
Короткий ответ: если Gemini Image возвращает 429, чаще всего проблема не в одном лишнем запросе, а в том, что у проекта нет платного доступа к генерации изображений или уже исчерпано проектное окно квоты. По состоянию на 15 марта 2026 года актуальные preview-модели Gemini для генерации изображений остаются платными, суточные квоты сбрасываются в полночь по тихоокеанскому времени, а официальная страница лимитов по-прежнему привязывает переход между Free, Tier 1, Tier 2 и Tier 3 к истории биллинга проекта.
Это важно, потому что решение не всегда сводится к «подождите и попробуйте снова». Если у проекта фактически нулевая квота на изображения, экспоненциальная задержка просто отложит тот же отказ. Если биллинг уже включён, нужно понять, упёрлись ли вы в RPM, RPD, TPM или IPM, не продолжается ли применение изменений на нужном проекте и не скрывается ли за всей этой диагностикой другая ошибка вроде 503 из-за перегрузки или регионального ограничения с 400. Цель этого материала — довести читателя до самого дешёвого рабочего решения как можно быстрее, а затем показать, как масштабироваться без постоянной борьбы с лимитами.
Краткое содержание
Gemini может возвращать 429 RESOURCE_EXHAUSTED даже тогда, когда реальная проблема не во временном всплеске запросов, а в том, что проект всё ещё не получил платный доступ к генерации изображений. Актуальная документация Google прямо указывает, что квоты считаются на уровне проекта, а не API-ключа, RPD сбрасывается в полночь по тихоокеанскому времени, Batch API даёт скидку 50% и использует отдельный пул квот, а переход в Tier 2 и Tier 3 по-прежнему требует накопленных расходов и 30-дневного окна. Самая быстрая последовательность действий — проверить биллинг именно на том проекте, откуда идёт запрос, а затем уже решать, нужны ли вам повторные попытки, ожидание сброса, Batch API или другой маршрут доступа.
| Симптом | Вероятная причина | Самое быстрое решение | Когда отпустит |
|---|---|---|---|
Запросы на изображения сразу падают, квота выглядит как 0 или image-лимит недоступен | Проект ещё не получил платный доступ к нужной image-модели | Подключить биллинг к правильному проекту и заново открыть live rate-limit dashboard | Обычно минуты, иногда часы при задержке верификации |
| Ошибка 429 появляется только при всплесках нагрузки | Вы исчерпали RPM, TPM или IPM окно | Добавить exponential backoff с jitter и снизить параллелизм | От секунд до нескольких минут |
| Ошибка 429 начинается после долгой работы в течение дня | Исчерпан суточный лимит RPD | Дождаться полуночи по Pacific Time или увести несрочную работу в Batch API | До следующего сброса |
| 429 остаётся даже после включения биллинга | Неправильный проект, задержка распространения или слишком низкий tier | Проверить project ID, billing account, tier и страницу квот для конкретной модели | Минуты при propagation, дольше при реальном потолке tier |
| На деле это 503 или региональная 400 ошибка | Это не quota case | Коротко ретраить 503, а для 400 проверить регион и биллинг | Зависит от класса ошибки |
Troubleshooting: быстрый выбор правильного решения
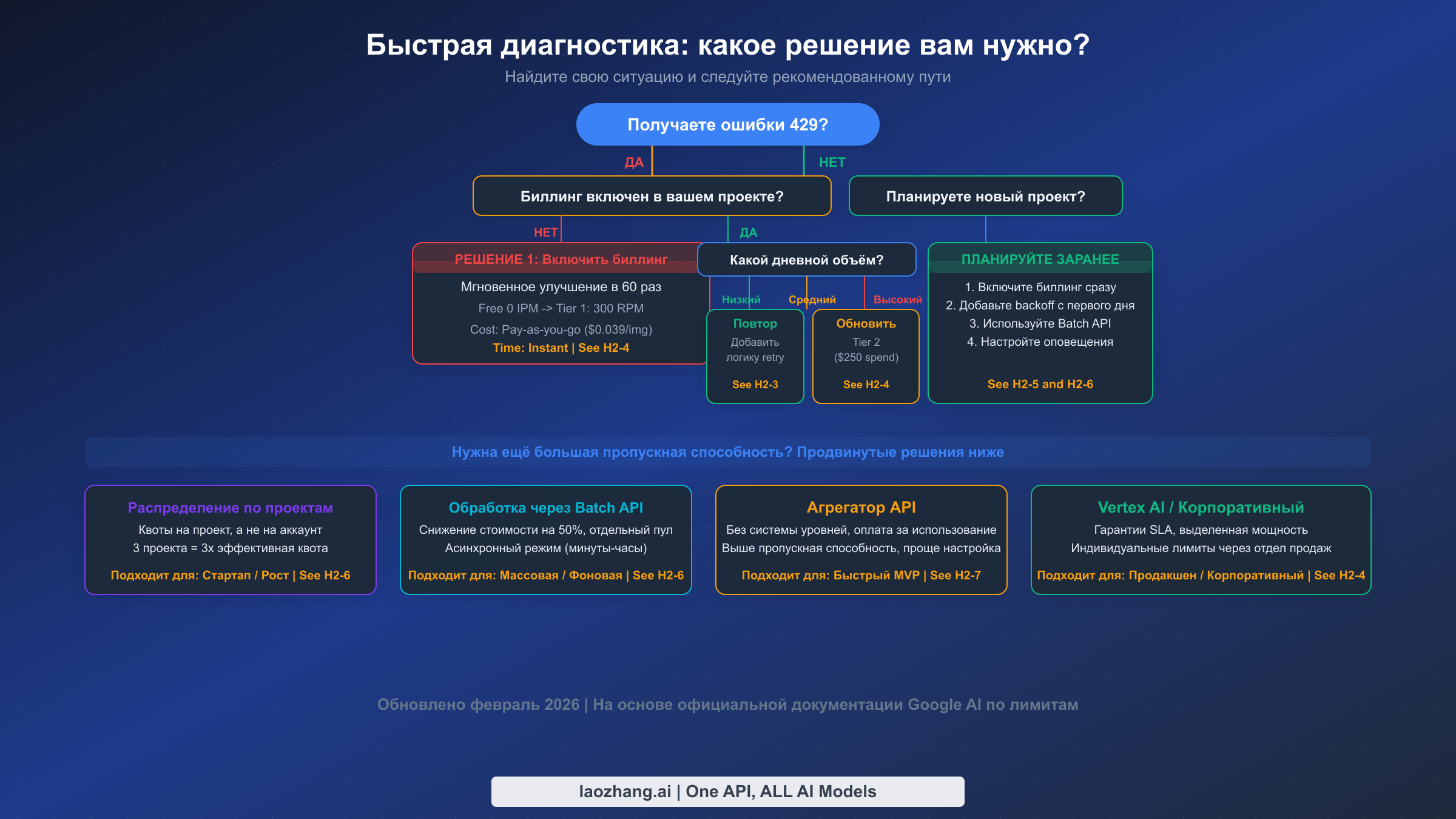
Прежде чем лезть в код и настройки, определите, к какому классу относится ваш сбой. Это звучит банально, но именно этот шаг чаще всего пропускают. Разработчик видит один и тот же 429 RESOURCE_EXHAUSTED и предполагает, что у всех случаев одна и та же причина. На практике самое быстрое решение зависит от того, не было ли у проекта платного доступа с самого начала, закончилась ли минутная квота или просто опустел суточный бак.
