高度な複雑タスク向けモデル」と位置づけ、1M context・64K output・Gemini app / Vertex AI / AI Studio / Gemini API / Google Antigravity / NotebookLM での利用を明示しています。これは、3.1を横断的な上位推論レーンに据えるという強いプロダクトシグナルです。
ただし Gemini 2.5 Pro model card(更新日: 2025-06-27)を読むと、2.5 Pro を切り捨てにくい理由も見えてきます。2.5 Pro は GA 化されており、同じ 1M context / 64K output を持ちます。つまり3.1に切り替えても、コンテキスト枠や出力枠が広がるわけではありません。多くの場合、買っているのは「上限」ではなく「難問への知能差」です。
この点は、3.1登場直前の2.5最終アップデート文脈を見るとさらに明確です。Googleの 2025-05-06 の記事 "Build rich, interactive web apps with an updated Gemini 2.5 Pro" では、コーディング・Webアプリ生成の改善や WebDev Arena での強さが前面に出されました。結果として2.5 Pro は「弱い旧世代」ではなく、実務で既に通用する基準モデルとして認知されています。
この比較で持つべき前提は以下です。
- Gemini 2.5 Pro は「古くて弱いモデル」ではない。
- Gemini 3.1 Pro は「同等機能の完全上位互換」ではない。
- 本質は「プレミアムPreview」と「安定GA」の選択である。
この前提で見ると、以降の価格や運用シグナルは矛盾なく読めます。
2026年3月19日時点の価格・無料枠・提供ステータス

移行判断が最も具体化するのは価格です。比較記事はベンチマークでぼかしがちですが、Gemini Developer API pricing を見ると、3月19日時点の差は明確です。
Gemini 3.1 Pro Preview の記載:
- 無料枠なし
- 200kトークンまで入力
\$2.00/ 1M - 200kトークンまで出力
\$12.00/ 1M - 200k超は入力
\$4.00/ 1M、出力\$18.00/ 1M - Batch API は標準料金の半額
Gemini 2.5 Pro の記載:
- 無料枠あり
- 200kトークンまで入力
\$1.25/ 1M - 200kトークンまで出力
\$10.00/ 1M - 200k超は入力
\$2.50/ 1M、出力\$15.00/ 1M - Batch API は標準料金の半額
標準価格差を整理すると次のとおりです。
- 入力単価: 3.1 Pro は 2.5 Pro より約60%高い
- 出力単価: 3.1 Pro は 2.5 Pro より約20%高い
- 無料枠: 3.1 Pro はなし、2.5 Pro はあり
本番アプリでは、上位モデルでリトライ削減やレビュー工数削減が効けば、この差は回収できます。ただし日常的な補助コーディング、広いユーザー向けトラフィック、ステージング用途では、値上がりと無料枠喪失の影響が先に出ます。多くのチームは「トークン単価差」より先に「安全な検証レーンの消失」を痛感します。
簡易試算でも傾向は同じです。たとえば月間で入力 50M、出力 10M、主に200k以下のプロンプトとすると:
- Gemini 2.5 Pro: 入力
50 x \$1.25 = \$62.50、出力10 x \$10 = \$100、合計\$162.50 - Gemini 3.1 Pro: 入力
50 x \$2.00 = \$100、出力10 x \$12 = \$120、合計\$220
この例では総額で約 35% の上昇です。しかも 2.5 側には無料枠を使った低リスク検証が残り、3.1にはありません。
