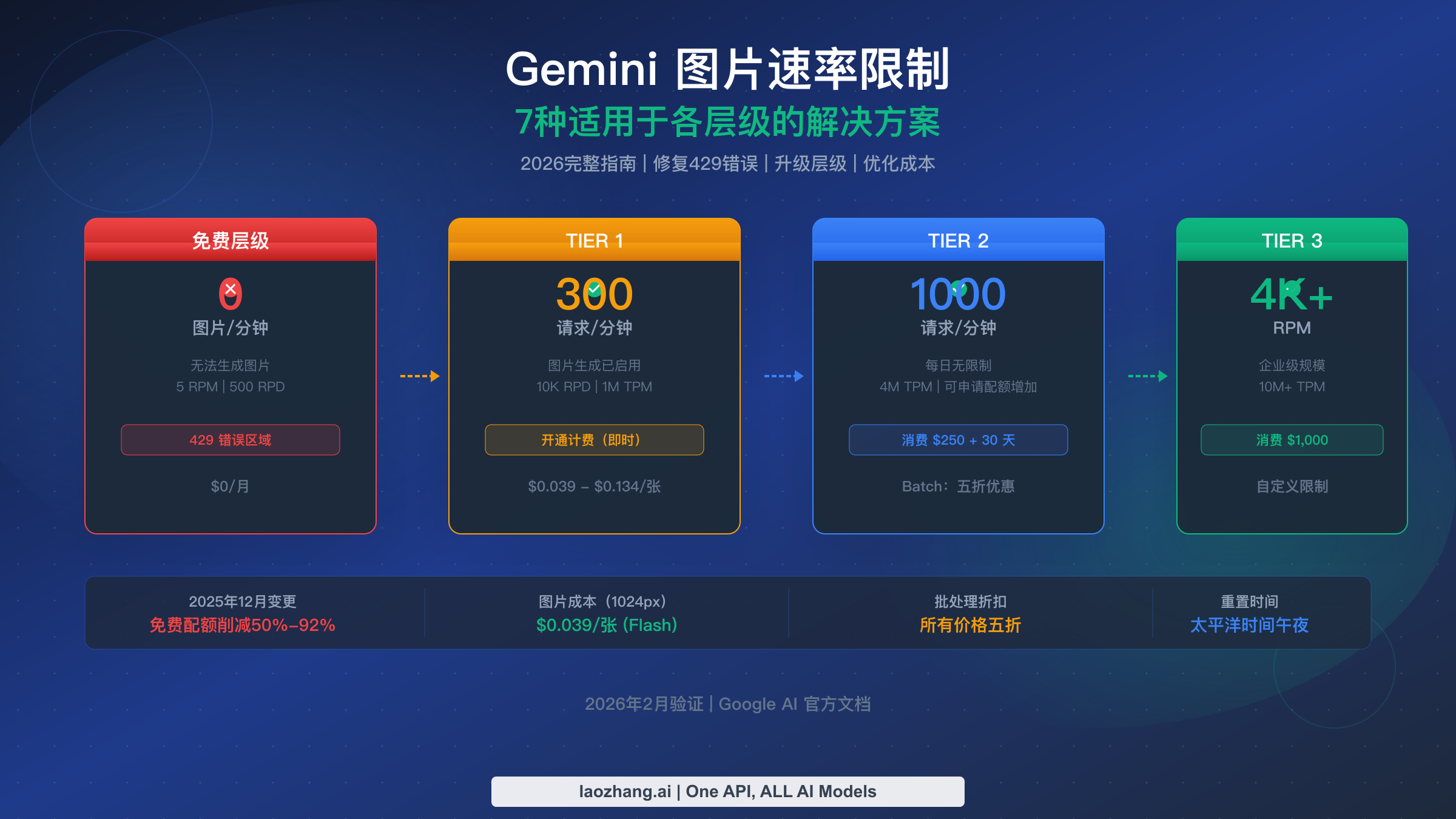
先说结论:Gemini 图片接口报 429 RESOURCE_EXHAUSTED,最常见的原因不是“你手速太快”,而是项目根本还没拿到可用的付费图片权限,或者项目级配额窗口已经被打满。截至 2026 年 3 月 15 日,Gemini 当前图片预览模型仍走付费路径,每日请求配额按太平洋时间午夜重置,官方速率限制页面也仍把项目计费历史作为 Free、Tier 1、Tier 2、Tier 3 的分界线。
这也是为什么“把重试次数调大一点”并不总是正确答案。如果你眼前的项目图片配额实际上等于 0,指数退避只会把失败延后,并不会让请求突然成功。只有先区分清楚你遇到的是计费没接对、分钟级配额被打满、日配额见底,还是其实是 503 过载 / 400 地区限制,后面的解决动作才会有意义。
要点速览
Gemini 图片 API 会返回 429 RESOURCE_EXHAUSTED,但这个 429 并不总意味着“暂时打太猛了”。很多情况下,真正的问题是“当前项目并没有可用的付费图片权限”。当前官方文档明确写着:配额按项目而不是按 API Key 执行;RPD 会在太平洋时间午夜重置;Batch API 有独立配额池且默认享受五折;Tier 2 和 Tier 3 仍然依赖累计消费和 30 天计费时钟。最快的操作顺序是:先核对计费是否挂在正确项目,再读错误元数据或控制台配额页,最后再决定是退避、等待重置、改用 Batch,还是走其他路由。
| 症状 | 常见根因 | 最快处理动作 | 一般恢复时间 |
|---|---|---|---|
图片请求一发就失败,配额看起来像 0 或根本不可用 | 当前项目还没有获得该模型的付费图片权限 | 把计费接到正确项目,再刷新速率限制页面 | 通常几分钟,少数账户会拖到数小时 |
| 只有高并发或突发时才报 429 | RPM、TPM 或 IPM 窗口被打满 | 增加带抖动的指数退避,同时降低瞬时并发 | 几秒到几分钟 |
| 跑了一整天后才开始报 429 | RPD 被耗尽 | 等太平洋时间午夜重置,或把非实时任务移到 Batch API | 直到重置 |
| 已经开通计费,还是持续 429 | 项目弄错、计费还在传播、层级仍然太低 | 核对项目 ID、账单状态、模型对应配额页 | 传播问题通常几分钟,真正层级不足则更久 |
| 实际返回的是 503 或地区相关 400 | 这不是同一种配额问题 | 503 短暂重试;400 先补计费或换支持地区 | 取决于具体错误类型 |
故障排查:按症状匹配最快修复路径

真正排查时,先不要急着套用“我以前给文本模型加过重试”的经验。图片工作负载比文本请求更容易同时碰到 IPM、RPD 和计费权限三类问题,所以第一步不是写代码,而是把自己遇到的故障归类。
如果你现在就需要把 429 先止住,先问一个最关键的问题:发请求的 API Key 背后,到底是不是那个已经开通计费的 Google Cloud 项目?官方计费页说,开通计费后 billable usage 会立即生效;但真实世界里的 GitHub issue 和论坛帖说明,很多人是在 A 项目开了计费,却一直拿 B 项目的老 Key 测试。只要你在配额页里看到图片能力仍然不可用,继续重试就没有意义。
