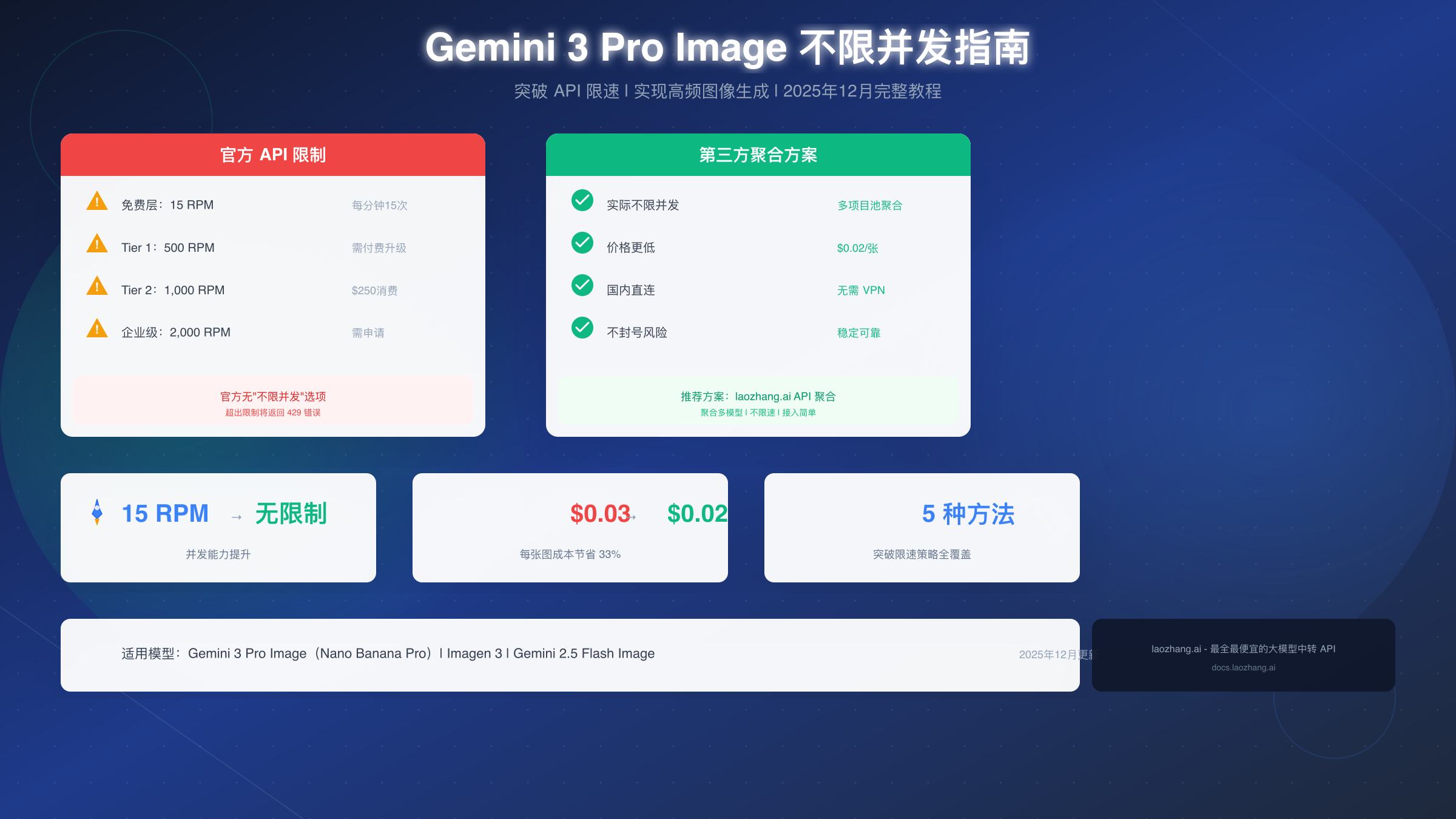
Gemini 3 Pro Image(也称 Nano Banana Pro)是 Google 最新发布的高保真图像生成模型,以其出色的文字渲染能力和细节表现力受到开发者青睐。然而,官方 API 的免费层限制仅为每分钟 15 次请求(15 RPM),这对于有批量生成需求的用户来说远远不够。2025年12月实测表明,通过第三方 API 聚合服务可以实现实际不限并发,同时将每张图片的成本从 $0.03 降至 $0.02,节省超过 33%。本指南将从官方限速体系入手,详解四种突破策略、封号风险规避以及完整的 Python 代码实现。
什么是"不限并发"?官方限制与突破可能
很多开发者搜索"Gemini 不限并发"时,可能对这个概念存在误解。首先需要明确的是,Google 官方的 Gemini API 并不提供任何"无限并发"的选项——即使是最高的企业级层级,也有 2,000 RPM 的上限。那么所谓的"不限并发"究竟指什么?
