
截至 2026 年 3 月 20 日,Gemini 3 Flash 更适合做“更强能力的快车道”,尤其是 coding、工具调用更重、需要 Computer Use 的工作流;Gemini 3.1 Flash-Lite 更适合做“更便宜的高吞吐车道”,尤其是翻译、抽取、分类、路由这类高频任务。 这才是这个关键词背后的真实答案。
难点在于,这不是一个 Google 官方已经帮你做成“同一张 benchmark 表”的对比题。Google 现在把证据分散在 pricing、Gemini 3 Flash model page、Gemini 3.1 Flash-Lite model page、release notes、rate limits,以及 DeepMind 的 Gemini 3 Flash page 和 Gemini 3.1 Flash-Lite page 上。
所以这篇文章不打算假装有一个“绝对赢家”。更合理的做法,是把当前官方能确认的价格、能力、工具支持、批处理上限和适配任务放到一起,然后给出一个可执行的路由判断。
要点速览
如果你只要最短答案,可以直接按下面这个规则走:
- 选 Gemini 3 Flash:当你更在意推理强度、agentic coding、Computer Use,以及“更强的 fast lane”。
- 选 Gemini 3.1 Flash-Lite:当你更在意 token 成本、批量吞吐、翻译、抽取、标签分类和模型路由。
- 两者都保留:如果你的生产流量里既有高价值重任务,也有大量便宜任务,这通常是最稳的答案。
当前官方对比可以先记住下面这张表:
| 项目 | Gemini 3.1 Flash-Lite | Gemini 3 Flash | 实际含义 |
|---|---|---|---|
| 状态 | Preview | Preview | 两者都不是 Stable 默认车道 |
| 上线日期 | 2026-03-03 | 2025-12-17 | Flash-Lite 更新,但不代表层级更高 |
| Model ID | gemini-3.1-flash-lite-preview | gemini-3-flash-preview | 必须显式路由 |
| Standard input | 免费后 $0.25 / 1M | 免费后 $0.50 / 1M | Flash-Lite 输入成本减半 |
| Standard output | 免费后 $1.50 / 1M | 免费后 $3.00 / 1M | Flash-Lite 输出成本减半 |
| Batch 价格 | 免费后 $0.125 / $0.75 | 无免费 batch,之后 $0.25 / $1.50 | Flash-Lite 更适合异步高吞吐 |