さらに重要なのがステータス差です。Gemini API models と Vertex AI models はいずれも「3.1はPreview、2.5はGA」という同じ構図を示しています。Preview は即「不安定」を意味しませんが、挙動変更や運用前提の変化リスクを見込むべき段階です。
したがって本番で問うべきは「3.1を払えるか」ではなく、「2.5で足りる広いワークロードを捨ててまで、3.1の追加性能が必要か」です。多くのトラフィックでは依然として答えは No、難問レーンでは Yes になり得ます。
APIチームとGeminiアプリ利用者で結論が分かれる理由
このキーワードで検索結果が混線しやすいのは、読者が2種類いるからです。1つは本番で APIモデル選定 をする読者、もう1つは Google の Geminiアプリ上の利用可能モデル を知りたい読者です。関連はありますが、最適解は同一ではありません。
実際、SERPの露出も分かれています。API側の主要根拠は Gemini pricing、Gemini models、Vertex catalog、model card 群です。アプリ側は Gemini Apps limits and upgrades のようなヘルプページが上位に出やすく、「そのプランでこのモデルが使えるか」という別問題に読者が集中していることが分かります。
APIチーム での比較軸は主に5つです。
- 難問に対するモデル品質
- トークン単価
- 無料枠の有無
- 運用成熟度
- キャッシュ・バッチ・グラウンディングなど周辺課金
Geminiアプリ利用者 の関心はよりシンプルです。
- モデルピッカーで見えるか
- 契約プランで解放されるか
- 使用回数制約はどうか
- 体感品質が上がるか
この違いを無視すると「新しいほど高い」の雑な説明になり、実務では外れます。
pricingページ を詳しく見ると、Gemini 3.1 Pro Preview は有料のみで、周辺コストも高めです。200k以下では:
- 3.1 Pro Preview の context caching は
\$0.20/ 1M - 2.5 Pro の context caching は
\$0.125/ 1M - storage は両者とも
\$4.50 / 1,000,000 tokens per hour
200k超でも差は続きます。
- 3.1 Pro Preview の caching は
\$0.40 - 2.5 Pro の caching は
\$0.25
標準入力/出力だけを見ると見落としがちな点ですが、長いシステムプロンプトや再利用コンテキストが多い実運用では、この差が効きます。
Batch API も同様です。両者とも「半額化」は効くものの、200k以下では:
- 3.1 Pro Preview: 入力
\$1.00/ 出力\$6.00 - 2.5 Pro: 入力
\$0.625/ 出力\$5.00
つまりバッチ適用後も 3.1 の方が高いままです。非同期大量処理では「両方安くなる」だけで、差が消えるわけではありません。
グラウンディング課金は表記単位が異なるため、単純な横比較は危険です。現行表記では 3.1 Pro Preview は Search/Maps grounding が 月5,000プロンプト無料 の後に \$14 / 1,000 search queries、2.5 Pro は 1,500 RPD無料 の後に Search \$35 / 1,000 grounded prompts、Maps \$25 / 1,000 grounded prompts です。単位が揃わないので「どちらが絶対安い」と断定は避けるべきですが、実務的には「モデル選択 = ツール課金設計の選択」になる点が重要です。
この文脈では無料枠の価値が大きくなります。無料枠は単なる節約ではなく、検証ライン維持の手段です。
- ステージング検証
- 新テンプレート試験
- 低リスクの回帰確認
- ルーティング変更時のスモークテスト
2.5 Pro にはこの入口が残り、3.1 Pro Preview にはありません。だから実務チームは通常、「3.1が上位だから全面移行」ではなく、「2.5を低摩擦デフォルトに残し、3.1は高難度の価値が出る領域に限定」から始めます。