如果计费已经打开但还是报错,下一步就不是“继续等”,而是分辨到底是哪一个桶先满。高峰期一波流量冲上去就挂,通常更像 RPM、TPM 或 IPM;跑了一整天、晚上突然全挂,更像 RPD;请求量其实不大但还是报错,则往往与计费刚传播、项目挂错、模型仍在更紧的 preview 限额中有关。这个时候,错误里的 quota_limit、控制台里的模型限额页、以及你日志中的项目 ID,比一切“经验主义”都更重要。
如果你是在规划一个新项目,最好从第一天就按“配额现实”来设计:默认开通计费;每次 429 都把项目 ID、模型名和 quota_limit 打进日志;非实时图片任务直接送去 Batch API;团队内部统一把官方 rate limits 页面 作为唯一可信的实时配额看板。这样做的成本很低,但能显著减少“Gemini 图片怎么又不工作了”的运维时间。
2026 年 Gemini 图片限额到底怎么生效

Gemini 图片 API 的限额不是一个数字,而是四个独立维度同时生效:RPM、RPD、TPM、IPM。很多人只盯着 RPM,看起来每分钟请求并不多,就误以为自己不可能被限流;但图片工作负载里真正更容易踩到的是 IPM、RPD 和“该项目根本没有可用图片权限”。
RPM(每分钟请求数) 决定 60 秒滚动窗口内能发多少次调用。对图片场景来说,它最常在用户集中点击、任务队列瞬间回放、或者失败后同步重试时被打满。更完整的模型级 RPM 表,建议直接同时看官方页面和我们的 Gemini API 速率限制详解。
RPD(每日请求数) 是最容易制造“上午还行,晚上全挂”的那个限制。当前官方文档仍写明,RPD 按太平洋时间午夜重置。也正因为如此,Gemini 图片限制何时重置 这类问题在真实搜索里始终很高频。
TPM(每分钟 Token 数) 往往不是排查时最先看的,但它会在长提示词、多参考图、或图文混合调用里突然成为隐形瓶颈。很多开发者明明“每分钟只发了几个请求”,却还是被挡住,常见原因就是 TPM 比自己想象中更早见顶。
IPM(每分钟图片数) 是图片工作负载最核心、但也最容易被忽视的维度。它只对能出图的模型生效,这也是为什么很多团队从文本 Gemini 切到图片模型时,会突然发现原本熟悉的配额习惯不再适用。对实操最关键的一句结论是:如果当前项目还没有可用的付费图片能力,你的有效图片配额就是不可用,无论文本模型配额看起来有多健康。
2025 年 12 月 7 日之后,Firebase 的配额文档明确提醒开发者:Gemini Developer API 配额被调整后,应用可能会开始返回 429 RESOURCE_EXHAUSTED。这也是为什么很多旧教程、旧 Reddit 贴、旧截图会明显误导今天的排查动作。
| 计费和层级变化真正影响什么 | 当前官方结论 |
|---|---|
| 配额归属 | 配额按项目执行,不按 API Key 执行 |
| Tier 1 入口 | 给正确项目挂上计费即可进入 billable usage |
| Tier 2 条件 | 累计消费超过 250 美元,且成功付费满 30 天 |
| Tier 3 条件 | 累计消费超过 1000 美元,且成功付费满 30 天 |