Если 429 нужно снять прямо сейчас, начните с одного вопроса: привязан ли биллинг к тому же проекту Google Cloud, чей API-ключ вы используете? Официальная billing-документация говорит, что billable usage включается сразу после настройки, но реальные треды показывают, что люди часто включают биллинг в одном проекте, а тестируют другой. Если страница usage всё ещё показывает нулевую или недоступную image-квоту, retry здесь не поможет. Сначала чините связку project + billing.
Если биллинг уже включён, а 429 не исчезает, смотрите, какой бак опустел. Короткие всплески почти всегда указывают на RPM, TPM или IPM. Длинный процесс, который валится ближе к концу дня, обычно упирается в RPD. Даже маленькая нагрузка может падать из-за того, что биллинг ещё не распространился на нужный проект, что проект привязан не к той billing account или что выбранная preview-модель живёт на более жёстком лимите, чем text-only-модели, с которыми команда работала раньше. Поэтому project ID, usage dashboard и quota_limit в ошибке важнее, чем общий совет «просто подождите».
Если вы только планируете проект, стройте архитектуру с учётом квот с первого дня. Подключайте биллинг сразу, логируйте project ID и quota_limit на каждом 429, уводите несрочную генерацию в Batch API и держите под рукой официальную страницу rate limits, чтобы операторы смотрели живые лимиты модели, а не старые скриншоты из блогов.
Понимание лимитов генерации изображений Gemini в 2026 году

API Gemini от Google измеряет использование по четырём различным параметрам, и понимание их взаимодействия критически важно для диагностики и устранения узких мест при генерации изображений. Большинство разработчиков концентрируются исключительно на RPM (запросы в минуту), однако для задач генерации изображений картина значительно сложнее. Каждый параметр действует независимо, что означает: вы можете столкнуться с лимитом по любому из них, даже если по остальным далеки от предела. API возвращает ошибку 429 RESOURCE_EXHAUSTED при превышении любого одного параметра, причём сообщение об ошибке не всегда чётко указывает, какой именно лимит был достигнут.
RPM (Requests Per Minute — запросы в минуту) определяет количество API-вызовов, допустимых в 60-секундном окне. После изменений в декабре 2025 года бесплатный уровень допускает лишь 5 RPM для Gemini 2.5 Pro (ранее 10) и 10 RPM для моделей Flash (ранее 15). Tier 1 обеспечивает скачок до 300 RPM — 60-кратное улучшение, которое само по себе решает большинство проблем с лимитами для небольших нагрузок. Для полного разбора всех лимитов Gemini API, включая вариации по моделям, обратитесь к нашему подробному руководству.
RPD (Requests Per Day — запросы в день) устанавливает потолок общего числа API-вызовов за сутки. Этот лимит особенно сильно пострадал в декабре 2025 года: RPD бесплатного уровня для модели Flash упал с 250 до всего 20 — сокращение на 92%. Tier 1 предоставляет 10 000 RPD, а Tier 2 и выше — неограниченное количество ежедневных запросов. Понимание времени сброса лимитов Gemini на изображения (полночь по тихоокеанскому времени для пользователей API) помогает планировать самые ресурсоёмкие нагрузки.
TPM (Tokens Per Minute — токены в минуту) измеряет пропускную способность по токенам, а не по количеству запросов. Для генерации изображений это важно, поскольку каждое выходное изображение потребляет фиксированное количество токенов вне зависимости от сложности содержимого: 1290 токенов для изображений до 1024×1024 пикселей и 1120 токенов на более высоком уровне для изображений 2048×2048. Бесплатный уровень допускает 250 000 TPM, Tier 1 открывает 1 миллион, а Tier 2 достигает 4 миллионов.
