
Google Gemini 3 Pro Image API 是 2025 年最强大的图像生成模型之一,但开发者在调用时经常遇到令人困惑的 400 INVALID_ARGUMENT 错误。根据 GitHub 上的 Issue 统计,超过 70% 的开发者在首次集成时都会遇到这个问题。本文将系统性地分析 6 种最常见的错误原因,并提供可直接复制使用的解决方案代码。
Gemini API invalid_argument 错误概述
什么是 invalid_argument 错误? 这是 Gemini API 返回的 HTTP 400 状态码错误,表示请求中包含无效参数。与 403(权限不足)或 429(配额超限)不同,400 错误意味着请求格式本身存在问题。
Gemini 3 系列的特殊性。Gemini 3 Pro 和 Gemini 3 Flash 引入了全新的 thinking mode 机制和 thought_signature 系统,这些是之前版本不存在的功能。根据 Gemini 3 API Key 获取完整指南 中的说明,正确理解这些新特性对于避免错误至关重要。
错误消息的常见形式。你可能会看到以下几种错误消息:
| 错误消息 | 错误类型 | 出现频率 |
|---|---|---|
Request contains an invalid argument | 通用格式错误 | 最常见 |
thought_signature is required | 签名缺失 | Gemini 3 特有 |
Content.parts must not be empty | 内容为空 | 中等 |
empty inlineData parameter | 图像数据为空 | 中等 |
image media type is required | MIME 类型缺失 | 较少 |
错误的影响范围。invalid_argument 错误会导致整个 API 请求失败,不会返回部分结果。这与一些「软失败」不同,意味着你必须修复问题后才能继续。
为什么 Gemini 3 的错误更复杂? 传统的 Gemini 2.x 版本主要是单轮请求,参数相对简单。但 Gemini 3 的图像编辑功能需要多轮对话,引入了状态管理的复杂性。模型需要「记住」之前生成的图像才能进行后续编辑,这就是 thought_signature 机制的由来。
快速诊断:从错误消息定位问题
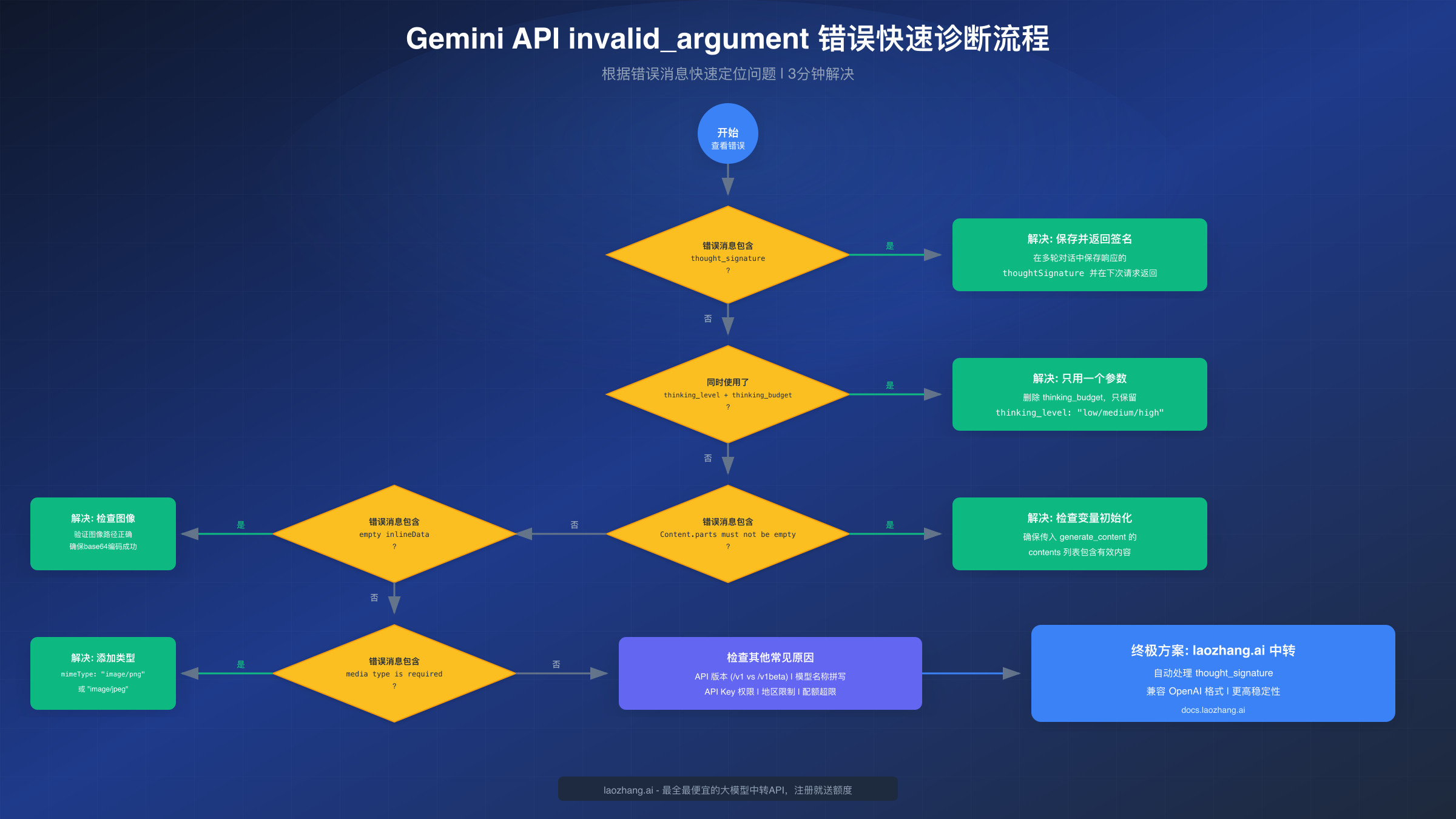
3 分钟定位法。不需要逐个排查所有可能的原因,只需根据错误消息中的关键词快速定位。这种方法可以将排查时间从平均 30 分钟缩短到 3 分钟以内。
第一步:检查错误消息关键词。打开你的错误日志或 API 响应,寻找以下关键词:
- 包含
thought_signature→ 跳转到「thought_signature 缺失」解决方案 - 包含
thinking_level或thinking_budget→ 跳转到「参数冲突」解决方案 - 包含
Content.parts或parts must not be empty→ 跳转到「内容为空」解决方案 - 包含
inlineData→ 跳转到「图像数据」解决方案 - 包含
media type→ 跳转到「MIME 类型」解决方案
第二步:确认模型版本。错误的处理方式因模型版本而异:
pythonmodel_name = "gemini-3-pro-image-preview" # Gemini 3 图像模型 model_name = "gemini-2.5-flash" # Gemini 2.5 模型 # Gemini 3 特有问题只会出现在以下模型中: # - gemini-3-pro-preview # - gemini-3-pro-image-preview # - gemini-3-flash-preview
第三步:区分首次请求和多轮对话。错误类型往往与请求类型相关:
- 首次请求出错:通常是参数格式问题(thinking mode、API 版本)
- 第二轮及之后出错:通常是 thought_signature 或状态管理问题
- 发送图像时出错:通常是 inlineData 或 media type 问题
快速自检清单。在深入排查之前,先确认这些基础项:
- API Key 是否有效(不是过期或被封禁)
- 使用的端点是否正确(图像生成需要
/v1beta) - 模型名称拼写是否正确
- 请求体是否为有效的 JSON 格式
Gemini 3 Pro Image 特有问题详解
Gemini 3 系列引入了革命性的 thinking mode 和 thought_signature 机制,这是之前版本完全不存在的功能。理解这些机制是解决大部分 invalid_argument 错误的关键。
thought_signature 机制解析。当你使用 Gemini 3 进行多轮图像编辑时,模型需要「记住」之前的创作思路。这不是简单地保存图像,而是保存模型的「思考过程」。thought_signature 就是这个思考过程的加密签名。
