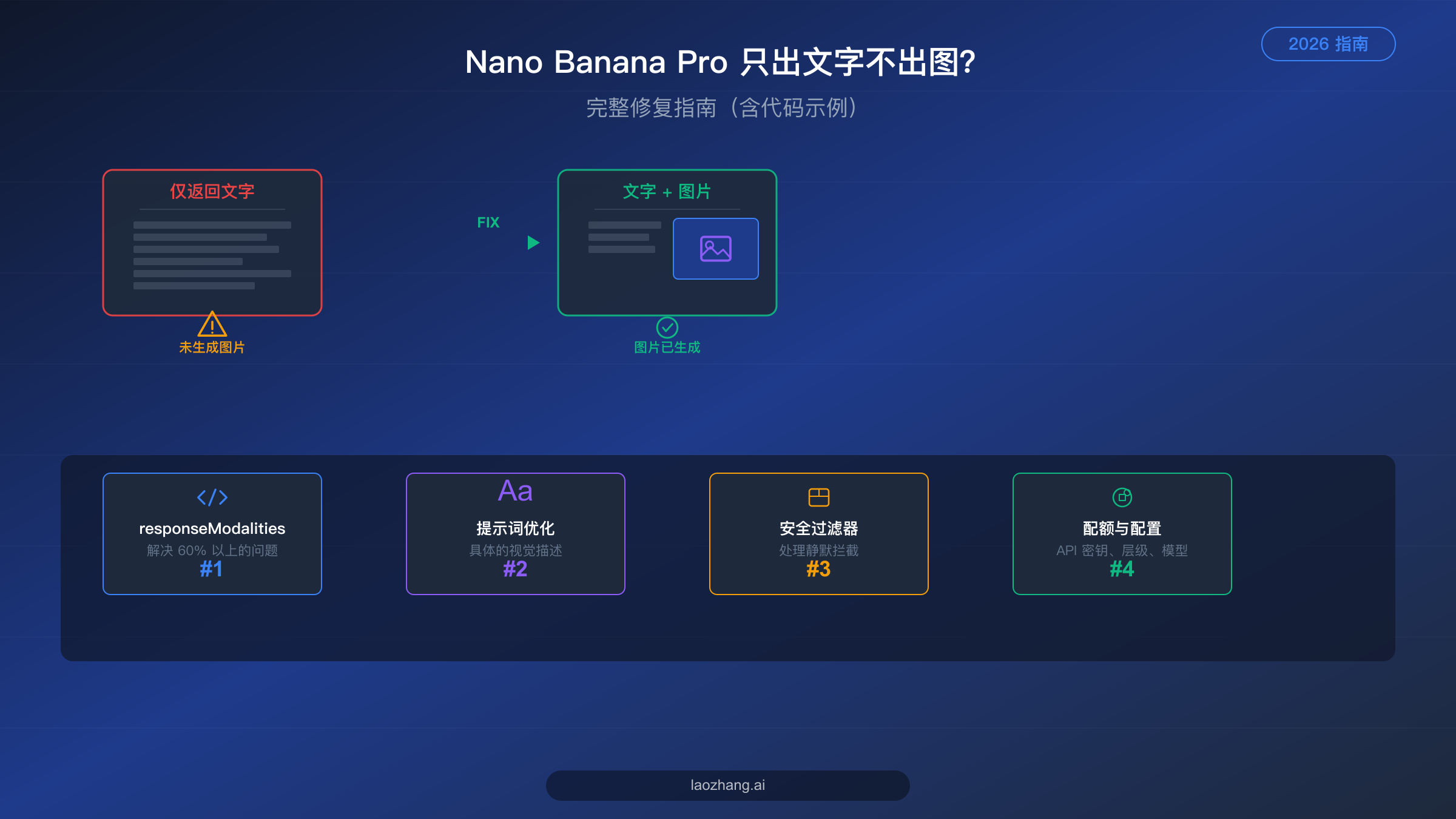
Nano Banana Pro 只返回文本而不生成图片,最常见的原因是 API 配置中缺少 responseModalities: ["TEXT", "IMAGE"] 参数。仅这一项修复就能解决超过 60% 的问题。其他原因包括提示词过于模糊、安全过滤器拦截、API 配额耗尽或选错模型等。本指南涵盖全部 7 大根本原因,提供可直接运行的 Python 和 JavaScript 代码示例,所有信息均基于 Google 官方文档(2026 年 2 月验证)。
要点速览 — 快速修复清单
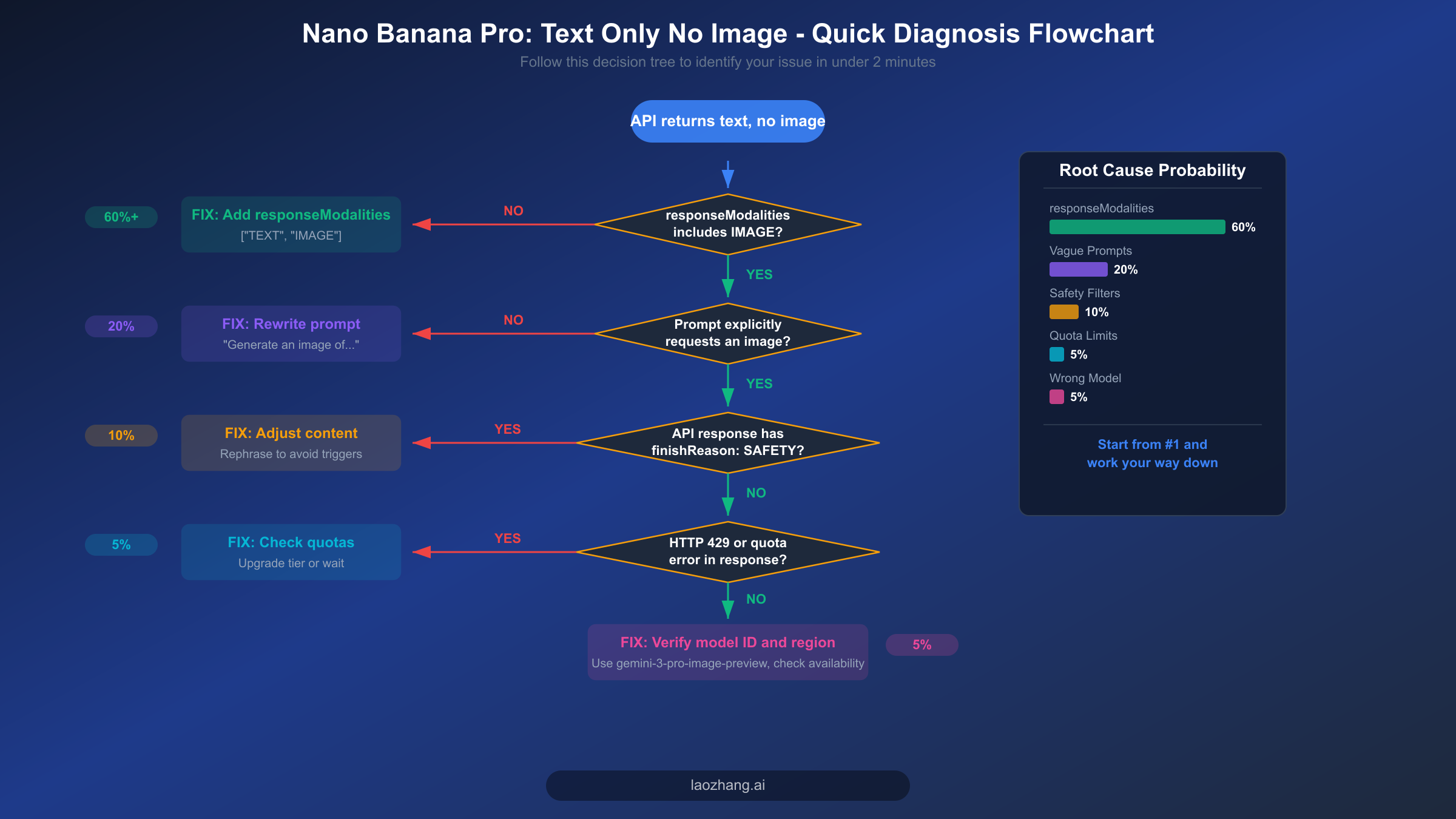
在深入分析之前,这里是修复 Nano Banana Pro 只输出文字问题的最快路径。遇到此问题的绝大多数开发者可以在五分钟内按照以下清单逐步排查解决,从最常见的原因开始,逐步到较罕见的场景。每一项修复都针对一个特定的根本原因,建议你在应用每项修复后都测试一下图片生成功能,以确认问题是否已解决。
第 1 步:在生成配置中添加 responseModalities。 这是迄今为止最常见的原因,大约占所有"只有文字没有图片"反馈的 60%。你的 API 调用必须在生成配置对象中包含 responseModalities: ["TEXT", "IMAGE"](Python 中使用 snake_case 风格的 response_modalities)。如果没有这个参数,Gemini API 默认进入纯文本输出模式,这意味着模型会用文字描述图片而不是真正生成像素数据。请参阅下方的代码对比部分查看 Python 和 JavaScript 的确切语法。
第 2 步:确认你的提示词明确要求生成图片。 像"山上的日落"这样的提示词是模糊的,模型可能将其理解为要求文字描述而非图片生成。相反,应该写明确包含视觉生成语言的提示词,例如:"Generate a photorealistic image of a sunset over snow-capped mountains with warm golden light。"将"generate"或"create"等词与视觉描述结合使用,可以向模型发出信号,要求它在文本回复的同时生成图片输出。
第 3 步:检查 API 响应中是否有安全过滤器标志。 如果你的响应成功返回(HTTP 200)但 parts 数组中没有图片数据,请检查 finishReason 字段。如果值为 SAFETY,说明内容被 Google 的安全过滤器拦截了。这是一种静默失败,让很多开发者措手不及,因为没有明确的错误提示,图片就是不出现。重写你的提示词以避免潜在的敏感内容,或参阅我们的安全过滤器故障排除深度指南了解详细的解决方案。
第 4 步:确认你的 API 密钥有足够的配额并处于正确的计费层级。 Nano Banana Pro(gemini-3-pro-image-preview)没有免费层级(ai.google.dev/pricing,2026-02-19 验证)。你需要一个已激活的 Blaze(按量付费)计费账户。如果你看到 HTTP 429 错误,说明你已触发了速率限制,要么等待重置窗口,要么升级你的计费层级。Tier 1 需要完成计费设置,Tier 2 需要总消费 250 美元以上且账户创建满 30 天,Tier 3 需要总消费 1,000 美元以上且满 30 天。
第 5 步:仔细核对你的模型 ID。 确保你使用的是 gemini-3-pro-image-preview 作为 Nano Banana Pro 的模型标识符,而不是旧版本的模型名称。有些开发者会误用 gemini-pro 或 gemini-pro-vision,这些是上一代模型,不支持原生图片生成输出。模型 ID 必须完全匹配,包括 -image-preview 后缀。
为什么 Nano Banana Pro 会返回文字而不是图片
要理解为什么 Nano Banana Pro 输出的是文字描述而非真正的图片,需要了解 Gemini API 的多模态生成流水线在底层是如何工作的。与传统的图片生成 API(如 DALL-E,它拥有专门的图片端点且始终返回像素数据)不同,Nano Banana Pro 是一个统一的多模态模型,能够根据配置返回文本、图片或两者兼有。这种架构差异是大多数困惑的根源,因为除非你明确告诉模型在输出中包含图片,否则模型的默认行为就是生成文本。
Gemini 3 Pro Image 模型(gemini-3-pro-image-preview)通过单一推理流水线处理你的提示词,产出交错排列的文本和图片 token。然而,API 层位于你的代码和模型之间,这个层使用 responseModalities 参数来决定将哪些类型的 token 包含在响应中。当未指定 responseModalities 时,API 默认为仅 ["TEXT"] 模式,这意味着模型在内部确实生成了图片 token,但在响应到达你的应用之前就被丢弃了。这不是一个 bug,而是有意设计的默认行为,旨在为纯对话场景最小化带宽和成本。后果就是,你的模型在技术上确实生成了你请求的图片,但 API 在你看到之前就将其从响应中过滤掉了。