IPM (Images Per Minute — изображения в минуту) — это параметр, который большинство разработчиков упускают из виду, и при этом именно он наиболее важен для задач генерации изображений. Этот лимит применяется к моделям, способным генерировать изображения, таким как Gemini 2.5 Flash Image и Gemini 3 Pro Image Preview. Ключевая деталь, которая удивляет многих разработчиков: бесплатный уровень имеет 0 IPM. Генерация изображений полностью недоступна без включения биллинга. Именно этот факт является основной причиной большинства вопросов «почему я не могу генерировать изображения?» на форумах разработчиков.
Сокращение квот в декабре 2025 года стало самым значительным изменением лимитов с момента запуска Gemini API. Google объяснил это «беспрецедентным спросом», но практическое воздействие оказалось серьёзным: разработчики, чьи приложения опирались на квоты бесплатного уровня, внезапно столкнулись с ошибками 429 без предупреждения. Сокращения затронули как RPM, так и RPD для всех моделей, хотя семейство Gemini 1.5 заметно не пострадало — деталь, которая приобретает стратегическое значение при необходимости запасного варианта.
| Параметр | Бесплатный | Tier 1 | Tier 2 | Tier 3 |
|---|---|---|---|---|
| RPM | 5-10 | 300 | 1,000 | 2,000-4,000+ |
| RPD | 20-500 | 10,000 | Без лимита | Без лимита |
| TPM | 250K | 1M | 4M | 10M+ |
| Генерация изображений | Заблокировано (0 IPM) | Доступно | Доступно | Доступно |
| Пакетные токены | Н/Д | 2M | 270M | 1B |
Один распространённый миф заслуживает явного опровержения: квоты применяются на уровне проекта, а не на уровне API-ключа. Создание нескольких API-ключей в одном проекте Google Cloud не умножит ваши лимиты — все ключи используют один и тот же пул квот. Это принципиально важное различие, которое лежит в основе стратегии распределения по нескольким проектам, описанной в разделе продвинутых решений ниже. Ещё одно типичное заблуждение связано с тем, как все четыре параметра взаимодействуют в рамках одного запроса. Когда вы отправляете запрос на генерацию изображения, API проверяет все четыре параметра одновременно. Запрос может пройти по RPM, RPD и TPM, но всё равно быть отклонён, если достигнут лимит IPM. Ответ с ошибкой 429 содержит заголовок Retry-After, указывающий время ожидания, но не всегда сообщает, какой именно параметр вызвал ограничение. Именно поэтому критически важно отслеживать все четыре метрики в вашей системе мониторинга. Понимание этой модели взаимодействия также объясняет, почему некоторые разработчики наблюдают периодические сбои, хотя частота их запросов вроде бы далека от RPM-лимита уровня: узким местом может оказаться совершенно другой параметр.
Исправление ошибок 429 за 5 минут: реализация экспоненциальной задержки
Когда вы сталкиваетесь с ошибками 429 и вам нужно как можно быстрее вернуть генерацию изображений в рабочее состояние, экспоненциальная задержка — наиболее эффективное решение для немедленного применения. Эта техника автоматически повторяет неудачные запросы с прогрессивно увеличивающимися интервалами, позволяя временным окнам ограничений сброситься. Согласно собственной документации Google по устранению неполадок, внедрение экспоненциальной задержки способно превратить 80% неудачных запросов в почти 100% итоговый успех — и добавить этот код в существующий проект можно менее чем за пять минут.
Концепция проста: когда запрос возвращает код состояния 429, нужно подождать базовый интервал перед повторной попыткой. Если повторная попытка тоже не удаётся, интервал удваивается. Удвоение продолжается, пока запрос не будет успешным или не будет исчерпано максимальное число попыток. Добавление случайного джиттера (небольшого разброса в задержке) предотвращает проблему «громового стада» — ситуацию, когда множество клиентов повторяют попытки в абсолютно одинаковые интервалы, что парадоксальным образом может усугубить проблему с лимитами. Более подробный разбор этой ошибки и её разновидностей представлен в нашем руководстве по исправлению ошибок 429 при превышении квоты.
Вот готовая к продакшну реализация на Python, специально адаптированная для генерации изображений:
pythonimport time import random from google import generativeai as genai def generate_image_with_retry(prompt, model_name="gemini-2.0-flash-exp", max_retries=5, base_delay=1.0): """Generate an image with exponential backoff retry logic. Args: prompt: The image generation prompt model_name: Gemini model to use max_retries: Maximum retry attempts (default 5) base_delay: Initial delay in seconds (default 1.0) Returns: Generated content response or raises after max retries """ model = genai.GenerativeModel(model_name) for attempt in range(max_retries): try: response = model.generate_content(prompt) return response except Exception as e: error_str = str(e) if "429" in error_str or "RESOURCE_EXHAUSTED" in error_str: if attempt == max_retries - 1: raise RuntimeError( f"Rate limit exceeded after {max_retries} retries. " f"Consider upgrading your tier or reducing request frequency." ) from e # Calculate delay with exponential backoff + jitter delay = base_delay * (2 ** attempt) jitter = delay * 0.25 * (random.random() - 0.5) wait_time = delay + jitter print(f"Rate limited (attempt {attempt + 1}/{max_retries}). " f"Waiting {wait_time:.1f}s before retry...") time.sleep(wait_time) else: # Non-rate-limit errors should propagate immediately raise
Эта реализация включает несколько важных деталей, которые часто упускаются в базовых примерах повторных попыток. Диапазон джиттера в 25% предотвращает синхронизированные повторы от нескольких клиентов. Функция различает ошибки ограничения частоты (которые следует повторять) и другие ошибки (которые должны немедленно передаваться дальше, чтобы не маскировать баги). Сообщение об ошибке после исчерпания попыток содержит практические рекомендации по повышению уровня.
