
谷歌在 2025 年 12 月 6-7 日对 Gemini API 免费层级进行了一次重大调整,将 Gemini 2.5 Flash 的每日请求配额从 250 次骤降至约 20 次,降幅高达 92%。这一变化在没有任何官方预告的情况下突然生效,导致大量开发者的应用突然收到 429 Too Many Requests 错误,引发了社区的强烈反响。本文将从官方数据出发,详细解析这次变化的前因后果,提供完整的模型限制对比表、429 错误诊断流程和生产级解决方案代码,同时为国内开发者提供专门的使用指南。
2025年12月:Gemini API 免费层级发生了什么?
如果你是在 2025 年 12 月 6 日之后开始遇到 Gemini API 的 429 错误,那么你并不是个例。根据 Google AI 开发者论坛 的讨论,数百名开发者在同一时间报告了类似的问题。这次变化的核心内容可以概括为以下几点:
Gemini 2.5 Flash 的每日请求配额从 250 次降至约 20-25 次,这意味着即使你的应用之前运行良好,现在每天只能发送约 20 个请求就会被限流。这对于依赖免费层级进行原型开发或个人项目的开发者来说是一个巨大的打击。与此同时,Gemini 2.5 Pro 的免费访问也受到了更严格的限制,虽然官方并未完全取消,但实际可用性大大降低。
Google 的 Logan Kilpatrick(AI Studio 和 Gemini API 产品负责人)在开发者论坛的回复中承认了这些变化,并解释说这是为了"将计算容量重新分配给新发布的模型"。他特别提到 Gemini 2.5 Pro 的免费层级"原本只打算开放一个周末",但由于各种原因意外延续了几个月。这一表态虽然解释了变化的原因,但也让开发者感到不满——毕竟在没有任何预警的情况下大幅削减配额,对于已经将应用集成到 Gemini API 的开发者来说是一个严重的信任问题。

从时间线来看,这次调整与 Gemini 3 系列模型的发布密切相关。Google 需要为新模型预留更多的计算资源,而免费层级用户消耗的算力显然成为了优化的对象。值得注意的是,Gemini Flash-Lite 模型的配额基本没有变化,仍然保持每天 1000 次请求的相对宽松限制,这为需要更高吞吐量但对模型能力要求不那么高的应用提供了一个替代方案。
各模型免费限制完整对比(2025年12月数据)
理解 Gemini API 的限流机制需要掌握三个关键维度:RPM(每分钟请求数)、TPM(每分钟 Token 数)和 RPD(每日请求数)。这三个限制相互独立,触发任何一个都会导致 429 错误。以下是 2025 年 12 月各模型的完整限制数据:
| 模型 | RPM | TPM | RPD | 上下文窗口 | 适用场景 |
|---|---|---|---|---|---|
| Gemini 2.5 Pro | 5 | 250,000 | 100 | 1M tokens | 复杂推理、代码生成 |
| Gemini 2.5 Flash | 10 | 250,000 | 20-25 | 1M tokens | 通用任务(限额后) |
| Gemini 2.5 Flash-Lite | 15 | 250,000 | 1,000 | 1M tokens | 高吞吐量场景 |
| Gemini 3 Pro Preview | 5 | 250,000 | 50 | 2M tokens | 最新能力测试 |
从这张表可以看出几个重要的信息。首先,所有免费层级模型都保持了 1M token(部分新模型为 2M)的完整上下文窗口,这是 Gemini 相比 ChatGPT 的一个显著优势,即使在免费层级也没有缩水。其次,Flash-Lite 的 1000 RPD 配额使其成为当前免费层级中最"能用"的模型,虽然能力不如 Flash,但对于简单的问答和翻译任务完全足够。