| 每日重置时间 | RPD 在太平洋时间午夜重置 |
| Batch 路径 | 拥有独立批处理配额池,价格默认五折,最长 24 小时完成 |
最需要纠正的误区只有一句:多个 API Key 不会给同一个项目叠出多份配额。如果你只是把同一项目下的 Key 轮着换,看到的仍然是同一个配额池。只有换项目、升层级、改用 Batch、或者走独立中继,才是真正意义上的“扩容”。
5 分钟修复 429:指数退避怎么写
当你已经确认项目本身具备可用图片权限,429 的第一段代码级修复仍然是指数退避。Google 的 troubleshooting 页面对 429 的官方建议依旧是“稍后重试”或“申请更多配额”,而在生产环境里,最稳妥的“稍后重试”实现方式,就是递增延迟 + 随机抖动。
原理很简单:请求返回 429 后,不要立刻再打一次,而是先等待一个基础延迟;如果还是失败,再把等待时间翻倍;每次再叠加一点随机抖动,避免多台 worker 在同一秒一起回放,反而把限流放大。对于“分钟级配额偶尔碰顶”的场景,这通常就是最划算、最先应该加的保护层。
下面是可以直接放进图片调用客户端里的 Python 版本:
pythonimport time import random from google import generativeai as genai def generate_image_with_retry(prompt, model_name="gemini-3.1-flash-image-preview", max_retries=5, base_delay=1.0): """带指数退避的图片生成调用。""" model = genai.GenerativeModel(model_name) for attempt in range(max_retries): try: response = model.generate_content(prompt) return response except Exception as e: error_str = str(e) if "429" in error_str or "RESOURCE_EXHAUSTED" in error_str: if attempt == max_retries - 1: raise RuntimeError( f"Rate limit exceeded after {max_retries} retries." ) from e delay = base_delay * (2 ** attempt) jitter = delay * 0.25 * (random.random() - 0.5) wait_time = delay + jitter print(f"Rate limited. Waiting {wait_time:.1f}s before retry...") time.sleep(wait_time) else: raise
如果你用的是 JavaScript / TypeScript,逻辑完全一样:
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); async function generateImageWithRetry(prompt, { modelName = "gemini-3.1-flash-image-preview", maxRetries = 5, baseDelay = 1000 } = {}) { const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY); const model = genAI.getGenerativeModel({ model: modelName }); for (let attempt = 0; attempt < maxRetries; attempt++) { try { const result = await model.generateContent(prompt); return result.response; } catch (error) { const isRateLimit = error.message?.includes("429") || error.message?.includes("RESOURCE_EXHAUSTED"); if (isRateLimit && attempt < maxRetries - 1) { const delay = baseDelay * Math.pow(2, attempt); const jitter = delay * 0.25 * (Math.random() - 0.5); await new Promise(resolve => setTimeout(resolve, delay + jitter)); } else { throw error; } } } }
但也要清楚它的边界:指数退避只能解决“窗口暂时满了”的问题,不能解决“你本来就没有权限”或“你的层级根本扛不住当前负载”。如果你的问题是日配额见底、项目仍未接入正确计费、或生产流量已稳定超过现有层级,退避只会增加延迟,不会创造新容量。
如何升级 Gemini API 层级
长期看,层级升级仍然是最直接的官方扩容路径。Gemini 现在仍按累计消费和付费时长,把项目从 Free 自动推进到 Tier 1、Tier 2、Tier 3。对多数读者来说,最重要的不是背完整层级体系,而是弄明白:你今天需要的是“先开通计费”,还是“这个月得尽快爬到更高层级”。
Free -> Tier 1 依然是影响最大的那一步。官方 billing 页面明确写着,开通计费后 billable usage 会立即启用;rate limits 页面也把它视作从免费态进入 Tier 1 的入口。对图片开发者来说,这一步的现实意义就是:如果项目目前还表现得像“没有可用图片权限”,就先别研究更复杂的架构。
最快的路径一般还是从 AI Studio 走:登录 aistudio.google.com,进入 Usage and Billing,挂上付款方式。官方同时说明,400 和 500 这类失败请求虽然不计费,但仍会消耗配额。这一点很关键,因为它说明“尽早接计费”并没有很多人想象中那么危险,但无效重试仍然会白白烧掉额度。
已开通计费却仍然报 429 时,先跑一遍最短检查清单:
- 日志里打印的项目 ID,是否就是当前挂账单的项目。