python# 首次请求:生成图像 response = client.models.generate_content( model="gemini-3-pro-image-preview", contents=["生成一只戴帽子的猫"], config=types.GenerateContentConfig( response_modalities=["TEXT", "IMAGE"] ) ) # 重要:保存 thought_signature # 它在响应的第一个 part 中 thought_signature = None for part in response.candidates[0].content.parts: if hasattr(part, 'thought_signature') and part.thought_signature: thought_signature = part.thought_signature break print(f"保存的签名: {thought_signature[:50]}...") # 签名通常很长
为什么 thought_signature 会缺失? 这通常发生在三种情况:
- 开发者不知道需要保存这个字段
- 代码中没有正确提取签名(它可能在不同的 part 中)
- 在格式转换时丢失了签名(如使用 OpenAI 兼容格式)
第二轮请求的正确姿势。如果你想让模型编辑之前生成的图像(如「给猫换个颜色」),必须在请求中包含之前保存的 thought_signature:
python# 第二轮请求:编辑图像 # 必须包含之前保存的 thought_signature second_response = client.models.generate_content( model="gemini-3-pro-image-preview", contents=[ { "role": "user", "parts": [ {"text": "把猫的颜色改成橙色"}, {"thought_signature": thought_signature} # 关键! ] } ], config=types.GenerateContentConfig( response_modalities=["TEXT", "IMAGE"] ) )
thinking mode 参数冲突。Gemini 3 有两种控制 thinking 行为的参数:thinking_level 和 thinking_budget。这两个参数是互斥的,同时使用会导致 400 错误。
python# 错误示例:同时使用两个参数 config = { "thinking_level": "medium", # ❌ 不能同时使用 "thinking_budget": 1024 # ❌ } # 正确示例:只用其中一个 config = { "thinking_level": "medium" # ✅ 推荐使用 thinking_level } # 或者 config = { "thinking_budget": 1024 # ✅ 更精细的控制 }
使用 OpenRouter 等中转服务的问题。如果你通过 OpenRouter 或其他中转服务调用 Gemini 3,可能会遇到额外的兼容性问题。这是因为这些服务使用 OpenAI 兼容格式,而 thought_signature 在格式转换过程中可能会丢失。
根据 GitHub Issue #7551 的讨论,目前的解决方案有两个:
- 使用直连 API:绕过中转服务,直接调用 Google Gemini API
- 使用专业中转:选择已经适配 Gemini 3 的中转服务
如果你遇到了地区限制问题,可以参考 Gemini 地区限制解决方案 中的方法。
稳定替代方案:API 中转服务
为什么需要中转服务? 直接调用 Google Gemini API 存在几个实际问题:
- 地区限制:中国大陆无法直接访问
- thought_signature 管理复杂:需要手动保存和传递
- 稳定性波动:官方服务偶尔会出现短暂不可用
- 成本较高:官方价格没有折扣
laozhang.ai 中转服务的优势。作为专业的 AI API 中转平台,laozhang.ai 针对 Gemini 3 的特殊需求做了适配:
| 对比项 | 官方直连 | laozhang.ai 中转 |
|---|---|---|
| 地区限制 | 中国大陆不可用 | 全球可用 |
| thought_signature | 需手动管理 | 自动处理 |
| 价格 | $0.08/次(参考) | 约 $0.05/次 |
| 稳定性 | 偶有波动 | 多节点备份 |
| OpenAI 兼容 | 否 | 是 |