如果你对 Gemini API 的定价和更详细的配置感兴趣,可以参考我们之前的 Gemini 2.5 API 定价详解,那里有付费层级的完整信息。需要特别强调的是,这些数据可能随时变化,建议通过 Google AI Studio 查看你项目的实际配额,那里显示的是针对你账户的实时数据。
付费层级对比:如果你决定升级到付费层级,限制会有显著提升。Tier 1(需要绑定付费账户)的 RPM 通常是免费层级的 10 倍以上,RPD 限制也会大幅放宽或完全取消。具体的升级条件是累计消费超过 250 美元可升级到 Tier 2,超过 1000 美元可升级到 Tier 3,每个层级都有更高的配额。
限流机制详解:Project、API Key 与配额
很多开发者在遇到 429 错误时的第一反应是"再创建一个 API Key",但这通常不能解决问题。根据 Google 官方文档,Gemini API 的限流是基于 Project(项目) 而非单个 API Key 的。这意味着无论你在同一个项目下创建多少个 API Key,它们共享同一套配额。
具体来说,当你在 Google Cloud Console 或 AI Studio 中创建一个项目时,这个项目会被分配一个配额池。你在该项目下生成的所有 API Key 的请求都会计入这个池子。如果你想要更高的总配额,正确的做法是创建多个不同的 Google Cloud 项目,每个项目都有独立的配额。但需要注意的是,Google 可能会检测并限制明显的配额规避行为,大量创建项目可能导致账户被标记。
配额重置时间也是一个经常被误解的点。根据官方说明,每日请求配额(RPD)在太平洋时间(PT)午夜重置,而不是 UTC 或你的本地时区。这意味着如果你在北京时间下午遇到 RPD 限制,可能需要等到次日下午 3-4 点左右(取决于夏令时)才会重置。
如何查看当前配额使用情况:最直接的方式是登录 Google AI Studio,在 API Keys 页面可以看到每个项目的配额使用状态。此外,API 响应的 header 中通常也包含配额相关的信息,包括剩余请求数和重置时间,这对于在代码中实现智能限流非常有用。
429 错误完整诊断与解决方案
遇到 429 Too Many Requests 错误时,首先需要判断是哪种限制被触发了。错误信息通常会给出提示,但不同的限制类型需要不同的解决策略。以下是一个系统化的诊断流程:
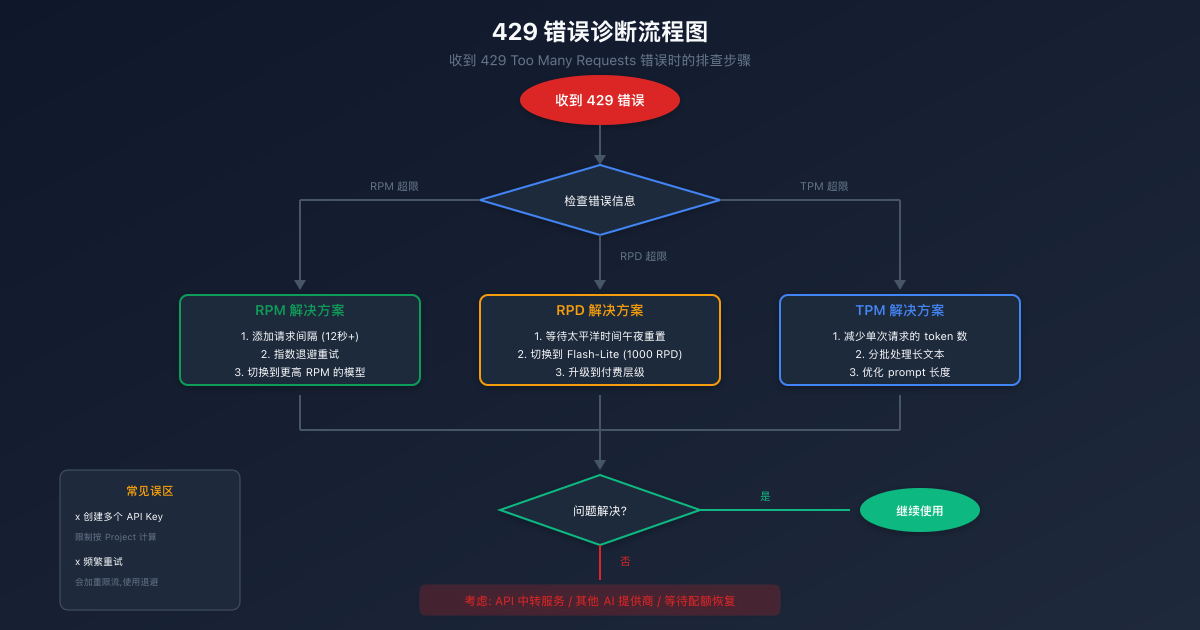
如果是 RPM(每分钟请求数)超限:这通常发生在短时间内发送了大量请求的情况下。对于免费层级的 5 RPM 限制,意味着连续调用时需要保持至少 12 秒的间隔。解决方案包括:在请求之间添加延时、实现指数退避重试机制,或者切换到 RPM 更高的 Flash-Lite 模型。
如果是 RPD(每日请求数)超限:这是 12 月调整后最常见的情况。当你收到这个错误时,唯一的免费解决方案是等待太平洋时间午夜配额重置,或者切换到 RPD 更高的 Flash-Lite 模型(1000 RPD)。如果你的应用确实需要更多请求,可能需要考虑升级到付费层级或使用 API 中转服务。
如果是 TPM(每分钟 Token 数)超限:这通常发生在处理长文本时。解决方案包括减少单次请求的输入文本长度、对长文档进行分批处理、优化 prompt 以减少不必要的 token 消耗。
下面是一个生产级的 Python 实现,包含指数退避和错误分类:
pythonimport time import random from typing import Optional, Dict, Any import google.generativeai as genai class GeminiClient: """带有智能重试和限流处理的 Gemini API 客户端""" def __init__(self, api_key: str, model: str = "gemini-2.5-flash"): genai.configure(api_key=api_key) self.model = genai.GenerativeModel(model) self.base_delay = 1.0 self.max_retries = 5 self.max_delay = 60.0 def generate(self, prompt: str, **kwargs) -> Optional[str]: """发送请求,自动处理限流和重试""" for attempt in range(self.max_retries): try: response = self.model.generate_content(prompt, **kwargs) return response.text except Exception as e: error_msg = str(e).lower() # 判断错误类型 if "429" in error_msg or "resource_exhausted" in error_msg: if "daily" in error_msg or "rpd" in error_msg: print(f"每日配额已用尽,建议等待或切换模型") return None # RPM/TPM 限制,可以重试 delay = self._calculate_delay(attempt) print(f"请求限流,{delay:.1f}秒后重试... (尝试 {attempt + 1}/{self.max_retries})") time.sleep(delay) continue elif "401" in error_msg or "403" in error_msg: print(f"认证错误,请检查 API Key") return None else: print(f"未知错误: {e}") if attempt < self.max_retries - 1: time.sleep(self._calculate_delay(attempt)) continue return None print("重试次数已用尽") return None def _calculate_delay(self, attempt: int) -> float: """计算指数退避延时,带随机抖动""" delay = self.base_delay * (2 ** attempt) jitter = random.uniform(0, delay * 0.1) return min(delay + jitter, self.max_delay) client = GeminiClient(api_key="your-api-key") result = client.generate("解释什么是机器学习") if result: print(result)
对于频繁遇到限流的应用,可以考虑使用 laozhang.ai 等 API 中转服务作为备用方案。这类服务通常聚合了多个 API 提供商的配额,可以在主 API 限流时自动切换,确保应用的可用性。关于更多 429 错误的解决方案,可以参考我们之前的文章了解更多处理技巧。
免费层级够用吗?升级决策指南
是否需要升级到付费层级取决于你的具体使用场景和需求量。以下是一个简单的决策框架:
场景一:学习和实验。如果你只是在学习 AI 开发或进行小规模实验,免费层级的 Flash-Lite(1000 RPD)通常足够。即使是 Flash 的 20 RPD 限制,对于每天调试几十次 prompt 的场景也基本够用。建议充分利用 AI Studio 的 Playground 进行初期测试,那里不消耗 API 配额。
场景二:原型开发。如果你正在开发一个需要频繁测试的应用原型,20 RPD 可能很快就会用完。这时候有几个选择:使用 Flash-Lite 替代 Flash(能力会有所下降)、创建多个项目分散请求、或者升级到 Tier 1。考虑到 Gemini API 的价格相对便宜(Flash 输入约 $0.075/百万 token),升级通常是更省心的选择。