- 该项目账单是否处于 active 状态,而不是待验证。
- 控制台的模型配额页里,这个图片模型是否已经显示可用的 billable entitlement。
- 返回的错误是否仍然是 429,而不是 503 过载或地区相关 400。
Tier 1 -> Tier 2 的条件仍然是:累计消费 超过 250 美元,且成功付费 满 30 天。Tier 2 -> Tier 3 则是累计消费 超过 1000 美元,外加同样的 30 天时钟。换句话说,如果你这周就要把生产流量顶上去,Tier 2 和 Tier 3 不是唯一依赖对象,因为它们天然带有时间延迟。
还有一个经常被忽视的事实:层级按项目算,不按账号算。 这既是困惑来源,也是后面多项目策略的基础。同一个组织里,如果你为了扩容而开了多个项目,每个项目都要自己走消费与时钟,不会自动共享层级。
Gemini 图片生成现在到底多少钱
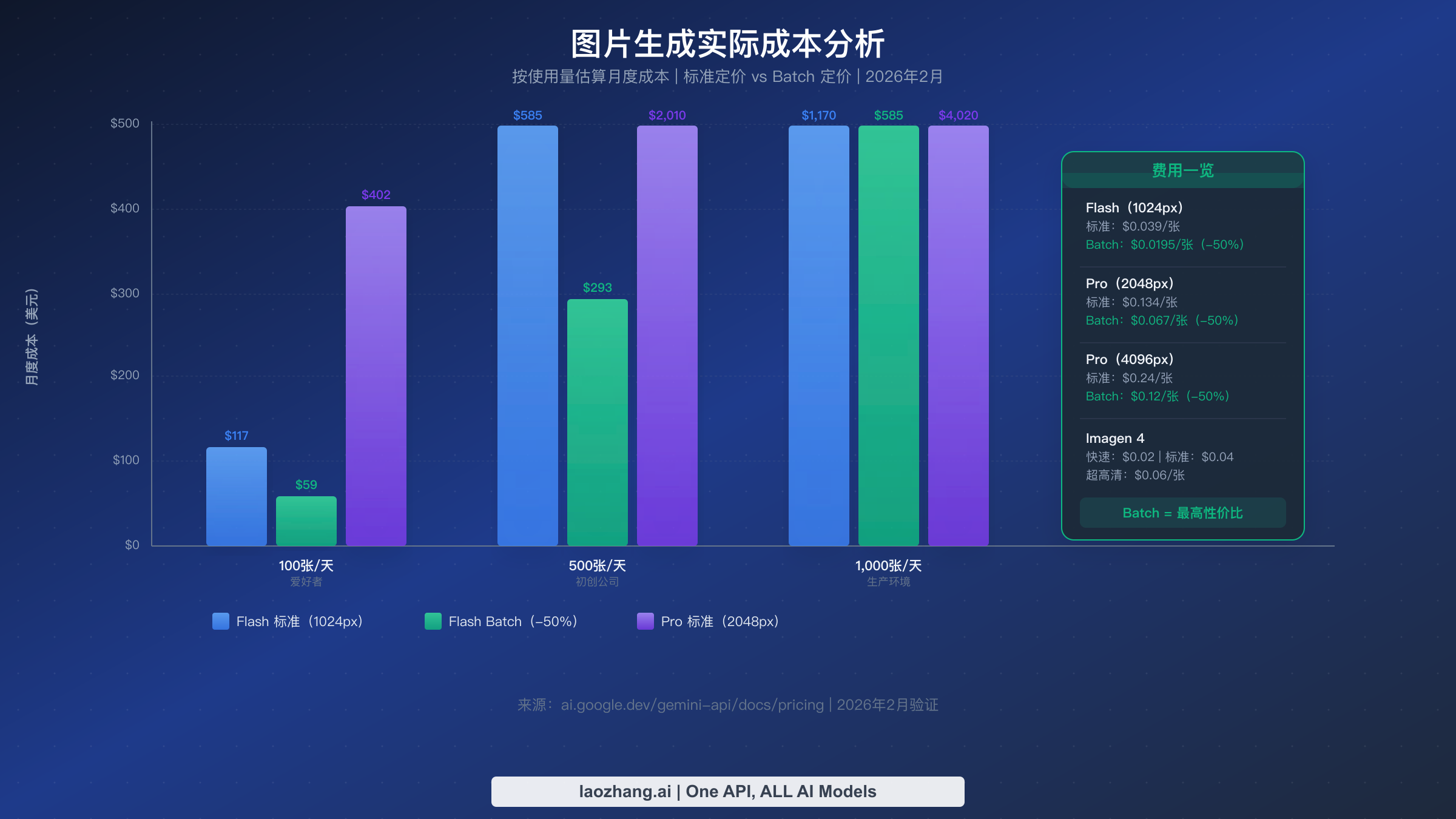
对很多排查 429 的团队来说,真正的问题并不只是“怎么恢复”,而是“恢复之后到底要花多少钱”。这也是为什么定价页必须和排障文档一起看。下面所有价格,都基于 2026 年 3 月 15 日 时官方 pricing 页面重新核对后的数字。
对大多数目前遇到 Gemini 图片 429 的读者来说,实际上的付费入门模型通常是 Gemini 3.1 Flash Image Preview。官方定价把它换算为:512 输出约 $0.045,1024 输出约 $0.067,2048 输出约 $0.101,4096 输出约 $0.151。如果你需要更高质量的出图,Gemini 3 Pro Image Preview 当前列出的价格是:1024 和 2048 输出每张 $0.134,4096 输出每张 $0.24。
官方 Batch API 仍然是最值得优先考虑的降本手段:默认五折,最长24 小时完成,而且使用独立配额池。只要你的任务不是“用户点一下就必须立刻返图”,Batch 就不仅是降价工具,也是缓解 429 的吞吐工具。
| 使用场景 | 月图片量 | Flash 1024 标准 | Flash 1024 Batch | Pro 2K 标准 | Pro 2K Batch |
|---|---|---|---|---|---|
| 爱好者 | 3,000(100/天) | $201 | $100.50 | $402 | $201 |
| 初创团队 | 15,000(500/天) | $1,005 | $502.50 | $2,010 | $1,005 |
| 生产环境 | 30,000(1,000/天) | $2,010 | $1,005 | $4,020 | $2,010 |
| 大规模业务 | 300,000(10,000/天) | $20,100 | $10,050 | $40,200 | $20,100 |
把这个表换成一句最容易拿去做决策的话就是:如果你能接受异步,Batch 几乎总是同时缓解成本和限流压力。 以 Flash 1024 为例,单张成本从 $0.067 降到 $0.0335;如果每天跑 1,000 张图,月成本就从 $2,010 下降到 $1,005。