除了配置问题之外,还有六个额外的根本原因会导致即使配置正确也无法获得图片输出。模糊或歧义的提示词大约占 20% 的案例。模型解析自然语言,如果你的提示词读起来更像一个问题或描述请求,而不是图片生成指令,即使启用了图片模态,模型也会默认生成文本响应。安全过滤器拦截约占 10% 的案例,这尤其令人头疼,因为它们是静默失败的——你会收到成功的 HTTP 200 响应,但响应体中根本没有图片数据,只有元数据中一个不起眼的 finishReason: "SAFETY" 标志来表明发生了什么。
其余的原因包括配额耗尽(当你超出当前层级的速率限制时收到 HTTP 429 错误)、选错模型(使用不支持图片输出的模型 ID)、区域可用性问题(图片生成功能可能并非在所有地区都可用),以及 Files API 限制(在图片编辑任务中使用 fileData 引用而非 inlineData 来传入图片,这会导致静默失败,已在 Google 开发者论坛中有记录)。这些原因中的每一个都有特定的诊断特征和修复方法,我们将在后续章节中逐一讲解。
修复方案 #1 — 正确设置 responseModalities(解决 60% 以上的问题)
修复 Nano Banana Pro 只输出文字问题最有效的方法就是在生成配置中添加 responseModalities 参数。这个参数告诉 API 你希望在响应中获得哪些类型的内容,而如果不明确包含 "IMAGE",你就只会收到文本。准确理解在代码中的什么位置、以什么方式设置这个参数,就能解决绝大多数案例。下面我们用完整的、可运行的示例来演示 Python 和 JavaScript 的正确实现方式。
Python 实现
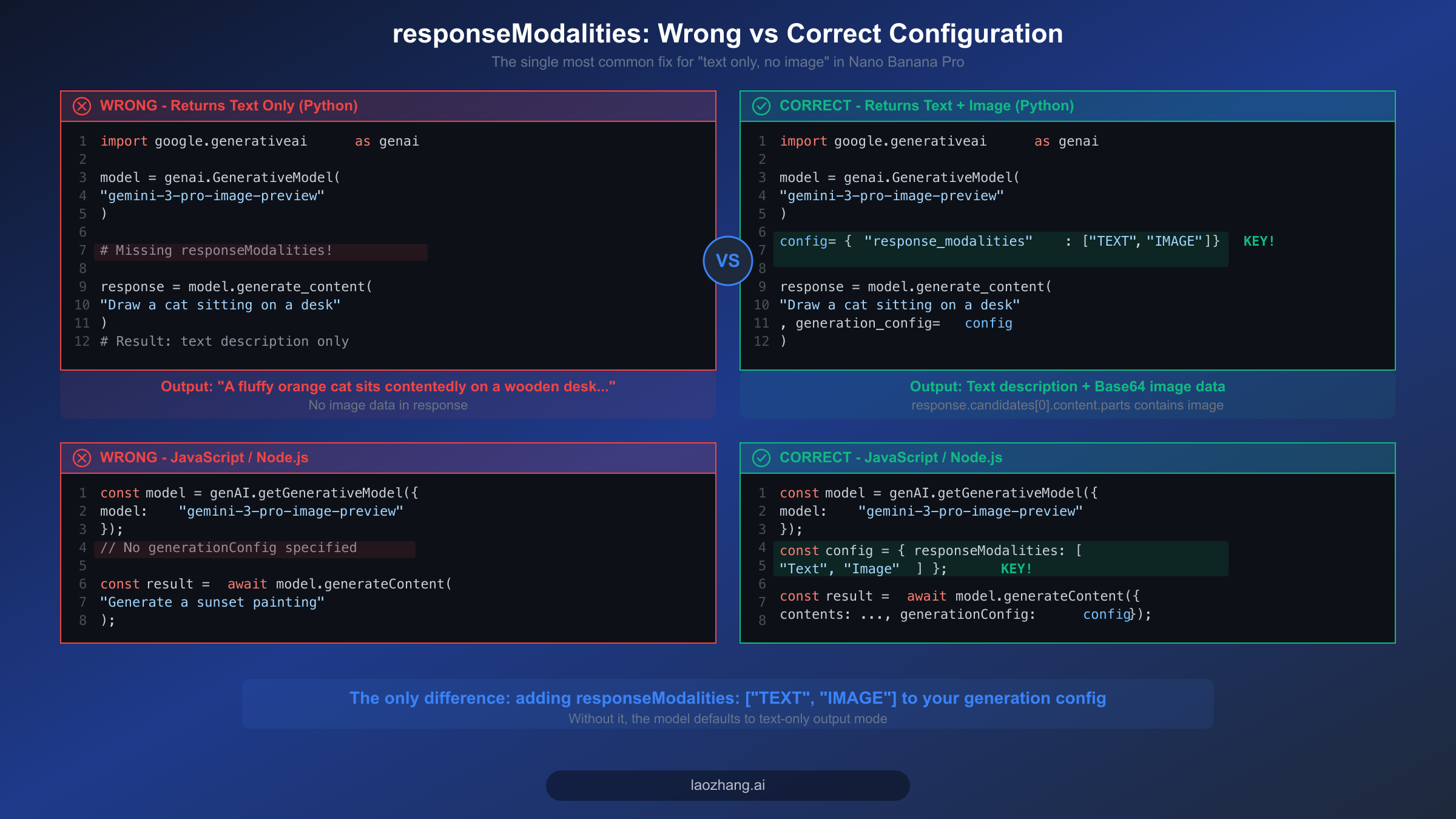
Google Generative AI Python SDK 使用 snake_case 命名规范,因此参数名为 response_modalities 而非 responseModalities。以下是一个完整的、可运行的示例,展示了使用 Nano Banana Pro 生成图片的正确配置。这段代码基于 2026 年 2 月最新版本的 google-generativeai 包验证通过,可以直接复制到你的项目中使用。
pythonimport google.generativeai as genai import base64 genai.configure(api_key="YOUR_API_KEY") # Create the model instance model = genai.GenerativeModel("gemini-3-pro-image-preview") # The critical configuration — without this, you get text only generation_config = { "response_modalities": ["TEXT", "IMAGE"], # Both text AND image "temperature": 0.7, } # Generate content with image output enabled response = model.generate_content( "Generate a photorealistic image of a golden retriever playing in autumn leaves", generation_config=generation_config ) # Process the response — iterate through parts to find image data for part in response.candidates[0].content.parts: if hasattr(part, "inline_data") and part.inline_data: # This is the image data (base64-encoded) image_bytes = base64.b64decode(part.inline_data.data) with open("output.png", "wb") as f: f.write(image_bytes) print(f"Image saved! MIME type: {part.inline_data.mime_type}") elif hasattr(part, "text") and part.text: print(f"Text response: {part.text}")
开发者最常犯的错误是将 response_modalities 放错了位置。它必须放在 generation_config 字典内部,而不是作为 generate_content() 的独立参数。另一个常见错误是在 Python 中使用 camelCase 写法(responseModalities)而非 snake_case 写法(response_modalities)——SDK 期望使用 Python 命名规范,对于无法识别的参数名会静默忽略,这意味着你的代码运行时不会报任何错误,但只会产生纯文本输出。