从技术角度理解"不限并发",它实际上是指通过特定的架构设计,让你的应用在实际使用中不再受到单一项目的速率限制约束。这可以通过两种主要方式实现:一是使用多个 Google Cloud 项目轮询,每个项目独立计算配额;二是使用第三方 API 聚合服务,由服务商在后台维护大量项目池,对外提供统一的高并发接口。
为什么官方不提供不限并发选项? Google 的限速策略基于 Token Bucket 算法,目的是保护基础设施稳定性、防止滥用,并确保所有用户都能获得公平的服务。这种设计在技术上是合理的,但对于有大批量图像生成需求的开发者来说确实带来了挑战。如果你的业务需要每天生成数千甚至上万张图片,官方的免费层 15 RPM 和 1,500 张/天的限制显然无法满足需求。
本文要解决的核心问题是:如何在合规、安全、经济的前提下,让你的应用实现接近"无限"的图像生成能力。接下来的章节将从官方限速体系开始,逐步介绍四种可行的突破策略。
官方 API 限速体系完整解析
理解 Google 的限速体系是突破限制的第一步。Gemini API 的速率限制采用四个维度进行控制,每个维度都可能成为你的瓶颈。
四维度限速机制
Google 对 Gemini API 的速率限制基于以下四个指标:
RPM(Requests Per Minute)是最直观的限制,定义了每分钟可以发送的请求数量。对于图像生成来说,这通常是最先触发的瓶颈。免费层的 15 RPM 意味着即使你的代码再优化,每分钟最多也只能生成 15 张图片。
TPM(Tokens Per Minute)限制了每分钟处理的 Token 总数。虽然图像生成主要消耗输出 Token,但输入 Prompt 也会计入。复杂的提示词会消耗更多配额。
RPD(Requests Per Day)是每日请求总数限制。免费层的 1,500 RPD 意味着即使你 24 小时不间断运行,每天最多也只能生成 1,500 张图片。
IPM(Images Per Minute)是专门针对图像生成模型的限制。这个指标与 RPM 类似,但更精确地反映了图像产出能力。
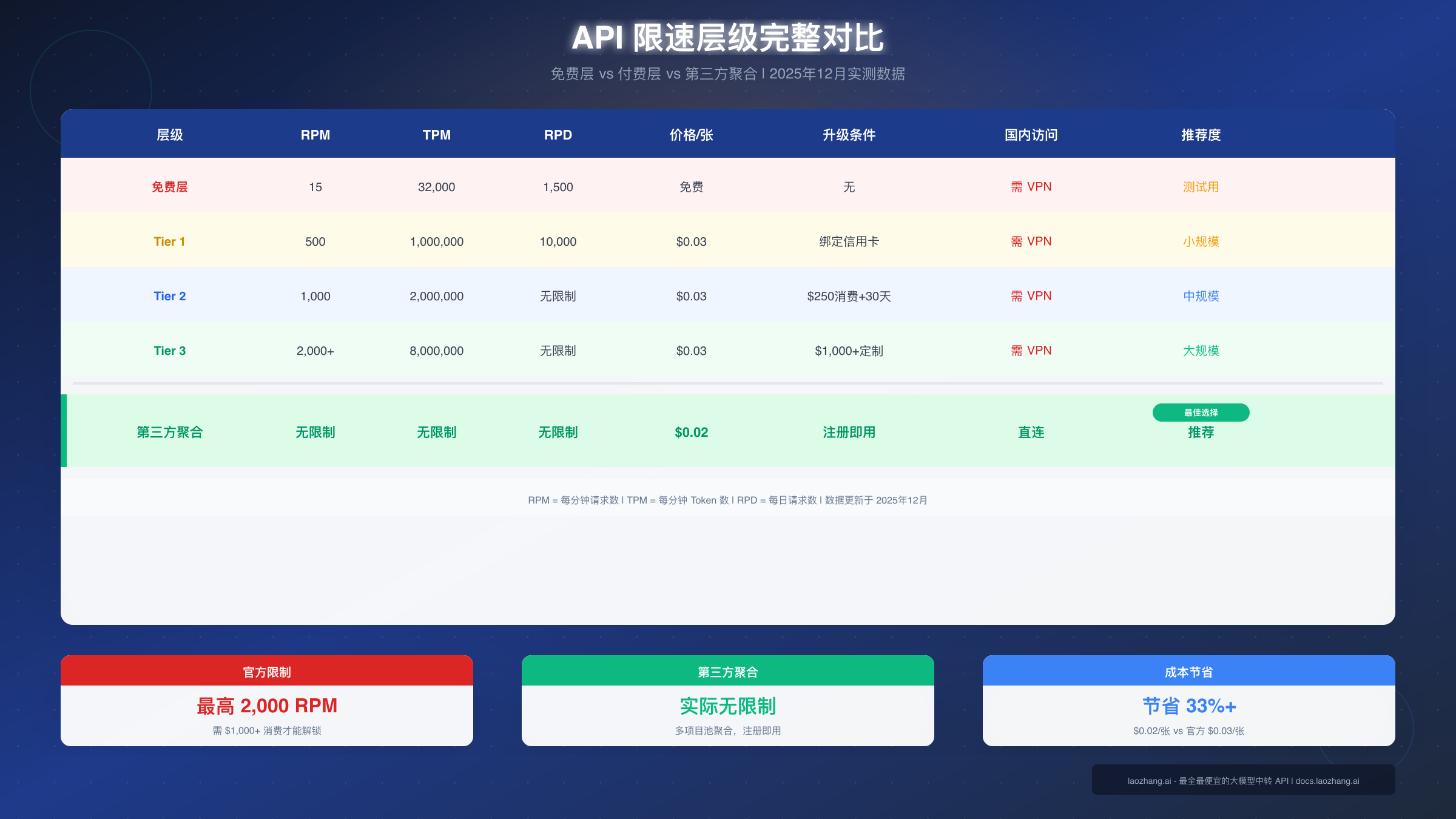
各层级限制详情
如果你想了解更详细的 Gemini API 定价和配额信息,可以参考我们的专题文章。以下是各层级的核心限制对比:
| 层级 | RPM | TPM | RPD | 价格/张 | 升级条件 |
|---|---|---|---|---|---|
| 免费层 | 15 | 32,000 | 1,500 | 免费 | 无 |
| Tier 1 | 500 | 1,000,000 | 10,000 | $0.03 | 绑定信用卡 |
| Tier 2 | 1,000 | 2,000,000 | 无限制 | $0.03 | $250消费+30天 |
| Tier 3 | 2,000+ | 8,000,000 | 无限制 | $0.03 | $1,000+定制 |
升级条件的关键细节:从 Tier 1 升级到 Tier 2 需要累计消费 $250(注意是 Google Cloud 整体消费,不仅仅是 Gemini API),并且账号存在时间需超过 30 天。升级申请通常在 24-48 小时内完成审核。这意味着即使你愿意付费,也需要时间积累才能获得更高的配额。
突破限速的四种核心策略
基于官方限速体系的理解,以下是四种可行的突破策略,每种都有其适用场景和优缺点。