| 上下文窗口 | 1,048,576 tokens | 1,048,576 tokens | 不是区分点 |
| 最大输出 | 65,536 tokens | 65,536 tokens | 也不是区分点 |
| Computer Use | 不支持 | 支持 | 这是最重要的能力差之一 |
| Search / Maps grounding | 支持,但无免费 grounding | 支持,但无免费 grounding | grounding 不是这组对比里的免费优势 |
| 更适合 | 低成本高频任务 | 更强的推理与 agentic 工作流 | 真实区别是车道,不是代际口号 |
为什么这组对比很容易让人看错
很多人看到名字,会下意识以为 Flash-Lite 只是 Flash 的便宜版,或者觉得 3.1 一定天然高于 3。官方页面其实不是这么讲的。
Google 对 Gemini 3 Flash 的定位,是“最强的 multimodal understanding fast model”以及更强的 agentic / vibe coding 能力。Google 对 Gemini 3.1 Flash-Lite 的定位,则是高频轻量任务、低延迟、高吞吐、低成本、简单数据处理和路由。
也就是说,这不是“谁更新谁赢”的故事,而是:
- 一条更强、更贵、更偏 premium 的快车道
- 一条更便宜、更高吞吐、更适合 bulk traffic 的快车道
如果你用这个框架看,后面的价格差、能力差、批处理差都会变得更好理解。
价格、免费层、grounding 与 batch 吞吐
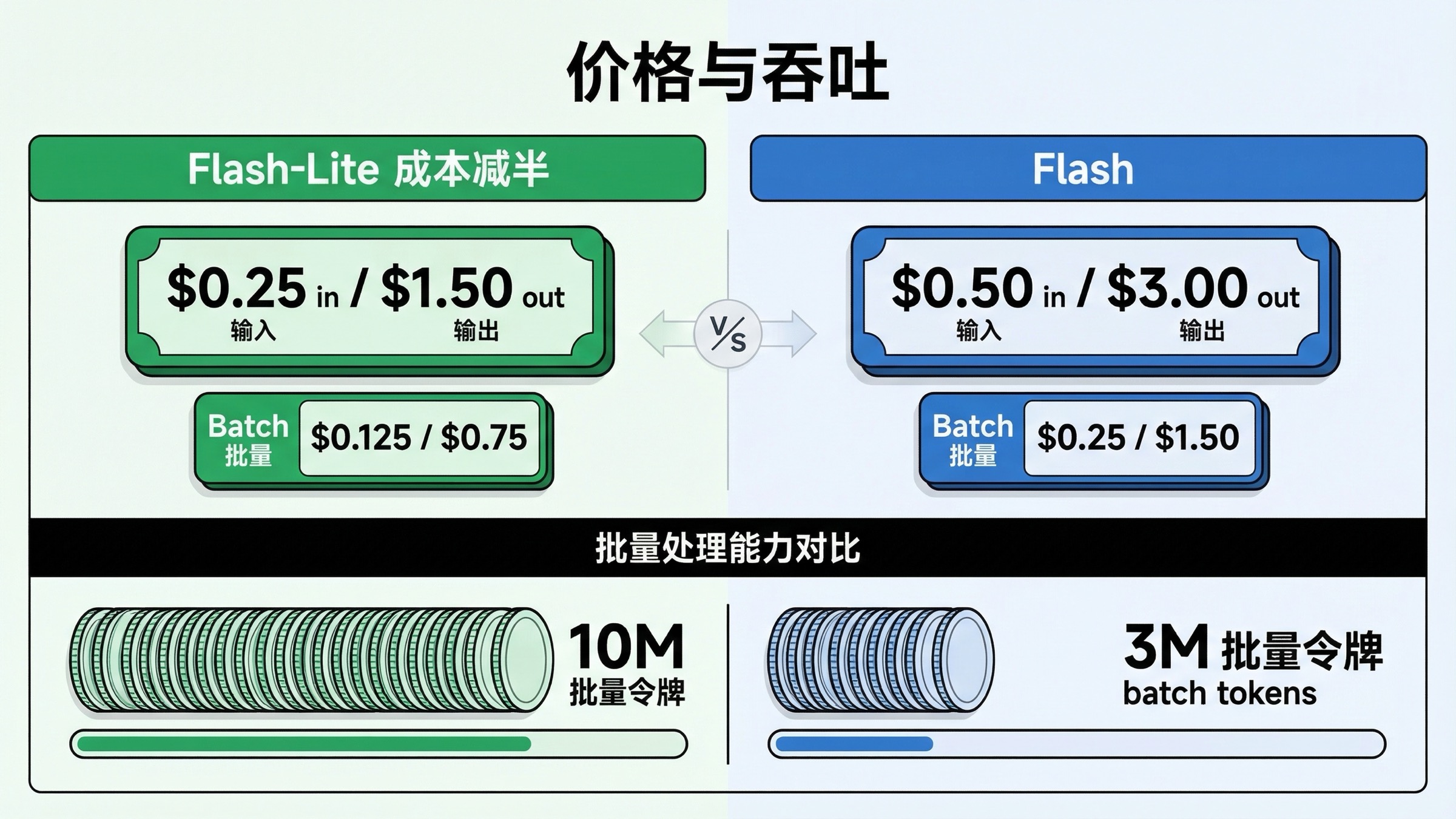
在这组对比里,价格是最清楚的官方差异。
按照 Gemini Developer API pricing 当前页面:
- Gemini 3.1 Flash-Lite Preview:免费层后,input
\$0.25/ 1M,output\$1.50/ 1M - Gemini 3 Flash Preview:免费层后,input
\$0.50/ 1M,output\$3.00/ 1M
也就是 Gemini 3 Flash 目前大约是 2 倍价格。
如果你的任务本身更像:
- 翻译
- 抽取
- 标签分类
- 路由
- 大规模摘要
- 大量异步批处理
那么光是价格差,已经足够把答案推向 Flash-Lite。
Batch 价格也延续这个方向:
- Gemini 3.1 Flash-Lite Batch:免费层后
\$0.125input,\$0.75output - Gemini 3 Flash Batch:没有免费 batch,之后