JavaScript / Node.js 实现
JavaScript SDK 使用 camelCase 写法,因此参数名为 responseModalities。以下是 Node.js 环境下的等效实现。请注意 generationConfig 对象的结构以及它在 generateContent 调用中的传递方式,因为 JavaScript API 的调用签名与 Python 略有不同。
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); const fs = require("fs"); const genAI = new GoogleGenerativeAI("YOUR_API_KEY"); const model = genAI.getGenerativeModel({ model: "gemini-3-pro-image-preview", }); // Critical: include responseModalities with "Image" const generationConfig = { responseModalities: ["Text", "Image"], // Note: capitalized in JS SDK temperature: 0.7, }; async function generateImage() { const result = await model.generateContent({ contents: [{ role: "user", parts: [{ text: "Generate a photorealistic image of a golden retriever playing in autumn leaves" }] }], generationConfig: generationConfig, }); const response = result.response; for (const part of response.candidates[0].content.parts) { if (part.inlineData) { // Save the generated image const imageBuffer = Buffer.from(part.inlineData.data, "base64"); fs.writeFileSync("output.png", imageBuffer); console.log(`Image saved! MIME: ${part.inlineData.mimeType}`); } else if (part.text) { console.log(`Text: ${part.text}`); } } } generateImage();
Python SDK 和 JavaScript SDK 之间有一个容易忽略的区别,那就是模态值的大小写。JavaScript SDK 中应使用 "Text" 和 "Image"(首字母大写),而 Python SDK 使用 "TEXT" 和 "IMAGE"(全部大写)。使用错误的大小写可能导致参数被静默忽略,产生同样的纯文本输出问题。如果你正在跨语言迁移代码,这是一个非常容易遗漏的坑。如果你需要从零开始设置 API,可以参阅我们的 Nano Banana Pro API 分步设置指南获取完整的配置流程。
修复方案 #2 — 编写针对图片生成优化的提示词
即使 responseModalities 配置正确,你的提示词的质量和具体程度也会显著影响 Nano Banana Pro 是生成图片还是默认返回文字描述。模型处理自然语言,并推断什么类型的输出最能满足你的请求。如果你的提示词是模糊的、对话式的,或者以问题形式表达,模型可能会判定文字解释才是更合适的回答——即使你已经在配置中启用了图片输出。
关键原则是编写毫无歧义地表达你想要视觉输出意图的提示词。这意味着需要明确使用与图片创建相关的动作动词("generate"、"create"、"draw"、"render"、"design")并包含具体的视觉描述词(颜色、构图、风格、光线、视角)。一个能稳定生成图片的提示词与一个有时返回文字的提示词之间的差异,往往仅在于你传达视觉意图的直接程度。
经常无法生成图片的提示词通常是简短的、模糊的,或者表述为描述而非指令。例如,"a sunset over the ocean"既可以被理解为生成图片的请求,也可以被理解为获取日落信息的请求。类似地,"tell me about a Victorian house"几乎肯定会产生文本,因为"tell"这个词传达了对话意图。即使像"sunset painting"这样没有任何生成动词的表述,也足够模糊,以至于模型可能返回关于日落画作的文字分析,而不是创建一幅画。模型的设计初衷是以它理解的最有帮助的方式回应你的请求,这意味着你必须明确表达想要视觉输出的意图。