层级门槛也要放回成本框架里一起看。Tier 2 需要累计消费超过 $250。按照当前价格粗略换算,这大致相当于 3,731 张 Flash 1024 图片,或 1,865 张 Pro 2K 图片。当然,真实项目里这笔消费不一定全来自 Gemini 图片,也可能来自同一 Google Cloud 账单下的其他服务。
如何把图片吞吐量再往上拉
当你已经加好了退避,也确认了项目计费没挂错,如果吞吐量还是不够,就要开始用更系统化的办法扩容。这里真正有用的,不是“再多试几次”,而是把不同类型的流量拆开处理。
多项目分发是最直接的吞吐量倍增器,因为配额按项目执行。你可以维护一个项目池,把请求按轮询或权重打到不同项目。下面这个思路在英文源文里也保留了:
pythonimport itertools from google import generativeai as genai class MultiProjectImageGenerator: def __init__(self, api_keys: list[str], model_name: str = "gemini-3.1-flash-image-preview"): self.clients = [] for key in api_keys: genai.configure(api_key=key) self.clients.append(genai.GenerativeModel(model_name)) self.key_cycle = itertools.cycle(range(len(self.clients))) def generate(self, prompt: str): project_idx = next(self.key_cycle) client = self.clients[project_idx] try: return client.generate_content(prompt) except Exception as e: if "429" in str(e): next_idx = next(self.key_cycle) return self.clients[next_idx].generate_content(prompt) raise
要注意的是,多项目分发并不是“零成本扩容”。如果你要把三个项目都推到 Tier 2,就意味着每个项目都要自己满足 250 美元 + 30 天 的门槛。但对真正有业务量的团队来说,这通常仍然比持续停机更便宜。
Batch API 分流后台任务是另一条非常稳的路。官方文档当前给出的约束是:最长 24 小时完成、默认五折、100 个并发 jobs、每个输入文件最多 2 GB、总批处理存储 20 GB。这些条件决定了它非常适合:批量回填图库、生成缩略图、夜间跑素材、定时生产内容资产。
除此之外,下面三种手段也值得同时部署:
- 请求队列:让调用先进入队列,再按你的层级能力平滑发出,避免尖峰时刻把项目直接打穿。
- 结果缓存:如果你的图片生成存在大量重复 prompt 或模板化需求,一个简单的 Redis / CDN 层就能显著降低调用总量。
- 监控配额元数据:每次 429 都记录项目 ID、模型名、错误码和
quota_limit,再配合控制台做 70% / 90% 阈值提醒。这样你会知道自己到底缺的是更高层级、更多项目、还是更合理的任务拆分。