アプリ系ヘルプページがSERPで強いのも同じ構図です。多くの読者が必要としているのはベンチマークより アクセス面の整理 です。アプリでは「プランと利用可能モデル」、APIでは「経済性と運用設計」が中心課題になります。
この2つを切り分けると結論はシンプルです。
- アプリ中心の判断: 新モデルが見えれば試し、体感で評価。
- API中心の判断: 安定デフォルトとプレミアムレーンを分離し、価格・キャッシュ・グラウンディング・バッチまで含めて判断。
本記事は後者、つまり本番API判断を主軸にしています。ここが曖昧だと、検索上位の断片情報を読んでも意思決定が進みません。
ベンチマーク比較: 3.1が伸びる領域と比較が難しい領域
AI比較のベンチマーク節は、実際より確実そうに見えがちです。ここで特に注意したいのは、Gemini 3.1 Pro と Gemini 2.5 Pro の公式 model card が、同日同条件の完全な1枚表を提供していない点です。公式値は有用ですが、読み方は慎重であるべきです。
2つの model card から読み取れる方向性を整理すると、次の表になります。
| ベンチマーク | Gemini 3.1 Pro(公式) | Gemini 2.5 Pro(公式) | 安全な解釈 |
|---|---|---|---|
| Humanity's Last Exam | 44.4% | 21.6% | フロンティア推論で3.1が前進している強いシグナル |
| GPQA Diamond | 94.3% | 86.4% | 科学推論で3.1が有意に強い傾向 |
| SWE-Bench Verified | 80.6% | 59.6% | 3.1優勢の方向性は明確だが、同一日付同一条件の完全比較ではない |
| Terminal-Bench 2.0 | 68.5% | 2.5 GAカードに記載なし | 3.1がエージェント型コーディング重視であることを補強 |
| APEX-Agents | 33.5% | 2.5 GAカードに記載なし | 長い推論連鎖での性能強化を示唆 |
| Context / output | 1M / 64K | 1M / 64K | 上限値では3.1の明確な勝ちではない |
最も安全な要約は、3.1 Pro はGoogleの先端推論・エージェント性能を押し上げているが、全項目を完全な同条件比較として断定してはいけない です。直接比較しやすい指標もあれば、そうでない指標もあります。
それでも実務判断に必要なパターンは明確です。3.1 Pro は次のような仕事で価値が出やすい。
- マルチステップかつツール依存が強い
- 推論品質差が結果を左右する
- 補完よりエージェント実行に近い
- 初回失敗の人手修正コストが高い
2.5 Pro が依然として強いのは次の領域です。
- 高品質だが先端難問ではないタスク
- 大量反復処理
- コスト優先運用
- 広い本番トラフィックの安定処理
このため、ベンチマークは「全面置換の根拠」ではなく「トラフィック配分を賢くする根拠」として使うべきです。最難関5%の価値が高い組織では3.1のプレミアムは回収しやすく、定常的な補助コーディングや構造化業務中心なら2.5の経済性とGA成熟度が依然有利です。
さらに重要なのは、両者が既に 1M context / 64K output を共有している点です。今回買っているのは「枠の拡大」ではなく、特定タスクでの「知能差」です。だからこそ、ワークロード分類が移行成否を決めます。
レイテンシ・長文コンテキスト・本番信頼性
公式ドキュメントは能力差を示しますが、運用上の問いは残ります。新モデルは実トラフィックでどれだけ予測可能か、という点です。
