
Short answer: Claude 529 overloaded_error usually means Anthropic is temporarily overloaded, or a service upstream from your request is saturated, so the fastest first move is to check the live Claude status page and recent incidents before you start rewriting prompts or rotating API keys. If you are using the API, your second move is controlled retry with backoff. If you are using Claude chat or Claude Code, you also need to make sure you are not actually looking at a plan limit or a chat-side capacity warning instead.
That distinction matters more in 2026 than it did a year ago. Anthropic's own release notes say that as of August 11, 2025, some sharp-usage scenarios that used to return 529 overloaded_error now show up as 429 rate_limit_error instead. So a modern 529 guide has to do more than say "wait and try again." It has to tell you which class of failure you actually hit.
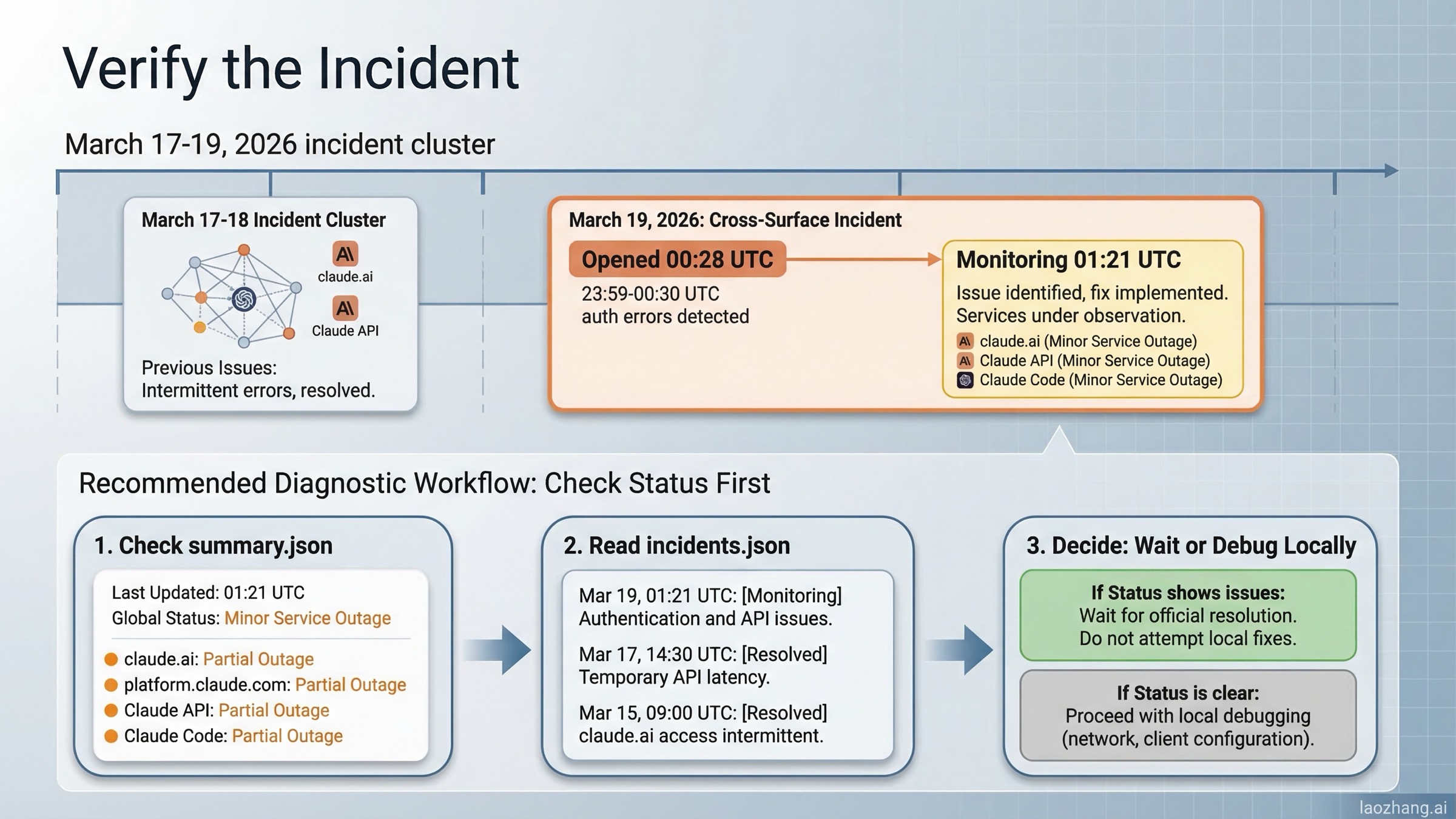
That status-first habit is not theoretical. Anthropic's public status feed opened an incident called "Elevated errors across surfaces" on March 19, 2026 at 00:28 UTC, and the summary endpoint marked claude.ai, platform.claude.com, the Claude API, and Claude Code as a partial outage. By the latest re-check for this article at 01:21 UTC, the incident had already moved to monitoring, and Anthropic said users experienced elevated authentication errors from 23:59-00:30 UTC. That is exactly the kind of moment when a 529 searcher needs a diagnosis workflow, not generic prompt advice.