\$0.25input,\$1.50output
这个差异不是小修小补,而是很明确的“便宜车道”与“premium 车道”。
更重要的是,rate limits 页面 还给出一个对异步流量非常关键的信号。在 Tier 1 Batch API 表里:
- Gemini 3.1 Flash-Lite Preview:
10,000,000enqueued batch tokens - Gemini 3 Flash Preview:
3,000,000enqueued batch tokens
如果你在做高吞吐异步任务,这一条比很多 benchmark 更有决策价值。因为它说明更便宜的模型,公开 batch ceiling 还更大。
grounding 这里也要说清楚。两边的 model page 都写了 Search grounding 和 Maps grounding 支持,但 pricing 页当前显示:
- 两边都没有免费层 grounding
- 在 paid 模式里,两边都是 每月 5,000 个免费 grounding prompts,超过后再收费
所以你不能把其中任何一个理解成“grounding 免费优势模型”。如果 grounding 是你的主诉求,这组对比的关键词本身就不是最好入口。
如果你更关心配额与预算,可以继续看我们的 Gemini API rate limits per tier 指南 和 Gemini API context caching 成本说明。
能力差异:为什么它们不是同一个模型的高低配
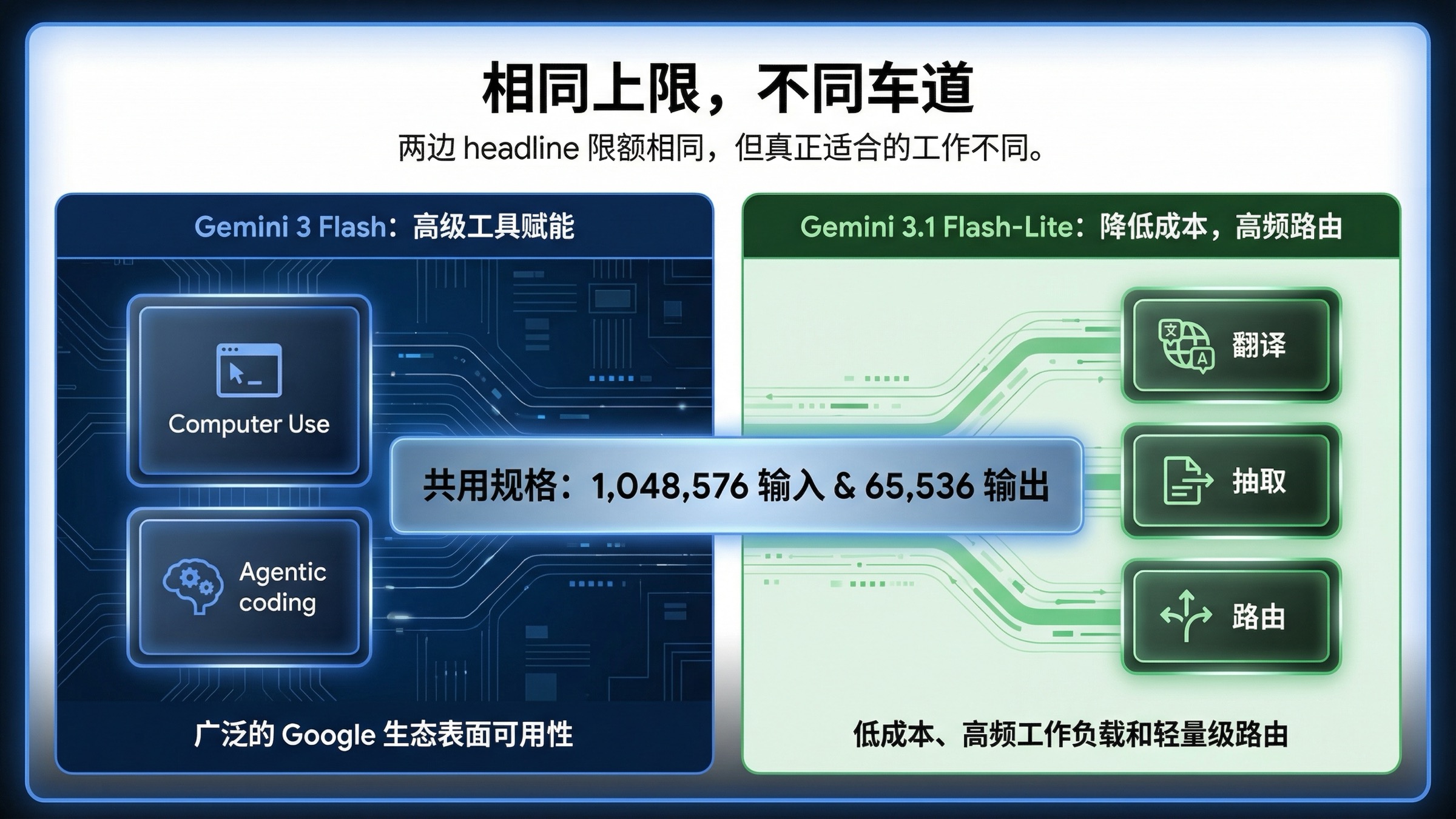
很多人真正容易误判的地方,不在价格,而在能力层。
先说相同点。两边在 headline 规格上很接近:
- 都支持 text output
- 都支持 text、image、video、audio、PDF 输入
- 都是
1,048,576input tokens - 都是
65,536output tokens - 都支持 Batch、Function Calling、Structured Outputs、Code Execution、Caching
如果你只看这些,很容易得出“那不就是一个贵一点、一个便宜一点吗”的结论。
但真正拉开差距的是工作流层面的能力。
Gemini 3 Flash 支持 Computer Use,Gemini 3.1 Flash-Lite 不支持。
这不是小差别。如果你的 agent 需要真正操作 UI,或者你在评估更重的 tool-use / browser-use 场景,3 Flash 立刻就不是可有可无的 premium,而是功能上真正更完整的那条线。