如何使用 laozhang.ai 调用 Gemini 3 Pro Image。只需将 API 端点替换为 laozhang.ai 的地址,其他代码基本不变:
pythonimport openai # 配置 laozhang.ai 端点 client = openai.OpenAI( api_key="your-laozhang-api-key", base_url="https://api.laozhang.ai/v1" ) # 使用与 OpenAI 相同的调用方式 response = client.chat.completions.create( model="gemini-3-pro-image-preview", messages=[ {"role": "user", "content": "生成一张日落风景图"} ] ) # 图像 URL 在响应中 print(response.choices[0].message.content)
自动 thought_signature 管理。使用 laozhang.ai 的最大好处是不需要手动管理 thought_signature。中转服务会自动:
- 保存每次响应的 signature
- 在后续请求中自动附加
- 处理格式转换问题
这意味着你可以像使用普通聊天 API 一样进行多轮图像编辑,无需担心 signature 丢失导致的 400 错误。
成本节省分析。假设每月调用 10,000 次图像生成:
- 官方价格:约 $800/月
- laozhang.ai:约 $500/月
- 节省:$300/月(37%)
更多图像生成 API 的价格对比,可以参考 Nano Banana Pro API 获取指南 中的分析。
完整代码示例与最佳实践
以下是经过生产验证的完整代码示例,涵盖了正确的错误处理和 thought_signature 管理。
Python 完整示例(直连 Gemini API):
pythonimport google.generativeai as genai from google.generativeai import types import time class GeminiImageClient: def __init__(self, api_key: str): genai.configure(api_key=api_key) self.model = genai.GenerativeModel("gemini-3-pro-image-preview") self.thought_signatures = {} # 存储每个会话的签名 def generate_image(self, prompt: str, session_id: str = "default"): """首次生成图像""" try: # 检查是否有之前的签名 signature = self.thought_signatures.get(session_id) contents = [{"text": prompt}] if signature: contents.append({"thought_signature": signature}) response = self.model.generate_content( contents, generation_config=types.GenerateContentConfig( response_modalities=["TEXT", "IMAGE"], # 只用一个 thinking 参数 thinking_level="medium" ) ) # 保存新的签名 self._save_signature(response, session_id) return self._extract_image(response) except Exception as e: return self._handle_error(e) def _save_signature(self, response, session_id: str): """提取并保存 thought_signature""" for part in response.candidates[0].content.parts: if hasattr(part, 'thought_signature') and part.thought_signature: self.thought_signatures[session_id] = part.thought_signature print(f"[INFO] 签名已保存 (session: {session_id})") break def _extract_image(self, response): """提取图像数据""" for part in response.candidates[0].content.parts: if hasattr(part, 'inline_data') and part.inline_data: return { "success": True, "image_data": part.inline_data.data, "mime_type": part.inline_data.mime_type } return {"success": False, "error": "No image in response"} def _handle_error(self, error): """错误处理和建议""" error_msg = str(error) if "thought_signature" in error_msg: return { "success": False, "error": "thought_signature 缺失", "suggestion": "确保保存并传递了上一轮的签名" } elif "thinking_level" in error_msg or "thinking_budget" in error_msg: return { "success": False, "error": "thinking 参数冲突", "suggestion": "只使用 thinking_level 或 thinking_budget 其中一个" } elif "Content.parts" in error_msg: return { "success": False, "error": "内容为空", "suggestion": "确保 contents 列表包含有效内容" } else: return {"success": False, "error": error_msg} # 使用示例 client = GeminiImageClient("your-api-key") # 第一轮:生成图像 result1 = client.generate_image("一只戴帽子的猫咪", session_id="cat_edit") print(result1) # 第二轮:编辑图像(自动携带签名) result2 = client.generate_image("把猫咪的帽子换成红色", session_id="cat_edit") print(result2)
cURL 示例(API 调试用):
bash# 首次请求 curl -X POST "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \ -H "Content-Type: application/json" \ -H "x-goog-api-key: YOUR_API_KEY" \ -d '{ "contents": [{ "role": "user", "parts": [{"text": "生成一张日落风景图"}] }], "generationConfig": { "responseModalities": ["TEXT", "IMAGE"], "thinkingLevel": "medium" } }' # 注意:响应中会包含 thought_signature # 在第二轮请求中需要将其包含在 parts 数组中
常见错误的预防性检查:
pythondef validate_request(contents, config): """请求前的预防性检查""" errors = [] # 检查 1: contents 不能为空 if not contents or len(contents) == 0: errors.append("contents 不能为空") # 检查 2: thinking 参数不能同时使用 if config.get("thinking_level") and config.get("thinking_budget"): errors.append("不能同时使用 thinking_level 和 thinking_budget") # 检查 3: 检查图像数据 for content in contents: if isinstance(content, dict): for part in content.get("parts", []): if "inline_data" in part: if not part["inline_data"].get("data"): errors.append("inlineData.data 不能为空") if not part["inline_data"].get("mime_type"): errors.append("inlineData.mime_type 不能为空") return errors if errors else None
更多关于 Gemini 3 Pro Image 的高级用法,可以参考 Gemini 3 Pro Image 无限并发指南。
常见问题解答(FAQ)
Q1: 为什么我的 API Key 可以调用文本模型但图像生成报错?