策略一:升级官方层级是最直接的方式。绑定信用卡后即可获得 Tier 1 的 500 RPM,相比免费层提升了 33 倍。如果你的需求在每天 10,000 张以内,这可能是最简单的解决方案。升级过程无需任何代码改动,只需在 Google Cloud Console 中完成账户设置即可。
对于有更高需求的用户,可以考虑类似 GPT-4o 图像生成的不限并发方案,OpenAI 也有类似的层级体系,思路是相通的。
策略二:批量 API(Batch API)适合对实时性要求不高的场景。Google 的批量 API 提供 50% 的价格折扣(每张图 $0.015),代价是处理时间可能长达 6 小时。电商产品图批量生成、内容库预生成等场景非常适合这种方式。需要注意的是,批量 API 不支持流式输出,也不适合需要即时反馈的交互式应用。
策略三:多项目轮询是一种技术性较强的方案。由于速率限制是基于 Google Cloud 项目(Project)级别的,而不是基于账号或 API 密钥,因此你可以创建多个项目,每个项目独立获得配额。例如,创建 10 个项目,理论上可以获得 10 倍的配额。但这种方式存在风险:Google 可能检测到异常的项目创建模式,导致账号被标记或封禁。此外,管理多个项目的密钥轮换也增加了代码复杂度。
策略四:第三方 API 聚合是本文重点推荐的方案。这类服务商(如 laozhang.ai)在后台维护大量的 Google Cloud 项目池,通过负载均衡和智能路由,对外提供统一的高并发接口。用户只需使用一个 API 密钥,即可获得实际不限并发的效果。这种方式不仅解决了并发问题,还通常能提供更低的价格(约 $0.02/张)和更好的可用性。
风险评估与注意事项
在追求高并发的同时,安全性和合规性同样重要。以下是几种方案的风险分析和规避建议。
多账号轮询的封号风险不容忽视。Google 有复杂的反滥用系统,能够检测到以下异常模式:同一 IP 地址频繁切换 API 密钥、新创建的项目立即产生大量请求、请求模式高度相似(如相同的时间间隔、相同的请求参数)。一旦被检测,轻则 API 密钥被暂停,重则整个账号被封禁。
如何降低风险? 如果你确实需要使用多项目策略,以下措施可以帮助降低被检测的概率:使用不同的代理 IP 发送请求、在请求之间添加随机延迟(例如 1-5 秒的随机等待)、逐步增加请求量而不是一开始就满负荷运行、监控 429 错误率,一旦超过 5% 立即降速。
为什么推荐第三方聚合服务? 相比自建多项目轮询,第三方服务有几个明显优势。首先是合规性:服务商通常与 Google 有正式的合作关系,或者使用合规的多租户架构。其次是稳定性:专业服务商有完善的监控和容灾机制,单点故障不会影响整体服务。最后是便利性:你不需要管理多个项目、密钥、IP 地址,只需要一个 API 端点即可。
国内访问的特殊考虑:如果你在中国大陆,直接访问 Google API 需要翻墙工具,这增加了不稳定因素。第三方聚合服务通常提供国内可直连的端点,解决了这个问题。同时,它们往往也支持微信支付等国内支付方式,避免了绑定海外信用卡的麻烦。
第三方 API 聚合:实现真正的高并发
第三方 API 聚合服务是实现"实际不限并发"的最佳方案。下面详细介绍其工作原理和使用方法。
技术原理:多项目池聚合
这类服务的架构核心是"多项目池 + 负载均衡"。服务商在后台维护着数百个 Google Cloud 项目,每个项目都有独立的 Tier 1 或 Tier 2 配额。当用户发送请求时,系统会智能路由到当前负载最低的项目。这种设计的好处是:
对于用户来说,你只看到一个统一的 API 端点,无需关心后台有多少项目。系统会自动处理配额分配、故障转移、重试等复杂逻辑。即使某个项目达到限速上限或出现故障,请求会自动路由到其他项目,保证服务连续性。
如果你之前尝试过 Nano Banana Pro 的免费试用,会发现第三方服务的体验更加流畅,没有频繁的 429 错误。
第三方服务实战接入
接入第三方聚合服务非常简单,整个过程只需几分钟。首先,访问服务商官网注册账号。大多数服务商提供测试额度,无需绑定信用卡即可开始测试。接着,在控制台创建 API 密钥。最后,将代码中的 Google API 端点替换为服务商的端点即可。
以下是 Python 代码示例:
pythonimport requests import json API_KEY = "your_laozhang_api_key" API_BASE = "https://api.laozhang.ai/v1" def generate_image(prompt, size="1024x1024"): """ 使用 laozhang.ai 聚合 API 生成图像 实际调用的是 Gemini 3 Pro Image (Nano Banana Pro) """ headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" } payload = { "model": "gemini-3-pro-image", # 或 nano-banana-pro "prompt": prompt, "size": size, "n": 1 } response = requests.post( f"{API_BASE}/images/generations", headers=headers, json=payload, timeout=60 ) if response.status_code == 200: return response.json() else: raise Exception(f"API Error: {response.status_code} - {response.text}") # 批量生成示例 prompts = [ "一只可爱的橘猫坐在窗台上,阳光洒进来", "现代简约风格的客厅设计,大落地窗", "科技感十足的未来城市夜景,霓虹灯光" ] for i, prompt in enumerate(prompts): try: result = generate_image(prompt) print(f"图片 {i+1} 生成成功: {result['data'][0]['url']}") except Exception as e: print(f"图片 {i+1} 生成失败: {e}")
成本对比分析
使用第三方聚合服务相比官方 API 有明显的成本优势:
| 项目 | 官方 API | 第三方聚合 | 节省 |
|---|---|---|---|
| 单张图片价格 | $0.03 | $0.02 | 33% |
| 1,000 张 | $30 | $20 | $10 |
| 10,000 张 | $300 | $200 | $100 |
| 100,000 张 | $3,000 | $2,000 | $1,000 |