第二个差别是官方定位本身。Google 对 3 Flash 的用词,是更强的 multimodal understanding、agentic coding、advanced reasoning、long-context understanding。Google 对 3.1 Flash-Lite 的用词,则更偏 translation、extraction、routing、high-frequency lightweight tasks、extremely low latency。
所以我更建议这样理解:
- Gemini 3 Flash:更强能力的 fast lane
- Gemini 3.1 Flash-Lite:更便宜的 high-volume lane
把 Flash-Lite 当成 3 Flash 的“平替”会出问题;把它当成一条专门承接便宜流量的车道,反而更符合官方给出的产品形状。
官方性能页能说明什么,不能说明什么
Google DeepMind 给两边都做了很强的官方展示页:
这些页面是有价值的,但也要注意一个 caveat:它们不是同一张官方 head-to-head 对照表。
Gemini 3.1 Flash-Lite 的 model card 还明确提醒,当前结果使用了改进后的评测方式,不能直接与更早的 Gemini model card 数字做完全一一对应。这也是为什么这篇文章不想假装自己能给你一个“实验室级绝对胜负”。
但如果只做方向性判断,官方页面还是已经很清楚:
- Gemini 3 Flash 的官方能力叙事更强
- Gemini 3.1 Flash-Lite 的官方成本效率叙事更强
换句话说,3 Flash 的问题不是“值不值”,而是“你愿不愿意为这条 premium fast lane 付这笔钱”;3.1 Flash-Lite 的问题不是“能不能用”,而是“你的任务是不是更适合廉价高吞吐,而不需要 premium 工具能力”。
哪些任务该选哪一个
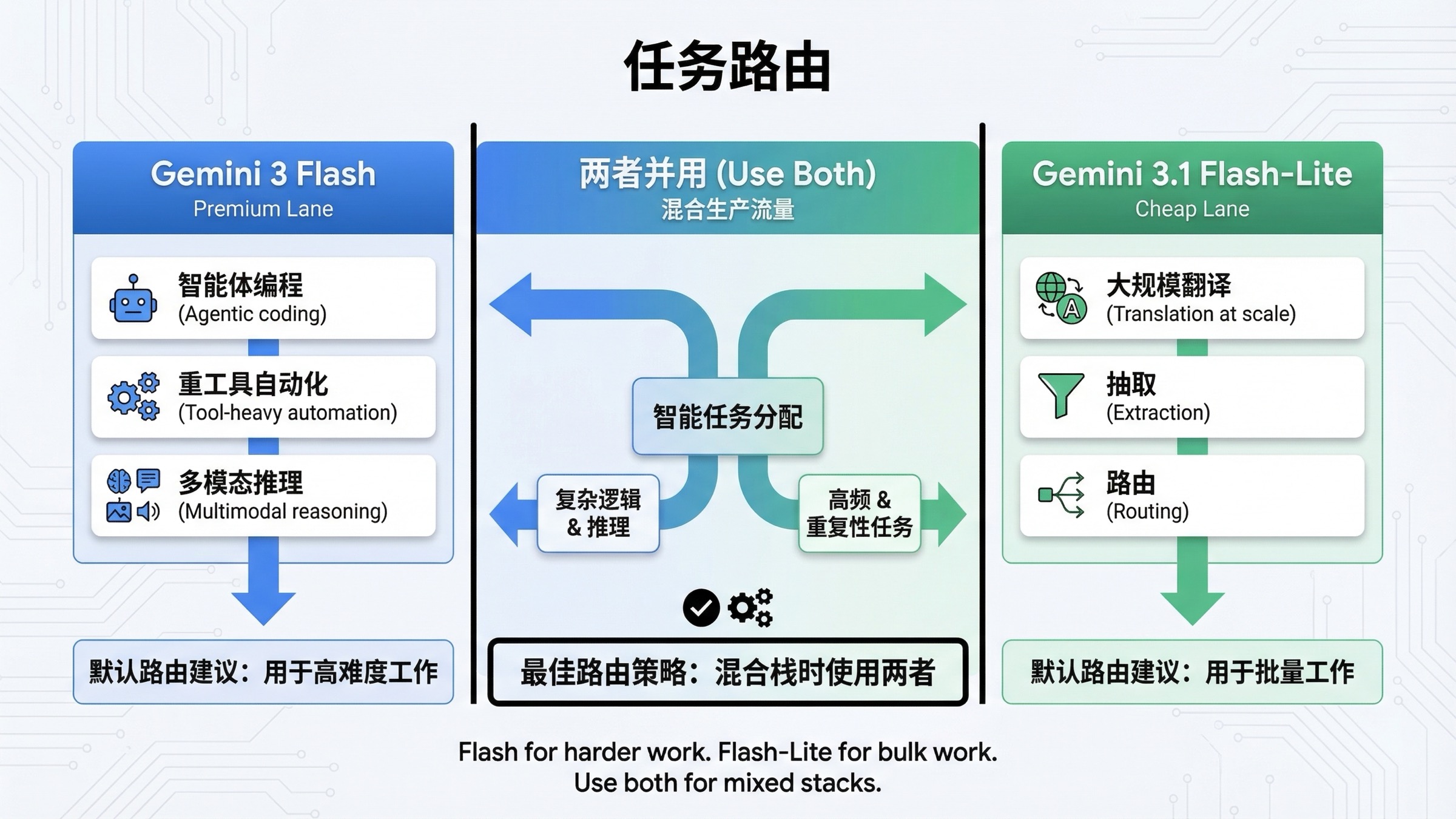
最有用的结论,还是要落回任务类型。
| 场景 | 更建议先选 | 原因 |
|---|---|---|
| agentic coding | Gemini 3 Flash | 官方定位和能力叙事都更强 |
| tool-heavy automation | Gemini 3 Flash | Computer Use 是决定性差异 |
| 更难的 multimodal reasoning | Gemini 3 Flash | 更像 premium fast lane |