ここでSERPが示すシグナルは興味深いです。公式ページと並んで、Google AI Developers Forum の "Gemini 3 significantly worse thant 2.5 Pro at long context. Temperature likely to blame" のようなユーザー摩擦スレッドも露出します。これは公式仕様ではなく、1投稿を確定事実扱いすべきではありません。ただし「新モデルかどうか」より「難しい長文で挙動が安定するか」で評価している利用者が多い、という現場シグナルとしては有用です。
両モデルとも model card 上は 1M context / 64K output なので、紙面上は同等に見えます。しかし上限値が同じでも体験は同じになりません。本番で見るべきは次の点です。
- 自分たちのプロンプト分布で予測しやすいのはどちらか
- 高コストな失敗初回出力を減らせるのはどちらか
- フォールバックやルーティングの複雑性を下げられるのはどちらか
- 価格プレミアムを、再試行削減や修正時間短縮で回収できるか
多くのチームで 2.5 Pro が安定寄りに見えるのは、GAかつ低単価だからです。Preview が即不安定という意味ではありませんが、自社トラフィックで計測する前に 3.1 を全量デフォルトにする理由にはなりません。
ここで分けるべきは 能力リスク と プロダクトリスク です。難問性能では3.1が有利な可能性が高い一方、広域配備では次の理由で2.5が有利になりやすい。
- GAである
- 無料枠がある
- 単価が低い
- 既に運用挙動を把握しているチームが多い
したがって大規模運用の安全策は、全面置換より 段階的ルーティング です。2.5を本線に置き、本当に難しい入力だけ3.1へ上げる。3.1が実測で失敗率とレビュー工数を下げるなら比率を広げる。効かないなら本線を壊さない。この順序が合理的です。
Google系ワークフローを深く使っている場合は、関連運用情報も合わせて確認しておくと判断しやすくなります。Gemini 3.1 Pro output limit guide(英語)、Gemini 3.1 Pro timeout guide(英語)、Gemini API error troubleshooting guide のような周辺課題は、実際には「使えるモデルかどうか」を左右することが多いためです。
コーディング・エージェント・研究・コストでの選び分け
この比較を実務に効かせる最短ルートは、「総合勝者」を探すのをやめて、ワークロード別に割り当てることです。
| ワークロード | 優先デフォルト | 理由 |
|---|---|---|
| 日常的な開発補助 | Gemini 2.5 Pro | 低単価かつGAで、一般的な補助コーディングに十分強い |
| 高難度エージェント型コーディング | Gemini 3.1 Pro | 公式の位置づけとベンチマーク傾向がエージェント性能優位を示す |
| 研究寄りの高度分析 | Gemini 3.1 Pro | 先端推論指標で上振れが見え、プレミアムを正当化しやすい |
| 長文ドキュメント大量処理 | まず2.5 Pro、必要時のみ3.1 | 上限は同じ1Mで、2.5の方が安く安定運用しやすい |
| 無料枠中心の検証 | Gemini 2.5 Pro | 3.1 Proに無料枠がない |
| 広域の本番トラフィック | Gemini 2.5 Pro | GAと低コストが運用摩擦を下げる |
| プレミアムなフォールバックレーン | Gemini 3.1 Pro | 必要なときだけ上位知能を使う用途に最適 |
個人開発者・小規模チーム なら、まず2.5を基準にして、難問だけ3.1へ回す構成が最も失敗しにくいです。プレミアムレーンが費用対効果を示すまで、設計を複雑化しないのが無難です。
中規模以上の開発組織 では、結論はアーキテクチャ問題になります。既にルーティング層を持っているなら、2.5を大量処理レーン、3.1を高知能レーンに分けるだけで導入効果が出ます。ここで避けるべき最悪手は「必要性を判定せず、全リクエストを高価なPreviewモデルへ送る」ことです。