Для сред JavaScript/TypeScript вот эквивалентная реализация с использованием async/await:
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); async function generateImageWithRetry(prompt, { modelName = "gemini-2.0-flash-exp", maxRetries = 5, baseDelay = 1000 } = {}) { const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY); const model = genAI.getGenerativeModel({ model: modelName }); for (let attempt = 0; attempt < maxRetries; attempt++) { try { const result = await model.generateContent(prompt); return result.response; } catch (error) { const isRateLimit = error.message?.includes("429") || error.message?.includes("RESOURCE_EXHAUSTED"); if (isRateLimit && attempt < maxRetries - 1) { const delay = baseDelay * Math.pow(2, attempt); const jitter = delay * 0.25 * (Math.random() - 0.5); const waitTime = delay + jitter; console.log(`Rate limited (attempt ${attempt + 1}/${maxRetries}). ` + `Waiting ${(waitTime / 1000).toFixed(1)}s...`); await new Promise(resolve => setTimeout(resolve, waitTime)); } else { throw error; } } } }
Обе реализации должны быть частью вашего стандартного API-клиента, а не разбросаны по всему коду приложения — это обеспечивает единообразное поведение повторных попыток для всех вызовов генерации изображений. Логика повторных попыток действует как страховочная сетка: она элегантно обрабатывает временные ответы 429, которые естественным образом возникают при приближении запросов к границам лимитов, без необходимости вручную отслеживать тайминги или интервалы между вызовами.
Когда одной задержки недостаточно: экспоненциальная задержка отлично работает для временных окон ограничений и пиковых нагрузок, но она не может преодолеть фундаментальные лимиты квот. Если вы стабильно генерируете больше изображений, чем позволяет ваш уровень в минуту или в день, задержка лишь добавит латентность, не решив проблему ёмкости. В таком случае решением является повышение уровня, использование пакетного API или распределение нагрузки между несколькими проектами.
Как повысить уровень Gemini API (пошаговое руководство)
Повышение уровня — самое простое долгосрочное решение проблем с лимитами, и процесс проще, чем ожидает большинство разработчиков, хотя есть несколько подводных камней, которые могут вызвать ненужные задержки. Система уровней кумулятивна: вы автоматически переходите с бесплатного на Tier 1, затем на Tier 2 и Tier 3 по мере выполнения требований каждого уровня по расходам и времени. Для стандартного пути повышения ручная заявка не требуется.
С бесплатного на Tier 1 (мгновенно, самое важное): это единственное обновление оказывает наибольшее влияние из всех решений проблемы лимитов. Простое включение биллинга в проекте Google Cloud запускает мгновенное повышение до Tier 1, которое разблокирует генерацию изображений (с 0 IPM до активного состояния), увеличивает RPM с 5 до 300 и расширяет RPD с 500 до 10 000. Важно: включение биллинга не означает, что с вас немедленно снимут деньги — вы платите только за фактическое использование API сверх квот бесплатного уровня. Пошаговый процесс описан в нашем руководстве по обновлению уровня.
Самый быстрый путь проходит через AI Studio: перейдите на aistudio.google.com, войдите в свой аккаунт Google, откройте Dashboard, затем Usage and Billing, нажмите вкладку Billing и выберите «Set up Billing». Вам потребуется привязать способ оплаты (банковскую карту или счёт), однако Google не снимет деньги, пока вы не превысите лимиты бесплатного уровня. Обновление обычно вступает в силу в течение нескольких минут.
Распространённая проблема №1: некоторые разработчики отмечают, что верификация биллинга занимает больше времени, чем ожидалось, особенно для новых аккаунтов Google Cloud. Если обновление не активируется в течение часа, проверьте электронную почту на наличие запроса верификации от Google Cloud. Международные способы оплаты иногда запускают дополнительные этапы проверки, которые могут задержать процесс на 24–48 часов.
С Tier 1 на Tier 2 ($250 расходов + 30 дней): для этого обновления необходимы два условия — не менее $250 совокупных расходов в Google Cloud (не только на Gemini API — учитываются любые сервисы Google Cloud, включая Compute Engine, Cloud Storage и BigQuery) и не менее 30 дней с момента первого платного биллингового события. Обновление обрабатывается автоматически в течение 24–48 часов после выполнения обоих условий. Важное уточнение: бесплатные пробные кредиты Google Cloud ($300 для новых аккаунтов) не засчитываются в порог $250.
С Tier 2 на Tier 3 ($1000 расходов + 30 дней): корпоративный уровень требует $1000 совокупных расходов плюс 30 дней. В качестве альтернативы организации могут заключить корпоративное соглашение с отделом продаж Google Cloud для получения индивидуальных лимитов и гарантий SLA. Этот путь обычно занимает от 2 до 4 недель от первого обращения до активации.
Распространённая проблема №2: повышение уровня привязано к проекту, а не к аккаунту. Если у вас несколько проектов Google Cloud, каждый проект имеет собственный уровень и должен самостоятельно выполнить требования по расходам. Это на самом деле полезно для стратегии распределения по нескольким проектам, описанной в разделе продвинутых решений, но может сбить с толку, если вы ожидаете, что расходы в одном проекте разблокируют уровни в другом.