能稳定生成图片的提示词包含明确的生成语言和丰富的视觉细节。不要写"a cat",而要写"Generate a photorealistic image of an orange tabby cat sitting on a sunlit windowsill, with soft bokeh background and warm afternoon lighting。"不要写"logo for a tech company",而要写"Create a minimalist logo design for a technology company called TechFlow, using blue and silver colors, featuring an abstract wave pattern, on a white background。"额外的具体细节不仅能确保图片生成,还能产出更高质量的结果,因为模型有更多信息可以参考。如需了解更多提示词技巧,可以参阅我们的 Nano Banana Pro 高级提示词工程技术。
以下是基于 Gemini API 实测的具体前后对比示例,展示了提示词改写如何影响图片生成成功率:
| 差的提示词(经常只返回文字) | 好的提示词(稳定生成图片) |
|---|---|
| "a mountain landscape" | "Generate a photorealistic image of snow-capped mountains at golden hour with a reflection in a calm alpine lake" |
| "what does a neural network look like" | "Create a technical diagram illustration of a neural network architecture showing input, hidden, and output layers with connecting nodes" |
| "product photo of headphones" | "Render a professional product photograph of matte black over-ear headphones on a clean white background with soft studio lighting and subtle shadow" |
| "cute dog" | "Generate an image of a fluffy golden retriever puppy sitting in a field of wildflowers, looking at the camera with a playful expression, shallow depth of field" |
修复方案 #3 — 应对安全过滤器和内容拦截
安全过滤器拦截是 Nano Banana Pro 返回文字而非图片的最令人头疼的原因,因为它是静默失败的。与配额错误(HTTP 429)或身份验证失败(HTTP 401)不同,安全过滤器拦截返回的是完全正常的 HTTP 200 响应和有效的 JSON,只是图片数据从响应体中消失了。许多开发者花了数小时调试代码或配置,最后才发现问题不在技术层面而在内容层面。理解这些过滤器的工作原理以及如何用代码检测它们,对于构建可靠的图片生成流水线至关重要。
Google 的图片生成安全过滤器在多个层级运作。第一层级评估输入提示词是否包含潜在有害内容类别,包括暴力、色情内容、仇恨言论和危险活动。第二层级在生成的图片返回给你之前评估图片本身,对照相同的安全类别检查视觉内容。任何一个层级都可以独立拦截图片输出,这意味着你的提示词可能通过了输入过滤器,但生成的图片可能被输出过滤器拦截。当这种情况发生时,API 响应中的 finishReason 字段会被设置为 "SAFETY",parts 数组要么只包含文本,要么为空。关键在于,你必须在响应处理代码中主动检查这个条件,而不是假设成功的 HTTP 响应就意味着你获得了图片。
以下是如何用代码检测安全过滤器拦截,并实现自动提示词调整以从被拦截的请求中恢复。这个模式在尝试提取图片数据之前先检查响应元数据,如果检测到安全拦截,它会用更温和的语言重写提示词并重试请求。如需了解安全过滤器行为的全面分析(包括边缘案例和高级解决方案),请参阅我们的安全过滤器故障排除深度指南。