研究・評価中心チーム では、3.1の優先度は上がります。3.1 model card は2.5 GA card より先端推論の強い物語を持っており、難しい統合推論・ツール連鎖・エージェント実行が主業務ならプレミアム回収可能性は高いです。ただし「強い = 安い」ではない点は変わりません。
コスト厳守の本番 では、2.5 Pro は依然として非常に強い選択肢です。GA・無料枠・低単価の三点が揃っているため、広域配備の経済合理性が高い。3.1の改善が事業KPIに効く実測がない限り、2.5を本線に置く判断は妥当です。
また、2世代のGeminiを1つのコードベースで運用する際は、単一プロバイダー固定よりもルーティング設計そのものが課題になります。その文脈では laozhang.ai のようなゲートウェイ層が有効な場合があります。理由は単純で、問題は「どちらのモデルを愛用するか」ではなく、「どのトラフィックをどの単価・どの品質で処理するか」に移るからです。
3.1 Pro を昇格させる前に計測すべきこと
この比較を読んだ直後に起きがちな失敗は、3.1 Pro で数件の印象的な成功例を見て、そのまま全体デフォルトを切り替えることです。これは評価設計として不十分です。今回の差分は価格と成熟度に直結するため、好奇心ベースではなく運用者ベースで検証する必要があります。
まずはワークロードを価値構造で分割してください。実務で使いやすい初期分類は次のとおりです。
| 評価バケット | 代表例 | 本当に答えるべき問い |
|---|---|---|
| 定常的コーディング編集 | リファクタ、小規模テスト、単純バグ修正 | 日常業務で3.1は追加コストを回収できるか |
| 高難度エージェント作業 | 複数ステップ改修、ツール連鎖修復、長い実行チェーン | 3.1は初回失敗を減らしレビュー工数を削れるか |
| 長文コンテキスト分析 | 大規模文書、長尺ログ、複数ファイル推論 | 入力が重くなっても3.1優位は維持されるか |
| グラウンディング/ツール活用 | 検索連携回答、外部ツール呼び出し | ツール連携改善は追加課金を正当化するか |
| コスト重視の大量処理 | 高ボリューム定型リクエスト | 2.5を本線から外す合理性は本当にあるか |
1バケットだけ試すと判断を誤ります。3.1が高難度で有効でも、大量定常バケットでは不利というケースは普通に起こります。だからこそルーティング推奨が必要です。
次に重要なのは、出力品質そのもの ではなく 受け入れ可能な成果物あたりコスト を測ることです。つまり「どちらが賢く見えるか」ではなく、「再試行・修正・レビュー込みでどちらが安く通るか」を比較します。
最低限追うべき指標は次です。
- first-pass acceptance rate
- human correction minutes
- retry rate
- p95 latency
- token cost
- caching cost(該当時)
- grounding cost(該当時)
- fallback rate
これがないと、3.1が「高いのに得」なのか「高いだけ」なのか判断できません。高単価モデルでも修正時間を大きく減らせば勝てますし、逆に改善が上位3%にしか効かないなら負けます。
ここで多くのチームが気づくのが、「ベンチマーク勝者」と「デフォルト勝者」は別物だという事実です。
比較条件を揃えるための最低ルールは以下です。
- 検証期間中はプロンプトテンプレートを固定する。
- ツールセットを両モデルで揃える。
- APIが許す範囲で温度・推論設定を合わせる。
- 公開ベンチ課題ではなく本番類似プロンプトで測る。
- 難易度の異なるタスクを平均前に分離する。
とくに5は重要です。全体平均だけだと、高難度での3.1改善が定常タスクに埋もれます。逆に「ヒーロー課題」だけを過剰サンプルして全面移行を正当化するのも同じ誤りです。
3つ目のルールは、正誤だけでなく 運用挙動 を測ることです。両者とも 1M/64K を持つため、差は以下のような挙動面に出やすい。
- 再試行が何回必要か
- 長いツール連鎖で破綻しないか
- 長文入力で一貫性を保てるか