TL;DR
Claude 529 overloaded_error is usually an Anthropic-side overload signal, not proof that your request format is wrong. Start with status.claude.com and the recent incidents feed. At the latest re-check for this article on March 19, 2026, Anthropic's summary still showed a Minor Service Outage, while the "Elevated errors across surfaces" incident had already moved from investigating to monitoring after elevated authentication errors from 23:59-00:30 UTC. If the platform is healthy when you check, retry with jitter and reduce concurrency spikes. If your failure is actually 429, solve rate limiting instead. If you are seeing a message like "Due to unexpected capacity constraints" in Claude chat, Anthropic's support docs say that is not the same thing as a formal outage and it may not appear on the status page.
| Signal | What it usually means | Where it appears | First action |
|---|---|---|---|
529 overloaded_error | Anthropic or an upstream service is temporarily overloaded | API, Workbench, Claude Code, routed integrations | Check status, retry with backoff, log request ID |
429 rate_limit_error | Your org hit RPM, ITPM, OTPM, or acceleration limits | API and API-backed tools | Respect retry-after, reduce burst traffic, review rate limits |
| "Due to unexpected capacity constraints..." | Claude chat is under high demand | claude.ai | Wait a few minutes; support says this is not a formal outage |
| "5-hour limit reached" | Your plan quota is exhausted | Claude chat / Claude Code subscription flow | Wait for reset, reduce usage, or review Claude Code rate limits |
What Claude 529 Overloaded Error Actually Means
When Anthropic returns 529 overloaded_error, it is usually telling you that the service cannot process your request right now because capacity is temporarily constrained. That is a very different problem from a malformed request, an expired API key, or a permissions error. In practice, 529 is the error many developers see when the platform is having a bad hour, a model family is under unusual load, or a routed workflow such as Claude Code or Workbench is hitting a stressed backend.
This is why the search intent around the error is so anxious. Users hit 529 in the middle of active work, then search the literal string because they want to know one thing fast: "Is this me, or is this Anthropic?" The problem with most page-one results is that they stop at confirmation. They tell you other people see it too, but they rarely give you a clean operating model for deciding what to do next.
The official sources support a more precise interpretation. Anthropic's help center separates service incidents and outages, capacity constraints in Claude chat, and usage-limit messages into different buckets. The API docs separately explain rate limits, service tiers, and retry behavior. Once you read those together, the useful diagnosis becomes straightforward:
529usually points to service overload or temporary upstream saturation.429points to rate limiting, including burst or acceleration behavior.- Chat-side capacity messages are high-demand conditions in Claude's consumer experience.
- Five-hour plan limits are quota messages, not outage messages.
That difference is the whole article. If you misclassify the symptom, you will use the wrong fix.
One more practical point: 529 is an availability problem, not a semantic problem. If Anthropic is overloaded, trimming a prompt a little or rewriting a perfectly valid request will not usually solve the root issue. You still need a status-first mindset, because this is often a platform-health problem before it is a prompt-engineering problem.