此外,还有一些隐性成本的节省:无需翻墙工具的费用、无需管理多个 GCP 项目的时间成本、无需处理 429 错误的开发成本。
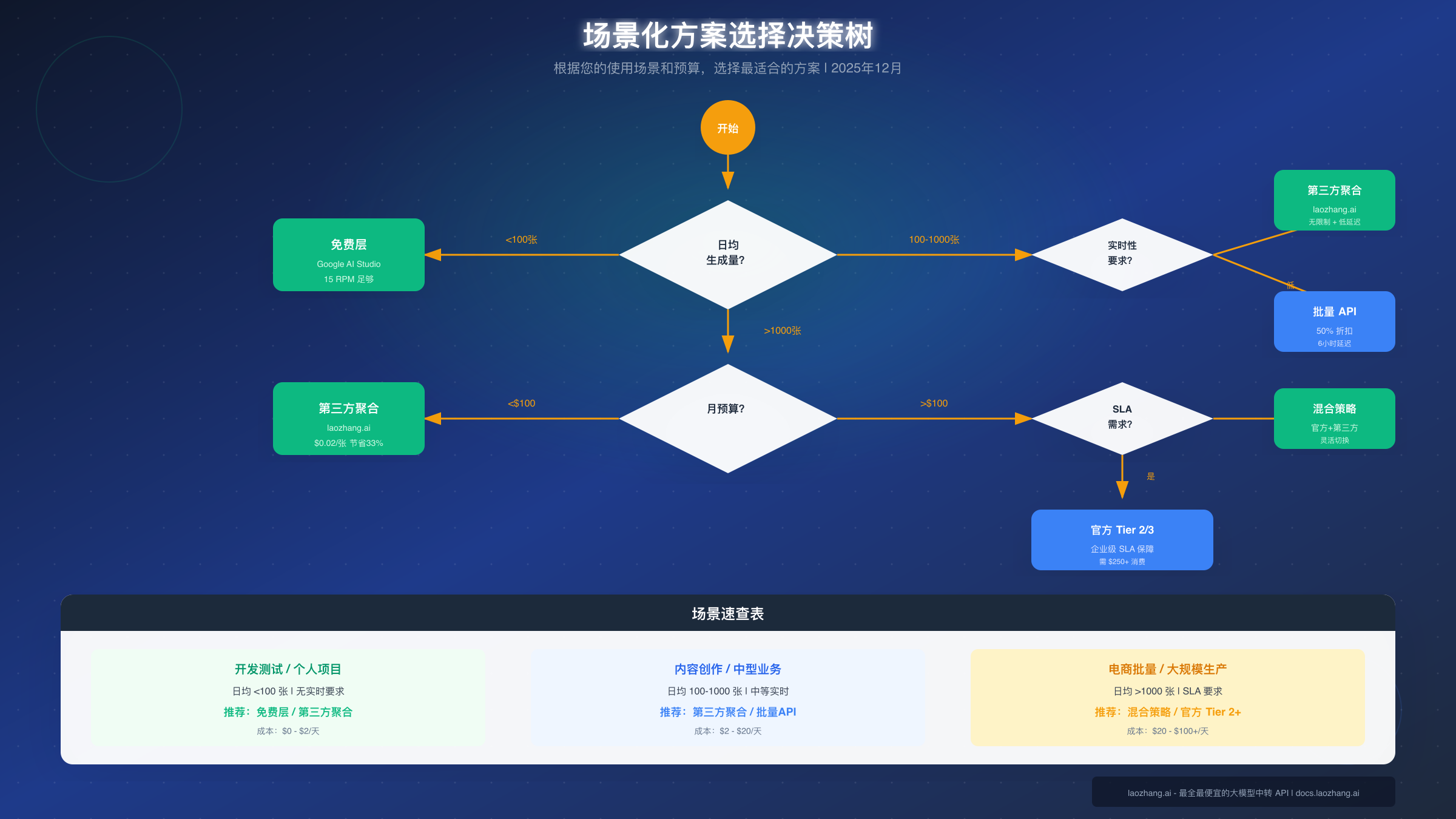
不同场景的最优方案选择
不同的使用场景对并发、成本、实时性的要求各不相同。以下是三种典型场景的推荐方案。
场景一:开发测试(日均 <100 张)
如果你正在开发原型或进行技术验证,Google 的免费层完全足够。15 RPM 意味着每分钟可以测试 15 次,每天 1,500 张的配额对于开发调试来说绑绑有余。建议:直接使用免费层,通过 Gemini API 国内访问方案 解决网络问题。
免费层的主要限制是不能用于生产环境。一旦你的应用上线,用户量增长后很快就会触发限速。因此,开发阶段就应该考虑好后续的升级路径。
场景二:内容创作(日均 100-1000 张)
自媒体、设计师、营销团队通常属于这个区间。需求特点是:数量中等、对质量要求高、有一定的实时性需求(比如根据用户反馈调整生成参数)。
推荐方案是使用第三方聚合服务。原因如下:官方 Tier 1 的 500 RPM 理论上可以满足,但 $0.03/张的价格加起来也是一笔不小的开支。第三方服务的 $0.02/张 可以节省 1/3 的成本。更重要的是,你不用担心偶发的高峰导致限速。
场景三:电商批量(日均 >1000 张)
电商平台、内容农场、素材网站的需求往往在数千甚至上万张。对于这类用户,成本优化和稳定性是首要考虑。
推荐采用混合策略:对于实时性要求高的(如用户上传图片后立即生成变体),使用第三方聚合服务;对于可以延迟处理的(如每日定时生成的产品图库),使用官方批量 API 享受 50% 折扣。如果有严格的 SLA 要求,可以考虑升级到官方 Tier 2/3,获得企业级支持。
代码实战:完整 Python 实现
本节提供两套完整的代码实现:官方 API 调用(带智能重试)和第三方聚合 API 调用(带批量处理)。
官方 API 调用(带指数退避重试)
pythonimport google.generativeai as genai import time import random from typing import Optional class GeminiImageGenerator: """ Gemini 3 Pro Image 官方 API 封装 包含指数退避重试和限速处理 """ def __init__(self, api_key: str): genai.configure(api_key=api_key) self.model = genai.GenerativeModel('gemini-3-pro-image-preview') self.max_retries = 5 self.base_delay = 1.0 def generate_with_retry( self, prompt: str, retry_count: int = 0 ) -> Optional[bytes]: """ 带重试的图像生成 使用指数退避策略处理 429 错误 """ try: response = self.model.generate_content( prompt, generation_config={ "response_mime_type": "image/png" } ) return response.data