Запрос увеличения квоты сверх вашего уровня: для Tier 2 и выше Google предлагает форму запроса на увеличение квоты через Cloud Console (IAM & Admin, затем Quotas). Найдите «generate_content_requests_per_minute», нажмите меню из трёх точек и выберите «Edit quota». Включите чёткое обоснование варианта использования и ожидаемые объёмы. Сроки ответа варьируются: стандартные запросы рассматриваются в течение 1–3 рабочих дней, хотя Google прямо указывает, что «не гарантирует увеличение вашего лимита». Корпоративные клиенты с выделенными менеджерами обычно получают ответы быстрее.
Реальная стоимость генерации изображений в Gemini
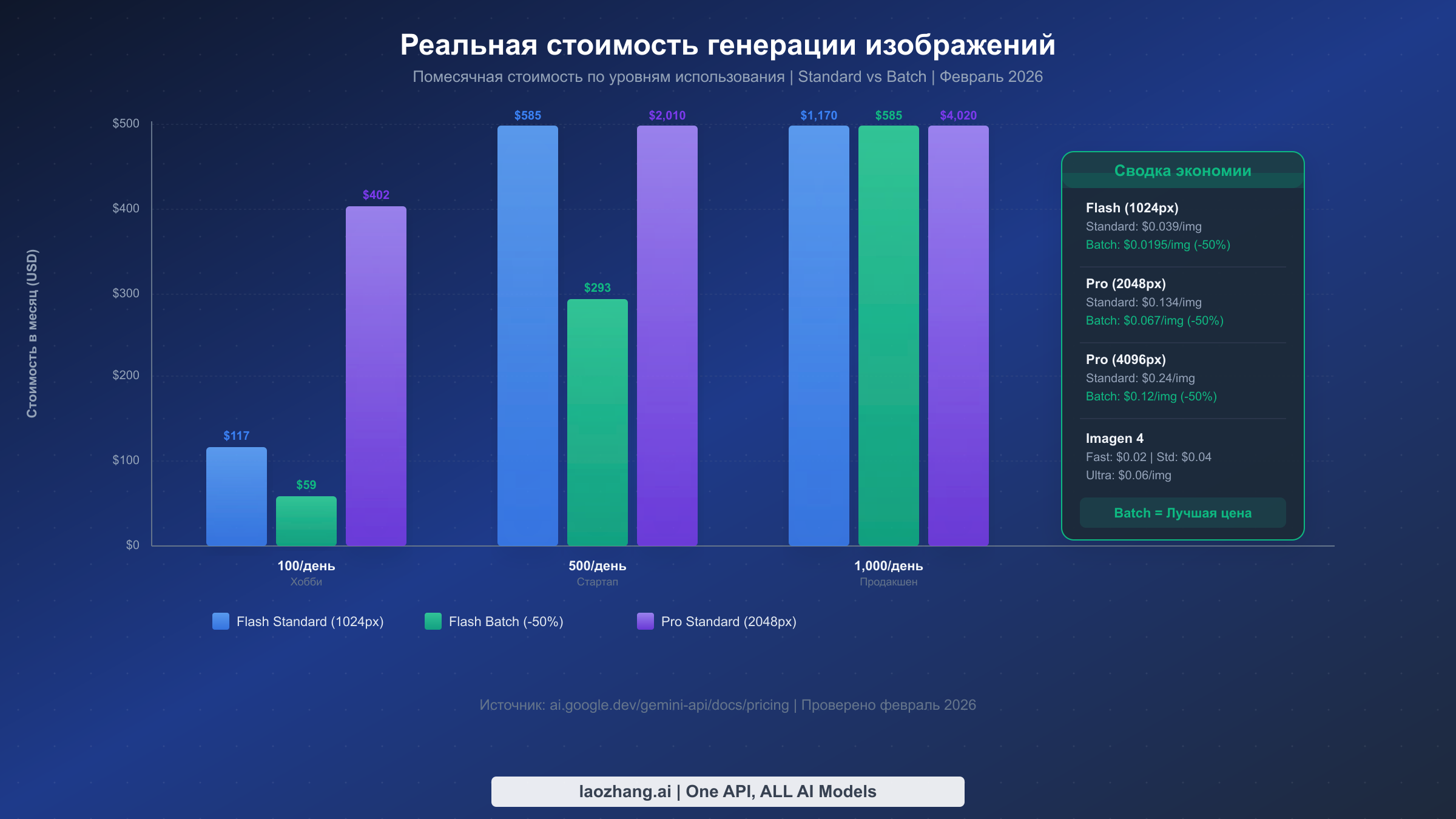
Понимание реальной стоимости генерации изображений в Gemini критически важно для бюджетирования и принятия решения о том, какой уровень экономически целесообразен для вашей нагрузки. Структура ценообразования включает множество переменных — выбор модели, разрешение, стандартная обработка или пакетная — и различия могут быть существенными. Все данные о ценах ниже проверены на официальной странице ценообразования Google AI (ai.google.dev/gemini-api/docs/pricing, февраль 2026).
Базовая стоимость зависит прежде всего от выбранной модели и разрешения. Gemini 2.5 Flash Image — наиболее доступный вариант по цене $0,039 за изображение при стандартном разрешении (до 1024×1024 пикселей). Каждое сгенерированное изображение потребляет ровно 1290 выходных токенов независимо от сложности содержимого, что позволяет точно рассчитать затраты без беспокойства о переменном потреблении токенов. Для более высокого качества Gemini 3 Pro Image Preview стоит $0,134 за изображение при стандартном/2K-разрешении (1024–2048 пикселей) и $0,24 за изображение при 4K-разрешении (до 4096 пикселей). Imagen 4 предлагает отдельную тарифную линейку: $0,02 за быструю генерацию, $0,04 за стандартную и $0,06 за ультракачество.