529 vs 429 vs Capacity Constraints vs Usage Limits

The biggest reason people waste time on this topic is that Anthropic has several different "you cannot continue right now" states, and they do not all belong to the same layer.
Anthropic's support article on understanding Claude error messages says that chat-side capacity constraints happen when demand is high system-wide and that these issues are temporary. It also says they do not appear on the status page because they are considered normal load management rather than formal technical incidents. That single sentence explains why many users get confused: they see a problem, look at the status page, see green, and assume their account or browser must be broken.
The API side is different. Anthropic's rate limits documentation explains that limits exist at the organization level and are enforced over shorter intervals as well, not only over a simple per-minute bucket. That means a burst can fail even if your minute average looks fine. Then Anthropic's release notes add the crucial 2025 nuance: on August 11, 2025, Anthropic noted that some sharp increases in API usage now produce 429 errors in cases where 529 would previously have appeared.
So if you remember older community advice saying 529 and 429 are basically the same overload event, treat that advice as partially outdated. It may have been directionally useful in 2024 or early 2025, but it is not precise enough for 2026 troubleshooting.
Here is the practical comparison:
| Condition | Layer | Typical cause | What not to do |
|---|---|---|---|
529 overloaded_error | Anthropic service / upstream capacity | Temporary overload, live incident, stressed model backend | Do not immediately rotate keys or rewrite good code |
429 rate_limit_error | Your org's API usage behavior | Tier cap, RPM or token pressure, acceleration limit | Do not treat it like a platform outage |
| Capacity-constraint banner | Claude chat product experience | High user demand on chat infrastructure | Do not assume status.claude.com must show red |
| Five-hour limit message | Plan quota | Your Pro/Max usage window is exhausted | Do not keep debugging network settings |
If you use Claude Code, there is one more twist: your symptoms may surface through the tool, but the bottleneck may still be a shared underlying Anthropic component. That is why it helps to also know the difference between subscription quota issues and API-side issues. Our Claude Code rate limit guide goes deeper on that split.
Check Status First: How to Verify a Real Anthropic Incident
For this query, the first truly useful answer is not a definition. It is a status workflow.
Start with the public status page at status.claude.com. Then, if you need more detail, check the machine-readable feeds:
https://status.claude.com/api/v2/summary.jsonhttps://status.claude.com/api/v2/incidents.json
Those endpoints matter because they show component-level data for:
claude.aiplatform.claude.comClaude API (api.anthropic.com)Claude Code
When I re-checked the official feeds on March 19, 2026, the summary endpoint did not show a clean green board. It reported a Minor Service Outage, marked claude.ai, platform.claude.com, the Claude API, and Claude Code as partial outage, and listed the "Elevated errors across surfaces" incident that started at 2026-03-19T00:28:57Z. A later status update at 01:21 UTC moved that incident to monitoring and said users experienced elevated authentication errors from 23:59-00:30 UTC. The incidents feed also showed why recency matters: Claude had multiple resolved incidents on March 17-18, 2026, including:
- March 17, 2026: elevated errors on Claude Opus 4.6
- March 18, 2026: elevated errors on Claude Opus 4.6
- March 18, 2026: increased errors on Opus 4.6
- March 18, 2026: elevated errors on Claude.ai, with Claude Code also affected
- March 19, 2026: "Elevated errors across surfaces" opened at 00:28 UTC and moved to monitoring at 01:21 UTC after cross-surface authentication errors
This is exactly why generic advice like "wait 30 seconds and retry" is not enough. Sometimes that works because the incident is brief. Sometimes you are sitting inside a real outage window and should stop blaming your own integration.
There is one caveat here. A GitHub issue in the anthropics/claude-code repo, Issue #1838, documented a June 9, 2025 case where users reported overloaded_error while Claude Code still looked healthy on the dashboard. You should not overstate that single report, but it is useful as an operational warning: status pages are essential, not magical. In the first minutes of an incident, user reports may appear before every component flips state.
My recommendation is simple:
- Check the summary page.
- Check the incidents feed.