except Exception as e: error_str = str(e) # 429 Rate Limit 错误 if "429" in error_str or "quota" in error_str.lower(): if retry_count < self.max_retries: # 指数退避 + 随机抖动 delay = self.base_delay * (2 ** retry_count) jitter = random.uniform(0, delay * 0.1) wait_time = delay + jitter print(f"Rate limited, waiting {wait_time:.2f}s before retry {retry_count + 1}") time.sleep(wait_time) return self.generate_with_retry(prompt, retry_count + 1) else: raise Exception(f"Max retries exceeded: {e}") else: raise def batch_generate( self, prompts: list, delay_between: float = 4.5 # 保持在 15 RPM 以下 ) -> list: """ 批量生成图像 自动控制请求频率避免触发限速 """ results = [] for i, prompt in enumerate(prompts): try: result = self.generate_with_retry(prompt) results.append({"index": i, "success": True, "data": result}) print(f"Generated {i+1}/{len(prompts)}") except Exception as e: results.append({"index": i, "success": False, "error": str(e)}) print(f"Failed {i+1}/{len(prompts)}: {e}") # 除了最后一张,每张之间等待 if i < len(prompts) - 1: time.sleep(delay_between) return results # 使用示例 if __name__ == "__main__": generator = GeminiImageGenerator("YOUR_GOOGLE_API_KEY") # 单张生成 image_data = generator.generate_with_retry("一只橘猫在阳光下打盹") # 批量生成(自动控制频率) prompts = ["提示词1", "提示词2", "提示词3"] results = generator.batch_generate(prompts)
第三方聚合 API 调用(高并发版)