pythondef generate_image_with_safety_handling(model, prompt, generation_config, max_retries=3): """Generate an image with automatic safety filter detection and retry.""" for attempt in range(max_retries): response = model.generate_content(prompt, generation_config=generation_config) # Check finish reason for safety blocks candidate = response.candidates[0] if candidate.finish_reason.name == "SAFETY": print(f"Attempt {attempt + 1}: Safety filter triggered. Adjusting prompt...") # Soften the prompt and retry prompt = f"Create a family-friendly, artistic illustration: {prompt}" continue # Check if image data actually exists in the response has_image = any( hasattr(part, "inline_data") and part.inline_data for part in candidate.content.parts ) if has_image: return response # Success! # No image but no safety block either — prompt may need to be more explicit print(f"Attempt {attempt + 1}: No image in response. Making prompt more explicit...") prompt = f"Generate a detailed image of: {prompt}" raise Exception(f"Failed to generate image after {max_retries} attempts")
常见的安全过滤器触发因素包括:提示词中提到真人姓名(尤其是公众人物)、请求生成儿童的照片级图片、涉及武器或暴力的提示词(即使是虚构场景),以及医学或解剖学内容。过滤器的设计倾向于保守,这意味着它们有时会拦截你认为无害的内容。最有效的解决方法是用更抽象或艺术性的语言重新表述你的提示词——例如,不要写"a soldier in a battle scene",而是尝试写"an artistic illustration of a medieval knight in an epic fantasy landscape"。这传达了类似的视觉概念,同时避免了触发暴力过滤器的特定语言模式。
修复方案 #4 — 验证配额、API 密钥和模型配置
当你的 responseModalities 配置正确、提示词也很明确、安全过滤器也不是问题时,下一个需要排查的问题类别就是你的账户和 API 基础设施。这些问题通常更容易诊断,因为它们会产生明确的错误代码而非静默失败,但当症状与"只输出文字"问题重叠时仍会造成困惑——尤其是在图片生成容量暂时耗尽时,API 回退到纯文本模式而不是返回错误的情况下。
首先要验证的是你的 API 密钥是否关联了 Blaze(按量付费)计费账户。Nano Banana Pro 的图片生成功能(gemini-3-pro-image-preview)没有免费层级。输入 token 的费用为每百万 token 2.00 美元,图片输出的费用约为每张 0.134 美元(1K-2K 分辨率)或每张 0.24 美元(4K 分辨率)(ai.google.dev/pricing,2026-02-19 验证)。如果你的计费配置不正确,图片生成请求可能会静默失败或返回纯文本响应,而不是产生明确的计费错误。你可以在 Google Cloud Console 的 Billing > Account Overview 中验证你的计费状态。
速率限制按层级组织,每个层级有特定的要求。Tier 1 需要完成付费计费账户设置。Tier 2 需要至少 250 美元的总消费加上账户创建后至少 30 天。Tier 3 需要至少 1,000 美元的总消费加上 30 天。更高的层级提供更宽裕的每分钟请求数(RPM)和每分钟 token 数(TPM)限制。当你触及速率限制时,API 会返回 HTTP 429(Too Many Requests)。你应该在重试逻辑中实现指数退避策略,而不是立即重试,因为快速重试只会延长限速期。如需了解所有错误代码及其含义的完整参考,请参阅我们的 Nano Banana 完整错误代码参考。
模型 ID 验证是另一个关键检查点。支持图片生成的 Nano Banana Pro 正确模型 ID 是 gemini-3-pro-image-preview。常见的错误包括使用 gemini-pro(不带图片输出的基础文本模型)、gemini-pro-vision(上一代视觉模型,可以分析图片但不能生成图片)或 gemini-3-pro(可能默认为纯文本操作)。这些模型中的每一个都会接受你的提示词并返回文本响应且不报任何错误,使得问题看起来与 responseModalities 配置错误完全一样,而实际问题是你调用的模型根本不具备图片生成能力。如果你正在管理大规模图片生成的成本,可以考虑使用第三方 API 聚合服务如 laozhang.ai,它以更低的价格提供 Nano Banana Pro 的访问,免去直接管理 Google Cloud 计费层级的复杂性。