场景三:生产环境。如果你的应用已经在服务真实用户,免费层级几乎肯定是不够的。即使是小规模应用,100 个用户每人每天发送 1 个请求就会超过 RPD 限制。生产环境必须使用付费层级,并且建议实现完善的错误处理和备用方案。对于预算有限但需要稳定服务的小团队,也可以考虑使用 laozhang.ai 等按量付费的 API 中转服务,可以更灵活地控制成本。
成本估算示例:假设你的应用每天需要处理 1000 个请求,每个请求平均消耗 500 输入 token 和 1000 输出 token。使用 Gemini 2.5 Flash,每天的成本约为:
- 输入:1000 × 500 / 1,000,000 × $0.075 = $0.0375
- 输出:1000 × 1000 / 1,000,000 × $0.3 = $0.3
- 每天总计:约 $0.34,每月约 $10
相比之下,使用 OpenAI 的 GPT-4 处理同样的量级,成本会高出数倍。如果你对各大 API 的定价比较感兴趣,可以参考我们的 ChatGPT API 定价指南。
国内开发者使用指南
对于国内开发者来说,使用 Gemini API 面临着一些特殊的挑战,主要包括网络访问、支付和账户问题。这里提供一些经过验证的解决方案。
网络访问问题是第一道门槛。Gemini API 的端点位于 generativelanguage.googleapis.com,这个域名在国内无法直接访问。常见的解决方案包括:使用代理服务器、通过云服务器中转请求、或者使用支持 Gemini API 的国内中转服务。对于生产环境,建议使用稳定的企业级代理或中转服务,避免因网络问题导致服务不稳定。
支付问题同样棘手。Google Cloud 的付费账户需要绑定信用卡,而且不接受中国大陆发行的银联卡。可行的解决方案包括:使用 Visa/Mastercard 双币卡或外币卡、通过虚拟信用卡服务、或者使用支持人民币支付的 API 中转服务。laozhang.ai 提供支持支付宝付款的 Gemini API 中转,无需信用卡即可使用,注册还能获得免费额度用于测试。
账户注册也需要注意。注册 Google AI Studio 账户需要 Google 账号,部分功能可能需要验证手机号。如果你还没有可用的 Google 账号,可以考虑使用海外手机号注册,或者直接使用提供完整账户服务的中转平台。
对于不想折腾网络和支付问题的开发者,国内也有一些优秀的替代方案值得考虑:DeepSeek 提供了接近 GPT-4 水平的能力,API 价格非常有竞争力,且原生支持中文;通义千问 是阿里巴巴的大模型服务,接入阿里云生态非常方便;智谱 GLM 也提供了不错的 API 服务。如果你对 Claude API 的国内使用感兴趣,可以参考我们的 Claude API 国内使用指南。
主流 AI API 对比:Gemini vs 竞品
在考虑是否继续使用 Gemini API 或迁移到其他平台时,了解各家 API 的优劣势是必要的。以下是主流 AI API 的综合对比:
| 特性 | Gemini API | OpenAI API | Claude API | DeepSeek |
|---|---|---|---|---|
| 免费层级 | 有(限制严格) | 无 | 有(限制严格) | 有 |
| 上下文窗口 | 1M-2M tokens | 128K tokens | 200K tokens | 128K tokens |
| 价格(输入) | $0.075/M | $2.5/M | $3/M | $0.14/M |
| 价格(输出) | $0.3/M | $10/M | $15/M | $0.28/M |
| 中国可访问 | 需代理 | 需代理 | 需代理 | 原生支持 |
| 多模态能力 | 强 | 强 | 中 | 中 |
| 代码能力 | 强 | 强 | 最强 | 强 |
从这个对比可以看出,Gemini API 的核心优势在于超大的上下文窗口和相对便宜的价格。即使免费层级受限,其付费价格仍然是主流 API 中最低的之一。如果你的应用需要处理长文档或进行复杂的多轮对话,Gemini 的 1M token 上下文是一个显著优势。