什么时候该考虑第三方中继,以及下一步怎么做
并不是所有团队都适合和官方层级体系硬耗。有些场景下,第三方中继或聚合 API 会更务实,特别是你明知道自己未来会跨模型、跨项目、跨客户地跑。
像 laozhang.ai 这种聚合型 API 网关,价值不在于“神奇地消灭所有限流”,而在于它把多模型接入、统一计费、切换路由这件事做成了一个更简单的运维层。如果你现在最缺的是快速上线 MVP、减少多项目账单管理负担、或者把多种图片模型接入成本压低,它会比一味等官方层级时钟更实用。
当然,什么时候仍然应该坚持官方 API 也很清楚:你需要严格合规、数据驻留、与 Vertex AI / Cloud Functions / BigQuery 深度集成、或者你本来就运行在 Google Cloud 生态里。这些情况下,官方 API 仍然是更自然、更长期的主路径。
实际决策可以按时间线拆成三档:
- 今天就要恢复可用:先确认计费挂在正确项目,再加指数退避。
- 这个月内要把成本和吞吐压住:尽快往 Tier 2 走,同时把非实时任务迁到 Batch API。
- 准备长期生产化:把限流当成架构问题处理,统一日志、监控、队列、缓存、项目池和备用路由,而不是把它当成偶发 bug。
常见问题 FAQ
Gemini 免费层每天到底能出多少张图?
对今天的开发者来说,最实用的答案就是:在项目没有获得可用付费图片权限之前,可以视为没有可靠的 API 出图能力。 实时配额表会按模型变化,但当前图片预览路线本质上是付费路径,所以第一步是接计费,而不是盲目调重试。
Free 升到 Tier 1 一般要多久?
大多数项目是几分钟内生效。官方 billing 文档写的是立即启用 billable usage,但新账户、支付方式验证、项目切换错误,都会把这件事拖久。如果一小时后还不对,先核对项目和账单,而不是先怀疑 SDK。
多建几个 API Key 能不能提高限额?
不能。限额按项目执行,不按 Key 执行。同一项目下的十个 Key,看到的仍然是同一个配额池。想增容,就得升层级、换项目、上 Batch 或换路由。
Gemini 配额什么时候重置?
分钟级窗口会自己滚动恢复;RPD 这种日配额,官方当前仍写明按太平洋时间午夜重置。如果你的任务可以等,围绕这个时间点安排大批量作业,是最简单的无代码优化。
Batch API 值得用吗?
值得,只要你的任务不要求立刻返图。官方当前仍给出五折和最长 24 小时完成的承诺,而且它走独立批处理配额池。对缩略图、素材库回填、后台生产任务来说,Batch 几乎是官方体系里性价比最高的方案之一。
为什么我明明已经开通计费,还是一直报 429?
因为“已经开通计费”这句话常常没有你想象中那么确定。最常见的原因还是:项目挂错、计费仍在传播、当前层级对流量仍然太低、或者你其实在排查 503 / 400。先看项目 ID、模型配额页和原始错误元数据,再决定要不要改架构。
我是先申请提额,还是先做 workaround?
如果你这周就要恢复稳定,先做 workaround。申请提额适合已经稳定、可预测的生产负载,但它不是最快的救火路径。退避、Batch、项目分流、缓存和更明确的日志,通常都比等待审批更快见效。