- Check whether the failure is isolated to one surface, one model, or your entire workflow.
- If the platform looks green but reports are piling up, treat your own retries conservatively and avoid making irreversible code changes based on a maybe-false local diagnosis.
If you run anything production-facing, save the incidents endpoint in monitoring rather than relying only on the public dashboard UI. The JSON feed is easier to alert on, easier to correlate with your own logs, and easier to review when you need a postmortem later.
Troubleshooting: What to Do in the First 10 Minutes
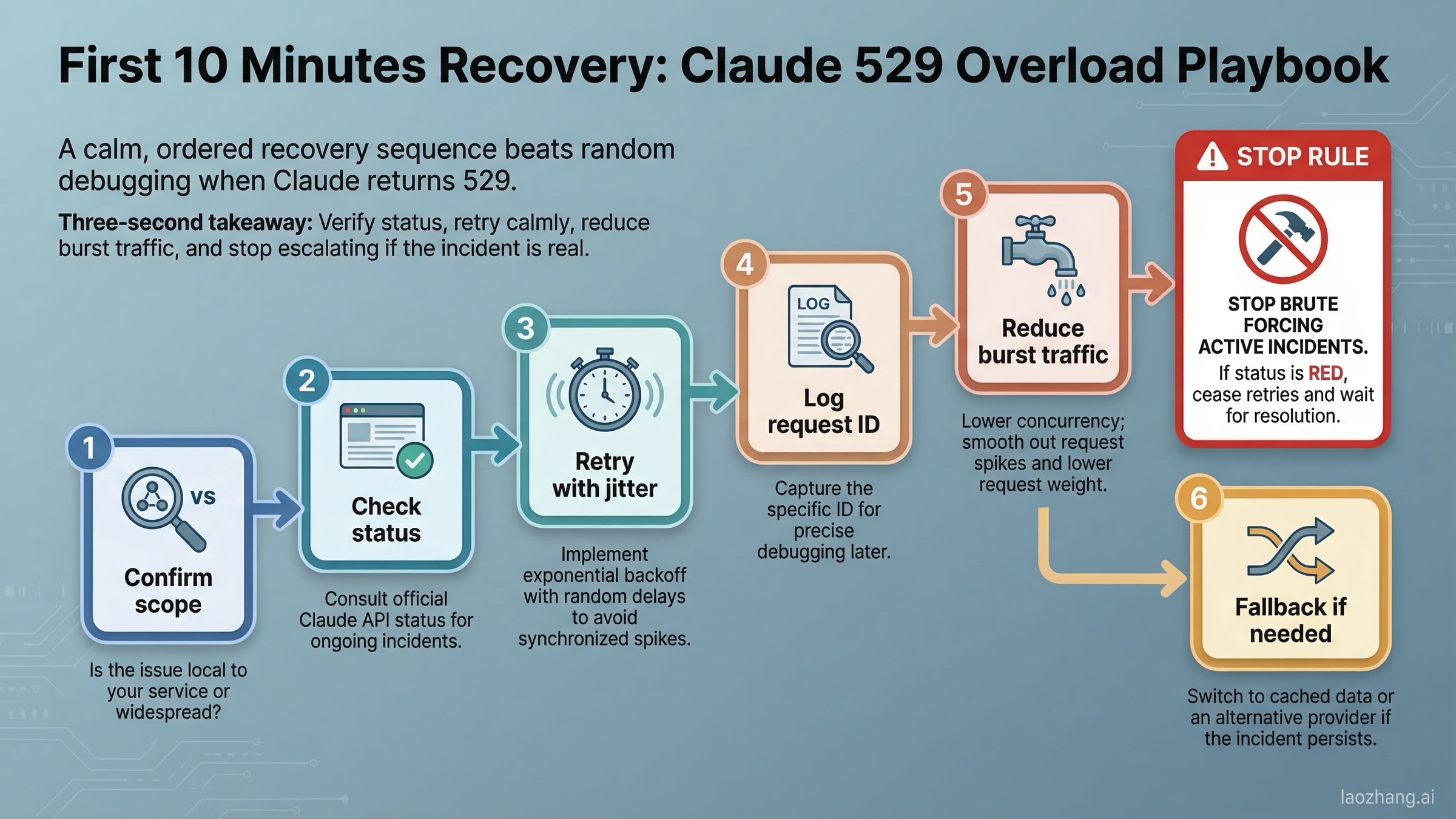
If you are seeing 529 in the API, Workbench, or Claude Code, use this order of operations.