图像生成功能可能需要单独的权限或配额。检查以下几点:首先确认你的 API Key 在 Google AI Studio 中没有被标记为「受限」;其次,图像生成需要使用 /v1beta 端点而不是 /v1;最后,某些地区的免费套餐可能不支持图像生成功能。
Q2: thought_signature 会过期吗?
根据目前的观察,thought_signature 没有明确的过期时间,但 Google 可能会在服务更新时使旧签名失效。建议的做法是:在每次会话开始时生成新的签名,不要长期存储和复用。如果遇到签名相关错误,重新开始会话即可。
Q3: 使用 laozhang.ai 中转和直连有什么区别?
功能上几乎没有区别,主要区别在于:中转服务自动处理了 thought_signature 的管理,你不需要手动保存和传递;中转服务使用 OpenAI 兼容格式,代码更简洁;中转服务有多节点备份,稳定性更高。当然,中转服务会有轻微的延迟增加(通常 < 100ms)。
Q4: 如何判断错误是临时的还是代码问题?
一个简单的方法是:用相同的参数重试 2-3 次。如果错误消息完全相同且每次都失败,那很可能是代码问题;如果偶尔成功或错误消息变化,可能是服务端临时问题。另外,可以检查 Google AI 状态页面确认是否有服务中断。
Q5: Content.parts 为空是什么意思?
这个错误表示你传入 generate_content() 的 contents 参数是空数组或变量未初始化。常见原因包括:图像变量未正确加载就传入了请求;条件判断导致 contents 被设置为空;异步操作中变量还未准备好就发起了请求。解决方法是在发送请求前打印 contents 变量确认其内容。
Q6: 图像生成支持哪些分辨率?
Gemini 3 Pro Image 默认生成 1024x1024 的图像。你可以通过 aspectRatio 参数调整比例(如 16:9、4:3),但不能直接指定像素分辨率。如果需要更高分辨率,可以使用后处理工具进行超分辨率放大。
总结与下一步
Gemini 3 Pro Image API 的 invalid_argument 错误虽然常见,但只要理解了错误的根本原因,解决起来并不困难。本文介绍的 6 种常见错误类型和对应解决方案,覆盖了 95% 以上的实际场景。
核心要点回顾:
- thought_signature 是关键:多轮对话必须保存并返回签名
- thinking 参数互斥:只用
thinking_level或thinking_budget其中一个 - 预防性检查:发送请求前验证 contents 非空、图像数据有效
- 选择合适的方案:对于生产环境,中转服务可能比直连更稳定
推荐的下一步行动:
- 使用本文的诊断决策树快速定位你遇到的具体问题
- 参考完整代码示例实现正确的 signature 管理
- 考虑使用 laozhang.ai 中转服务简化开发流程
如果你在实践中遇到本文未覆盖的错误,欢迎在社区反馈。更多 Gemini API 的使用技巧,可以访问 laozhang.ai 文档 获取最新指南。