- 後段処理しやすい出力構造か
- 週単位で挙動が安定するか
ここでPreviewステータスが効いてきます。Previewでも本番適用は可能ですが、広域デフォルトに昇格させるなら、変更リスク込みで基準を上げるべきです。
現実的な昇格試験は次の流れです。
- 直近2〜4週間の代表プロンプトを収集する。
- タスク種別と業務重要度でラベル付けする。
- 同一セットを 2.5 Pro と 3.1 Pro の両方で実行する。
- 可能な範囲でブラインド人手評価する。
- 品質と同時にレイテンシ・再試行を記録する。
- token単価ではなく「受け入れ成果物あたりコスト」で比較する。
- 発売直後の短期ノイズで判断せず、変動を観測できる期間で見る。
トラフィック量があるなら、オフライン比較で終わらせず、制御付き本番実験に進めるのが堅実です。
- 2.5 Pro をデフォルトに維持
- 最難関バケットのみ 3.1 Pro に送る
- そのバケットの業務KPIを比較
- 効果が継続する場合のみ配分を拡大
これはGoogle側の製品構図とも整合します。2.5は安定本線、3.1は価値を証明して配分を獲得する上位レーンです。
4つ目のルールは、モデル出力だけでなく 周辺課金挙動 を測ることです。長文プロンプト、キャッシュ、バッチ、グラウンディングを使う運用では、移行判断はインフラ経済設計の問題でもあります。
- キャッシュ単価が上がっても3.1は成立するか
- バッチ適用で収益性を維持できるか
- グラウンディング課金が許容範囲か
- 無料枠喪失で検証速度が落ちないか
この問いの答えで、誰に3.1が向くかは変わります。高価値な研究業務ならプレミアムを許容しやすく、中難度大量処理の消費者サービスではエスカレーション用途に限定されることが多いです。
最後に重要なのは、結果を見る前に昇格基準を固定することです。後から基準を動かすと、組織は都合のよい結論に寄ります。たとえば次のようなゲートが有効です。
- 高難度バケットで3.1が2.5を有意に上回ること
- レイテンシ増加がSLA許容内であること
- 受け入れ成果物あたりコストが許容プレミアム内であること
- Preview挙動が数日〜数週スパンで安定すること
- 大量バケットは2.5維持、または移行根拠が明確であること
このゲートを満たせば3.1を昇格、満たさなければ専門レーンに留める。どちらも成功です。評価の目的は全面移行の正当化ではなく、ルーティングを賢くすることにあります。
実装パターンとしては次が扱いやすいです。
- リクエストを low / medium / high 難易度に分類
- low と大半の medium は
gemini-2.5-pro - high と高レビューコスト案件は
gemini-3.1-pro-preview - hard バケットを週次監視し、月次で昇格条件を再評価
これで高価なPreviewを全量に流さずに、3.1の価値を取り込めます。
この節を一文で要約するなら次です。3.1 Pro は「新しいから採用」ではなく、「修正コストを減らせると証明できた範囲で昇格」させるモデルです。
移行戦略: 全置換・分離ルーティング・据え置き
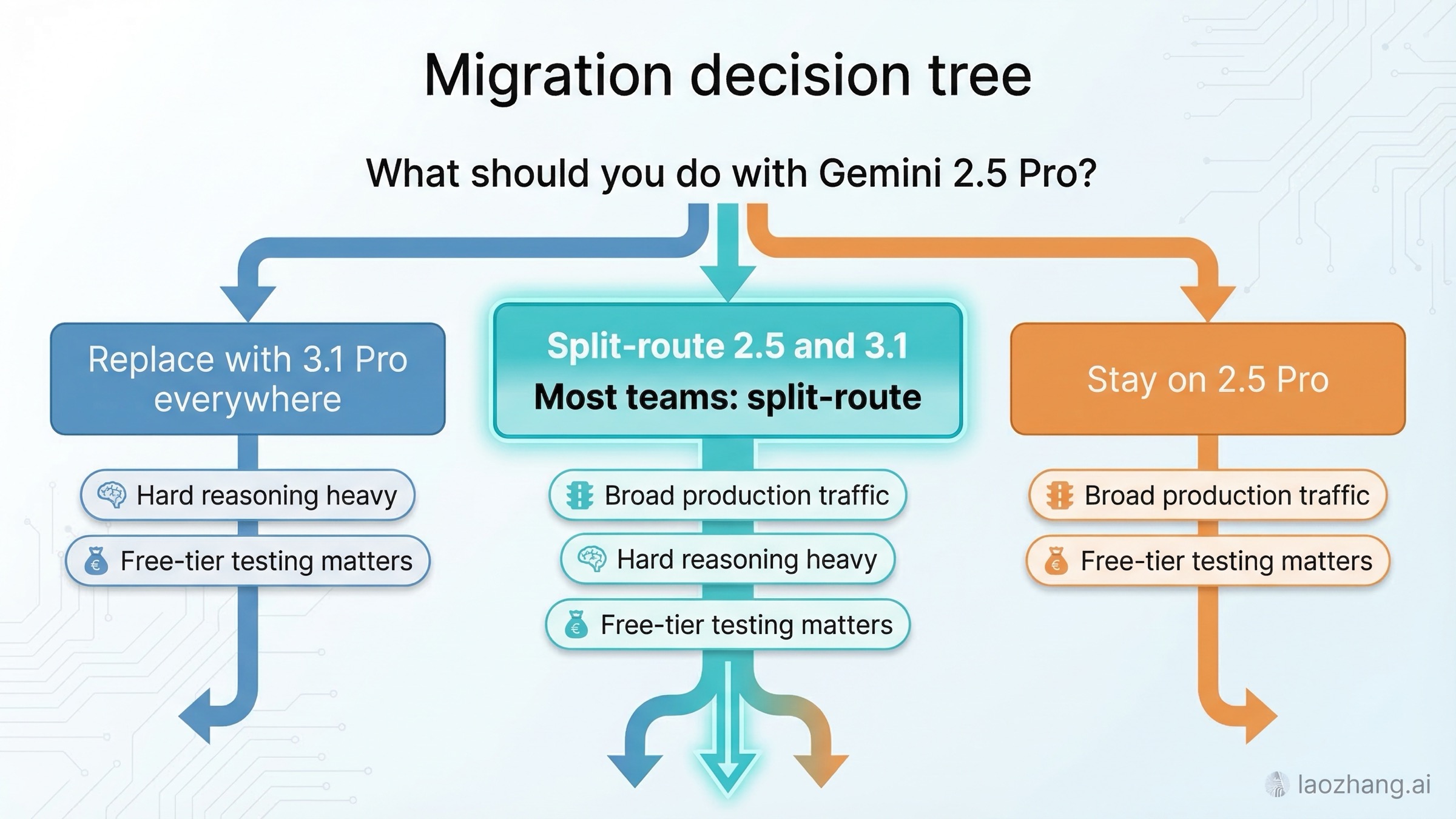
多くのチームは、次の3パターンのどれかを選ぶことになります。
パターン1: Gemini 3.1 Pro に全面置換。 これは、ワークロードが高難度推論・エージェント型コーディングに強く偏っており、Previewをデフォルト運用してもよい組織に限って成立します。最も攻めた選択であり、品質・遅延・コストを実測していないと失敗しやすい経路です。
パターン2: 2.5 Pro と 3.1 Pro を分離ルーティング。 これが最も汎用的な推奨です。2.5をデフォルトに置き、次条件で3.1にエスカレーションします。
- 高重要度で人手レビュー単価が高い
- 2.5で初回失敗率がボトルネックになっている
- 単発回答よりマルチステップ実行が中心
- コスト低減より推論強化の価値が高い