| 大规模翻译 | Gemini 3.1 Flash-Lite | 更便宜,也更符合官方定位 |
| 结构化抽取 | Gemini 3.1 Flash-Lite | 高吞吐、低成本更重要 |
| 分类 / 路由层 | Gemini 3.1 Flash-Lite | 这是它最自然的场景之一 |
| 大量异步批处理 | Gemini 3.1 Flash-Lite | batch 价格更低,batch ceiling 更高 |
| 混合生产流量 | 两者都保留 | 高价值任务走 3 Flash,bulk traffic 走 Flash-Lite |
这组表其实已经足够回答大多数团队的实际问题。你不需要把这篇文章读成“谁更先进”,而要读成“哪条车道该承接哪类任务”。
怎么落地,才不容易后悔
我更推荐的上线方式,不是“一刀切换模型”,而是分车道:
- 先把 Flash-Lite 放到便宜车道
把翻译、抽取、标签、路由、轻量摘要这些 bulk traffic 先切给 gemini-3.1-flash-lite-preview。这些地方最容易马上获得成本收益。
- 把 3 Flash 留给 premium fast lane
把 coding、复杂工具流、需要 Computer Use 的工作流、以及更难的 multimodal reasoning 留给 gemini-3-flash-preview。
- 评估失败样本,而不是只看平均分
因为两边都还是 Preview,你不该只看平均延迟或者平均分数,还应该看:
- structured output 是否更稳
- tool calling 是否更可靠
- 长上下文下是否漂移
- 每个成功任务的真实成本,而不只是 token 单价
如果你现在的 rollout 纪律还不够强,建议顺手看看我们的 Gemini API 故障排查指南。
一句话总结就是:
- 更强任务,走 3 Flash
- 更便宜的大流量任务,走 3.1 Flash-Lite
- 混合场景,最好两者并用
升级默认路由前,至少先测这 5 件事
很多团队真正会踩坑的地方,不是价格表,而是把“官方更强”直接翻译成“业务一定更稳”。在把 Gemini 3 Flash 或 Gemini 3.1 Flash-Lite 提升成默认路由之前,我建议至少把下面 5 件事跑一遍。
第一,看结构化输出的稳定性。如果你的下游依赖 JSON、schema 或函数参数,不要只看文本质量。要看字段是否缺失、格式是否漂移、重试后是否更稳。很多时候,便宜模型真正省下来的不是 token,而是你为了修复失败结果少写了多少兜底逻辑。