构建可靠的图片生成流水线
超越单个修复方案,生产环境应用面临的真正挑战是构建一个能够自动处理所有失败模式并在问题出现时优雅降级的图片生成流水线。一个简单地调用 generate_content 并期望获得图片数据的原始实现,在生产环境中会由于我们讨论过的各种潜在失败模式而间歇性失败。你需要的是一个健壮的封装层,它能验证配置、检测失败、实现智能重试逻辑,并在出错时提供清晰的诊断信息。
以下 Python 实现展示了一个生产级的图片生成流水线,具备全面的错误处理、带指数退避的自动重试、安全过滤器检测和详细的日志记录。这是我们推荐的模式,适用于任何依赖 Nano Banana Pro 进行可靠图片生成的应用,它将前面章节讨论的所有修复方案整合到一个单一的、可复用的类中。
pythonimport time import base64 import logging from typing import Optional, Tuple import google.generativeai as genai logging.basicConfig(level=logging.INFO) logger = logging.getLogger("image_pipeline") class NanoBananaProPipeline: """Production-ready image generation pipeline for Nano Banana Pro.""" def __init__(self, api_key: str): genai.configure(api_key=api_key) self.model = genai.GenerativeModel("gemini-3-pro-image-preview") self.generation_config = { "response_modalities": ["TEXT", "IMAGE"], "temperature": 0.7, } def generate( self, prompt: str, max_retries: int = 3, save_path: Optional[str] = None ) -> Tuple[Optional[bytes], str]: """ Generate an image with full error handling. Returns: (image_bytes or None, status_message) """ current_prompt = prompt base_delay = 2 # seconds for attempt in range(max_retries): try: logger.info(f"Attempt {attempt + 1}/{max_retries}: Generating image...") response = self.model.generate_content( current_prompt, generation_config=self.generation_config ) # Check for empty response if not response.candidates: logger.warning("Empty candidates list — possible content filter") current_prompt = f"Create an artistic, family-friendly illustration: {prompt}" continue candidate = response.candidates[0] # Check finish reason finish_reason = candidate.finish_reason.name if finish_reason == "SAFETY": logger.warning(f"Safety filter triggered on attempt {attempt + 1}") current_prompt = f"Create a safe, artistic illustration of: {prompt}" continue elif finish_reason == "RECITATION": logger.warning("Recitation filter triggered") current_prompt = f"Generate an original image inspired by: {prompt}" continue # Extract image data from parts image_data = None text_response = "" for part in candidate.content.parts: if hasattr(part, "inline_data") and part.inline_data: image_data = base64.b64decode(part.inline_data.data) elif hasattr(part, "text") and part.text: text_response = part.text if image_data: if save_path: with open(save_path, "wb") as f: f.write(image_data) logger.info(f"Image saved to {save_path}") return image_data, f"Success. Text: {text_response[:100]}..." # No image data — make prompt more explicit logger.warning(f"No image data in response. Text: {text_response[:200]}") current_prompt = f"Generate a detailed visual image (not text): {prompt}" except Exception as e: error_str = str(e) if "429" in error_str: delay = base_delay * (2 ** attempt) logger.warning(f"Rate limited. Waiting {delay}s...") time.sleep(delay) elif "403" in error_str: return None, "Authentication error: check API key and billing" else: logger.error(f"Unexpected error: {e}") if attempt < max_retries - 1: time.sleep(base_delay) else: return None, f"Failed after {max_retries} attempts: {e}" return None, f"Failed to generate image after {max_retries} attempts" # Usage pipeline = NanoBananaProPipeline(api_key="YOUR_API_KEY") image_bytes, status = pipeline.generate( "Generate a photorealistic landscape of Mount Fuji at sunrise", save_path="fuji_sunrise.png" ) print(status)
这个流水线自动处理五种不同的失败模式:响应中缺少图片数据(调整提示词使其更明确)、安全过滤器拦截(用更安全的语言重写提示词)、速率限制(指数退避)、身份验证错误(立即失败并提供清晰信息)以及意外异常(延迟后重试)。对于高可靠性要求的生产部署,你还可能需要添加监控和告警——追踪你的成功率变化趋势,如果低于某个阈值,排查 Google 是否更改了模型行为或更新了安全过滤器。对于需要更高可靠性但不想管理这些复杂性的团队,laozhang.ai 等第三方 API 提供商提供聚合访问,内置速率限制、自动故障转移和简化的计费方式,可以大幅降低运维负担。
Nano Banana Pro 与 Nano Banana:如何选择正确的模型
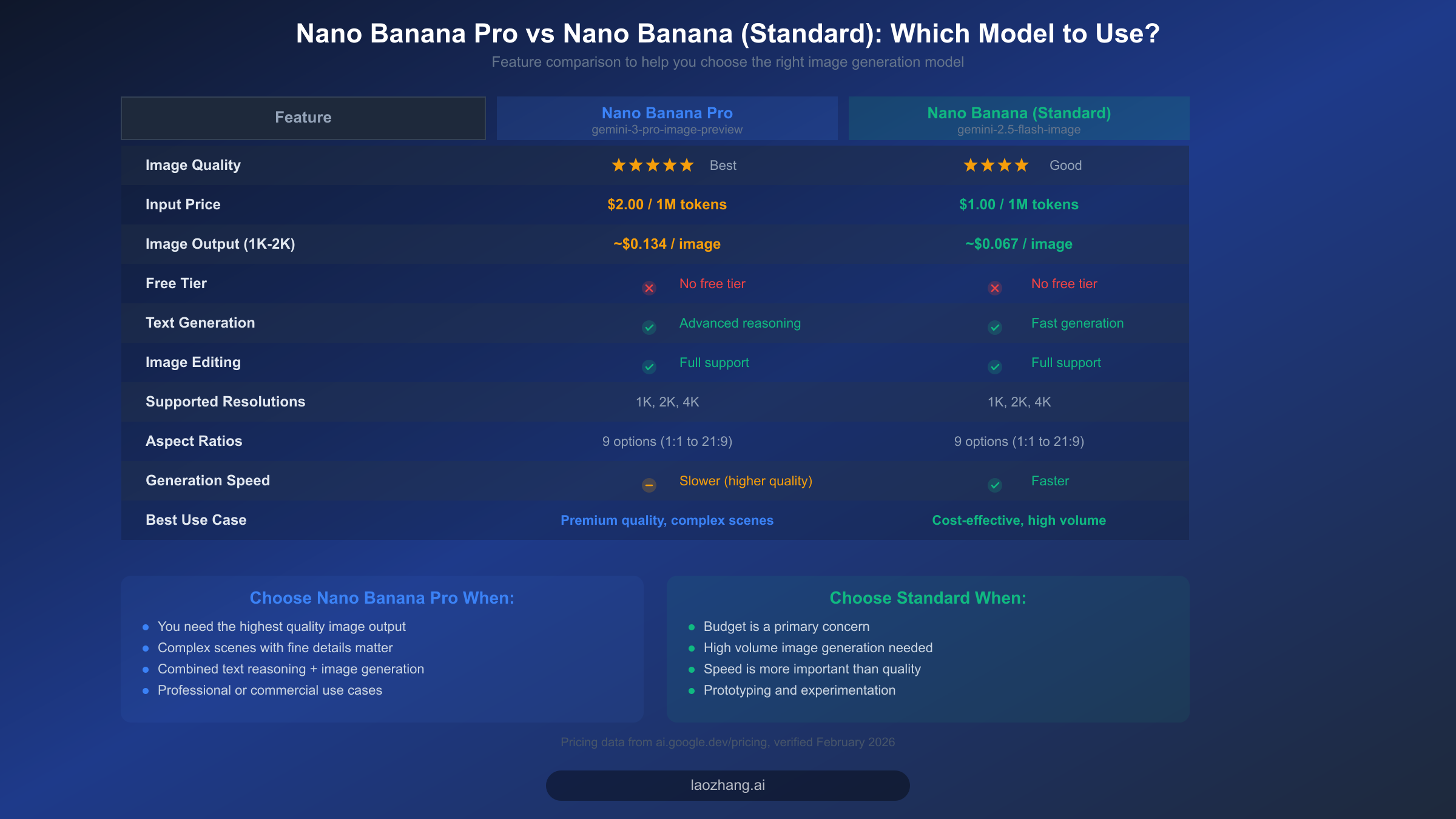
一个经常被忽视的"只有文字没有图片"问题原因是完全用错了模型。Google 在 Nano Banana 品牌下提供两个不同的图片生成模型,它们之间的混淆会导致难以诊断的配置问题。Nano Banana Pro(gemini-3-pro-image-preview)是高级模型,拥有更高质量的输出和更强的推理能力,而 Nano Banana 标准版(gemini-2.5-flash-image)则是更快、更经济的选项,同样能生成高质量的图片。两个模型都支持图片生成,但它们有不同的 API 标识符、定价结构和功能。
对于故障排除而言,最重要的区别就是模型 ID。Nano Banana Pro 使用 gemini-3-pro-image-preview,其中 -image-preview 后缀表示图片生成是这个模型变体的活跃功能。如果你使用不带后缀的 gemini-3-pro,你可能获得一个支持文本生成和图片理解(输入)但不支持图片生成(输出)的模型。这是一个微妙但关键的区别,不会产生任何错误——模型只是在纯文本模式下运行,因为你选择的变体不包含图片生成功能。务必确认你的模型 ID 包含带有 -image-preview 或 -image 后缀的完整字符串。