Batch API представляет наиболее значительную возможность оптимизации затрат: фиксированная 50%-ная скидка на все цены за токены в обмен на асинхронную обработку. Вместо мгновенного получения результатов пакетные запросы обрабатываются в течение 24-часового окна. Для нагрузок, не требующих генерации изображений в реальном времени — массовое создание контента, генерация миниатюр, подготовка фоновых ассетов — эта скидка кардинально меняет экономику. Если вы изучаете самые дешёвые способы доступа к генерации изображений Gemini, пакетная обработка должна быть на первом месте в вашем списке.
Вот как выглядят реальные ежемесячные затраты при различных уровнях использования:
| Уровень использования | Изображений/месяц | Flash стандарт | Flash пакет | Pro стандарт (2K) | Pro пакет (2K) |
|---|---|---|---|---|---|
| Хобби | 3 000 (100/день) | $117 | $58,50 | $402 | $201 |
| Стартап | 15 000 (500/день) | $585 | $292,50 | $2 010 | $1 005 |
| Продакшн | 30 000 (1 000/день) | $1 170 | $585 | $4 020 | $2 010 |
| Корпоративный | 300 000 (10 000/день) | $11 700 | $5 850 | $40 200 | $20 100 |
Несколько стратегий экономии складываются друг с другом. Использование Flash вместо Pro экономит 70–85% за изображение, если разрешения 1024 пикселей достаточно. Добавление пакетной обработки вдвое снижает оставшуюся стоимость. Сочетание обоих подходов — Flash с пакетной обработкой — доводит стоимость изображения до $0,0195, что означает, что даже 1000 изображений в день обходятся примерно в $585 в месяц. Для проектов с ограниченным бюджетом настройка оповещений о расходах (в Cloud Console через Billing, затем Budgets & Alerts) обеспечивает раннее предупреждение до превышения порога.
Затраты на квалификацию уровня также учитываются в общей картине. Для достижения Tier 2 требуется $250 совокупных расходов в Google Cloud, которые могут быть распределены между любыми сервисами Google Cloud. Если вы уже используете Compute Engine, Cloud Storage или BigQuery для своего проекта, эти расходы засчитываются. Для Gemini API конкретно $250 расходов позволят сгенерировать примерно 6400 изображений Pro или 17 800 изображений Flash — разумный объём для большинства стартапов, приближающихся к потребности в более высоких лимитах. Для высоконагруженных продакшн-систем сервисы вроде laozhang.ai предоставляют доступ к генерации изображений Gemini через единый API-эндпоинт с иными ценовыми структурами, которые могут быть более выгодными при масштабировании, особенно когда административная нагрузка по управлению уровнями становится обременительной.
Продвинутые стратегии максимизации пропускной способности
После внедрения базовой логики повторных попыток и повышения до соответствующего уровня несколько продвинутых стратегий способны многократно увеличить эффективную пропускную способность за пределами того, что обеспечивает один проект на любом данном уровне. Эти техники особенно ценны для продакшн-приложений, которым нужна стабильная высокообъёмная генерация изображений без штрафов по задержке от агрессивной экспоненциальной задержки.
Распределение по нескольким проектам — самый мощный множитель пропускной способности, поскольку квоты применяются на уровне проекта. Создание трёх проектов Google Cloud и распределение запросов между ними фактически утраивает ваши лимиты. Реализация проста: поддерживайте пул API-ключей (по одному на проект) и используйте циклическое или взвешенное распределение для балансировки запросов. Каждый проект независимо отслеживает собственное потребление квоты, поэтому событие ограничения в одном проекте не влияет на другие.
pythonimport itertools from google import generativeai as genai class MultiProjectImageGenerator: def __init__(self, api_keys: list[str], model_name: str = "gemini-2.0-flash-exp"): self.clients = [] for key in api_keys: genai.configure(api_key=key) self.clients.append(genai.GenerativeModel(model_name)) self.key_cycle = itertools.cycle(range(len(self.clients))) def generate(self, prompt: str): """Generate image using next available project in rotation.""" project_idx = next(self.key_cycle) client = self.clients[project_idx] try: return client.generate_content(prompt) except Exception as e: if "429" in str(e): # Try next project on rate limit next_idx = next(self.key_cycle) return self.clients[next_idx].generate_content(prompt) raise generator = MultiProjectImageGenerator([ "AIzaSy-project1-key", "AIzaSy-project2-key", "AIzaSy-project3-key", ])
Ключевое соображение при распределении по нескольким проектам состоит в том, что каждому проекту необходимы собственный биллинговый аккаунт и отдельная прогрессия по уровням. Порог $250 для Tier 2 применяется к каждому проекту отдельно, поэтому три проекта на уровне Tier 2 означают $750 совокупных расходов в Google Cloud. Для многих продакшн-нагрузок эти инвестиции быстро окупаются за счёт сокращения простоев и ошибок из-за лимитов.
Batch API для фоновой обработки отделяет срочную генерацию изображений в реальном времени от массовой обработки, которая может допускать задержки. Batch API обрабатывает запросы асинхронно в течение 24-часового окна и предоставляет 50%-ную скидку на все цены за токены. Tier 1 допускает 2 миллиона пакетных токенов, а Tier 2 — масштабные 270 миллионов, что достаточно для примерно 209 000 изображений при стандартном разрешении. Перенаправляя несрочные нагрузки через Batch API, вы высвобождаете квоту реального времени для критичных по времени запросов.