pythonimport aiohttp import asyncio from typing import List, Dict import time class LaozhangImageGenerator: """ laozhang.ai 聚合 API 封装 支持高并发异步请求 """ def __init__(self, api_key: str): self.api_key = api_key self.base_url = "https://api.laozhang.ai/v1" self.headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" } async def generate_single( self, session: aiohttp.ClientSession, prompt: str, index: int ) -> Dict: """ 异步生成单张图片 """ payload = { "model": "gemini-3-pro-image", "prompt": prompt, "size": "1024x1024", "n": 1 } try: async with session.post( f"{self.base_url}/images/generations", headers=self.headers, json=payload, timeout=aiohttp.ClientTimeout(total=120) ) as response: if response.status == 200: data = await response.json() return { "index": index, "success": True, "url": data["data"][0]["url"] } else: error_text = await response.text() return { "index": index, "success": False, "error": f"HTTP {response.status}: {error_text}" } except Exception as e: return { "index": index, "success": False, "error": str(e) } async def batch_generate( self, prompts: List[str], concurrency: int = 10 # 同时并发数 ) -> List[Dict]: """ 高并发批量生成 使用信号量控制并发数 """ semaphore = asyncio.Semaphore(concurrency) async def limited_generate(session, prompt, index): async with semaphore: return await self.generate_single(session, prompt, index) async with aiohttp.ClientSession() as session: tasks = [ limited_generate(session, prompt, i) for i, prompt in enumerate(prompts) ] results = await asyncio.gather(*tasks) return results # 使用示例 async def main(): generator = LaozhangImageGenerator("YOUR_LAOZHANG_API_KEY") # 准备 100 个提示词 prompts = [f"产品展示图 {i+1}:现代简约风格" for i in range(100)] start_time = time.time() results = await generator.batch_generate(prompts, concurrency=20) elapsed = time.time() - start_time success_count = sum(1 for r in results if r["success"]) print(f"完成 {success_count}/{len(prompts)} 张,耗时 {elapsed:.2f} 秒") print(f"平均每张 {elapsed/len(prompts):.2f} 秒") if __name__ == "__main__": asyncio.run(main())
这段代码展示了使用异步编程实现高并发请求。设置 concurrency=20 意味着同时有 20 个请求在飞行中。如果使用官方 API 的免费层(15 RPM),你需要将并发数降到 1 并添加 4 秒延迟;而使用第三方聚合服务,可以放心地使用高并发,系统会自动处理负载均衡。
常见问题解答
FAQ
Q1: 官方 API 的 429 错误如何处理?
429 错误表示你触发了速率限制。推荐的处理方式是指数退避重试:第一次重试等待 1 秒,第二次等待 2 秒,第三次等待 4 秒,以此类推。同时添加随机抖动(例如 ±10%)可以避免多个请求同时重试导致的"惊群效应"。如果持续出现 429 错误,考虑升级层级或使用第三方聚合服务。
Q2: 多项目轮询会被封号吗?
存在风险。Google 的反滥用系统能够检测异常的项目创建和使用模式。短时间内创建大量项目、使用相似的请求模式、同一 IP 频繁切换密钥等行为都可能触发检测。建议:如果必须使用多项目策略,控制在 3-5 个项目,使用不同 IP,添加随机延迟。更安全的选择是使用正规的第三方聚合服务。
Q3: 第三方服务的图像质量和官方一样吗?
是的,质量完全一致。第三方聚合服务只是代理转发请求,实际的图像生成仍然由 Google 的 Gemini 3 Pro Image 模型完成。你可以把它理解为"批发商"——从 Google 批量采购配额,然后分发给用户,但产品(图像)本身没有任何变化。
Q4: 如何监控 API 使用量和成本?
官方提供了 Google Cloud Console 的监控面板,可以查看请求量、错误率、延迟等指标。建议设置预算告警,在达到设定金额的 50%、80%、100% 时发送通知。对于第三方服务,通常在各自的控制台中有类似的功能。代码层面,可以自行实现请求计数和日志记录。
Q5: 批量 API 和实时 API 可以混用吗?
可以。混合策略是企业用户的常见做法:对于实时性要求高的场景(如用户交互时生成图像),使用实时 API 或第三方聚合服务;对于可以延迟处理的场景(如每晚批量生成第二天的素材),使用批量 API 享受 50% 折扣。这样可以在成本和用户体验之间取得平衡。
通过本文的详细介绍,相信你已经对 Gemini 3 Pro Image 的限速体系和突破策略有了全面了解。无论你是开发测试阶段的个人开发者,还是有大批量生成需求的企业用户,都能找到适合自己的方案。如果你希望快速实现高并发且控制成本,推荐直接使用第三方聚合服务,省去自建复杂架构的麻烦。更多技术细节可以参考 docs.laozhang.ai 的官方文档。