シンプルなポリシーでも十分運用できます。
tsfunction chooseGeminiModel(task: { requiresAgenticCoding: boolean; reasoningDifficulty: "low" | "medium" | "high"; costSensitive: boolean; needsFreeTierFallback: boolean; }) { if (task.needsFreeTierFallback || task.costSensitive) { return "gemini-2.5-pro"; } if (task.requiresAgenticCoding || task.reasoningDifficulty === "high") { return "gemini-3.1-pro-preview"; } return "gemini-2.5-pro"; }
パターン3: 2.5 Pro を当面維持。 これは保守的だからではなく、品質が既に要件を満たし、無料枠検証に依存し、3.1の追加能力が事業成果を明確に押し上げない場合に合理的な判断です。モデルアップグレードは、ワークフロー価値を上げて初めて「アップグレード」と言えます。
実務で使いやすい移行チェックリストは次です。
- 公開課題ではなく自社プロンプトで比較する。
- 出力品質と修正工数をセットで追う。
- 3.1が実トラフィックで証明されるまで2.5フォールバックを残す。
- model card が強いからといって即全面移行しない。
- 価格プレミアムとPreviewリスクを上回る実測改善が出た範囲だけ昇格する。
要するに、Gemini 3.1 Pro は「デフォルトで採用するモデル」ではなく「証拠で昇格させるモデル」です。
FAQ
Gemini 3.1 Pro は Gemini 2.5 Pro より優れていますか?
高難度推論やエージェント作業では、Googleの現行ポジショニングと公式 model card の傾向から 3.1 Pro が有利です。ただし「あらゆる実務で常に上位」という意味ではありません。2.5 Pro は低コスト・GA・無料枠があり、多くのチームでは依然として優れたデフォルトです。
Gemini 3.1 Pro にするとコンテキストや出力上限は増えますか?
増えません。2026年3月19日時点の公式情報では、両モデルとも 1M context と 64K output です。差分は上限値ではなく、性能・単価・提供ステータスです。
Gemini 3.1 Pro の方が高いですか?
はい。公式 pricing では、3.1 Pro は 200kまでで入力 \$2.00、出力 \$12.00(いずれも1Mあたり)。2.5 Pro は同条件で入力 \$1.25、出力 \$10.00 で、無料枠もあります。
2.5 Pro の全トラフィックを 3.1 Pro に移すべきですか?
通常は不要です。2.5を広域デフォルトに残し、難問だけ3.1へ回す方が現実的です。全面移行は、追加推論性能が価格プレミアムとPreviewリスクを上回ると実測で確認できた場合に限るべきです。
ベンチマーク数字は完全に apples-to-apples ですか?
完全ではありません。どちらも公式値ですが、単一の同日同条件ドキュメントに統合されているわけではありません。方向性として使い、価格・ステータス・ワークロード適合と合わせて判断するのが安全です。
この比較は Gemini アプリ利用者にも API利用者にも同じ重要度ですか?
同じではありません。アプリ利用者はプラン解放やモデル選択UIが中心課題で、API利用者は無料枠・単価・バッチ・ルーティング設計が中心です。本記事がAPI判断を主軸にしているのはこのためです。
結論
高難度推論とエージェント作業の上限性能を優先するなら Gemini 3.1 Pro。安定性とコスト効率を重視した広域運用なら Gemini 2.5 Pro。ルーティング可能なら、両方を併用してワークロードごとに使い分けるのが最も実務的です。