第二,看工具调用成功率,而不是只看“支持不支持”。官方页面写着都支持 Function Calling,但实际体验往往取决于复杂工具链、调用深度和失败恢复策略。对于重度 tool-use,你应该用自己的真实 prompt 和真实工具 schema 跑一轮,而不是只凭官方 capability 表拍板。
第三,看长上下文里的回忆质量。两边 headline 都是 1M context,但这不代表长文档、多轮检索、跨段引用时表现一样。尤其是你要做长文档问答、审阅或多轮规划时,更要关心“能不能稳住”,而不是只关心“能不能塞进去”。
第四,看成功任务的真实成本。便宜模型不一定总是更便宜。如果一个模型需要更多重试、更多后处理、更多 fallback,它的业务总成本可能反而更高。把 input/output 单价、重试率、超时率、以及人工纠偏成本放到同一张表里看,结论会更可靠。
第五,把 split-route 当成默认候选,而不是失败妥协。很多团队一开始就试图找“唯一默认模型”,结果反而把高价值任务和 bulk traffic 都绑在同一条车道上。对这组模型来说,最自然的架构往往就是:Gemini 3 Flash 负责 premium task,Gemini 3.1 Flash-Lite 负责 bulk task。
如果你把这 5 件事测完,再回头看这篇文章,通常会发现答案没有那么抽象:不是“哪个模型更先进”,而是“你的系统该把哪类任务送进哪条车道”。
FAQ
Gemini 3 Flash 比 Gemini 3.1 Flash-Lite 更好吗?
如果“更好”指的是更强的能力、更强的 agentic / coding 定位、以及 Computer Use 支持,那是的。如果“更好”指的是性价比,那不一定,Flash-Lite 便宜得多。
Gemini 3.1 Flash-Lite 只是 Gemini 3 Flash 的便宜版吗?
不是。更准确的理解是,它是 Gemini 3 家族里的高吞吐价值车道,而不是 3 Flash 的简单降配版。
两边都有免费层吗?
都有 standard token 的免费层,但 batch、caching 和 grounding 细节并不完全一样。
两边都支持 grounding 吗?
支持,但 pricing 页面当前显示两边都没有免费层 grounding;paid usage 下则有每月 5,000 个免费 prompts。
哪一个更适合 coding?
Gemini 3 Flash。
哪一个更适合翻译、抽取和模型路由?
Gemini 3.1 Flash-Lite。
应该把 3 Flash 全量替换成 3.1 Flash-Lite 吗?
不建议。更好的做法是把 Flash-Lite 用在便宜车道,把 3 Flash 留给更难、更值钱的任务。