Очередь запросов с ограничением частоты добавляет локальную защиту, которая предотвращает превышение лимитов со стороны вашего приложения. Вместо того чтобы полагаться исключительно на ошибки 429 и повторные попытки (которые увеличивают задержку), превентивный ограничитель частоты обеспечивает правильный интервал между запросами. Алгоритм Token Bucket хорошо подходит для этого: поддерживайте «ведро», которое пополняется с частотой RPM вашего уровня, и отправляйте запросы только при наличии доступных токенов. Запросы, поступающие при пустом ведре, ставятся в очередь, а не отправляются в API, полностью устраняя ошибки 429 при сохранении максимальной пропускной способности.
Кэширование сгенерированных изображений часто упускается из виду, но может радикально сократить количество API-вызовов для приложений, которые часто генерируют похожие изображения. Если ваши пользователи регулярно запрашивают вариации на распространённые темы или ваше приложение генерирует изображения для конечного набора типов контента, реализация кэш-слоя (Redis, локальная файловая система или CDN) позволяет отдавать ранее сгенерированные изображения без потребления квоты. Даже простой кэш на основе хеширования с 24-часовым TTL может сократить API-вызовы на 30–50% во многих приложениях.
Планирование времени запросов с учётом графика сброса квот обеспечивает простую, но эффективную оптимизацию. Суточные квоты сбрасываются в полночь по тихоокеанскому времени для пользователей API. Планирование самых тяжёлых операций по генерации изображений на время сразу после полуночи PT гарантирует доступность полного суточного лимита. Кроме того, контроль лимитов обычно строже в часы пик (с 9:00 до 17:00 PT в будние дни), поэтому перенос массовых операций на непиковые часы может снизить частоту ошибок 429 даже при том же уровне.
Цепочки резервных моделей повышают устойчивость за счёт автоматического переключения на альтернативные модели при достижении лимита основной. Поскольку модели Gemini 1.5 не пострадали от сокращения квот в декабре 2025 года, они служат надёжными резервными вариантами для задач без генерации изображений. Для генерации изображений можно выстроить цепочку: Gemini 3 Pro Image Preview как основная модель (высшее качество), Gemini 2.5 Flash Image как вторичная (самая экономичная) и Imagen 4 как третичная. У каждой модели независимые лимиты, поэтому ошибка 429 на одной модели не блокирует остальные. Паттерн резервирования особенно хорошо работает в сочетании со стратегией распределения по нескольким проектам, создавая матрицу комбинаций «модель–проект», которая радикально снижает вероятность одновременного ограничения по всем путям.
Мониторинг потребления квоты проактивно предотвращает проблемы с лимитами до того, как они повлияют на ваших пользователей. API Gemini возвращает заголовки с информацией о лимитах в своих ответах, которые показывают текущее потребление относительно ограничений вашего уровня. Отслеживайте эти метрики с помощью простого логирования или интегрируйте с сервисами мониторинга вроде Datadog, Grafana или даже таблицу с ежедневным подсчётом API-вызовов. Установите оповещения при 70% и 90% от суточных пороговых значений, чтобы иметь время скорректировать нагрузку или активировать резервные стратегии до достижения жёсткого лимита. Панель управления AI Studio также предоставляет визуальный обзор статуса лимитов на aistudio.google.com/rate-limit, хотя этот интерфейс обновляется с небольшой задержкой по сравнению с заголовками API в реальном времени.
Когда стоит рассмотреть сторонние альтернативы
Несмотря на все доступные стратегии оптимизации для официального Gemini API, существуют обоснованные сценарии, когда сторонний подход имеет больше смысла, чем борьба с системой уровней Google. Решение зависит не только от стоимости — речь идёт о скорости разработки, операционной простоте и конкретных ограничениях по срокам вашего проекта.
Сервисы-агрегаторы API, такие как laozhang.ai, предоставляют доступ к моделям генерации изображений Gemini через единый эндпоинт, который работает вне системы уровней Google. Вместо управления повышением уровней, биллинговыми аккаунтами и распределением по нескольким проектам вы получаете один API-ключ с оплатой по факту использования и, как правило, более высокими лимитами пропускной способности. Компромисс заключается в том, что вы добавляете стороннюю зависимость в свою архитектуру, а ценовые структуры могут отличаться от прямого ценообразования Google. Для стартапов, создающих MVP, где скорость разработки важнее оптимизации стоимости за изображение, это может быть прагматичным выбором.
Когда оставаться с официальным API: если вы строите продакшн-систему, требующую гарантий SLA, соблюдения требований по локализации данных или прямой интеграции с другими сервисами Google Cloud (Vertex AI, Cloud Functions, BigQuery), официальный API — правильный выбор. Корпоративные клиенты также получают согласованные лимиты и выделенную поддержку, которые приходят с Tier 3 и формальными корпоративными соглашениями. Организации в регулируемых отраслях, таких как здравоохранение или финансы, часто нуждаются в аудиторском следе и сертификатах соответствия, которые обеспечивает прямое взаимодействие с Google Cloud, и официальный путь через API предоставляет эти гарантии «из коробки». Кроме того, если ваше приложение уже работает на инфраструктуре Google Cloud, сохранение всего в одной экосистеме упрощает сетевое взаимодействие, снижает задержки и позволяет использовать VPC Service Controls для дополнительной безопасности.