如果因为限流问题考虑迁移,建议先评估迁移成本。Gemini API 的调用方式与 OpenAI 不完全兼容,但差异不大,通常半天到一天的工作量可以完成基本迁移。也可以考虑使用 laozhang.ai 这类聚合多家 API 的中转服务,它们通常提供统一的 OpenAI 兼容接口,可以轻松在不同模型间切换。
总结与下一步行动
Gemini API 2025 年 12 月的免费层级调整确实给很多开发者带来了困扰,但了解变化的原因和应对策略后,这个问题是可以解决的。以下是本文的核心要点和建议的行动步骤:
核心要点回顾:
- Flash 模型的 RPD 从 250 降至约 20,降幅 92%
- 限流是基于 Project 而非 API Key,创建多个 Key 不能解决问题
- Flash-Lite 仍保持 1000 RPD,是当前免费层级的最佳选择
- 配额在太平洋时间午夜重置
建议的下一步行动:
- 短期:如果遇到 429 错误,先切换到 Flash-Lite 模型缓解压力
- 中期:实现指数退避重试机制,提高应用的健壮性
- 长期:根据实际需求评估是否升级付费层级或使用中转服务
如果你还有其他关于 Gemini API 的问题,欢迎查阅我们的 Gemini API 国内访问完整指南,那里有更多关于网络配置和使用技巧的详细信息。
常见问题(FAQ)
Q1: 为什么我的请求数明明没用完,还是收到 429 错误?
429 错误可能由 RPM、TPM 或 RPD 任一限制触发。即使你的每日配额还有剩余,如果在短时间内发送了太多请求,也会触发 RPM 限制。检查错误信息中的具体说明,或在请求间添加适当的延时。
Q2: 创建多个 API Key 能增加配额吗?
不能。配额是按 Project(项目)计算的,同一个项目下的所有 API Key 共享同一个配额池。如果需要更高配额,可以考虑创建多个 Google Cloud 项目,但要注意避免被检测为配额规避行为。
Q3: 为什么 Google 要大幅削减免费配额?
根据 Google 官方的解释,这是为了将计算资源重新分配给新发布的 Gemini 3 等模型。免费层级用户消耗了大量算力,影响了付费用户和新模型的服务质量。
Q4: Flash 和 Flash-Lite 有什么区别?
Flash-Lite 是 Flash 的轻量版,在模型能力上有所缩减,但推理速度更快、成本更低。对于简单的问答、翻译、摘要等任务,Flash-Lite 完全够用,且免费层级有 1000 RPD 的宽松配额。
Q5: 配额什么时候重置?
每日请求配额(RPD)在太平洋时间(PT)午夜重置。对于北京时间来说,大约是下午 3-4 点(取决于夏令时)。每分钟配额(RPM)则是滚动重置。
Q6: 国内用户如何使用 Gemini API?
需要解决网络访问和支付两个问题。网络可以通过代理或中转服务解决,支付可以使用双币信用卡或选择支持支付宝的中转服务如 laozhang.ai。
Q7: 免费层级的数据会被用于训练吗?
根据 Google 的隐私政策,免费层级的请求数据可能被用于改进产品。如果你对数据隐私有顾虑,建议升级到付费层级,付费用户的数据不会被用于训练。
Q8: 429 错误会永久封禁我的账户吗?
不会。429 是临时性的限流错误,不是封禁。等待配额重置或降低请求频率即可恢复正常。但如果你频繁进行可能被视为滥用的行为,可能会触发更严格的限制。
Q9: 有什么方法可以监控配额使用情况?
可以在 Google AI Studio 的 API Keys 页面查看配额使用状态。此外,API 响应的 header 中通常包含剩余配额信息,可以在代码中实现监控和预警。
Q10: 升级到付费层级需要什么条件?
需要为你的 Google Cloud 项目绑定有效的付费账户(信用卡)。绑定后自动进入 Tier 1,累计消费超过 250 美元可申请升级到 Tier 2,超过 1000 美元可升级到 Tier 3。