Step 1: Confirm whether the problem is broad or local. If both Claude chat and the API are struggling, the odds of a platform-side issue rise sharply. If only one integration path is failing, the issue may still be upstream, but you should also inspect your own toolchain.
Step 2: Retry with jitter, not with panic. Transient overload is one of the few cases where retrying is rational, but hammering the service makes things worse. Use exponential backoff with a small random component. Anthropic's own Python SDK documentation says the SDK automatically retries connection errors, 408, 409, 429, and >=500 errors two times by default with short exponential backoff. That means if you are already using the official SDK, you should understand what it is doing before you stack five more retry layers on top.
Step 3: Log the request ID. Anthropic's SDK docs expose _request_id for exactly this reason. If you need support later, a clean request ID is more useful than saying "it seemed broken around lunchtime."
Step 4: Reduce burst behavior. Anthropic's rate-limit docs say a published minute rate can still be enforced over shorter intervals and that the API uses a token-bucket algorithm. Even if your visible error is 529, reducing sudden concurrency spikes is still smart because bursty behavior can move you into rate-limit territory or worsen recovery after a stressed backend stabilizes.
Step 5: Check whether you are really dealing with 429 instead. If the error body or your SDK exceptions show RateLimitError, switch mental models immediately. Then the right guide is not "Claude is overloaded" but how to fix Claude API 429 rate limit errors.
Step 6: Reduce request weight while you wait. If your current workflow sends very large context windows, many tool results, or oversized attachments, temporarily scale those down. This does not mean heavy prompts "cause" every 529, but lighter requests are easier to retry, faster to fail, and less likely to compound trouble with timeout or secondary rate-limit behavior.
Step 7: Change timing, not only code. If a model family is clearly having a bad hour, pausing non-critical work for 10-20 minutes can be smarter than chewing through retries and attention. The goal is to resume useful work fast, not to prove your retry loop is persistent.
For developers, a minimal Python recovery pattern looks like this:
pythonimport time import random from anthropic import Anthropic, APIStatusError, RateLimitError client = Anthropic(max_retries=2) def call_with_jitter(messages, max_attempts=5): for attempt in range(max_attempts): try: return client.messages.create( model="claude-sonnet-4-6", max_tokens=1024, messages=messages, ) except RateLimitError: # 429: treat as rate limiting, not generic overload raise except APIStatusError as e: if e.status_code == 529: delay = min(2 ** attempt, 20) + random.uniform(0, 1) time.sleep(delay) continue raise raise RuntimeError("Claude remained overloaded after retries")
This is intentionally conservative. If 529 persists for several attempts and the status page shows an active incident, stop escalating request volume. The goal is graceful degradation, not brute force.
The same principle applies in JavaScript or any other client: a good overload handler is transparent to operators, gentle to the provider, and quick to stop once the evidence says the service is still unhealthy.
What Claude Chat and Claude Code Users Should Do Instead
Many users searching this keyword are not making raw API calls at all. They are inside claude.ai, Claude Code, Workbench, Cursor, an MCP chain, or another tool that ultimately reaches Anthropic underneath. That changes the troubleshooting sequence.
For Claude chat, Anthropic's support article says capacity-constraint messages can appear during high demand and that these are temporary. If the message you see is the chat-specific capacity warning, the right move is usually to wait a few minutes, not to clear cookies for an hour. The same article also says five-hour usage-limit messages are a different class of issue entirely. Those indicate your plan budget for the session has been used up.
For Claude Code, check whether the failure is paired with login trouble, missing history, or broader service oddities. In the March 18, 2026 incident feed, the Claude.ai incident update explicitly noted that Claude Code login/logout actions were also affected. That is a strong hint that Claude Code symptoms can be part of a wider Anthropic event rather than an isolated local bug.