Когда рассмотреть альтернативы: если у вашего проекта жёсткие сроки и 30-дневное ожидание квалификации на Tier 2 может заблокировать запуск, или если паттерн использования крайне нестабилен (пиковые нагрузки в тысячи изображений, сменяющиеся периодами затишья), или если вам нужен доступ к нескольким моделям генерации изображений (не только Gemini) через единую интеграцию, сервисы-агрегаторы могут устранить операционную нагрузку по управлению множеством API-отношений. Это особенно актуально для агентств и консалтинговых компаний, которые создают приложения для множества клиентов — поддержка отдельных проектов Google Cloud, биллинговых аккаунтов и прогрессий по уровням для каждого клиента создаёт значительную административную нагрузку, которую один ключ агрегатора может устранить. При сравнении стоимости следует учитывать не только цену за изображение, но и часы разработчиков, потраченные на управление инфраструктурой, мониторинг квот и устранение проблем с повышением уровней в нескольких проектах.
Альтернативные модели генерации изображений также заслуживают рассмотрения при оценке вариантов. Imagen 4 (специализированная модель Google для изображений) предлагает быструю генерацию по $0,02 за изображение — примерно вдвое дешевле Gemini 2.5 Flash — хотя с иными характеристиками возможностей и качества. DALL-E 3 через API OpenAI, Stable Diffusion через Stability AI и API Midjourney — у каждой собственная структура лимитов, которая может лучше подходить для конкретных нагрузок. Для приложений, требующих нескольких моделей, мультимодельная маршрутизация позволяет динамически выбирать наиболее подходящую (или наиболее доступную) модель для каждого запроса. Ключевое преимущество этого подхода — устойчивость: если один провайдер неожиданно ужесточит лимиты (как произошло с Gemini в декабре 2025), ваше приложение может плавно перенаправить трафик на альтернативы без простоя или ошибок, видимых пользователям.
Ваш план действий по устранению лимитов
Правильное решение зависит от вашей конкретной ситуации, бюджета и сроков. Вот итоговая система координат для определения следующих шагов.
Для немедленного облегчения (решение в течение часа): включите биллинг в вашем проекте Google Cloud, если ещё не сделали этого, и реализуйте логику повторных попыток с экспоненциальной задержкой. Эти два шага решают 90% проблем с лимитами для разработчиков, генерирующих менее нескольких сотен изображений в день.
Для среднесрочного масштабирования (ближайшие 30–90 дней): двигайтесь к Tier 2, накапливая $250 расходов в Google Cloud, начните использовать Batch API для несрочной генерации изображений и настройте мониторинг для отслеживания паттернов потребления квот. Эта комбинация обеспечивает существенную пропускную способность при разумных затратах.
Для продакшн-готовности (построение с расчётом на масштаб): реализуйте распределение по нескольким проектам для отказоустойчивости и пропускной способности, используйте очередь запросов для превентивного предотвращения ошибок 429, кэшируйте часто генерируемые изображения и оцените, что лучше подходит для ваших объёмов и бюджета — Tier 3 или сторонний агрегатор. На этом этапе инвестируйте в полноценную наблюдаемость: настройте дашборды, отслеживающие потребление квот по проектам, перцентили задержки API и частоту ошибок 429 во времени. Эти данные подскажут, когда добавить дополнительные проекты, когда перенести нагрузку на Batch API и когда экономика оправдывает переход на более высокий уровень. Наиболее устойчивые архитектуры рассматривают лимиты как штатную операционную задачу, а не как исключительную ситуацию, проектируя плавную деградацию изначально, а не встраивая решения после сбоев в продакшне.
Часто задаваемые вопросы
Сколько изображений я могу генерировать в день на бесплатном уровне Gemini?
Через API — ноль. Бесплатный уровень имеет 0 IPM (изображений в минуту), что означает полную блокировку генерации изображений. Бесплатный уровень поддерживает только текстовый и мультимодальный ввод/вывод. Для генерации изображений через Gemini API необходимо включить биллинг (перейти на Tier 1). Это самый распространённый сюрприз для новых разработчиков.
Сколько времени занимает переход с бесплатного уровня на Tier 1?
Обычно мгновенно. После привязки биллингового аккаунта к проекту Google Cloud (через AI Studio или Cloud Console) повышение до Tier 1 вступает в силу в течение нескольких минут. Некоторые разработчики с новыми аккаунтами или международными способами оплаты сообщали о задержках в 24–48 часов из-за верификации биллинга, но это нетипично.
Увеличивают ли несколько API-ключей мой лимит?
Нет. Лимиты применяются на уровне проекта, а не на уровне API-ключа. Создание десяти API-ключей в одном проекте даёт вам десять ключей, разделяющих один и тот же пул квот. Для фактического увеличения доступной квоты нужно либо повысить уровень, либо распределить нагрузку между несколькими проектами Google Cloud (каждый со своим биллинговым аккаунтом).
Когда сбрасываются лимиты Gemini?
Поминутные лимиты (RPM, TPM, IPM) сбрасываются каждые 60 секунд по принципу скользящего окна. Суточные лимиты (RPD) сбрасываются в полночь по тихоокеанскому времени (PT) для пользователей API. Понимание этого графика помогает планировать тяжёлые нагрузки на момент максимально доступной квоты — запуск пакетных заданий сразу после полуночи PT обеспечивает полный суточный лимит.
Стоит ли использовать Batch API для генерации изображений?
Безусловно, если вы можете допустить асинхронную обработку. Batch API предоставляет фиксированную 50%-ную скидку на все цены за токены, снижая стоимость изображений Gemini 2.5 Flash с $0,039 до $0,0195 за каждое, а изображений Gemini 3 Pro — с $0,134 до $0,067. Компромисс заключается во времени обработки: пакетные запросы выполняются в течение 24-часового окна, а не мгновенно. Для генерации миниатюр, создания библиотек контента или любой фоновой обработки изображений экономия значительна.