从定价角度来看,两个模型都需要付费计费(任何一个都没有免费层级)。Nano Banana Pro 每百万输入 token 收费 2.00 美元,每张生成的图片(1K-2K 分辨率)约收费 0.134 美元,而 Nano Banana 标准版每百万输入 token 收费 1.00 美元,相同分辨率下每张图片约收费 0.067 美元(ai.google.dev/pricing,2026-02-19 验证)。这意味着在同等工作负载下,Nano Banana 标准版的成本大约是 Pro 版的一半。两个模型都支持相同的分辨率(1K、2K、4K)和宽高比(1:1、2:3、3:2、3:4、4:3、4:5、5:4、9:16、16:9、21:9),因此选择主要取决于质量要求与预算限制的权衡。如需了解何时使用哪个模型的更深入分析,请参阅我们的 Nano Banana Pro 与 Nano Banana 详细对比。
在以下场景选择 Nano Banana Pro: 你的应用需要尽可能高的图片质量,需要模型处理包含精细细节和图片中精确文字渲染的复杂场景,或者你需要在单次交互中将高级文本推理与图片生成结合使用。Pro 版在遵循复杂的多部分提示词和生成与详细规格高度匹配的图片方面表现出色。
在以下场景选择 Nano Banana 标准版: 你最关心的是成本效率,需要大批量生成图片,或者生成速度比最高质量更重要。标准版更适合原型开发、批量处理以及"足够好"的图片质量但只需一半成本的工程权衡场景。两个模型使用相同的 responseModalities 配置,因此修复"只有文字"问题的方法完全一致,无论你选择哪个模型。
常见问题解答
为什么 Nano Banana Pro 返回的是图片的文字描述而不是真正的图片?
最常见的原因是你的 API 调用在生成配置中缺少 responseModalities: ["TEXT", "IMAGE"] 参数。没有这个参数,Gemini API 默认进入纯文本输出模式。模型在内部确实生成了图片,但 API 层在响应到达你的应用之前就将图片数据剥离了。添加这一个参数就能解决超过 60% 的此类问题。
Nano Banana Pro 的图片生成功能可以免费使用吗?
不可以。Nano Banana Pro(gemini-3-pro-image-preview)没有免费层级。你需要一个 Google Cloud 的 Blaze(按量付费)计费账户。输入费用为每百万 token 2.00 美元,图片生成费用约为每张 0.134 美元(标准分辨率)(ai.google.dev/pricing,2026-02-19 验证)。如果你想找更低成本的选择,Nano Banana 标准版(gemini-2.5-flash-image)以大约一半的价格提供类似的功能。
API 响应中的 finishReason: SAFETY 是什么意思?
这表示 Google 的安全过滤器阻止了你的提示词进行图片生成。API 返回 HTTP 200(成功),但响应中不包含任何图片数据——这是一种许多开发者都会忽略的静默失败。要修复它,请重新表述你的提示词以避免可能触发安全过滤器的内容,例如涉及真人、暴力或敏感话题的引用。请在每个响应中检查 candidates[0].finish_reason 字段,以便用代码检测这种情况。
为什么我的代码处理文本提示词正常,但无法生成图片?
这通常意味着你的 responseModalities 设置不正确,或者你使用的模型变体不支持图片输出。确认你使用的是 gemini-3-pro-image-preview(不是 gemini-pro 或 gemini-3-pro),并确认你的生成配置包含 responseModalities: ["TEXT", "IMAGE"]。同时检查你是否使用了正确的 SDK 大小写格式——Python 使用 response_modalities(snake_case 加全大写值),而 JavaScript 使用 responseModalities(camelCase 加首字母大写值)。
如何从 API 响应中提取图片?
生成的图片以 base64 编码数据的形式包含在响应的 parts 数组中。遍历 response.candidates[0].content.parts,查找具有 inline_data(JavaScript 中为 inlineData)属性的部分。data 字段包含 base64 编码的图片字节,mime_type 字段告诉你图片格式(通常为 image/png)。解码 base64 数据后,将其保存为文件或在应用中进一步处理。
使用 Files API 和 inlineData 进行图片编辑有区别吗?
有区别,这是一个已在 Google 开发者论坛中记录的已知问题。在执行图片编辑任务(提供输入图片让模型修改)时,使用 Files API(fileData)可能导致静默失败,模型返回文字而不是编辑后的图片。使用 base64 格式的 inlineData 作为输入图片可以解决这个问题。如果你的图片编辑工作流返回的是文字描述而不是修改后的图片,请将输入方式从 fileData 切换为 inlineData。