If your Claude Code workflow sits behind an MCP server or another local bridge, also inspect the layer in front of Anthropic. A routing layer can wrap or blur the original error. If you need more background on how those intermediary layers behave, the Claude MCP guide is worth bookmarking.
This is also why paid users get especially frustrated by 529 events. Paying for Pro, Max, or a funded API account does not buy immunity from overload. It buys access under that plan's rules. If the underlying service is stressed, even a correctly configured workflow can still stall.
The practical rule is this:
- If the whole Anthropic ecosystem feels unstable, think incident first.
- If only your subscription workflow is blocked, think plan limits or chat capacity.
- If only your API automation is blocked, inspect 529 vs 429 before touching product settings.
How to Reduce Future Overloaded Errors
You cannot eliminate platform-side overload, but you can reduce how much it hurts.
The first layer is better traffic shape. Avoid launching from zero to maximum concurrency in a burst. Anthropic's docs explicitly warn that shorter-interval enforcement and token-bucket behavior mean bursty traffic can fail even when your average looks safe.
The second layer is prompt and context discipline. Smaller, cleaner requests are easier to retry and less likely to run into edge conditions around long response times. If a request might run for a long time, use streaming where it makes sense rather than waiting on a giant non-streaming response.
The third layer is cache and reuse strategy. If your application re-sends the same large prefix over and over, you are increasing cost and failure surface at the same time. Prompt caching will not eliminate Anthropic-side overload, but it does reduce unnecessary traffic and makes it easier to separate genuine provider distress from self-inflicted request bloat.
The fourth layer is tier strategy. Anthropic's service tiers documentation says Priority Tier is intended for production workflows where availability and predictable pricing matter, and it explicitly says the tier helps minimize server-overloaded errors during peak times. That does not mean Priority Tier makes you outage-proof. It means teams with real uptime needs should stop pretending that Standard behaves like a production SLA.
The fifth layer is fallback architecture. If your entire business process stops when one provider has a bad hour, that is an operational design issue, not only a vendor issue. For teams that need a secondary API route, a relay or aggregation layer can help keep traffic moving during provider-specific instability. This is one of the few places where mentioning a provider like laozhang.ai is actually useful: not as a magical fix, but as an example of a secondary OpenAI-compatible routing path when you want redundancy instead of single-provider dependence.
The sixth layer is monitoring. Polling the incidents feed, logging request IDs, tracking model-specific error spikes, and alerting on repeated failures gives you a real operational picture. Community threads are useful as smoke signals, but they are not a monitoring system.
If recurring 529 problems are actually masking rate-limit design issues, read the fuller Claude API tier and quota breakdown after this article. A lot of teams think they have an outage problem when they really have a burst-control problem.
FAQ
Is Claude 529 overloaded error my fault? Usually no. 529 overloaded_error most often means Anthropic or an upstream service is temporarily saturated. Your code can still make the symptom worse if it retries too aggressively, but the existence of the error itself usually points to service pressure, not a malformed prompt.
How long does a 529 error usually last? There is no fixed window. Some incidents clear in a few minutes. Others take much longer. The right source is the live incidents feed on status.claude.com, not a recycled estimate from an old forum thread.
Should I retry immediately? Retry, but do it with backoff and jitter. One or two calm retries make sense. Flooding the API with parallel retries does not.
Is 529 the same as 429? No. In 2026 you should treat them as different diagnosis paths. 429 is a rate-limit path. 529 is usually an overload path. Anthropic's August 11, 2025 release note is the clearest official reason not to blur them.
Why is Claude chat broken but the status page looks normal? Because Anthropic's support docs say chat-side capacity constraints are not formal outages and do not appear on the status page. That is frustrating, but it is officially documented behavior.
What is the fastest safe workflow when this happens during coding? Check status, save your work, retry with backoff, and switch to a fallback model or endpoint if the incident persists. If you use Claude Code heavily, keep a second route available so a single provider outage does not erase your whole workday.